想象一下,你面对一个从未整理过的、堆满各种物品的房间。没有人告诉你"书应该放书架""衣服该进衣柜",但你能自然而然地根据物品的形状、颜色、材质,把相似的东西归在一起。这种不依赖明确指令,仅凭观察事物本身来发现规律 的能力,正是无监督学习 (Unsupervised Learning)试图赋予机器的核心智能。
在人工智能领域,无监督学习是让机器在没有"标准答案"(即数据标签)的情况下,自主探索海量数据内在结构和规律的魔法。它就像一位充满好奇心的探险家,在未知的数据森林中独自绘制地图。今天,就让我们用最生活化的语言,揭开它的神秘面纱。
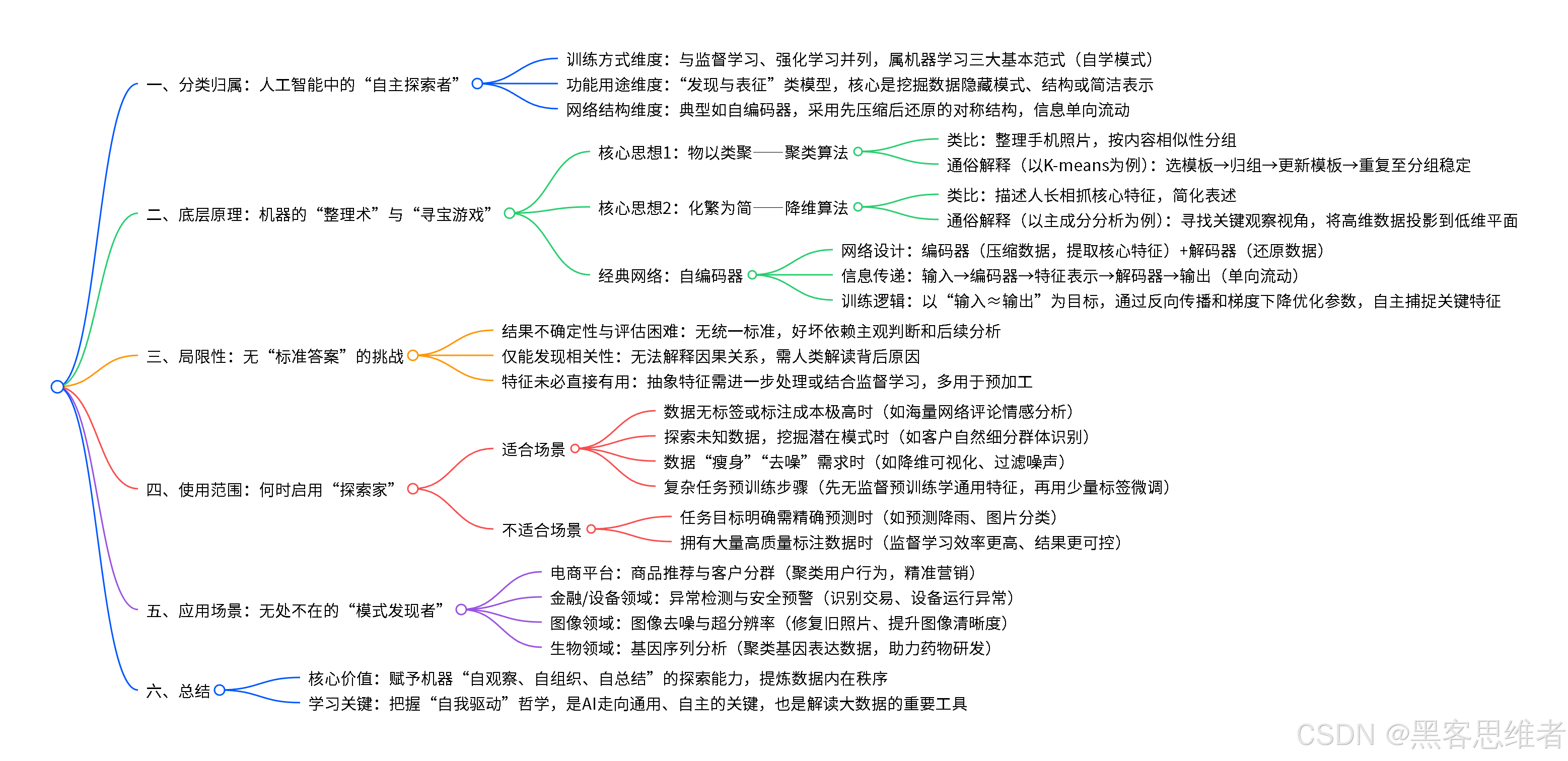
一、分类归属:人工智能中的"自主探索者"
在主流人工智能技术版图中,我们可以从几个维度来定位无监督学习:
- 从"训练方式"划分 ,它与监督学习 、强化学习并列为机器学习的三大基本范式。如果说监督学习是"有老师手把手教解题",强化学习是"通过试错和奖励来学习下棋",那么无监督学习就是"没有老师,只给一堆资料让你自己总结规律"的自学模式。
- 从"功能用途"划分 ,它属于**"发现与表征"类模型**。它的核心任务不是预测一个具体结果(比如明天股价是多少),而是挖掘数据中隐藏的模式、结构或简洁表示,例如将客户分成不同群体,或将复杂图片压缩成关键特征。
- 从"网络结构"看 ,典型的无监督学习神经网络,如自编码器,通常采用先压缩后还原的对称结构,信息在其中单向流动,目的是学习高效的数据"代表"。
简单来说,无监督学习是AI家族中那位擅长观察、归纳和总结 的成员,它工作的前提是:数据本身就有故事,而我要自己读懂它。
二、底层原理:机器的"整理术"与"寻宝游戏"
无监督学习是如何工作的?我们通过两个核心思想和一个经典网络来拆解。
核心思想1:物以类聚------聚类算法
类比 :想象你要整理手机里上千张照片。没有人告诉你标准,但你会不自觉地创建相册:"家人的笑脸"、"旅行的风景"、"美食打卡"、"工作截图"。你依据的是照片内容的相似性。这就是聚类------无监督学习的经典任务。
