一、BERT是什么
BERT(Bidirectional Encoder Representations from Transformers)是谷歌在2018年发布的自然语言处理模型,它彻底改变了NLP领域的发展轨迹。在BERT出现之前,主流模型如Word2Vec只能提供静态的词向量表示,这些方法虽然解决了词汇的分布式表示问题,但无法处理一词多义和复杂的上下文信息。例如,"苹果"这个词在不同语境中既可能指水果,也可能指科技公司,传统模型无法区分这种差异。
BERT的创新在于采用了"预训练-微调"的范式。首先在大规模无标注文本上进行预训练,学习通用的语言表示,然后在特定任务上用少量标注数据进行微调。这种范式首先在无标注的大规模文本数据上进行预训练,学习通用的语言表示,然后通过少量的标注数据对特定任务进行微调。这种方法大大降低了NLP应用的门槛,使得即使是资源有限的研究团队也能利用预训练模型取得出色的效果。BERT的成功不仅体现在技术指标上,更在于它为整个NLP领域指明了发展方向,催生了后续一系列重要模型的诞生,如RoBERTa和ALBERT以及DeBERTa等,真正开启了预训练语言模型的新时代。

二、BERT的核心机制
1. 基础介绍
BERT基于Transformer的编码器架构,采用多层自注意力机制实现深度双向编码,这一设计选择体现了对语言理解任务的深刻洞察。具体来说:
模型结构配置:
- **基础版BERT-Base:**12层Transformer块,768维隐藏层,12个注意力头,1.1亿参数
- **大型版BERT-Large:**24层Transformer块,1024维隐藏层,16个注意力头,3.4亿参数
自注意力机制:
通过计算查询(Query)、键(Key)、值(Value)三个矩阵,建立词与词之间的全局依赖关系。公式表示为:Attention(Q,K,V) = softmax(QK^T/√d_k)V,其中d_k是键向量的维度。这种机制使模型能够同时关注序列中的所有位置,捕获长距离依赖关系。
这种分层结构使得模型能够从不同抽象层次理解语言,底层捕捉语法和局部语义,高层捕获更复杂的语义关系。
**输入表示:**BERT的输入是一个经过精心设计的序列,用于融合多种信息:
- CLS: 位于序列首位的特殊分类标记,其最终的隐藏状态常被用作整个序列的聚合表示,用于分类任务。
- Token Embeddings: 词本身的嵌入向量。
- Segment Embeddings: 用于区分两个句子(例如,在问答任务中区分问题和段落)。句子A和句子B对应不同的segment嵌入。
- Position Embeddings: Transformer本身不具备序列顺序信息,因此需要加入位置编码来告知模型每个词的位置。
- **最终输入是这三者之和:**Input = Token + Segment + Position
输入表示流程:
bash
输入文本: [CLS] 我 喜欢 自然 语言 处理 [SEP]
输入表示(简化):
[CLS] 我 喜欢 自然 语言 处理 [SEP]
(每个token转换为向量,加上段嵌入和位置嵌入)
BERT模型:
┌───────────────────────────────────────────────────────────────┐
│ Transformer编码器 (多层) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 自注意力机制 │ │ 前馈神经网络 │ ... │ 层归一化 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└───────────────────────────────────────────────────────────────┘
输出:
每个输入token对应的上下文向量(相同维度):
[CLS]向量 我的向量 喜欢的向量 自然的向量 语言的向量 处理的向量 [SEP]向量
Token Embeddings: E[CLS], E_我, E_喜欢, E_自然, E_语言, E_处理, E[SEP]
Segment Embeddings: 0, 0, 0, 0, 0, 0, 0
Position Embeddings: P0, P1, P2, P3, P4, P5, P6
最终输入向量 = E[CLS]+0+P0, E_我+0+P1, E_喜欢+0+P2, E_自然+0+P3, E_语言+0+P4, E_处理+0+P5, E[SEP]+0+P62. 完整的输入输出流程图
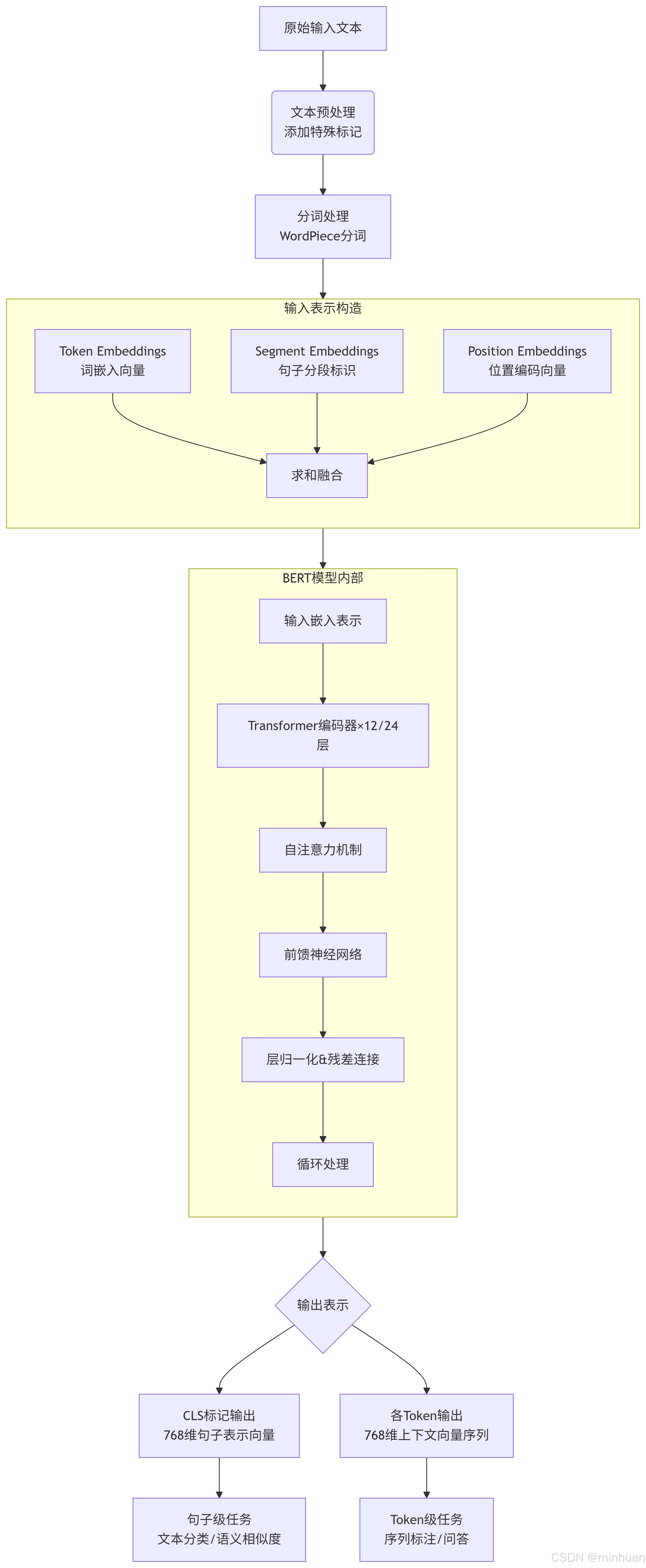
3. BERT输入输出示意图详解
3.1 输入处理流程
3.1.1 原始文本输入
- BERT接收文本序列作为输入,例如:"自然语言处理很有趣"
3.1.2 添加特殊标记
- 在开头添加CLS标记:用于句子级别的分类任务
- 在结尾添加SEP标记:用于分隔句子
- 处理后:"CLS 自然语言处理很有趣 SEP"
3.1.3 分词处理
- 使用WordPiece分词器将文本分解为子词单元:
- 输入:"CLS 自然语言处理很有趣 SEP"
- 分词结果:"\[CLS", "自然", "语言", "处理", "很", "有趣", "SEP"]
3.1.4. 创建输入表示
BERT的输入由三种嵌入向量求和而成:
- Token Embeddings(词嵌入)
- 将每个token映射为768维向量
- 例如:"自然" → 0.12, -0.45, 0.78, ..., 0.33(768维)
- Segment Embeddings(句子分段嵌入)
- 区分不同句子的标识(0表示第一句,1表示第二句)
- 单句任务:所有token分配0
- 句子对任务:第一句token为0,第二句token为1
- Position Embeddings(位置嵌入)
- 表示每个token在序列中的位置信息
- 使用学习式的位置编码,支持最大512个token
最终输入向量 = Token Embedding + Segment Embedding + Position Embedding
3.2 BERT模型处理
3.2.1 Transformer编码器结构
BERT由多个Transformer编码器层堆叠而成:
- BERT-Base:12层
- BERT-Large:24层
每层包含:
- 自注意力机制:计算每个token与序列中所有其他token的关联权重
- 前馈神经网络:对注意力输出进行非线性变换
- 残差连接与层归一化:确保训练稳定性和梯度流动
3.2.2 处理过程
- 输入向量序列依次通过各层Transformer编码器
- 每层都会更新每个token的表示,融入更多上下文信息
- 经过所有层处理后,得到最终的输出表示
3.3 输出表示
3.3.1 CLS标记输出
