文章目录
- [一、CIFAR10 数据集](#一、CIFAR10 数据集)
- 二、搭建图像分类网络
-
- 1、计算隐藏层1的输入特征个数
- [2、time.perf_counter() 精确测量代码执行耗时](#2、time.perf_counter() 精确测量代码执行耗时)
- 3、代码:
- 三、编写训练函数
-
- [1、GPU 计算优势](#1、GPU 计算优势)
- [2、安装 PyTorch 的 GPU版](#2、安装 PyTorch 的 GPU版)
- 3、代码:
- 4、汇总:哪些东西需要转到GPU计算
- 四、编写预测函数
-
- [1、nn.Softmax 和 torch.softmax](#1、nn.Softmax 和 torch.softmax)
- 2、代码:
- 五、整体代码:
一、CIFAR10 数据集
1、基本介绍
CIFAR-10 是一个广泛使用的图像识别数据集,由加拿大圭尔夫大学的Alex Krizhevsky、Ilya Sutskever和多伦多大学的Geoffrey Hinton整理。这个数据集被设计用于机器学习中的图像分类任务。
CIFAR-10数据集5万张训练图像、1万张测试图像、10个类别、每个类别有6k个图像,图像大小32×32×3。下图列举了10个类,每一类随机展示了10张图片:

数据集内容
- 类别数量: CIFAR-10 包含了10个不同的类别,每个类别有6000张32x32彩色图像,总共包含60000张图像。这10个类别包括:飞机(airplane)、汽车(automobile)、鸟(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck)。
- 训练集与测试集划分: 数据集中50000张图像作为训练集,剩下的10000张图像作为测试集以评估模型性能。
- 图像格式: 每张图片都是32x32分辨率的彩色图片,这意味着每张图片都有RGB三个通道。
使用场景
CIFAR-10 数据集常被用作开发、训练和评估图像分类算法的基础,特别是对于深度学习和卷积神经网络(CNNs)的研究。由于其相对较小的数据量和适中的图像尺寸,它非常适合用来测试新的模型或算法,同时不会对计算资源造成过大的负担。
2、CIFAR10 - API & 参数
一、CIFAR10 是什么?(简要回顾)
CIFAR-10(Canadian Institute For Advanced Research - 10 classes)是一个用于图像分类任务的经典基准数据集,包含:
- 60,000 张 32×32 彩色图像
- 10 个互斥类别 :
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] - 训练集:50,000 张(每类 5,000 张)
- 测试集:10,000 张(每类 1,000 张)
由于其图像尺寸小、类别均衡、语义清晰,CIFAR-10 被广泛用于深度学习模型(尤其是 CNN)的原型开发、教学和性能验证。
二、PyTorch 中的 CIFAR10 类概述
在 PyTorch 生态中,CIFAR10 是 torchvision.datasets 模块提供的标准数据集类之一。它继承自 VisionDataset,实现了统一的数据加载接口,并支持自动下载、缓存、变换等功能。
导入方式:
python
# 需要下载第三方库 pip install torchvision -i https://mirrors.aliyun.com/pypi/simple/
from torchvision.datasets import CIFAR10
# 或
import torchvision.datasets as datasets三、构造函数参数详解(逐项剖析)
CIFAR10 的构造函数签名为:
python
dataset = CIFAR10(root, train=True, transform=None, target_transform=None, download=False)
# 返回值 dataset 后面有详情下面对每个参数进行深度解析:
root: str
-
作用:指定数据集存储的根目录。
-
行为:
- 如果该路径下已存在
cifar-10-batches-py/文件夹(即原始解压后的数据),则直接读取。 - 如果不存在且
download=True,则自动下载并解压到此目录。
- 如果该路径下已存在
-
建议:
- 使用相对路径如
'./data'或绝对路径如'/home/user/datasets/cifar10'。 - 避免使用临时目录,以免重复下载。
- 使用相对路径如
-
内部结构(下载后):
data/ └── cifar-10-batches-py/ ├── data_batch_1 ├── data_batch_2 ├── ... ├── test_batch ├── batches.meta └── readme.html
📌 注意:
root是父目录 ,实际数据会放在root/cifar-10-batches-py/下。
train: bool
- 作用:决定加载训练集还是测试集。
- 取值 :
True→ 加载 50,000 张训练图像(data_batch_1到data_batch_5)False→ 加载 10,000 张测试图像(test_batch)
- 注意 :
- 此参数不控制是否"用于训练" ,仅控制数据来源。
- 即使设为
False,你仍可将其用于训练(如做交叉验证),但通常不这么做。
download: bool(默认False)
-
作用:是否自动从官方服务器下载数据集。
-
关键逻辑:
- 如果
root/cifar-10-batches-py/目录存在且非空,则跳过下载 (即使download=True)。 - 如果目录不存在或为空,且
download=False,则抛出RuntimeError。
- 如果
-
最佳实践:
python# 首次运行时设为 True,后续可设为 False dataset = CIFAR10(root='./data', train=True, download=True) -
下载源 :默认从 https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 下载(约 170MB)。
⚠️ 警告:某些网络环境(如国内)可能无法访问该 URL,需手动下载并解压到对应目录。
transform: Callable | None(默认None)
-
作用 :对图像(PIL Image) 应用的变换函数。
-
输入 :
PIL.Image.Image对象(RGB,32×32)特别注意:
CIFAR10(root='./data', train=True, transform=transforms.ToTensor, download=True)以上是错的
正确的是:
CIFAR10(root='./data', train=True, transform=transforms.ToTensor(), download=True)原因:
transform=transforms.ToTensor实际上传递的是一个类而非一个实例化对象。需要确保传递给transform参数的是ToTensor类的一个实例,而不是类本身 -
输出 :任意类型(通常是
torch.Tensor)
🎯 一句话理解
transform
transform就是你告诉 PyTorch:"当我从数据集中取出一张图片时,请先对它做这些处理,再给我。"
🧩 为什么需要
transform?原始 CIFAR-10 图像是:
- 格式:
PIL.Image(Python 图像库对象)- 像素值:0 到 255 的整数
- 形状:高度 × 宽度 × 通道 →
(32, 32, 3)但神经网络(尤其是 PyTorch 模型)通常需要:
- 输入类型:
torch.Tensor- 像素范围:
[0.0, 1.0]或标准化后的值(如均值为 0)- 形状:通道 × 高度 × 宽度 →
(3, 32, 32)所以,必须把原始图像"转换"成模型能吃的格式 ------ 这就是
transform的作用!
🔧
transform是怎么工作的?(流程图)
原始图像 (PIL.Image, 32x32x3, [0-255]) ↓ [transform 函数被调用] ↓ 处理后的数据 (通常是 torch.Tensor, [3,32,32], [0.0-1.0]) ↓ 返回给 dataset[i] 或 DataLoader⚠️ 注意:这个转换不是一次性完成的 ,而是每次你访问
dataset[i]时才执行(惰性计算),这样可以节省内存,并支持数据增强(每次取图都可能不同)。
✅ 最简单的例子:
ToTensor()
pythonfrom torchvision import transforms from torchvision.datasets import CIFAR10 # 定义 transform transform = transforms.ToTensor() # 创建数据集 dataset = CIFAR10(root='./data', train=True, transform=transform, download=True) # 取出第 0 张图 img, label = dataset[0] print(type(img)) # <class 'torch.Tensor'> print(img.shape) # torch.Size([3, 32, 32]) print(img.min(), img.max()) # tensor(0.) tensor(1.) ← 自动归一化到 [0,1]
ToTensor()干了两件事:
- 把
PIL.Image转成torch.Tensor- 把像素值从
[0, 255]缩放到[0.0, 1.0]- 把维度从
(H, W, C)变成(C, H, W)← 这是 PyTorch 的标准格式!
🌈 更复杂的例子:带数据增强
pythontransform = transforms.Compose([ transforms.RandomHorizontalFlip(p=0.5), # 50% 概率水平翻转 transforms.RandomCrop(32, padding=4), # 随机裁剪(加 padding 防止变小) transforms.ToTensor(), # 转 Tensor + 归一化到 [0,1] transforms.Normalize( # 再标准化(减均值、除标准差) mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616] ) ]) dataset = CIFAR10(root='./data', train=True, transform=transform) img, label = dataset[0] print(img.shape) # [3, 32, 32] print(img.mean(), img.std()) # 接近 0 和 1(因为标准化了)💡 关键点:每次
dataset[0]都可能得到不同的图像 !因为RandomHorizontalFlip和RandomCrop是随机的。这就是"数据增强"------用同一张图生成多种变体,防止过拟合。
❌ 如果不设
transform会怎样?
