目录
一,sed编辑
1,sed编辑概念
sed会在处理数据之前基于预先提供的一组数据来编辑数据流
sed编辑可以根据命令来处理数据流的数据,这些命令要么从命令行中输,要么存储一个文本文件之内
2,sed编辑工作流程
sed的工作流程主要包括读取,执行和显示三个过程:
读取:sed从输入流之内读取一行内容并存储到临时的缓冲区之内
执行:一些状态之内,所有的sed命令都在模式空间之内顺序的执行,除非指定了行的地址,否则临时的sed命令会在所有的行之内依次执行
显示:发送更改后的到输出流。再发送数据后,模式空间将会被整理空
注意:因为所有的sed命令都是在模式空间之内执行的,因此文件本身不会发生变化,除非是用重定向存储输出
3,sed编辑用法
|-------------------|---------------------------------------------|
| 选项 | 意义 |
| -e或--expression | 表使用指定命令处理输入的文本文件,只有一个操作命令时可省略,一般在执行多个操作命令时用 |
| -n,--quiet或silent | 禁止sed编辑输出,但可以与p命令一同完成输出 |
| -i | 直接更改目标文件 |
| -r | 支持正则表达式 |
|----|---------------------------------|
| 操作 | 意义 |
| s | 替换指定字符 |
| d | 删除选定的行 |
| a | 在当下行下面增加一行 |
| i | 在当下行上面插一行 |
| c | 将选定行替换为指定行 |
| y | 字符替换,转换时字符长度必须相同 |
| p | 打印指定行,或所有行,或以ASCII码输出,通常结合- n选项 |
| = | 打印行号 |
| l | 打印数据流之内的文本和不可打印的ASCII字符 |
(1),
bash
sed -n -e "p;=" 3.txt
#带行号输出3.txt之内的所有字符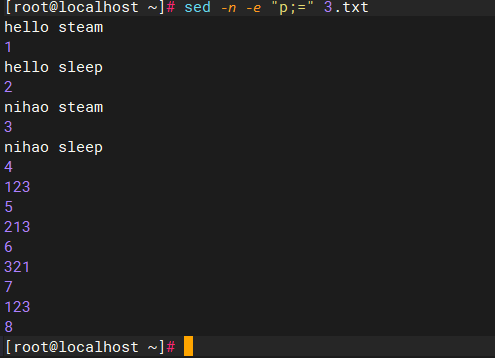
(2),
bash
sed -n "n;p;=" 3.txt
#带行号输出3.txt之内的偶数行的所有字符 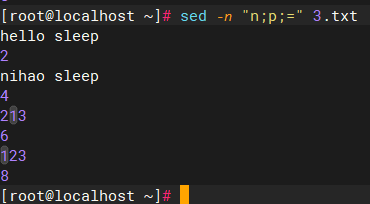
(3),
bash
sed -n "/123\|steam/p" 3.txt
#只输出3.txt之内的带有steam或123的行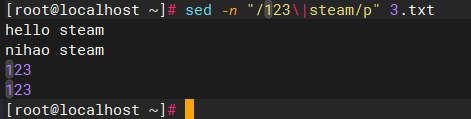
(4),
bash
sed -n "/123\|steam/d" 3.txt
#输出3.txt之内删除包含123或steam的行 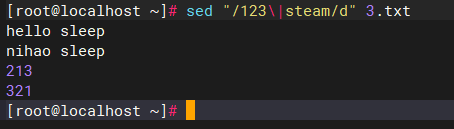
(5),
bash
sed "1,8 s/^/#/" 3.txt
#为3.txt之内的1至8行增添注释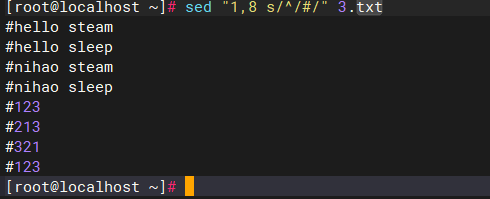
二,awk编辑
1,概念
sed命令常用于一整行的整理,而awk常将一行分为多个"字段"再进行处理。
2,工作原理
逐行读取文本,以空格或tab键为分隔符进行分隔,将分隔所得的各字段保存在内建变量之内,并按模式或条件执行编辑命令
3,用法
|----------|------------------------|
| 内建变量 | 意义 |
| FS | 列分隔符 |
| NF | 当下处理行的字段个数,NF表示最后一个字段 |
| NR | 当下处理的行的行号 |
| 0 | 当下处理的行的整行内容 |
| $n | 当下处理的行的第n个字段 |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符 |
(6),
bash
awk '{print}' 3.txt
#输出3.txt之内的所有字符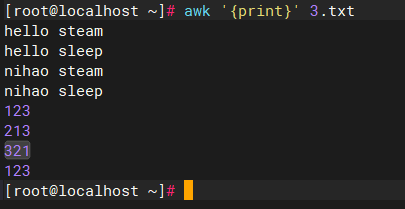
(8),
bash
awk '(NR>=1) && (NR<=8){print}' 3.txt
#输出3.txt之内的第1行到第8行之内的所有字符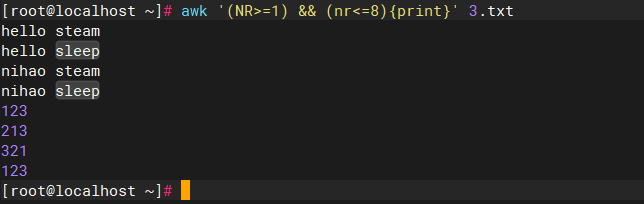
(9),
bash
awk '(NR%2)==0{print}' 3.txt
#输出3.txt之内的偶数行
awk '(NR%2)==1{print}' 3.txt
#输出3.txt之内的奇数行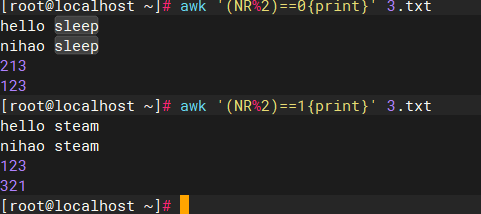
(10),
bash
awk '/^hello/{print}' 3.txt
#输出3.txt之内的开头为hello的所有行
awk '/steam$/{print}' 3.txt
#输出3.txt之内的结尾为steam的所有行 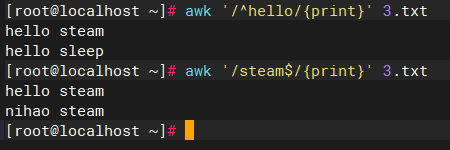
BEGIN模式表示,在处理文本之前,需要先执行BEGIN模式之内指定的动作;awk再处理指定的文本,之后再执行END模式之内指定的动作,END{}语句块之内,常与打印结果合用
(11),
bash
awk 'BEGIN{x=0}"/steam$/"{x++}{print x+2}' 3.txt
#输出3.txt之内的结尾为steam的行,每次匹配每次赋值1给x,结尾再加2 
打赏链接:
