今天凌晨,阿里通义团队发布了下一代基础模型架构 Qwen3-Next,新架构采用高稀疏度 MoE 设计和混合注意力机制,成功将训练成本降低 90% 以上,同时实现长文本推理吞吐量 10 倍的提升。
团队认为 Context Length Scaling 和 Total Parameter Scaling 是未来大模型发展的两大趋势,为进一步提升模型在长上下文和大规模总参数下的训练和推理效率,因此设计了全新的 Qwen3-Next 的模型结构,可以说是大语言模型发展的重要里程碑。
其最引人注目的特点是总参数达到 800 亿,但每次推理仅激活 30 亿参数,却能达到与 Qwen3 旗舰版 235B 模型相媲美的性能。这种设计使得模型计算效率大幅提升,算力利用率约为 3.7%,帮助用户极致省钱。
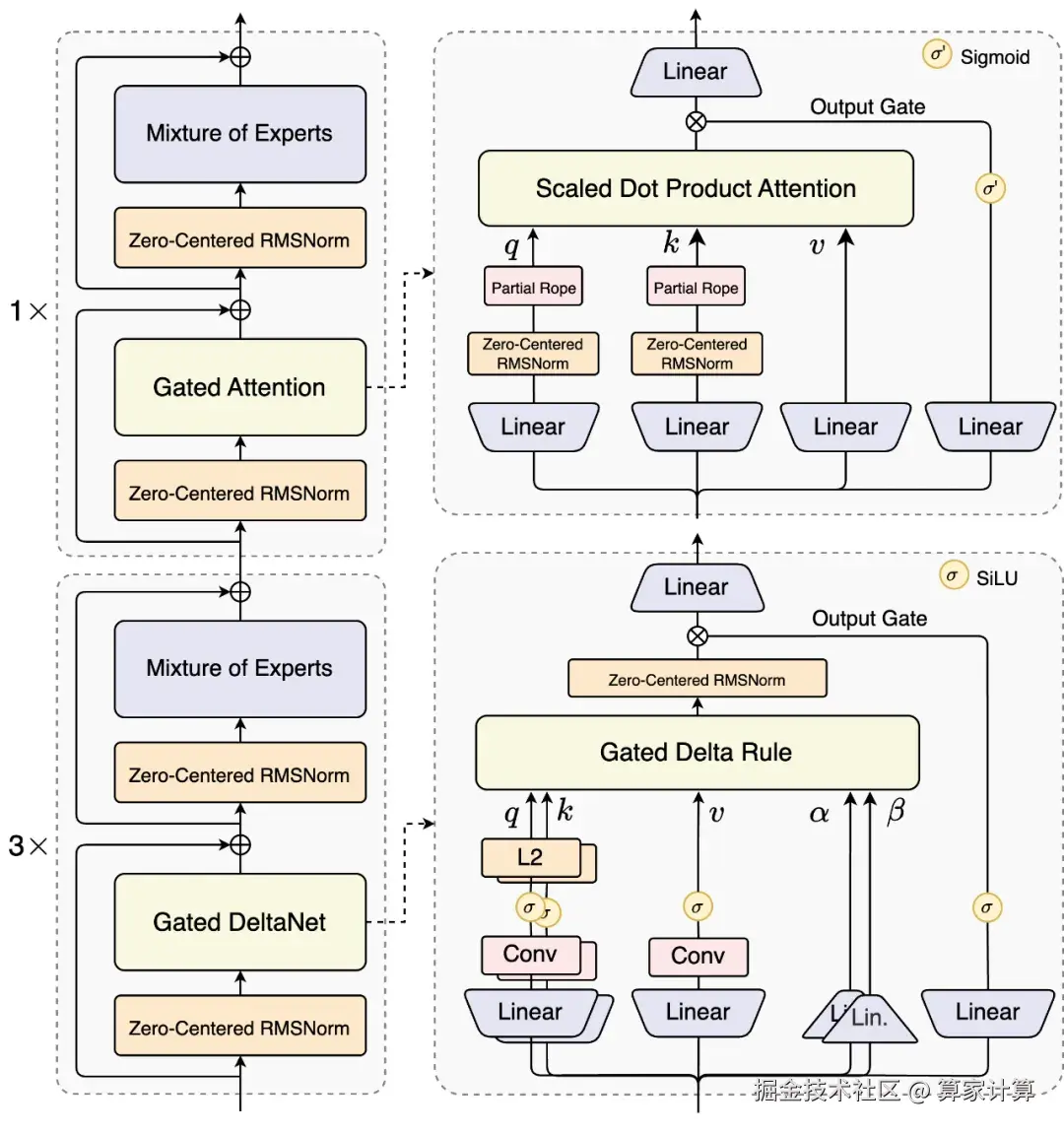
技术架构方面,Qwen3-Next 采用了全球首创的混合注意力机制。75% 的层使用 Gated DeltaNet(线性注意力),25% 的层保留原创的 Gated Attention(门控注意力)。这种混合比例经过系统实验验证,能在长序列建模上实现效率与性能的双重优化。