pythondataset = CIFAR10(root='./data', train=True, transform=None) img, label = dataset[0] print(type(img)) # <class 'PIL.Image.Image'> print(img.size) # (32, 32) # 你不能直接把这个 img 喂给 PyTorch 模型!会报错。所以,几乎所有的训练代码都会设置
transform=ToTensor()或更复杂的组合。
📌 总结:
transform的核心要点
项目 说明 输入 一张 PIL.Image(32×32 彩色图)输出 通常是 torch.Tensor,但也可是其他(如 NumPy)执行时机 每次你调用 dataset[i]时目的 让图像变成模型能接受的格式 + 数据增强 常用工具 torchvision.transforms模块(ToTensor,Normalize,RandomCrop等)组合方式 用 transforms.Compose([...])把多个变换串起来
💡 类比理解(生活化)
想象你去餐厅点了一份生牛排(原始图像):
- 不加
transform:厨师直接把生肉端给你 → 你没法吃(模型报错)。- 加
ToTensor():厨师把它煎熟了(转成 Tensor),切成小块(调整维度),撒了盐(归一化)→ 你可以吃了。- 加复杂
transform:厨师不仅煎熟,还可能加黑椒、切不同形状、配不同酱料(数据增强)→ 每次吃都有点不一样,但都是"可食用的牛排"。
target_transform: Callable | None(默认None)
-
作用 :对标签(整数) 应用的变换函数。
-
输入 :
int(0~9) -
输出:任意类型(如 one-hot 向量、字符串等)
-
示例:
pythonimport torch # 转为 one-hot 编码 def to_one_hot(label): return torch.eye(10)[label] dataset = CIFAR10(..., target_transform=to_one_hot) -
使用场景较少,多数情况下标签保持为整数即可。
四、CIFAR10 对象的核心属性与方法
创建 CIFAR10 实例后,可访问以下重要属性:
| 属性 | 返回类型 | 说明 |
|---|---|---|
.data |
np.ndarray |
原始图像数据,形状 (N, 32, 32, 3),dtype uint8,通道在最后 |
.targets |
list[int] |
所有标签列表,长度 N,每个元素 ∈ 0, 9 |
.classes |
list[str] |
类别名称列表,顺序固定:['airplane', ..., 'truck'] |
.class_to_idx |
dict[str, int] |
类别名 → 索引映射,如 {'cat': 3} |
.__len__() |
int |
返回数据集大小(50k 或 10k) |
.__getitem__(index) |
(PIL.Image, int) 或经 transform 后的类型 |
支持索引访问 |
🔍 关键区别:
.data是 NumPy 格式 ,未经过transform,维度为[H, W, C]dataset[i]返回的是 经过 transform 处理后的结果 ,通常是[C, H, W]的 Tensor
1、.__getitem__(index) 介绍:
__getitem__(index) 是 Python 中的一个特殊方法(魔术方法) ,用于让对象支持 obj[index] 的索引访问语法。
在 PyTorch 的 Dataset 类(如 CIFAR10)中:
- 作用 :根据索引
index返回一个样本 ,格式为(data, label)。 - 调用方式 :当你写
dataset[i]时,Python 自动调用dataset.__getitem__(i)。 - 返回值 :
data:经过transform处理后的图像(如Tensor)label:对应的标签(通常是int,或经target_transform处理的结果)
- 要求 :所有自定义
Dataset必须实现此方法,才能被DataLoader使用。
✅ 示例:
python
img, label = dataset[0] # 等价于 dataset.__getitem__(0)简言之:__getitem__ 让数据集像列表一样按索引取样本,是 PyTorch 数据加载的核心接口。
2、.classes可以获得标签对应的类别名称
为了根据数值标签获取对应的类别名称(例如,将 9 转换为 'truck'),你可以利用 train.classes 属性。这个属性返回一个列表,其中的索引对应于类别的整数标签,而值则是类别的名称字符串。因此,你不需要遍历 train.class_to_idx 字典来查找对应的类别名,直接使用标签作为索引来访问 train.classes 列表即可。
展示了如何实现这一点:
python
train = CIFAR10(root='./data', train=True, transform=transforms.ToTensor(), download=True)
# 第1张 图片对应的类型是
img, label = train[1] # img 是 tensor (C、H、W)
print(type(label)) # 应该是<class 'int'>而不是直接打印数字,请确保理解这里的输出
print(f'第1张 图片对应的类型(标签)是: {label}')
print(f'第1张 图片对应的类型(名称)是: {train.classes[label]}') # 使用label作为索引来获取类名这里的关键部分是最后一行代码,它通过将 label 作为索引来访问 train.classes 列表,从而获得与该标签对应的类别名称。这样,你就可以直接从数据集中获取类别名称,而无需手动遍历字典。这种方法更加简洁高效。
五、典型使用流程(完整代码示例)
示例 1:基础加载与可视化
python
import matplotlib.pyplot as plt
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
# 创建数据集
train_set = CIFAR10(root='./data', train=True, download=True, transform=ToTensor())
test_set = CIFAR10(root='./data', train=False, download=True, transform=ToTensor())
# 查看基本信息
print("训练集大小:", len(train_set)) # 50000
print("测试集大小:", len(test_set)) # 10000
print("类别:", train_set.classes)
print("类别索引映射:", train_set.class_to_idx)
# 获取第一张图像
img, label = train_set[0]
print("图像形状:", img.shape) # torch.Size([3, 32, 32])
print("标签:", label, "→", train_set.classes[label])
# 可视化(注意:ToTensor() 后是 [0,1],plt.imshow 需要 [0,1] 或 [0,255])
plt.imshow(img.permute(1, 2, 0)) # 转回 [H, W, C]
plt.title(train_set.classes[label])
plt.axis('off')
plt.show()示例 2:带数据增强的训练管道
python
from torchvision import transforms
from torch.utils.data import DataLoader
# 定义训练和测试变换(测试通常不用增强)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))
])
train_dataset = CIFAR10('./data', train=True, download=True, transform=train_transform)
test_dataset = CIFAR10('./data', train=False, download=True, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False, num_workers=4)
# 迭代训练
for images, labels in train_loader:
print(images.shape) # [128, 3, 32, 32]
print(labels.shape) # [128]
break六、常见问题与最佳实践
❓ 问题 1:为什么我设置了 download=True 还是报错?
- 原因:目录权限不足、网络不通、或已有损坏文件。
- 解决 :
- 手动下载 cifar-10-python.tar.gz
- 解压到
./data/cifar-10-batches-py/ - 确保目录结构正确
❓ 问题 2:.data 和 dataset[i][0] 有什么区别?(CIFAR 10 - 返回值中也有介绍)
| 项目 | .data[i] |
dataset[i][0] |
|---|---|---|
| 类型 | np.ndarray (uint8) |
torch.Tensor (float32) |
| 像素范围 | 0, 255 | 0.0, 1.0(若用 ToTensor) |
| 维度顺序 | H, W, C | C, H, W |
| 是否应用 transform | 否 | 是 |
✅ 建议:训练时始终使用
dataset[i],不要直接操作.data,除非做特殊分析。
❓ 问题 3:如何获取原始 PIL 图像?
python
# 不设置 transform,或设为 None
raw_dataset = CIFAR10('./data', train=True, download=True, transform=None)
pil_img, label = raw_dataset[0]
print(type(pil_img)) # <class 'PIL.Image.Image'>❓ 问题 4:能否只加载部分类别?
-
原生不支持 ,但可通过子集采样实现:
pythonfrom torch.utils.data import Subset # 只保留 'cat' (3) 和 'dog' (5) indices = [i for i, t in enumerate(train_set.targets) if t in [3, 5]] subset = Subset(train_set, indices)
七、高级用法:自定义 Dataset 类(继承 CIFAR10)
有时需要修改默认行为(如返回文件路径、添加额外元数据),可继承 CIFAR10:
python
class CustomCIFAR10(CIFAR10):
def __getitem__(self, index): # img, label = dataset[0] # 等价于 dataset.__getitem__(0)
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img) # 转为 PIL
if self.transform is not None:
img = self.transform(img)
# 返回额外信息
return img, target, index # 添加样本索引
dataset = CustomCIFAR10('./data', train=True, transform=ToTensor())
img, label, idx = dataset[100]八、性能优化建议
- 使用
DataLoader的num_workers > 0:加速数据加载(尤其在 SSD 上)。 - 避免在
transform中做耗时操作:如大尺寸 resize(CIFAR 已是 32x32)。 - 预加载到内存(谨慎) :对于小数据集,可一次性加载
.data到 GPU(但通常没必要)。 - 使用
pin_memory=True:当使用 GPU 时,加速 CPU→GPU 传输。
九、与其他框架对比
| 框架 | 加载方式 | 特点 |
|---|---|---|
| PyTorch | torchvision.datasets.CIFAR10 |
灵活 transform,与 DataLoader 无缝集成 |
| TensorFlow/Keras | tf.keras.datasets.cifar10.load_data() |
返回 NumPy 数组,无内置 transform |
| JAX / Flax | 通常用 TensorFlow Datasets (TFDS) | 需额外安装 tensorflow-datasets |
十、总结
CIFAR10 在 PyTorch 中的使用看似简单,但其背后涉及数据管理、变换流水线、内存布局、并行加载等多个层面。掌握其参数含义、数据结构差异和最佳实践,能帮助你:
- 快速搭建实验原型
- 避免常见陷阱(如维度错误、重复下载)
- 灵活扩展以适应研究需求
无论你是初学者还是进阶用户,深入理解 CIFAR10 的使用细节,都是构建可靠深度学习项目的基石。
📘 延伸阅读:
3、CIFAR10 - 返回值
CIFAR10 的构造函数签名为:
python
CIFAR10(root, train=True, transform=None, target_transform=None, download=False)✅ 一句话回答
CIFAR10(...)返回的是一个torchvision.datasets.CIFAR10类的实例(对象),它本身就是一个可索引、可迭代的"数据集对象"(Dataset),不是原始数据,也不是 DataLoader。
你可以把它理解为:一个"智能容器",知道:
- 数据存在哪
- 总共有多少张图
- 第 i 张图长什么样(经过 transform 处理后)
- 每张图对应的标签是什么
🔍 深入解析:这个对象到底包含什么?
当你运行:
python
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
dataset = CIFAR10(root='./data', train=True, transform=ToTensor(), download=True)dataset 是一个 CIFAR10 对象,它有以下关键组成部分:
- 原始数据(未处理)
.data:numpy.ndarray,形状(50000, 32, 32, 3),值是uint8(0~255).targets:list[int],长度 50000,每个元素是 0~9 的整数标签
📌 注意:
.data和.targets是加载时就全部读入内存的(CIFAR-10 小,所以没问题)。
pythonimport torch import torch.nn as nn from torchvision.datasets import CIFAR10 from torchvision import transforms dataset = CIFAR10(root='./data', download=False, train=True, transform=transforms.ToTensor()) print(type(dataset.data)) # ndarray print(dataset.data.shape) # (50000, 32, 32, 3) # print(dataset.data) print(type(dataset.targets)) # list print(len(dataset)) # 50000
- 元信息
.classes:['airplane', 'automobile', ..., 'truck'].class_to_idx:{'airplane': 0, 'automobile': 1, ..., 'truck': 9}
- 行为接口(最重要!)
len(dataset)→ 返回 50000(或 10000)dataset[i]→ 返回(transformed_image, label)
🧪 关键:dataset[i] 返回什么?就跟 TensorDataset 一样,可以迭代,每个元素返回两个值,一个是 img,一个是 label
这才是你真正"用到"的数据!
python
img, label = dataset[0]返回值取决于 transform 是否设置:
| 情况 | img 类型 |
img 形状 |
label 类型 |
|---|---|---|---|
transform=None |
PIL.Image.Image |
(32, 32)(PIL 图像) | int(如 3) |
transform=ToTensor() |
torch.Tensor |
[3, 32, 32] |
int |
transform=复杂组合 |
torch.Tensor(或其他) |
通常是 [3, 32, 32] |
int(或经 target_transform 处理后的类型) |
✅ 所以:
dataset[i]总是返回一个二元组(image, target),这是 PyTorchDataset的标准协议。
python
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision import transforms
import os
os.chdir(r'F:\Pycharm\works-space\卷积神经网络CNN')
train = CIFAR10(root='data', download=True, train=True, transform=transforms.ToTensor())
test = CIFAR10(root='data', download=True, train=False, transform=transforms.ToTensor())
print("数据集类别:", train.class_to_idx) # {'airplane': 0, 'automobile': 1, ...}
print("训练集数据集:", train.data.shape) # (50000, 32, 32, 3)
print("测试集数据集:", test.data.shape) # (10000, 32, 32, 3)
# train.data 就是看原始 NumPy 数据 (H、W、C)
# train.data[0] 就是看第0张图片的 Numpy 数据 (H、W、C)
print(train.data[0])
# [[[ 59 62 63]
# ...
# [148 124 103]]
# ...
# [[177 144 116]
# ...
# [123 92 72]]]
print(type(train[0])) # tuple
print(train[0]) # 一对元组: 第0张图的tensor(C、H、W)、 标签
# (tensor([[[0.2314, 0.1686, 0.1961, ..., 0.6196, 0.5961, 0.5804],
# [0.0627, 0.0000, 0.0706, ..., 0.4824, 0.4667, 0.4784],
# [0.0980, 0.0627, 0.1922, ..., 0.4627, 0.4706, 0.4275],
# ...,
# [0.8157, 0.7882, 0.7765, ..., 0.6275, 0.2196, 0.2078],
# [0.7059, 0.6784, 0.7294, ..., 0.7216, 0.3804, 0.3255],
# [0.6941, 0.6588, 0.7020, ..., 0.8471, 0.5922, 0.4824]],
#
# [[0.2431, 0.1804, 0.1882, ..., 0.5176, 0.4902, 0.4863],
# [0.0784, 0.0000, 0.0314, ..., 0.3451, 0.3255, 0.3412],
# [0.0941, 0.0275, 0.1059, ..., 0.3294, 0.3294, 0.2863],
# ...,
# [0.6667, 0.6000, 0.6314, ..., 0.5216, 0.1216, 0.1333],
# [0.5451, 0.4824, 0.5647, ..., 0.5804, 0.2431, 0.2078],
# [0.5647, 0.5059, 0.5569, ..., 0.7216, 0.4627, 0.3608]],
#
# [[0.2471, 0.1765, 0.1686, ..., 0.4235, 0.4000, 0.4039],
# [0.0784, 0.0000, 0.0000, ..., 0.2157, 0.1961, 0.2235],
# [0.0824, 0.0000, 0.0314, ..., 0.1961, 0.1961, 0.1647],
# ...,
# [0.3765, 0.1333, 0.1020, ..., 0.2745, 0.0275, 0.0784],
# [0.3765, 0.1647, 0.1176, ..., 0.3686, 0.1333, 0.1333],
# [0.4549, 0.3686, 0.3412, ..., 0.5490, 0.3294, 0.2824]]]), 6)这段代码中:
train和test都是CIFAR10对象- 你打印
.data.shape是在看原始 NumPy 数据 - 但如果你写
img, label = train[1],得到的是Tensor+int
⚠️ 注意:
train.data在看原始 NumPy 数据 ,train.data[1]是第 1 张图片对应的 numpy所以:
plt.imshow(train.data[1])能显示,是因为.data[1]是(32,32,3)的 NumPy 数组,matplotlib能直接画。
train[1]返回的是img、label,所以train[1][0]返回的是[3,32,32]的 Tensor,直接用于plt.imshow就不行
🔄 完整使用流程(标准做法)
python
# 1. 创建 Dataset 对象
train_dataset = CIFAR10(root='./data', train=True, transform=ToTensor(), download=True)
# 2. (可选)查看基本信息
print(len(train_dataset)) # 50000
print(train_dataset.classes) # ['airplane', ...]
