加载图像
image = cv2.imread(filename, flags)
imgae:是imread()方法的返回值,返回的是读取到的图像
filename:要读取的图像文件,路径中尽量不出现中文。
flags:读取图像的颜色标记。默认为1,当为1时,表示读取彩色图像;当为0时,表示读取灰度图像。
若直接使用print()输出为numpy.ndarray数组类型。
显示图像
cv2.imshow(winname, mat)--直接显示,但是一闪而过
winname:显示图像的窗口名称
mat:要显示的图像
retval = waitKey(delay)
等待用户按下键盘的时间,若用户不按下按键或者返回不正确,则一直等待不进行下一步,可以用来输出需要图像显示的时间,到时间后自动关闭
retval:返回被按键的ASCII码。如果没有按键按下则返回-1delay:等待按键按下的时间。若为负数、零或者空的话则表示无限等待。
cv2.destroyAllWindows()
销毁现在显示的所有窗口
窗口交互
创建滑动条
cv2.creatTrackbar(trackbarname, winname, value, count, onChange, userdata)
trackbarname:滑动条的名称
winname:窗口名称
value:指向滑动条的初始值
count:滑动条的最大值
onChange:可选,每次滑动条更改位置时要调用的函数指针,如需要小数则可以将输出值除以10
userdata:传递给回调函数的可选参数
获取滑动条的当前位置
value = cv2.getTrackbarPos(trackbarname, winname)
trackbarname:滑动条的名称
winname:窗口名称
鼠标响应
None = cv2.setMouseCellback(winname, onMouse, userdata)
winname:在其中添加鼠标响应的窗口的名称
onMouse:鼠标响应的回调函数
鼠标响应事件
|-------------------------|----|-------------------|
| 标志 | 简记 | 说明 |
| cv2.EVENT_MOUSEMOVE | 0 | 鼠标指针在窗口上移动 |
| cv2.EVENT_LBUTTONDOWN | 1 | 按下鼠标左键 |
| cv2.EVENT_RBUTTONDOWN | 2 | 按下鼠标右键 |
| cv2.EVENT_MBUTTONDOWN | 3 | 按下鼠标中键 |
| cv2.EVENT_LBUTTONUP | 4 | 释放鼠标左键 |
| cv2.EVENT_RBUTTONUP | 5 | 释放鼠标右键 |
| cv2.EVENT_MBUTTONUP | 6 | 释放鼠标中键 |
| cv2.EVENT_LBUTTONDBLCLK | 7 | 双击鼠标左键 |
| cv2.EVENT_RBUTTONDBLCLK | 8 | 双击鼠标右键 |
| cv2.EVENT_MBUTTONDBLCLK | 9 | 双击鼠标中键 |
| cv2.EVENT_MOUSEWHEEL | 10 | 正值表示向前滚动,负值表示向后滚动 |
| cv2.EVENT_MOUSEHWHEEL | 11 | 正值表示向后滚动,负值表示向前滚动 |鼠标响应标志
|-------------------------|----|----------|
| 标志 | 简记 | 说明 |
| cv2.EVENT_FLAG_LBUTTON | 1 | 按住鼠标左键摇曳 |
| cv2.EVENT_FLAG_RBUTTON | 2 | 按住鼠标右键摇曳 |
| cv2.EVENT_FLAG_MBUTTON | 4 | 按住鼠标中键摇曳 |
| cv2.EVENT_FLAG_CTRLKEY | 8 | 按下Ctrl键 |
| cv2.EVENT_FLAG_SHIFTKEY | 16 | 按下Shift键 |
| cv2.EVENT_FLAG_ALTKEY | 32 | 按下Alt键 |userdata:可选,传递给回调函数的参数,其默认为0
import cv2 import numpy as np import sys def darw(event, x, y, flags ,param): # 要传入5个参数 global img, pre_pts if event == cv2.EVENT_LBUTTONDOWN: pre_pts = (x, y) elif event == cv2.EVENT_MOUSEMOVE and flags == cv2.EVENT_FLAG_LBUTTON: pts = (x, y) img = cv2.line(img, pre_pts, pts, (0, 0, 255), 5) pre_pts = pts cv2.imshow('img', img) if __name__ == '__main__': img = cv2.imread('images/alien.bmp') if img is None: sys.exit() pre_pts = (0, 0) cv2.imshow('img', img) cv2.setMouseCallback('img', darw) cv2.waitKey(-1) cv2.destroyAllWindows()此代码主要实现在图像上使用鼠标进行写字或画图
保存图像
cv2.imwrite(path, filename)
path:要将图像保存的路径
filename:要保存的文件
获取图像属性--维度大小、像素个数、数据类型
shape
返回数组的每个维度的大小
若使用shape(:2),其为切片操作,取前两个元素
对于灰度图:
(480, 640)[:2]→(480, 640)对于彩色图:
(480, 640, 3)[:2]→(480, 640)
size
获得图像包含的像素个数
dtype获取图像的数据类型
色彩空间转换
dst = cv2.cvtColor(filename, code)--RGB/BGR色彩空间转化为GRAY色彩空间
dst:转换后的图像
filename:需要转换的图像
BGR/RGB色彩空间:有蓝黄红/红黄蓝三原色组成的色彩空间(opencv采用的是BGR色彩空间)HSV:H--光的颜色 S--饱和度 V--亮度(等于0时为纯黑色)
GRAY:对于三原色则比例相同,对于HSV则饱和度(S)为0
code:色彩空间转换码
cv2.COLOR_BGR2GRAY--从BGR色彩空间转换到GRAY色彩空间(opencv使用的)
cv2.COLOR_RGB2GRAY--从RGB色彩空间转换到GRAY色彩空间(平常使用的)
反着的转换码也存在,但由于灰度图像失去原本的红黄蓝比例,故无法转化为彩色图像
cv2.COLOR_BGR2HSV--从BGR色彩空间转换到HSV色彩空间
拆分通道
b, g, r = cv2.split(image)
b:B通道图像 g:G通道图像 r:R通道图像
image:BGR图像
b, g ,r为二维的array数组
当提取出来后,要显示对应通道的图像,但由于图像是三维的,因此将三个通道均改成对应通道的值,从而会得到三张不同亮度的灰度空间图像
对于BGR,可以将其转化为BGRA,一共四个通道,其中A表透明度(0表示透明,255表示不透明)---png文件则为BGRA色彩空间
h, s, v = cv2.split(image)
h:H通道图像 s:S通道图像 v:V通道图像
h, s, v为二维的array数组
image:HSV图像
合并通道
bgr = cv2.merge(b, g, r)/rgb = cv2.merge(r, g, b)--hsv同理
bgr/rgb:合并后得到的图像
b:B通道图像 g:G通道图像 r:R通道图像
若要获得拆分前的原图像则只能使用bgr
归一化处理
cv2.normalize(src, dst, alpha, beta, norm_type, dtype, mask)
src:输入图像
dst:输出图像
alpha:范围下限(最大最小归一化时)或范数值(其他归一化类型时)
beta:范围上限(最大最小归一化时),其他类型忽略
norm_type:归一化类型
|-----------------|--------------------------|
| cv2.NORM_MINMAX | 将值线性缩放到alpha, beta范围 |
| cv2.NORM_L1 | 范数归一化,其绝对值之和为1 |
| cv2.NORM_L2 | 范数归一化,其平方和的平方根为1 |
| cv2.NORM_INF | 最大值归一化,基于最大值归一化 |dtype:输出图像的数据类型
mask:可选,图像掩膜
图像连接
dst = cv2.vconcat(src)--垂直连接
dst = cv2.hconcat(src)--水平连接
scr:需要拼接的图像,为一个元组类型,其每一个元素都是要拼接的原始图像,但是每一个原始图像都应具有相同的长度、数据类型和通道数
dst:拼接后的图像
绘制图形
绘制线段
img = cv2.line(img, pt1, pt2, color, thickness)
img:画布
pt1:线段的起点坐标
pt2:线段的终点坐标
color:绘制线段时的线条颜色(BGR)
thickness:绘制线段时的线条宽度
绘制矩形
img = cv2.rectangle(img, pt1, pt2, color, thickness)/img = cv2.rectangle(img, rec, color, thickness)
img:画布
pt1:矩形的左上角坐标
pt2:矩形的右下角坐标
color:绘制矩形时的线条颜色(BGR)
thickness:绘制矩形时的线条宽度(当为-1时,为绘制实心矩形)
rec:矩形的左上角顶点和矩形的长和宽
绘制圆形
img = cv2.circle(img, center, radius, color, thickness)
img:画布
center:圆形的原点坐标
radius:圆形的半径
color:绘制圆形时的线条颜色(BGR)
thickness:绘制圆形时的线条宽度(当为-1时,为绘制实心圆形)
绘制多边形
img = cv2.polylines(img, pts, isClosed, color, thickness)
img:画布
pts:有多边形各个顶点的坐标组成为一个列表,这个列表为Numpy的二维数组类型
isClosed:bool型。True表示图形封闭,False表示图形不封闭。
color:绘制多边形时的线条颜色(BGR)
thickness:绘制多边形时的线条宽度(当为-1时,为绘制实心多边形)
绘制文字
img = cv2.putText(img, text, org, fontFace, fontScale, color, thickness, lineType, bottomLeftOrigin)
img:画布
text:要绘制的文本内容--一般显示英文,若要显示中文则需PIL模块
org:文字在画布中,文本左下角坐标
fontFace:字体样式
|-----------------------------|---------------------------------------------------|
| 字体样式 | 含义 |
| FONT_HERSHEY_SIMPLEX | 正常大小的sans-serif字体 |
| FONT_HERSHEY_PLAIN | 小号的sans-serif字体 |
| FONT_HERSHEY_DUPLEX | 正常大小的sans-serif字体 (比FONT_HERSHEY_SIMPLEX字体样式更加复杂) |
| FONT_HERSHEY_COMPLEX | 正常大小的serif字体 |
| FONT_HERSHEY_TRIPLEX | 正常大小的serif字体 (比FONT_HERSHEY_COMPLEX字体样式更加复杂) |
| FONT_HERSHEY_COMPLEX_SMALL | FONT_HERSHEY_COMPLEX字体样式的简化版 |
| FONT_HERSHEY_SCRIPT_SIMPLEX | 手写风格的字体 |
| FONT_HERSHEY_SCRIPT_COMPLEX | FONT_HERSHEY_SCRIPT_SIMPLEX字体样式的进阶版 |
| FONT_ITALIC | 斜体(可以和其他字体一起连用) |fontScale:字体大小
color:绘制文字时的线条颜色(BGR)
thickness:绘制文字时的线条宽度
lineType:线型(线的产生算法,有4和8两个值,默认值为8)
bottomLeftOrigin:绘制文字的方向(bool型,默认为False)--True表示文字垂直镜像
直方图
直方图用于统计图像中每个灰度值的个数,并将统计结果通过值返回
通过直方图可以分析图像的亮暗对比度,并通过一定的方法进行映射从而调整图像的亮暗程度
直方图计算--画图可以使用matplotlib
hist = cv2.calcHist(images, channels, mask, histSize, ranges, accumlate)
images:带计算直方图的图像
channels:需要统计的通道索引
mask:图像掩膜,若为原图像为掩膜则输入None
histSize:存放每个维度直方图的数组尺寸
ranges:每个图像通道中灰度值的取值范围
accumlate:可选,表示是否积累统计直方图的标志,用于统计多个直方图
hist:输出的直方图,是一个histSize×1的数组
直方图比较
retval = cv2.compareHist(H1, H2, method)--可用于分析两张图的相似性
H1:第一幅图的直方图数据
H2:第二幅图的直方图数据
method:比较方法的标志
|---------------------------|----|--------|-------|
| 标志 | 简记 | 说明 | 相关性 |
| cv2.HISTCMP_CORREDL | 0 | 相关法 | 越大越相关 |
| cv2.HISTCMP_CHISQR | 1 | 卡方法 | 越小越相关 |
| cv2.HISTCMP_INTERSECCT | 2 | 直方图相交法 | 越大越相关 |
| cv2.HISTCMP_BHATTACHARYYA | 3 | 巴氏距离法 | 越小越相关 |
| cv2.HISTCMP_HELLINGER | 3 | 与上一个相同 | 越小越相关 |
| cv2.HISTCMP_CHISQR_ALT | 4 | 替代卡方法 | 越小越相关 |
| cv2.HISTCMP_KL_DIV | 5 | 相对熵法 | 越小越相关 |
直方图均衡化--提高对比度
dst = cv2.equalizeHist(src)
src:需要直方图均衡化的8位单通道图像--即灰度图像或者彩色图像的任一通道
dst:直方图均衡化后的输出图像,与src具有相同的尺寸和类型
阈值处理
一般阈值处理
retval, dst = cv2.threshold(src, thresh, maxval, type)
src:被处理的图像,可以为多通道图像
thresh:阈值,阈值在125-150范围内取值效果最好
maxval:阈值处理采用的最大值
type:阈值处理类型
|----------------------|-------------------------------------------------------|
| 类型 | 含义(0像素为纯黑色,默认最大值为255,为白色) |
| cv.THRSEH_BINARY | 二值化阈值处理 if 像素值 <= 阈值:像素值 = 0 if 像素值 > 阈值:像素值 = 最大值 |
| cv.THRSEH_BINARY_INV | 反二值化阈值处理 if 像素值 <= 阈值:像素值 = 最大值 if 像素值 > 阈值:像素值 = 0 |
| cv.THRSEH_TOZERO | 低于阈值零处理 if 像素值 <= 阈值:像素值 = 0 if 像素值 > 阈值:像素值 = 原值 |
| cv.THRSEH_TOZERO_INV | 超出阈值零处理 if 像素值 <= 阈值:像素值 = 原值 if 像素值 > 阈值:像素值 = 0 |
| cv.THRSEH_TRUNC | 截断阈值处理 if 像素值 <= 阈值:像素值 = 原值 if 像素值 > 阈值:像素值 = 阈值 |retval:处理时采用的阈值
dst:经过阈值处理后的图像
寻找合适的阈值--Otsu方法
retval, dst = cv2.threshold(src, thresh, maxval, type)--类似于上面的threshold函数
src:被处理的图像。需是灰度图像
thresh:阈值,且要把阈值设置为0
maxval:阈值处理采用的最大值,即255
type(区别):阈值处理类型,除了在之前的阈值处理类型中选择一个,还需在后面添加'+ cv2.THRESH_OTSU'
retval:由Otsu方法计算得到并使用的最合适的阈值
dst:经过阈值处理后的图像
自适应阈值处理
dst = cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C)
scr:被处理的图像,需是灰度图像
maxValue:阈值处理采用的最大值
adaptiveMethod:自适应阈值计算方法
|--------------------------------|---------------------------------------|
| 类型 | 含义 |
| cv2.ADAPTIVE_THRESH_MEAN_C | 对一个正方形区域内的所有像素平均加权 |
| cv2.ADAPTIVE_THRESH_GAUSSIAN_C | 根据高斯函数按照像素与中心点的距离对一个正方形区域内的所有像素进行加权计算 |thresholdType:阈值处理类型--仅还有二值化和反二值化阈值处理类型
blockSize:一个正方形区域的大小
C:常量。阈值等于均值或者加权值减去这个常量
dst:经过阈值处理后的图像
图像查找表--1D LUT
可以用于阈值处理,对于简单的颜色变换、对比度调整、二值化等操作,1D LUT的速度非常快且高效。
但是对于较为复杂的色彩分级,比如电影的质感和色彩对比需要3D LUT,opencv不包含3D LUT,若需要可以下载插件imageio.v3
dst = cv.LUT(src, lut)
src:输入图像
lut:256个灰度值的查找表,一个一维数组。当像素值为i时,输出luti
dst:输出图像
import cv2 import numpy as np # 读取灰度图 image = cv2.imread('input.jpg', 0) # 创建二值化查找表 # 假设阈值为 127,小于127的变为0(黑),大于等于的变为255(白) lut = np.zeros(256, dtype=np.uint8) lut[127:] = 255 # 从索引127开始到末尾,所有值都设为255 # 应用查找表 binary_image = cv2.LUT(image, lut) # 显示结果 cv2.imshow('Original', image) cv2.imshow('Binary', binary_image) cv2.waitKey(0) cv2.destroyAllWindows()
更改图像大小比例
