目录
前言
我们作为个体的开发是接触不到那种真正的模型核心点。但是我们可以从浅显的层次去了解和深入大模型,去了解使用,让它成为我们日常生活中的一个好帮手。同时能通过这些实际开发和应用来提升自己对大模型的理解和人工智能的一个应用方向的思考。
本篇文章将会从安装框架llamaindx,调用大模型来实现完成自己的ai本地模型部署,实现本地聊天。
安装llamaindx框架
官网:LlamaIndex - LlamaIndex --- LlamaIndex - LlamaIndex
安装指令(通过bash去安装)
bash
pip install llama-index
或者
pip install llama-index-llms-openai安装完成后我们可以通过指令来查看是否完成安装
bash
pip show llama-index注:需要通过vpn软件去访问外网,否则将无法下载
若需要不想访问外网下载,可以通过去学习使用x-get去下载。
基于llama-index实现聊天基础功能
AI模型Key获取
获取api-key可以参考这份文档:如何获取AI模型及本地部署_ai本地部署python-CSDN博客
Kimi:Moonshot AI 开放平台 - Kimi 大模型 API 服务
DeepSeek:DeepSeek 开放平台
这里就不过多介绍了。
模型创建和模型导入
我们可以先创建两个py文件
llms.py文件作为模型创建导入的文件。
main.py作为聊天模型启动文件。
若不想跟着一起操作,想要跟着官方文档操作的也可以:
示例文档可以参考这篇文章。
Starter Tutorial (Using Local LLMs) - LlamaIndex
OK那么正式我们的模型创建和导入了。
模型创建和导入
首先要在你的文件夹目录下创建一个.env文件用来存储自己的API。

之后在文件内写入以下内容
python
DEEPSEEK_API_KEY="填写你的deepseek-key"
MOONSHOT_API_KEY="填写你的kimi-key"
QWEN_API_KEY="填写你的qwen-key"当完成这个首要操作后,我们再继续模型的创建和导入。
需要导入的模块包
python
from typing import Dict
import os
from dotenv import load_dotenv
from llama_index.llms.openai import OpenAI
from llama_index.llms.openai.utils import ALL_AVAILABLE_MODELS, CHAT_MODELS然后怎么知道自己该如何写

将鼠标悬停到这个上,然后ctrl+鼠标左键点击进入查看时如何导入模型的。
如果不想去点击,我下面提供了部分内置代码观看。
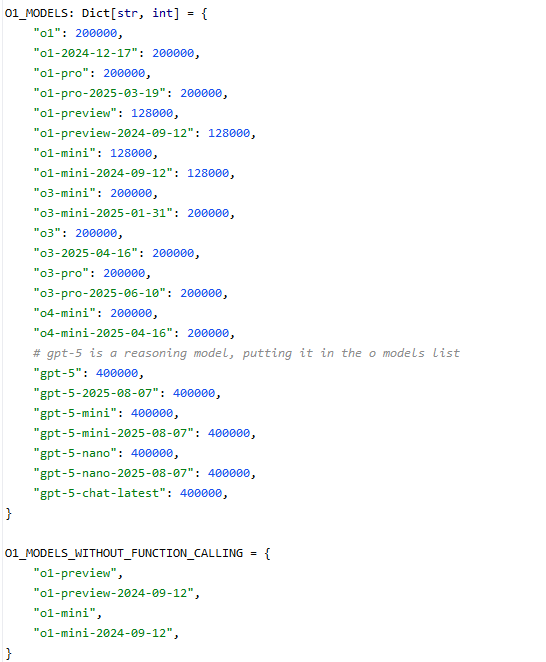