通俗解释:算法(比如K-means)像是一个自动整理助手。你告诉它"大概分成5类吧",它就会:
- 随机找5张照片作为"模板"。
- 把每一张照片都和这5个模板比较,归入最相似的那个组。
- 计算每个组所有照片的平均特征,更新为新的"模板"。
- 重复2、3步,直到分组稳定。
最终,照片被分成了5个有各自特点的群组。整个过程,算法只看到了像素,没有看到任何"家人"、"风景"的标签。
核心思想2:化繁为简------降维算法
类比 :你想向朋友描述一个人的长相,不需要事无巨细地汇报他每根头发的走向、每个毛孔的位置。你会说:"国字脸、浓眉、高鼻梁。"这寥寥几个特征,就抓住了核心,大幅简化了描述。这就是降维。
通俗解释:以主成分分析为例,它就像是在一堆混杂的数据中,寻找最能体现差异的"观察视角"。例如,描述学生,可能有"身高"、"体重"、"语数外成绩"等多个维度。降维算法会发现,或许"综合学业水平"和"身体素质"这两个新组合维度,就能解释大部分学生的特点。它将高维数据投影到更重要的低维平面上,便于我们可视化(比如画成二维散点图)和理解。
一个经典网络:自编码器
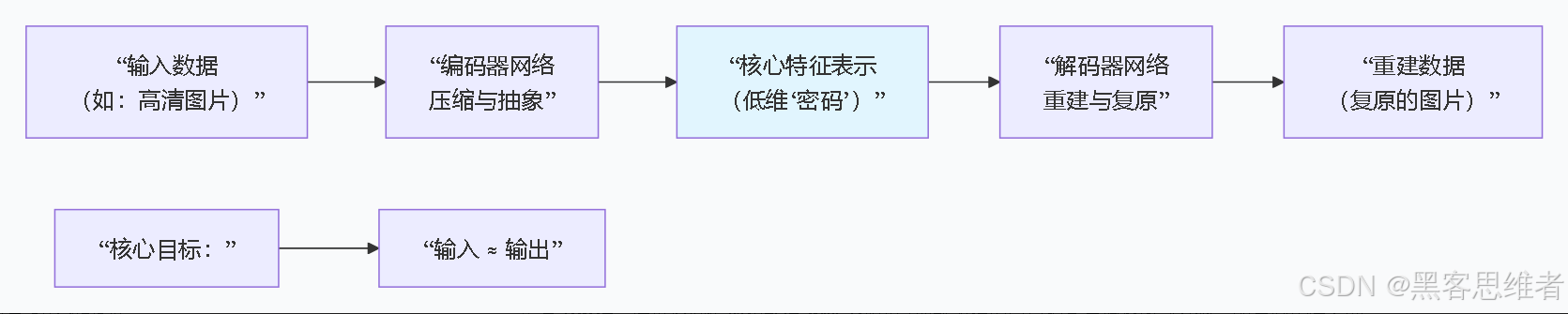
让我们用一个具体的神经网络结构------自编码器,来感受无监督学习如何"自我训练"。
类比:教机器玩一个"画简笔画并复原"的游戏。你给机器看一张猫的彩色照片(输入),要求它先只用几根线条(编码)概括这只猫,然后再根据这几根线条,尽最大努力画出原来的猫(输出)。目标是最初的照片和最后画出来的照片越像越好。
通俗拆解:
-
网络设计:自编码器通常由对称的两部分组成:
- 编码器 :像是一个"压缩软件"或"总结大师"。它把输入的高维数据(如图片)通过几层网络,压缩成一个低维的、密集的特征表示 (也叫"潜变量")。这个过程是保留精华,去除冗余。
- 解码器 :像一个"复原大师"或"画家"。它接收编码器压缩后的特征表示,试图还原出与原始输入尽可能相似的数据。