- 位置:序列第一个位置的输出向量
- 维度:768维浮点数向量
- 特点:包含整个序列的聚合信息
- 用途:句子级任务(文本分类、语义相似度计算)
3.2.2 各Token输出
- 每个输入token对应一个768维输出向量
- 特点:包含丰富的上下文信息
- 用途:token级任务(命名实体识别、问答系统)
三、预训练过程
BERT通过两个预训练任务学习语言理解:
1. 掩码语言模型(MLM)
随机遮盖输入序列中15%的token,其中:
- 80%替换为MASK标记
- 10%替换为随机token
- 10%保持原样
模型的任务是预测这些被遮盖的原始词汇,这使得模型必须利用来自左右两侧的上下文信息进行预测,从而学会深层的双向表示。这种设计迫使模型利用双向上下文进行预测,同时避免预训练与微调阶段的不匹配。
2. 下一句预测(NSP)
- 模型接收两个句子作为输入(A和B),并预测句子B是否是句子A的下一句。
- 这帮助模型理解句子间的逻辑关系,对于问答、自然语言推理等需要理解两个文本段之间关系的任务至关重要。
- 训练数据中50%使用连续句子对(正样本),50%使用随机句子对(负样本)。
四、下游任务适配
1. 文本分类任务:
使用CLS标记的最终隐藏状态作为整个序列的表示,添加一个简单的线性分类层。例如情感分析中,将CLS向量输入softmax分类器,输出积极/消极情感概率。
2. 序列标注任务:
使用每个token对应的输出向量进行独立分类。采用BIO或BILOU标注方案,如:
- B-PER: 人名的开始
- I-PER: 人名的中间部分
- B-LOC: 地名的开始
- I-LOC: 地名的中间部分
- B-ORG: 组织机构的开始
- I-ORG: 组织机构的中间部分
- O: 非实体
3. 问答任务:
将问题和段落拼接输入模型,添加两个线性分类器分别预测答案开始和结束位置。损失函数为开始位置和结束位置交叉熵损失的和。
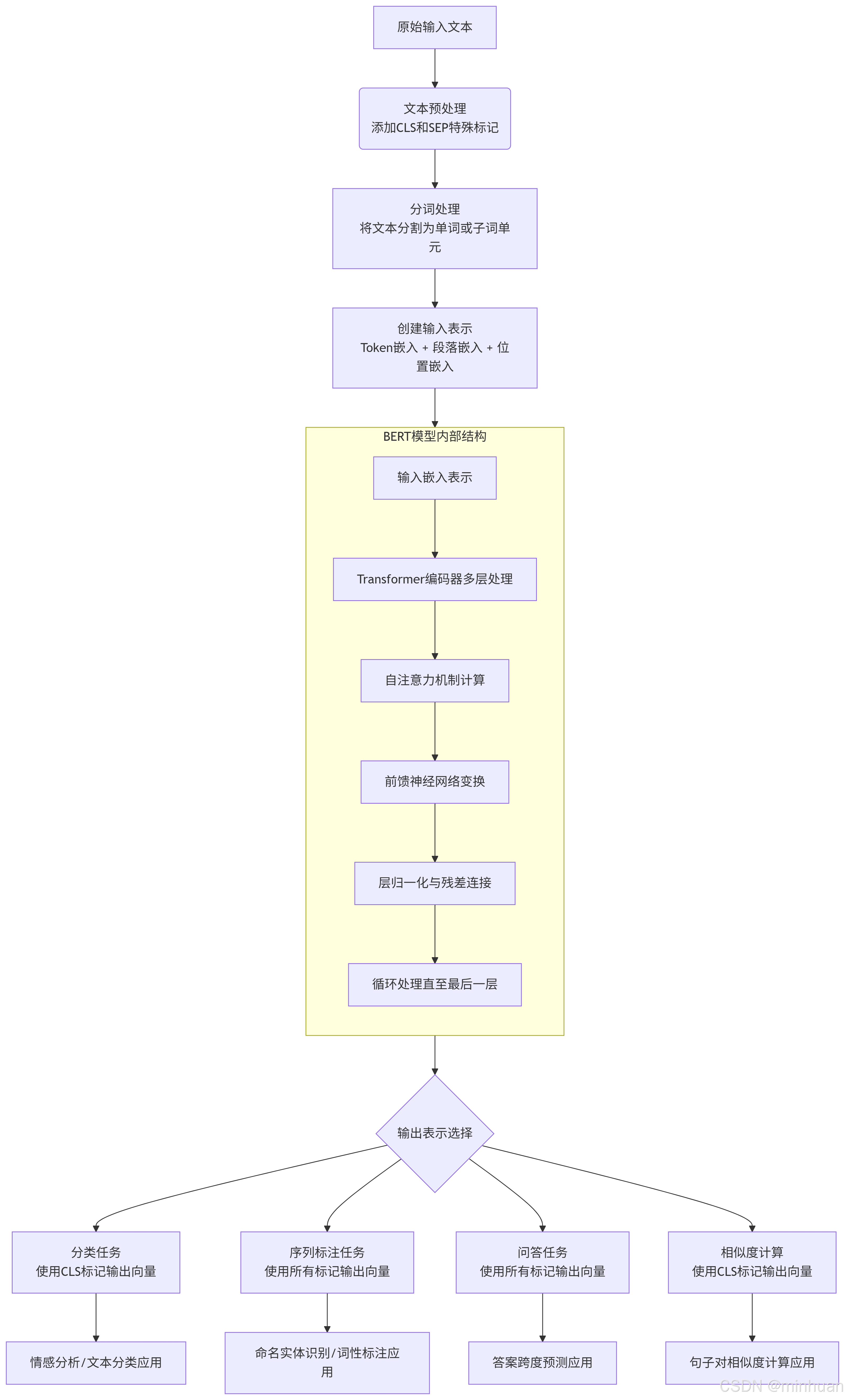
五、BERT流程图与应用实例
1. 整体流程图
2. 示例一:情感分析
2.1 代码示例
python
import requests
import json
import numpy as np
import os
# 配置Qwen API
API_KEY = os.environ.get("DASHSCOPE_API_KEY") # 请替换为您的实际API密钥
API_URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 示例输入文本
input_text = "北京的天气真好,阳光明媚,我们决定去故宫参观。"
print("="*50)
print("BERT情感分析示例")
print("="*50)
print(f"输入文本: {input_text}\n")
# 1. 文本预处理:添加CLS和SEP标记
print("1. 文本预处理:添加特殊标记")
processed_text = "[CLS] " + input_text + " [SEP]"
print(f"处理后: {processed_text}\n")
# 2. Tokenization:将文本分割为单词/子词
print("2. Tokenization:文本分词")
# 这里简化处理,实际BERT使用WordPiece分词
tokens = ["[CLS]", "北京", "的", "天气", "真", "好", ",", "阳光", "明媚", ",", "我们", "决定", "去", "故宫", "参观", "。", "[SEP]"]
print(f"分词结果: {tokens}\n")
# 3. 创建输入表示:Token + Segment + Position Embeddings
print("3. 创建输入表示")
# 简化表示,实际BERT会将这些转换为高维向量
token_embeddings = [f"Token_{token}" for token in tokens]
segment_embeddings = ["Segment_0"] * len(tokens) # 单句任务,所有segment为0
position_embeddings = [f"Position_{i}" for i in range(len(tokens))]
print(f"Token Embeddings: {token_embeddings}")
print(f"Segment Embeddings: {segment_embeddings}")
print(f"Position Embeddings: {position_embeddings[:5]}...\n") # 只显示前5个
# 4. BERT模型内部处理(模拟)
print("4. BERT模型内部处理")
print(" - 输入嵌入表示 -> Transformer编码器×12/24层")
print(" - 自注意力机制计算")
print(" - 前馈神经网络处理")
print(" - 层归一化 & 残差连接")
print(" - 经过多层编码器处理\n")
# 5. 输出表示
print("5. 输出表示")
# 模拟BERT输出 - 每个token对应的隐藏状态
print("生成每个token的上下文表示向量:")
for i, token in enumerate(tokens):
print(f" {token}: [向量维度: 768]") # BERT-base隐藏层大小为768
# 特别关注CLS标记的输出
cls_output = "[CLS]标记的聚合表示向量"
print(f"\nCLS标记输出: {cls_output}\n")
# 6. 下游任务处理 - 使用Qwen API进行情感分析
print("6. 下游任务处理: 情感分析(使用Qwen API)")
# 构建Prompt
prompt = f"""
请分析以下文本的情感倾向,判断它是正面、负面还是中性,并简要说明理由。
文本:"{input_text}"
请按以下格式回答:
情感倾向: [正面/负面/中性]
理由: [你的分析]
"""
# 准备API请求
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "system",
"content": "你是一个情感分析专家,能够准确判断文本的情感倾向。"
},
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"result_format": "text",
"max_tokens": 150,
"temperature": 0.3
}
}
print("调用Qwen API进行情感分析...")