dst = cv2.resize(src, dsize, fx, fy, interpolation)--若dsize和fx、fy同时存在,则后面的fx、fy无效
src:原始图像
dsize:输出图像的大小,格式为(宽, 高)
fx:可选,水平缩放比例
fy:可选,垂直缩放比例
interpolation:可选,缩放的插值方法。
在图像放大或缩小时需要缩减或补充像素,该参数用于指定使用哪种算法对像素进行增减
dst:缩放之后的图像
针对于插值方法:其主要代码以c++为主常用的包含:cv2.INTER_LINEAR 双线性插值
cv2.INTER_NEAREST 最近邻插值
cv2.INTER_CUBIC 双三次插值
cv2.INTER_AREA 区域插值
详细的看一看:
用法:https://blog.51cto.com/u_16213385/11512979
解析(以双线性和区域插值为主):详解opencv resize之INTER_LINEAR和INTER_AREA_cv:resize-CSDN博客
以自己理解,默认插值方法和平时一般使用的插值方法为cv2.INTER_LINEAR--双线性插值。
放大图像一般使用cv2.INTER_LINEAR--双线性插值,当放大比例过大时,需要较高精度,则使用cv2.INTER_CUBIC--双三次插值;缩小图像一般使用 cv2.INTER_AREA --区域插值
翻转
dst = cv2.flip(src, flipCode)
src:原始图像
flipCode:翻转类型
|-----|------------|
| 参数值 | 含义 |
| 0 | 沿着X周轴翻转 |
| 正数 | 沿着Y轴翻转 |
| 负数 | 同时沿着X、Y轴翻转 |dst:翻转后的图像
仿射变换
dst = cv2.warpAffine(src, M, dsize, flags, borderMode, borderValue)
scr:原始图像
M:一个2行3列的矩阵,根据此矩阵的值变换原图中的像素位置--M通过下面的函数求解
M = \[a, b, c, d, e, f]--可以通过numpy来创建
新x = 原x * a + 原y * b + c
新y = 原x * d + 原y * e + f
dsize:输出图像的尺寸大小
flags:可选,插值方法
borderMode:可选,边界类型
borderValue:可选,边界值
dst:经过仿射变换后输出图像
若要实现平移--M = \[1, 0, 水平移动的距离, 0, 1, 垂直移动的距离]旋转
M = cv2.getRotationMatrix2D(center, angle, scale)
center:旋转的中心点坐标
angle:旋转的角度。正数为逆时针旋转,负数为顺时针旋转
scale:缩放比例,浮点数
M:计算出的仿射矩阵
然后将M带入上面的函数中
倾斜
M = cv2.getAffineTransform(src, dst)
scr:原图的三个点坐标,格式为3行2列的32为浮点数列表
dst:倾斜图像的三个点坐标,格式与scr中的相同
M:计算出的仿射矩阵
然后将M带入上面的函数中
图像运算
加减法运算
dst = cv2.add(src1, src2, mask, dtype)--加法运算
dst = cv2.substact(src1, src2, mask, dtype)--减法运算
src1:第一幅图像
src2:第二幅图像
mask:可选,掩膜
dtpe:可选,图像深度
dst:相加之后的图像,若结果大于255,则取255/相减之后的图像,若结果小于0,则取0
若是直接对两张图像使用'+'运算符,则当其结果超过255时,其像素取除以255的余数,即取模运算
与运算
dst = cv2.bitewise_and(scr1, scr2, mask)
或运算
dst = cv2.bitewise_or(src1, src2, mask)
取反运算
dst = cv2.bitewise_nor(src1, scr2, mask)
异或运算
dst = cv2.bitewise_xor(src1, src2, mask)
卷积
卷积通过给出的卷积核分别与图像对应位置的元素相乘,然后相加把结果转给计算的位置
因此一般情况来说,卷积后图像各个元素的值都会增大,因此为了保持亮度的不变,可以对元素进行归一化处理
但是对于边缘的细节来说,其本身的细节就较暗,使用卷积后增大其的亮度从而使边缘的细节信息更加清楚
总的来说,就是对于需要增强亮度和对比度的图像,使用没有归一化的卷积核,而对于需要保持总体亮度和对比度的图像,则使用归一化后的卷积核
dst = cv2.filter2D(src, ddepth, kernel, anchor, delta, borderType)
src:输出图像
ddepth:输出图像的数据类型(深度),当为-1时,其与输出图像的数据类型相同
kernel:单通道卷积核,大小多为3×3、5×5,数据类型为float32
anchor:可选,卷积模块的内核基准点(锚点)
delta:可选,在计算结果中想要加入的偏差
borderType:可选,边界填充方式,默认为cv2.BORDER_REFLECT_101
|------------------------|-------|-----------------|
| cv2.BORDER_CONSTANT | 常数填充 | 使用0填充边界 |
| cv2.BORDER_REPLICATE | 复制边缘 | 复制最边缘的像素值填充 |
| cv2.BORDER_REFLECT | 反射填充 | 反射图像边界(包括边界像素) |
| cv2.BORDER_REFLECT_101 | 反射101 | 反射图像边界(不包括边界像素) |
| cv2.BORDER_WRAP | 包装填充 | 将图像对侧边界包装过来 |dst:输出图像
噪声
椒盐噪声
又称脉冲噪声,会随机改变图像的像素值,是相机、传输通道、解码处理等过程中产生的黑白相间的亮暗点噪声。
opencv无特定的椒盐噪声生成函数
import numpy as np def add_noise(image, n = 10000): result = image.copy() # 产生了椒盐噪声的图像 w, h = image.shape[:2] for i in range(n): # 分别在宽和高的范围内生成一个随机数,模拟代表(x, y)的坐标值 x = np.random.randint(1, w) y = np.random.randint(1, h) if np.random.randint(0, 2) == 0: # 生成白噪声(盐噪声) result[x, y] = 0 else: # 生成黑噪声(椒噪声) result[x, y] = 255 return result
高斯噪声
其是指噪声分布的概率密度函数服从高斯分布(正态分布)的一类噪声,其产生的主要原因是在拍摄时视场较暗且亮度不均匀,或是相机长时间工作使得元器件温度较高。
opencv无特定的高斯噪声生成函数
import numpy as np def add_noise(image, mean = 0, val = 0.01): size = image.shape image = image/255 gauss = np.random.normal(mean, val ** 0.5, size) noise = image + gauss return gauss, noise # 高斯噪声,添加高斯噪声的图像
滤波器
线性滤波
均值滤波器
均值滤波器指将每一个元素均当成"滤波核",计算每一个元素核内所有像素的平均值,最后该滤波核等于这个平均值
简单快速,但效果一般,常用于简单的预处理
dst = cv2.blur(src, ksize, anchor, borderType)
src:被处理的图像
ksize:滤波核的大小,格式一般为奇数边长--(3, 3)等,其值越大,处理后的图像越模糊
anchor:可选,滤波核的锚点,默认为自动计算锚点
borderType:可选,边界样式,与卷积中的可选参数相同
dst:处理后的图像
方框滤波器
其为均值滤波的一种形式,但是方框滤波在求得滤波器内所有像素值的和后不会进行归一化处理
dst = cv2.boxFilter(src, ddepth, ksize, anchor, normalize, borderType)
src:被处理的图像
ddepth:输出图像的数据类型(深度),当为-1时,其与输出图像的数据类型相同
ksize:卷积核的大小
anchor:可选,卷积模块的内核基准点(锚点)
normalize:可选,表示是否将卷积核按照其他区域进行归一化的标志,默认为True(不进行归一化)
borderType:可选,边界样式,与卷积中的可选参数相同
dst:处理后的图像
扩展方框滤波
其为均值滤波的一种形式,为方框滤波的扩展,其滤波求滤波器内所有像素值平方的和后,再说明是否进行归一化处理
dst = cv2.sqrBoxFilter(src, ddepth, ksize, anchor, normalize, borderType)
src:被处理的图像
ddepth:输出图像的数据类型(深度),当为-1时,其与输出图像的数据类型相同
ksize:卷积核的大小
anchor:可选,卷积模块的内核基准点(锚点)
normalize:可选,表示是否将卷积核按照其他区域进行归一化的标志,默认为True(不进行归一化)
borderType:可选,边界样式,与卷积中的可选参数相同
dst:处理后的图像
高斯滤波器
高斯滤波器与均值滤波器的区别在于其滤波核区域中的各个元素的权重不是完全相等的,而是越靠近滤波核的元素权重越大,反之越小,通过高斯函数和卷积的复杂运算从而得到一个值将其赋值给该滤波核
目前最常用的噪音处理方式,对高斯噪声效果好,更好地保留了图像的总体结构,但是对椒盐噪声效果一般
dst = cv2.GaussianBlur(src, ksize, sigmaX, sigmaY, borderType)
src:被处理的图像
ksize:滤波核的大小,格式一般为奇数边长--(3, 3)等,其值越大,处理后的图像越模糊
sigmaX:卷积核水平方向的标准差
sigmaY:卷积核垂直方向的标准差
修改sigmaX和sigmaY都会改变卷积核中的权重比例。如果不知道如何设计这两个参数值,则可以直接将这两个参数的值写为0,方法会根据滤波核的大小自动计算出合适的权重比例
borderType:可选,边界样式,与卷积中的可选参数相同
dst:处理后的图像
可分离滤波
dst = cv2.sepFilter2D(src, ddepth, kernelX, kernelY, anchor, delta, borderType)
src:被处理的图像
ddepth:输出图像的数据类型(深度),当为-1时,其与输出图像的数据类型相同
kernelX:x方向的滤波器
kernelY:y方向的滤波器
anchor:可选,卷积模块的内核基准点(锚点)
delta:可选,在计算结果中想要加入的偏差
borderType:可选,边界样式,与卷积中的可选参数相同
dst:处理后的图像
非线性滤波
中值滤波器
中值滤波器的原理与均值滤波器相似,只有最后一步不计算平均值,而是滤波核内所有的元素从小到大依次排序,取中间值赋值给该滤波核
对椒盐噪声效果好,且能保护边缘,常用于去除椒盐噪声
dst = cv2.medianBlur(src, ksize)
src:被处理的图像
ksize:滤波核的大小,格式一般为奇数边长--(3, 3)等,其值越大,处理后的图像越模糊
dst:处理后的图像
双边滤波器
双边滤波器与高斯滤波器类似,但是会加大边缘元素的权重,尽可能的使这些像素值不变
在平滑的同时能很好地保持边缘,同时对于高斯噪声和交验噪声都有很好的效果,但是对于强噪声则效果一般,同时计算相对缓慢,不适用于实时计算
同时对于其函数中的sigmaColor,sigmaSpace均不容易赋值
dst = cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace, borderType)
src:被处理的图像
d:以当前像素为中心的整合滤波区域的直径,如果d<0,则自动根据sigmaSpace参数计算得到。该值与保留的边缘信息数量成正比,与方法的运行效率成反比
小值(5-9):细节保持更好,处理更快
大值(>15):平滑效果更强,但处理慢
sigmaColor:参与计算的颜色范围,这个值是像素颜色与周围颜色的最大差值,只有颜色值之差小于这个值是,周围的元素才会开始进行滤波计算
小值(10-30):只有非常相似的颜色会被平滑
大值(75-150):允许更大颜色差异的像素参与平滑
sigmaSpace:坐标空间的σ值,该值越大,参与计算的元素越多
小值(10-30):只有很近的像素参与平滑
大值(75-150):更远的像素也能参与平滑
borderType:可选,边界样式,与卷积中的可选参数相同
dst:处理后的图像
导向滤波
它利用一张引导图像(可以是输入图像本身或其他图像)来对目标图像进行滤波,使得输出图像在引导图像的边缘处保持边缘,在平滑区域保持平滑
边缘保持性好,甚至优于双边滤波且计算效率高但是需要合适的引导图像
dst = cv2.ximgproc.createGuidedFilter(guide, radius, eps, dst\[, dDepth])
或者(下面的更加常用)
guided_filter = cv2.ximgproc.createGuidedFilter(guide, radius, eps)
dst = guided_filter.filter(src)
guide: 引导图像(1通道或3通道)--可以使用自身图像
radius: 滤波窗口半径
小值(2-8):保持更多细节,平滑效果弱
大值(16-64):平滑效果强,可能损失细节
eps: 正则化参数,控制平滑程度--对滤波影响非常大
小值(0.0001-0.01):边缘保持强,平滑效果弱
大值(0.04-0.16):平滑效果强,边缘可能模糊
src: 输入图像
dDepth: 输出图像深度
对于使用自身进行自适应滤波,由于其复杂的运算,因此首先需要将自身图像转化为np.float32浮点数类型,但是转化为浮点数后其速度下降,同时会使用很大内存一般只有在需要最高精度或进行复杂数学运算时,才必须转换为浮点数
img_float = image.astype(np.float32)
像素距离计算
欧氏距离
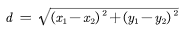
街区距离
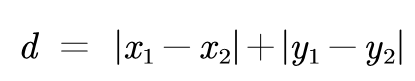
棋盘距离
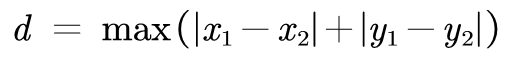
dst, labels = cv2.distanceTransformWithLabels(src, distanceType, maskSize, labelType)--(生成离散Voronoi图)
dst = cv2.distanceTransform(src, distanceType, maskSize, dstType)--(不生成离散Voronoi图)
src:输入图像
distanceType:选择计算两个像素之间距离的方法
|---------------|----|-------|
| 标志 | 简记 | 含义 |
| cv2.DIST_USER | -1 | 自定义距离 |
| cv2.DIST_L1 | 1 | 街区距离 |
| cv2.DIST_L2 | 2 | 欧式距离 |
| cv2.DIST_C | 3 | 棋盘距离 |maskSize:可选,距离变换掩膜矩阵的大小,默认为3×3
|-----------------|----|----------|
| 类型 | 简记 | 含义 |
| cv2.DIST_MASK_3 | 3 | 掩膜尺寸为3×3 |
| cv2.DIST_MASK_5 | 5 | 掩膜尺寸为5×5 |labelType:可选,要构建的标签数组的类型
|----------------------|----|-----------------------------------------|
| 类型 | 简记 | 含义 |
| cv2.DIST_LABEL_CCOMP | 0 | 输入图像中每个连接的零像素以及最接近连接区域的所有非零像素都被分配到相同的标签 |
| cv2.DIST_LABEL_PIXEL | 1 | 输入图像中每个连接的零像素以及最接近连接区域的所有非零像素都有自己的标签 |dst:与输入图像具有相同尺寸的输出图像
labels:与输入图像具有相同尺寸的二维标签数组(离散Voronoi图)
dstType:可选,输出图像的数据类型
选择欧式距离,当尺寸为3×3时,计算较为粗略;当尺寸为5×5时,计算较为精细,但是用时更多,因此一般选择5×5选择棋盘距离和街区距离时,掩膜尺寸对其计算无具体影响,因此选择3×3以加快计算
连通域
简单--仅有包含连通域的图像
retval, labels = cv2.connectedComponentsWithAlgporithm(image, connectivity, ltype, ccltype)
或
retval, labels = cv2.connectedComponents(image, connectivity, ltype)
image:待标记不同连通域的单通道图像
connectivity:(可选,)标记连通域时使用的邻域种类
ltype:(可选,)输出图像的数据类型
ccltype:标记不同连通域使用的算法,一般使用cv2.CCL_DEFAULT
|-----------------|----|--------------------------|
| 标志 | 简记 | 含义 |
| cv2.CCL_WU | 0 | 8领域使用的SAUF算法,4领域使用SAUF算法 |
| cv2.CCL_DEFAULT | -1 | 8领域使用的BBDT算法,4领域使用SAUF算法 |
| cv2.CCL_GRANA | 1 | 8领域使用的BBDT算法,4领域使用BBDT算法 |retval:图像中连通域的数目
labels:图像的标签结果矩阵,0表示图像中的背景区域
第二个函数为第一个函数的简化版,第一个函数的所有参数都必须填写使用该函数之前应该提前将图像进行二值化处理
对于ccltype中的SAUF算法是一个高效、自适应的通用算法,而BBDT是一个利用块处理和决策树来追求极限速度的高性能算法。
进阶-包括连通域的数量、面积等
retval, labels, stats, centroids = cv2.connectedComponentsWithStatsWithAlgporithm(image, connectivity, ltype, ccltype)
image:待标记不同连通域的单通道图像
connectivity:标记连通域时使用的邻域种类
ltype:输出图像的数据类型
ccltype:标记不同连通域使用的算法,一般使用cv2.CCL_DEFAULT
|-----------------|----|--------------------------|
| 标志 | 简记 | 含义 |
| cv2.CCL_WU | 0 | 8领域使用的SAUF算法,4领域使用SAUF算法 |
| cv2.CCL_DEFAULT | -1 | 8领域使用的BBDT算法,4领域使用SAUF算法 |
| cv2.CCL_GRANA | 1 | 8领域使用的BBDT算法,4领域使用BBDT算法 |retval:图像中连通域的数目