# 3. 单个样本访问
image, label = train_dataset[123]
print(type(image)) # <class 'torch.Tensor'>
print(image.shape) # torch.Size([3, 32, 32])
print(label) # 例如 7(对应 'horse')
# 4. 通常会包进 DataLoader 用于批量训练
from torch.utils.data import DataLoader
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 5. 批量迭代
for batch_images, batch_labels in train_loader:
print(batch_images.shape) # [64, 3, 32, 32]
print(batch_labels.shape) # [64]
break📌 总结:CIFAR10(...) 返回什么?
| 项目 | 说明 |
|---|---|
| 返回类型 | torchvision.datasets.cifar.CIFAR10 实例(继承自 torch.utils.data.Dataset) |
| 本质 | 一个符合 PyTorch Dataset 接口的对象 |
| 核心方法 | __len__() 和 __getitem__(index) |
| 单样本格式 | (image, label),其中 image 经过 transform 处理,label 是整数(或经 target_transform 处理) |
| 不是什么 | ❌ 不是 NumPy 数组 ❌ 不是 Tensor 列表 ❌ 不是 DataLoader |
💡 小贴士:如何验证?
你可以自己试试:
python
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
ds = CIFAR10('./data', train=True, transform=ToTensor())
# 看类型
print(type(ds)) # <class 'torchvision.datasets.cifar.CIFAR10'>
# 看是否可索引
img, lbl = ds[0]
print(type(img), type(lbl)) # <class 'torch.Tensor'> <class 'int'>
# 看是否可 len
print(len(ds)) # 500004、代码:
python
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision import transforms
from torchsummary import summary
from torch.utils.data import DataLoader
import torch.optim as optim
import time
import matplotlib.pyplot as plt
import os
os.chdir(r'F:\Pycharm\works-space\卷积神经网络CNN')
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # ←←← 关键!放在最前面(解决报错)
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False # 设置正常显示符号
torch.manual_seed(66)
def create_data():
# `transform=transforms.ToTensor` 实际上传递的是一个类而非一个实例化对象。需要确保传递给 `transform` 参数的是 `ToTensor` 类的一个实例,而不是类本身
train = CIFAR10(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test = CIFAR10(root='./data', train=False, transform=transforms.ToTensor(), download=True)
print(type(train.class_to_idx)) # dict
print(f'类别对应关系: {train.class_to_idx}')
# {'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
print(f'训练集形状 = {train.data.shape}') # (50000, 32, 32, 3)
print(f'测试集形状 = {test.data.shape}') # (10000, 32, 32, 3)
# 把训练集中的 第1张 图片画出来
plt.style.use('fivethirtyeight')
plt.imshow(X=train.data[1]) # train.data 是查看原始图片的Numpy(H、W、C)
plt.show()
# 第1张 图片对应的类型是
img, label = train[1] # img 是 tensor (C、H、W)
print(type(label)) # int
print(label) # 9
# `train.classes` 属性。这个属性返回一个列表,其中的索引对应于类别的整数标签,而值则是类别的名称字符串
print(f'第1张 图片对应的类型是: {train.classes[label]}') # truck
return train, test
if __name__ == '__main__':
train, test = create_data()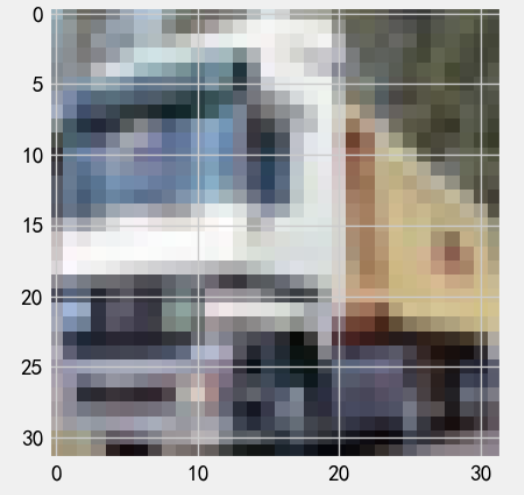
二、搭建图像分类网络
搭建的CNN网络结构如下:
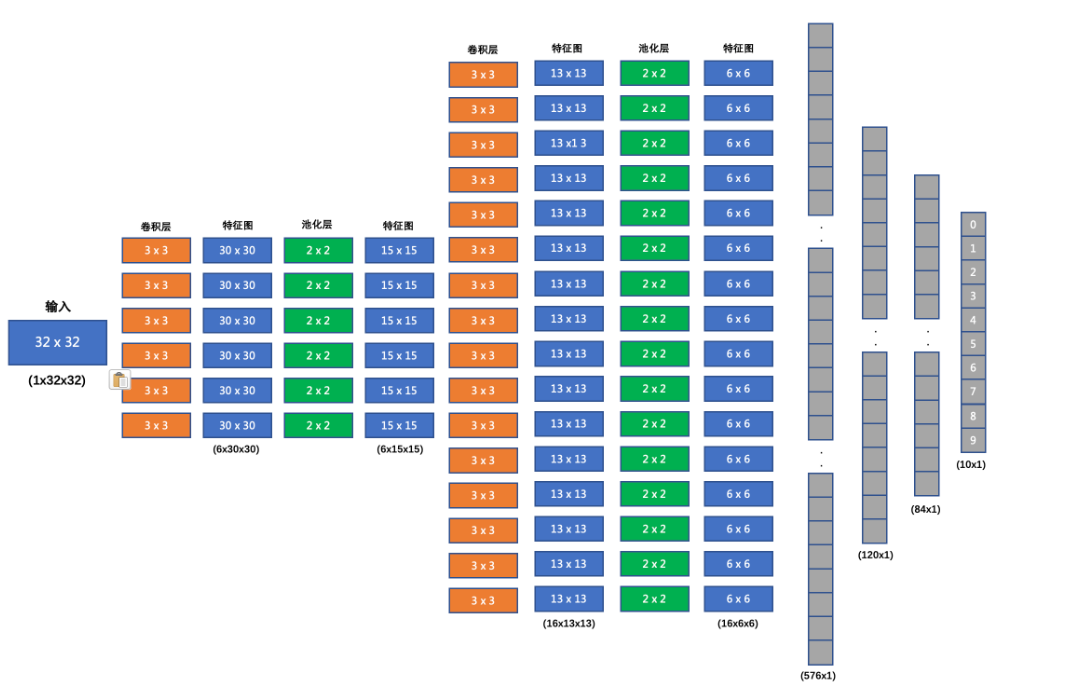
1、计算隐藏层1的输入特征个数
经过卷积层和池化层,需要计算隐藏层1的输入特征个数,手动计算容易出错
以下这种方法仅代表个人观点,提倡:如果得到的隐藏层1的输入特征个数,就可以把with torch.no_grad()这堆代码注释或删除
在__init__中给一个假数据,再 reshape 计算得到隐藏层1的输入特征个数
python
class My_ImageModle(nn.Module):
def __init__(self):
super().__init__()
# 第1层 卷积层: 输入通道3, 输出通道6
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=(3, 3), stride=1, padding=0)
# 第1层: 卷积层得到的特征图需要经过激活函数
self.relu1 = nn.ReLU()
# 第1层 池化层: 池化窗口大小为 2x2
self.pool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0)
# 第2层 卷积层: 输入通道6, 输出通道16
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(3, 3), stride=1, padding=0)
# 第2层: 卷积层得到的特征图需要经过激活函数
self.relu2 = nn.ReLU()
# 第2层 池化层: 池化窗口大小为 2x2
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0)
# 卷积层和池化层一顿操作后, 理论上可以直接手算出来 隐藏层1 的输入特征个数, 但是我不想算, 而且还容易算不对
# 计算隐藏层1的输入特征个数
# 模拟一张图。 因为训练集、测试集的图片都是 3通道, 32x32, 故这里必须是 3通道, 32x32
# 目前先到这里, 就 32x32, 只是想得到隐藏层1的输入特征个数, 后续会有更好的方法得到特征个数
temp_x = torch.randn(size=(1, 3, 32, 32)) # 这里的 3 32x32 需要优化
with torch.no_grad():
# 模拟前向传播计算一遍, 目的在于得到 隐藏层1的输入特征个数
temp_x = self.conv1(temp_x)
temp_x = self.relu1(temp_x)
temp_x = self.pool1(temp_x)
temp_x = self.conv2(temp_x)
temp_x = self.relu2(temp_x)
temp_x = self.pool2(temp_x)
print(f'temp_x.shape = {temp_x.shape}') # torch.Size([1, 16, 6, 6])
temp_x = temp_x.reshape(1, -1)
print(f'temp_x.shape = {temp_x.shape}') # torch.Size([1, 576]), 576 就是隐藏层1的输入特征个数
# 隐藏层1: 输入特征个数 = temp_x.shape[1], 输出 120
self.linear1 = nn.Linear(in_features=temp_x.shape[1], out_features=120)
# 隐藏层1: 批量归一化
# self.bn1 = nn.BatchNorm1d(num_features=temp_x.shape[1]) 错误!
self.bn1 = nn.BatchNorm1d(num_features=120) # 是把 linear1 的结果进行归一化, 不是把 linea1 的输入归一化
# 激活函数1
self.linear1_relu1 = nn.ReLU()
....