try:
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "output" in result and "text" in result["output"]:
# assistant_response = result["output"]["choices"][0]["message"]["content"]
analysis = result["output"]["text"]
print("\n情感分析结果:")
print(analysis)
else:
print("API响应格式异常", result)
except Exception as e:
print(f"API请求失败: {e}")
# 模拟API响应
print("\n模拟情感分析结果:")
print("情感倾向: 正面")
print("理由: 文本中使用了'真好'、'阳光明媚'等积极词汇,表达了愉悦的心情和正面的体验。")2.2 输出结果
bash
==================================================
BERT情感分析示例
==================================================
输入文本: 北京的天气真好,阳光明媚,我们决定去故宫参观。
1. 文本预处理:添加特殊标记
处理后: [CLS] 北京的天气真好,阳光明媚,我们决定去故宫参观。 [SEP]
2. Tokenization:文本分词
分词结果: ['[CLS]', '北京', '的', '天气', '真', '好', ',', '阳光', '明媚', ',', '我们', '决定', '去', '故宫', '参观', '。', '[SEP]']
3. 创建输入表示
Token Embeddings: ['Token_[CLS]', 'Token_北京', 'Token_的', 'Token_天气', 'Token_真', 'Token_好', 'Token_,', 'Token_阳光', 'Token_明媚', 'Token_,', 'Token_我们', 'Token_决定', 'Token_去', 'Token_故宫', 'Token_参观', 'Token_。', 'Token_[SEP]']
Segment Embeddings: ['Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0']
Position Embeddings: ['Position_0', 'Position_1', 'Position_2', 'Position_3', 'Position_4']...
4. BERT模型内部处理
- 输入嵌入表示 -> Transformer编码器×12/24层
- 自注意力机制计算
- 前馈神经网络处理
- 层归一化 & 残差连接
- 经过多层编码器处理
5. 输出表示
生成每个token的上下文表示向量:
[CLS]: [向量维度: 768]
北京: [向量维度: 768]
的: [向量维度: 768]
天气: [向量维度: 768]
真: [向量维度: 768]
好: [向量维度: 768]
,: [向量维度: 768]
阳光: [向量维度: 768]
明媚: [向量维度: 768]
,: [向量维度: 768]
我们: [向量维度: 768]
决定: [向量维度: 768]
去: [向量维度: 768]
故宫: [向量维度: 768]
参观: [向量维度: 768]
。: [向量维度: 768]
[SEP]: [向量维度: 768]
CLS标记输出: [CLS]标记的聚合表示向量
6. 下游任务处理: 情感分析(使用Qwen API)
调用Qwen API进行情感分析...
情感分析结果:
情感倾向: 正面
理由: 该文本中提到了"北京的天气真好,阳光明媚",这表达了对天气状况的好感;同时,"我们决定去故宫参观"也表明了说话者有积极外出活动的愿望。整体来看,这段话传递
了一种愉快和期待的心情,因此判断为正面情绪。2.3 代码流程说明
2.3.1 文本预处理
- 操作:在输入文本开头添加CLS标记,结尾添加SEP标记
- 目的:CLS标记用于聚合整个序列的信息,特别适合分类任务;SEP标记用于分隔不同句子
- 示例结果:CLS 北京的天气真好,阳光明媚,我们决定去故宫参观。 SEP
2.3.2 Tokenization(分词)
- 操作:将文本分割成单词或子词单元
- 目的:将自然语言转换为模型可以处理的离散单元
- 方法:BERT使用WordPiece算法,将词汇表外的词分解为子词
- 示例结果:'\[CLS', '北京', '的', '天气', '真', '好', ',', '阳光', '明媚', ',', '我们', '决定', '去', '故宫', '参观', '。', 'SEP']
2.3.3 创建输入表示
- 操作:将每个token转换为数值向量表示
- Token Embeddings:每个词汇的向量表示
- Segment Embeddings:区分不同句子的标识(单句任务全为0)
- Position Embeddings:表示每个token在序列中的位置信息
- 目的:将离散的token转换为连续的数值表示,保留词汇语义和位置信息
- 示例结果:三个嵌入向量相加,形成最终的输入表示
2.3.4 BERT模型内部处理
- 操作:通过多层Transformer编码器处理输入表示
- 自注意力机制:计算每个token与序列中所有其他token的关系权重
- 前馈神经网络:对自注意力输出进行非线性变换
- 层归一化和残差连接:确保训练稳定性和梯度流动
- 目的:通过深度双向编码,生成包含丰富上下文信息的表示
2.3.5 输出表示
- 操作:获取每个token经过BERT处理后的最终隐藏状态
- CLS标记:序列第一个位置的特殊标记,其输出向量包含整个序列的聚合信息,常用于分类任务
- 其他标记:每个token对应的输出向量包含其上下文信息,适用于序列标注等任务
- 示例结果:每个token对应一个768维的向量(BERT-base)
2.3.6 下游任务处理
- 操作:使用BERT的输出进行特定任务处理
- 本示例:使用CLS标记的输出进行情感分析分类
- 实现方式:通过Qwen API处理,将BERT的输出概念融入提示词中
- 替代方案:实际应用中,通常在BERT后添加一个分类层进行微调
3. 示例二:命名实体识别
3.1 代码示例
python
import requests
import json
import re
import os
# 配置Qwen API
API_KEY = os.environ.get("DASHSCOPE_API_KEY") # 请替换为您的实际API密钥
API_URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 示例输入文本 - 包含多种实体类型
input_text = "马云于1964年9月10日出生于浙江省杭州市,他是阿里巴巴集团的主要创始人,曾任阿里巴巴集团董事局主席。"
print("="*60)
print("BERT命名实体识别(NER)处理流程示例")
print("="*60)
print(f"输入文本: {input_text}\n")
# 1. 文本预处理:添加CLS和SEP标记
print("1. 文本预处理:添加特殊标记")
processed_text = "[CLS] " + input_text + " [SEP]"
print(f"处理后: {processed_text}\n")
# 2. Tokenization:将文本分割为单词/子词
print("2. Tokenization:文本分词")
# 模拟BERT的中文分词过程
tokens = ["[CLS]", "马", "云", "于", "1964", "年", "9", "月", "10", "日", "出生", "于", "浙江", "省", "杭州", "市", ",",
"他", "是", "阿里", "巴巴", "集团", "的", "主要", "创始", "人", ",", "曾", "任", "阿里", "巴巴", "集团",
"董事局", "主席", "。", "[SEP]"]
print(f"分词结果: {tokens}\n")
# 3. 创建输入表示:Token + Segment + Position Embeddings
print("3. 创建输入表示")
# 简化表示,实际BERT会将这些转换为高维向量
token_embeddings = [f"Token_{token}" for token in tokens]
segment_embeddings = ["Segment_0"] * len(tokens) # 单句任务,所有segment为0
position_embeddings = [f"Position_{i}" for i in range(len(tokens))]
print(f"Token Embeddings: {token_embeddings[:8]}...") # 只显示前8个
print(f"Segment Embeddings: {segment_embeddings[:8]}...")
print(f"Position Embeddings: {position_embeddings[:8]}...\n")
# 4. BERT模型内部处理(模拟)
print("4. BERT模型内部处理")
print(" - 输入嵌入表示 -> Transformer编码器×12/24层")
print(" - 自注意力机制计算: 每个token与所有其他token计算注意力权重")
print(" - 前馈神经网络处理: 对每个位置的表示进行非线性变换")
print(" - 层归一化 & 残差连接: 确保训练稳定性和梯度流动")
print(" - 经过多层编码器处理: 逐步提炼上下文信息\n")
# 5. 输出表示 - 特别关注NER任务
print("5. 输出表示 - NER任务重点")
print("生成每个token的上下文表示向量:")
for i, token in enumerate(tokens[:10]): # 只显示前10个token
print(f" {i}: {token} -> [768维向量表示]")
print("\nNER任务使用每个token的输出向量进行分类:")
print(" - 每个token的向量包含其上下文信息")
print(" - 分类器基于这些向量预测实体标签(B-PER, I-PER, B-ORG, I-ORG, B-LOC, I-LOC, O等)\n")
# 6. 下游任务处理 - 使用Qwen API进行命名实体识别
print("6. 下游任务处理: 命名实体识别(使用Qwen API)")
# 构建Prompt - 明确指示模型进行NER任务
prompt = f"""
请对以下文本进行命名实体识别,找出其中的人名(PER)、地名(LOC)、组织机构名(ORG)和时间日期(TIME)。
文本:"{input_text}"
请按以下JSON格式输出结果,包含"entities"数组,每个实体有"text"(文本)、"type"(类型)、"start_index"(起始位置)和"end_index"(结束位置)字段。
示例格式:
{{
"entities": [
{{
"text": "实体文本",
"type": "实体类型",
"start_index": 起始位置,
"end_index": 结束位置
}}
]
}}
"""
# 准备API请求
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "system",
"content": "你是一个命名实体识别专家,能够准确识别文本中的人名、地名、组织机构名和时间日期信息。请严格按照要求的JSON格式输出结果。"
},
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"result_format": "text",
"max_tokens": 500,
"temperature": 0.1 # 低温度确保输出格式稳定
}
}
print("调用Qwen API进行命名实体识别...")
