今日总结
- java随征录------kafka集群
- 科研随探录------
- 八股随笔录------MySQL面试篇(5/7)
- 代码随想录------删除二叉搜索树中的节点
详细内容
java随征录
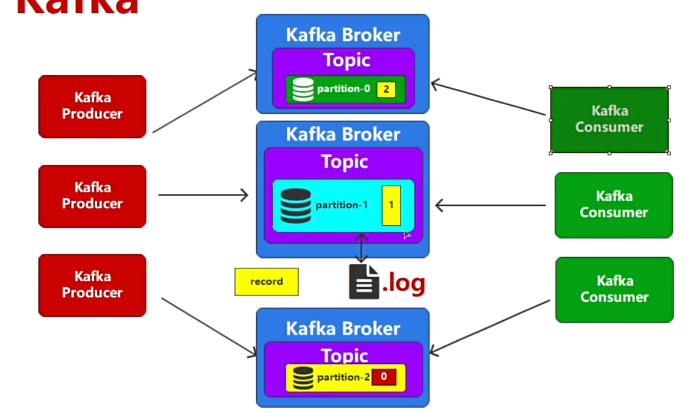
kafka集群
当分区(Partition)越来越多,单节点broker无法供应消息的传递时,可以进行横向和纵向扩展。
横向扩展:部署多个broker 。在kafka集群里,如果都集中在一台服务器上会造成性能瓶颈,此时可以分散部署在多台机器上。
纵向扩展:通过提升单台broker的硬件资源来增加处理能力。
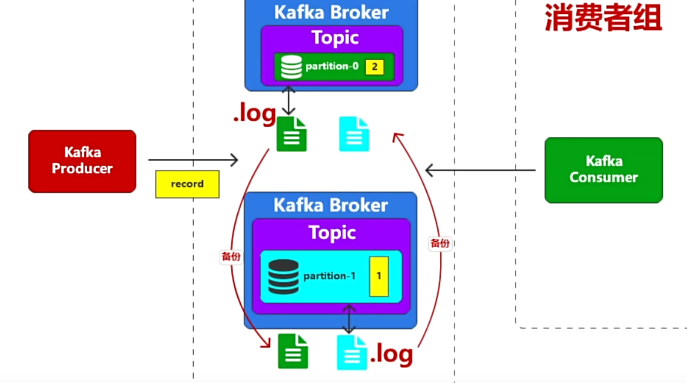
kafka的备份(提高安全可靠性)
当把备份日志文件放到自己的broker时,如果broker宕机,备份文件还是会丢失。因此将备份文件部署到另一台broker上,如下图所示。
为了数据的可靠性,可以将数据文件进行备份,但是Kafka没有备份的概念,Kafka中称之为副本,多个副本其中只能有一个提供数据的读写操作,其他副本只能用于备份,具有读写能力的副本称之为Leader副本,作为备份的副本称之为follower副本。
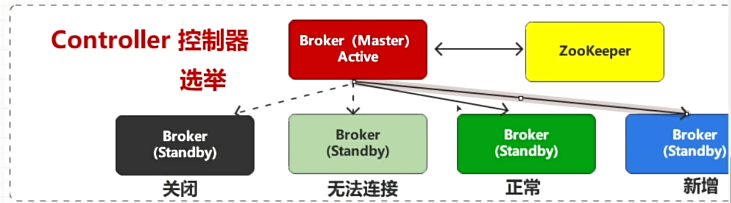
kafka的集群管理
在kafka集群管理中,有一个master主节点,管理各个分支节点。当主节点宕机时,有两种应对策略
- 对主节点broker做备份处理,当主节点宕机后,备份文件临危受命。但存在问题,如果备份节点也宕机了,还要重复操作。
- 利用zookeeper实现选举制,选取主节点管理的其中一个分支节点做主节点。
科研随探录
八股随笔录
- 索引的优缺点
-
索引最大的好处是提高查询速度,但是索引也有一些缺点
-
需要占用物理空间,数量越大,占用空间越大
-
创建索引和维护索引要耗费时间,这种时间随数据量的增大而增大
-
会降低表的正删改的效率,因为每次增删改索引,B+树为了维护索引有序性,需要进行动态维护
- 什么时候适合用索引,什么时候不适合
适合:
- 字段有唯一性限制的,比如商品编码
- 经常用于WHERE查询条件的字段,这样能够提高整个表的查询速度,如何查询条件不是一个,可以使用联合索引
- 经常用于GROUP BY 和RODER BY的字段,这样在查询的时候就不需要再去做一次排序了
不适合:
- WHERE条件,GROUP BY,ORDER BY里用不到的字段,索引的价值是快速定位,不然索引是会占用物理空间的
- 字段中存在大量的重复数据,不需要创建索引,
- 表数据太少的时候,不需要创建索引
- 经常更新的字段不用创建
- Mysql InnoDB引擎通过什么技术来保证事务的四大特性的?