labels:图像的标签结果矩阵,0表示图像中的背景区域
stats:不同连通域的统计信息矩阵,通过有N个连通域,则其尺寸为N×5
|--------------------|--------|------------------------------------|
| 标志 | 简记(顺序) | 作用 |
| cv2.CC_STAT_LEFT | 0 | 连通域内最左侧像素的x坐标,它是水平方向上包含连通域边界框的开始坐标 |
| cv2.CC_STAT_TOP | 1 | 连通域内最上方像素的y坐标,它是垂直方向上包含连通域边界框的开始坐标 |
| cv2.CC_STAT_WIDTH | 2 | 包含连通域边界框的水平长度 |
| cv2.CC_STAT_HEIGHT | 3 | 包含连通域边界框的垂直长度 |
| cv2.CC_STAT_AREA | 4 | 连通域面积(以像素为单位) |centroids:每个连通域的质心坐标
矩
区别
|-----|---------------|-------------|--------------------|
| 名称 | 核心思想 | 不变性 | 主要用途 |
| 空间矩 | 基于原始坐标的原始矩 | 无 | 计算面积、质心;是其他矩的基础 |
| 中心矩 | 以质心为原点,消除位置影响 | 平移不变性 | 描述形状本身;是计算Hu矩的中间步骤 |
| Hu矩 | 对中心矩进行归一化和组合 | 平移、旋转、缩放不变性 | 形状识别与分类的核心工具 |流程:
在图像中找到所有连通区域。
对每个区域计算其空间矩,得到质心和面积。
利用质心计算该区域的中心矩。
由中心矩计算出7个Hu矩,得到一个描述该区域形状的7维特征向量。
将这个特征向量与模板库中字母'A'的Hu矩特征向量进行比较(例如,计算欧氏距离或余弦相似度)。
如果距离足够小,则认为该区域是字母'A'。无论这个'A'在图像的哪个位置、有多大、或者有轻微旋转,都能被正确识别
空间矩和中心矩
retval = cv2.moments(array, binaryImage)
array:待计算区域的2D像素坐标集合或单通道数据类型为uin8的图像,在检测图像轮廓中的 contoursi
binaryImage:可选,是否将所有非零像素视为1的标志
retval:图像的空间矩、中心距和归一化的中心距,字典类型
|---------|-----------------------------------------|
| 种类 | 属性 |
| 空间矩 | m00、m10、m01、m20、m11、m02、m30、m21、m12、m03 |
| 中心距 | mu20、mu11、mu02、mu30、mu21、mu12、mu03 |
| 归一化的中心距 | nu20、nu11、nu02、nu30、nu21、nu12、nu03 |其中矩后面的数字则是计算公式中像素(x, y)的次方数,00则为0阶矩,01则为1阶矩
特殊的有m00指物体的面积;m10、m01可以用于计算物体的质心2
mu20指在x方向上的伸展程度(方差);mu02指在y方向上的伸展程度(方差);mu11则是指图像区域的协方差,用于描述形状的朝向
其余更高阶的矩则是有其他的分布特性
Hu矩
hu = cv2.HuMoments(m)
m:输入的图像矩--为上面的array字典
hu:输出Hu矩的矩阵,为ndarray对象参数
腐蚀与膨胀
腐蚀--使图像沿着自己的边界向内收缩
dst = cv2.erode(src, kernel, anchor, iterations, borderType, borderValue)
scr:原始图像
kernel:腐蚀使用的核
anchor:可选,核的锚点
iterations:可选,腐蚀操作的迭代次数,默认为1
borderType:可选,边界样式
borderValue:可选,边界值
dst:处理后的图像
膨胀--使图像沿着自己的边界向外扩张
dst = cv2.dilate(src, kernel, anchor, iterations, borderType, borderValue)
scr:原始图像
kernel:膨胀使用的核
anchor:可选,核的锚点
iterations:可选,膨胀操作的迭代次数,默认为1
borderType:可选,边界样式
borderValue:可选,边界值
dst:处理后的图像
开运算
将图像先进行腐蚀操作,然后进行膨胀操作
可以用来消除图像中的小噪点、椒盐噪声,去除指纹图像中的细小断裂和噪声,并且去除文档扫描中的小污点
闭运算
将图像先进行膨胀操作,然后进行腐蚀操作
可以用来闭合物体内部的小孔洞,填充凹陷部分,使边界更平滑,并且不显著增加物体的面积
形态学方法
获得图像形态学滤波的滤波器--腐蚀或膨胀时使用的核
retval = cv2.getStructuringElement(shape, ksize, anchor)
shape:结构元素的种类
|-------------------|----|--------------------|
| 标志 | 简记 | 含义 |
| cv2.MORPH_RECT | 0 | 矩形结构元素,所有元素均为1 |
| cv2.MORPH_CROSS | 1 | 十字结构元素,中间行和列元素为1 |
| cv2.MORPH_ELLIPSE | 2 | 椭圆结构元素,矩形的内接椭圆元素为1 |ksize:结构元素的大小
anchor:可选,结构元素的中心位置
实现形态学操作
dst = cv2.morphologyEx(src, op, kernel, anchor, iterations, borderType, borderValue)
src:原始图像
op:操作类型
|--------------------|------|
| 参考值 | 含义 |
| cv2.MORPH_ERODE | 腐蚀 |
| cv2.MORPH_DILATE | 膨胀 |
| cv2.MORPH_OPEN | 开运算 |
| cv2.MORPH_CLOSE | 闭运算 |
| cv2.MORPH_GRADIENT | 梯度运算 |
| cv2.MORPH_TOPHAT | 顶帽运算 |
| cv2.MORPH_BLACKHAT | 黑帽运算 |kernel:操作过程中所使用的核
anchor:可选,核的锚点位置
iterations:可选,迭代次数
borderType:可选,边界样式
borderValue:可选,边界值
dst:处理后的图像
对于op--操作类型来说其中腐蚀、膨胀、开运算和闭运算均与上文相同
梯度运算:膨胀结果减去腐蚀结果
顶帽运算:原图像减去开运算结果
黑帽运算:闭运算结果减去原图像
操作类型 主要应用场景 ERODE 去除噪声、分离粘连物体 DILATE 填补空洞、连接断线 OPEN 去除小噪点、指纹图像处理 CLOSE 填充小孔洞、文档修复 GRADIENT 边缘检测、轮廓提取 TOPHAT 背景均匀化、细小亮特征提取 BLACKHAT 阴影检测、暗区域提取
选择技巧
去噪:先用开运算,再用闭运算
边缘检测:形态学梯度比传统边缘检测更平滑
特征提取:顶帽用于亮特征,黑帽用于暗特征
结构元素:矩形用于一般情况,圆形用于各向同性,十字形用于特定方向
图像细化
dst = cv2.ximgproc.thinning(src, thinningType)
src:输入图像
dst:输出图像
thinningType:可选,细化算法的标志,默认为cv2.THINNING_ZHANGSUAN
|------------------------|----|
| 名称 | 简记 |
| cv2.THINNING_ZHANGSUAN | 0 |
| cv2.THINNING_GUOHALL | 1 |
图像细化是将图像中的线条从多像素宽度减少到单位像素宽度的过程,例如对文字的细化,可以增强对文字的辨识度,并且降低储存量和储存难度
但是并非所有图像都可以细化,其主要是由线条组成的物体(文字,圆环,方框等),但是如实心圆等实心的物体则不可以细化
图像轮廓
检测图像的轮廓
通过计算图像梯度来判断图像的边缘
contours, hierarchy = cv2.findContours(image, mode, method)--可以先进行二值化处理后再检测
image:被检测的图像
mode:轮廓的检索模式
|-------------------|---------------------|
| 参数值 | 含义 |
| cv2.RETR_EXTERNAL | 只检测外轮廓 |
| cv2.RETR_LIST | 检测所有轮廓,但不建立层次关系 |
| cv2.RETR_CCOMP | 检测所有轮廓,并建立两级层次关系 |
| cv2.RETR_TREE | 检测所有轮廓,并建立树状结构的层次关系 |method:检测轮廓时使用的方法
|----------------------------|-------------------|
| 参数值 | 含义 |
| cv2.CHAIN_APPROX_NONE | 储存轮廓上的所有点 |
| cv2.CHAIN_APPROX_SIMPLE | 只保存水平、垂直或对角线轮廓的端点 |
| cv2.CHAIN_APPROX_TC89_L1 | Ten-Chinl近似算法的一种 |
| cv2.CHAIN_APPROX_TC89_KCOS | Ten-Chinl近似算法的一种 |contours:检测出的所有轮廓,list类型,每一个元素都是某个轮廓的像素坐标数组
hierarchy:轮廓之间的层次关系
通过Hu矩来分类图像轮廓
retval = cv2.matchShapes(contour1, contour2, method, parameter)
contour1:待分类判断的原灰度图像或轮廓
contour2:模板图像或轮廓
method:匹配方法的标志
|-----------------------|----|----------------------------------------------------------------------------------------------------------------------------------------|
| 标志 | 简记 | 公式 |
| cv2.CONTOURS_MATCH_I1 | 1 ||
| cv2.CONTOURS_MATCH_I2 | 2 |
| cv2.CONTOURS_MATCH_I3 | 3 |parameter:特定于方法的参数,直接设置为0即可
findContours和matchShapes之间有较大区别,findContours主要用于判别边缘,如统计图像中物体的个数,但是其不能分类,而matchShapes则可以将findContours中判别的边缘分类,使其识别特定形状,而后通过后面的drawContours来绘制图像轮廓
绘制图像轮廓
image = cv2.drawContours(image, contours, contourIdx, color, thickness, lineTypee, hieranrchy, maxLevel, offse)
image:被绘制轮廓的图像,输入为原始图像(非二值化图像),输出图像中已经保存绘制的轮廓(也可以不输出)
contours:findContours()方法得出的轮廓列表
contourIdx:绘制轮廓的索引,当为-1时绘制所有轮廓(contours中list保存的元素,从左到右,从外到内依次保存)
color:绘制颜色
thickness:可选,画笔的宽度,当值为-1时绘制实心轮廓
lineTypee:可选,绘制轮廓的线型
hierarchy:可选,findContours()方法得出的层次关系
maxLevel:可选,绘制轮廓的层次深度,最深绘制第maxLevel层
offse:可选,偏移量,可以改变绘制结果的位置
轮廓信息
轮廓面积
retval = cv2.contourArea(contour, oriented)
contour:轮廓的像素
oriented:区域面积是否具有方向的标志
轮廓长度
retval = cv2.arcLength(curve, closed)
curve:轮廓或者曲线的2D像素点
closed:轮廓或者曲线是否闭合的标志
点到轮廓的距离
retval = cv2.pointPolygonTest(contour, pt, measureDist)
contour:输入的轮廓
pt:需要计算与轮廓距离的像素点
measureDist:统计的距离是否具有方向性
retval:返回的距离
当measureDist为True时,有方向,返回值为正数则像素点在轮廓内部,返回值为负数则像素点在轮廓外部,返回值为0则像素点在轮廓上
当measureDist为False时,无方向,返回值为1则像素点在轮廓内部,返回值为-1则像素点在轮廓外部,返回值为0则像素点在轮廓上
轮廓拟合
其仅能获得外接图形的基点,仍需上文中绘制图形中的函数(如img = cv2.rectangle(img, pt1, pt2, color, thickness))或者其他函数来进行绘制
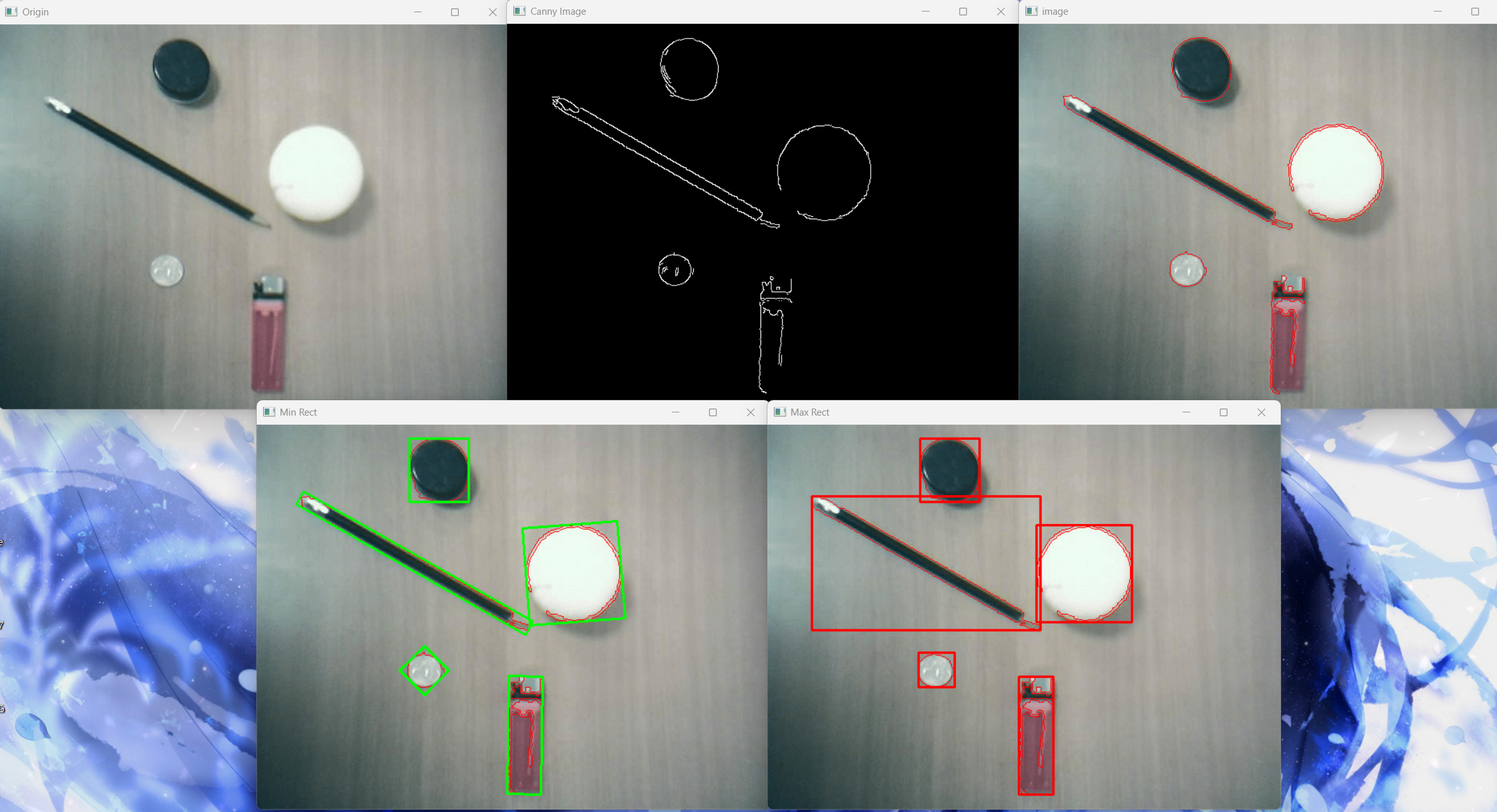
最大外接矩形
retval = cv2.boundingRect(array)/x, y ,w, h = cv2.boundingRect(array)
array:轮廓数组--(contoursi)
retval/x, y ,w, h:元组类型,包含四个整数值,分别时最小矩形包围框左上角顶点的横坐标、左上角顶点的纵坐标、矩形的宽和高
可以看出retval包含矩形左上角顶点的横坐标、左上角顶点的纵坐标、矩形的宽和高,因此可以直接使用img = cv2.rectangle(img, rec, color, thickness)来绘制矩形
最小外接矩形
retval = cv2.minAreaRect(array)
array:轮廓数组--(contoursi)
retval:元组类型,retval0表示矩形左上角顶点(x, y),retval1表示矩形的宽和高(w, h),retval2是矩形的旋转角度
可以看出retval不包含四个顶点的坐标,同时矩形有一定的旋转角度,因此不能直接使用img = cv2.rectangle(img, rec, color, thickness)来绘制矩形其需要通过points = cv2.boxPoints(retval)来得出矩形的四个顶点,通常是从角度最小的点开始,顺时针排列
由于包含四个顶点坐标,因此可以使用image = cv2.drawContours(image, contours, contourIdx, color, thickness, lineTypee, hieranrchy, maxLevel, offse)来绘制矩形,但是其中contours为三维的数组,因此其输入因为points,同时后面需要使用.astype(np.int64) /.astype(np.int32)来进行转化
以下是两种矩形轮廓的绘制
import sys import numpy as np import cv2 as cv if __name__ == '__main__': # 读取图像stuff.jpg image = cv.imread('./images/stuff.jpg') if image is None: print('Failed to read stuff.jpg.') sys.exit() cv.imshow('Origin', image) # 提取图像边缘 canny = cv.Canny(image, 80, 160, 3) cv.imshow('Canny Image', canny) # 膨胀运算 kernel = cv.getStructuringElement(0, (3, 3)) canny = cv.dilate(canny, kernel=kernel) # 轮廓检测及绘制 contours, hierarchy = cv.findContours(canny, mode=0, method=2) image_0 = cv.drawContours(image, contours, -1, (0, 0 ,255)) cv.imshow('image', image_0) # 寻找并绘制轮廓外接矩形 img1 = image.copy() img2 = image.copy() for i in range(len(contours)): # 绘制轮廓的最大外接矩形 max_rect = cv.boundingRect(contours[i]) cv.rectangle(img1, max_rect, (0, 0, 255), 2) # 绘制轮廓的最小外接矩形 min_rect = cv.minAreaRect(contours[i]) points = cv.boxPoints(min_rect).astype(np.int64) print(points) img2 = cv.drawContours(img2, [points], -1, (0, 255, 0), 2, 8) cv.imshow('Max Rect', img1) cv.imshow('Min Rect', img2) cv.waitKey(0) cv.destroyAllWindows()
圆形
center, radius = cv2.minEnclosingCircle(points)
points:轮廓数组--(contoursi)
center:元组类型,包含两个浮点数,是最小圆形 包围框圆心的横坐标和纵坐标
radius:浮点类型,最小圆形包围框的半径
凸包(多边形)
hull = cv2.convexHull(points, clockwise, returnPoints)
points:轮廓数组--(contoursi)
clockwise:可选,bool类型。为True时,凸包中的点按顺时针排列
returnPoints:可选,bool类型。为True时返回坐标,为False时返回索引,默认为Ture
hull:凸包的点阵数组
图像金字塔
高斯金字塔--下采样
dst = cv2.pyrDown(src, dstsize, borderType)
src:原始图像
dstsize:可选,元组类型,图像输出的大小
borderType:边界填充类型
拉普拉斯金字塔--上采样
dst = cv2.pyrUp(src, dstsize, borderType)
src:原始图像
dstsize:可选,元组类型,图像输出的大小
borderType:边界填充类型
def build_pyramid(image, levels=4): pyramid = [image] for i in range(levels): image = cv2.pyrDown(image) pyramid.append(image) return pyramid # 构建金字塔 pyramid = build_pyramid(img, levels=4)拉普拉斯金字塔是在高斯金字塔的基础上通过上采样形成的,而如果想要通过高斯金字塔恢复原样,则需要使用拉普拉斯金字塔构建。
同时拉普拉斯金字塔也可以用来保存高斯金字塔丢失的图像细节
