本节内容的目标是:实践声音克隆技术。理解CosyVoice的工作原理,完成声音克隆任务。目录结构如下:

🌟 CosyVoice项目背景
CosyVoice是阿里通义开发的语音生成大模型,是大模型驱动语音合成的代表,在GitHub上已获得16.1k star。可以通过参考音频来复制说话人的音色语气、并且支持跨语言,由同一音色表达不同语言,也能由prompt添加指令,切换情感表达。
项目地址:
https://github.com/FunAudioLLM/CosyVoice
CosyVoice部署使用
先来看下CosyVoice是如何部署使用的。
1.获取源码
首先克隆CosyVoice官方仓库:
bash
git clone https://github.com/FunAudioLLM/CosyVoice
cd CosyVoice2.安装uv包管理器
使用uv作为Python包管理器
arduino
curl -LsSf https://astral.sh/uv/install.sh | sh3.创建虚拟环境
创建Python 3.10的虚拟环境:
css
uv venv --python 3.10 cosyvoice_3104.激活虚拟环境
激活刚创建的虚拟环境,激活完成后,环境前缀为cosyvoice_310
bash
source cosyvoice_310/bin/activate5.安装依赖包
使用uv安装项目依赖,添加--index-strategy unsafe-best-match参数解决依赖冲突:
rust
uv pip install -r requirements.txt --index-strategy unsafe-best-match6.下载预训练模型
通过modelscope下载CosyVoice2-0.5B模型到 pretrained_models 目录:
bash
# 创建模型目录
mkdir -p pretrained_models通过modelscope下载:
less
python3 -c "from modelscope import snapshot_download; snapshot_download('iic/CosyVoice2-0.5B', local_dir='pretrained_models/CosyVoice2-0.5B')"7.修复兼容性问题
版本兼容性问题,需要修改cosyvoice/cli/frontend.py 文件,找到第153行左右的代码:
css
embedding = self.spk2info[spk_id]['embedding']替换为:
csharp
embedding = self.spk2info[spk_id].get('embedding', self.spk2info[spk_id].get('llm_embedding'))目的是解决新版本模型使用 llm_embedding 字段而旧代码仍访问 embedding 字段导致的 KeyError 问题。
