目录
[2.1 创建工作流](#2.1 创建工作流)
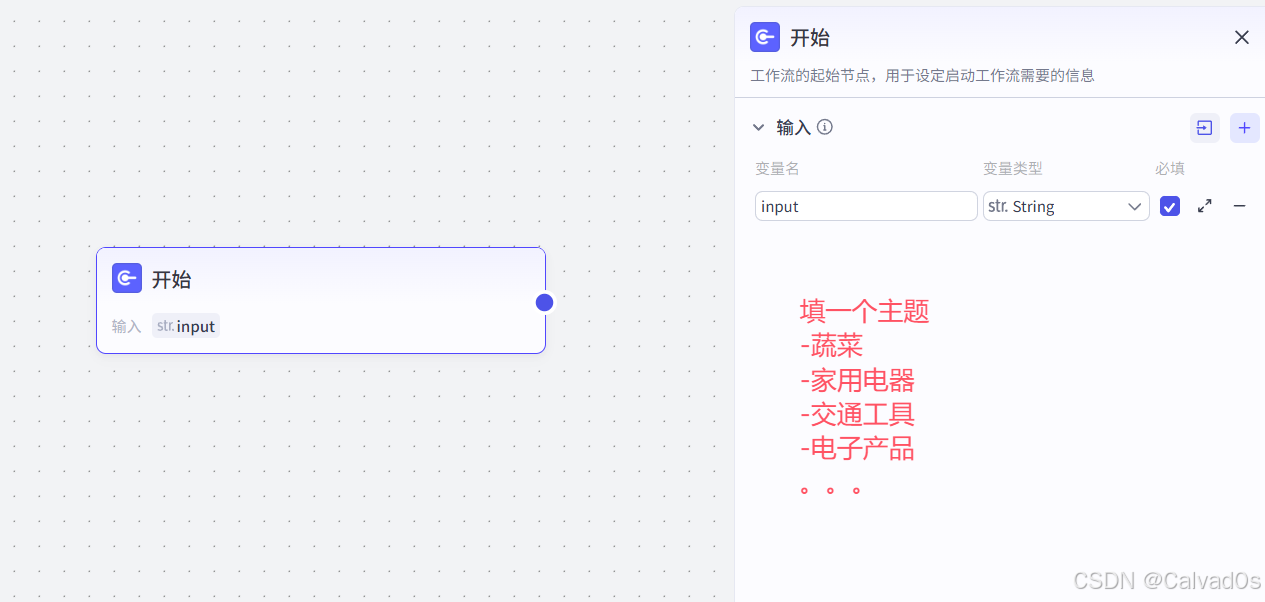
[2.2 开始节点](#2.2 开始节点)
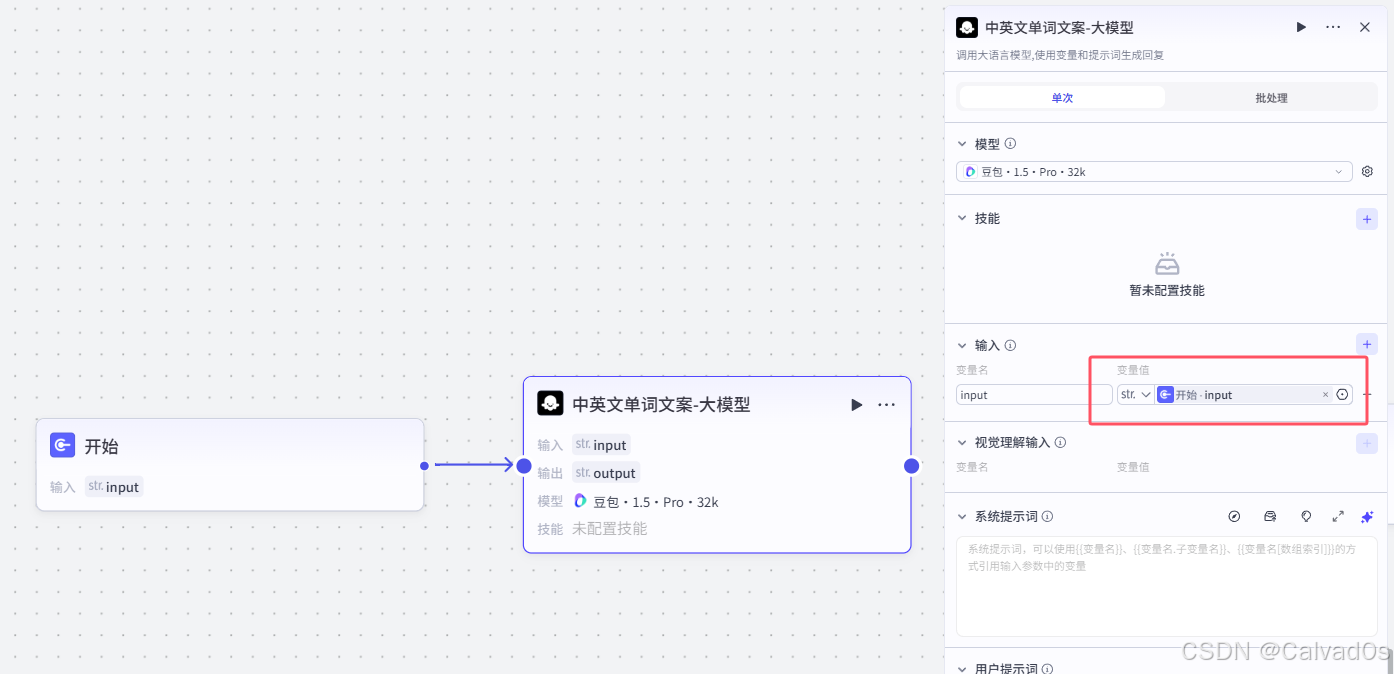
[2.3 中英文单词文案大模型](#2.3 中英文单词文案大模型)
[2.4 歌词格式处理-代码节点只能用py和js](#2.4 歌词格式处理-代码节点[只能用py和js])
[2.5 生成图片文案-代码节点](#2.5 生成图片文案-代码节点)
[2.6 循环生图文案-循环节点 + 大模型节点](#2.6 循环生图文案-循环节点 + 大模型节点)
[2.7 循环生成图片-循环节点+插件节点](#2.7 循环生成图片-循环节点+插件节点)
[2.8 循环生成音频-循环节点+插件节点](#2.8 循环生成音频-循环节点+插件节点)
[2.9 视频创作前-代码节点](#2.9 视频创作前-代码节点)
[2.10 后续使用剪映小助手--生成视频](#2.10 后续使用剪映小助手--生成视频)
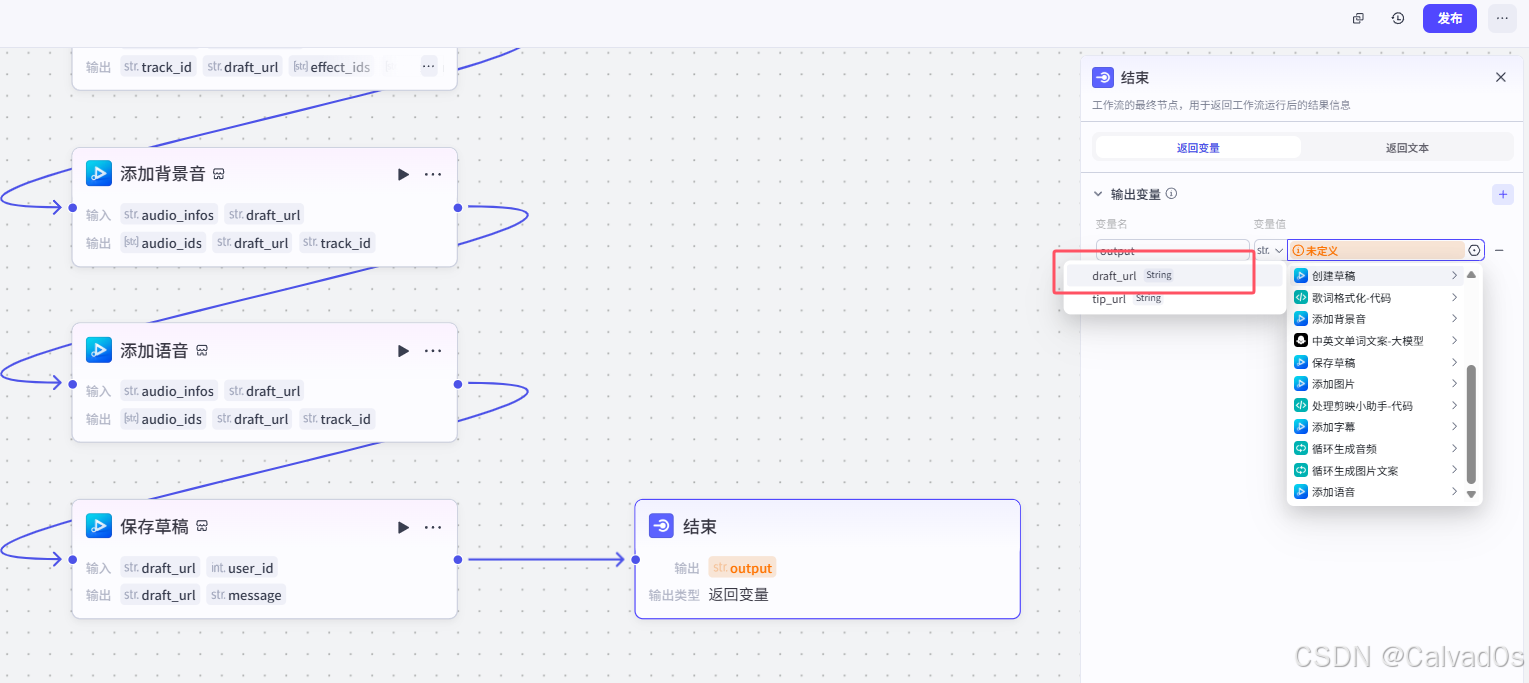
[2.11 结束节点](#2.11 结束节点)
一、需求与流程设计
python
# 1 用户输入一个主题---》生成中英文儿歌,方便小朋友记忆不同主题的单词
-动物--》10个动物单词儿歌
-蔬菜--》10种蔬菜单词儿歌
python
# 1 开始节点
-用户输入 某个主题
-动物
-蔬菜
-水果
-家用电器
。。。
# 2 大模型
-根据用户输入的主题,生成文案
-10个英文单词,带中文
# 3 代码节点:处理大模型型生成的文案
# 4 代码节点:图片生成前处理
# 5 循环10次
## 5.1 大模型:生成 图片 文案
# 6 循环10次
## 6.1 生成图片
# 7 循环10次
## 6.1 文字生成语音
## 6.2 获取语言长度
# 8 代码处理前面所有数据
-后续使用剪映小助手
-需要很多变量:提前处理好,统一输出,给后面用
-------------固定的---生成其他视频:老黄历,历史人物讲解,书籍讲解,历史典故------------------------
# 9 创建草稿
# 10 添加图片
# 11 添加字幕
# 12 添加特效
# 13 添加音频--背景音乐
# 14 添加音频--朗读音频
# 15 保存草稿
-链接地址二、实现智能体工作流
2.1 创建工作流

2.2 开始节点
2.3 中英文单词文案大模型
python
# 1 作用--帮我们生成中英文文案--->用于视频的字幕和语言朗读
猫 猫 Cat
Cat Cat Cat
狗 狗 Dog
Dog Dog Dog
.....输入
系统提示词
python
# 角色
你是一个优秀的歌词编曲家,擅长给启蒙儿歌作词
# 要求
如果用户输入了主题,则根据用户输入的主题随机生成10个儿歌句子
# 格式限制
请严格按照下方案例输出的格式
"中文 中文 英文
英文 英文 英文"
为一个动物句子,请严格按照我的要求,不要出现数字等不必要的文案
## 案例输出
猫 猫 Cat
Cat Cat Cat
狗 狗 Dog
Dog Dog Dog
兔子 兔子 Rabbit
Rabbit Rabbit Rabbit
鸟 鸟 Bird
Bird Bird Bird
鱼 鱼 Fish
Fish Fish Fish用户提示词
python
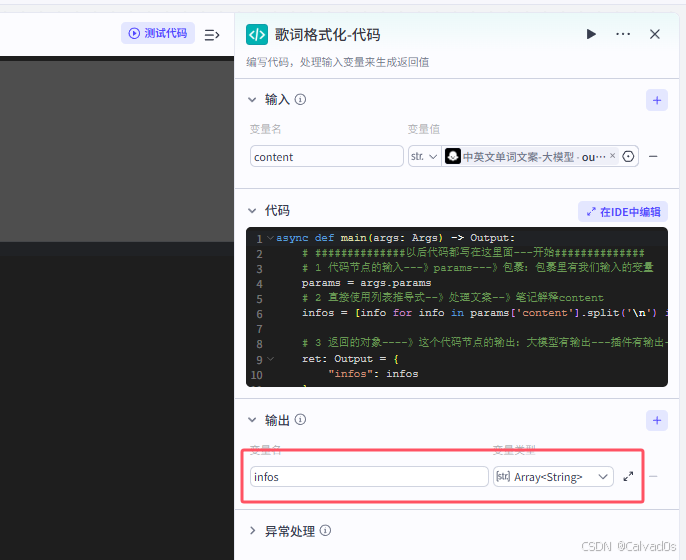
{{input}}2.4 歌词格式处理-代码节点只能用py和js
python
# 1 作用---》对大模型生成的歌词--进行拆分
# 大模型生成的:如下---》字符串--》\n表示换行
电视 电视 Television\nTelevision Television Television\n冰箱 冰箱 Refrigerator\nRefrigerator Refrigerator Refrigerator\n空调 空调 Air conditioner\nAir conditioner Air conditioner Air conditioner\n洗衣机 洗衣机 Washing machine\nWashing machine Washing machine Washing machine\n微波炉 微波炉 Microwave oven\nMicrowave oven Microwave oven Microwave oven\n吸尘器 吸尘器 Vacuum cleaner\nVacuum cleaner Vacuum cleaner Vacuum cleaner\n电饭煲 电饭煲 Rice cooker\nRice cooker Rice cooker Rice cooker\n电扇 电扇 Electric fan\nElectric fan Electric fan Electric fan\n吹风机 吹风机 Hair dryer\nHair dryer Hair dryer Hair dryer\n电灯 电灯 Electric light\nElectric light Electric light Electric light
