目录
[一、Spring Cloud Stream是什么?](#一、Spring Cloud Stream是什么?)
[2.1 微服务架构的挑战](#2.1 微服务架构的挑战)
[2.2 Spring生态的发展](#2.2 Spring生态的发展)
[2.3 Spring Integration的演进](#2.3 Spring Integration的演进)
[3.1 分层架构设计](#3.1 分层架构设计)
[3.2 核心组件详解](#3.2 核心组件详解)
[3.3 编程模型](#3.3 编程模型)
[4.1 解决的核心问题](#4.1 解决的核心问题)
[4.2 主要优势](#4.2 主要优势)
[5.1 消息中间件抽象](#5.1 消息中间件抽象)
[5.2 分区与负载均衡](#5.2 分区与负载均衡)
[5.3 函数式编程模型](#5.3 函数式编程模型)
[5.4 动态绑定](#5.4 动态绑定)
[5.5 死信队列支持](#5.5 死信队列支持)
[5.6 批量消费](#5.6 批量消费)
[6.1 与传统消息系统对比](#6.1 与传统消息系统对比)
[6.2 与Kafka Streams对比](#6.2 与Kafka Streams对比)
[6.3 与AWS Kinesis对比](#6.3 与AWS Kinesis对比)
[7.1 依赖配置](#7.1 依赖配置)
[7.2 函数式编程实现](#7.2 函数式编程实现)
[7.3 注解式模型实现](#7.3 注解式模型实现)
[7.4 动态绑定](#7.4 动态绑定)
[7.5 批量消费](#7.5 批量消费)
[7.6 死信队列配置](#7.6 死信队列配置)
[7.7 最佳实践](#7.7 最佳实践)
[8.1 事件驱动微服务](#8.1 事件驱动微服务)
[8.2 实时数据处理](#8.2 实时数据处理)
[8.3 微服务配置更新](#8.3 微服务配置更新)
[8.4 服务间异步通信](#8.4 服务间异步通信)
[9.1 云原生支持](#9.1 云原生支持)
[9.2 与Kubernetes集成](#9.2 与Kubernetes集成)
[9.3 响应式编程支持](#9.3 响应式编程支持)
[9.4 与Spring Cloud Function集成](#9.4 与Spring Cloud Function集成)
[9.5 与AI和机器学习结合](#9.5 与AI和机器学习结合)
Spring Cloud Stream是一个基于Spring Boot的框架,旨在简化消息中间件的集成和使用,为微服务架构提供统一的消息驱动通信模型 。它通过抽象化消息中间件的实现细节,使开发者能够专注于业务逻辑,而非底层消息传递机制。本文将深入探讨Spring Cloud Stream的定义、背景、架构、关键特性、使用方法及其在微服务中的应用价值,帮助开发者全面理解并掌握这一强大工具。

一、Spring Cloud Stream是什么?