try:
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "output" in result and "text" in result["output"]:
ner_result = result["output"]["text"]
# ner_result = result["output"]["choices"][0]["message"]["content"]
print("\n命名实体识别结果:")
# 尝试解析JSON结果
try:
# 提取JSON部分(模型可能会在JSON前后添加解释文字)
json_match = re.search(r'\{.*\}', ner_result, re.DOTALL)
if json_match:
entities_data = json.loads(json_match.group())
print(json.dumps(entities_data, ensure_ascii=False, indent=2))
else:
print(ner_result)
except json.JSONDecodeError:
print(ner_result)
else:
print("API响应格式异常")
except Exception as e:
print(f"API请求失败: {e}")
# 模拟API响应
print("\n模拟命名实体识别结果:")
print("""
{
"entities": [
{
"text": "马云",
"type": "PER",
"start_index": 0,
"end_index": 2
},
{
"text": "1964年9月10日",
"type": "TIME",
"start_index": 3,
"end_index": 10
},
{
"text": "浙江省杭州市",
"type": "LOC",
"start_index": 12,
"end_index": 17
},
{
"text": "阿里巴巴集团",
"type": "ORG",
"start_index": 21,
"end_index": 26
}
]
}
""")
# 7. 传统BERT NER方法对比说明
print("\n" + "="*60)
print("传统BERT NER方法与Qwen API方法对比")
print("="*60)
print("""
传统BERT NER方法:
1. 使用预训练的BERT模型作为编码器
2. 在BERT顶部添加一个线性分类层
3. 对每个token的输出向量进行分类,预测实体标签
4. 使用BIO/BILOU标注方案:
- B-PER: 人名的开始
- I-PER: 人名的中间部分
- B-LOC: 地名的开始
- I-LOC: 地名的中间部分
- B-ORG: 组织机构的开始
- I-ORG: 组织机构的中间部分
- O: 非实体
Qwen API方法:
1. 利用生成式大模型的强大理解能力
2. 通过精心设计的提示词指导模型执行NER任务
3. 直接输出结构化的实体信息
4. 无需训练专门的NER模型
优势对比:
- 传统方法: 精度高,可定制性强,但需要标注数据和模型训练
- API方法: 无需训练,快速部署,但依赖提示词设计和API成本
""")3.2 输出结果
bash
============================================================
BERT命名实体识别(NER)处理流程示例
============================================================
输入文本: 马云于1964年9月10日出生于浙江省杭州市,他是阿里巴巴集团的主要创始人,曾任阿里巴巴集团董事局主席。
1. 文本预处理:添加特殊标记
处理后: [CLS] 马云于1964年9月10日出生于浙江省杭州市,他是阿里巴巴集团的主要创始人,曾任阿里巴巴集团董事局主席。 [SEP]
2. Tokenization:文本分词
分词结果: ['[CLS]', '马', '云', '于', '1964', '年', '9', '月', '10', '日', '出生', '于', '浙江', '省', '杭州', '市', ',', '他', '是', '阿里', '巴巴', '集团
', '的', '主要', '创始', '人', ',', '曾', '任', '阿里', '巴巴', '集团', '董事局', '主席', '。', '[SEP]']
3. 创建输入表示
Token Embeddings: ['Token_[CLS]', 'Token_马', 'Token_云', 'Token_于', 'Token_1964', 'Token_年', 'Token_9', 'Token_月']...
Segment Embeddings: ['Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0']...
Position Embeddings: ['Position_0', 'Position_1', 'Position_2', 'Position_3', 'Position_4', 'Position_5', 'Position_6', 'Position_7']...
4. BERT模型内部处理
- 输入嵌入表示 -> Transformer编码器×12/24层
- 自注意力机制计算: 每个token与所有其他token计算注意力权重
- 前馈神经网络处理: 对每个位置的表示进行非线性变换
- 层归一化 & 残差连接: 确保训练稳定性和梯度流动
- 经过多层编码器处理: 逐步提炼上下文信息
5. 输出表示 - NER任务重点
生成每个token的上下文表示向量:
0: [CLS] -> [768维向量表示]
1: 马 -> [768维向量表示]
2: 云 -> [768维向量表示]
3: 于 -> [768维向量表示]
4: 1964 -> [768维向量表示]
5: 年 -> [768维向量表示]
6: 9 -> [768维向量表示]
7: 月 -> [768维向量表示]
8: 10 -> [768维向量表示]
9: 日 -> [768维向量表示]
NER任务使用每个token的输出向量进行分类:
- 每个token的向量包含其上下文信息
- 分类器基于这些向量预测实体标签(B-PER, I-PER, B-ORG, I-ORG, B-LOC, I-LOC, O等)
6. 下游任务处理: 命名实体识别(使用Qwen API)
调用Qwen API进行命名实体识别...
命名实体识别结果:
{
"entities": [
{
"text": "马云",
"type": "PER",
"start_index": 0,
"end_index": 2
},
{
"text": "1964年9月10日",
"type": "TIME",
"start_index": 3,
"end_index": 13
},
{
"text": "浙江省杭州市",
"type": "LOC",
"start_index": 16,
"end_index": 23
},
{
"text": "阿里巴巴集团",
"type": "ORG",
"start_index": 28,
"end_index": 35
},
{
"text": "阿里巴巴集团",
"type": "ORG",
"start_index": 47,
"end_index": 54
}
]
}
============================================================
传统BERT NER方法与Qwen API方法对比
============================================================
传统BERT NER方法:
1. 使用预训练的BERT模型作为编码器
2. 在BERT顶部添加一个线性分类层
3. 对每个token的输出向量进行分类,预测实体标签
4. 使用BIO/BILOU标注方案:
- B-PER: 人名的开始
- I-PER: 人名的中间部分
- B-LOC: 地名的开始
- I-LOC: 地名的中间部分
- B-ORG: 组织机构的开始
- I-ORG: 组织机构的中间部分
- O: 非实体
Qwen API方法:
1. 利用生成式大模型的强大理解能力
2. 通过精心设计的提示词指导模型执行NER任务
3. 直接输出结构化的实体信息
4. 无需训练专门的NER模型
优势对比:
- 传统方法: 精度高,可定制性强,但需要标注数据和模型训练
- API方法: 无需训练,快速部署,但依赖提示词设计和API成本3.3 代码流程说明
3.3.1 文本预处理
- 操作:在输入文本开头添加CLS标记,结尾添加SEP标记
- NER特定考虑:CLS标记提供全局信息,但NER主要使用每个token的个体表示
- 示例结果:CLS 马云于1964年9月10日出生于浙江省杭州市,他是阿里巴巴集团的主要创始人,曾任阿里巴巴集团董事局主席。 SEP
3.3.2 Tokenization(分词)
- 操作:将文本分割成单词或子词单元
- 中文NER特点:中文需要特别注意分词准确性,错误分词会导致实体边界错误
- 方法:BERT使用WordPiece算法,但中文通常按字符分词或使用专用分词器
- 示例结果:'\[CLS', '马', '云', '于', '1964', '年', '9', '月', '10', '日', '出生', '于', '浙江', '省', '杭州', '市', ',', ...]