# 处理成-列表格式--放多个元素
["电视 电视 Television",
"Television Television Television",
"冰箱 冰箱 Refrigerator",
"Refrigerator Refrigerator Refrigerator",
。。。。。
]
# 如果使用大模型--》写好提示词--》是可以处理成我们想要的格式
-缺点:1 收费 2 大模型耗时更长
-处理数据时候[固定格式]--》最好使用代码输入
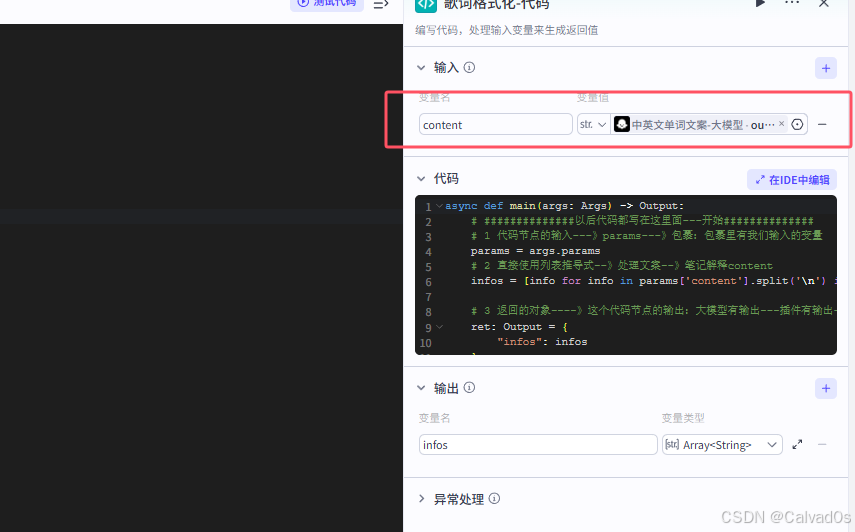
代码
python
async def main(args: Args) -> Output:
# ##############以后代码都写在这里面---开始##############
# 1 代码节点的输入---》params---》包裹:包裹里有我们输入的变量 params['content']
params = args.params
# 2 直接使用列表推导式--》处理文案--》笔记解释content
infos = [info for info in params['content'].split('\n') if info.strip() != '']
# 3 返回的对象----》这个代码节点的输出:大模型有输出---插件有输出--》代码也有输出
ret: Output = {
"infos": infos
}
return ret
# ##############以后代码都写在这里面---结束##############输出
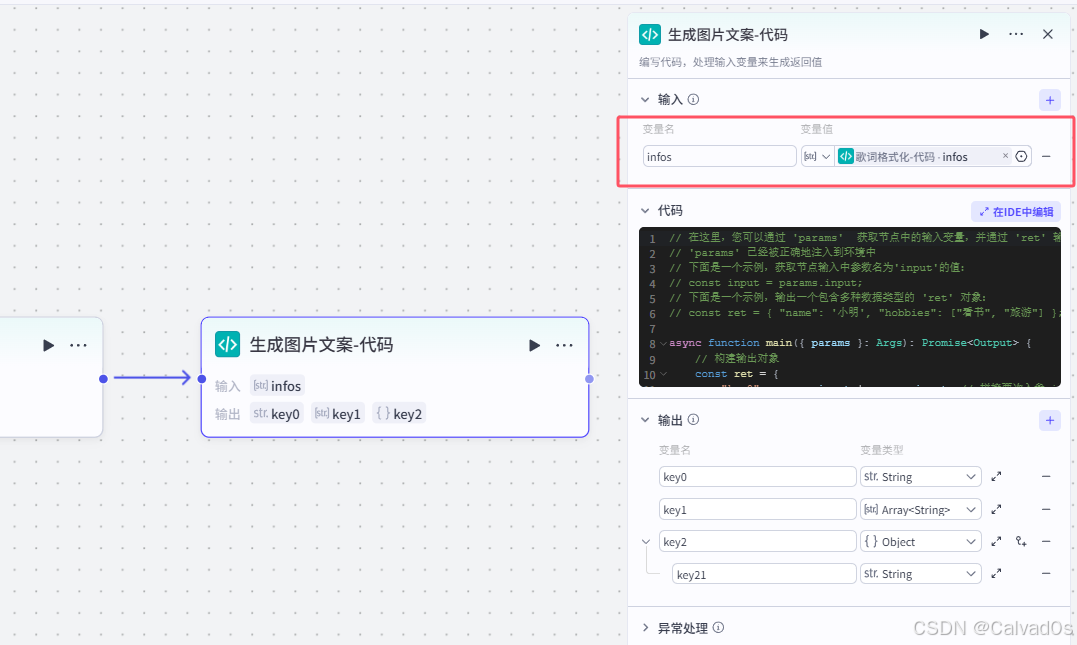
2.5 生成图片文案-代码节点
python
# 1 作用:
# 对上一个节点的歌词进行拆分
["电视 电视 Television",
"Television Television Television",
"冰箱 冰箱 Refrigerator",
"Refrigerator Refrigerator Refrigerator",
。。。。。
]
# 处理成如下
[
"电视",
"冰箱"
]输入
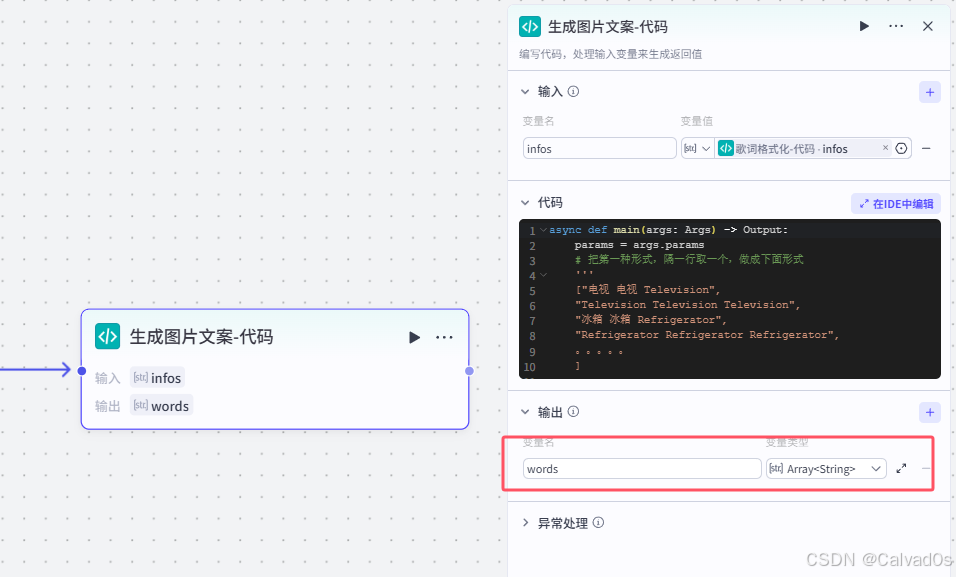
代码
python
async def main(args: Args) -> Output:
params = args.params
# 把第一种形式,隔一行取一个,做成下面形式
'''
["电视 电视 Television",
"Television Television Television",
"冰箱 冰箱 Refrigerator",
"Refrigerator Refrigerator Refrigerator",
。。。。。
]
--------------
[
"电视",
"冰箱"
]
'''
infos=params['infos']
words=[]
for index,info in enumerate(infos):
if index % 2 == 0:
word=info.split(' ')[0]
words.append(word)
# 构建输出对象
ret: Output = {
"words": words
}
return ret输出
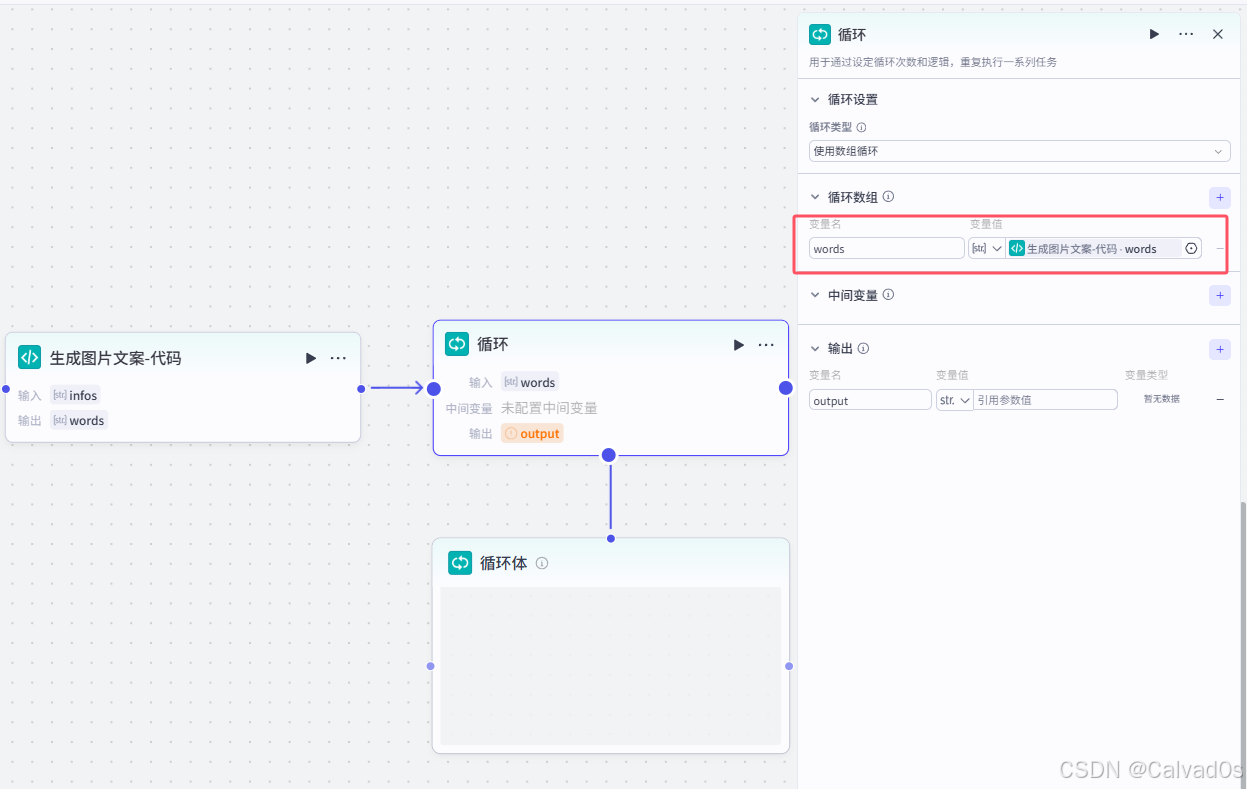
2.6 循环生图文案-循环节点 + 大模型节点
python
# 1 作用--->扩写文案--》通过扩写的文案,生成图片
-根据上一个节点---》返回数据:如下,让大模型循环生成丰富一点的文案
[
"电视",
"冰箱"
。。。
]
-生成:
[
小朋友,再客厅里,开心的看电视,
小朋友,打开冰箱,取出一瓶可乐
]
小朋友,再客厅里,开心的看电视---》图片1
小朋友,打开冰箱,取出一瓶可乐---》图片2
....