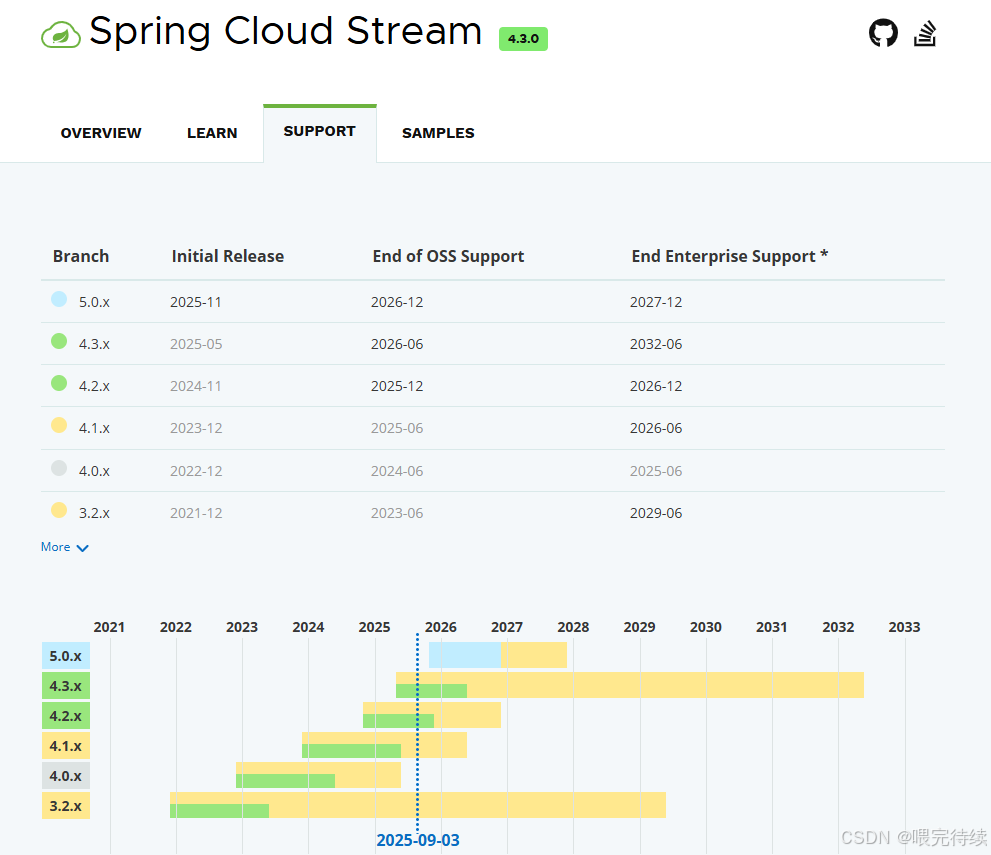
Spring Cloud Stream是一个用于构建消息驱动微服务的框架,它建立在Spring Boot和Spring Integration之上。Spring Cloud Stream的核心目标是提供一个统一的编程模型,让开发者能够轻松地与各种消息中间件进行交互,同时保持代码的中间件无关性 。通过这一框架,微服务可以作为消息的生产者或消费者,实现服务间松耦合的异步通信。
Spring Cloud Stream提供了一套简洁的API和注解,允许开发者以声明式的方式定义消息通道。这些通道通过Binder与具体的消息中间件(如Kafka、RabbitMQ等)连接。框架的核心组件包括Binder、消息通道、消息转换器和分区支持 ,它们共同构成了一个灵活且强大的消息处理平台。
Spring Cloud Stream的编程模型分为两种:注解式和函数式。注解式模型使用@EnableBinding、@Input、@Output和@StreamListener等注解定义消息通道和处理逻辑;函数式模型则通过定义Function、Supplier和Consumer接口实现更简洁的消息处理。这两种模型都旨在降低消息处理的复杂度,使开发者能够专注于业务逻辑。
二、诞生背景与设计动机
2.1 微服务架构的挑战
在分布式微服务架构中,服务间的通信是一个关键挑战。传统方法通常采用RESTful API进行同步通信,但这带来了紧耦合、延迟高和扩展性差等问题。消息驱动架构提供了一种更松耦合、异步且可扩展的通信方式,但直接使用消息中间件(如RabbitMQ或Kafka)的API往往会导致代码与中间件紧密耦合,使得系统难以适应中间件的变化。
2.2 Spring生态的发展
Spring框架自诞生以来,一直在简化Java开发。Spring Boot进一步简化了Spring应用的创建和部署,而Spring Cloud则扩展了Spring Boot的功能,为微服务架构提供了一系列解决方案。Spring Cloud Stream作为Spring Cloud生态系统的一部分,旨在解决微服务间消息通信的复杂性,它继承了Spring的简洁性和可配置性,同时提供了对消息中间件的抽象。
2.3 Spring Integration的演进
Spring Cloud Stream的设计受到Spring Integration的启发。Spring Integration是一个用于构建消息驱动应用的框架,提供了丰富的消息路由、转换和处理功能。Spring Cloud Stream在Spring Integration的基础上,进一步简化了消息中间件的集成,提供了更直观的API和配置方式,使开发者能够快速构建消息驱动的微服务。
三、架构设计与核心组件
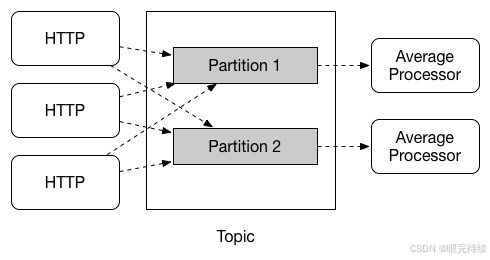
3.1 分层架构设计
Spring Cloud Stream采用分层架构设计,主要包括以下层次:
- 应用层:开发者编写业务逻辑,定义消息处理函数。
- 绑定层:通过Binder将应用层与消息中间件连接。
- 中间件层:具体的消息中间件实现(如Kafka、RabbitMQ等)。
这种分层设计确保了应用层与中间件层的解耦,使得中间件的替换变得简单。
3.2 核心组件详解
Spring Cloud Stream的核心组件包括:
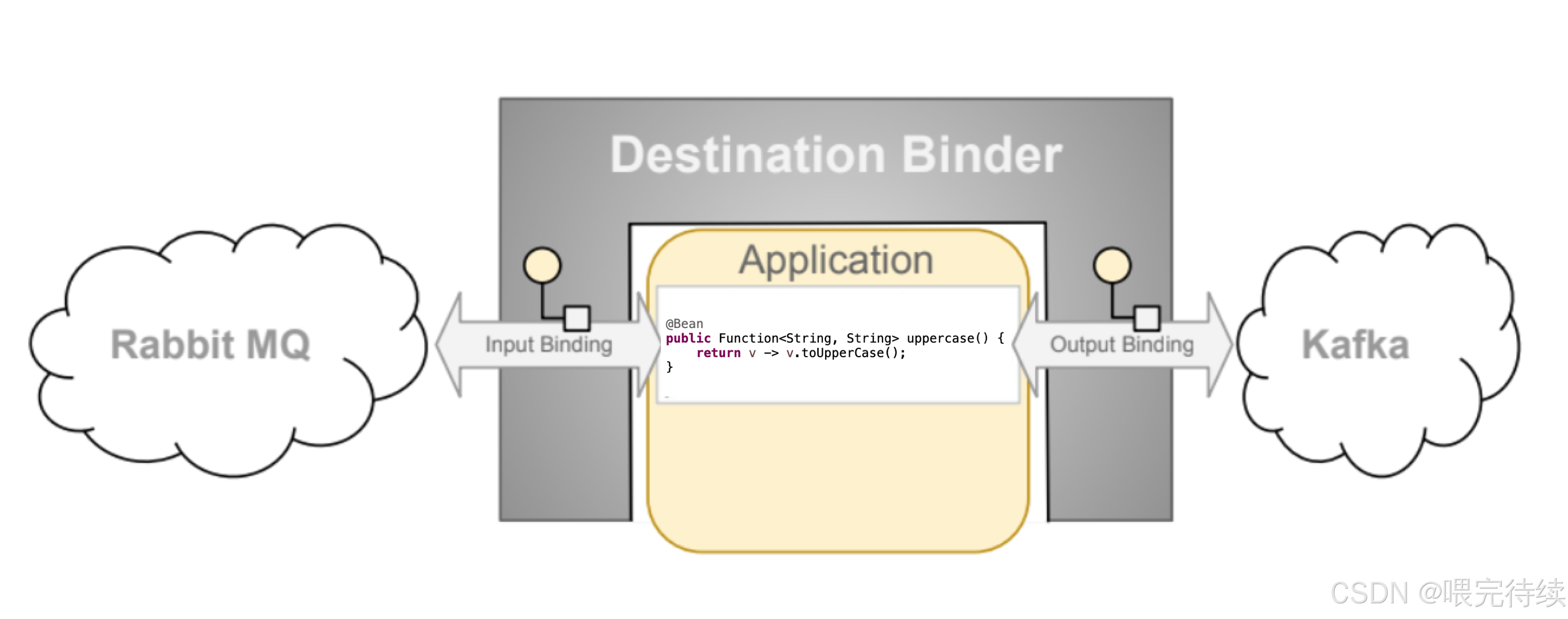
Binder:Binder是应用与消息中间件之间的桥梁。它负责创建和管理消息通道,处理消息的序列化和反序列化,并实现消息的发送和接收。Spring Cloud Stream提供了多种Binder实现,包括Kafka、RabbitMQ、AWS Kinesis和Azure Event Hubs等。
消息通道 :消息通道是应用与外部消息系统之间的连接点。Spring Cloud Stream定义了三种类型的通道:输入通道(@Input)、输出通道(@Output)和处理器通道(同时包含输入和输出)。开发者可以通过这些通道发送和接收消息。