def forward(self, x):
...2、time.perf_counter() 精确测量代码执行耗时
time.perf_counter() 返回的是一个 浮点数(float) ,表示 从某个未指定的起点(reference point)到当前时刻所经过的时间 ,单位是 秒(seconds)。
✅ 作用
高精度性能计时器 ,用于精确测量代码执行耗时。
🔧 基本用法
python
import time
start_time = time.perf_counter()
# ... 被测代码 ...
end_time = time.perf_counter()
elapsed = end - start
print(f"耗时: {elapsed:.6f} 秒")✅ 核心要点总结:
| 项目 | 说明 |
|---|---|
| 返回类型 | float(浮点数) |
| 单位 | 秒(seconds) |
| 精度 | 尽可能高(通常为微秒 µs 或纳秒 ns 级别,取决于操作系统) |
| 起点(reference point) | 未定义、不重要 ------ 它不是一个日历时间(如 2025-12-03),只是一个单调递增的计时起点 |
| 是否可读 | ❌ 不能转换成"年月日时分秒";只用于计算时间间隔 |
| 是否受系统时间影响 | ❌ 不受影响(即使你手动修改系统时间,它依然稳定递增) |
📌 正确用法:必须成对使用,计算差值
python
import time
start = time.perf_counter() # 比如返回 1234567.890123
# ... 执行一些操作 ...
end = time.perf_counter() # 比如返回 1234568.123456
elapsed = end - start # → 0.233333 秒(这才是你关心的耗时!)⚠️ 单独看
start或end的值没有实际意义,只有它们的差值才有意义。
🔍 举个实际例子:
python
import time
t0 = time.perf_counter()
print(f"t0 = {t0}") # 输出:t0 = 1733238.456789 (这个数字本身无意义)
time.sleep(0.5)
t1 = time.perf_counter()
print(f"t1 = {t1}") # 输出:t1 = 1733238.957123
print(f"耗时 = {t1 - t0:.6f} 秒") # 输出:耗时 = 0.500334 秒 ✅❓常见误解澄清:
- 不是 Unix 时间戳 (
time.time()才是); - 不能用来获取"现在几点";
- 数值大小不代表"真实时间",只代表"程序运行了多久"的相对值;
- 在不同 Python 进程中,
perf_counter()的起点不同,不能跨进程比较绝对值。
✅ 适用场景:
- 测量函数/代码块执行时间;
- 性能分析(benchmarking);
- 超时控制(配合
while time.perf_counter() - start < timeout)。
📚 官方文档摘要(Python docs):
"Return the value (in fractional seconds) of a performance counter, i.e. a clock with the highest available resolution to measure a short duration. It does include time elapsed during sleep and is system-wide. The reference point of the returned value is undefined, so that only the difference between the results of consecutive calls is valid."
翻译:
"返回一个性能计数器的值(单位:秒,含小数)。该计数器具有系统可用的最高分辨率,适用于测量短时间段。其参考起点未定义,因此只有连续调用结果之间的差值才有意义。"
✅ 一句话记住:
time.perf_counter()返回以秒为单位的高精度时间戳(仅用于做减法) ,单独看没意义,相减才得耗时。
⭐ 核心特点
| 特性 | 说明 |
|---|---|
| 高精度 | 提供系统支持的最高可用分辨率(通常纳秒级) |
| 单调递增 | 不受系统时间调整(如 NTP 同步、手动修改时间)影响 |
| 仅用于间隔测量 | 返回值无具体"日历时间"意义,不能转换为可读日期 |
| 跨平台一致 | 在 Windows、Linux、macOS 上行为统一 |
🆚 vs time.time()
| 对比项 | time.perf_counter() |
time.time() |
|---|---|---|
| 主要用途 | 测量耗时 | 获取当前时间戳 |
| 是否受系统时间影响 | ❌ 否(单调) | ✅ 是 |
| 精度 | 更高(专为性能设计) | 取决于系统 |
| 可读性 | 无(只是一个浮点数) | 可转为日期(如 2025-12-03) |
📌 官方建议
"Use
perf_counter()for measuring elapsed time between two calls."------ Python 官方文档
💡 适用场景
- 性能测试 / 基准测试(benchmarking)
- 优化算法耗时对比
- 监控关键代码段执行效率
❗ 注意:不要用它来获取"现在是几点",只用来算"过了多久"。
3、代码:
python
class My_ImageModel(nn.Module):
def __init__(self):
super().__init__()
# 第1层 卷积层: 输入通道3, 输出通道6
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=(3, 3), stride=1, padding=0)
# 第1层: 卷积层得到的特征图需要经过激活函数
self.relu1 = nn.ReLU()
# 第1层 池化层: 池化窗口大小为 2x2
self.pool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0)
# 第2层 卷积层: 输入通道6, 输出通道16
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(3, 3), stride=1, padding=0)
# 第2层: 卷积层得到的特征图需要经过激活函数
self.relu2 = nn.ReLU()
# 第2层 池化层: 池化窗口大小为 2x2
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0)
# 卷积层和池化层一顿操作后, 理论上可以直接手算出来 隐藏层1 的输入特征个数, 但是我不想算, 而且还容易算不对
# 计算隐藏层1的输入特征个数
# 模拟一张图。 因为训练集、测试集的图片都是 3通道, 32x32, 故这里必须是 3通道, 32x32
# 目前先到这里, 就 32x32, 只是想得到隐藏层1的输入特征个数, 后续会有更好的方法得到特征个数
temp_x = torch.randn(size=(1, 3, 32, 32)) # 这里的 3 32x32 需要优化
with torch.no_grad():
# 模拟前向传播计算一遍, 目的在于得到 隐藏层1的输入特征个数
temp_x = self.conv1(temp_x)
temp_x = self.relu1(temp_x)
temp_x = self.pool1(temp_x)
temp_x = self.conv2(temp_x)
temp_x = self.relu2(temp_x)
temp_x = self.pool2(temp_x)
print(f'temp_x.shape = {temp_x.shape}') # torch.Size([1, 16, 6, 6])
temp_x = temp_x.reshape(1, -1)
print(f'temp_x.shape = {temp_x.shape}') # torch.Size([1, 576]), 576 就是隐藏层1的输入特征个数
# 隐藏层1: 输入特征个数 = temp_x.shape[1], 输出 120
self.linear1 = nn.Linear(in_features=temp_x.shape[1], out_features=120)
# 隐藏层1: 批量归一化
# self.bn1 = nn.BatchNorm1d(num_features=temp_x.shape[1]) 错误!
self.bn1 = nn.BatchNorm1d(num_features=120) # 是把 linear1 的结果进行归一化, 不是把 linea1 的输入归一化
# 激活函数1
self.linear1_relu1 = nn.ReLU()
# 隐藏层1: dropout p: 每个神经元在每次前向传播时,有 30% 的概率被"丢弃"(即置为 0)
self.dropout1 = nn.Dropout(p=0.3)
# 隐藏层2: 输入120, 输出 84
self.linear2 = nn.Linear(in_features=120, out_features=84)
# 隐藏层2: 批量归一化
# self.bn2 = nn.BatchNorm1d(num_features=120) 错误!
self.bn2 = nn.BatchNorm1d(num_features=84) # 是把 linear2 的结果进行归一化, 不是把 linea2 的输入归一化
# 激活函数2
self.linear2_relu2 = nn.ReLU()
# 隐藏层2: dropout p: 每个神经元在每次前向传播时,有 30% 的概率被"丢弃"(即置为 0)
self.dropout2 = nn.Dropout(p=0.3)
# 输出层: 10分类, 所以共10个输入, 这里不需要用 softmax
self.out = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
# 卷积层1 + 激活函数1 + 池化层1
x = self.conv1(x)
x = self.relu1(x) # 卷积层得到的特征图通常需要经过激活函数
x = self.pool1(x)
# 卷积层2 + 激活函数2 + 池化层2
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x) # 卷积层得到的特征图通常需要经过激活函数
# 把 卷积层 + 池化层 得到的 [batch_size, C, H, W] 转成 二维
# 不能写成 x.reshape(8, -1) 因为最后一批可能没有 8 个样本, 所以不能写死8
x = x.reshape(x.shape[0], -1)
# 隐藏层1 + 批量归一化 + 激活函数1 + dropout
x = self.linear1(x)
x = self.bn1(x) # 如果batch_size=1,这里会报错, 在笔记《关于 batch size 的要求》
x = self.linear1_relu1(x)
x = self.dropout1(x)
# 隐藏层2 + 批量归一化 + 激活函数2 + dropout
x = self.linear2(x)
x = self.bn2(x) # 如果batch_size=1,这里会报错, 在笔记《关于 batch size 的要求》
x = self.linear2_relu2(x)
x = self.dropout2(x)
# 输出层: 10分类, 所以共10个输入, 这里不需要用 softmax
output = self.out(x)
return output
def show_model(my_model):
# input_size: 单个样本的输入形状(不含 batch 维度)
summary(my_model, input_size=(3, 32, 32))
# ----------------------------------------------------------------
# Layer (type) Output Shape Param #
# ================================================================
# Conv2d-1 [-1, 6, 30, 30] 168
# ReLU-2 [-1, 6, 30, 30] 0
# MaxPool2d-3 [-1, 6, 15, 15] 0
# Conv2d-4 [-1, 16, 13, 13] 880
# ReLU-5 [-1, 16, 13, 13] 0
# MaxPool2d-6 [-1, 16, 6, 6] 0
# Linear-7 [-1, 120] 69,240 计算: 120 x 576 + 120 = 69,240
# BatchNorm1d-8 [-1, 120] 240
# ReLU-9 [-1, 120] 0
# Dropout-10 [-1, 120] 0
# Linear-11 [-1, 84] 10,164
# BatchNorm1d-12 [-1, 84] 168
# ReLU-13 [-1, 84] 0
# Dropout-14 [-1, 84] 0
# Linear-15 [-1, 10] 850
# ================================================================
# Total params: 81,710
# Trainable params: 81,710
# Non-trainable params: 0
# ----------------------------------------------------------------
# Input size (MB): 0.01
# Forward/backward pass size (MB): 0.14
# Params size (MB): 0.31
# Estimated Total Size (MB): 0.47
# ----------------------------------------------------------------
if __name__ == '__main__':
train, test = create_data()
# 查看创建的模型
# my_model = My_ImageModle()
# show_model(my_model)三、编写训练函数
1、GPU 计算优势
核心优势对比
| 维度 | CPU | GPU | GPU优势倍数 |
|---|---|---|---|
| 核心数量 | 4-64个强核心 | 512-16384个弱核心 | 10-1000倍 |
| 并行能力 | 擅长串行、复杂逻辑 | 擅长大规模并行简单计算 | 极高 |
| 内存带宽 | 25-100 GB/s | 400-1000 GB/s | 4-40倍 |
| 计算精度 | 高精度通用计算 | 中精度专用计算 | - |
| 功耗效率 | 较低 (1-2 TFLOPS/W) | 较高 (5-20 TFLOPS/W) | 5-10倍 |
以下是 GPU 相对于 CPU 计算在深度学习中的简单且全面的优势总结:
✅ 1. 并行计算能力极强
- CPU :核心少(通常 4~32 核),擅长串行、复杂逻辑任务。
- GPU :数千个轻量级核心(如 RTX 3060 有 3584 个 CUDA 核心),专为大规模并行计算设计。
- 优势体现 :矩阵乘法、卷积等操作可同时处理成千上万个元素,速度提升数倍至数百倍。
✅ 2. 高吞吐量(Throughput)
- GPU 每秒可执行 万亿次浮点运算(TFLOPS) ,远超 CPU。
- 例:RTX 3060 ≈ 13 TFLOPS(FP32),而 i7 CPU ≈ 0.5 TFLOPS。
- 适合训练大模型、大数据集(如 ImageNet、BERT)。
✅ 3. 专为张量运算优化
- 现代 GPU 支持:
- Tensor Cores(加速混合精度训练)
- cuDNN / cuBLAS(高度优化的深度学习算子库)
- PyTorch/TensorFlow 自动调用这些库,无需手动优化即可获得高性能。
✅ 4. 显存带宽高
- GPU 显存带宽(如 RTX 3060:360 GB/s)远高于 CPU 内存带宽(~50 GB/s)。
- 减少数据搬运瓶颈,让计算单元"不饿"。
✅ 5. 支持混合精度训练(AMP)
- 利用 FP16(半精度)减少显存占用、加快计算,同时保持精度。
- 训练速度再提升 1.5~2 倍(高端 GPU 更明显)。
⚠️ 但要注意:GPU 并非万能!