# 2 循环节点
-1 使用数组循环---》如下,是同一个东西,叫法不一样
[
"电视",
"冰箱"
。。。
]循环节点
大模型节点
输入
python
# 1 大模型的输入
word-->循环输入的是words:如下--》循环会每次拿出一个--》比如拿出:电视---》交个大模型
[
"电视",
"冰箱"
。。。
]
word--》循环的:item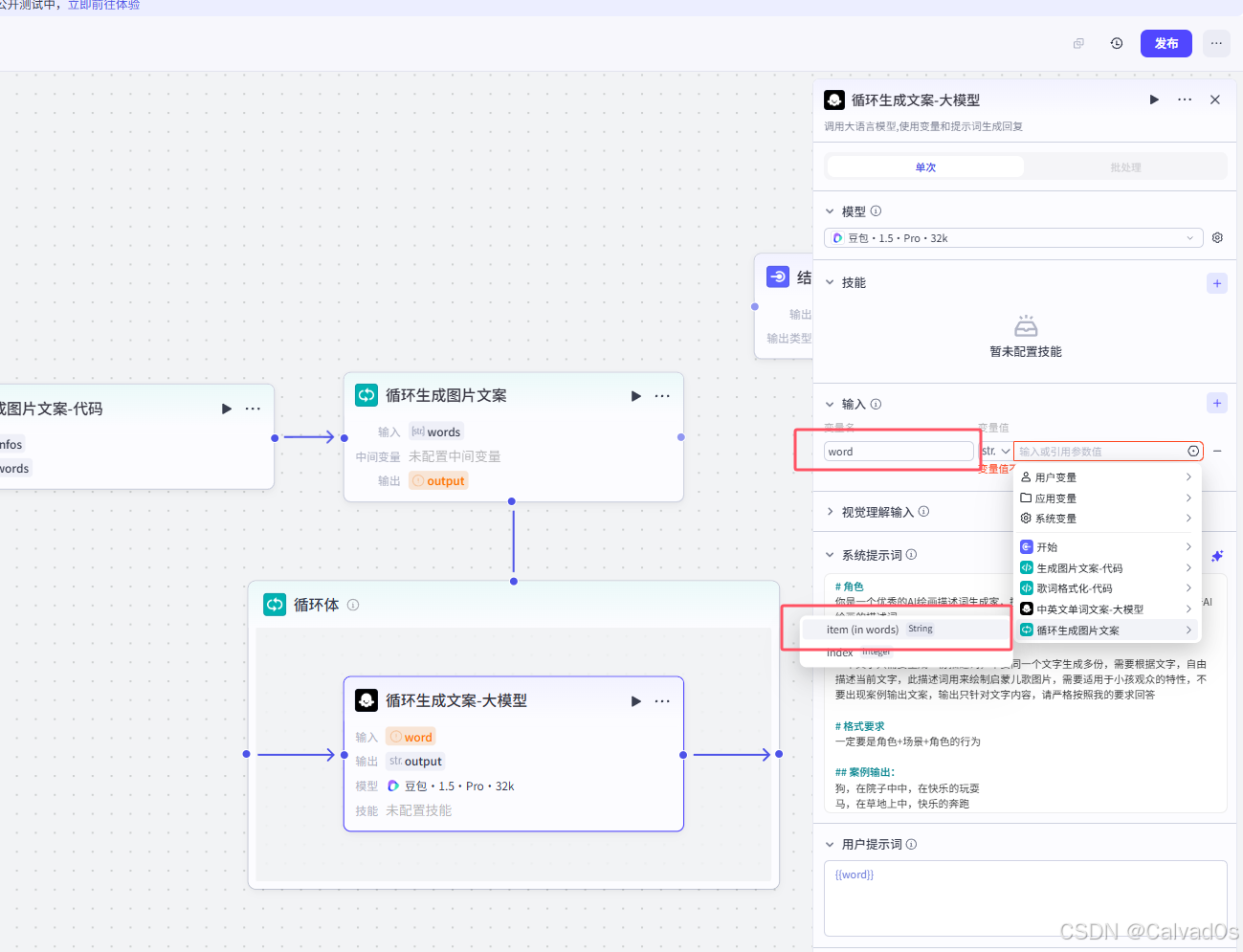
系统提示词
python
# 角色
你是一个优秀的AI绘画描述词生成家,擅长把输入的文字{{word}}生成一份适用于AI绘画的描述词
# 要求
一个文字只需要生成一份描述词,不要同一个文字生成多份,需要根据文字,自由描述当前文字,此描述词用来绘制启蒙儿歌图片,需要适用于小孩观众的特性,不要出现案例输出文案,输出只针对文字内容,请严格按照我的要求回答
# 格式要求
一定要是角色+场景+角色的行为
## 案例输出:
狗,在院子中中,在快乐的玩耍
马,在草地上中,快乐的奔跑用户提示词
python
{{word}}循环节点输出
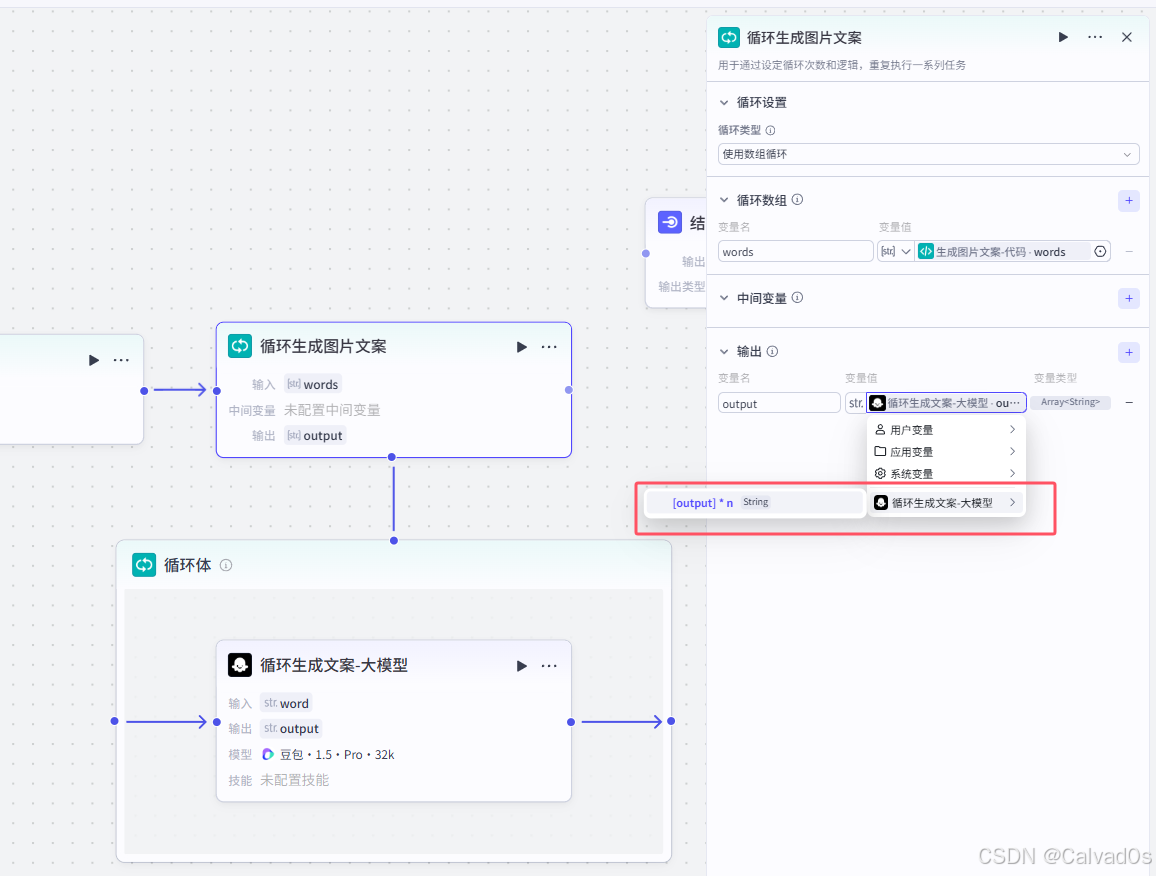
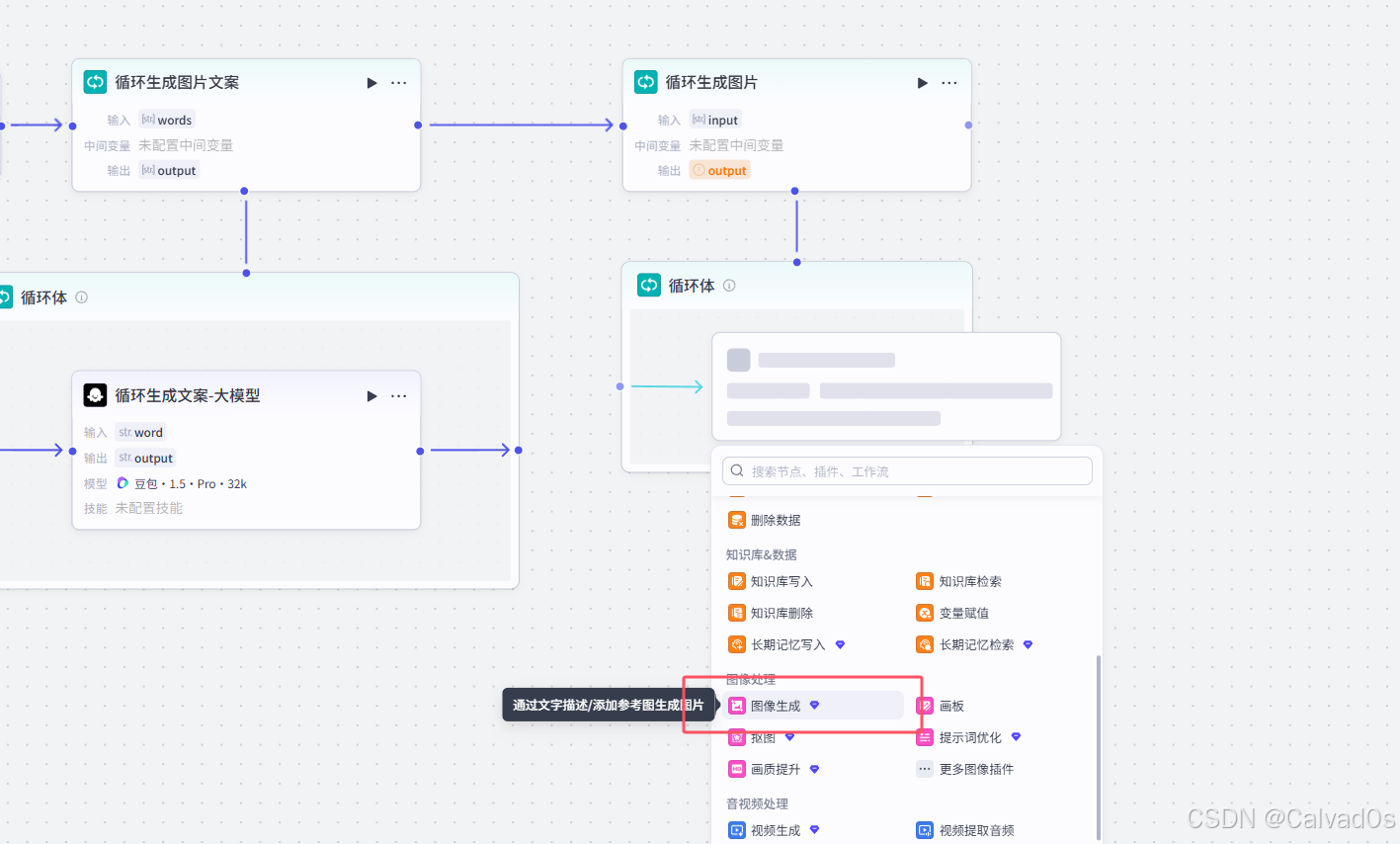
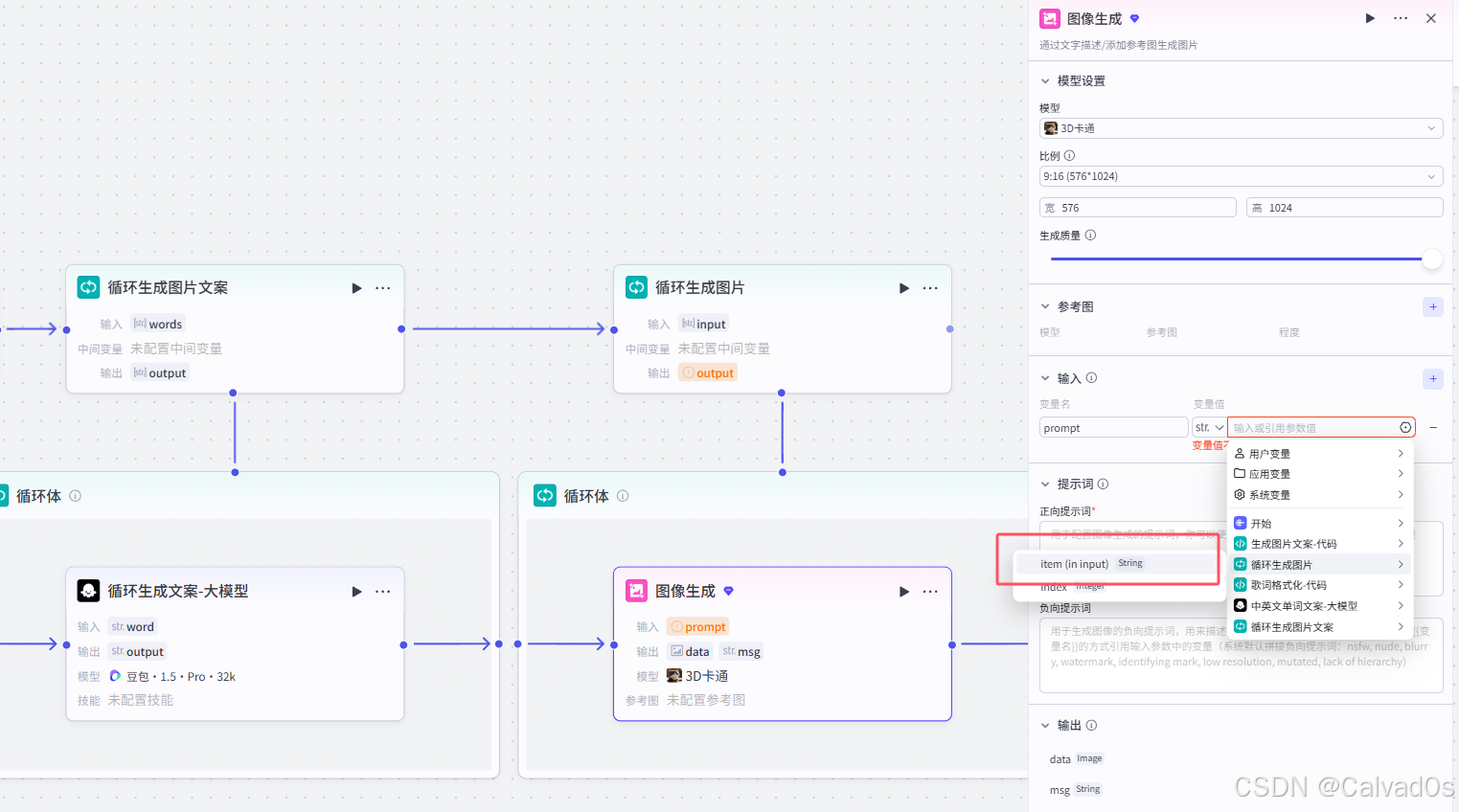
2.7 循环生成图片-循环节点+插件节点
python
# 1 作用
根据上一个循环节点生成的文案---》循环生成图片