def build_laplacian_pyramid(gaussian_pyramid): """拉普拉斯金字塔:保存高斯金字塔中丢失的细节""" laplacian_pyramid = [] # 从最底层开始,向上构建 for i in range(len(gaussian_pyramid)-1): # 1. 对上层高斯图像进行上采样 upsampled = cv2.pyrUp(gaussian_pyramid[i+1]) # 2. 调整尺寸(因为奇数尺寸问题) if upsampled.shape != gaussian_pyramid[i].shape: upsampled = cv2.resize(upsampled, (gaussian_pyramid[i].shape[1], gaussian_pyramid[i].shape[0])) # 3. 计算差值:原始图像 - 上采样后的模糊图像 # 这个差值就是丢失的细节! detail_layer = cv2.subtract(gaussian_pyramid[i], upsampled) laplacian_pyramid.append(detail_layer) # 最后一层就是高斯金字塔的最顶层 laplacian_pyramid.append(gaussian_pyramid[-1]) return laplacian_pyramid
边缘检测
边缘是指图像中像素灰度值突然发生变化的区域,故而其变化趋势可以使用导数来描述,但是由于导数可能正也可能负,故而直接添加绝对值即可
求矩阵绝对值
dst = cv2.convertScaleAbs(src, alpha, beta)
src:输入矩阵
alpha:可选,缩放因子
beta:可选,绝对值上添加的偏差
卷积边缘提取--有方向
常规卷积边缘检测
卷积边缘检测opencv无特定的函数,其可以再x和y方向上进行检测
对于x方向,可以使用卷积核1, 0, -1,不管中间像素的值,仅看左右两边的像素值,当左右两边的像素值相同时,其卷积为0,但是当其不相同时,其卷积为正值或负值,对于y方向的边缘检测也是一样的,其卷积核为1; 0; -1
最后将两个结果相加即可的得到最后的边缘检测的图像
import cv2 import numpy as np def jjdege(image, kernel): res = cv2.filter2D(image, cv2.CV_16S, kernel) res = cv2.convertScaleAbs(res) return res # 单一方向的边缘检测 image = cv2.imread('images/alien.bmp', 0) kernel_1 = np.array([1, 0, -1]) kernel_2 = kernel_1.reshape((3, 1)) res = jjdege(image, kernel_1) + jjdege(image, kernel_2) cv2.imshow('res', res) cv2.waitKey(0) cv2.destroyAllWindows()
Sobel算子边缘检测
通过离散微分方法求取图像边缘的边缘检测算子,是上面常规卷积边缘提取的增强版
dst = cv2.Sobel(src, ddepth, dx,dy, ksize, scale, delta, borderType)
src:待检测的图像
ddepth:输出图像的数据类型(深度),由于其可能存在负值,一般使用cv2.CV_16S
dx:x方向的差分阶数
dy:y方向的差分阶数
ksize:可选,Sobel边缘算子的大小,其必须为1、3、5或7
scale:对导数计算结果进行缩放的因子2,默认为1
delta:可选,在计算结果中想要加入的偏差
borderType:可选,边界样式,与卷积中的可选参数相同
dst:处理后的图像
其中最为重要的参数是dx、dy和ksize,其中当dx/dy=1时,ksize=3;dx/dy=2,ksize=5;dx/dy=3,ksize=7其中x方向的一阶边缘检测算子为-1, 0, 1; -1 ,0, 2; -1, 0, 1
其中y方向的一阶边缘检测算子为-1, -2, -1; 0 ,0, 0; 1, 2, 1
其整体用法和上面常规卷积边缘检测相同
Scharr算子边缘检测
Scharr算子时Sobel算子的增强版本,其对于图像中差异不明显的边缘有了更好的提取,但是其提取的矩阵在x、y方向只有各一个
dst = cv2.Scharr(src, ddepth, dx, dy, scale, delta, borderType)
src:待检测的图像
ddepth:输出图像的数据类型(深度),由于其可能存在负值,一般使用cv2.CV_16S
dx:x方向的差分阶数
dy:y方向的差分阶数
scale:对导数计算结果进行缩放的因子2,默认为1
delta:可选,在计算结果中想要加入的偏差
borderType:可选,边界样式,与卷积中的可选参数相同
dst:处理后的图像
dx和dy只有有一个为1,一个为0,不能同时为1或为0其中x方向的一阶边缘检测算子为-3, 0, 3; -10 ,0, 10; -3, 0, 3
其中y方向的一阶边缘检测算子为-3, 10, -3; 0 ,0, 0; 3, 10, 3
其整体用法和上面常规卷积边缘检测相同
生成边缘检测滤波器
由于上述Sobel算子由于阶数不同,其表达式也不同,通过原理计算则十分繁琐,而Scharr算子更是只有1阶的
但是实际中我们一般只需要提取图像边缘的滤波器,从而修改滤波器而使边缘检测的效果增强,因此想要获得该滤波器,则可以使用如下函数
kx, ky = cv2.getDerivKernels(dx, dy, ksize, normalize, ktype)
dx:x方向导数的阶次
dy:y方向导数的阶次
ksize:滤波器的大小
normalize:可选表示是否对滤波器系数进行归一化的标志
ktype:可选,滤波器系数的类型,默认为float32
kx:行滤波器系数的输出矩阵,默认为ksize×1
ky:列滤波器系数的输出矩阵,默认为ksize×1
其中当dx=1/dy=0时,生成检测x方向的一阶梯度边缘对于ksize,当其等于1、3、5或7时,其生成Sobel算子;当其等于cv2.FILTER_SCHARR(-1),其生成Scharr算子;以及下述的各个算法的算子,但是下述算法可以直接使用opencv自带的函数
Laplacian算子
dst = cv2.Laplacian(src, ddepth, ksize, scale, delta, borderType)
src:待检测的图像
ddepth:输出图像的数据类型(深度),由于其可能存在负值,一般使用cv2.CV_16S
ksize:滤波器的大小,必须为正奇数
scale:对导数计算结果进行缩放的因子2,默认为1
delta:可选,在计算结果中想要加入的偏差
borderType:可选,边界样式,与卷积中的可选参数相同
dst:处理后的图像
其无方向,但是对于噪声十分敏感,因此一般配合高斯滤波使用
Canny边缘检测--常用
edges = cv2.Canny(image, threshold1, threshold2, apertureSize, L2gradient)
image:检测的原始图像
threshold1:计算过程中使用的第一个阈值,可以是最小阈值,可以是最大阈值,通常用来设置最小阈值
threshold2:计算过程中使用的第二个阈值,通常来设置最大阈值
apertureSize:可选,Sobel算子的孔径大小
L2gradient:可选,计算图像梯度的标识,默认为False。值为True时会采用更精确的算法进行计算
edges:计算后得到的边缘图像,是一个二值灰度图像
对于两个阈值,最大阈值太高会损失很多重要边缘信息,但是太小则无法剔除噪声,最小阈值一般为最大阈值的1/2或者1/3如果图中边缘断裂太多,则阈值高了
如果出现太多无关的"噪声边缘",则阈值低了
霍夫变换
直线检测
图像直线检测
lines = cv2.HoughLinesP(image, rho, theta, threshold, minLineLEength, maxLineGap)
image:检测的原始图像
rho:检测直线使用的半径步长,值为1时,表示检测所有可能的半径步长
thera:搜索直线的角度,值为Π/180时,表示检测所有角度
threshold:阈值,该值越小,检测出的直线就越小
minLineLEength:线段的最小长度,小于该长度的直线不会记录到结果中
maxLineGap:线段之间的最小距离
lines:一个数组,元素为所有检测出的线段。每一个线段也是一个数组,内容为线段两个端点的横纵坐标,格式为\[\[x1, y1, x2, y2, x1, y1, x2, y2]]
检测之前先降噪,再做边缘处理或者二值化阈值处理
集合直线检测
lines = cv2.HoughLinesPointSet(point, lines_max, threshold, min_rho, max_rho, rho_step, min_theta, max_theta, theta_step)
point:输入点的集合
lines_max:检测直线的最大数目
threshold:累加器的阈值
min_rho:检测直线上两点之间的最短距离,以像素为单位
max_rho:检测直线上两点之间的最长距离,以像素为单位
rho_step:以像素为单位的距离分辨率,即距离r离散化时的单位长度
min_theta:检测的直线经过原点的垂线与x轴夹角的最小值,以弧度为单位
max_theta:检测的直线经过原点的垂线与x轴夹角的最大值,以弧度为单位
theta_step:以弧度为单位的角度分辨率,即夹角
lines:数组,尺寸为(line, 1, 3),其中line为检测到直线的数量,其不大于lines_max,可以通过如下函数输出lines的值
for item in lines: print('votes: {}, rho: {}, theta: {}'.format(item[0][0], item[0][1], item[0][2]))
圆环检测
circles = cv2.HoughCircles(image, method, dp, minDist, param1, param2, minRadius, maxRadius)
image:检测的原始图像
method:检测方法--常用:cv2.HOUGH_GRADIENT
dp:累加器分辨率与原始图像分辨率之比的倒数。通常使用1作为参数
minDist:圆心之间的最小距离
param1:可选,Canny边缘检测使用的最大阈值
param2:可选,检测圆环结果的投票数。第一轮筛选时投票超过该值的圆才会进入第二轮筛选。值越大,检测出的圆越少,但是越精准
minRadius:可选,圆的最小半径
maxRadius:可选,圆的最大半径
circles:一个数组,元素为所有检测的圆,每个圆也是一个数组,内容为圆心的横、纵坐标和半径长度,格式为\[\[x1, y1, r1, x1, y1, r1]]
检测之前先降噪,再转化为单通道灰度图像
直线拟合
最小二乘法
lines = cv2.fitLine(points, distType, param, reps, aeps)
points:输入待拟合的直线的2D集或3D集
distType:最小二乘算法使用的距离类型标志
|-----------------|----|--------------------------------------------------------------------------------------------------------------------------------------------|
| 标志 | 简记 | 距离计算公式 |
| cv2.DIST_L1 | 1 |
| cv2.DIST_L2 | 2 |
| cv2.DIST_L12 | 4 |
| cv2.DIST_FAIR | 5 |
| cv2.DIST_WELSCH | 6 |
| cv2.DIST_HUBER | 7 |param:某些距离系数的数值参数(C),填写0则自动选择最佳值
reps:坐标原点与拟合直线之间的距离精度,填写0则选择自适应参数,一般选择0.01
aeps:拟合直线的角度精度,填写0则选择自适应参数,一般选择0.01
line:拟合直线的描述参数
如果输入为2D集则输出4×1的ndarray对象\[vxvyx0y0]其直线表达形式为:
故其
如果输入为3D集则输出6×1的ndarray对象\[vxvyvzx0y0z0](vx, vy, vz)是与直线共线的归一化向量,(x0, y0, z0)是拟合直线上任一一点的坐标
模块匹配
模块匹配方法
result = cv2.matchTemplate(image, templ, method, mask)
image:原始图像,必须为8位或32位浮点型
templ:模块匹配,尺寸必须小于等于原始图像,且类型与原图像相同
method:匹配的方法
|----------------------|---|----------|
| 参数值 | 值 | 含义 |
| cv2.TM_SQDIFF | 0 | 差值平方和匹配 |
| cv2.TM_SQDIFF_NORMED | 1 | 归一化平方差匹配 |
| cv2.TM_CCORR | 2 | 相关匹配 |
| cv2.TM_CCORR_NORMED | 3 | 标准相关匹配 |
| cv2.TM_CCOFF | 4 | 相关系数匹配 |
| cv2.TM_CCOFF_NORMED | 5 | 标准相关系数匹配 |mask:可选,模型的掩模,只有cv2.TM_SQDIFF和cv2.TM_CCORR_NORMED支持此参数,必须和templ同类型和大小。
result:计算出的匹配结果,是一个输出矩阵,32位浮点型。如果image是W x H,templ是w x h,则result是(W-w+1) x (H-h+1)。
不同方法的特点:
方法 最佳匹配 特点 适用场景 TM_SQDIFF 最小值 对亮度变化敏感 精确匹配,背景简单 TM_SQDIFF_NORMED 最小值 归一化,对亮度变化不敏感 通用场景 TM_CCORR 最大值 计算相关性 快速匹配 TM_CCORR_NORMED 最大值 归一化相关匹配 最常用,性能平衡 TM_CCOEFF 最大值 计算相关系数 对模板亮度变化鲁棒 TM_CCOEFF_NORMED 最大值 归一化相关系数 最佳性能,推荐使用
单模板匹配
minValue, maxValue, minLoc, maxLoc = cv2.minMaxLoc(result , mask)
result:matchTemplate()方法计算得出的数组
mask:可选,掩模
minValue:数组中的最大值
maxValue:数组中的最小值
minLoc:最小值的坐标,格式为(x, y)
maxLoc:最大值的坐标,格式为(x, y)
需要注意模板匹配使用的方法最佳结果时最大值还是最小值
对于图片要对这两张图像进行模块匹配,由于其配色不同,故而可以采用阈值处理的方法
import cv2 import numpy as np image = cv2.imread('images/original_image.png') # templ_1 = cv2.imread('images/templ_1.png') # templ_2 = cv2.imread('images/templ_2.png') templ_3 = cv2.imread('images/templ_3.png') # templ_4 = cv2.imread('images/templ_4.png') # templ_5 = cv2.imread('images/templ_5.png') # templ_6 = cv2.imread('images/templ_6.png') image_Grey = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) templ_3_Grey = cv2.cvtColor(templ_3, cv2.COLOR_BGR2GRAY) a1, image_threshold = cv2.threshold(image_Grey, 125, 150, cv2.THRESH_TOZERO_INV) a2, templ_3_threshold = cv2.threshold(templ_3_Grey, 125, 150, cv2.THRESH_TOZERO_INV) h, w, c = templ_3.shape results = cv2.matchTemplate(image_threshold, templ_3_threshold, cv2.TM_CCOEFF_NORMED) minValue, maxValue, minLoc, maxLoc = cv2.minMaxLoc(results) resultPoints_1 = maxLoc resultPoints_2 = (resultPoints_1[0] + w, resultPoints_1[1] + h) cv2.rectangle(image, resultPoints_1, resultPoints_2, (0 , 0 ,255), 2) cv2.imshow('image', image) cv2.waitKey() cv2.destroyAllWindows()从而可以找到图像



多模板匹配
对于原始图像
对于目标图像
和
可以设计如下代码进行分析
import cv2 import numpy as np def myMatchTemplate(img, templ): loc = list() h, w ,c = templ.shape results = cv2.matchTemplate(img, templ, cv2.TM_CCOEFF_NORMED) for i in range(len(results)): for j in range(len(results[i])): if results[i][j] > 0.9: # 可以适当将降低 loc.append((j ,i , j + w, i + h)) return loc img = cv2.imread('images/original_image.png') templ = list() loc = list() templ.append(cv2.imread('images/templ_6.png')) templ.append(cv2.imread('images/templ_2.png')) for t in templ: loc += myMatchTemplate(img, t) # 使用append会增加loc列表的维数 for i in loc: cv2.rectangle(img, (i[0], i[1]), (i[2], i[3]), (0, 0, 255), 2) cv2.imshow('image', img) cv2.waitKey() cv2.destroyAllWindows()其中对于匹配图像时,应该想遍历图像把所有的相关坐标全部记录到loc列表后,再遍历loc列表画出方框,否则会使得匹配图像少一部分的坐标
同时对于匹配图像少一部分坐标时,可以尝试减低匹配的相关系数

特征点检测与匹配
特征点
对于下面检测关键点和描述子的函数(Feature2D类),使用前都需要先对图像进行特征点类的创建再使用(如retval = cv2.SIFT_create(),retval = cv2.SURF_create()和retval = cv2.ORB_create()等)
SIFT特征点检测
其在光照、噪声、缩放和旋转等干扰下仍然具有良好的稳定性,但是其计算速度较慢,因此一般用于需要高精度或者离线处理图像的情况下