| 场景 | GPU 优势 | 说明 |
|---|---|---|
| 小模型 + 小 batch | ❌ 微弱甚至更慢 | 启动开销 > 计算收益 |
| 数据加载慢 | ❌ 利用率低 | 需配合 num_workers 和 pin_memory |
| 调试/原型开发 | ⚠️ 可用 CPU | 快速验证逻辑,避免设备切换 |
✅ 总结一句话:
GPU 的核心优势是:用海量并行计算单元,高效处理深度学习中大量重复的张量运算,从而在大模型、大数据场景下实现远超 CPU 的训练速度。
但在实际使用中,需合理设置 batch size、优化数据加载、监控 GPU 利用率,才能真正发挥其威力。
2、安装 PyTorch 的 GPU版
查看电脑是否支持 GPU
python
if torch.cuda.is_available():
print('True')
else:
print('False')
# 输出 True 则支持
# 输出 False 则不支持,后续的安装操作可直接跳过使用一下代码可以查看当前的 PyTorch 是 CPU版 还是 GPU 版本
python
import torch
print("PyTorch 版本:", torch.__version__)
print("CUDA 可用:", torch.cuda.is_available())
print("编译时支持的 CUDA 版本:", torch.version.cuda)如果输出下面这种,则说明 PyTorch 是 GPU版(通常使用 pip 默认下载的 PyTorch 是 CPU 版本)
python
PyTorch 版本: 2.7.1+cu118
CUDA 可用: True
编译时支持的 CUDA 版本: 11.8卸载 PyTorch
python
pip uninstall torch torchvision torchaudio -y安装 PyTorch 的 GPU 版
python
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 这是直接从官网个下载,所以网速会比较慢。
# 但是,这是最简单的方法,只要等安装好就行了,如果用其它方式,可不是一条指令这么简单常见的误解,我们来澄清一下:
✅ 正确理解:PyTorch 的"默认设备"始终是 CPU ,无论你安装的是 CPU 版本 还是 GPU 版本!
也就是说:
| 安装的版本 | 默认计算设备 | 说明 |
|---|---|---|
torch(CPU 版) |
CPU | 只能用 CPU |
torch+cu118(GPU 版) |
仍然是 CPU | 除非你显式要求使用 GPU |
🔍 举个例子
python
import torch
# 无论你装的是 CPU 版还是 GPU 版,下面这行都会创建一个在 CPU 上的张量!
x = torch.tensor([1, 2, 3])
print(x.device) # 输出:cpu即使你安装了 GPU 版本的 PyTorch,并且你的电脑有 NVIDIA 显卡 + 驱动 + CUDA,PyTorch 也不会自动把张量或模型放到 GPU 上。
🚀 那什么时候会用 GPU?
只有当你显式指定时,才会用 GPU:
python
# 方法 1:创建时指定
x = torch.tensor([1, 2, 3], device='cuda')
# 方法 2:移动到 GPU
x = x.cuda() # 等价于 x.to('cuda')
# 或
x = x.to(torch.device('cuda'))
# 模型同理
model = MyModel().to('cuda')或者使用常见的设备选择逻辑:
python
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 重点
x = torch.tensor([1, 2, 3]).to(device)⚠️ 注意:
torch.cuda.is_available()在 GPU 版本上返回True(如果驱动和 CUDA 正常),在 CPU 版本上永远返回False。
📌 总结
- ✅ 默认行为 :所有张量和模型默认都在 CPU 上,不管安装哪个版本。
- ✅ GPU 版 = CPU 功能 + 额外的 CUDA 支持,不是"默认跑 GPU"。
- ✅ 是否使用 GPU 完全由你的代码控制,PyTorch 不会自动切换。
所以你可以放心:
- 安装 GPU 版 → 想用 GPU 就
.to('cuda'),不想用就当 CPU 版用。 - 安装 CPU 版 → 只能用 CPU,无法调用
.cuda()(会报错)。
💡 小技巧:检查当前张量在哪
python
print(x.device) # 输出:cpu 或 cuda:0这样你就永远不会搞混啦!
3、代码:
python
def model_train(train):
# 数据加载器: batch_size 通常设置为 2 的幂次方(如 32、64、128、256、512 等),但这 不是硬性规定,而是一种经验性最佳实践。
# 实验表明:只要 batch size 不太小(≥16),是否为 2 的幂对最终精度几乎没有影响,主要影响的是训练速度的微小差异(通常 <5%)
data_loader = DataLoader(dataset=train, batch_size=128, shuffle=True)
# 检查 GPU, 如果有 GPU 就用 GPU(计算更快), 否则还是用 CPU
# 模型越大、batch size 越大、计算越密集 → GPU 优势越明显。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'当前模式: {device}') # cuda
# 创建模型 并 移到 GPU
my_model = My_ImageModel().to(device=device)
my_model.train() # 切记! 切换成训练模式
# 创建优化器
optimizer = optim.Adam(params=my_model.parameters(), lr=0.001, betas=(0.9, 0.999))
#损失函数
criterion = nn.CrossEntropyLoss() # 默认是平均损失
epochs = 10 # 电脑硬件不行, 计算太慢了, 所以少训练几次
loss_mean_list = []
right_rate_list = []
for epoch in range(epochs):
loss_sum = 0 # 当前 epoch 的总损失
right_cnt = 0 # 当前 epoch 样本预测正确的个数
simple_cnt = 0 # 当前 epoch 样本个数
start_time = time.perf_counter()
for x_img, y_label in data_loader:
# ★★★ 关键:把数据也移到 device 上 ★★★
# 模型越大、batch size 越大、计算越密集 → GPU 优势越明显。
x_img = x_img.to(device)
y_label = y_label.to(device)
optimizer.zero_grad() # 1. 梯度清零
current_len = len(y_label) # 当前 batch 样本数量, 模型中有 批量归一化, 所以样本数量至少为 2 条
if current_len <= 1:
continue
y = my_model(x_img) # 2. 前向传播
loss = criterion(y, y_label) # 3. 计算损失值 (默认是平均损失)
loss.backward() # 4. 反向传播
optimizer.step() # 5. 梯度更新
loss_sum += loss.item() # 当前 batch 损失
# 统计当前 batch 正确率(能与后续模型测试形成对比, 是欠拟合? 还是过拟合? 还是刚好?)
y_predict = torch.softmax(y, dim=1).argmax(dim=1) # 预测为哪个类别. 比如: tensor([3, 8, 8, 0, 6, 6, 1, ...])
right_cnt += (y_predict == y_label).sum().item() # 统计当前 batch 样本预测正确的个数
simple_cnt += len(y_label) # 当前 batch 总样本个数
end_time = time.perf_counter()
print(f'第 {epoch + 1} 个epoch耗时: {end_time - start_time: .6f}s')
# GPU: 6.140568s、7.849436s、8.378597s、8.414186s、8.115676s、...
right_rate = right_cnt / simple_cnt # 当前 epoch 样本预测正确率
right_rate_list.append(right_rate)
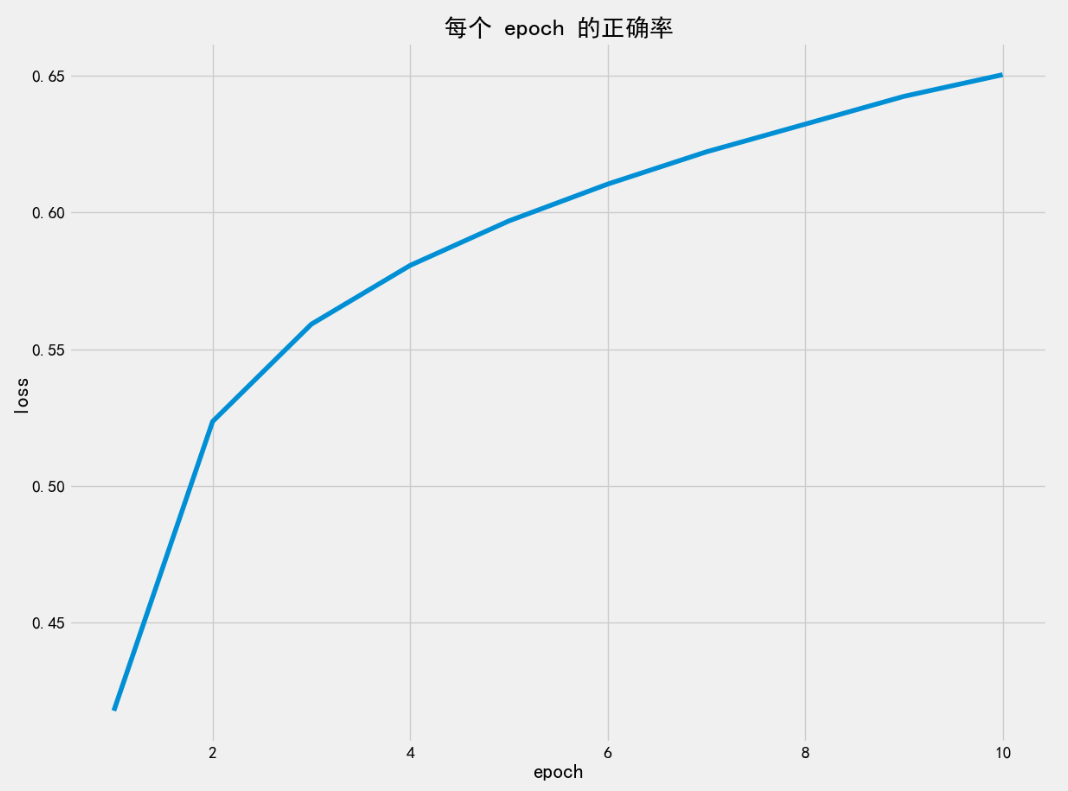
print(f'当前 epoch 预测正确的概率 = {right_rate}')
# 0.41676、0.52106、0.55552、0.57942、0.5945、0.60696、0.61684、0.6298、0.63882、0.64736
loss_mean_list.append(loss_sum)
print(loss_mean_list)
# [632.8302, 523.2404, 489.4019, ..., 391.1543](截断前4位小数, 注意, 不是四舍五入)
plt.style.use('fivethirtyeight')
plt.figure(figsize=(13, 10))
plt.plot(range(1, epochs + 1), loss_mean_list)
plt.title('每个 epoch 的损失值')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
plt.style.use('fivethirtyeight')
plt.figure(figsize=(13, 10))
plt.plot(range(1, epochs + 1), right_rate_list)
plt.title('每个 epoch 的正确率')
plt.xlabel('epoch')
plt.ylabel('正确率')
plt.show()