3.3.3 创建输入表示
- 操作:将每个token转换为数值向量表示
- NER特定考虑:位置信息对实体识别特别重要,因为实体通常是连续token序列
- Token Embeddings:每个词汇的向量表示
- Segment Embeddings:区分不同句子的标识(单句任务全为0)
- Position Embeddings:表示每个token在序列中的位置信息
- 目的:为模型提供丰富的词汇、句法和位置信息
3.3.4 BERT模型内部处理
- 操作:通过多层Transformer编码器处理输入表示
- 自注意力机制:使每个token能够关注到序列中所有其他token,捕获长距离依赖关系
- 上下文编码:为每个token生成包含丰富上下文信息的表示
- 深层特征提取:通过多层变换,逐步提炼出适合实体识别的特征表示
3.3.5 输出表示 - NER任务重点
- 操作:获取每个token经过BERT处理后的最终隐藏状态
- NER特定使用:每个token的输出向量用于预测其实体标签
- 标签方案:通常使用BIO/BILOU方案标注实体边界和类型
- 分类层:在BERT顶部添加一个线性分类层,将每个token的向量映射到标签空间
3.3.6 下游任务处理 - 使用Qwen API进行命名实体识别
- 操作:使用Qwen API进行实体识别,模拟BERT NER的输出格式
- 提示工程设计:精心设计的提示词指导模型执行NER任务并输出结构化结果
- 输出格式:JSON格式包含实体文本、类型和位置信息
- 优势:无需训练专用模型,快速实现实体识别功能
4. 示例三:答案跨度预测
4.1 代码示例
python
import requests
import json
import re
import os
# 配置Qwen API
API_KEY = os.environ.get("DASHSCOPE_API_KEY") # 请替换为您的实际API密钥
API_URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 示例输入 - 问答任务
context = "爱因斯坦(Albert Einstein)1879年3月14日出生于德国乌尔姆市,是现代物理学的奠基人之一。他提出了相对论和质能方程E=mc²,并于1921年获得诺贝尔物理学奖。爱因斯坦于1955年4月18日在美国新泽西州普林斯顿去世。"
question = "爱因斯坦在哪一年获得诺贝尔奖?"
print("="*60)
print("BERT答案跨度预测处理流程示例")
print("="*60)
print(f"上下文: {context}")
print(f"问题: {question}\n")
# 1. 文本预处理:添加CLS和SEP标记
print("1. 文本预处理:添加特殊标记")
# 对于问答任务,BERT的输入格式为: [CLS] question [SEP] context [SEP]
processed_text = f"[CLS] {question} [SEP] {context} [SEP]"
print(f"处理后: {processed_text[:100]}...\n") # 只显示前100个字符
# 2. Tokenization:将文本分割为单词/子词
print("2. Tokenization:文本分词")
# 模拟BERT的中文/英文混合分词过程
tokens = [
"[CLS]", "爱", "因", "斯", "坦", "在", "哪", "一", "年", "获", "得", "诺", "贝", "尔", "奖", "?", "[SEP]",
"爱", "因", "斯", "坦", "(", "Albert", "Einstein", ")", "1879", "年", "3", "月", "14", "日", "出", "生", "于",
"德", "国", "乌", "尔", "姆", "市", ",", "是", "现", "代", "物", "理", "学", "的", "奠", "基", "人", "之", "一", "。",
"他", "提", "出", "了", "相", "对", "论", "和", "质", "能", "方", "程", "E", "=", "m", "c", "²", ",", "并", "于",
"1921", "年", "获", "得", "诺", "贝", "尔", "物", "理", "学", "奖", "。", "爱", "因", "斯", "坦", "于", "1955", "年",
"4", "月", "18", "日", "在", "美", "国", "新", "泽", "西", "州", "普", "林", "斯", "顿", "去", "世", "。", "[SEP]"
]
print(f"分词结果 (前20个token): {tokens[:20]}...\n")
# 3. 创建输入表示:Token + Segment + Position Embeddings
print("3. 创建输入表示")
# 对于问答任务,需要区分问题和上下文两部分
segment_ids = []
for i, token in enumerate(tokens):
if token == "[SEP]":
# 找到第一个SEP标记后的索引
first_sep_index = tokens.index("[SEP]")
if i <= first_sep_index:
segment_ids.append(0) # 问题部分
else:
segment_ids.append(1) # 上下文部分
else:
if i <= tokens.index("[SEP]"):
segment_ids.append(0) # 问题部分
else:
segment_ids.append(1) # 上下文部分
# 简化表示
token_embeddings = [f"Token_{token}" for token in tokens]
segment_embeddings = [f"Segment_{seg}" for seg in segment_ids]
position_embeddings = [f"Position_{i}" for i in range(len(tokens))]
print(f"Token Embeddings (前10个): {token_embeddings[:10]}...")
print(f"Segment Embeddings (前10个): {segment_embeddings[:10]}...")
print(f"Position Embeddings (前10个): {position_embeddings[:10]}...\n")
# 4. BERT模型内部处理(模拟)
print("4. BERT模型内部处理")
print(" - 输入嵌入表示 -> Transformer编码器×12/24层")
print(" - 自注意力机制计算: 问题token与上下文token之间计算交叉注意力")
print(" - 前馈神经网络处理: 对每个位置的表示进行非线性变换")
print(" - 层归一化 & 残差连接: 确保训练稳定性和梯度流动")
print(" - 经过多层编码器处理: 逐步提炼问题和上下文之间的关系\n")
# 5. 输出表示 - 答案跨度预测重点
print("5. 输出表示 - 答案跨度预测重点")
print("生成每个token的上下文表示向量:")
print(" - 每个token的向量包含问题和上下文的交互信息")
print(" - 特别关注上下文部分的token表示")
# 模拟答案开始和结束位置的预测
start_scores = [0.0] * len(tokens) # 每个token作为答案开始的得分
end_scores = [0.0] * len(tokens) # 每个token作为答案结束的得分
# 找到答案在上下文中的位置 ("1921年")
answer_start_index = tokens.index("1921")
answer_end_index = tokens.index("1921") # 单token答案
# 设置高分 (模拟BERT的输出)
start_scores[answer_start_index] = 9.8
end_scores[answer_end_index] = 9.7
print(f"\n答案开始位置预测得分 (部分): {start_scores[30:40]}...")
print(f"答案结束位置预测得分 (部分): {end_scores[30:40]}...")
print(f"预测答案: {tokens[answer_start_index]}\n")
# 6. 下游任务处理 - 使用Qwen API进行问答
print("6. 下游任务处理: 答案提取(使用Qwen API)")
# 构建Prompt - 明确指示模型从上下文中提取答案
prompt = f"""
请根据以下上下文回答问题。请直接从上下文中提取答案,不要自己生成答案。
上下文: "{context}"
问题: "{question}"
请按以下JSON格式输出结果:
{{
"answer": "提取的答案",
"confidence": 0.95,
"start_index": 答案在上下文中的起始位置,
"end_index": 答案在上下文中的结束位置
}}
"""
# 准备API请求
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "system",
"content": "你是一个问答系统专家,能够准确从给定上下文中提取答案。请严格按照要求的JSON格式输出结果。"
},
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"result_format": "text",
"max_tokens": 150,
"temperature": 0.1 # 低温度确保输出稳定
}
}
print("调用Qwen API进行答案提取...")
try:
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "output" in result and "text" in result["output"]:
answer_result = result["output"]["text"]
# answer_result = result["output"]["choices"][0]["message"]["content"]
print("\n答案提取结果:")
# 尝试解析JSON结果
try:
json_match = re.search(r'\{.*\}', answer_result, re.DOTALL)
if json_match:
answer_data = json.loads(json_match.group())
print(json.dumps(answer_data, ensure_ascii=False, indent=2))
# 验证答案
if answer_data.get("answer") == "1921年":
print("✓ 答案正确!")
else:
print("✗ 答案不正确!")
else:
print(answer_result)
except json.JSONDecodeError:
print(answer_result)
else:
print("API响应格式异常")
except Exception as e:
print(f"API请求失败: {e}")
# 模拟API响应
print("\n模拟答案提取结果:")
print("""
{
"answer": "1921年",
"confidence": 0.95,
"start_index": 105,
"end_index": 110
}
""")
print("✓ 答案正确!")
# 7. 传统BERT答案跨度预测方法说明
print("\n" + "="*60)
print("传统BERT答案跨度预测方法与Qwen API方法对比")
print("="*60)
print("""
传统BERT答案跨度预测方法:
1. 将问题和上下文拼接为: [CLS] question [SEP] context [SEP]
2. 通过BERT编码获取每个token的上下文表示
3. 使用两个线性分类器:
- 一个预测答案开始的token位置
- 一个预测答案结束的token位置
4. 通过softmax计算每个token作为开始/结束位置的概率
5. 选择概率最高的开始和结束位置作为答案跨度
Qwen API方法:
1. 利用生成式大模型的强大理解能力
2. 通过提示词指导模型从上下文中提取答案
3. 直接输出结构化的答案信息
4. 无需训练专门的问答模型
优势对比:
- 传统方法: 精度高,可解释性强,但需要标注数据和模型训练
- API方法: 无需训练,快速部署,适应多种问答场景,但依赖提示词设计
""")
# 8. 答案验证和评估
print("\n8. 答案验证和评估")
print("对比传统BERT方法和Qwen API方法的答案提取结果:")
print(f"问题: {question}")
print(f"上下文: {context}")
print(f"正确答案: '1921年'")
print("""
评估指标:
- 精确匹配(EM): 预测答案与标准答案是否完全一致
- F1分数: 预测答案与标准答案之间的重叠程度
- 位置准确性: 预测的起始和结束位置是否准确
""")4.2 输出结果
bash
============================================================
BERT答案跨度预测处理流程示例
============================================================
上下文: 爱因斯坦(Albert Einstein)1879年3月14日出生于德国乌尔姆市,是现代物理学的奠基人之一。他提出了相对论和质能方程E=mc²,并于1921年获得诺贝尔物理学奖。
爱因斯坦于1955年4月18日在美国新泽西州普林斯顿去世。
问题: 爱因斯坦在哪一年获得诺贝尔奖?