-
信息传递 :信息单向从输入层流经编码器,到特征表示层,再流经解码器到输出层。没有外部的标签指导,信息在内部自我循环比较。
-
训练逻辑 :训练的核心就是自我比较与优化。
- 目标(损失函数):让网络的输出(重建数据)与输入(原始数据)之间的差异尽可能小。这个差异通常用"均方误差"等来衡量。
- 学习过程 :通过反向传播和梯度下降(你可以理解为模型自己摸索着调整内部参数,朝着减少误差的方向一点点改进),网络不断调整编码器和解码器的参数。
- 神奇的结果:为了完美地复原输入,编码器被迫学会捕捉数据中最关键、最有区分度的特征。那个低维的"特征表示",就是数据本质的精华。
一个简单的重建损失公式(了解即可):
Loss = (原始图片像素值 - 重建图片像素值)² 的平均值
初学者请记住 :公式只是量化目标的方式,核心思想是让机器通过"压缩-复原"的游戏,自主学会抓住重点。
三、局限性:没有"标准答案"带来的挑战
无监督学习虽然强大,但并非万能。它的局限性根源在于 "缺乏监督信号"。
-
结果的不确定性与评估困难:因为没有标准答案,所以"好"与"不好"很难绝对量化。比如,把客户分成5组还是8组?哪一种是"正确"的?这往往依赖于人的主观判断和后续分析。这个过程有时显得有点"玄学"。
-
发现的不一定是因果,可能只是相关 :它善于发现"哪些东西总是一起出现",但无法告诉你"为什么"。比如,它发现"买啤酒的人常买尿布",但它不知道这是因为年轻爸爸们的采购习惯。相关性不等于因果性,解读结果需要人类智慧。
-
学到的特征未必直接有用:自编码器学到的特征表示可能非常抽象,需要进一步处理或结合监督学习,才能用于具体的分类或预测任务。它更像一个优秀的"预加工"环节,而非最终解决方案。
简单来说,无监督学习是一位出色的"数据观察员"和"特征提炼师",但它不是"决策者"。它提供深刻的洞见和更好的数据表示,但如何利用这些发现做出最终判断,往往需要人类或其他模型的介入。
四、使用范围:何时该请出这位"探索家"?