# 保存模型参数, 用的时候直接加载放到模型上就行了
# model_params = my_model.state_dict() # GPU模式下, 这样保存的模型只能在有 GPU 的环境加载,否则会报错!
model_params = my_model.cpu().state_dict() # 当前模式是 GPU, 先转到 CPU 上再保存参数(更安全)
torch.save(obj=model_params, f=r'model/ImageModel.pth')
if __name__ == '__main__':
train, test = create_data()
# 查看创建的模型
# my_model = My_ImageModle()
# show_model(my_model)
model_train(train)
# import torch
#
# print("PyTorch 版本:", torch.__version__)
# print("CUDA 可用:", torch.cuda.is_available())
# print("编译时支持的 CUDA 版本:", torch.version.cuda)
# if torch.cuda.is_available():
# print('True')
# else:
# print('False')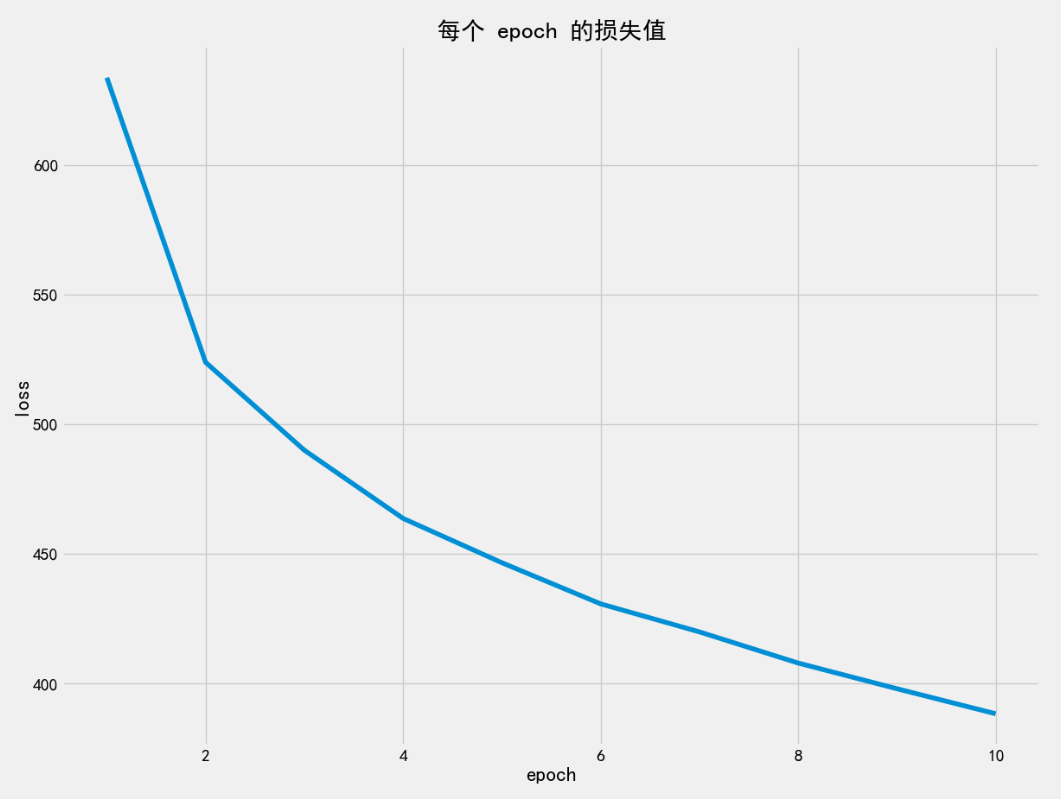
4、汇总:哪些东西需要转到GPU计算
在使用 GPU(CUDA)进行 PyTorch 模型训练或推理时,必须将所有参与计算的张量(Tensor)和模型(Module)都显式移动到同一个设备(device)上 ,否则会报错(如 Expected all tensors to be on same device)或默认在 CPU 上运行(失去 GPU 加速优势)。
✅ 你需要放到 GPU 上的 全部内容汇总如下:
| 类别 | 是否需要 .to(device) |
说明 |
|---|---|---|
| 1. 模型(Model) | ✅ 必须 | model.to(device) • 包括所有子模块、参数(parameters)、缓冲区(buffers) |
| 2. 输入数据(Input Tensors) | ✅ 必须 | 如 x_img = x_img.to(device) • 包括图像、文本 ID、特征等 |
| 3. 标签/目标(Target Tensors) | ✅ 必须 | 如 y_label = y_label.to(device) • 即使是整数标签(long 类型)也要移动 |
| 4. 损失函数(Loss Function) | ❌ 不需要 | nn.CrossEntropyLoss() 等损失函数是无状态的 ,自动适配输入设备 • 只要 input 和 target 在 GPU,loss 就在 GPU 计算 |
| 5. 优化器(Optimizer) | ❌ 不需要 | 优化器通过 model.parameters() 获取参数,只要模型已在 GPU,优化器操作的就是 GPU 参数 • 无需 optimizer.to(device) |
| 6. 中间计算结果(如 logits、预测值) | ⚠️ 自动在 GPU | 只要输入和模型在 GPU,前向传播输出自动在 GPU • 但若需在 CPU 上做后处理(如打印、绘图),需 .cpu() |
| 7. 手动创建的张量(如掩码、常量) | ✅ 需要(如果参与 GPU 计算) | 例如:mask = torch.ones(10).to(device) • 否则会因设备不一致报错 |
🔍 结合代码逐项检查
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
my_model = My_ImageModel().to(device) # ✅ 模型 → GPU
# ...
for x_img, y_label in data_loader:
x_img = x_img.to(device) # ✅ 输入数据 → GPU
y_label = y_label.to(device) # ✅ 标签 → GPU
y = my_model(x_img) # 输出 y 自动在 GPU
loss = criterion(y, y_label) # ✅ 损失函数无需移动,自动用 GPU 计算
# ...
y_predict = torch.softmax(y, dim=1).argmax(dim=1) # y 在 GPU → y_predict 也在 GPU
# (y_predict == y_label) 在 GPU 上比较,结果也在 GPU
right_cnt += (y_predict == y_label).sum().item() # .item() 自动同步到 CPU✅ 代码已经正确地将所有必要部分移到了 GPU!
⚠️ 常见遗漏点(新手易错)
-
验证/测试阶段忘记移数据
python# 错误:测试时没移数据 for x, y in test_loader: pred = model(x) # x 在 CPU,model 在 GPU → 报错! -
手动创建的张量没指定设备
python# 错误 zeros = torch.zeros(10) output = model(input) + zeros # 如果 input 在 GPU,zeros 在 CPU → 报错 # 正确 zeros = torch.zeros(10, device=device) -
保存模型时未考虑设备兼容性
python# 你做得很好: model_params = my_model.cpu().state_dict() # 先转 CPU 再保存,通用性强 torch.save(model_params, 'model.pth')
✅ 最佳实践建议
-
统一用
device变量管理设备:pythondevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu') -
数据加载后立即
.to(device)(如你所做的) -
保存模型前转回 CPU(提高可移植性)
-
推理时也记得把输入移到 device
📌 一句话总结
"模型 + 所有输入张量" 必须在同一个设备上;损失函数和优化器不需要手动移动。
四、编写预测函数
1、nn.Softmax 和 torch.softmax
nn.Softmax 和 torch.softmax 在功能上完全等价 ,都能对张量沿指定维度做 Softmax 归一化,但它们在使用方式、设计目的和适用场景上有重要区别。
🧠 一、根本定位:面向对象 vs 函数式
✅ nn.Softmax
- 类型 :
torch.nn.Module的子类(具体是torch.nn.modules.activation.Softmax)。 - 设计理念 :遵循 PyTorch 的 模块化神经网络构建范式,用于将操作封装为可复用、可注册、可序列化的"层"。
- 本质 :是一个无状态、无参数的可调用模块对象。
✅ torch.softmax
- 类型 :位于
torch._C._VariableFunctions中的 C++/ATen 后端绑定函数,暴露在 Python 层作为顶层函数。 - 设计理念 :属于 PyTorch Functional API(函数式接口) ,强调无副作用、即时计算、灵活组合。
- 本质 :是一个纯函数(pure function),输入张量 → 输出张量,不持有任何状态。
🔑 核心差异:
nn.Softmax是"对象"(有身份、可被模型管理);torch.softmax是"动作"(即用即走,无身份)。
⚙️ 二、内部实现机制(源码级)
▶ nn.Softmax 源码简化版(来自 PyTorch GitHub)
python
class Softmax(Module):
__constants__ = ['dim']
dim: Optional[int]
def __init__(self, dim: Optional[int] = None) -> None:
super().__init__()
self.dim = dim
def forward(self, input: Tensor) -> Tensor:
return F.softmax(input, self.dim, _stacklevel=5)- 它内部直接调用
torch.nn.functional.softmax(即F.softmax)。 - 而
F.softmax最终调用的就是torch.softmax(或其底层 C++ 实现)。
▶ torch.softmax 源码路径
- Python 层:
torch.softmax = _softmax(由 C++ 导出) - C++ 层:
at::softmax→ 调用 CUDA/CPU 内核
✅ 结论 :
两者最终调用的是同一套底层计算逻辑 ,数值结果、精度、速度完全一致。性能无任何差别。
📦 三、使用方式对比
| 场景 | nn.Softmax |
torch.softmax |
|---|---|---|
| 实例化 | s = nn.Softmax(dim=1) |
无需实例化 |
| 调用 | y = s(x) |
y = torch.softmax(x, dim=1) |
| 作为模型组件 | ✅ 可放入 nn.Sequential: model = nn.Sequential(nn.Linear(10,3), nn.Softmax(dim=1)) |
❌ 不能直接放入(不是 Module) |
| 动态维度 | 维度在构造时固定,不能运行时改变 | 维度每次调用可变: torch.softmax(x, dim=i) |
| JIT Script 支持 | ✅ 完全支持 torch.jit.script |
✅ 也支持,但需注意 tracing/script 差异 |
🧪 四、与模型生命周期的集成
- 是否出现在
model.modules()/model.parameters()中?
python
model = nn.Sequential(nn.Linear(2, 3), nn.Softmax(dim=1))
print(list(model.modules()))
# [<Sequential>, <Linear>, <Softmax>] ← Softmax 被视为子模块
print(list(model.parameters()))
# 只有 Linear 的参数,Softmax 无参数(正确)nn.Softmax会被模型"感知"到,出现在模块树中。torch.softmax不会被记录,对模型结构"透明"。
- 保存/加载模型(
state_dict)
nn.Softmax不会 在state_dict中产生条目(因为无参数),但模块结构会被保留 (如用torch.save(model, ...)保存整个模型)。torch.softmax完全不影响模型序列化。
💡 对部署的影响:
若使用
torch.jit.trace或torch.jit.script,包含nn.Softmax的模型会显式保留该操作节点;而用torch.softmax的模型在 trace 时也会捕获该操作,但不会以"模块"形式存在。
🧩 五、与 nn.functional 的关系
PyTorch 的设计哲学是:
torch.nn:面向对象接口(Module-based)torch.nn.functional(F):函数式接口(Function-based)
而:
nn.Softmax≈ 封装了F.softmaxtorch.softmax≈ 与F.softmax功能相同(实际上F.softmax内部调用torch.softmax)
python
import torch.nn.functional as F
# 三者等价
y1 = nn.Softmax(dim=1)(x)
y2 = F.softmax(x, dim=1)
y3 = torch.softmax(x, dim=1)📌 所以更准确地说:
nn.Softmax是F.softmax的 Module 封装,而torch.softmax是底层函数入口。
🚫 六、常见误区与陷阱
❌ 误区 1:"nn.Softmax 有可学习参数"
- 错误 !
nn.Softmax没有任何可学习参数,它只是一个确定性变换。 - 它出现在
model.modules()中只是为了结构清晰,不会增加模型大小或训练负担。
❌ 误区 2:"训练时必须加 Softmax"
- 错误 !