-
持久性是通过redo log(重做日志)来保证的
-
原子性是通过undo log(回滚日志)来保证的
3, 隔离性是通过MVCC(多版本并发控制)或锁机制来保证的
- 一致性是通过持久性+原子性+隔离性来保证的
代码随想录
给定一个二叉搜索树的根节点 root 和一个值 key ,删除二叉搜索树中的 key对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
- 首先找到需要删除的节点;
- 如果找到了,删除它。
示例 :
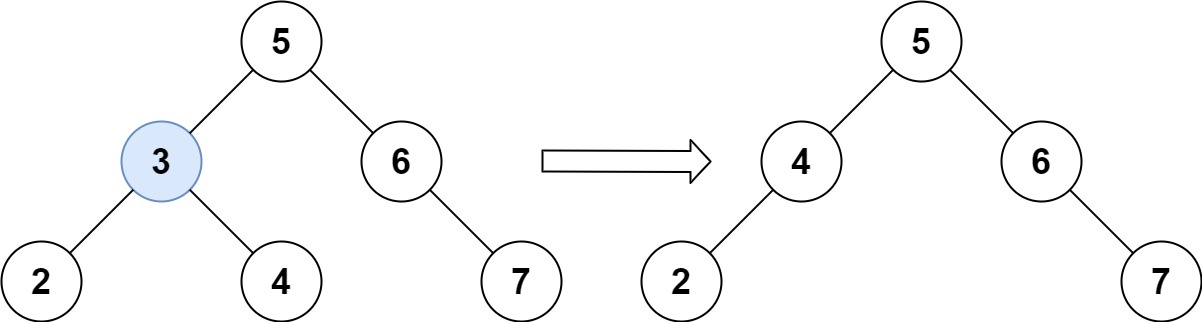
输入:root = [5,3,6,2,4,null,7], key = 3
输出:[5,4,6,2,null,null,7]
解释:给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。
一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。
另一个正确答案是 [5,2,6,null,4,null,7]。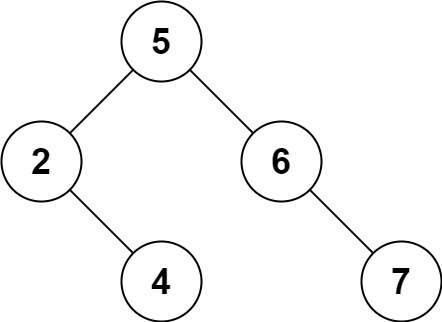
java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
if(root == null) return root;
if(root.val == key) {
if(root.left == null) {
return root.right;
}else if(root.right == null) {
return root.left;
}else{
TreeNode index = root.right;
while(index.left != null) {
index = index.left;
}
index.left = root.left;
root = root.right;
return root;
}
}
if(root.val > key)
root.left = deleteNode(root.left, key);
if(root.val <key)
root.right = deleteNode(root.right, key);
return root;
}
}