消息转换器:消息转换器负责将应用层的消息对象转换为中间件支持的消息格式,反之亦然 。Spring Cloud Stream提供了多种内置转换器,也支持自定义转换器。
分区支持 :分区是消息中间件(如Kafka)中用于提高吞吐量和实现并行处理的机制。Spring Cloud Stream提供了一个统一的分区抽象,使得开发者可以在不关心具体中间件实现的情况下,利用分区功能提高系统性能。
3.3 编程模型
Spring Cloud Stream提供了两种编程模型:
注解式模型 :使用@EnableBinding注解启用绑定器,并通过@Input和@Output定义消息通道。消息处理通过@StreamListener注解实现。
函数式模型 :通过定义Function、Supplier和Consumer接口实现消息处理逻辑,配置通过spring.cloud.stream.function狭义属性定义。函数式模型在Spring Cloud Stream 3.x版本中成为推荐方式,提供了更简洁的API。
这两种模型都遵循Spring的配置即代码理念,使开发者能够以声明式的方式定义消息处理逻辑,而无需关心底层实现细节。
四、解决的问题与优势
4.1 解决的核心问题
Spring Cloud Stream主要解决了以下几个关键问题:
消息中间件耦合 :传统消息系统开发中,应用代码与特定消息中间件的API紧密耦合,使得中间件的替换变得困难。Spring Cloud Stream通过Binder抽象层隔离了应用与中间件的实现细节 ,使代码与中间件无关。
配置复杂度 :直接使用消息中间件API需要处理大量配置细节,如连接参数、交换机/主题创建、队列绑定等。Spring Cloud Stream通过声明式配置简化了这些过程 ,使开发者能够专注于业务逻辑。
分区与消费组管理 :消息中间件的分区和消费组机制复杂,需要开发者手动管理。Spring Cloud Stream提供了一套统一的分区和消费组管理API,简化了这些功能的使用。
消息转换 :不同消息中间件对消息格式有不同的要求,需要开发者手动处理转换。Spring Cloud Stream内置了多种消息转换器 ,并支持自定义转换器,使消息格式转换变得透明。
4.2 主要优势
Spring Cloud Stream相比传统消息系统和同类框架具有以下优势:
中间件无关性:通过Binder抽象层,开发者可以轻松切换消息中间件,无需修改应用代码。
声明式配置:使用YAML/Properties文件进行配置,避免了硬编码,提高了配置的灵活性和可维护性。
简化API:提供了简洁的API和注解,使消息处理逻辑的编写变得简单直观。
统一的消息处理模型:提供了一套统一的消息处理模型,包括分区、消费组和消息转换等高级功能。
与Spring生态无缝集成:与Spring Boot、Spring Cloud和Spring Integration等框架无缝集成,可以与其他Spring Cloud组件(如Config、Bus等)协同工作 。
五、关键特性与高级功能
5.1 消息中间件抽象
Spring Cloud Stream的核心优势在于其消息中间件抽象能力 。通过Binder接口,框架屏蔽了不同消息中间件的实现差异,为开发者提供了一致的编程模型。这种抽象使得应用可以轻松切换消息中间件,而无需修改业务逻辑代码。
目前,Spring Cloud Stream支持多种消息中间件,包括:
- Apache Kafka
- RabbitMQ
- AWS Kinesis
- Azure Event Hubs
- Google Pub/Sub
每种中间件都有对应的Binder实现,如spring-cloud-stream-binder-kafka或spring-cloud-stream-binder-rabbit。
5.2 分区与负载均衡