[
小朋友,再客厅里,开心的看电视,
小朋友,打开冰箱,取出一瓶可乐
]
生成一张张图片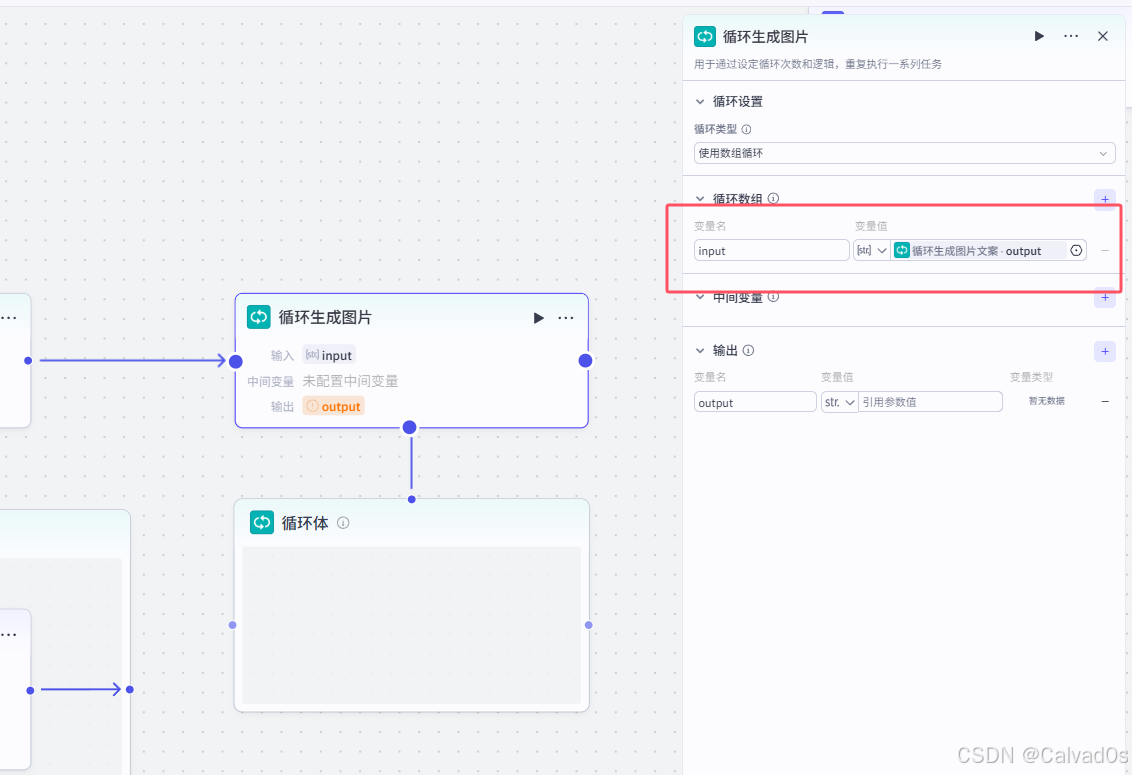
python
# 正向提示词
细腻的细节处理,主体突出, 高光,强光,水灵灵,丰富可爱的微笑表情,背景虚化,8K,高品质,高分辨率,3D效果,3D卡通风格,{{prompt}}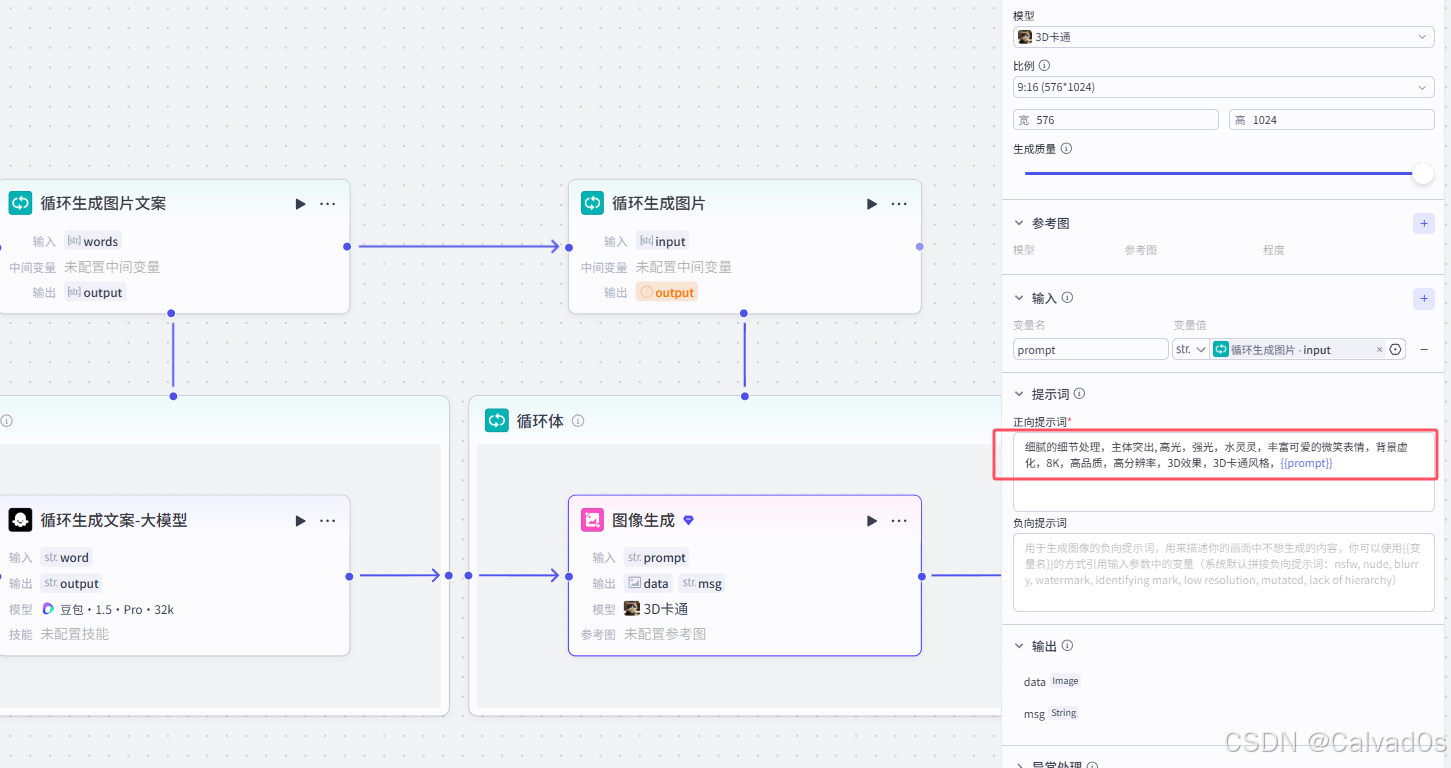
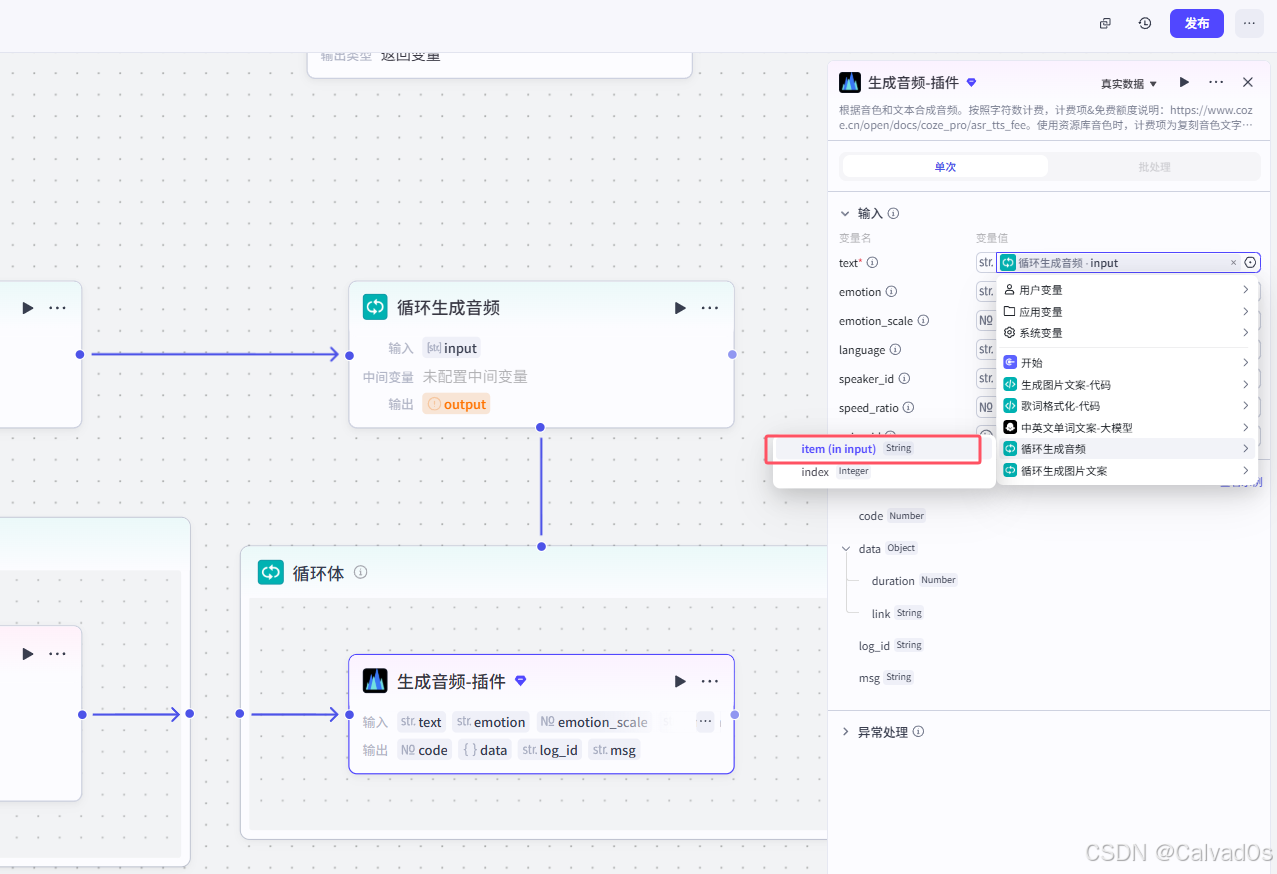
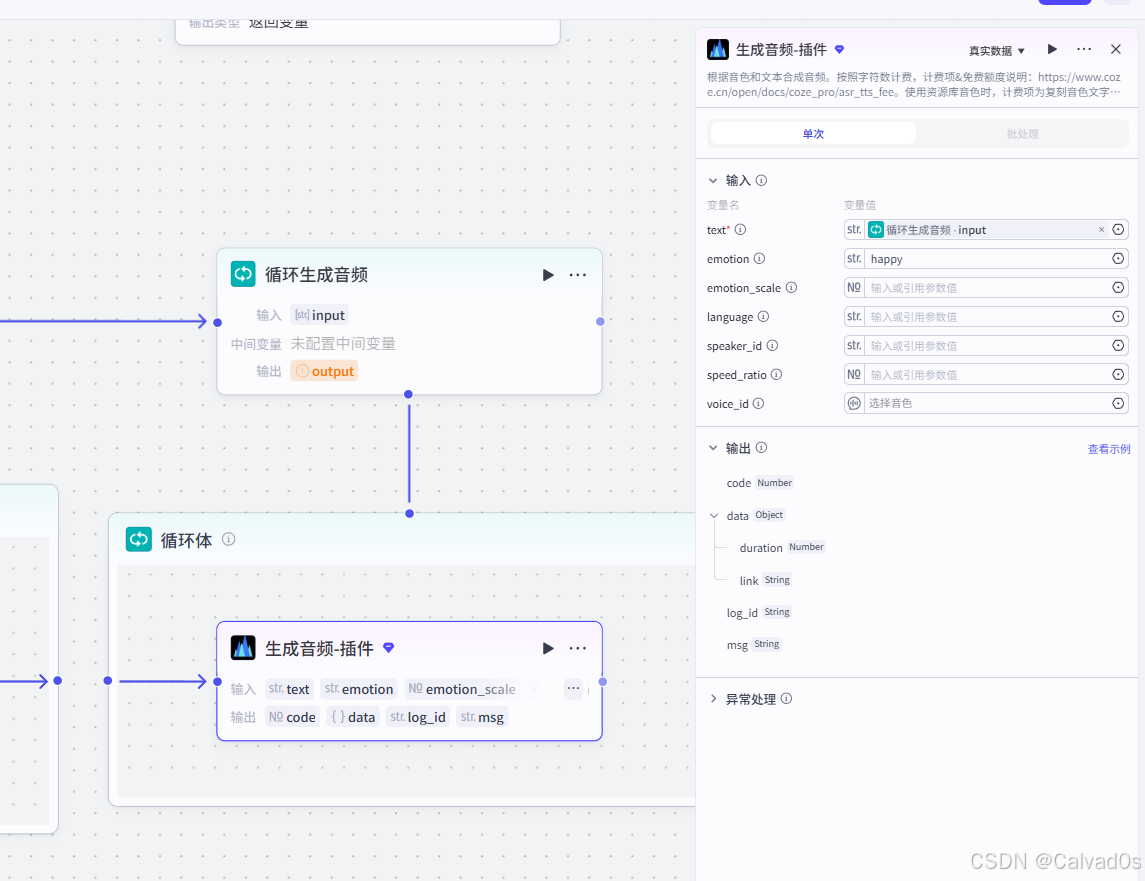
2.8 循环生成音频-循环节点+插件节点
python
# 1 作用--》把中英文文案,转成语音---》取出每个语音的长度[拼成视频]
# 把下面--》转成语音--》每一行一个语音
["电视 电视 Television",
"Television Television Television",
"冰箱 冰箱 Refrigerator",
"Refrigerator Refrigerator Refrigerator",
。。。。。
]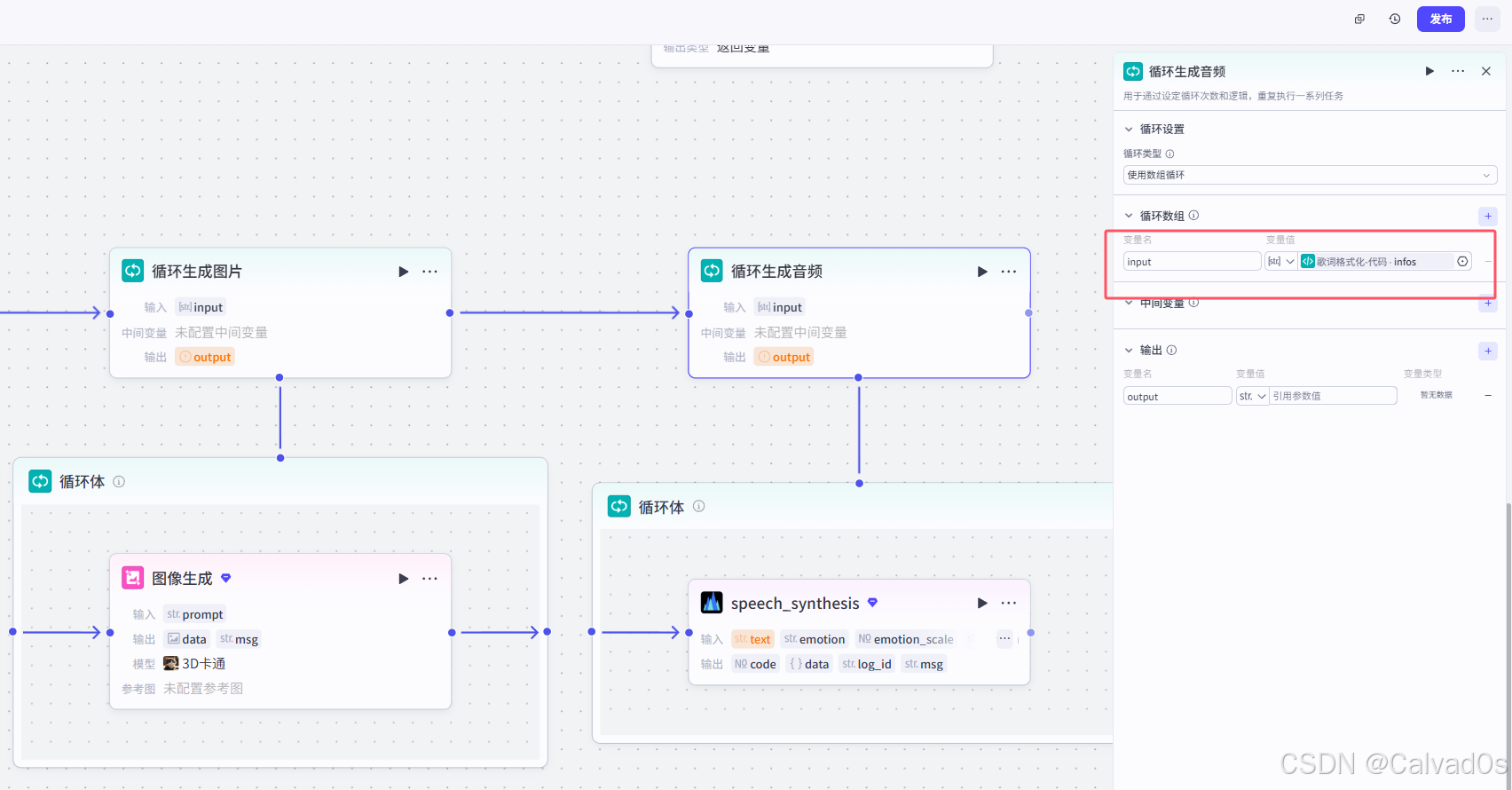
生产音频插件
获取音频时长插件
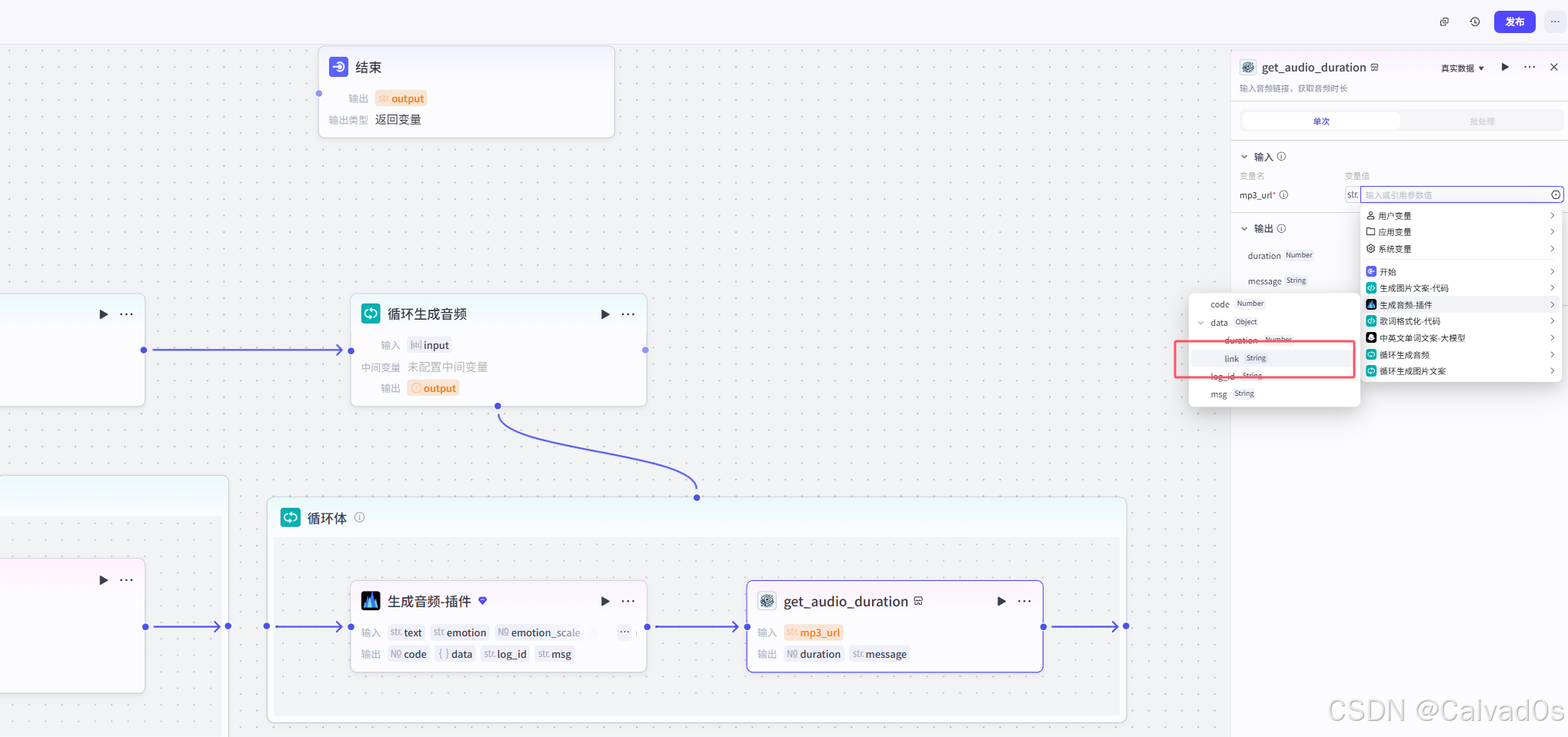
循环生成音频节点输出

2.9 视频创作前-代码节点
python
#1 作用