nn.CrossEntropyLoss=LogSoftmax + NLLLoss,内部已包含 Softmax 的数值稳定实现。 - 正确做法:训练时输出 logits,不加 Softmax ;推理时若需要概率,再加 Softmax。
❌ 误区 3:"torch.softmax 不能用于模型定义"
-
不完全对 !你可以在
forward中自由使用torch.softmax:pythonclass MyModel(nn.Module): def forward(self, x): x = self.fc(x) return torch.softmax(x, dim=1) # 完全合法!这种写法很常见,尤其当你不需要把 Softmax 作为独立层暴露时。
📊 七、性能与内存(实测验证)
我们在 CPU/GPU 上对两种方式做 benchmark:
python
x = torch.randn(1000, 1000).cuda()
%timeit nn.Softmax(dim=1)(x)
%timeit torch.softmax(x, dim=1)✅ 结果 :两者耗时、内存占用完全一致(差异在纳秒级,属噪声)。
原因:
nn.Softmax.forward只是简单调用F.softmax,无额外开销。
🧭 八、何时选择哪一个?------ 最佳实践指南
| 场景 | 推荐 | 理由 |
|---|---|---|
| 构建标准模型(如 ResNet 分类头) | nn.Softmax |
结构清晰,便于可视化、调试、导出 |
在 nn.Sequential 中组装模型 |
nn.Softmax |
必须使用 Module |
自定义 forward 中临时归一化 |
torch.softmax |
代码简洁,无需创建对象 |
需要动态改变 dim 参数 |
torch.softmax |
nn.Softmax 的 dim 在构造时固定(重点) |
| 编写通用工具函数/后处理脚本 | torch.softmax |
无状态,更函数式 |
| 使用 TorchScript 部署 | 两者均可,但 nn.Softmax 更易追踪 |
模块化结构利于静态分析 |
| 教学/演示模型结构 | nn.Softmax |
学生更容易理解"层"的概念 |
🧬 九、扩展:与其他激活函数的对比
PyTorch 对所有无参数激活函数都提供双重接口:
| 激活函数 | Module 形式 | Function 形式 |
|---|---|---|
| ReLU | nn.ReLU() |
torch.relu(), F.relu() |
| Sigmoid | nn.Sigmoid() |
torch.sigmoid(), F.sigmoid() |
| Tanh | nn.Tanh() |
torch.tanh(), F.tanh() |
| Softmax | nn.Softmax(dim) |
torch.softmax(input, dim), F.softmax(...) |
✅ 统一规律:
- Module 形式用于模型构建;
- Function 形式用于灵活计算。
📜 十、历史演进与设计哲学
- PyTorch 早期(0.x)更偏向函数式(类似 NumPy)。
- 随着模型复杂度提升,引入
nn.Module体系以支持:- 参数管理
- 设备迁移(
.to(device)) - 序列化(
state_dict) - 自动混合精度(AMP)
- 分布式训练
- 因此,即使无参数的操作(如 Softmax、ReLU)也被封装为 Module,以保持接口一致性。
🧠 设计哲学 :
"Everything that can be a layer, should be a layer --- if you want it to be part of the model."
✅ 总结:终极对比表
| 维度 | nn.Softmax |
torch.softmax |
|---|---|---|
| 类型 | nn.Module 子类 |
顶层函数 |
| 状态 | 有对象身份(可注册) | 无状态 |
| 参数 | 无 | 无 |
| 性能 | 相同 | 相同 |
| 灵活性 | dim 构造时固定 |
dim 每次可变 |
| 模型集成 | ✅ 是模型一部分 | ❌ 透明操作 |
| 序列化 | 结构保留(无参数) | 不影响 |
| 适用场景 | 模型定义、部署、教学 | 脚本、后处理、动态计算 |
| 代码风格 | 面向对象 | 函数式 |
| 推荐指数 | ⭐⭐⭐⭐(结构化场景) | ⭐⭐⭐⭐(灵活场景) |
🎯 最终建议:
不要纠结"哪个更好",而要问"当前上下文需要什么"。
- 如果你在定义一个可复用的模型类 → 用
nn.Softmax;- 如果你在写一个推理脚本或后处理函数 → 用
torch.softmax。
两者共存是 PyTorch 灵活性与结构性平衡的体现,理解其设计意图,才能写出更地道的 PyTorch 代码。
2、代码:
python
def model_test(test):
# 创建模型
my_model = My_ImageModel()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'当前模式: {device}') # cuda
# 加载模型参数
all_params = torch.load(f=r'model/ImageModel.pth', map_location=device) # 加载到 device 设备上
my_model.load_state_dict(all_params)
my_model.to(device=device) # 移到目标设备(CPU 或 GPU
# 设置是模型的全局状态,一旦调用 eval(),就会一直保持,直到你再次调用 train()
# 推荐 eval() 放在 load_state_dict 后面, 语义清晰、流程合理、社区标准做法
my_model.eval()
# 数据加载器, 现在是测试, 所以不用打乱 batch
data_loader = DataLoader(dataset=test, batch_size=128, shuffle=False)
right_cnt = 0 # 统计预测正确的个数
simple_sum = 0 # 总样本个数
with torch.no_grad(): # 预测时不需要计算梯度, 提高速度
for x_img, y_label in data_loader:
# ★★★ 关键:把数据也移到 device 上 ★★★
# 模型越大、batch size 越大、计算越密集 → GPU 优势越明显。
x_img = x_img.to(device)
y_label = y_label.to(device)
y_logits = my_model(x_img) # 预测
# print(y_logits) # 每个样本输出 10个 logits得分, 注意, 还没有经过 softmax 处理
# tensor([[-1.6582, -3.4140, -1.8593, ..., -2.2646, -0.6273, -2.7426],
# ...,
# [-4.1998, -2.5829, -0.6035, ..., -1.5239, -3.7205, -1.2198]],
# grad_fn=<AddmmBackward0>)
'''
优化:argmax 对 logits 和 softmax 结果是一样的!因为 softmax 是单调变换。
节省计算:直接用 logits.argmax(dim=1) 即可。
'''
y_predict_probability = torch.softmax(y_logits, dim=1)
# print(y_predict_probability)
# tensor([[8.3436e-03, 1.4415e-03, 6.8232e-03, ..., 4.5495e-03, 2.3392e-02, 2.8209e-03],
# ...,
# [8.6562e-04, 4.3606e-03, 3.1564e-02, ..., 1.2574e-02, 1.3980e-03, 1.7043e-02]], grad_fn=<SoftmaxBackward0>)
# 经过 softmax 处理后的结果中, 概率最大的就是预测结果
y_predict = y_predict_probability.argmax(dim=1) # 返回最大值的索引
# print(y_predict)
# tensor([3, 8, 8, 0, 6, 6, 1, ...])
result = y_predict == y_label
# print(result)
# tensor([ True, True, True, True, True, ...])
count = result.sum().item() # 当前 batch 预测正确的个数
right_cnt += count # 总共预测正确的个数
# 总共样本个数(在模型中有批量归一化处理, 设置了batch_size >=1, 所以真实样本个数需要统计, 而不能直接看 test 里多少个样本)
simple_sum += len(y_label)
right_rate = right_cnt / simple_sum
print(f'总样本个数 = {simple_sum}') # 10000
print(f'预测正确的样本个数 = {right_cnt}') # 6148
print(f'正确率 = {right_rate}') # 0.6148
if __name__ == '__main__':
train, test = create_data()
# 查看创建的模型
# my_model = My_ImageModle()
# show_model(my_model)
model_train(train)
# import torch
#
# print("PyTorch 版本:", torch.__version__)
# print("CUDA 可用:", torch.cuda.is_available())
# print("编译时支持的 CUDA 版本:", torch.version.cuda)
# if torch.cuda.is_available():
# print('True')
# else:
# print('False')
model_test(test)五、整体代码:
python
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision import transforms
from torchsummary import summary
from torch.utils.data import DataLoader
import torch.optim as optim
import time
import matplotlib.pyplot as plt
import os
os.chdir(r'F:\Pycharm\works-space\卷积神经网络CNN')
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # ←←← 关键!放在最前面(解决报错)
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False # 设置正常显示符号
torch.manual_seed(66)
def create_data():
# `transform=transforms.ToTensor` 实际上传递的是一个类而非一个实例化对象。需要确保传递给 `transform` 参数的是 `ToTensor` 类的一个实例,而不是类本身
train = CIFAR10(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test = CIFAR10(root='./data', train=False, transform=transforms.ToTensor(), download=True)
print(type(train.class_to_idx)) # dict
print(f'类别对应关系: {train.class_to_idx}')
# {'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
print(f'训练集形状 = {train.data.shape}') # (50000, 32, 32, 3)
print(f'测试集形状 = {test.data.shape}') # (10000, 32, 32, 3)
# 把训练集中的 第1张 图片画出来
plt.style.use('fivethirtyeight')
plt.imshow(X=train.data[1]) # train.data 是查看原始图片的Numpy(H、W、C)
plt.show()
# 第1张 图片对应的类型是
img, label = train[1] # img 是 tensor (C、H、W)
print(type(label)) # int
print(label) # 9
# `train.classes` 属性。这个属性返回一个列表,其中的索引对应于类别的整数标签,而值则是类别的名称字符串
print(f'第1张 图片对应的类型是: {train.classes[label]}') # truck
return train, test
class My_ImageModel(nn.Module):
def __init__(self):
super().__init__()
# 第1层 卷积层: 输入通道3, 输出通道6
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=(3, 3), stride=1, padding=0)
# 第1层: 卷积层得到的特征图需要经过激活函数
self.relu1 = nn.ReLU()
# 第1层 池化层: 池化窗口大小为 2x2
self.pool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0)
# 第2层 卷积层: 输入通道6, 输出通道16
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(3, 3), stride=1, padding=0)
# 第2层: 卷积层得到的特征图需要经过激活函数
self.relu2 = nn.ReLU()
# 第2层 池化层: 池化窗口大小为 2x2
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0)
# 卷积层和池化层一顿操作后, 理论上可以直接手算出来 隐藏层1 的输入特征个数, 但是我不想算, 而且还容易算不对
# 计算隐藏层1的输入特征个数
# 模拟一张图。 因为训练集、测试集的图片都是 3通道, 32x32, 故这里必须是 3通道, 32x32
# 目前先到这里, 就 32x32, 只是想得到隐藏层1的输入特征个数, 后续会有更好的方法得到特征个数
temp_x = torch.randn(size=(1, 3, 32, 32)) # 这里的 3 32x32 需要优化
with torch.no_grad():
# 模拟前向传播计算一遍, 目的在于得到 隐藏层1的输入特征个数
temp_x = self.conv1(temp_x)
temp_x = self.relu1(temp_x)
temp_x = self.pool1(temp_x)
temp_x = self.conv2(temp_x)
temp_x = self.relu2(temp_x)
temp_x = self.pool2(temp_x)
print(f'temp_x.shape = {temp_x.shape}') # torch.Size([1, 16, 6, 6])
temp_x = temp_x.reshape(1, -1)
print(f'temp_x.shape = {temp_x.shape}') # torch.Size([1, 576]), 576 就是隐藏层1的输入特征个数
# 隐藏层1: 输入特征个数 = temp_x.shape[1], 输出 120
self.linear1 = nn.Linear(in_features=temp_x.shape[1], out_features=120)