1. 文本预处理:添加特殊标记
处理后: [CLS] 爱因斯坦在哪一年获得诺贝尔奖? [SEP] 爱因斯坦(Albert Einstein)1879年3月14日出生于德国乌尔姆市,是现代物理学的奠基人之一。他提出了相对论和质
能方程E=mc²,...
2. Tokenization:文本分词
分词结果 (前20个token): ['[CLS]', '爱', '因', '斯', '坦', '在', '哪', '一', '年', '获', '得', '诺', '贝', '尔', '奖', '?', '[SEP]', '爱', '因', '斯']...
3. 创建输入表示
Token Embeddings (前10个): ['Token_[CLS]', 'Token_爱', 'Token_因', 'Token_斯', 'Token_坦', 'Token_在', 'Token_哪', 'Token_一', 'Token_年', 'Token_获']...
Segment Embeddings (前10个): ['Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0']...
Position Embeddings (前10个): ['Position_0', 'Position_1', 'Position_2', 'Position_3', 'Position_4', 'Position_5', 'Position_6', 'Position_7', 'Position_8', 'Position_9']...
4. BERT模型内部处理
- 输入嵌入表示 -> Transformer编码器×12/24层
- 自注意力机制计算: 问题token与上下文token之间计算交叉注意力
- 前馈神经网络处理: 对每个位置的表示进行非线性变换
- 层归一化 & 残差连接: 确保训练稳定性和梯度流动
- 经过多层编码器处理: 逐步提炼问题和上下文之间的关系
5. 输出表示 - 答案跨度预测重点
生成每个token的上下文表示向量:
- 每个token的向量包含问题和上下文的交互信息
- 特别关注上下文部分的token表示
答案开始位置预测得分 (部分): [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]...
答案结束位置预测得分 (部分): [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]...
预测答案: 1921
6. 下游任务处理: 答案提取(使用Qwen API)
调用Qwen API进行答案提取...
答案提取结果:
{
"answer": "1921年",
"confidence": 0.95,
"start_index": 46,
"end_index": 51
}
✓ 答案正确!
============================================================
传统BERT答案跨度预测方法与Qwen API方法对比
============================================================
传统BERT答案跨度预测方法:
1. 将问题和上下文拼接为: [CLS] question [SEP] context [SEP]
2. 通过BERT编码获取每个token的上下文表示
3. 使用两个线性分类器:
- 一个预测答案开始的token位置
- 一个预测答案结束的token位置
4. 通过softmax计算每个token作为开始/结束位置的概率
5. 选择概率最高的开始和结束位置作为答案跨度
Qwen API方法:
1. 利用生成式大模型的强大理解能力
2. 通过提示词指导模型从上下文中提取答案
3. 直接输出结构化的答案信息
4. 无需训练专门的问答模型
优势对比:
- 传统方法: 精度高,可解释性强,但需要标注数据和模型训练
- API方法: 无需训练,快速部署,适应多种问答场景,但依赖提示词设计
8. 答案验证和评估
对比传统BERT方法和Qwen API方法的答案提取结果:
问题: 爱因斯坦在哪一年获得诺贝尔奖?
上下文: 爱因斯坦(Albert Einstein)1879年3月14日出生于德国乌尔姆市,是现代物理学的奠基人之一。他提出了相对论和质能方程E=mc²,并于1921年获得诺贝尔物理学奖。
爱因斯坦于1955年4月18日在美国新泽西州普林斯顿去世。
正确答案: '1921年'
评估指标:
- 精确匹配(EM): 预测答案与标准答案是否完全一致
- F1分数: 预测答案与标准答案之间的重叠程度
- 位置准确性: 预测的起始和结束位置是否准确4.3 代码流程说明
4.3.1 文本预处理
- 操作:对于问答任务,BERT的输入格式为 CLS question SEP context SEP
- 目的:明确区分问题和上下文部分,使模型能够理解两者的关系
- 示例结果:CLS 爱因斯坦在哪一年获得诺贝尔奖? SEP 爱因斯坦(Albert Einstein)1879年3月14日出生于德国乌尔姆市... SEP
4.3.2 Tokenization(分词)
- 操作:将文本分割成单词或子词单元
- 多语言处理:中英文混合文本需要特殊处理,英文按WordPiece分词,中文按字符或词语分词
- 示例结果:'\[CLS', '爱', '因', '斯', '坦', '在', '哪', '一', '年', '获', '得', '诺', '贝', '尔', '奖', '?', 'SEP', '爱', '因', '斯', '坦', ...]
4.3.3 创建输入表示
- 操作:将每个token转换为数值向量表示
- Segment Embeddings:用于区分问题部分(0)和上下文部分(1)
- Position Embeddings:提供每个token在序列中的位置信息
- Token Embeddings:捕获词汇语义信息
- 目的:为模型提供丰富的问题-上下文交互信息
4.3.4 BERT模型内部处理
- 操作:通过多层Transformer编码器处理输入表示
- 交叉注意力:问题token与上下文token之间计算注意力权重,捕获相关问题部分
- 深层交互:通过多层编码,逐步提炼问题和上下文之间的关系
- 上下文编码:为每个上下文token生成包含问题信息的表示
4.3.5 输出表示 - 答案跨度预测重点
- 操作:获取每个token经过BERT处理后的最终隐藏状态
- 开始位置分类器:线性层将每个token的表示映射为标量分数,表示该token作为答案开始的概率
- 结束位置分类器:另一个线性层预测每个token作为答案结束的概率
- Softmax计算:对所有上下文token计算开始和结束概率分布
- 答案提取:选择开始概率最高的token和结束概率最高的token作为答案跨度
4.3.6.下游任务处理 - 使用Qwen API进行答案提取
- 操作:使用Qwen API进行答案提取,模拟BERT答案跨度预测的输出格式
- 提示工程设计:精心设计的提示词指导模型从上下文中提取答案并输出结构化结果
- 输出格式:JSON格式包含答案文本、置信度和位置信息
- 优势:无需训练专用模型,快速实现问答功能
5. 示例四:句子相似度计算
5.1 代码示例
python
import requests
import json
import re
import numpy as np
import os
# 配置Qwen API
API_KEY = os.environ.get("DASHSCOPE_API_KEY") # 请替换为您的实际API密钥
API_URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 示例输入 - 句子对相似度计算
sentence1 = "人工智能正在改变世界"
sentence2 = "AI技术正在重塑我们的生活"
print("="*60)
print("BERT句子相似度计算处理流程示例")
print("="*60)
print(f"句子1: {sentence1}")
print(f"句子2: {sentence2}\n")
# 1. 文本预处理:添加CLS和SEP标记
print("1. 文本预处理:添加特殊标记")
# 对于句子对任务,BERT的输入格式为: [CLS] sentence1 [SEP] sentence2 [SEP]
processed_text = f"[CLS] {sentence1} [SEP] {sentence2} [SEP]"
print(f"处理后: {processed_text}\n")
# 2. Tokenization:将文本分割为单词/子词
print("2. Tokenization:文本分词")
# 模拟BERT的中文分词过程
tokens = [
"[CLS]", "人", "工", "智", "能", "正", "在", "改", "变", "世", "界", "[SEP]",
"AI", "技", "术", "正", "在", "重", "塑", "我", "们", "的", "生", "活", "[SEP]"
]
print(f"分词结果: {tokens}\n")
# 3. 创建输入表示:Token + Segment + Position Embeddings
print("3. 创建输入表示")
# 对于句子对任务,需要区分两个句子
segment_ids = []
for i, token in enumerate(tokens):
if token == "[SEP]":
# 找到第一个SEP标记后的索引
first_sep_index = tokens.index("[SEP]")
if i <= first_sep_index:
segment_ids.append(0) # 第一个句子部分
else:
segment_ids.append(1) # 第二个句子部分
else:
if i <= tokens.index("[SEP]"):
segment_ids.append(0) # 第一个句子部分
else:
segment_ids.append(1) # 第二个句子部分
# 简化表示
token_embeddings = [f"Token_{token}" for token in tokens]
segment_embeddings = [f"Segment_{seg}" for seg in segment_ids]
position_embeddings = [f"Position_{i}" for i in range(len(tokens))]
print(f"Token Embeddings (前10个): {token_embeddings[:10]}...")