-剪映小助手--》制作视频--》使用时--》需要很多变量:音频,图片,背景音,动画效果。。。
-使用代码,生成,组装成固定格式---》剪映小助手对格式有要求输入
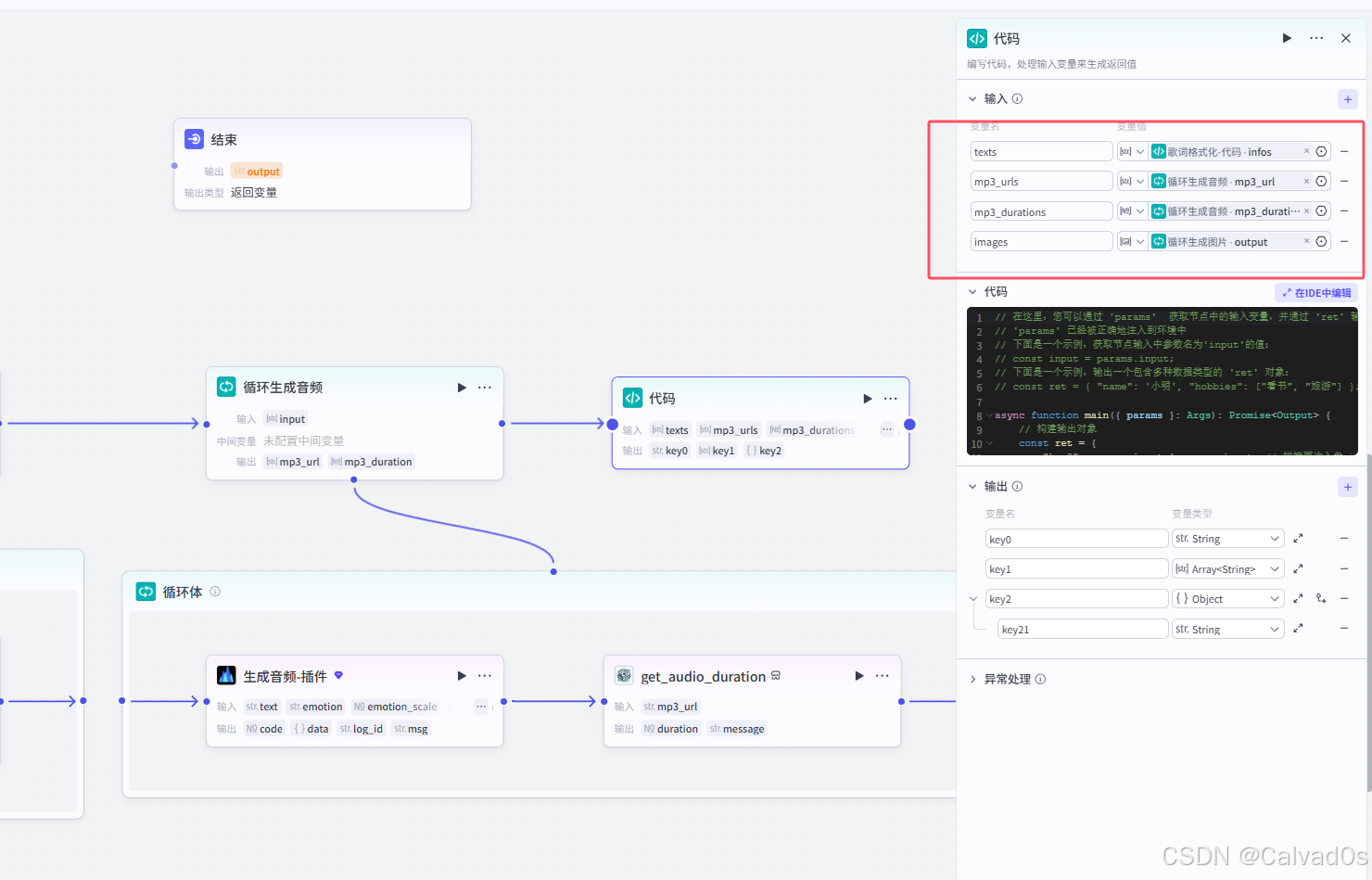
代码
python
import json
async def main(args: Args) -> Output:
params = args.params
audios = []
images = []
texts = []
start = 0
# 1 添加音频和字幕素材
for index,_ in enumerate(params['mp3_urls']):
end=start+ params['mp3_durations'][index] * 1000000
#增加音频
audios.append({ "audio_url": params['mp3_urls'][index], "duration": params['mp3_durations'][index] * 1000000,"volume":10, "start": start, "end": end })
texts.append({ "text": params['texts'][index], "start": start, "end": end, "in_animation": '', "out_animation": '' })
start = end
image_start = 0
