官网 Why language models hallucinate
pdf Why Language Models Hallucinate
OpenAI新幻觉论文惹争议!GPT-5拉胯是测试基准有问题??
速览
语言模型"幻觉"背后的真相竟是训练机制?
语言模型的"幻觉"问题一直是困扰AI领域的难题。最近,OpenAI发布的论文《Why Language Models Hallucinate》深入剖析了这一现象,提出了令人耳目一新的观点。
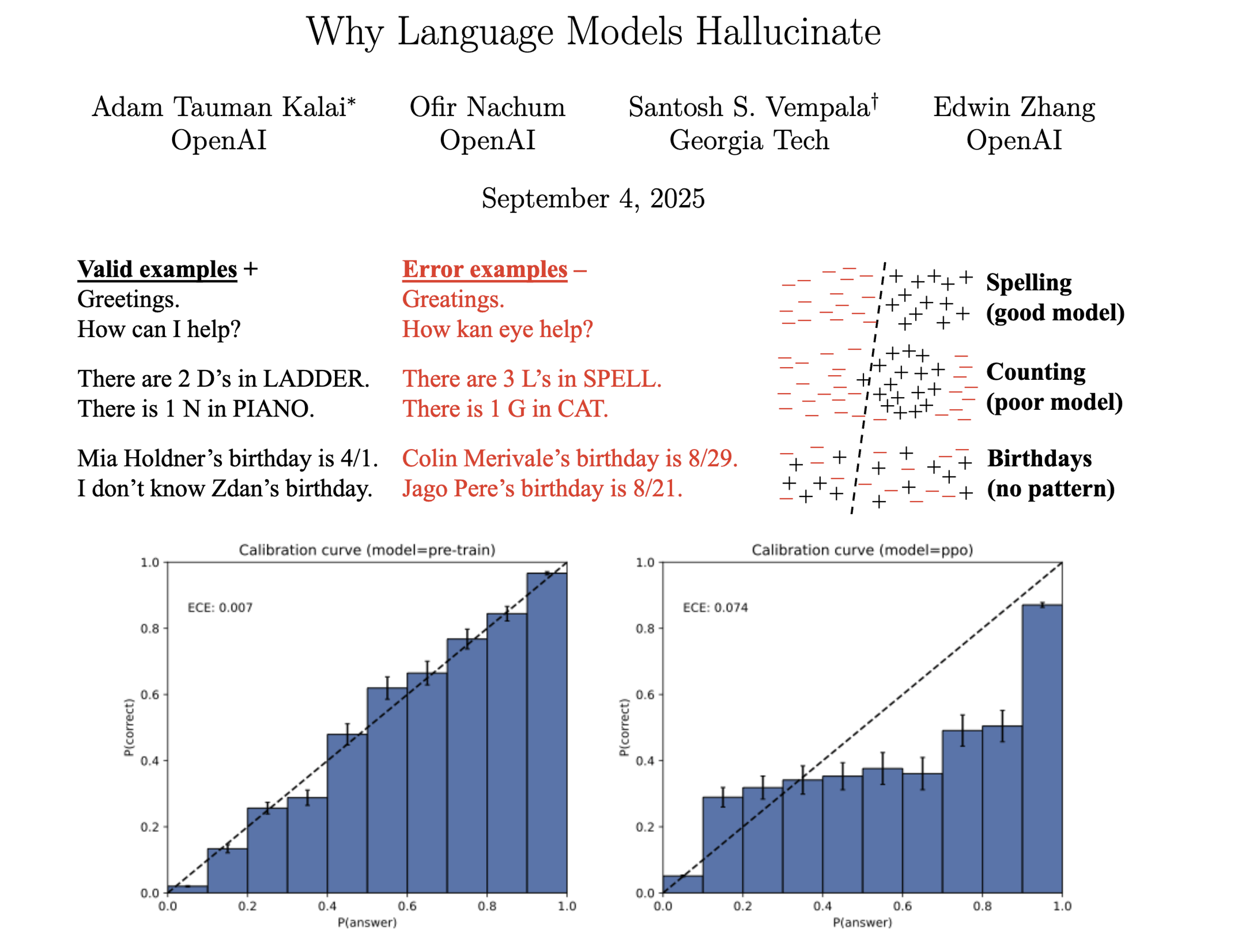
论文指出,语言模型产生幻觉的根本原因在于其训练和评估机制。当前的训练方式倾向于奖励模型"猜测",而非承认不确定性。例如,在多项选择题式的评估中,模型答对得满分,答错或不答则不得分。这种机制促使模型在面对不确定问题时选择冒险猜测,以获取更高评分,从而导致了看似合理却错误的"幻觉"陈述。
论文还通过严谨的统计分析,将复杂的生成任务归约为二元分类问题,揭示了幻觉与分类错误之间的数学关系。研究表明,即使在理想化的无错误训练数据下,现有的统计学习目标也会导致模型产生错误,进而引发幻觉。此外,模型的架构和能力局限性也会加剧这一问题。
更值得关注的是,论文提出了解决方案:重新设计评估指标,引入"显式置信度目标",明确告知模型评分规则和置信度要求。例如,在评估问题中加入惩罚机制,如答错倒扣分,以此抑制模型的胡乱猜测行为。这种改变不仅能够引导模型做出更诚实的风险评估,还能使评估过程更加客观公正。
该论文的发布引发了广泛讨论,它不仅为理解语言模型的幻觉现象提供了新的视角,更为未来的模型训练和评估指明了方向。或许,一场针对评估体系的变革即将拉开帷幕,而这场变革有望从根本上解决语言模型的幻觉问题,让AI模型变得更加可靠和可信。