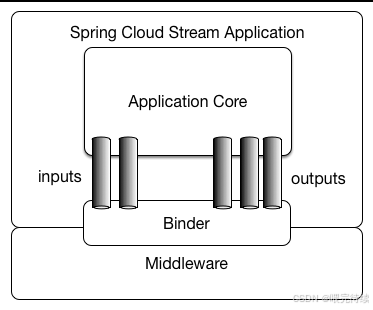
分区是Spring Cloud Stream中的一个关键特性,它允许应用在多个实例之间分配数据处理任务。在有状态处理场景(如时间窗口计算)中,确保同一数据由同一实例处理至关重要。Spring Cloud Stream提供了统一的分区API,使得开发者可以在不关心具体中间件实现的情况下,利用分区功能提高系统性能。
分区支持包括:
- 分区键表达式 :通过
partitionKeyExpression属性定义分区键,决定消息发送到哪个分区 。 - 分区计数 :通过
partitionCount属性指定消息的分区数量 。 - 负载均衡策略:支持多种负载均衡策略,如轮询、随机等,确保消息在不同分区间均匀分布。
5.3 函数式编程模型
函数式编程模型是Spring Cloud Stream 3.x版本中的重要特性,它提供了更简洁的消息处理方式。在函数式模型中,开发者只需定义消息处理函数,而无需关注消息通道的创建和绑定。
函数式模型支持以下接口:
Function<T, R>:处理输入消息并生成输出消息。Supplier<T>:生成输出消息。Consumer<T>:处理输入消息。
通过spring.cloud.stream.function狭义属性,可以指定应用使用的函数。
5.4 动态绑定
Spring Cloud Stream支持动态绑定,允许应用在运行时切换消息中间件或通道配置 。通过BinderAwareChannelResolver和ExpressionEvaluatingRouter,应用可以根据需要动态创建和路由消息通道。
动态绑定的配置包括:
spring.cloud.stream dynamicDestinations:指定允许动态绑定的通道名称白名单 。spring.cloud.stream.bindings.*.destination:定义通道绑定的消息中间件目标(如Kafka的Topic或RabbitMQ的Exchange)。
5.5 死信队列支持
消息处理失败是分布式系统中的常见问题,Spring Cloud Stream提供了对死信队列(DLQ)的支持 ,允许应用将处理失败的消息发送到特定队列,以便后续分析或重试。
死信队列的配置包括:
spring.cloud.stream.bindings.*.consumer.max-attempts:指定消息处理的最大重试次数。spring.cloud.stream.bindings.*.consumer RepublishMessageRecoverer:配置消息重试失败后的恢复策略,如发送到死信队列 。
5.6 批量消费
在处理高吞吐量消息时,批量消费可以显著提高处理效率。Spring Cloud Stream支持批量消费模式,允许消费者一次性处理多条消息。
批量消费的配置包括:
spring.cloud.stream.bindings.*.consumer.batch-mode=true:启用批量消费模式 。spring.cloud.stream.bindings.*.consumer.batch-size=100:指定批量消费的消息数量 。
六、与同类产品的对比
6.1 与传统消息系统对比
传统消息系统(如直接使用RabbitMQ或Kafka客户端)需要开发者手动处理消息中间件的细节,连接管理、交换机/主题创建、队列绑定等。这些硬编码的配置使得系统难以适应中间件的变化。
| 特性 | Spring Cloud Stream | 传统消息系统 |
|---|---|---|
| 中间件耦合 | 低(通过Binder抽象) | 高(硬编码API) |
| 配置复杂度 | 简单(声明式配置) | 复杂(手动配置) |
| 分区支持 | 统一API | 中间件特定API |
| 消息转换 | 内置支持 | 需手动实现 |
| 跨中间件迁移 | 简单 | 困难 |
6.2 与Kafka Streams对比
