异常检测:
异常检测也是无监督学习的一种,通过查看正常事件的无标签数据集,从而学习来检测/发出异常警报。
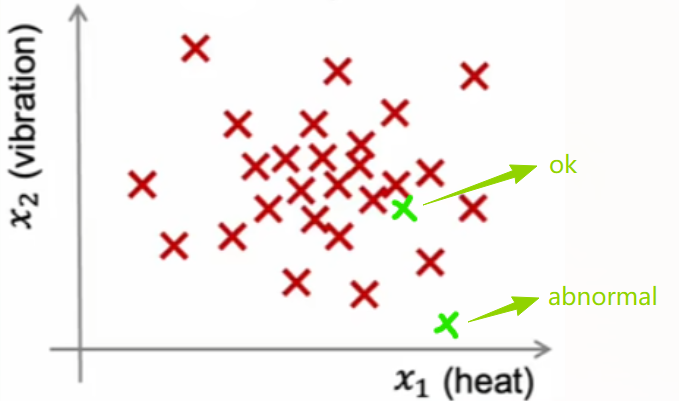
如上图所示,红色部分表示训练集样本,而绿色部分表示新样本。如果新样本的位置与训练集样本接近,我们倾向于认为新样本正常;而如果与训练集样本有较大差异,则认为存在异常情况。
密度估计:
在实际运用中,我们通过密度估计的方法来判断新样本是否与训练集样本相似。它的主要思想是:根据n个训练集样本来建立模型,该模型可以反映不同
,也就是具体样本的实际存在概率,而当有一个新样本
时,利用该模型,若:
则认为该样本异常。
高斯分布:
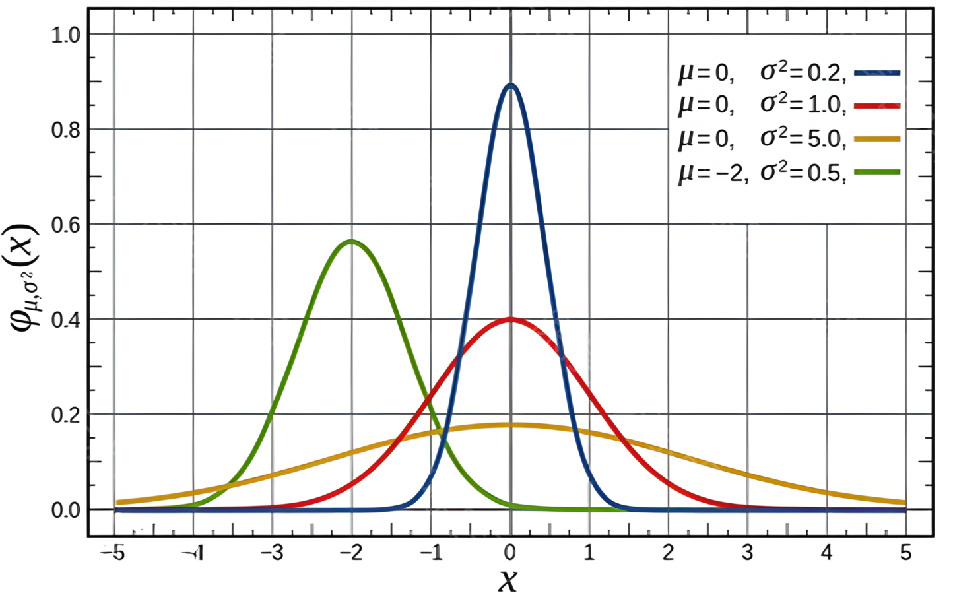
为了建立此模型,首先介绍高斯分布(正态分布)的概念,下图几条典型的钟形曲线均为高斯分布的概率密度函数,函数中的表示均值,
表示标准差。根据图像易知,取值越接近均值,它的概率就越大。而对应到异常检测中则是,新样本与训练集样本偏离越小,也就是越接近"均值",它属于正常的概率就越大。
因此,已知m个样本时:
对应样本存在n个特征时,模型表示为:
建模与评估:
首先选择可能表明异常的特征计算得到相应的和
,制作训练集构建
模型;
将模型运用于验证集,检查结果调整与特征;
最终将模型运用于测试集。
当我们有一定的异常样本时,在验证集和测试集中添加少量 的异常样本是很有帮助的,因为如果无监督异常检测模型只学习了"正常"的模式,任何偏离该模式的数据都会被标记为异常,这可能导致一些稀有但正常的样本被误报。而在验证集和测试集中添加异常样本有助于我们更好的确定决策边界,调整与特征。由于异常样本一般很少,有时候也可能直接删除测试集 ,把所用样本全部用于训练和验证,但有可能会带来过拟合风险。
在之后遇到新样本时,我们需要比较模型预测结果与实际结果,需要注意的是,异常检测问题属于数据倾斜 的情况,此时采用精确率、召回率以及分数(精确率、召回率与F1分数)来进行评估会更为合理。
特征选择:
前面提到了根据验证集结果来调整特征,而实际在特征选择的时候,异常检测模型更多的会选择本身较为符合高斯分布的特征来进行建模,或者是对于原始特征进行一定的转换,如取对数、+常数后取对数以及开方等等,使得转换后的特征更符合高斯分布。
此外,我们还可以根据已有模型的误差分析来优化特征选择。根据模型检测结果,分析未能成功检测出来的异常,可以发掘出新的特征,或是对旧特征进行重组。
异常检测与监督学习:
假设目前已经拥有了一定的异常样本,那么实际上也可以采用监督学习的方法来检测是否存在异常,如何在异常检测与监督学习中进行抉择呢?
首先,如果我们拥有的样本是大量的正常样本以及极少量的异常样本 ,一般来说选择异常检测 的效果会更好;如果两类样本数量都很多 时,则更倾向于选择监督学习,因为如果在异常检测的训练集中混入了太多的异常样本,会影响到模型对主体正常分布的学习。
如果该问题的异常样本有很多种不同的类型 ,甚至之后还有可能会出现新的类型 ,一般来说异常检测 的效果会更好。因为对于多类型的异常,采用监督学习需要保证每个类型的样本数量足够,这在实际应用中是很少见的,同时对于没有见过的新型异常,监督学习无法给出有效地预测结果。即监督学习 更多地认为需要检测地异常样本会与原始训练集中的异常样本很相似 ;而对于异常检测 而言,它更多地关注正常样本并依此建模,因此只要与正常样本偏离较大则会被认为异常。