要计算SIFT特征点需要先通过下采样构建多尺度的高斯金字塔,然后对每一相邻层数做差分构建高斯差分金字塔,而关键点就是由每一层的高斯差分金字塔的局部极值构成的
对于opencv4.5.0之后的版本直接使用cv2.SIFT_create(),同时其专利也到期了,可以免费使用
retval = cv2.SIFT_create(nfeatures, nOctaveLayers, contrastThreshold, edgeThreshold, sigma)
nfeatures:可选,保留的关键点数量,0表示无限制
nOctaveLayers:可选,每组金字塔的层数
contrastThreshold:可选,对比度阈值,用于过滤特征
edgeThreshold:可选,边缘阈值
sigma:可选高斯模糊参数
这个函数是创建一个SIFT特征点的类,而上文中detect、compute和detectAndCompute函数都是这类里面的实例函数
SURF特征点检测
由于SIFT特征点检测的速度较慢,不适合实时处理图像,而SURF特征点检测则是基于SIFT特征点检测上提出的加快检测速度的提取特征值的方法
retval = cv2.SURF_create(hessianThreshold, nOctave, nOctaveLayers, extended, upright)
hessianThreshold:可选,海森矩阵阈值,其值越大则检测到的特征值减少但是更加稳定
nOctave:可选,金字塔组数
nOctaveLayers:可选,每组金字塔中的层数
extended:可选,是否使用扩展描述符,True为128维,False为64维
upright:可选,是否计算方向
ORB特征点检测
SURF特征点检测的运行必须使用到GPU,而没有GPU的环境则可以使用ORB特征点检测,同时其计算速度也是最快的
其首先通过FAST角点确定图像中与周围像素存在明显差异的像素,从而确定关键点,然后计算每个关键点的BRIEF描述子,从而确定唯一的ORB特征点
retval = cv2.ORB_create(nfeatures, scaleFactor, nlevels, edgeThreshold, firstLevel, WTA_K, scoreType, patchSize, fastThreshold)
nfeatures:要保留的最大特征数
scaleFactor:金字塔尺度因子
nlevels:金字塔层数
edgeThreshold:边缘阈值
firstLevel:将原图放入金字塔的层数
WTA_K:生成每个描述符的像素点数
scoreType:使用的评分方式
patchSize:描述符的补丁大小
fastThreshold:FAST阈值
关键点
特征点是图像中含有特殊信息的集合,其不仅包含图像的像素和位置,而还包含描述图像信息唯一性的描述子,而描述图像的像素和位置的参数称为关键点,因此特征点可以看作关键点和描述子的统一
关键点类型
class KeyPoint{angel, class_id, octave, pt, response, size}
angel:关键点的角度,float类型
class_id:关键点分类号,int类型
octave:特征点来源(金字塔的层级),int类型
pt:关键点的坐标,x为横坐标,y为纵坐标
response:最强关键点的响应,可用于进一步分类和二次采样,float类型
size:关键点的直径,float类型
关键点转化
<KeyPoint object> = cv2.KeyPoint(x, y, size, angle, response, octave, class_id)
x:关键点的横坐标
y:关键点的纵坐标
size:关键点的直径
angel:可选,关键点的角度
response:可选,最强关键点的响应,可用于进一步分类和二次采样
octave:可选,特征点来源(金字塔的层级)
class_id:可选,关键点分类号,int类型
关键点检测
keypoints = cv2.Feature2D.detect(image, mask)
image:需要计算关键点的输入图像
mask:可选,计算关键点时使用的掩膜图像
keypoints:检测到的关键点
绘制关键点
outImage = cv2.drawKeypoints(image, keypoints, color, flags)
image:需要绘制关键点的图像
keypoints:来自原图像的关键点列表,必须为keypoints类型
color:可选,绘制关键点空心圆的颜色。输入0为随机绘制颜色
flags:可选,绘制功能的选择标志
|-----------------------------------------------|----|-------------------------|
| 标志 | 简记 | 含义 |
| cv2.DRAW_MATCHES_FLAGS_DEFAULT | 0 | 在输出图像中绘制关键点,但是不包含其大小和方向 |
| cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG | 1 | 在原图像中绘制关键点,但是不包含其大小和方向 |
| cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS | 2 | 不绘制单个关键点 |
| cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS | 4 | 在输出图像中绘制关键点,但是包含其大小和方向 |outImage:绘制关键点后的输出图像,其不可以和输入图像以相同的形式命名,需要直接在原图像中绘制需给flags赋值为cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG,但是仍需在前面使用outImage来接受,只不过接受后的outImage为None
描述子
计算描述子
keypoints, descriptors = cv2.Feature2D.compute(image, keypoints)
image:关键点对应的输入图像
keypoints:已经在输入图像中得到的关键点以及计算后的关键点
descriptors:每个关键点对应的描述子
这个函数往往伴随着cv2.Feature2D.detect的使用
直接计算关键点和描述子
keypoints, descriptors = cv2.Feature2D.detectAndCompute(image, mask, useProvidedKeypoints)
image:需要提取特征点的输入图像
mask:计算关键点使用的掩膜
useProvidedKeypoints:可选,是否使用已有关键点的标识符,若值为True,则该函数作用与cv2.Feature2D.compute功能相似,若值为False,则该函数即计算关键点又计算描述子
keypoints:计算得到的关键点坐标
descriptors:每个关键点对应的描述子
特征点
SIFT特征点检测
其在光照、噪声、缩放和旋转等干扰下仍然具有良好的稳定性,但是其计算速度较慢,因此一般用于需要高精度或者离线处理图像的情况下
要计算SIFT特征点需要先通过下采样构建多尺度的高斯金字塔,然后对每一相邻层数做差分构建高斯差分金字塔,而关键点就是由每一层的高斯差分金字塔的局部极值构成的
对于opencv4.5.0之后的版本直接使用cv2.SIFT_create(),同时其专利也到期了,可以免费使用
retval = cv2.SIFT_create(nfeatures, nOctaveLayers, contrastThreshold, edgeThreshold, sigma)
nfeatures:可选,保留的关键点数量,0表示无限制
nOctaveLayers:可选,每组金字塔的层数
contrastThreshold:可选,对比度阈值,用于过滤特征
edgeThreshold:可选,边缘阈值
sigma:可选高斯模糊参数
这个函数是创建一个SIFT特征点的类,而上文中detect、compute和detectAndCompute函数都是这类里面的实例函数
SURF特征点检测
由于SIFT特征点检测的速度较慢,不适合实时处理图像,而SURF特征点检测则是基于SIFT特征点检测上提出的加快检测速度的提取特征值的方法
retval = cv2.SURF_create(hessianThreshold, nOctave, nOctaveLayers, extended, upright)
hessianThreshold:可选,海森矩阵阈值,其值越大则检测到的特征值减少但是更加稳定
nOctave:可选,金字塔组数
nOctaveLayers:可选,每组金字塔中的层数
extended:可选,是否使用扩展描述符,True为128维,False为64维
upright:可选,是否计算方向
ORB特征点检测
SURF特征点检测的运行必须使用到GPU,而没有GPU的环境则可以使用ORB特征点检测,同时其计算速度也是最快的
其首先通过FAST角点确定图像中与周围像素存在明显差异的像素,从而确定关键点,然后计算每个关键点的BRIEF描述子,从而确定唯一的ORB特征点
retval = cv2.ORB_create(nfeatures, scaleFactor, nlevels, edgeThreshold, firstLevel, WTA_K, scoreType, patchSize, fastThreshold)
nfeatures:要保留的最大特征数
scaleFactor:金字塔尺度因子
nlevels:金字塔层数
edgeThreshold:边缘阈值
firstLevel:将原图放入金字塔的层数
WTA_K:生成每个描述符的像素点数
scoreType:使用的评分方式
patchSize:描述符的补丁大小
fastThreshold:FAST阈值
特征点匹配
特征点匹配是指在不同图像中寻找不同的特征点,特征点匹配方法总体可以分为2类,第一类是计算描述子之间的欧氏距离,这种匹配方式包含的特征点有SIFT特征点、SURF特征点等;第二类是计算描述子之间的汉明距离,这种匹配方式包含的特征点有ORB特征点、BRISK特征点等
在特征点匹配前都需创建特征点匹配的虚类,如下述的BFMatcher和FlannBasedMatcher,然后通过描述点匹配将特征点的匹配结果放在DMatch类中
用于匹配的特征点描述子集合分别称为查询描述子集合和训练描述子集合
特征值类
类别 DMatch BFMatcher/FlannBasedMatcher 角色 数据结构(存储匹配结果) 算法类(执行匹配操作) 功能 存储两个特征点的匹配信息 实现暴力匹配算法 使用方式 被匹配器创建和返回 创建匹配器对象,调用匹配方法 包含信息 queryIdx, trainIdx, distance等 匹配参数、距离度量方式等 DMatch是匹配结果的容器,不包含任何匹逻辑
BFMatcher是执行匹配的算法,它创建并返回DMatch对象
DMatch类
<DMatch object> = cv2.DMatch(queryIdx, trainIdx, imgIdx, distance)
queryIdx:查询描述子集合中匹配的描述子索引
trainIdx:训练描述子集合中匹配的描述子索引
imgIdx:当有多张训练图像时,指定训练图像的序号
distance:两个描述子之间的距离,距离越小,匹配越好
特性 BFMatcher FlannBasedMatcher 匹配原理 暴力搜索,计算所有距离 近似最近邻,建立索引加速 速度 较慢,O(n²) 较快,适合大数据集 精度 精确匹配 近似匹配,可能牺牲精度 内存使用 较低 较高(需要建立索引) 适用场景 小数据集,需要精确匹配 大数据集,实时应用
BFMatcher类--暴力匹配
<BFMatcher object> = cv2.BFMatcher(normType, crossCheck)
normType:两个描述子之间距离的类型标志
当需要匹配的是SIFT特征点、SURF特征点时,使用cv2.NORM_L1,cv2.NORM_L2
当需要匹配的是ORB特征点时,使用cv2.NORM_HANGMING(当WTA_K=2),使用cv2.NORM_HANGMING2(当WTA_K=3或者4)
crossCheck:是否进行交叉验证的标志,默认为False
FlannBasedMatcher类--FLANN匹配
<FlannBasedMatcher object> = cv2.FlannBasedMatcher(indexParams, searchParams)
indexParams:匹配时需要使用的搜索算法标志
|---------------------------|----|-------------------|
| 标志 | 简记 | 含义 |
| cv2.FLANN_INDEX_KDTREE | 1 | 采用随机K-D树寻找匹配点(默认) |
| cv2.FLANN_INDEX_KMEANS | 2 | 采用随机K-Means树寻找匹配点 |
| cv2.FLANN_INDEX_COMPOSITE | 3 | 采用随机层次聚类树寻找匹配点 |searchParams:递归遍历的次数,遍历次数越多,则结果越准,但是需要的时间也越多
使用FLANN匹配时需要将描述子结合转化为float32类型
描述子匹配
一对一(最佳匹配)
matches = cv2.BFMatcher/FlannBasedMatcher.match(queryDescriptors, trainDescriptors, mask)
queryDescriptors:查询描述子集合,数组对象
trainDescriptors:训练描述子集合,数组对象
mask:可选,描述子匹配时使用的掩膜矩阵
matches:两个集合的描述子匹配结果,保存在DMatch对象中,里面存放着两个描述子的索引、距离等
一对k
matches = cv2.BFMatcher/FlannBasedMatcher.knnMatch(queryDescriptors, trainDescriptors, k, mask, compactResult)
queryDescriptors:查询描述子集合,数组对象
trainDescriptors:训练描述子集合,数组对象
k:每个查询描述子集合在训练描述子集合中寻找的最优匹配结果的数目
mask:可选,描述子匹配时使用的掩膜矩阵
compactResult:可选,输出匹配结果数目是否与查询描述子数目相同的选择标志
matches:两个集合的描述子匹配结果,保存在DMatch对象中,里面存放着两个描述子的索引、距离等
指定阈值类的所有特征点
matches = cv2.BFMatcher/FlannBasedMatcher.radiusMatch(queryDescriptors, trainDescriptors, maxDistance, mask, compactResult)
queryDescriptors:查询描述子集合,数组对象
trainDescriptors:训练描述子集合,数组对象
maxDistance:两个描述子之间满足匹配条件的距离(欧式距离或汉明距离)阈值
mask:可选,描述子匹配时使用的掩膜矩阵
compactResult:可选,输出匹配结果数目是否与查询描述子数目相同的选择标志
matches:两个集合的描述子匹配结果,保存在DMatch对象中,里面存放着两个描述子的索引、距离等
绘制特征点
outImg = cv2.drawMatches(img1, keypoints1, img2, keypoints2, matches1to2, matchColor, singlePointColor, matchesMask, flags)
img1:查询描述子集合对应的图像
keypoints1:第一幅图像的关键点
img2:训练描述子集合对应的图像,两幅图像通道数一定相同即可
keypoints2:第二幅图像的关键点
matches1to2:第一幅图像中的关键点与第二幅图像中的关键点的匹配关系
matchColor:可选,连接点和关键点的颜色
singlePointColor:可选,没有匹配点的特征点的颜色
matchesMask:可选,匹配掩膜矩阵
flags:可选,绘制功能选择标志
|-----------------------------------------------|----|-------------------------|
| 标志 | 简记 | 含义 |
| cv2.DRAW_MATCHES_FLAGS_DEFAULT | 0 | 在输出图像中绘制关键点,但是不包含其大小和方向 |
| cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG | 1 | 在原图像中绘制关键点,但是不包含其大小和方向 |
| cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS | 2 | 不绘制单个关键点 |
| cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS | 4 | 在输出图像中绘制关键点,但是包含其大小和方向 |outImg:输出图像
优化特征点匹配
即使使用了描述子距离作为约束优化匹配的特征点,但是也会出现少许的误匹配,而减少这种误匹配的方法就是提高匹配的阈值,但是随着阈值的提高,其正确匹配的特征点也随之减少,同时实际情况也通常不允许多次修改阈值而来优化特征点匹配
因此该函数即是在此基础上做到减少误匹配,同时不改变阈值
retval, mask0= cv2.findHonmography(srcPoints, dstPoints, method, ransacReprojThreshold, mask, maxIters, confidence)
srcPoints:原始图像的特征点坐标,数组类型
dstPoints:目标图像的特征点坐标,数组类型
method:可选,计算单应矩阵的方法
|------------|-----------------|
| 标志 | 含义 |
| 0 | 使用最小二乘法计算单应矩阵 |
| cv2.RANSAC | 使用RANSAC法计算单应矩阵 |
| cv2.LMEDS | 使用最小中值法计算单应矩阵 |
| cv2.PROSAC | 使用PROSAC法计算单应矩阵 |ransacReprojThreshold:可选,重投影的最大误差,仅在cv2.RANSAC时有用,默认为3
mask:可选,掩膜矩阵
maxIters:可选,RANSAC算法迭代的最大次数,默认为3000
confidence:可选,置信区间,取值范围为0~1,默认为0.995
retval:是否满足单应矩阵重投影误差的特征点
mask0:优化匹配后的图像矩阵,其坐标元素与匹配点对应,当该值为1时,则该匹配点可信
实践代码
import numpy as np
import cv2 as cv
import sys
if __name__ == '__main__':
# 读取图像
image1 = cv.imread('./images/box.png')
image2 = cv.imread('./images/box_in_scene.png')
if image1 is None or image2 is None:
print('Failed to read box.png or box_in_scene.png.')