# 隐藏层1: 批量归一化
# self.bn1 = nn.BatchNorm1d(num_features=temp_x.shape[1]) 错误!
self.bn1 = nn.BatchNorm1d(num_features=120) # 是把 linear1 的结果进行归一化, 不是把 linea1 的输入归一化
# 激活函数1
self.linear1_relu1 = nn.ReLU()
# 隐藏层1: dropout p: 每个神经元在每次前向传播时,有 30% 的概率被"丢弃"(即置为 0)
self.dropout1 = nn.Dropout(p=0.3)
# 隐藏层2: 输入120, 输出 84
self.linear2 = nn.Linear(in_features=120, out_features=84)
# 隐藏层2: 批量归一化
# self.bn2 = nn.BatchNorm1d(num_features=120) 错误!
self.bn2 = nn.BatchNorm1d(num_features=84) # 是把 linear2 的结果进行归一化, 不是把 linea2 的输入归一化
# 激活函数2
self.linear2_relu2 = nn.ReLU()
# 隐藏层2: dropout p: 每个神经元在每次前向传播时,有 30% 的概率被"丢弃"(即置为 0)
self.dropout2 = nn.Dropout(p=0.3)
# 输出层: 10分类, 所以共10个输入, 这里不需要用 softmax
self.out = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
# 卷积层1 + 激活函数1 + 池化层1
x = self.conv1(x)
x = self.relu1(x) # 卷积层得到的特征图通常需要经过激活函数
x = self.pool1(x)
# 卷积层2 + 激活函数2 + 池化层2
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x) # 卷积层得到的特征图通常需要经过激活函数
# 把 卷积层 + 池化层 得到的 [batch_size, C, H, W] 转成 二维
# 不能写成 x.reshape(8, -1) 因为最后一批可能没有 8 个样本, 所以不能写死8
x = x.reshape(x.shape[0], -1)
# 隐藏层1 + 批量归一化 + 激活函数1 + dropout
x = self.linear1(x)
x = self.bn1(x) # 如果batch_size=1,这里会报错, 在笔记《关于 batch size 的要求》
x = self.linear1_relu1(x)
x = self.dropout1(x)
# 隐藏层2 + 批量归一化 + 激活函数2 + dropout
x = self.linear2(x)
x = self.bn2(x) # 如果batch_size=1,这里会报错, 在笔记《关于 batch size 的要求》
x = self.linear2_relu2(x)
x = self.dropout2(x)
# 输出层: 10分类, 所以共10个输入, 这里不需要用 softmax
output = self.out(x)
return output
def show_model(my_model):
# input_size: 单个样本的输入形状(不含 batch 维度)
summary(my_model, input_size=(3, 32, 32))
# ----------------------------------------------------------------
# Layer (type) Output Shape Param #
# ================================================================
# Conv2d-1 [-1, 6, 30, 30] 168
# ReLU-2 [-1, 6, 30, 30] 0
# MaxPool2d-3 [-1, 6, 15, 15] 0
# Conv2d-4 [-1, 16, 13, 13] 880
# ReLU-5 [-1, 16, 13, 13] 0
# MaxPool2d-6 [-1, 16, 6, 6] 0
# Linear-7 [-1, 120] 69,240 计算: 120 x 576 + 120 = 69,240
# BatchNorm1d-8 [-1, 120] 240
# ReLU-9 [-1, 120] 0
# Dropout-10 [-1, 120] 0
# Linear-11 [-1, 84] 10,164
# BatchNorm1d-12 [-1, 84] 168
# ReLU-13 [-1, 84] 0
# Dropout-14 [-1, 84] 0
# Linear-15 [-1, 10] 850
# ================================================================
# Total params: 81,710
# Trainable params: 81,710
# Non-trainable params: 0
# ----------------------------------------------------------------
# Input size (MB): 0.01
# Forward/backward pass size (MB): 0.14
# Params size (MB): 0.31
# Estimated Total Size (MB): 0.47
# ----------------------------------------------------------------
def model_train(train):
# 数据加载器: batch_size 通常设置为 2 的幂次方(如 32、64、128、256、512 等),但这 不是硬性规定,而是一种经验性最佳实践。
# 实验表明:只要 batch size 不太小(≥16),是否为 2 的幂对最终精度几乎没有影响,主要影响的是训练速度的微小差异(通常 <5%)
data_loader = DataLoader(dataset=train, batch_size=128, shuffle=True)
# 检查 GPU, 如果有 GPU 就用 GPU(计算更快), 否则还是用 CPU
# 模型越大、batch size 越大、计算越密集 → GPU 优势越明显。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'当前模式: {device}') # cuda
# 创建模型 并 移到 GPU
my_model = My_ImageModel().to(device=device)
my_model.train() # 切记! 切换成训练模式
# 创建优化器
optimizer = optim.Adam(params=my_model.parameters(), lr=0.001, betas=(0.9, 0.999))
#损失函数
criterion = nn.CrossEntropyLoss() # 默认是平均损失
epochs = 10 # 电脑硬件不行, 计算太慢了, 所以少训练几次
loss_mean_list = []
right_rate_list = []
for epoch in range(epochs):
loss_sum = 0 # 当前 epoch 的总损失
right_cnt = 0 # 当前 epoch 样本预测正确的个数
simple_cnt = 0 # 当前 epoch 样本个数
start_time = time.perf_counter()
for x_img, y_label in data_loader:
# ★★★ 关键:把数据也移到 device 上 ★★★
# 模型越大、batch size 越大、计算越密集 → GPU 优势越明显。
x_img = x_img.to(device)
y_label = y_label.to(device)
optimizer.zero_grad() # 1. 梯度清零
current_len = len(y_label) # 当前 batch 样本数量, 模型中有 批量归一化, 所以样本数量至少为 2 条
if current_len <= 1:
continue
y = my_model(x_img) # 2. 前向传播
loss = criterion(y, y_label) # 3. 计算损失值 (默认是平均损失)
loss.backward() # 4. 反向传播
optimizer.step() # 5. 梯度更新
loss_sum += loss.item() # 当前 batch 损失
# 统计当前 batch 正确率(能与后续模型测试形成对比, 是欠拟合? 还是过拟合? 还是刚好?)
y_predict = torch.softmax(y, dim=1).argmax(dim=1) # 预测为哪个类别. 比如: tensor([3, 8, 8, 0, 6, 6, 1, ...])
right_cnt += (y_predict == y_label).sum().item() # 统计当前 batch 样本预测正确的个数
simple_cnt += len(y_label) # 当前 batch 总样本个数
end_time = time.perf_counter()
print(f'第 {epoch + 1} 个epoch耗时: {end_time - start_time: .6f}s')
# GPU: 6.140568s、7.849436s、8.378597s、8.414186s、8.115676s、...
right_rate = right_cnt / simple_cnt # 当前 epoch 样本预测正确率
right_rate_list.append(right_rate)
print(f'当前 epoch 预测正确的概率 = {right_rate}')
# 0.41676、0.52106、0.55552、0.57942、0.5945、0.60696、0.61684、0.6298、0.63882、0.64736
loss_mean_list.append(loss_sum)
print(loss_mean_list)
# [632.8302, 523.2404, 489.4019, ..., 391.1543](截断前4位小数, 注意, 不是四舍五入)
plt.style.use('fivethirtyeight')
plt.figure(figsize=(13, 10))
plt.plot(range(1, epochs + 1), loss_mean_list)
plt.title('每个 epoch 的损失值')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
plt.style.use('fivethirtyeight')
plt.figure(figsize=(13, 10))
plt.plot(range(1, epochs + 1), right_rate_list)
plt.title('每个 epoch 的正确率')
plt.xlabel('epoch')
plt.ylabel('正确率')
plt.show()
# 保存模型参数, 用的时候直接加载放到模型上就行了
# model_params = my_model.state_dict() # GPU模式下, 这样保存的模型只能在有 GPU 的环境加载,否则会报错!
model_params = my_model.cpu().state_dict() # 当前模式是 GPU, 先转到 CPU 上再保存参数(更安全)
torch.save(obj=model_params, f=r'model/ImageModel.pth')
def model_test(test):
# 创建模型
my_model = My_ImageModel()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'当前模式: {device}') # cuda
# 加载模型参数
all_params = torch.load(f=r'model/ImageModel.pth', map_location=device) # 加载到 device 设备上
my_model.load_state_dict(all_params)
my_model.to(device=device) # 移到目标设备(CPU 或 GPU
# 设置是模型的全局状态,一旦调用 eval(),就会一直保持,直到你再次调用 train()
# 推荐 eval() 放在 load_state_dict 后面, 语义清晰、流程合理、社区标准做法
my_model.eval()
# 数据加载器, 现在是测试, 所以不用打乱 batch
data_loader = DataLoader(dataset=test, batch_size=128, shuffle=False)
right_cnt = 0 # 统计预测正确的个数
simple_sum = 0 # 总样本个数
with torch.no_grad(): # 预测时不需要计算梯度, 提高速度
for x_img, y_label in data_loader:
# ★★★ 关键:把数据也移到 device 上 ★★★
# 模型越大、batch size 越大、计算越密集 → GPU 优势越明显。
x_img = x_img.to(device)
y_label = y_label.to(device)
y_logits = my_model(x_img) # 预测
# print(y_logits) # 每个样本输出 10个 logits得分, 注意, 还没有经过 softmax 处理
# tensor([[-1.6582, -3.4140, -1.8593, ..., -2.2646, -0.6273, -2.7426],
# ...,
# [-4.1998, -2.5829, -0.6035, ..., -1.5239, -3.7205, -1.2198]],
# grad_fn=<AddmmBackward0>)
'''
优化:argmax 对 logits 和 softmax 结果是一样的!因为 softmax 是单调变换。
节省计算:直接用 logits.argmax(dim=1) 即可。
'''
y_predict_probability = torch.softmax(y_logits, dim=1)
# print(y_predict_probability)
# tensor([[8.3436e-03, 1.4415e-03, 6.8232e-03, ..., 4.5495e-03, 2.3392e-02, 2.8209e-03],
# ...,
# [8.6562e-04, 4.3606e-03, 3.1564e-02, ..., 1.2574e-02, 1.3980e-03, 1.7043e-02]], grad_fn=<SoftmaxBackward0>)
# 经过 softmax 处理后的结果中, 概率最大的就是预测结果
y_predict = y_predict_probability.argmax(dim=1) # 返回最大值的索引
# print(y_predict)
# tensor([3, 8, 8, 0, 6, 6, 1, ...])
result = y_predict == y_label
# print(result)
# tensor([ True, True, True, True, True, ...])
count = result.sum().item() # 当前 batch 预测正确的个数
right_cnt += count # 总共预测正确的个数
# 总共样本个数(在模型中有批量归一化处理, 设置了batch_size >=1, 所以真实样本个数需要统计, 而不能直接看 test 里多少个样本)
simple_sum += len(y_label)
right_rate = right_cnt / simple_sum
print(f'总样本个数 = {simple_sum}') # 10000
print(f'预测正确的样本个数 = {right_cnt}') # 6148
print(f'正确率 = {right_rate}') # 0.6148
if __name__ == '__main__':
train, test = create_data()
# 查看创建的模型
# my_model = My_ImageModle()
# show_model(my_model)
model_train(train)
# import torch
#
# print("PyTorch 版本:", torch.__version__)
# print("CUDA 可用:", torch.cuda.is_available())
# print("编译时支持的 CUDA 版本:", torch.version.cuda)
# if torch.cuda.is_available():
# print('True')
# else:
# print('False')
model_test(test)