不难发现啊,模型导入只要这三部分,我们来根据这个内容来写。
python
# 加载环境变量
load_dotenv()
# 创建大模型
MOONSHOT_MODELS: Dict[str, int] ={
"kimi-k2-0711-preview":128000, #模型上下文长度
}
DEEP_SEEK_MODELS: Dict[str, int] ={
"deepseek-reasoner":128000, #模型上下文长度
}
QWEN_MODELS: Dict[str, int] ={
"qwen-max":128000, #模型上下文长度
}
ALL_AVAILABLE_MODELS.update(
#更新模型列表
MOONSHOT_MODELS |
DEEP_SEEK_MODELS|
QWEN_MODELS
)
CHAT_MODELS.update(
#更新模型列表
MOONSHOT_MODELS |
DEEP_SEEK_MODELS |
QWEN_MODELS
)关于模型上下文长度,需要去各自平台的官方文档去查看。
在导入模型之后,我们就需要去创建如何调用它们的模型了,你光创建导入,只有空壳子,缺少内在的驱动,怎么使用,那么接下来就要注入灵魂了。
python
def moonshot_llm(**kwargs):
llm = OpenAI(
api_key=os.getenv("MOONSHOT_API_KEY", #填写你的大模型api的key
model="kimi-k2-0711-preview",
api_base="https://api.moonshot.cn/v1",
temperature=0.6,
**kwargs
)
return llm
def deepseek_llm(**kwargs):
llm = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"), #填写你的大模型api的key
model="deepseek-reasoner",
api_base="https://api.deepseek.com/v1",
temperature=1.3,
**kwargs
)
return llm
def qwen_llm(**kwargs):
llm = OpenAI(
api_key=os.getenv("QWEN_API_KEY"), #填写你的大模型api的key
model="qwen-max",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.6,
**kwargs
)
return llm需要记住model要和上面导入的模型里要含有的一直,至于temperature模型温度需要依据官方文档的来填写,不过大部分来说都是温度值越低需要的任务精细度就越高,也就是任务的需求要求精度就越高,适合做一些精密计算和一些精度需求高的文档任务。
OK模型也创建了,那么接下来就要创建本地部署的聊天模型了。
本地聊天模型部署
包模块的导入
python
# 导入相关模块
# llms配置
from llama_index.core import settings, Settings
# 聊天引擎模型
from llama_index.core.chat_engine import SimpleChatEngine
# 导入大模型相关配置
from llms import deepseek_llm, moonshot_llm, qwen_llm聊天模型的创建
代码很简单,就不做过多的介绍了。
python
# Settings.llm = moonshot_llm()
# Settings.llm = deepseek_llm()
Settings.llm = qwen_llm()
chat_engine = SimpleChatEngine.from_defaults()
chat_engine.streaming_chat_repl() #启动聊天ok到这一步,你基本上就完成了本地的聊天模型部署了。
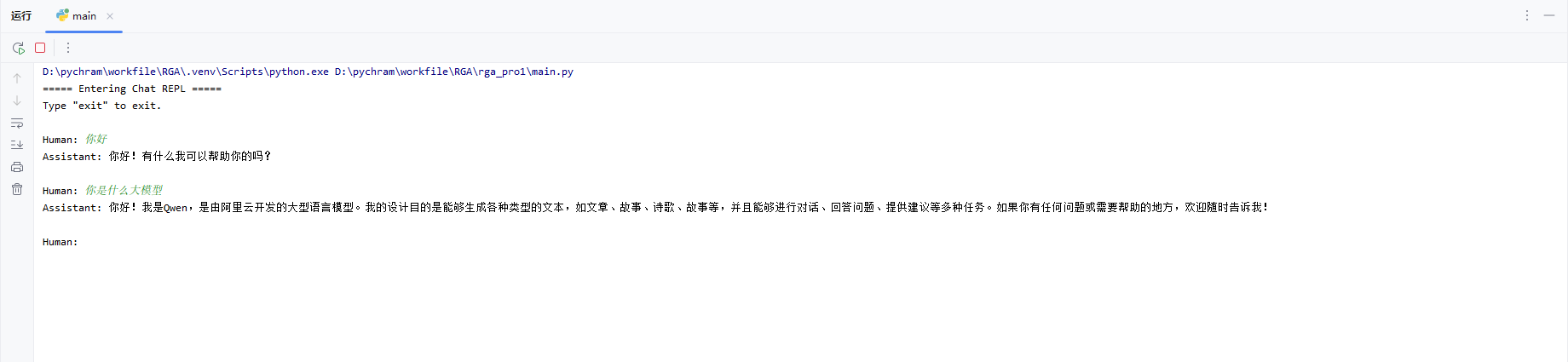
运行演示
通过在控制台输入对话内容聊天,实现与AI模型的本地聊天。