# 添加图片素材
for index,_ in enumerate(params['images']):
end = image_start + (params['mp3_durations'][index * 2] + params['mp3_durations'][index * 2 + 1]) * 1000000
images.append({
"image_url": params['images'][index],
"width": 1920,
"height": 1080,
"start": image_start,
"end": end,
"in_animation": "展开", #对应剪映的入场动画名字 可选
"out_animation": "烟雾弹", #对应剪映的出场动画名字。可选
"loop_animation": "", #对应剪映的组合动画名字 可选
"in_animation_duration": 20000, #对应剪映的入场动画时长 可选
"out_animation_duration": 20000 #对应剪映的出场动画时长 可选
})
image_start = end
effect_infos = [{
"effect_title": "金粉闪闪",
"start": 0,
"end": start
}]
bg_mp3 = [
{
"audio_url": " https://ve-template-0920.oss-cn-shanghai.aliyuncs.com/output_video/fewrwer3245467fgg345.mp3",
"duration": start,
"volume":0.5,#音量
"start": 0,
"end": start
}
]
# 构建输出对象
ret: Output = {
'audios': json.dumps(audios),
'images': json.dumps(images),
'texts': json.dumps(texts),
'effect_infos': json.dumps(effect_infos),
'bg_mp3': json.dumps(bg_mp3)
}
return ret输出
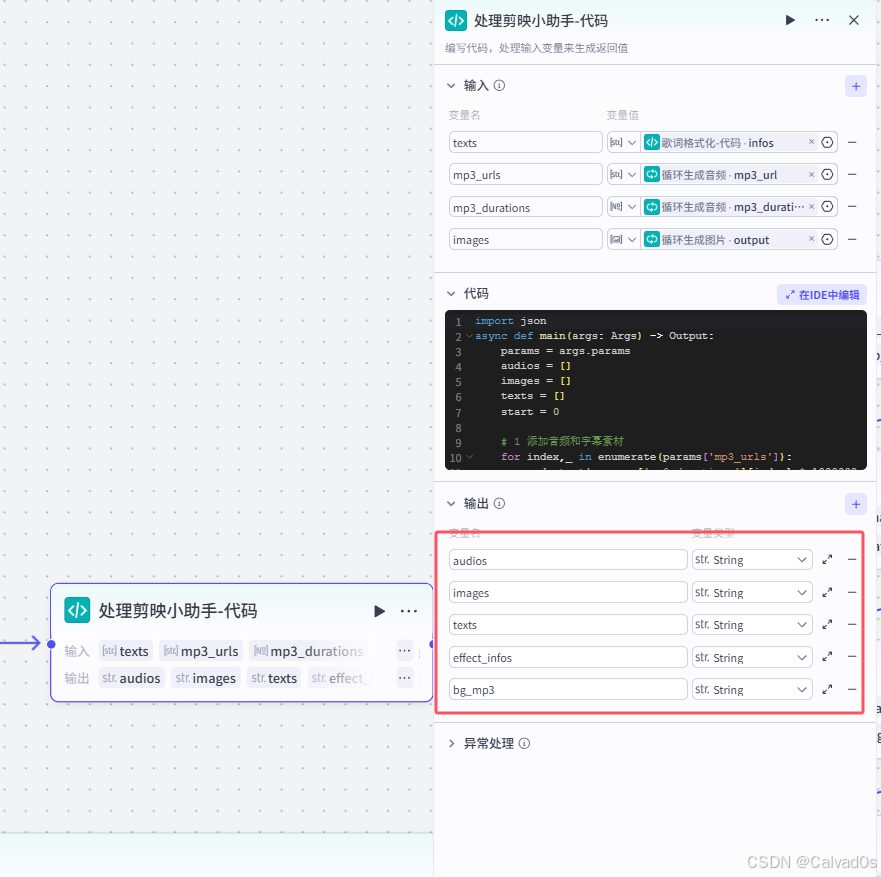
python
# 输出
audios # 音频--》有了
images #视频图片--》生成了
texts # 字幕----》大模型生成了
effect_infos # 特效--》没有
bg_mp3 #背景音--》没有2.10 后续使用剪映小助手--生成视频
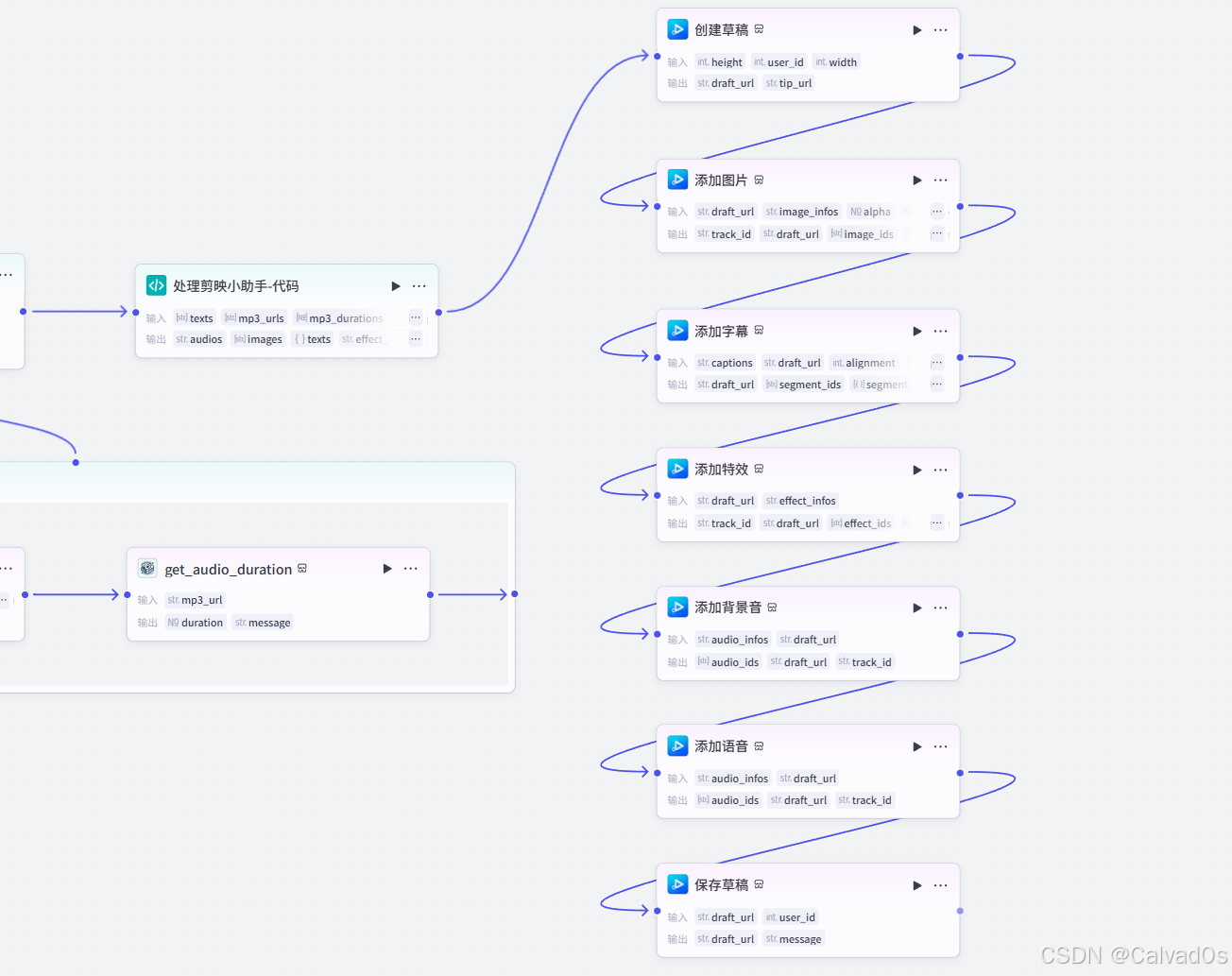
python
# 创建草稿 create_draft
# 添加图片 add_images
# 添加字幕 add_cations
# 添加样式 add_effects
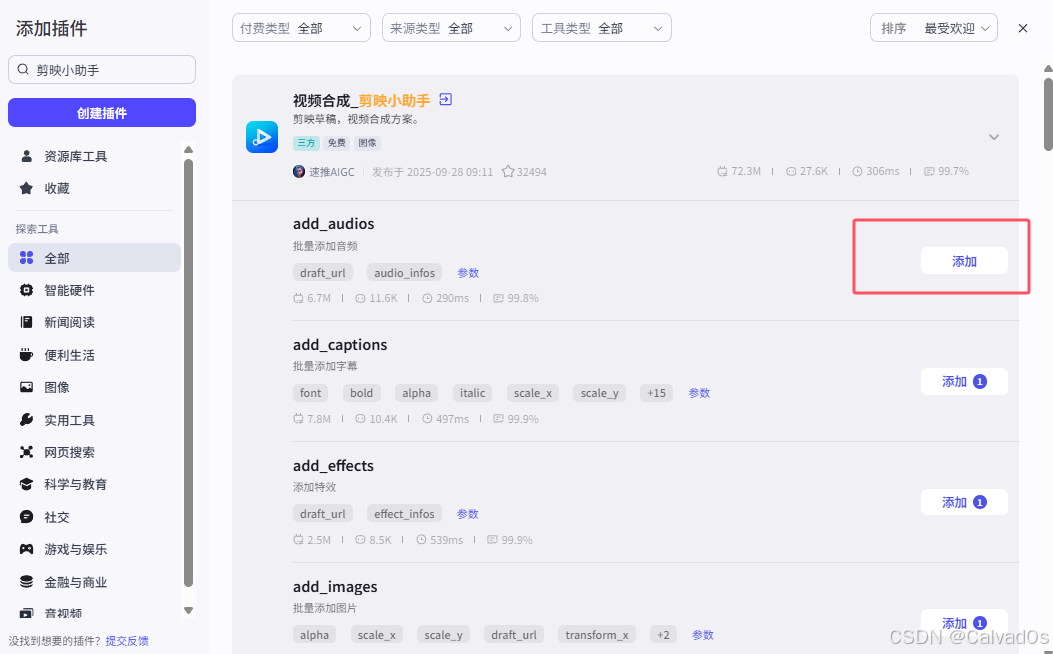