Kafka Streams是Kafka生态中的流处理库,它提供了强大的流处理能力,但仅限于Kafka环境。与Kafka Streams相比,Spring Cloud Stream更专注于消息通信的抽象,支持多种消息中间件,更适合需要灵活切换中间件的场景。
| 特性 | Spring Cloud Stream | Kafka Streams |
|---|---|---|
| 中间件支持 | 多种(Kafka、RabbitMQ等) | 仅Kafka |
| 编程模型 | 注解式/函数式 | 流处理API(KStream、KTable) |
| 中间件耦合 | 低 | 高(深度集成Kafka) |
| 适用场景 | 通用消息通信 | Kafka特定流处理 |
| 部署灵活性 | 高 | 中(依赖Kafka环境) |
6.3 与AWS Kinesis对比
AWS Kinesis是AWS云平台上的流数据处理服务 ,它提供了强大的流处理能力,但仅限于AWS环境。Spring Cloud Stream通过AWS Kinesis Binder提供了对Kinesis的支持,但相比直接使用Kinesis SDK,Spring Cloud Stream提供了更统一的API和配置方式。
| 特性 | Spring Cloud Stream + Kinesis | AWS Kinesis SDK |
|---|---|---|
| 云平台支持 | AWS、Azure、Google等 | 仅AWS |
| 中间件抽象 | 是 | 否 |
| 配置方式 | 声明式(YAML/Properties) | 程序化配置 |
| 与其他Spring组件集成 | 完美支持 | 需额外适配 |
| 代码可移植性 | 高 | 低(AWS特定) |
七、使用方法与最佳实践
7.1 依赖配置
Spring Cloud Stream的依赖配置相对简单,主要通过添加对应的消息中间件Binder实现。以下是基于Spring Boot 3.5.3和Spring Cloud 2025.0.0的依赖配置示例:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>3.5.3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2025.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring Cloud Stream核心依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream</artifactId>
</dependency>
<!-- Kafka Binder依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
<!-- 或者RabbitMQ Binder依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
</dependencies>7.2 函数式编程实现
函数式编程模型是Spring Cloud Stream 3.x版本中的推荐方式,它提供了更简洁的API。以下是一个使用函数式模型的消息生产者和消费者示例:
// 生产者
@Service
public class OrderProducer {
@Bean
public Supplier<Order> createOrder() {
return () -> {
Order order = new Order();
order.setOrderId UUID.randomUUID().toString());
order.set productId "P123";
order.set quantity 10;
log.info("发送订单: {}", order.getOrderId());
return order;
};
}
}
// 消费者
@Service