适合使用无监督学习的情况:
- 数据没有标签或获取标签成本极高时:这是它的主战场。比如,对海量网络评论进行情感倾向分析,人工一条条标注"正面/负面"几乎不可能,无监督学习可以自动发现评论中的情感簇。
- 想要探索未知数据,发现潜在模式时:比如,市场部门想了解客户有哪些自然形成的细分群体,而不是预先假设。
- 需要为数据"瘦身"或"去噪"时:降维可以简化数据,便于可视化分析;自编码器可以学习过滤噪声。
- 作为复杂任务的"预备步骤":先用无监督学习从大量无标签数据中预训练模型,学到通用特征,再用少量有标签数据微调,完成特定任务。这已成为当前大模型训练的关键流程。
不适合使用无监督学习的情况:
- 任务目标非常明确且需要精确预测时:比如预测明天是否会下雨、判断一张图片是否是猫。这类有清晰"是/否"答案的问题,监督学习通常更直接有效。
- 拥有大量高质量标注数据时:既然有"老师"(标签),直接请"老师"教(监督学习)通常效率更高、结果更可控。
五、应用场景:无处不在的"模式发现者"
无监督学习已经深深嵌入我们的生活与工业中:
-
商品推荐与客户分群(电商平台)
- 作用:通过聚类分析用户的浏览、购买记录,自动将用户划分为"精打细算族"、"品质生活家"、"数码发烧友"等不同群体。即使平台一开始并不知道这些群体叫什么。基于此,可以进行更精准的群体营销和"可能喜欢"的商品推荐。
-
异常检测与安全预警(金融反欺诈、设备运维)
- 作用:通过学习正常用户交易行为(或设备正常运行数据)的模式,无监督模型能够敏锐地识别出"与众不同"的异常点。例如,一笔在异国半夜发生的巨额交易,或工厂传感器传出一组从未有过的读数组合,系统会立即标记为可疑行为或故障前兆,触发警报。
-
图像去噪与超分辨率(手机拍照、医疗影像)
- 作用:训练一个自编码器,输入是带噪声的或模糊的低清图片,输出是清晰的高清图片。网络在训练中学会了如何从受损数据中恢复出干净、清晰的本质特征。你手机相册的"旧照片修复"功能,背后可能就有它的功劳。
-
基因序列分析与生物信息学(药物研发)
- 作用:对成千上万的基因表达数据进行聚类,可以帮助科学家发现那些在特定疾病(如癌症)中表达模式相似的基因簇,这些基因簇可能对应着相同的生物学通路,为靶向药物研发提供关键线索。
总结
无监督学习的核心价值,在于赋予机器一种 "自观察、自组织、自总结" 的探索能力。它不依赖人类预先提供的"标准答案",而是直面数据的海洋,从中提炼出内在的结构、模式与简洁表达。
对于初学者而言,理解无监督学习的关键,在于把握其 "自我驱动" 的哲学:无论是通过"物以类聚"的整理,还是"化繁为简"的概括,抑或是"压缩复原"的游戏,其目的都是让机器学会在未知中寻找秩序。它是人工智能走向更通用、更自主的关键一步,也是我们解开庞大数据背后隐藏故事的一把神奇钥匙。记住,当你面对一堆没有说明书的零件时,无监督学习就是那位能帮你找出它们之间联系的最佳伙伴。