sys.exit()
# 创建ORB对象
orb = cv.ORB_create(1000, 1.2, 8, 31, 0, 2, cv.ORB_HARRIS_SCORE, 31, 20)
# 分别计算image1,image2的ORB特征点和描述子
kps1, des1 = orb.detectAndCompute(image1, None, None)
kps2, des2 = orb.detectAndCompute(image2, None, None)
# 创建BFMatcher对象
bf = cv.BFMatcher(cv.NORM_HAMMING)
# 暴力匹配
matches = bf.match(des1, des2)
# 查找最小汉明距离
matches_list = []
for match in matches:
matches_list.append(match.distance)
min_dist = min(matches_list)
# 设定阈值,筛选出合适汉明距离的匹配点对
good_matches = []
for match in matches:
if match.distance <= max(2.0 * min_dist, 20.0):
good_matches.append(match)
# 使用RANSAC算法筛选匹配结果
# 获取关键点坐标
src_kps = np.float32([kps1[i.queryIdx].pt for i in good_matches]).reshape(-1, 1, 2)
dst_kps = np.float32([kps2[i.trainIdx].pt for i in good_matches]).reshape(-1, 1, 2)
# 使用RANSAC算法筛选
M, mask = cv.findHomography(src_kps, dst_kps, method=cv.RANSAC, ransacReprojThreshold=5.0)
# 保存筛选后的匹配点对
good_ransac = []
for i in range(len(mask)):
if mask[i] == 1:
good_ransac.append(good_matches[i])
# 绘制筛选前后的匹配结果
result = cv.drawMatches(image1, kps1, image2, kps2, good_ransac, None)
# 展示结果
cv.imshow('RANSAC Matches', result)
cv.waitKey(0)
cv.destroyAllWindows()
角点
Harris角点
主要用于检测图像中线段的端点和两条线段的交点
dst = cv2.cornerHarris(src, blockSize, ksize, k, borderType)
src:待检测Harris角点的输入图像
blockSize:邻域大小
ksize:Sobel算子的尺寸
k:计算Harris角点评价系数R的权重系数,多为0.02~0.04
borderType:可选,像素边界外推算法的标志
|------------------------|-------|-----------------|
| cv2.BORDER_CONSTANT | 常数填充 | 使用0填充边界 |
| cv2.BORDER_REPLICATE | 复制边缘 | 复制最边缘的像素值填充 |
| cv2.BORDER_REFLECT | 反射填充 | 反射图像边界(包括边界像素) |
| cv2.BORDER_REFLECT_101 | 反射101 | 反射图像边界(不包括边界像素) |
| cv2.BORDER_WRAP | 包装填充 | 将图像对侧边界包装过来 |dst:存放Harris角点评价系数R的矩阵
由于dst后的矩阵系数有正有负,因此可以通过cv2.normalize来进行归一化,然后与阈值125进行比较得出Harris角点,最后通过cv2.drawKeypoints来绘制所有角点
Shi-Tomasi角点检测
其本质为Harris角点的变形
corners = cv2.goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance, mask, blocksize, useHarrisDetector, k)
image:待检测Shi-Tomasi角点的输入图像
maxCorners:要寻找Shi-Tomasi角点数目的最大值
qualityLevel:Shi-Tomasi角点阈值与最佳Shi-Tomasi角点数之间的关系,用于避免Shi-Tomasi角点过于密集
minDistance:两个Shi-Tomasi角点之间的最短欧式距离
mask:可选,掩膜矩阵,表示检测Shi-Tomasi角点的区域
blocksize:可选,计算梯度协方差矩阵的大小,默认为3
useHarrisDetector:可选,表示是否使用Harris角点,默认为False
k:可选,Harris角点检测过程中的常值权重系数,默认为0.04
corners:检测到的Shi-Tomasi角点的输出量
亚像素级别角点检测
上述两个角点都是像素级别的,若需要更加精确的角点,则可以使用亚像素级别的角点
corners = cv2.cornerSubPix(image, corners, winSize, zeroZone, criteria)
image:输入图像,必须是单通道的灰度图像
corners:角点坐标,既是输入的角点初始坐标,又是精细后的角点坐标
winSize:搜索窗口尺寸的一半,必须是整数
zeroZone:搜索区域中间"死区"大小的一半,用于指定不用进行检测的区域,通常设为(-1, -1),表示无"死区"
criteria:终止角点位置优化迭代的条件
针对于criteria,其是一个包含三个元素的元素criteria = (type, maxiter, epsilon),其中type表示终止条件类型,maxiter表示最大迭代次数,epsilon表示精度阈值
对于type(终止条件类型)来说,一般使用cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER,也可以分开使用,前一个表示达到最大精度后停止,后一个表示达到最大迭代次数后停止
比如:criteria1 = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001),表示为达到30次迭代或精度0.001时停止
对于后面两个参数
应用场景 maxiterepsilon说明 实时应用 10-20 0.1-0.01 快速但精度较低 一般标定 20-30 0.01-0.001 平衡精度和速度 高精度测量 30-50 0.001-0.0001 高精度,计算成本高
摄像头
初始化摄像头/读取显示视频
capture = cv2.VideoCapture(index)/capture = cv2.VideoCapture(video)
capture:要打开的摄像头/要打开的视频
index:摄像头的设备索引。当值为0是,表示打开windows内部摄像头;当值为1时,表示打开外部摄像头
video:打开视频的名称
初始化摄像头
当出现兼容性的问题时,可以使用如下代码来避免兼容性问题
capture = cv2.VideoCapture(0, cv2.CAP_DSHOW)为检验摄像头初始化是否成功,可以使用如下代码进行检验,返回为bool类型
retval = cv2.VideoCapture.isOpened() ## 或者 retval = capture.isOpened()读取摄像头里面的帧数,可以使用如下方法实现
retval, image = cv2.VideoCapture.read() ## 或者 retval, image = capture.read() ## retval:是否读取到帧,返回bool类型 ## image:读取到的帧当不需要摄像头时,关闭摄像头
cv2.VideoCapture.release() ## 或者 capture.release()其中capture为摄像头名称,同时可以通过cv2.imwrite来保存图像
读取显示视频
cv2.nameWindow('Video', 0) # 对视频标题命名 cv2.resiezeWindow('video', 420, 300) # 对视频窗口大小进行命名对于视频的暂停和继续,可以使用如下代码
第一行表示视频的播放速度为50ms,同时将接送的按键信息传递给key参数
当key参数为32即按下空格键时,系统执行cv2.waitKey(0)这行代码,使视频无限暂停
但是程序并未跳出if语句的判断,仍在执行cv2.waitKey(0)这行代码,只有当按下其余任意按键后程序才继续执行,从而实现视频的继续
如果需要实现按下空格转换暂停和继续的功能,可以定义一个pause的bool类型参数,当按下空格后转化pause的值,以实现该功能
key = cv2.waitKey(50) if key == 32: cv2.waitKey(0) continue获取视频文件的属性
retval = cv2.VideoCapture.get(propId) # retval:获取到与propId对应的属性值 # propId:视频的属性值|----------------------------|----------------------------|
| 视频文件的属性值 | 含义 |
| cv2.CAP_PROP_POS_MSEC | 视频文件播放的当前位置(单位:ms) |
| cv2.CAP_PROP_POS_FRAMES | 帧的索引,从0开始 |
| cv2.CAP_PROP_POS_AVI_RATIO | 视频文件的相对位置(0表示开始播放,1表示结束播放) |
| cv2.CAP_PROP_FRAME_WIDTH | 视频文件的帧宽度 |
| cv2.CAP_PROP_FRAME_HEIGHT | 视频文件的帧高度 |
| cv2.CAP_PROP_FPS | 帧速率 |
| cv2.CAP_PROP_FOURCC | 用4个字符表示的视频编码格式 |
| cv2.CAP_PROP_FRAME_COUNT | 视频文件的帧数 |
| cv2.CAP_PROP_FORMAT | retrieve()方法返回的Mat对象的格式 |
| cv2.CAP_PROP_MODE | 指示当前捕获模式的后端专用的值 |
| cv2.CAP_PROP_CONVERT_RGB | 指示是否应将图像转化为RGB |对于视频是否打开,读取视频文件,关闭视频文件均与初始化摄像头中相同
对于cv2.waitKey()代码可以控制视频文件的播放速度,越大越慢。
保存视频文件
<VideoWriter object> = cv2.VideoWriter(filename, fourcc, fps, frameSize)
VideoWriter object:VideoWriter类对象名称
filename:保存文件的路径,包括文件名
fourcc:用4个字符表示的视频编码格式
fourcc = cv2.VideoWriter_fourcc('X', 'V', 'I', 'D') # 或者 fourcc = cv2.VideoWriter_fourcc(*'XVID')|-------------------------------------------|------------------------------|-------|
| fourcc的值 | 视频编码格式 | 文件扩展名 |
| fourcc = cv2.VideoWriter_fourcc(*'I420') | 未压缩的YUV颜色编码格式,兼容性好,但文件较大 | .avi |
| fourcc = cv2.VideoWriter_fourcc(*'PIMI') | MPEG-1编码格式 | .avi |
| fourcc = cv2.VideoWriter_fourcc(*'XVID') | MPEG-4编码格式,视频文件大小为平均值,帧速率为20 | .avi |
| fourcc = cv2.VideoWriter_fourcc(*'THEO') | Ogg Vorbis编码格式,兼容性差 | .ogv |
| fourcc = cv2.VideoWriter_fourcc(*'FLVI') | Flash视频编码格式 | .flv |fps:帧速率
frameSize:每一帧的大小,元组类型
VideoWriter_object.write(frame) # 将读取到的帧写入VideoWriter类对象 VideoWriter_object.release() # 释放VideoWriter类对象
立体视觉
单目视觉
齐次坐标
齐次坐标的核心思想在于升维,一个矩阵表示其旋转和缩放十分简单,只需要乘以一个对应矩阵即可
缩放 : 将一个点 (x,y) 缩放 sx 倍和 sy 倍。乘以一个缩放矩阵
旋转 : 将一个点绕原点旋转 θ 角度。乘以一个旋转矩阵
但是其无法表示平移,因此使用齐次坐标升维,则可以将对应点表示为(x,y,w),通常我们令w=1
缩放 : 将一个点 (x,y) 缩放 sx 倍和 sy 倍。乘以一个缩放矩阵
旋转 : 将一个点绕原点旋转 θ 角度。乘以一个旋转矩阵
平移 : 将一个点平移dx和dy。乘以一个平移矩阵
同时齐次坐标中的w也有很大的作用,当其为1时,其表示一个具体的点(x,y);但是当其为0时,其表示为一个向量(x,y,0),只有方向和大小,没有位置,因此平移矩阵对于该向量来说没有任何的影响
非齐次坐标转化为齐次坐标
dst = cv2.convertPointToHomogeneous(src)
src:非齐次坐标,数组类型
dst:齐次坐标,数组类型
齐次坐标转化为非齐次坐标
dst = cv2.convertPointFromHomogeneous(src)
src:齐次坐标,数组类型
dst:非齐次坐标,数组类型
单目视觉模型
像素坐标系
像素坐标系是计算机内部储存图像的坐标系,也是前文中一直提到的坐标系,其坐标原点位于图像的左上方,u轴和v轴分别平行于图像坐标系的x轴和y轴
图像坐标系
图像坐标系是用物理长度来描述一个图像的具体位置,它位于相机感光片上,其坐标原点为光轴在感光片上的投影,通常为图像的几何中心,x轴和y轴贴合图像边缘,x轴以水平向右为正,y轴以垂直向下为正
转化关系
假设在图像中存在一个点p,它在像素坐标系下的坐标为p(u,v),它在图像坐标系下的坐标为p(x,y),则它们二者存在如下关系:
其中
相机坐标系
相机坐标系是用来描述观测环境与相机之间相对位姿关系的坐标系,其原点
单目相机成像模型
点
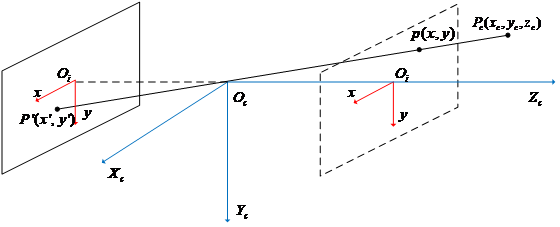
内参矩阵定义
由上面的单目相机成像模型可得到一个关系式
这样的相似关系使得相机坐标系中坐标与图像坐标系中坐标的负号相反,因此为了将负号去掉,则可以得到对应的成像图像即
使用齐次坐标的形式表示则为
其中u,v即为前面的x,y;
而参数K即为相机的内参矩阵,其仅由相机的内部参数决定,具体的内参矩阵与相机内参之间的关系和推到,一般使用张正友标定法
相机标定求内参矩阵和外参矩阵
对于内参矩阵的求解,通过上文可知
其中
然后将该式子带入上式可得
其中K为相机内参矩阵,R t是外参矩阵,表示相机坐标系与世界坐标系之间的关系
世界坐标系是人为指定的,因此我们需要选取一个便于计算和理解的坐标进行构建,通常选取第一个内角点作为原点,棋盘所在的平面为z=0平面,该内角点的行和列分别为世界坐标轴的x、y轴,这样可以根据棋盘网格的尺寸计算出每个内角点的坐标
畸变
在上述的标定计算中,标定板可能由于环境、放置或者相机拍摄的问题而产生畸变,畸变分为径向和切向畸变,通常出现的为径向畸变
对于切向畸变,其一般是由镜头安装偏差引起的,通常调试一下镜头即可,同时其对于图像的影响也没有径向畸变的影响大,其表达式可以由下面的式子来描述,其中
该图由左至右依次为无畸变、负径向畸变和正径向畸变,其表达式可以由下面的式子来描述,其中
将两者项结合则是相机畸变

相机成像
其整体流程为:相机标定->拍摄多角度图像->运行标定算法->得到内参和畸变系数->利用这些系数进行测量或者抓取等功能
标定板角点提取
由于一般使用的标定板均为黑白相间的棋盘方格板,因此在黑白相间的区域内,角点最为明显。对于第一张图,它的角点位于两个黑白方格的交点处;对于第二张图,它的角点位于每个黑色实心圆的圆心

retval, corners = cv2.findChessboardCorners(image, patternSize, flags)--对于黑白相间标定板
image:含棋盘标定板的图像,可为彩色或灰色图像,但数据类型一定为uint8或uint32
patternSize:图像中棋盘格内角点的行数和列数
flags:可选,检测内角点的方法,可以互相结合使用,使用'+'连接
|------------------------------|----|----------------------------------------------|
| 标志 | 简记 | 含义 |
| cv2.CALIB_CB_ADAPTIVE_THRESH | 1 | 使用自适应阈值将图像转化为二值图像 |
| cv2.CALIB_CB_NORMALIZE_IMAGE | 2 | 在应用固定阈值或者自适应阈值之前,使用cv2.equlizeHist()函数将图像均衡化 |
| cv2.CALIB_CB_FILTER_QUADS | 4 | 使用其他条件(如轮廓区域、周长、方形形状)过滤掉在轮廓检索阶段提取的假四边形 |
| cv2.CALIB_CB_FAST_CHECK | 8 | 用快速方法查找图像中的角点 |retval:是否找到满足要求的内角点
corners:检测到的内角点坐标
对于retval,满足的要求是指对于一个7×6的标定板,其应该有6×5个内角点,若是检测到的内角点刚好为6×5个内角点,则满足要求,反之则不满足对于corners,检测到的内角点坐标仅为近似值,如果需要更精确的定位内角点的坐标,可以使用前面介绍的亚像素级别角点坐标检测corners = cv2.cornerSubPix()。此外其也有专门提高标定板坐标精度的函数如下
retval, centers= cv2.findCirclesGrid(image, patternSize, flags, blobDetector)--对于实心圆标定板
image:含棋盘标定板的图像,可为彩色或灰色图像,但数据类型一定为uint8或uint32
patternSize:图像中每行和每列圆形的数目
flags:可选,检测内角点的方法,默认为cv2.CALIB_CB_SYMMETRIC_GRID
|------------------------------|----|------------------------------------|
| 标志 | 简记 | 含义 |
| cv2.CALIB_CB_SYMMETRIC_GRID | 1 | 使用圆的对称模式 |
| cv2.CALIB_CB_ASYMMETRIC_GRID | 2 | 使用不对称的圆形图案 |
| cv2.CALIB_CB_CLUSTERING | 4 | 使用特殊算法进行网格检测,它对透视扭曲更加稳健,但对背景杂乱更加敏感 |blobDetector:可选,在浅色背景中寻找黑色圆形斑点的特征探测器
retval:是否找到满足要求的内角点
corners:检测到的内角点坐标
提高标定板角点坐标精度
针对于棋盘格角点
retval, corners = cv2.find4QuadCornerSubpix(img, corners, region_size)
img:计算出内角点坐标的图像
corners:函数内部的为计算出的角点坐标,函数返回值为优化后的内角点坐标
region_size:优化坐标时考虑的邻域,一般选择(3, 3)或(5, 5)
retval:是否成功找到亚像素角点
通用--亚像素级别角点检测
corners = cv2.cornerSubPix(image, corners, winSize, zeroZone, criteria)
image:输入图像,必须是单通道的灰度图像
corners:角点坐标,既是输入的角点初始坐标,又是精细后的角点坐标
winSize:搜索窗口尺寸的一半,必须是整数
zeroZone:搜索区域中间"死区"大小的一半,用于指定不用进行检测的区域,通常设为(-1, -1),表示无"死区"
criteria:终止角点位置优化迭代的条件
针对于criteria,其是一个包含三个元素的元素criteria = (type, maxiter, epsilon),其中type表示终止条件类型,maxiter表示最大迭代次数,epsilon表示精度阈值
对于type(终止条件类型)来说,一般使用cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER,也可以分开使用,前一个表示达到最大精度后停止,后一个表示达到最大迭代次数后停止
比如:criteria1 = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001),表示为达到30次迭代或精度0.001时停止
对于后面两个参数
应用场景 maxiterepsilon说明 实时应用 10-20 0.1-0.01 快速但精度较低 一般标定 20-30 0.01-0.001 平衡精度和速度 高精度测量 30-50 0.001-0.0001 高精度,计算成本高
