本文档系统阐述 DeerFlow 中 Planner 的职责边界、端到端执行流程、关键节点设计、数据结构、容错与人审机制,以及与研究/编码子代理的协同方式。面向开发与运维读者,帮助快速理解与调优 Planner 相关链路。
时序图(Sequence Diagram)
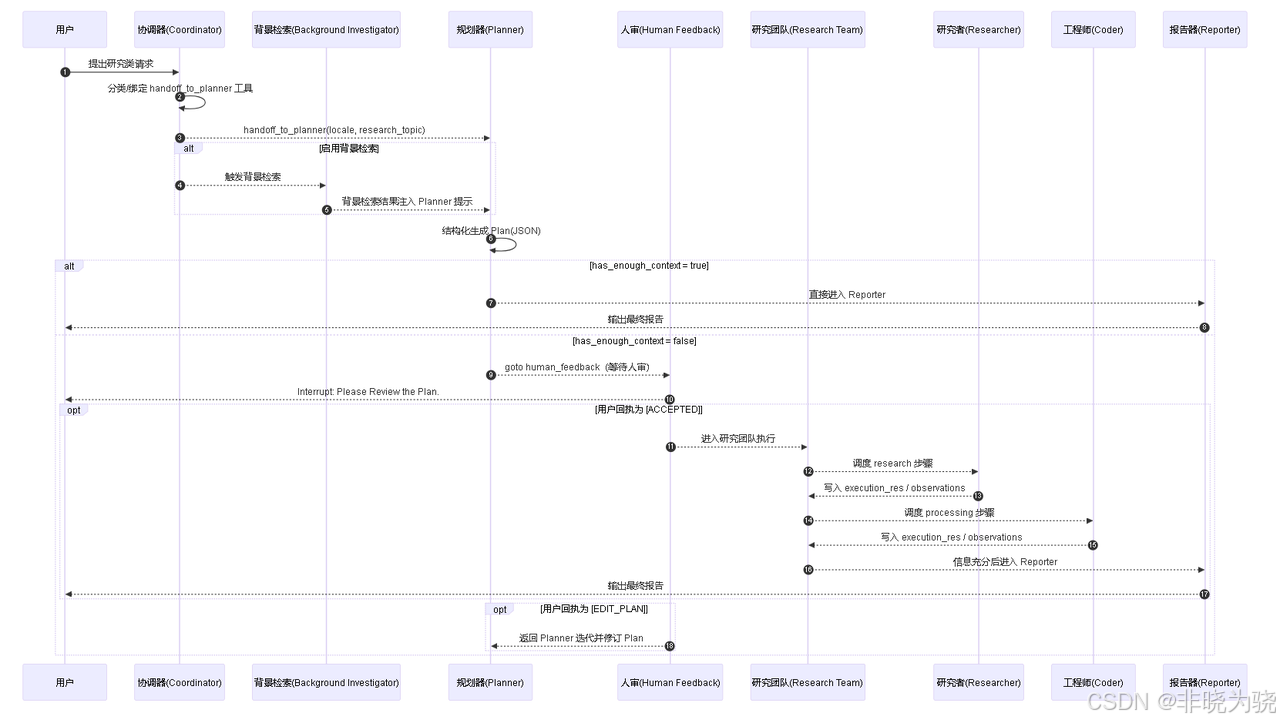
1. 角色与职责
- 协调器
coordinator:识别用户请求类型;将研究类问题通过工具信号handoff_to_planner路由给 Planner;必要时在规划前触发"背景检索"。 - 规划器
planner:依据严格的规划提示词与结构化输出模式,产出Plan(包含步骤、类型与是否需要检索等元数据)。 - 人审
human_feedback:对Plan进行人工把关;支持接受或要求修改。 - 研究者
researcher:执行research类型步骤(检索/爬取/RAG)。 - 工程师
coder:执行processing类型步骤(计算/编程/数据加工)。 - 报告器
reporter:将已收集的信息与分析组织成最终报告。
2. 工作流与时序
- User → Coordinator:用户提出研究类问题(任意语言,保持同语回复)。
- Coordinator → Tool Call:LLM 绑定
handoff_to_planner工具。若判断为研究请求,则调用该工具(可携带locale、research_topic)。 - 可选 Background Investigation:当启用
enable_background_investigation=true时,协调器先进入background_investigator节点进行"轻量背景检索",将结果拼入 Planner 提示(作为额外用户消息)。 - Planner:在"结构化输出"模式下生成
PlanJSON。若has_enough_context=true,直接跳转 Reporter;否则转到人审。 - Human Feedback(中断):向外部发出 "Please Review the Plan." 的可恢复中断;等待
[ACCEPTED]或[EDIT_PLAN]开头的回执。 - Research Team:当被接受后,进入
research_team协作执行;依据首个未完成步骤的step_type,转给researcher或coder节点,并循环直至步骤完成或回到 Planner 迭代。 - Reporter:按设定的报告风格,组织生成最终报告内容并返回。
3. 核心数据结构
- Plan(
src/prompts/planner_model.py)locale: string:输出语言;继承用户输入或由 Coordinator 传入。has_enough_context: boolean:严格判定当前是否信息充足。为 true 时可跳过研究直接成稿。thought: string:对用户需求的复述与规划思路。title: string:任务标题。steps: Step[]:最多max_step_num个步骤(默认 3)。
- Step
need_search: boolean:是否需要外部检索/抓取。title: string,description: string:步骤名与需采集/处理的具体数据点。step_type: "research" | "processing":研究或加工;决定路由至researcher/coder。execution_res?: string:步骤执行产出,由执行节点回填。
4. 关键节点实现要点
-
Coordinator(
src/graph/nodes.py)- 使用
get_llm_by_type(AGENT_LLM_MAP["coordinator"])绑定handoff_to_planner工具; - 若工具被调用,则路由至
planner或(在启用背景检索时)background_investigator; - 工具参数中的
locale、research_topic会覆盖当前状态。
- 使用
-
Background Investigator(可选)
- 依据
SELECTED_SEARCH_ENGINE(Tavily 或其它)执行简要检索; - 将结果拼入 Planner 的输入消息,提高初次规划质量与召回范围。
- 依据
-
Planner
- 采用结构化输出(JSON Mode);basic 模式直接
with_structured_output(Plan),其它模式走流式拼接; - 对 JSON 做
repair_json_output + json.loads容错; - 分支:
has_enough_context=true:校验为Plan对象,goto=reporter;- 否则:将"原始 JSON 字符串"暂存到
current_plan,goto=human_feedback。