public class InventoryConsumer {
@Bean
public Consumer<Order> updateInventory() {
return order -> {
log.info("接收订单: {}", order.getOrderId());
// 更新库存逻辑
};
}
}
// 主类
@SpringBootApplication
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}在application.yml中配置:
spring:
cloud:
stream:
function:
definition: createOrder;updateInventory
.bindings:
createOrder-out-0:
destination: order-topic
updateInventory-in-0:
destination: order-topic
group: inventory-group7.3 注解式模型实现
注解式模型是Spring Cloud Stream的传统方式,它提供了更细粒度的控制。以下是一个使用注解式模型的消息生产者和消费者示例:
// 定义绑定接口
public interface OrderBinding {
String ORDER = "order";
@Output(ORDER)
MessageChannel orderChannel();
}
// 生产者
@RestController
public class OrderController {
@Autowired
private OrderBinding orderBinding;
@PostMapping("/orders")
public String createOrder(@RequestBody Order order) {
// 发送消息
orderBinding.orderChannel().send(
MessageBuilder.withPayload(order)
.setHeader("partitionKey", order的产品ID)
.build()
);
return "订单创建成功";
}
}
// 消费者
@Service
public class InventoryService {
@EnableBinding(OrderBinding.class)
public class InventoryConsumer {
@StreamListener(OrderBinding.ORDER)
public void handleOrder(Order order) {
// 更新库存逻辑
}
}
}
// 主类
@SpringBootApplication
public class InventoryServiceApplication {
public static void main(String[] args) {
SpringApplication.run(InventoryServiceApplication.class, args);
}
}在application.yml中配置:
spring:
cloud:
stream:
.bindings:
order:
destination: order-topic
group: inventory-group
.kafka:
binder:
brokers: localhost:9092
defaultBrokerPort: 90927.4 动态绑定
动态绑定允许应用在运行时切换消息通道的绑定目标,这对于需要灵活路由消息的场景非常有用。以下是一个动态绑定的示例:
@RestController
public class DynamicDestinationController {
@Autowired
private StreamBridge streamBridge;