绘制棋盘格角点
image = cv2.drawChessboardCorners(image, patternSize, corners, patternWasFound)
image:输入为待绘制角点的图像,输出为绘制角点后的图像,必须为uint8的彩色图像
patternSize:图像中棋盘格内角点的行数和列数
corners:检测到的角点数组
patternWasFound:是否找到完整的标定板的标志。
若为False,则只绘制角点的位置;若为True,则绘制所有角点,同时也判断是否检测完整的标定板。
如果没有检测完整的标定板,则会使用红色圆圈将角点标记出来;若检测出完整的标定板,则会使用不同颜色将角点按从左向右的顺序连接起来,并且每行角点具有相同的颜色,不同行则颜色不同
单目相机标定
获得棋盘格内角点在图像中的坐标之后,只需要再获取棋盘格内角点在环境中的三维坐标即可计算出相机的内参矩阵
相机标定最主要的作用就是求出内参矩阵和相机畸变的五个系数
retval, camerMatrix, distCoeffs, rvecs, tvecs = cv2.calibrateCamera(objectPoints, imagePoints, imageSize, camerMatrix,distCoeffs, flags, criteria)
objectPoints:每幅图像中棋盘格内角点在世界坐标系中的三维坐标
imagePoints:每幅图像中棋盘格内角点在像素坐标系中的三维坐标
imageSize:图像的尺寸
camerMatrix:输入可以直接输入None,输出为相机的内参矩阵,是一个float32的二维的3×3数组类型
distCoeffs:输入可以直接输入None,输出为相机畸变系数矩阵,是一个float32的二维的1×5数组类型
flags:可选,选择标定算法,可以结合使用
|-----------------------------------|---------|-------------------------------------------------------------------------------------------------------|
| 标志 | 简记 | 含义 |
| cv2.CALIB_USE_INTEINSIC_GUESS | 0x00001 | 使用该参数时需要有内参矩阵的初值,否则将图像中心设置为初值,并利用最小二乘法计算焦距 |
| cv2.CALIB_FIX_PRINCIPAL_POINT | 0x00004 | 进行优化时固定光轴在图像中的投影点 |
| cv2.CALIB_FIX_ASPECT_RATIO | 0x00002 | 将
| cv2.CALIB_ZERO_TANGENT_DIST | 0x00008 | 忽略切向畸变,将切向畸变系数设置为0 |
| cv2.CALIB_FIX_K1,···,CALIB_FIX_K6 | 无 | 最后的数字可以改为1~6,一共6个标志,表示对应的径向畸变系数不变 |
| cv2.CALIB_RATIONAL_MODEL | 0x04000 | 用六阶径向畸变修正公式,否则用三阶 |criteria:迭代终止条件,与上文corners = cv2.cornerSubPix()一样
retval:相机标定的平均重投影误差
retval值范围标定质量评价 建议 < 0.5 像素 优秀 标定结果非常可靠 0.5 - 1.0 像素 良好 适用于大多数应用 1.0 - 2.0 像素 一般 可能需要改进 > 2.0 像素 较差 建议重新标定 rvecs:相机坐标系与世界坐标系之间的旋转向量
tvecs:相机坐标系与世界坐标系之间的平移向量
对于objectPoints的使用世界坐标系的坐标通常由我们自己定义,通常将棋盘板作为z=0的平面,原点选择左上角
import numpy as np def create_world_points(board_size, square_size): """ board_size: 棋盘格内角点数量,如 (9,6) 表示9列6行 square_size: 每个方格的实际物理尺寸(单位:米/毫米) """ objp = np.zeros((board_size[0] * board_size[1], 3), np.float32) objp[:, 0:2] = np.mgrid[0:board_size[0], 0:board_size[1]].T.reshape(-1, 2) objp *= square_size # 转换为实际物理尺寸 return objp # 示例:创建9×6棋盘格的世界坐标,每个方格25mm world_points = create_world_points((9, 6), 0.025)
对于flags的使用
初步标定:首次标定相机参数时,可不设置flags,让OpenCV从初始估计开始完全优化内参和畸变系数。
固定已知参数:若已知相机某些参数(如焦距比、主点位置或某些畸变系数),可使用cv2.CALIB_USE_INTEINSIC_GUESS并提供初始矩阵,然后结合cv2.CALIB_FIX_ASPECT_RATIO、cv2.CALIB_FIX_PRINCIPAL_POINT或cv2.CALIB_FIX_K1,···,CALIB_FIX_K6等标志固定这些参数。固定不必要的自由度通常能提高标定稳定性和精度。
单目相机校正
一共有两种方法,第一种是首先使用cv2.initUndistortRectifyMap()函数计算出校正图像需要的映射矩阵,之后利用cv2.remap()函数去掉原始图像中的畸变;第二种是根据内参矩阵和畸变系数直接通过cv2.undistort()函数对原始图像进行校正
第一种方法
map1, map2 = cv2.initUndistortRectifyMap(cameraMatrix, distCoeffs, R, newCameraMatrix, size, m1type)
cameraMatrix:相机的内参矩阵
distCoeffs:相机的畸变矩阵
R:第1副图和第2副图对应的相机位置之间的旋转矩阵,一般设置为单位矩阵或None
newCameraMatrix:校正后的相机内参矩阵,若没有定义,则可以直接使用None
size:图像的尺寸,输入格式为(wight, height)
m1type:第1个输出映射到矩阵变量的数据类型,一般设置为0或5,前者对应的输出结果为三维,后者为二维的
map1:第1个输出的x坐标的校正映射矩阵
map2:第2个输出的y坐标的校正映射矩阵
dst = cv2.remap(src, map1, map2, interpolation, borderType, borderValue)
src:畸变的原图像
map1:x坐标的校正映射函数
map2:y坐标的校正映射函数
interpolation:插值类型标志,详细可见更改图像比例大小中的描述
borderType:可选,边界填充方式,默认为cv2.BORDER_CONSTANT
|------------------------|-------|-----------------|
| cv2.BORDER_CONSTANT | 常数填充 | 使用0填充边界 |
| cv2.BORDER_REPLICATE | 复制边缘 | 复制最边缘的像素值填充 |
| cv2.BORDER_REFLECT | 反射填充 | 反射图像边界(包括边界像素) |
| cv2.BORDER_REFLECT_101 | 反射101 | 反射图像边界(不包括边界像素) |
| cv2.BORDER_WRAP | 包装填充 | 将图像对侧边界包装过来 |borderValue:可选,常值外推法使用的常值像素,默认为0
dst:去畸变后的图像
第二种方法
dst = cv2.undistort(src, cameraMatrix, distCoeffs, newCameraMatrix)
cv2.undistort()是带有单位矩阵的cv2.initUndistortRectifyMap()和使用双线性插值方法的cv2.remap的结合
src:畸变的原图像cameraMatrix:相机的内参矩阵
distCoeffs:相机的畸变矩阵
newCameraMatrix:校正后的相机内参矩阵,若没有定义,则可以直接使用None
dst:去畸变后的图像
单目投影
该模块函数的作用是将世界坐标系中的三维坐标投影到像素坐标系中的二维坐标
imagePoints, jacobin = cv2.projectPoints(objectPoints, rvec, tvec, cameraMatrix, distCoeffs, aspectRatio)
objectPoints:世界坐标系的三维坐标
rvecs:相机坐标系与世界坐标系之间的旋转向量
tvecs:相机坐标系与世界坐标系之间的平移向量,这两个变量可以通过相机标定中的cv2.calibrateCamera()函数来求得
cameraMatrix:相机的内参矩阵
distCoeffs:相机的畸变矩阵
aspectRatio:可选,是否固定"宽高比"的标志,默认为0,若不为0,则相机内参矩阵中的
imagePoints:三维坐标在像素坐标系中的二维坐标
jacobin:雅可比矩阵
单目位姿估计
单目位姿估计主要用于求世界坐标系到相机坐标系的平移变量和旋转变量,当得知的世界坐标和对应的相机坐标越多,则计算的旋转变量和平移变量越精确
估计旋转变量和平移变量
retval, rvec, tvec = cv2.solveP3P(objectPoints, imagePoints, cameraMatrix, distCoeffs, useExtrinsicGuess, flags)--用于已知三个世界坐标和其对应的相机坐标
retval, rvec, tvec = cv2.solvePnP(objectPoints, imagePoints, cameraMatrix, distCoeffs, useExtrinsicGuess, flags)--用于已知多个世界坐标和其对应的相机坐标
objectPoints:世界坐标系中三维点的三维坐标
imagePoints:三维点在图像对应的像素的二维坐标
cameraMatrix:相机的内参矩阵
distCoeffs:相机的畸变矩阵
useExtrinsicGuess:可选,是否使用旋转变量初值和平移变量初值
flags:可选,选择计算PnP问题的方法,默认为cv2.SOLVEPNP_ITERATIVE
|------------------------|----|-----------------------------|
| 标志 | 简记 | 含义 |
| cv2.SOLVEPNP_ITERATIVE | 0 | 基于Levenberg-Marquardt迭代方法计算 |
| cv2.SOLVEPNP_EPNP | 1 | 使用扩展PnP方法计算 |
| cv2.SOLVEPNP_P3P | 2 | 使用P3P方法计算 |
| cv2.SOLVEPNP_DLS | 3 | 使用最小二乘法计算 |
| cv2.SOLVEPNP_UPNP | 4 | 计算旋转变量和平移变量的同时重新估计焦距和内参矩阵等 |
| cv2.SOLVEPNP_AP3N | 5 | 使用3点透视法计算 |retval:表示算法成功与否以及求解质量的关键返回值
rvecs:世界坐标系到相机坐标系之间的旋转向量
tvecs:世界坐标系到相机坐标系之间的平移向量
对于flags:当其使用cv2.SOLVEPNP_ITERATIVE时,useExtrinsicGuess默认为False
同时
方法类型 retval主要含义典型值范围 说明 SOLVEPNP_ITERATIVESOLVEPNP_SQPNP重投影误差的RMS值 (单位:像素) 0.1 - 2.0像素为优秀,< 5.0像素通常可接受。值越大,精度越差 这是最常用的类型。返回值是一个浮点数,直接衡量精度 SOLVEPNP_P3PSOLVEPNP_AP3P通常为布尔成功标志 (True/False) 或 1/0。 True(1) 或False(0)这类方法直接计算解析解,不迭代优化,所以不返回误差值 SOLVEPNP_EPNP重投影误差的RMS值 同 EPNP是默认方法,会返回误差值
修正旋转变量和平移变量
retval, rvec, tvec, inliers = cv2.solvePnPRansac(objectPoints, imagePoints, cameraMatrix, distCoeffs, useExtrinsicGuess, iterationsCount, reprojectionError, confidence, flags)
objectPoints:世界坐标系中三维点的三维坐标
imagePoints:三维点在图像对应的像素的二维坐标
cameraMatrix:相机的内参矩阵
distCoeffs:相机的畸变矩阵
useExtrinsicGuess:可选,是否使用旋转变量初值和平移变量初值
iterationsCount:可选,迭代的次数,默认为100
reprojectionError:可选,RANSAC算法计算的重投影误差的最小值,默认为8.0
confidence:可选,置信度概率,默认为0.99,其值越高,则结果越可信
flags:可选,选择计算PnP问题的方法,同上
retval:表示算法成功与否以及求解质量的关键返回值
rvecs:世界坐标系到相机坐标系之间的旋转向量
tvecs:世界坐标系到相机坐标系之间的平移向量
inliers:内点的三维坐标和二维坐标
内点是指某一个点的重投影误差小于reprojectionError的值,则该坐标点为内点,否则为外点
双目视觉
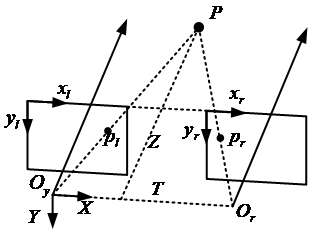
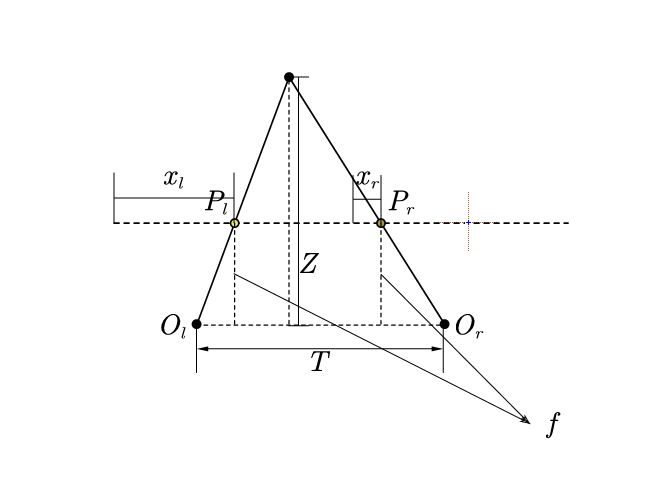
双目相机模型
如图为一个双目相机的立体成像模型,抽象出来如下
假设其具有相同的焦距f,则两部相机拍摄得到的图像位于同一平面且与x轴共线,其z轴也相互平行。其中T表示两个相机原点之间的距离,而P点则是需要捕获求解的点,其分别在两个相机中对应的成像位置为
其中
由于焦距和两原点之间的距离一般为固定值,故而某一点的深度Z只与图像的视差相关,其中f可以通过对每一个单独的相机进行标定得到,而T与两部相机的摆放位置相关
但是上述的为理想情况,两部相机很难在实际中在同一x轴上,或者两部相机的z轴完全平行,其总是存在一定的平移变量和旋转变量
双目相机和单目相机最大的区别便在于外参单目相机外参系数(旋转变量和平移变量)是该物体相对于相机的旋转和平移,即是世界坐标系到相机坐标系的变化关系
双目相机有着三组外参系数(旋转变量和平移变量),其中两组便是单目相机中世界坐标系到左右两个相机坐标系的变化关系,还有一个则描述右相机相对于左相机的位置和姿态
对于双目相机的三组外参系数,其中最终重要的便是第三组外参系数(描述右相机相对于左相机的位置和姿态),这一组系数直接描述点的深度,其除了旋转变量和平移变量外,还有一个基线长度,其为平移变量的模长
双目相机标定
retval, cameraMatrix1, discCoeffs1, cameraMatrix2, discCoeffs2, R, T, E, F = cv2.stereoCalibrate(objectPoints, imagePoints1, imagePoints2, cameraMatrix1, discCoeffs1, cameraMatrix2, discCoeffs2, imageSize, flags, criteria)
objectPoints:棋盘格内角点的三维坐标
imagePoints1:棋盘格左相机拍摄的图像中的像素坐标
imagePoints1:棋盘格右相机拍摄的图像中的像素坐标
cameraMatrix1:左相机的内参矩阵
discCoeffs1:左相机的畸变系数
cameraMatrix2:右相机的内参矩阵
discCoeffs2:右相机的畸变系数
imageSize:图像的尺寸
flags:可选,选择双目相机标定算法,不同算法可以相互组合
|-----------------------------------|---------|-------------------------------------------------------------------------------------------------------|
| 标志 | 简记 | 含义 |
| cv2.CALIB_USE_INTEINSIC_GUESS | 0x00001 | 使用该参数时需要有内参矩阵的初值,否则将图像中心设置为初值,并利用最小二乘法计算焦距 |
| cv2.CALIB_FIX_PRINCIPAL_POINT | 0x00004 | 进行优化时固定光轴在图像中的投影点 |
| cv2.CALIB_FIX_ASPECT_RATIO | 0x00002 | 将
| cv2.CALIB_ZERO_TANGENT_DIST | 0x00008 | 忽略切向畸变,将切向畸变系数设置为0 |
| cv2.CALIB_FIX_K1,···,CALIB_FIX_K6 | 无 | 最后的数字可以改为1~6,一共6个标志,表示对应的径向畸变系数不变 |
| cv2.CALIB_RATIONAL_MODEL | 0x04000 | 用六阶径向畸变修正公式,否则用三阶 |criteria:可选,迭代终止的条件
R:两个相机之间的选择矩阵
T:两个相机之间的平移变量
E:两个相机之间的本征矩阵
F:两个相机之间的基本矩阵
前面的8个参数都与单目相机中的相同,其中R和T即使上文所说的第三组外参系数,而后面的两个矩阵,本征矩阵包含三组外参系数,而基本矩阵除了三组外参系数外,还包含两部相机的内参矩阵
双目相机校正
R1, R2, P1, P2, Q, validPixROI1, validPixROI1 = cv2.stereoRectify(cameraMatrix1, discCoeffs1, cameraMatrix2, discCoeffs2, imageSize, R, T, flags, alpha, newImageSize)
cameraMatrix1:左相机的内参矩阵
discCoeffs1:左相机的畸变系数
cameraMatrix2:右相机的内参矩阵
discCoeffs2:右相机的畸变系数
imageSize:图像的尺寸
R:两个相机之间的选择矩阵
T:两个相机之间的平移变量
flags:可选,校正图像时图像中心位置是否固定的标志
alpha:可选,缩放参数
newImageSize:可选,校正后图像的大小
R1:把左相机校正前的图像坐标转化为校正后的图像坐标所需的旋转矩阵
R2:把右相机校正前的图像坐标转化为校正后的图像坐标所需的旋转矩阵
P1:左相机校正后坐标系的投影矩阵
P2:右相机校正后坐标系的投影矩阵
Q:深度差异映射矩阵
validPixROI1:第一张图像输出矩形
validPixROI2:第二张图像输出矩形
输出Q主要用于相机的立体测距,与图像校正无关flags参数可选0或cv2.CALIB_ZERO_DISPARITY,选择0表示校正时会移动图像以最大化有用区域;选择cv2.CALIB_ZERO_DISPARITY表示相机光轴在图像上投影的光电中心固定
alpha参数可选-1和0~1之间的值,选择-1表示不进行缩放;选择0表示对图像进行缩放和平移以使图像中有效像素最大限度地显示;选择1表示显示显示校正后的全部图像