print(f"Segment Embeddings (前10个): {segment_embeddings[:10]}...")
print(f"Position Embeddings (前10个): {position_embeddings[:10]}...\n")
# 4. BERT模型内部处理(模拟)
print("4. BERT模型内部处理")
print(" - 输入嵌入表示 -> Transformer编码器×12/24层")
print(" - 自注意力机制计算: 两个句子的token之间计算交叉注意力")
print(" - 前馈神经网络处理: 对每个位置的表示进行非线性变换")
print(" - 层归一化 & 残差连接: 确保训练稳定性和梯度流动")
print(" - 经过多层编码器处理: 逐步提炼两个句子之间的关系\n")
# 5. 输出表示 - 句子相似度计算重点
print("5. 输出表示 - 句子相似度计算重点")
print("生成每个token的上下文表示向量:")
print(" - [CLS]标记的向量包含两个句子的聚合信息")
print(" - 特别关注[CLS]标记的输出,用于句子级分类任务")
# 实际调用BERT模型计算相似度
print("\n实际调用BERT模型计算相似度...")
from transformers import BertTokenizer, BertModel
import torch
# 加载中文BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 对输入句子进行编码
inputs = tokenizer(sentence1, sentence2, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
# 提取[CLS]标记的向量
cls_vector = outputs.last_hidden_state[:, 0, :].numpy()[0]
print(f"[CLS]标记输出向量: 维度{cls_vector.shape}, 范数{np.linalg.norm(cls_vector):.4f}")
# 计算余弦相似度
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 分别计算两个句子的[CLS]向量
inputs1 = tokenizer(sentence1, return_tensors="pt", padding=True, truncation=True)
inputs2 = tokenizer(sentence2, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs1 = model(**inputs1)
outputs2 = model(**inputs2)
cls_vector1 = outputs1.last_hidden_state[:, 0, :].numpy()[0]
cls_vector2 = outputs2.last_hidden_state[:, 0, :].numpy()[0]
# 计算余弦相似度
similarity_score = cosine_similarity(cls_vector1, cls_vector2)
print(f"余弦相似度: {similarity_score:.4f}\n")
# 6. 下游任务处理 - 使用Qwen API进行句子相似度计算
print("6. 下游任务处理: 句子相似度计算(使用Qwen API)")
# 构建Prompt - 明确指示模型计算句子相似度
prompt = f"""
请评估以下两个句子的语义相似度,给出一个0到1之间的相似度分数,其中0表示完全不相关,1表示完全等价。
句子1: "{sentence1}"
句子2: "{sentence2}"
请按以下JSON格式输出结果:
{{
"similarity_score": 0.85,
"explanation": "简要解释相似度评分的原因"
}}
"""
# 准备API请求
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": "qwen-max",
"input": {
"messages": [
{
"role": "system",
"content": "你是一个语义相似度评估专家,能够准确判断两个句子的语义相似程度。请给出0到1之间的相似度分数,并简要解释评分原因。"
},
{
"role": "user",
"content": prompt
}
]
},
"parameters": {
"result_format": "text",
"max_tokens": 150,
"temperature": 0.1 # 低温度确保输出稳定
}
}
print("调用Qwen API进行句子相似度计算...")
try:
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "output" in result and "text" in result["output"]:
similarity_result = result["output"]["text"]
print("\n句子相似度计算结果:")
# 尝试解析JSON结果
try:
json_match = re.search(r'\{.*\}', similarity_result, re.DOTALL)
if json_match:
similarity_data = json.loads(json_match.group())
print(json.dumps(similarity_data, ensure_ascii=False, indent=2))
else:
print(similarity_result)
except json.JSONDecodeError:
print(similarity_result)
else:
print("API响应格式异常")
except Exception as e:
print(f"API请求失败: {e}")
# 模拟API响应
print("\n模拟句子相似度计算结果:")
print("""
{
"similarity_score": 0.82,
"explanation": "两个句子都表达了人工智能技术对世界的积极影响,虽然用词不同但核心语义相似"
}
""")
# 7. 传统BERT句子相似度计算方法说明
print("\n" + "="*60)
print("传统BERT句子相似度计算方法与Qwen API方法对比")
print("="*60)
print("""
传统BERT句子相似度计算方法:
1. 将两个句子拼接为: [CLS] sentence1 [SEP] sentence2 [SEP]
2. 通过BERT编码获取每个token的上下文表示
3. 使用[CLS]标记的输出向量作为整个句子对的表示
4. 在[CLS]向量上添加线性分类层或回归层:
- 分类方法: 将相似度分为几个等级(如0-4分)
- 回归方法: 直接输出0-1之间的相似度分数
5. 使用余弦相似度作为替代方法:
- 分别计算每个句子的[CLS]向量
- 计算两个向量的余弦相似度
Qwen API方法:
1. 利用生成式大模型的语义理解能力
2. 通过提示词指导模型评估句子相似度
3. 直接输出结构化的相似度分数和解释
4. 无需训练专门的相似度模型
优势对比:
- 传统方法: 计算效率高,可部署在资源受限环境,但需要训练数据和模型训练
- API方法: 无需训练,理解能力强,能提供解释,但依赖网络连接和API成本
""")
# 8. 相似度计算方法扩展
print("\n8. 相似度计算方法扩展")
print("除了整体相似度,还可以计算不同层面的相似度:")
print("""
1. 词汇层面相似度:
- Jaccard相似度: 计算两个句子词汇集合的重叠程度
- 词嵌入余弦相似度: 计算句子平均词向量的余弦相似度
2. 语义层面相似度:
- BERT句子嵌入: 使用[CLS]向量或所有token向量的平均
- SBERT(Sentence-BERT): 专门优化的句子嵌入模型
3. 结构层面相似度:
- 句法树相似度: 比较两个句子的句法结构
- 依存关系相似度: 比较句子的依存关系图
4. 生成式方法:
- 使用LLM评估: 如本示例中的Qwen API方法
- 自然语言推理: 判断两个句子是否蕴含、矛盾或中立
""")
# 9. 应用场景示例
print("\n9. 应用场景示例")
print("句子相似度计算在实际应用中的场景:")
application_scenarios = [
"搜索引擎: 查询和文档的相似度匹配",
"推荐系统: 用户历史行为和候选项目的相似度计算",
"重复检测: 识别文档中的重复或近似重复内容",
"问答系统: 问题和候选答案的相似度评估",
"文本摘要: 评估摘要与原文的语义一致性",
"机器翻译评估: 比较原文和译文的语义等价性",
" plagiarism检测: 识别文本之间的相似性"
]
for i, scenario in enumerate(application_scenarios, 1):
print(f" {i}. {scenario}")5.2 输出结果
bash
============================================================
BERT句子相似度计算处理流程示例
============================================================
句子1: 人工智能正在改变世界
句子2: AI技术正在重塑我们的生活
1. 文本预处理:添加特殊标记
处理后: [CLS] 人工智能正在改变世界 [SEP] AI技术正在重塑我们的生活 [SEP]
2. Tokenization:文本分词
分词结果: ['[CLS]', '人', '工', '智', '能', '正', '在', '改', '变', '世', '界', '[SEP]', 'AI', '技', '术', '正', '在', '重', '塑', '我', '们', '的', '生', '活', '[SEP]']
3. 创建输入表示
Token Embeddings (前10个): ['Token_[CLS]', 'Token_人', 'Token_工', 'Token_智', 'Token_能', 'Token_正', 'Token_在', 'Token_改', 'Token_变', 'Token_世']...
Segment Embeddings (前10个): ['Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0', 'Segment_0']...
Position Embeddings (前10个): ['Position_0', 'Position_1', 'Position_2', 'Position_3', 'Position_4', 'Position_5', 'Position_6', 'Position_7', 'Position_8', 'Position_9']...
4. BERT模型内部处理
- 输入嵌入表示 -> Transformer编码器×12/24层
- 自注意力机制计算: 两个句子的token之间计算交叉注意力
- 前馈神经网络处理: 对每个位置的表示进行非线性变换
- 层归一化 & 残差连接: 确保训练稳定性和梯度流动
- 经过多层编码器处理: 逐步提炼两个句子之间的关系
5. 输出表示 - 句子相似度计算重点
生成每个token的上下文表示向量:
- [CLS]标记的向量包含两个句子的聚合信息
- 特别关注[CLS]标记的输出,用于句子级分类任务
实际调用BERT模型计算相似度...
[CLS]标记输出向量: 维度(768,), 范数22.5603
余弦相似度: 0.8570
6. 下游任务处理: 句子相似度计算(使用Qwen API)
调用Qwen API进行句子相似度计算...