- 采用结构化输出(JSON Mode);basic 模式直接
-
Human Feedback(中断)
- 仅接受以下前缀的回执:
[ACCEPTED]:通过;[EDIT_PLAN]:携带修改意见,回到 Planner 迭代;
- 其它值将抛出类型错误,避免不明状态。
- 仅接受以下前缀的回执:
-
Researcher / Coder
- Researcher:
need_search=true的research步骤,提供"检索工具 + 爬取工具 +(可选)RAG 本地检索工具"; - Coder:
processing步骤,负责统计、计算、程序化分析与结构化数据产出; - 两者将执行结果写回
execution_res,并将观察结果纳入observations供后续步骤使用。
- Researcher:
-
Reporter
- 根据
report_style(如 academic/popular_science)生成成稿; - 添加表格/引用提示,规范输出格式与引用规范。
- 根据
5. 配置项与默认值
max_plan_iterations:默认 1;超过即直接进入 Reporter,避免无限循环。max_step_num:默认 3;Planner 必须在限定步数内覆盖关键信息面。max_search_results:默认 3;影响检索结果数量与速度。enable_deep_thinking:默认 false;启用后 Planner 选用"reasoning"类模型。enable_background_investigation(State 层):默认 true;可关闭以缩短首轮延迟。AGENT_RECURSION_LIMIT(env):研究/编码子代理的递归深度,默认 25,非法值自动回落。
6. 容错与兜底
- JSON 解析失败:
- 首次失败:
goto=__end__(防止无效循环); - 非首次失败:
goto=reporter(使用已有信息成稿)。
- 首次失败:
- 规划超限:当
plan_iterations >= max_plan_iterations,直接goto=reporter。 - 无工具调用:Coordinator 未调用任何工具 → 终止执行(
__end__),写日志排查提示词或模型配置。
7. 设计原则与最佳实践
- 严格的"上下文充足性"判定:宁缺毋滥,缺数据则规划下一步收集;
- 研究/加工解耦:
research仅采集与溯源,不做计算;processing仅做计算与结构化加工,不做外网检索;
- 逐步累积
observations,在后续步骤与 Reporter 复用; - 对外提供明确的人审接口,确保关键节点的质量把关与可控性。
8. 参考 Plan 模板(含 processing)
json
{
"locale": "zh-CN",
"has_enough_context": false,
"thought": "对用户研究需求的简要复述与拆解思路",
"title": "主题名称",
"steps": [
{
"need_search": true,
"title": "历史沿革与核心研发方向",
"description": "收集公司成立背景、阶段性技术演进、关键研发里程碑、投入强度。",
"step_type": "research"
},
{
"need_search": true,
"title": "现有技术能力与指标",
"description": "采集架构方案、团队构成、专利与测评、典型案例等定量+定性信息。",
"step_type": "research"
},
{
"need_search": true,
"title": "同行对比与趋势",
"description": "与同赛道 3--5 家进行横向对比;收集专家/媒体/投研观点。",
"step_type": "research"
},
{
"need_search": false,
"title": "指标归并与结构化输出",
"description": "将采集信息做指标口径统一、表格化对比、评分与结论归纳。",
"step_type": "processing"
}
]
}9. 人审回执格式
- 接受执行(继续):
text
[ACCEPTED] 按当前 Plan 执行。- 需要修改(回到 Planner):
text
[EDIT_PLAN] 请在步骤 3 后新增 1 步 processing:用于指标归并、横向表格对比与评分输出。10. 与业务落地的建议
- 在
description中显式列出"首选信息源清单"(官网/企信/专利/测评/投研等)与"指标口径"; - 结合
resources注入本地资料,强制researcher先用本地检索工具; - 根据需求切换
report_style(如学术体 vs. 通俗体),确保对外输出一致性。