# -*- coding:utf-8 -*- import cv2 as cv import numpy as np import sys def compute_points(img): # 转为灰度图像 gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) # 定义方格标定板内角点数目(行,列) board_size = (9, 6) # 计算方格标定板角点 _, points = cv.findChessboardCorners(gray, board_size) # 细化角点坐标 _, points = cv.find4QuadCornerSubpix(gray, points, (5, 5)) return points if __name__ == '__main__': # 生成棋盘格内角点的三维坐标 obj_points = np.zeros((54, 3), np.float32) obj_points[:, :2] = np.mgrid[0:9, 0:6].T.reshape(-1, 2) obj_points = np.reshape(obj_points, (54, 1, 3)) * 10 # 计算棋盘格内角点的三维坐标及其在图像中的二维坐标 all_obj_points = [] all_points_L = [] all_points_R = [] imageLs = [] imageRs = [] for i in range(1, 5): # 读取图像 imageL = cv.imread('./images/left0{}.jpg'.format(i)) if imageL is None: print('Failed to read left0{}.jpg.'.format(i)) sys.exit() imageLs.append(imageL) imageR = cv.imread('./images/right0{}.jpg'.format(i)) if imageR is None: print('Failed to read right0{}.jpg.'.format(i)) sys.exit() imageRs.append(imageR) # 获取图像尺寸 h, w = imageL.shape[:2] # 计算三维坐标 all_obj_points.append(obj_points) # 计算二维坐标 all_points_L.append(compute_points(imageL)) all_points_R.append(compute_points(imageR)) # 分别计算相机内参矩阵和畸变系数 _, cameraMatrix1, distCoeffs1, rvecs1, tvecs1 = cv.calibrateCamera(all_obj_points, all_points_L, (w, h), None, None) _, cameraMatrix2, distCoeffs2, rvecs2, tvecs2 = cv.calibrateCamera(all_obj_points, all_points_R, (w, h), None, None) # 进行标定 _, _, _, _, _, R, T, E, F = cv.stereoCalibrate(all_obj_points, all_points_L, all_points_R, cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, (w, h), flags=cv.CALIB_USE_INTRINSIC_GUESS) # 计算校正变换矩阵 R1, R2, P1, P2, Q, _, _ = cv.stereoRectify(cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, (w, h), R, T, flags=0) # 计算校正映射矩阵 mapL1, mapL2 = cv.initUndistortRectifyMap(cameraMatrix1, distCoeffs1, None, None, (w, h), 5) mapR1, mapR2 = cv.initUndistortRectifyMap(cameraMatrix2, distCoeffs2, None, None, (w, h), 5) # 校正 for i in range(len(imageLs)): # 校正图像 result1 = cv.remap(imageLs[i], mapL1, mapL2, cv.INTER_LINEAR) result2 = cv.remap(imageRs[i], mapR1, mapR2, cv.INTER_LINEAR) # 拼接图像(同样处理原图像以便做对比) origin = np.concatenate([imageLs[i], imageRs[i]], 1) result = np.concatenate([result1, result2], 1) # 绘制直线,用于比较同一个内角点y轴是否一致 origin = cv.line(origin, (0, int(all_points_L[i][0][0][1])), (len(result[0]), int(all_points_L[i][0][0][1])), (0, 0, 255), 2) result = cv.line(result, (0, int(all_points_L[i][0][0][1])), (len(result[0]), int(all_points_L[i][0][0][1])), (0, 0, 255), 2) # 展示结果 cv.imshow('origin', origin) cv.imshow('result', result) k = cv.waitKey(0) # 设置点击enter键继续,其它键退出 if k == 13: cv.destroyAllWindows() else: sys.exit()
人脸跟踪
级联分类器
一般所在目录为\Python\Lib\site-packages\cv2\data\
其中cv2存在一些已经训练好的检测方法
原文链接:https://blog.csdn.net/DDDDWJDDDD/article/details/147028992
|--------------------------------------------|---------------|
| 次联分类器XML文件名 | 检测的内容 |
| haarcascade_frontalface_default.xml | 正面人脸(最常用) |
| haarcascade_frontalface_alt.xml | 正面人脸(另一种训练版本) |
| haarcascade_frontalface_alt2.xml | 正面人脸(更高准确率) |
| haarcascade_frontalface_alt_tree.xml | 正面人脸(树结构) |
| haarcascade_profileface.xml | 侧脸检测 |
| haarcascade_eye.xml | 检测双眼 |
| haarcascade_eye_tree_eyeglasses.xml | 戴眼镜的人眼检测 |
| haarcascade_mcs_mouth.xml | 嘴部检测(效果一般) |
| haarcascade_smile.xml | 微笑检测 |
| haarcascade_mcs_nose.xml | 鼻子检测(旧版本) |
| haarcascade_upperbody.xml | 上半身 |
| haarcascade_lowerbody.xml | 下半身 |
| haarcascade_fullbody.xml | 整个人体 |
| haarcascade_righteye_2splits.xml | 右眼检测 |
| haarcascade_lefteye_2splits.xml | 左眼检测 |
| haarcascade_licence_plate_rus_16stages.xml | 俄罗斯车牌 |
| haarcascade_russian_plate_number.xml | 俄罗斯车牌(更高精度) |
| haarcascade_catface.xml | 猫脸检测 |
| haarcascade_catface_extended.xml | 猫脸(增强版) |
使用方法--先加载次联分类器,再使用分类器识别图像
<CascadeClassifier object> = cv2.CascadeClassifier(filename)
filename:级联分类器的XML文件名
CascadeClassifier object:分类器对象
对于添加次联分类器的地址一般有两张方法第一种是直接使用其所在文件夹的位置,比如我自己的为
D:/python/Lib/site-packages/cv2/data/haarcascade_frontalface_default.xml第二种是通过opencv自己来帮忙找--推荐使用
cv2.data.haarcascade + 'haarcascade_frontalface_default.xml'
objects = CascadeClassifier.detectMultiScale(image, scaleFactor, minNeighors, minSize, maxSize)
CascadeClassifier:上面加载的分类器对象
image:待分析的图像
scaleFactor:可选,扫描图像时的缩放比例,一般为1.05~1.4
minNeighors:可选,每个候选区至少保留多少个检测结果才可以判定为人脸。该值越大,分析的误差越小,一般取3~6
minSize:可选,最小的目标尺寸
maxSize:可选,最大的目标尺寸
objects:捕捉到的目标区域数组,数组每一个元素都是一个目标区域,每一个目标区域都包含四个值,分别是:左上角点横坐标、左上角点纵坐标、区域宽、区域高
人脸识别
Eigenfaces人脸识别器
Eigenfaces通过主成分分析(PCA)来将人脸数据转化到另一个空间维度去做相似性计算。在计算过程中,算法可以忽略掉一些无关紧要的数据,仅识别一些具有代表性的"特征"数据,最后根据这些数据来识别人脸。
创建人脸识别器对象
recognizer = cv2.face.EigenFaceRecognizer_create(num_components, thresold)
num_components:可选,PCA方法中保留的分量个数
threshold:可选,人脸识别时使用的阈值
recognizer:创建完的Eigenfaces人脸识别器对象
训练识别器
recognizer.train(src, labels)
recognizer:已有的Eigenfaces人脸识别器对象
src:用来训练的人脸图像样本列表,格式为list。样本宽高必须一致
labels:样本对应的标签,格式为数组,元素类型为整数。数组长度必须与样本列表长度相同。样本与标签按照插入顺序一一对应
对于labels可以先使用list列表,通过append添加标签,最后使用numpy.array(labels)来转化为数组
识别对象
label, confidence = recognizer.predict(src)
recognizer:已有的Eigenfaces人脸识别器对象
src:需要识别的人脸图像,该图像宽高必须与样本一致
label:与样本匹配长度最高的标签值
confidence:匹配程度最高的信用度评分。评分小于5000就可以认为匹配度较高,0分则表示完全一致
Fisherfaces人脸识别器
Fisherfaces通过线性判别分析技术(LDA)来将人脸数据转化为另一个空间维度去做投影计算,最后根据不同人脸数据的投影距离来判断其相似度。
创建人脸识别器对象
recognizer = cv2.face.FisherFacesRecognizer_create(num_components, thresold)
num_components:可选,LDA方法中保留的分量个数
threshold:可选,人脸识别时使用的阈值
recognizer:创建完的Fisherfaces人脸识别器对象
训练识别器
recognizer.train(src, labels)
recognizer:已有的Fisherfaces人脸识别器对象
src:用来训练的人脸图像样本列表,格式为list。样本宽高必须一致
labels:样本对应的标签,格式为数组,元素类型为整数。数组长度必须与样本列表长度相同。样本与标签按照插入顺序一一对应
对于labels可以先使用list列表,通过append添加标签,最后使用numpy.array(labels)来转化为数组
识别对象
label, confidence = recognizer.predict(src)
recognizer:已有的Fisherfaces人脸识别器对象
src:需要识别的人脸图像,该图像宽高必须与样本一致
label:与样本匹配长度最高的标签值
confidence:匹配程度最高的信用度评分。评分小于5000就可以认为匹配度较高,0分则表示完全一致
Local Binary Pattern Histogram 人脸识别器(LBPH)
Local Binary Pattern Histogram通过局部二值模式算法来将训练人脸数据,其善于捕捉局部纹理特征。
创建人脸识别器对象
recognizer = cv2.face.LBPHFaceRecognizer_create(radius, neighbors, grid_x, grid_y, threshold)
radius:可选,圆形局部二进制模式的半径
neighbors:可选,圆心局部二进制模式的采样点数目
grid_x:可选,水平方向上的单元格数
grid_y:可选,垂直方向上的单元格数
threshold:可选,人脸识别时使用的阈值
训练识别器
recognizer.train(src, labels)
recognizer:已有的LBPHFace人脸识别器对象
src:用来训练的人脸图像样本列表,格式为list。样本宽高必须一致
labels:样本对应的标签,格式为数组,元素类型为整数。数组长度必须与样本列表长度相同。样本与标签按照插入顺序一一对应
对于labels可以先使用list列表,通过append添加标签,最后使用numpy.array(labels)来转化为数组
识别对象
label, confidence = recognizer.predict(src)
recognizer:已有的LBPHFace人脸识别器对象
src:需要识别的人脸图像,该图像宽高必须与样本一致
label:与样本匹配长度最高的标签值
confidence:匹配程度最高的信用度评分。评分小于50就可以认为匹配度较高,0分则表示完全一致
视频分析
现在更加主流的目标跟踪都需要结合深度学习(也有像相关滤波的一些方法现在也较为普及),它利用深度神经网络强大的特征提取能力,能自动学习目标的外观和运动模式,对遮挡、形变、光照变化等复杂情况有更好的鲁棒性。但是opencv主要是图像检测的函数库,对于深度学习的要求较低,因此这里不过多介绍原理或者算法,只介绍函数的使用
差值法检测移动物体
对于实时性要求高、背景相对静止、目标运动较快的简单监控场景适用,其计算简单,速度快,实时性好,但是对于慢速或静止目标不敏感
计算像素差值绝对值
dst = cv2.absdiff(src1, src2)
src1:第一张图像
src2:第二张图像
dst:两个数据差值的绝对值
import cv2 import sys import numpy as np def pre_process(img): """图像预处理""" gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转化为灰度图像 gray_img = cv2.GaussianBlur(gray_img, (5, 5), 0) # 高斯滤波 return gray_img if __name__ == '__main__': # 加载视频图像 capture = cv2.VideoCapture('./images/bike.avi') if not capture.isOpened(): print("视频未加载成功") sys.exit() # 获取视频属性 fps = capture.get(cv2.CAP_PROP_FPS) width = capture.get(cv2.CAP_PROP_FRAME_WIDTH) height = capture.get(cv2.CAP_PROP_FRAME_HEIGHT) num_fps = capture.get(cv2.CAP_PROP_FRAME_COUNT) print(f"视频宽度{width},视频高度{height},视频速度{fps},视频总长度{num_fps}") frame_fps = 0 # 读取视频帧数 retval, pre_image = capture.read() if not retval: print("视频未读取成功") sys.exit() pre_gray_image = pre_process(pre_image) kernel = cv2.getStructuringElement(0, (5, 5)) # 生成滤波核 while True: # 再读一帧 retval, image = capture.read() frame_fps += 1 if frame_fps == num_fps: print("视频读取完成") sys.exit() if not retval: print("视频未读取成功") sys.exit() gray_image = pre_process(image) # 获得两个图像的差值 image_different = cv2.absdiff(gray_image, pre_gray_image) # 形态学处理 ret, image_different = cv2.threshold(image_different, 25, 255, cv2.THRESH_BINARY) # 阈值处理 image_different = cv2.morphologyEx(image_different, cv2.MORPH_OPEN, kernel) # 开运算 image_different = cv2.dilate(image_different, kernel, iterations = 2) # 使边缘膨胀 # 轮廓检测绘制 contours, hierarchy = cv2.findContours(image_different, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) for cnt in contours: # 如果轮廓面积太小,认为是噪点,直接跳过 area = cv2.contourArea(cnt) if area < 150: continue # 绘制外接矩形 rect = cv2.boundingRect(cnt) cv2.rectangle(image, rect, (0, 255, 0), 2) # 显示图像 cv2.imshow("origin", image) cv2.imshow("result", image_different) pre_gray_image = gray_image.copy() if cv2.waitKey(50) & 0xFF == 27: break capture.release() cv2.destroyAllWindows()
均值迁移法目标跟踪(爬山算法)
对于目标与背景颜色区分明显、运动相对平缓、无严重遮挡的场景适用,其计算速度较快,但是过于依赖颜色特征,在相似背景或者目标被遮挡时会失去跟踪
选择ROI区域
retval = cv2.selectROI(windowName, img, showCrosshair, fromCenter)
windowName:显示图像的窗口名称
img:选择ROI的原图像
showCrosshair:可选,是否在矩形中心显示十字准线
fromCenter:可选,ROI中心位置与光标当前位置的关系
均值迁移法
retval, window = cv2.meanShift(probImage, window, criteria)
probImage:目标区域的直方图反向投影
window:直方图反向投影图像中的初始搜索窗口和搜索结束时的窗口
criteria:停止迭代算法的条件
retval:是否搜索到目标
window:搜索到的窗口位置,以(x, y, w, h)返回
自适应均值迁移法
retval, window = cv2.CamShift(proImage, window, criteria)
probImage:目标区域的直方图反向投影
window:直方图反向投影图像中的初始搜索窗口和搜索结束时的窗口
criteria:停止迭代算法的条件
retval:是否搜索到目标
window:搜索到的窗口位置,以(x, y, w, h)返回
光流法
对于需要分析目标运动轨迹和速度、硬件计算资源充足的研究或离线分析适用,其无需预知场景信息,但是计算非常复杂,而且实时性差,对光照变化和噪声敏感
Farneback稠密光流法
flow = cv2.calcOpticalFlowFarnback(prev, next, flow, pyr_scale, levels, winsize, iterations, poly_n, poly_sigam, flags)
prev:前一帧图像
next:当前帧图像
flow:输出的光流图像,输入一般为None
pyr_scale:图像金字塔两层之间尺寸缩放的比例,其值需要小于1
levels:构建图像金字塔的层数,若为1则不构建图像金字塔
winsize:均值窗口的尺寸
iterations:算法在每个金字塔图层中迭代的次数
poly_n:在每个像素中找到多项式展开的像素邻域的大小,一般为5或7,其值越大则图像将用更光滑的表面相似,算法更加稳健,但是会模糊光流运动场
poly_sigam:高斯标准差,平滑导数,一般为1~1.5
flags:计算方法,使用cv2.OPTFLOW_USE_INITIAL_FLOW时,表示使用输入流作为初始流的近似值,使用cv2.OPTFLOW_FARNEBACK_GAUSSIAN时,表示使用高斯滤波器代替方框滤波器进行光流估计,更加精确但是运算会更慢
LK稀疏光流法
nextPts, status, err = cv2.calcOpticalFlowPyrLK(prevImg, nextImg, prevPts, nextPts, status, err, winSize, maxLevel, criteria, flags, minEigThreshold)
prevImg:前一帧图像
nextImg:当前帧图像
prevPts:前一帧图像的稀疏光流点坐标
nextPts:当前帧图像的稀疏光流点坐标
status:可选,输出状态向量
err:可选,输出误差向量
winSize:可选,每层金字塔中搜索窗口的大小
maxLevel:可选,构建的图像金字塔层数
criteria:可选,迭代搜索的终止条件
flags:可选,寻找匹配光流点的操作标志
minEigThreshold:可选,响应的最小特征值