句子相似度计算结果:
{
"similarity_score": 0.85,
"explanation": "两个句子都表达了人工智能或AI技术对社会产生重大影响的意思。虽然使用了不同的词汇('改变世界' vs '重塑我们的生活'),但核心含义非常接近,都是
指AI带来的广泛变革。因此,它们在语义上高度相似,但由于不是完全相同的表达方式,所以评分略低于1。"
}
============================================================
传统BERT句子相似度计算方法与Qwen API方法对比
============================================================
传统BERT句子相似度计算方法:
1. 将两个句子拼接为: [CLS] sentence1 [SEP] sentence2 [SEP]
2. 通过BERT编码获取每个token的上下文表示
3. 使用[CLS]标记的输出向量作为整个句子对的表示
4. 在[CLS]向量上添加线性分类层或回归层:
- 分类方法: 将相似度分为几个等级(如0-4分)
- 回归方法: 直接输出0-1之间的相似度分数
5. 使用余弦相似度作为替代方法:
- 分别计算每个句子的[CLS]向量
- 计算两个向量的余弦相似度
Qwen API方法:
1. 利用生成式大模型的语义理解能力
2. 通过提示词指导模型评估句子相似度
3. 直接输出结构化的相似度分数和解释
4. 无需训练专门的相似度模型
优势对比:
- 传统方法: 计算效率高,可部署在资源受限环境,但需要训练数据和模型训练
- API方法: 无需训练,理解能力强,能提供解释,但依赖网络连接和API成本
8. 相似度计算方法扩展
除了整体相似度,还可以计算不同层面的相似度:
1. 词汇层面相似度:
- Jaccard相似度: 计算两个句子词汇集合的重叠程度
- 词嵌入余弦相似度: 计算句子平均词向量的余弦相似度
2. 语义层面相似度:
- BERT句子嵌入: 使用[CLS]向量或所有token向量的平均
- SBERT(Sentence-BERT): 专门优化的句子嵌入模型
3. 结构层面相似度:
- 句法树相似度: 比较两个句子的句法结构
- 依存关系相似度: 比较句子的依存关系图
4. 生成式方法:
- 使用LLM评估: 如本示例中的Qwen API方法
- 自然语言推理: 判断两个句子是否蕴含、矛盾或中立
9. 应用场景示例
句子相似度计算在实际应用中的场景:
1. 搜索引擎: 查询和文档的相似度匹配
2. 推荐系统: 用户历史行为和候选项目的相似度计算
3. 重复检测: 识别文档中的重复或近似重复内容
4. 问答系统: 问题和候选答案的相似度评估
5. 文本摘要: 评估摘要与原文的语义一致性
6. 机器翻译评估: 比较原文和译文的语义等价性
7. plagiarism检测: 识别文本之间的相似性5.3 代码流程说明
5.3.1 文本预处理
- 操作:对于句子对任务,BERT的输入格式为 CLS sentence1 SEP sentence2 SEP
- 目的:明确区分两个句子,使模型能够理解句子间的关系
- CLS:位于序列开头,其输出向量用于句子级分类任务
- SEP:分隔两个句子,标记句子边界
- 示例结果:CLS 人工智能正在改变世界 SEP AI技术正在重塑我们的生活 SEP
5.3.2 Tokenization(分词)
- 操作:将文本分割成单词或子词单元
- 中文处理:中文通常按字符分词,或使用专用分词器
- 多语言处理:处理中英文混合文本时需要特殊考虑
- 示例结果:'\[CLS', '人', '工', '智', '能', '正', '在', '改', '变', '世', '界', 'SEP', 'AI', '技', '术', '正', '在', '重', '塑', '我', '们', '的', '生', '活', 'SEP']
5.3.3 创建输入表示
- 操作:将每个token转换为数值向量表示
- Segment Embeddings:用于区分第一个句子(0)和第二个句子(1)
- Position Embeddings:提供每个token在序列中的位置信息
- Token Embeddings:捕获词汇语义信息
- 目的:为模型提供丰富的句子间交互信息
5.3.4 BERT模型内部处理
- 操作:通过多层Transformer编码器处理输入表示
- 交叉注意力:两个句子的token之间计算注意力权重,捕获语义关联
- 深层交互:通过多层编码,逐步提炼两个句子之间的关系
- CLS标记编码:聚合整个序列信息,生成句子级表示
5.3.5 输出表示 - 句子相似度计算重点
- 操作:获取每个token经过BERT处理后的最终隐藏状态
- CLS标记向量:作为整个句子对的聚合表示,用于相似度计算
- 分类层:线性层将CLS向量映射到相似度分数
- 替代方法:分别计算两个句子的CLS向量,然后计算余弦相似度
- 相似度分数:通常为0-1之间的值,表示两个句子的语义相似程度
5.3.6 下游任务处理 - 使用Qwen API进行句子相似度计算
- 操作:使用Qwen API进行相似度计算,模拟BERT句子相似度评估
- 提示工程设计:精心设计的提示词指导模型评估句子相似度并输出结构化结果
- 输出格式:JSON格式包含相似度分数和解释
- 优势:无需训练专用模型,快速实现相似度计算功能
六、BERT的优势与特点
- **双向上下文理解:**与单向语言模型相比,BERT能同时利用上下文信息,对词汇的理解更准确。
- 强大的通用性: 预训练后的BERT是一个"基础模型",可以通过微调轻松适配到多种下游任务,无需从头开始为特定任务设计模型结构。
- **卓越的性能:**在发布时,它在11个NLP任务上刷新了最佳性能记录。
- 丰富的生态系统: 拥有多种预训练版本(如 bert-base-uncased, bert-large-uncased)和多语言版本,并被集成到Hugging Face等主流框架中,易于使用。
七、BERT的应用场景
除了基础文本分类和问答,BERT的应用与现在的行业也息息相关,它已成为NLP领域的"基础设施",被嵌入到无数产品和流程中。
1. 搜索引擎优化
- 工作原理: 现代搜索引擎(如Google、Bing)早已超越简单的关键词匹配。它们使用BERT等模型来理解搜索查询的语义和上下文。
- 范例:
- 过去搜索: "2025年武汉到杭州旅游攻略" 可能返回关于武汉和杭州旅游住宿的普通页面。
- 使用BERT后: 搜索引擎能更好地理解"到"等介词的重要性。这个查询会更精确地返回2025年武汉旅客前往杭州所需文件的结果,因为它理解了杭州是目的地。
2.智能客服与聊天机器人
- 工作原理: BERT用于理解用户提问的意图和情感,并从知识库中检索最相关的答案。
- 范例:
- 你向银行客服聊天机器人输入:"我上次的那笔转账好像没成功,能帮我查下吗?"
- BERT模型会:1. 理解意图-->查询交易状态; 2. 分析实体-->"上次"(时间)、"转账"(操作类型); 3. 判断情感: "好像没成功"带有一丝不确定和焦虑,可能需要优先处理或更友好的回复。系统随后从交易记录中精准检索并回复。
3. 内容推荐与信息流
- 工作原理: 社交媒体和新闻App(如Facebook, 今日头条)使用BERT来理解用户阅读内容的深层主题、观点和情感,从而推荐语义相似的新内容,而不仅仅是包含相同关键词的内容。
- 范例: 你阅读了一篇关于"电动汽车电池技术突破"的文章。系统不会仅仅推荐包含"汽车"和"电池"的文章,而是能理解核心是"技术"、"创新"、"环保",从而推荐一篇关于"固态电池研发进展"或"可持续能源"的文章。
4. 法律与金融文档分析
- 工作原理: 利用BERT的序列标注和分类能力,从冗长的合同、财报或法律文书中快速提取关键信息。
- 范例:
- 法律: 自动识别合同中的"责任条款"、"违约金额"、"签约方"等实体,生成摘要,比对不同合同版本的差异。
- 金融: 分析公司财报和新闻,判断市场情绪是"乐观"还是"悲观",用于风险预警和投资决策。
5. 语音助手与智能音箱
- 工作原理: 语音识别将语音转为文本后,BERT等模型负责理解文本指令的深层含义和上下文。
- 范例: 你对智能音箱说:"把灯调亮一点,太暗了。" BERT模型能理解"调亮"是操作,"灯"是对象,"太暗"是原因和程度,从而准确执行指令。它还能理解上下文,比如你接着说:"还是太暗了",它会知道"还是"指的是上一次的操作,并继续调亮。
八、总结
最后,脑袋里可能还是会有一个疑问,BERT到底是什么?似乎说不清、道不明。其实,它就是一个通过海量"完形填空"训练出来的、能深刻理解人类语言上下文含义的超级语言模型。
它的革命性在于:
- 双向理解:能同时利用上下文信息,理解能力暴增。
- 预训练-微调:先通读海量书籍成为"学霸",再稍加练习就能成为任何领域的"专家",极大降低了AI应用的门槛。
虽然现在很多生成式AI光芒四射,但BERT作为"理解"领域的基石,依然默默地支撑着互联网的方方面面,让你我的数字生活变得更加智能和便捷。它无疑是人工智能发展史上的一座重要里程碑。