在 MoE 架构上,Qwen3-Next 实现了极致稀疏度。相比 Qwen3 MoE 的 128 个总专家和 8 个路由专家,新架构扩展到了 512 总专家,10 路由专家与 1 共享专家的组合,实现了 1 比 50 的极致激活比,创下了业界新高。
同时,在训练稳定性方面,Qwen3-Next 引入了多项创新优化。包括采用 Zero-Centered RMSNorm 并施加 weight decay 来避免权重无界增长,以及在初始化时归一化 MoE router 的参数,确保每个专家在训练早期都能被无偏地选中。
多 token 预测机制则是另一项重要创新。Qwen3-Next 引入原生 Multi-Token Prediction 机制,既得到了 Speculative Decoding 接受率较高的 MTP 模块,又提升了主干本身的综合性能。这一机制特别优化了多步推理性能,通过训练推理一致的多步训练,进一步提高了实用场景下的 Speculative Decoding 接受率。
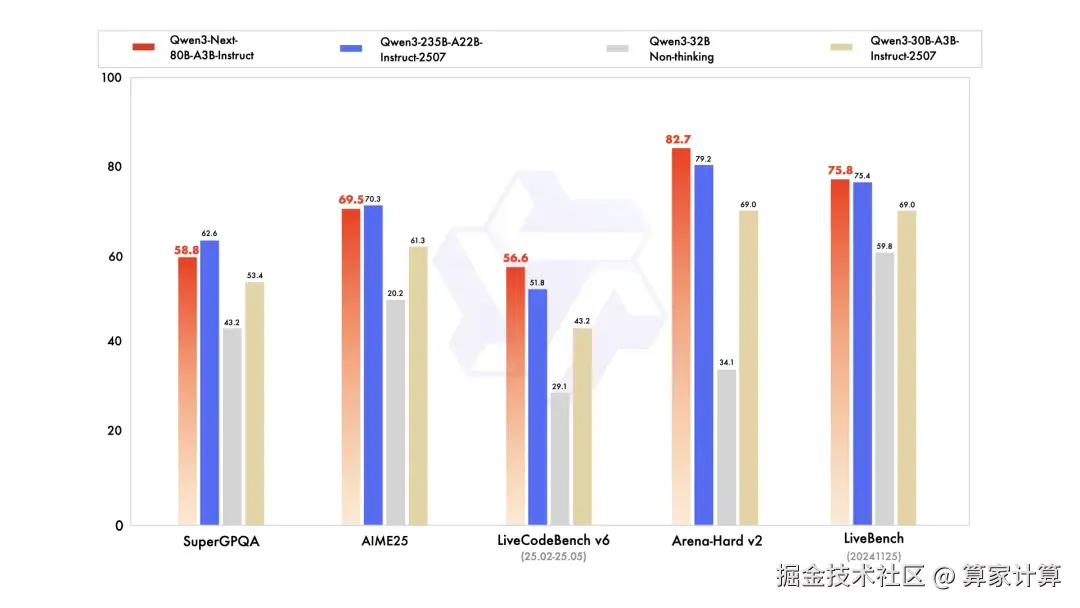
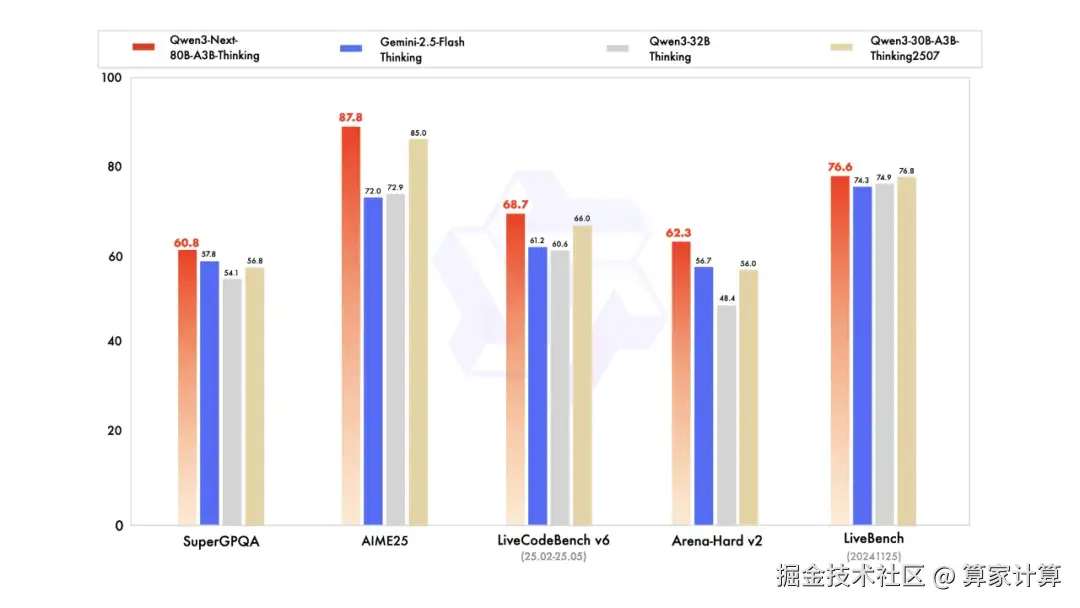
在多个评测中,Qwen3-Next 具有优异的表现。Qwen3-Next-Instruct 在编程、人类偏好对齐以及综合性能力评测中表现甚至超过了千问的开源旗舰模型。Qwen3-Next-Thinking 则全面超越了 Gemini2.5-Flash-Thinking,在数学推理 AIME25 评测中获得了 87.8 分。
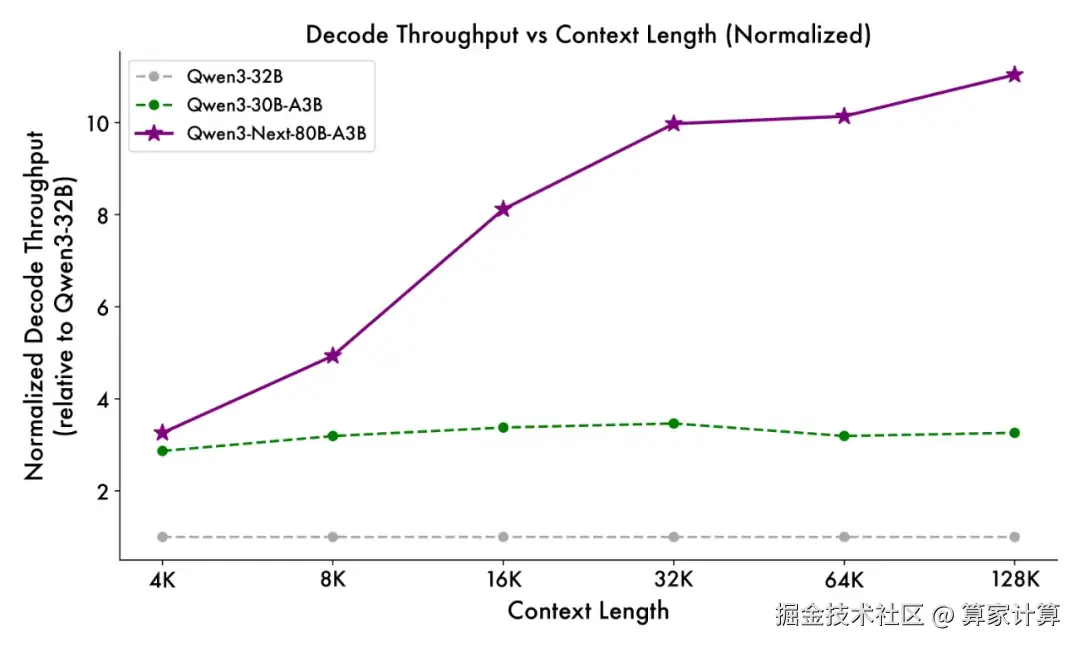
与 Qwen3-32B 相比,新模型在 4k tokens 的上下文长度下,预填充阶段吞吐量接近前者的七倍。当上下文长度超过 32k 时,吞吐提升达到十倍以上。在解码阶段,4k 上下文下实现近四倍的吞吐提升,在超过 32k 的长上下文场景中仍能保持十倍以上的吞吐优势。
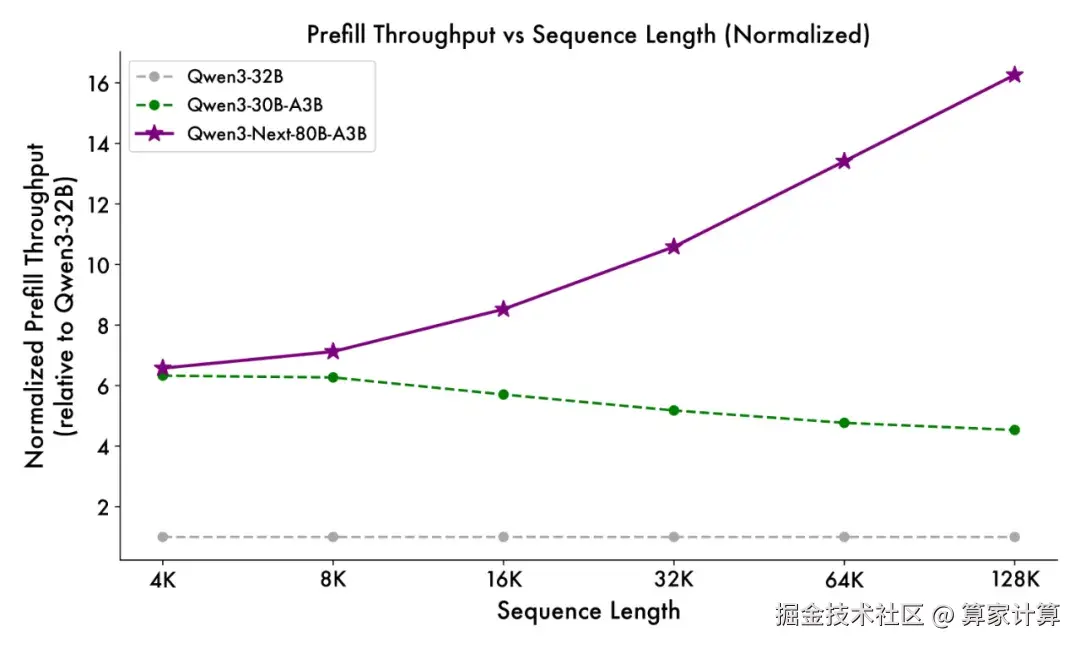
训练成本的大幅降低是新架构的另一大优势。Qwen3-Next 模型训练成本较今年 4 月发布的密集模型 Qwen3-32B 大降超 90%。新模型在 Qwen3 预训练数据的子集 15T tokens 上进行预训练,仅需 Qwen3-32B 所用 GPU 计算资源的 9.3%,便能训练出性能更好的基座模型。
目前,新模型已在魔搭社区和 HuggingFace 开源,开发者也可通过 Qwen Chat 免费体验,或直接调用阿里云百炼平台提供的 API 服务。阿里通义团队开源了 Qwen3-Next-80B-A3B 的指令模型和推理两款模型,解决了混合注意力机制加高稀疏度 MoE 架构在强化学习训练中长期存在的稳定性与效率难题。
Qwen3-Next 的发布标志着大语言模型技术进入新的发展阶段。通过大幅降低训练和推理成本,同时提升模型性能,这一创新将为 AI 技术的普及和应用提供更强有力的支持。
而随着模型的开源,开发者和企业将能够更容易地获得先进的 AI 能力,推动人工智能技术在更多领域的创新应用。