@PostMapping("/send")
public String sendDynamicMessage(
@RequestParam String message,
@RequestHeader("dest") String destination
) {
// 动态发送消息
streamBridge.send(
destination + "-out-0",
MessageBuilder.withPayload(message)
.build()
);
return "消息发送成功";
}
}在application.yml中配置:
spring:
cloud:
stream:
dynamicDestinations: dynamic1,dynamic2,dynamic3
.bindings:
dynamic1-out-0:
destination: dynamic1-topic
dynamic2-out-0:
destination: dynamic2-topic
dynamic3-out-0:
destination: dynamic3-topic7.5 批量消费
批量消费可以显著提高高吞吐量场景下的处理效率。以下是一个启用批量消费的示例:
@Service
public class BatchConsumer {
@Bean
public Consumer<List<Order>> batchHandleOrder() {
return orders -> {
log.info("接收批量订单: {}条", orders.size());
// 批量处理订单逻辑
};
}
}在application.yml中配置:
spring:
cloud:
stream:
.bindings:
batchHandleOrder-in-0:
destination: order-topic
consumer:
batch-mode: true
batch-size: 1007.6 死信队列配置
死信队列(DLQ)是处理消息处理失败的重要机制 。以下是一个配置死信队列的示例:
spring:
cloud:
stream:
.bindings:
input:
destination: order-topic
group: inventory-group
consumer:
max-attempts: 3
republish-to-dlq: true
dlq-name: order-dlq-topic
.kafka:
binder:
default-retryable: true当消息处理失败超过max-attempts次数时,消息会被自动发送到指定的死信队列。
7.7 最佳实践
在使用Spring Cloud Stream时,以下是一些最佳实践:
-
版本兼容性:确保Spring Boot和Spring Cloud版本的兼容性。例如,Spring Boot 3.5.3对应Spring Cloud 2025.0.0。
-
分区策略 :合理选择分区键,确保同一数据由同一消费者实例处理。例如,可以使用
partitionKeyExpression: payload的产品ID将同一产品的订单路由到同一分区。 -
消息头处理 :充分利用消息头传递元数据,如时间戳、优先级等。例如,可以使用
setHeader("x-delay", 5000)实现消息的延迟发送 。 -
重试机制 :合理配置重试次数和退避策略,避免消息处理失败导致系统不稳定。例如,可以使用
back-off-initial-interval: 1000和back-off-max-interval: 10000配置重试间隔 。 -
死信队列监控:定期监控死信队列中的消息,分析处理失败原因,及时修复问题。
-
资源管理:在高吞吐量场景中,合理配置消费者数量和分区数量,确保系统资源的充分利用。
八、实际应用场景
8.1 事件驱动微服务