8.启动Web界面
运行以下命令启动CosyVoice的Web界面:
css
python webui.py --port 8000 --model_dir pretrained_models/CosyVoice2-0.5B9.访问界面
启动成功后,在浏览器中访问:
arduino
http://localhost:8000可以看到CosyVoice的web界面,体验声音克隆功能。在网页上传一小段参考语音及其逐字稿,再输入你想合成的目标文本,就可以生成得到一段带有与参考音频音色的合成语音。
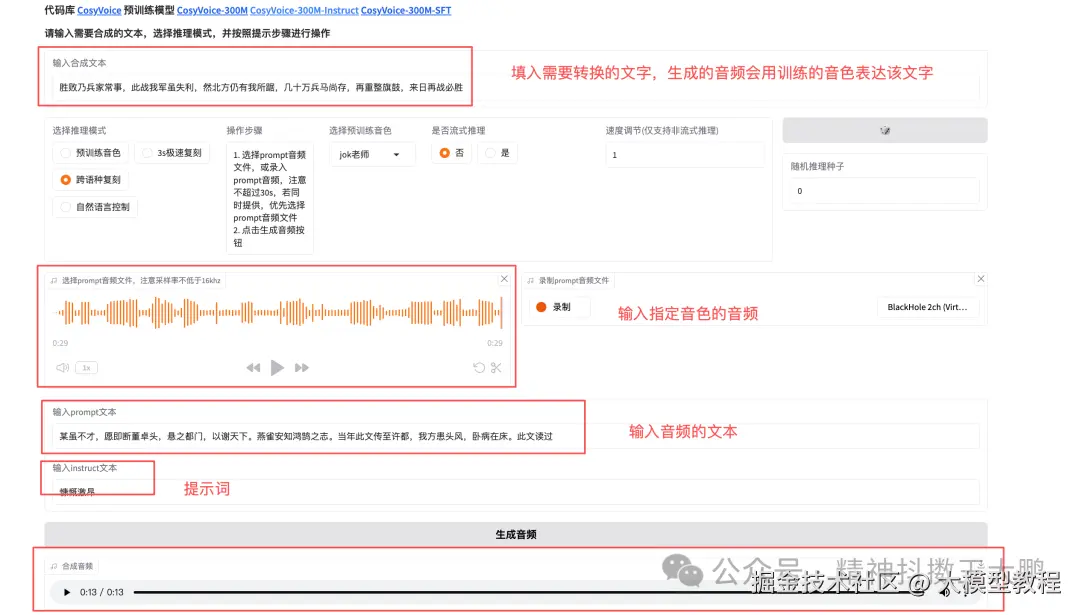
CosyVoice工作原理
如果让你模仿刀郎唱歌,你会怎么做?首先,你需要反复听刀郎的歌曲,熟悉他的声音特点(沙哑)、转折特征。接着你要了解歌词,歌词内容表达什么样的情感,最后调整自己的发声,结合歌词情感,唱出刀郎风格的歌。
那么对应CosyVoice的工作流程,也是类似的。
1.参考音频(S3模型):语音信号本质是连续的模拟信号,但AI模型更适合处理离散的token。S3模型将连续语音信号转换为离散的"语义token"序列,这些token既包含声学特征,又承载语义内容;
2.说话人特征提取:从参考音频中提取x-vector说话人嵌入向量,这是说话人独特音色的数字特征;
3.序列构造与自回归生成:将所有信息(说话人embedding、提示文本tokens、目标文本tokens、转换标识、参考语音tokens)组合成完整输入序列,然后自回归Transformer根据这些条件逐个预测并生成目标语音的token序列;
4.特征重构(Flow Matching):将生成的离散语音tokens重构为连续的梅尔频谱(声学特征)。Flow Matching将抽象的token序列转化为具体的声谱图;
5.声码器合成:声码器(HiFiGAN)将梅尔频谱还原成最终可听的音频波形;
基于CosyVoice论文的架构设计,整个系统分为三个核心组件:
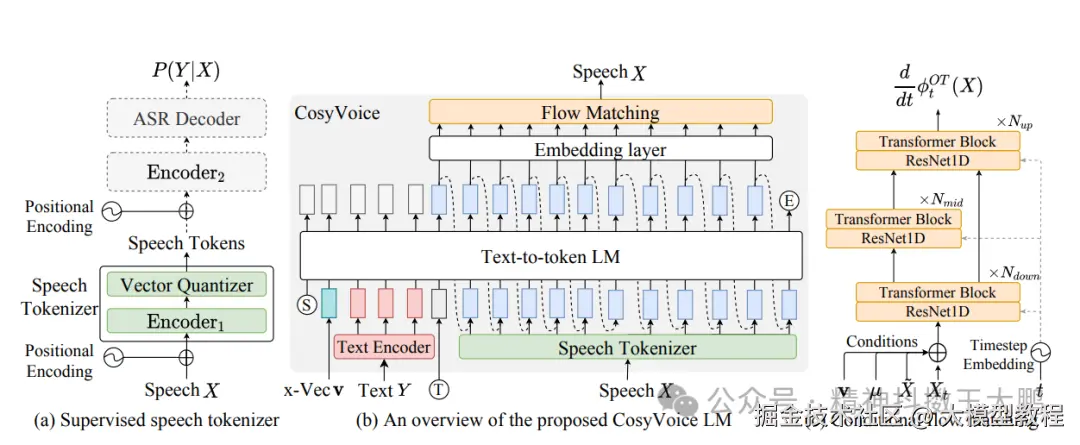
1.语音分词器 S3
将连续语音信号转换为离散token序列。基于预训练的语音识别模型,在编码器的第6层后插入量化层,包含4096个码本。每个token既保留声学特征(音色、语调),又承载语义内容,实现有意义的离散化。
2.自回归Transformer
根据输入条件逐个生成语音token序列。采用Teacher Forcing策略加速训练。输入序列构造为: 说话人embedding + 提示文本tokens + 目标文本tokens + 转换标识 + 参考语音tokens + 待生成位置 ,目标是预测对应的语音token序列。
3.Flow Matching
将离散tokens重构为连续的声学特征(梅尔频谱)。通过求解最优传输,学习从简单分布到复杂梅尔频谱的最优路径。