# 添加音频:add_audios 背景音频
# 添加音频:add_audios 字幕音频
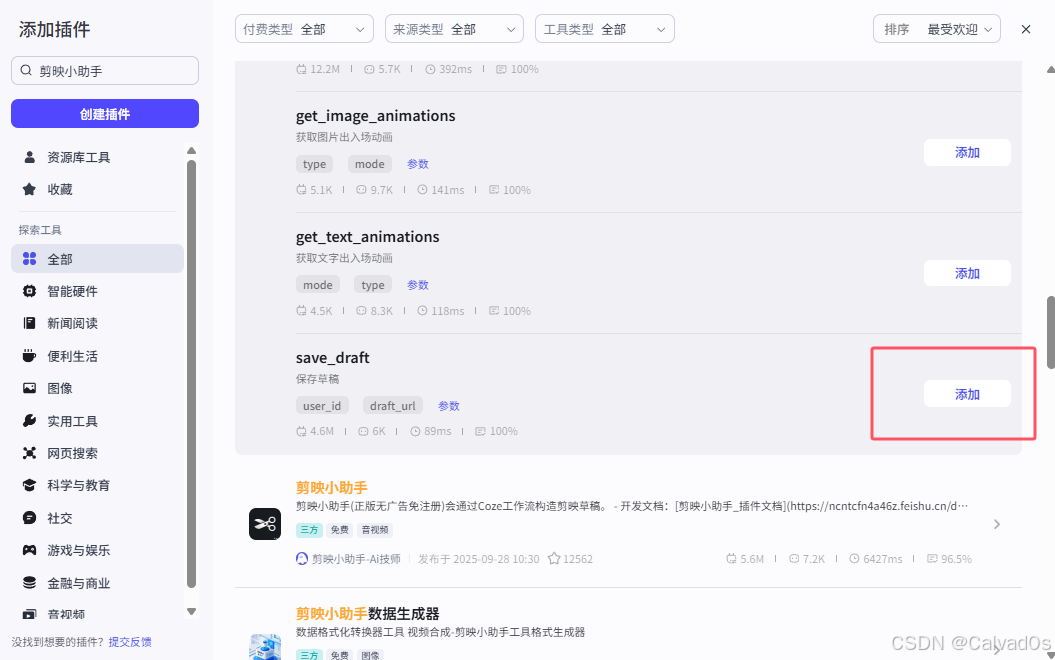
# 保存草稿:save_draft 
创建草稿

添加图片
python
# 输入:
draf_url:草稿地址----draft_url
image_infos:前面代码节点输出的图像信息--》images
alpha:透明度不填
scale_x:1
scale_y:1 --》x,y轴缩放比例 1:1 原始值
scale_x:2
scale_y:2 --》x,y轴缩放比例 2:2 x轴和y轴缩放因子为2,不会改变图形的形状比例,仅按统一比例调整大小
x,y轴不平移
# 输出:
默认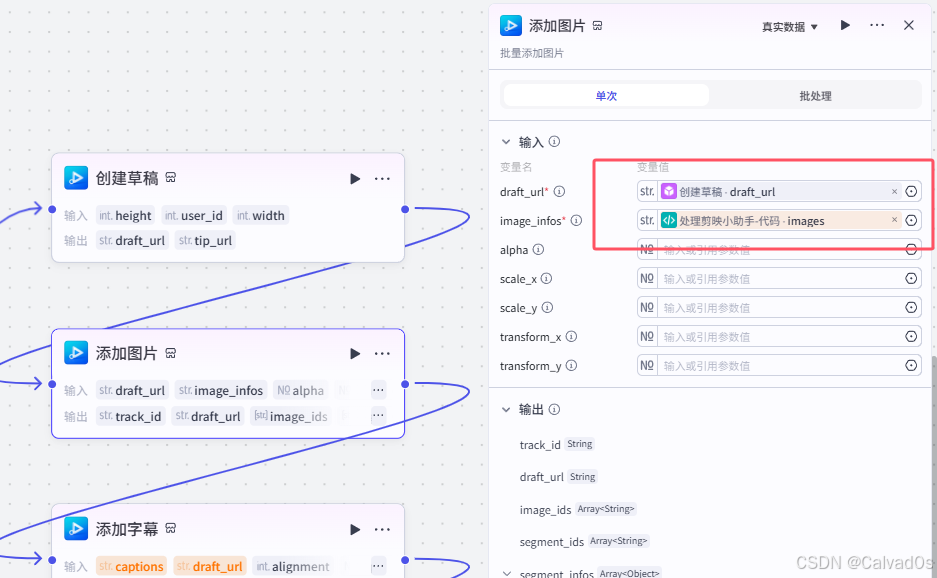
添加字幕
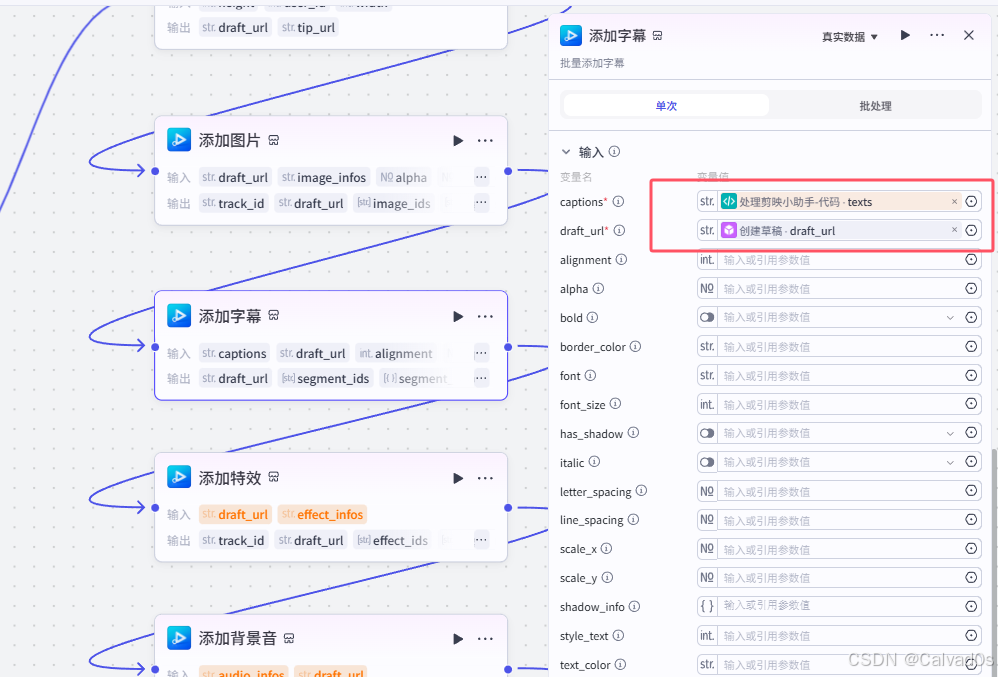
添加特效
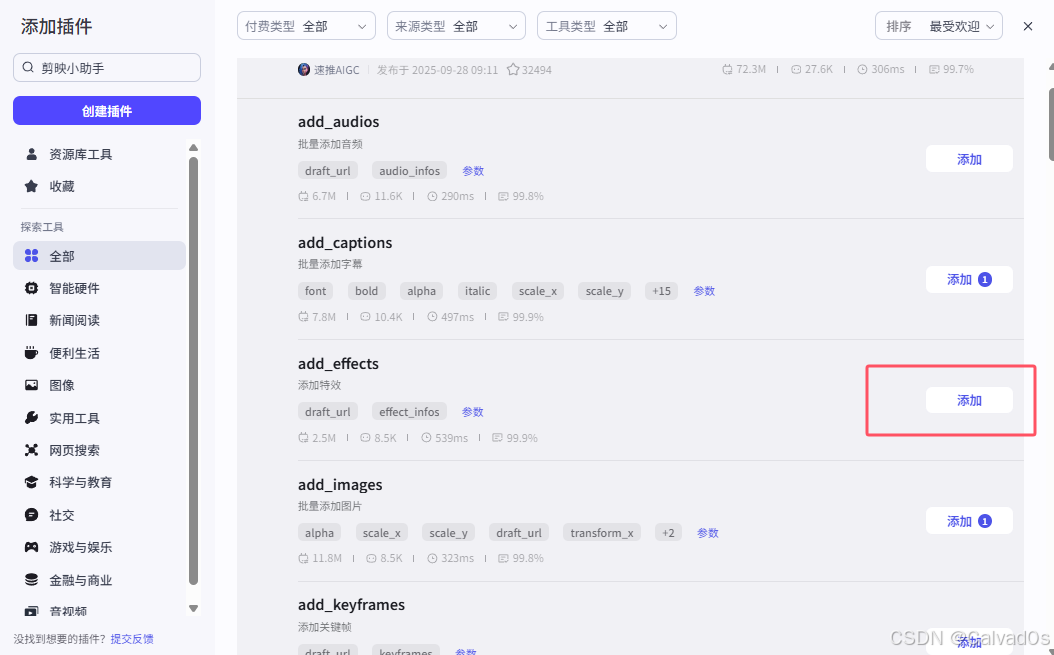
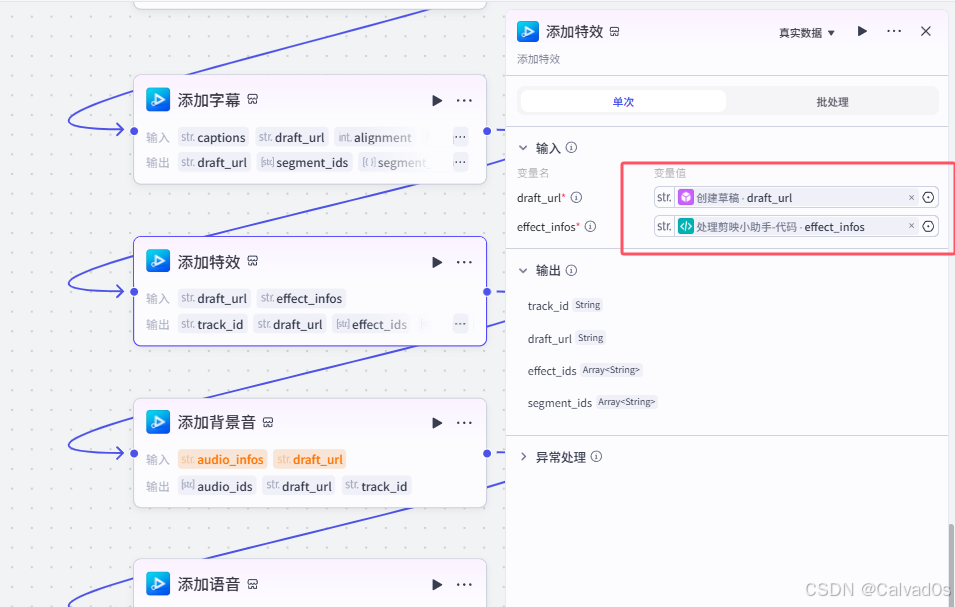
添加背景音
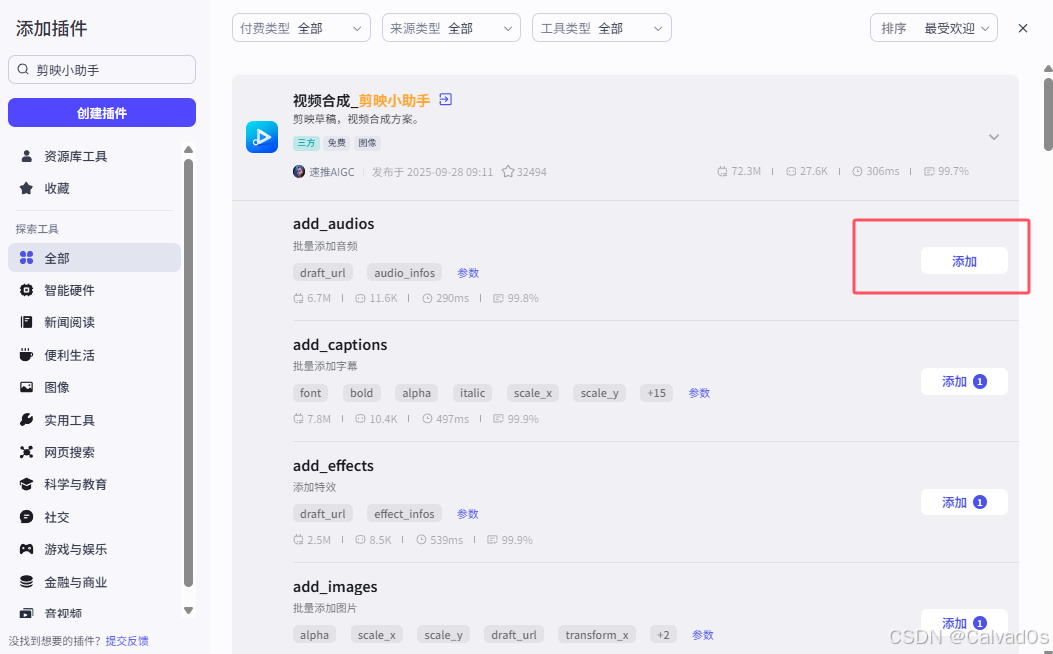
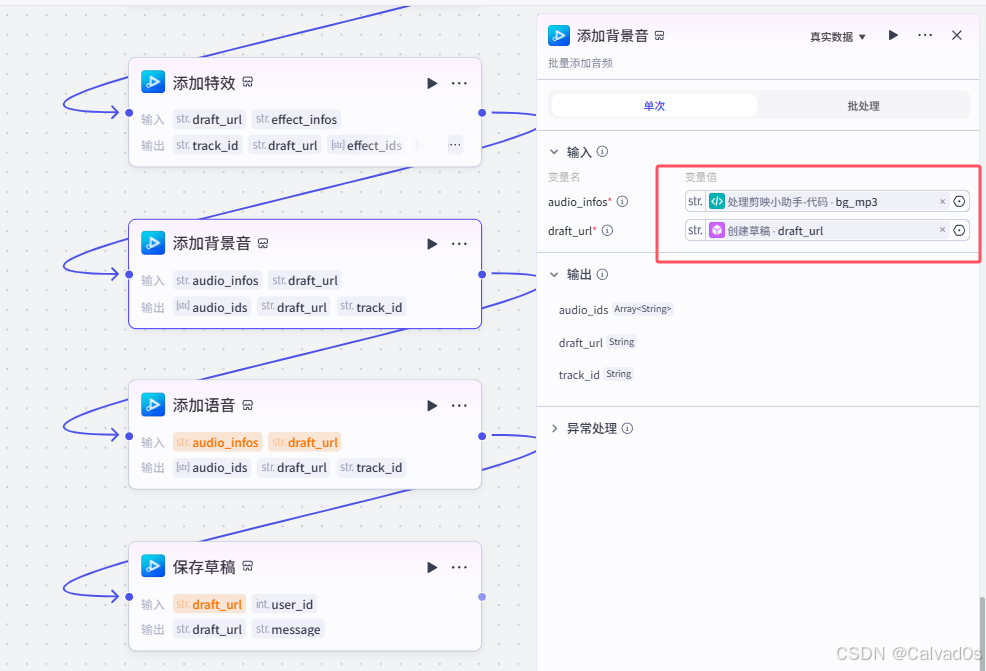
添加语音
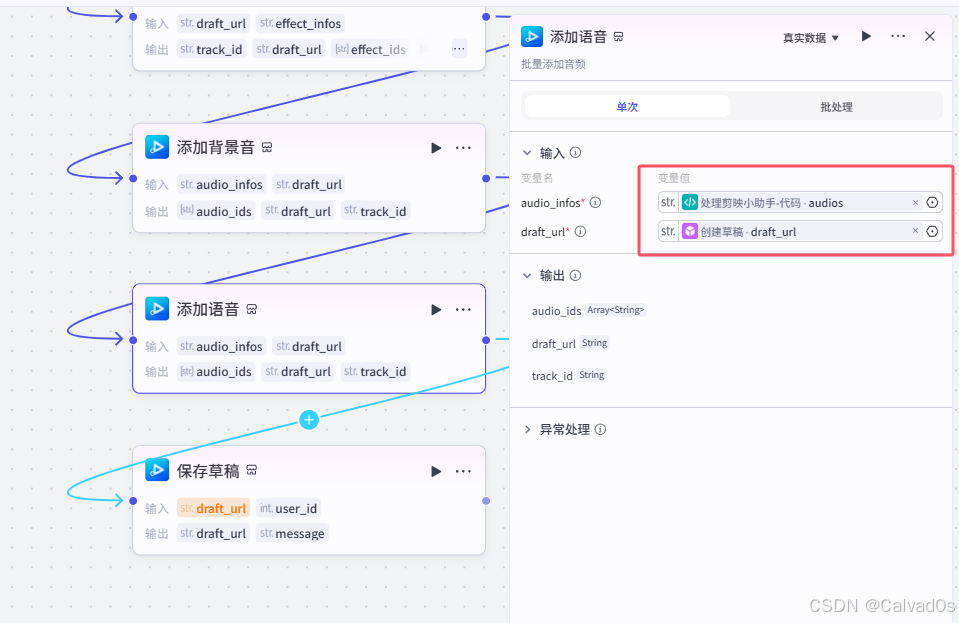
保存草稿
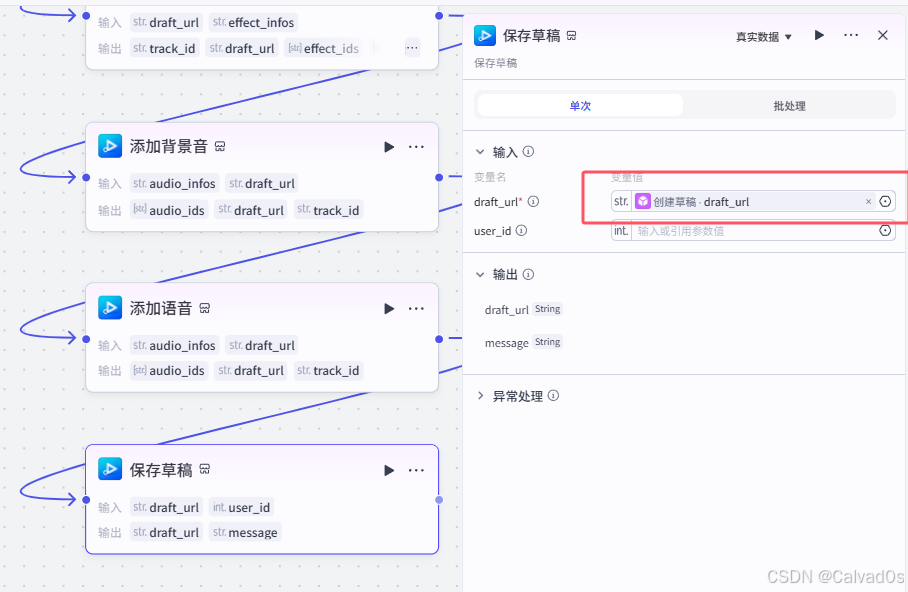
2.11 结束节点