在事件驱动架构中,Spring Cloud Stream是构建微服务间通信的理想选择 。订单服务在创建订单后,可以发布一个OrderCreated事件,库存服务、物流服务和通知服务等消费者可以监听并处理这一事件,实现服务间的松耦合通信。
8.2 实时数据处理
Spring Cloud Stream适合实时数据处理场景,如日志分析、实时监控和交易处理等。通过结合函数式编程模型和批量消费功能,可以高效处理大量实时数据流。
8.3 微服务配置更新
Spring Cloud Bus可以与Spring Cloud Stream结合使用 ,实现微服务配置的动态更新。通过发布一个Refresh事件,可以通知所有订阅该事件的服务重新加载配置,无需重启整个系统。
8.4 服务间异步通信
在需要异步通信的场景中,Spring Cloud Stream提供了一种简洁的解决方案 。例如,支付服务在处理支付请求后,可以异步通知订单服务更新订单状态,避免同步调用带来的延迟和性能问题。
九、未来发展趋势
9.1 云原生支持
随着云原生技术的发展,Spring Cloud Stream正在加强对其的支持。Spring Cloud Azure提供了对Azure Event Hubs和Service Bus的支持,而Spring Cloud Alibaba则提供了对阿里云消息服务的支持。这些云原生绑定器使开发者能够在云环境中更轻松地使用Spring Cloud Stream。
9.2 与Kubernetes集成
Kubernetes已成为微服务部署的主流平台 ,Spring Cloud Stream正在加强与Kubernetes的集成。例如,通过kafka-clients和kafka行政等依赖,可以更好地管理Kafka集群在Kubernetes环境中的部署和扩展。
9.3 响应式编程支持
响应式编程(如Project Reactor)在处理高并发和异步操作方面具有显著优势 ,Spring Cloud Stream正在加强对其的支持。例如,通过Flux和Mono等响应式类型,可以更高效地处理消息流,并实现背压(Backpressure)管理。
9.4 与Spring Cloud Function集成
Spring Cloud Function是Spring Cloud生态系统中的一个新兴项目,它提供了一套统一的函数式API,可以与Spring Cloud Stream无缝集成。这种集成将进一步简化消息驱动应用的开发,并提高代码的可重用性。
9.5 与AI和机器学习结合
随着AI和机器学习技术的发展,Spring Cloud Stream正在探索与这些技术的结合。通过将流处理与机器学习模型结合,可以实现更智能的消息处理和分析。这种结合将为微服务架构带来更强大的数据处理能力。
十、总结与建议
Spring Cloud Stream是一个强大的框架,为微服务架构提供了统一的消息驱动通信模型 。它通过抽象化消息中间件的实现细节,简化了消息处理的开发过程,使开发者能够专注于业务逻辑。
在实际应用中,建议根据项目需求选择合适的编程模型(函数式或注解式)和消息中间件。对于简单场景,函数式模型提供了更简洁的API;对于需要细粒度控制的场景,注解式模型提供了更多灵活性。同时,合理配置分区策略、消息头和重试机制,可以提高系统的性能和可靠性。
随着云原生和响应式编程的发展,Spring Cloud Stream将继续演进,为微服务架构提供更强大的数据处理能力。开发者应该关注其最新版本和云原生绑定器的更新,以便更好地利用这些新技术。
Spring Cloud Stream是构建消息驱动微服务的理想选择,它通过简化消息中间件的集成和使用,提高了开发效率和系统可维护性。通过合理应用其特性,开发者可以构建更加灵活、高效和可靠的微服务架构。
参考资料:
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊"技术内外的那些事",让你的代码之外,更有"技术眼光"。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!
关于博主: