在自动驾驶领域,V2X 技术虽能突破单车感知局限,但现有研究难充分利用帧间时间线索支撑轨迹预测。同济大学团队提出 Co-MTP 框架,创新实现历史与未来双时间域融合,以异构图 Transformer 处理不完整历史轨迹、扩展至未来域捕捉交互,在 V2X-Seq 数据集获最优性能,且对噪声和延迟具强鲁棒性。
原文链接:https://arxiv.org/pdf/2502.16589
项目主页:https://xiaomiaozhang.github.io/Co-MTP/
代码链接:https://github.com/xiaomiaozhang/Co-MTP
沐小含持续分享前沿算法论文,欢迎关注...
一、引言
1.1 研究背景与核心问题
自动驾驶车辆(AVs)需在复杂动态环境中实现安全高效运行,轨迹预测作为感知与规划的关键衔接环节,其准确性直接决定驾驶安全性。然而,单车辆传感器存在感知范围有限、遮挡频发等固有缺陷,易导致轨迹历史信息不完整,进而引发预测偏差甚至灾难性后果。
车联网(V2X)技术通过多智能体信息共享,为突破单车感知局限、穿透遮挡提供了理想范式。但现有 V2X 相关研究多聚焦于单帧协同感知,尚未充分探索如何利用 V2X 捕捉帧间时间线索,以支撑轨迹预测乃至后续规划任务。此外,真实场景中存在两大核心挑战:
- 历史轨迹不完整:多智能体传感器性能、覆盖范围差异显著,同一目标可能被多智能体同时漏检,简单的轨迹拼接无法处理传感器误差与时间戳缺失问题;
- 未来交互缺失:预测的核心目标是支撑规划,但现有方法要么仅依赖孤立预测导致车辆过度保守,要么仅考虑自车规划意图导致驾驶激进,均未充分融合周边智能体的未来意图。
1.2 研究目标与贡献
本文提出Co-MTP(Cooperative Multi-Temporal fusion Prediction) 框架,首次实现 V2X 环境下历史与未来双时间域的全面融合,为规划导向的轨迹预测提供解决方案。核心贡献如下:
- 提出首个跨历史 - 未来双时间域的通用协同轨迹预测框架,充分挖掘 V2X 的时间维度信息价值;
- 设计异构图 Transformer 结构,有效融合多智能体的不完整历史轨迹,捕捉历史交互特征;
- 扩展异构图至未来域,建模自车规划与周边车辆未来意图的交互关系,输出特定规划动作下的未来场景状态;
- 在真实世界数据集 V2X-Seq 上验证,取得当前最优性能,且通过鲁棒性测试验证了模型在噪声与延迟场景下的可靠性。
二、相关工作
2.1 协同预测(Cooperative Prediction)
现有 V2X 研究以单帧协同感知为主,协同预测领域仍处于起步阶段:
- V2VNet:首个探索 V2X 协同感知与预测的端到端模型,但预测头设计简单,未考虑地图信息与复杂交互;
- V2X-Seq:开源首个 V2X 序列数据集,为协同预测提供数据支撑;
- V2XPnP:提出端到端协同感知与预测的通用框架及序列数据集;
- V2X-Graph:基于 V2X-Seq 构建图神经网络,学习协同轨迹表示,但仅聚焦历史域融合,未充分利用多时间域信息。
2.2 规划感知预测(Planning-informed Prediction)
预测与规划的耦合是交互场景安全驾驶的核心:
- PiP 模型:首次将规划信息融入预测过程;
- 后续研究(Liu et al.、Huang et al.)进一步融合预测与优化规划模块,但仅考虑自车规划会导致过度乐观预测与危险行为,需补充周边智能体的未来意图。
2.3 交互感知预测(Interaction-aware Prediction)
轨迹预测的核心是捕捉智能体间交互,特征提取器经历三代演进:
- CNN:早期用于交互特征提取,但难以建模长时依赖;
- GNN:通过节点 - 边结构建模复杂交互,适用于多智能体场景;
- Transformer:基于多头注意力机制,无需顺序处理即可捕捉序列时间特征,在处理不完整轨迹与多源融合方面具有天然优势。
三、方法论详解
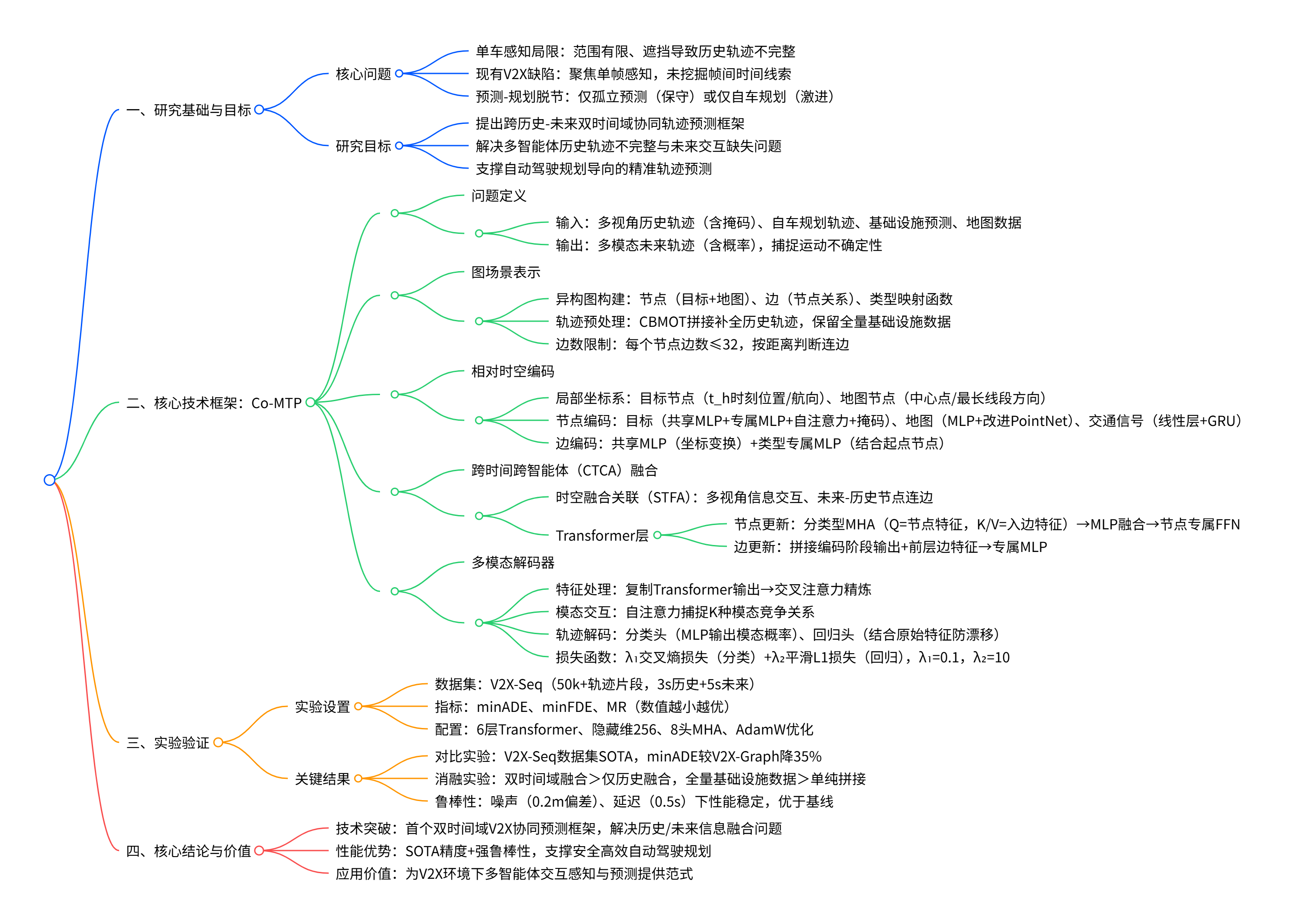
Co-MTP 框架整体架构如图 1 所示,核心流程包括:场景图构建、相对时空编码、跨时间跨智能体融合、多模态解码四大模块,实现 AV 与基础设施的历史信息、未来预测结果及自车规划信息的深度融合。
注:基础设施向自车共享历史数据与预测结果,基于处理后的轨迹数据和地图信息构建异构场景图,通过 CTCA Fusion 模块更新节点与边特征,最终由多模态解码器输出多模态轨迹预测结果。
3.1 问题定义
3.1.1 输入信息
- 历史轨迹:多视角(AV + 基础设施)观测的目标轨迹,含坐标、航向、速度等,伴随掩码向量标记数据有效性(1 表示存在,0 表示缺失);
- 未来信息:自车规划轨迹(通过五次多项式插值未来真实轨迹模拟)、基础设施预测的周边目标未来轨迹;
- 地图数据:道路、交通信号等,以折线 / 多边形表示(如车道线、斑马线、停止线)。
3.1.2 预测目标
学习模型,输入上述信息输出周边目标的未来轨迹
,并输出多模态预测结果及对应概率,以捕捉轨迹不确定性。
3.2 图场景表示(Scene Representing with Graph)
3.2.1 异构图构建(Heterogeneous Graph)
构建异构图,其中:
- 节点集
:包含目标节点(车辆、行人、自行车等)与地图节点(道路、交通信号);
- 边集
- 类型映射函数
3.2.2 轨迹数据预处理
- 历史轨迹:采用 CBMOT 方法拼接 AV 与基础设施的历史轨迹,利用高检测分数插值补全缺失数据,同时保留原始基础设施轨迹作为图节点,避免信息丢失;
- 未来轨迹:包含自车规划轨迹与基础设施预测的周边目标轨迹;
- 边数限制:为降低计算量,每个节点的边数设为上限(32),目标节点基于最后时刻位置计算距离,地图节点采用到折线 / 多边形的最短距离判断是否连边。
3.3 相对时空编码(Relative Spatial-Temporal Encoding)
3.3.1 局部坐标系(Local Coordinate System)
为实现归一化交互学习,为每个节点建立局部坐标系:
- 目标节点:以最后时刻
- 地图节点:以中心点坐标为位置基准,最长线段方向为航向基准。
3.3.2 图节点编码
- 目标节点:位置特征经共享参数 MLP 编码后,与边界框、速度等信息拼接,输入 AV / 基础设施专属 MLP,通过两层自注意力捕捉时空特征,掩码向量参与编码以处理轨迹不完整问题;
- 地图节点:结合坐标编码 MLP 与改进 PointNet 实现位置编码;
- 交通信号:通过线性层与 GRU 编码状态信息。
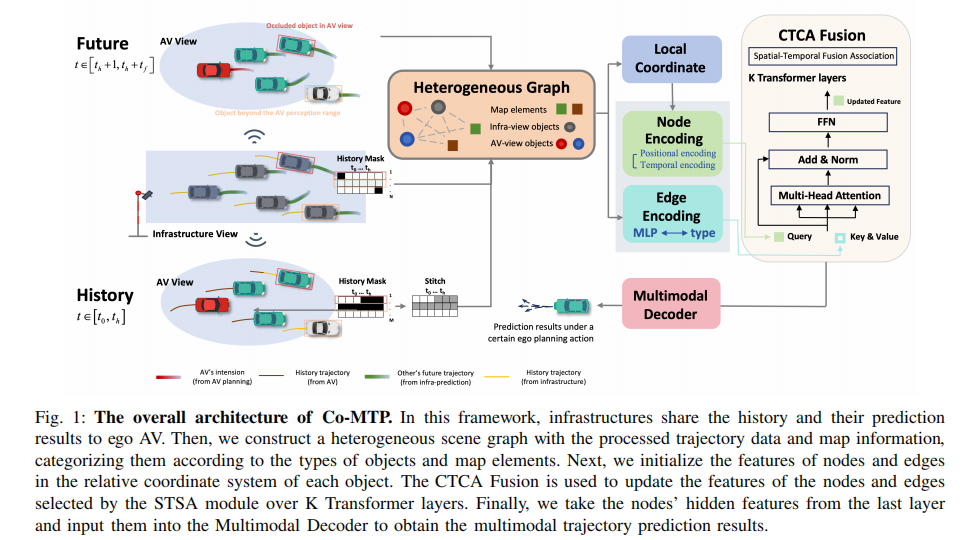
3.3.3 图边编码
-
首先通过共享参数 MLP 编码坐标变换
-
基于类型映射函数,将边与起点节点结合输入类型专属 MLP,生成初始边特征:
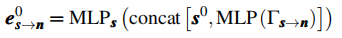
3.4 跨时间跨智能体融合(CTCA Fusion)
提出时空融合关联(STFA)模块与 K 层 Transformer,实现多视角、多时间域信息的深度融合。
3.4.1 时空融合关联(STFA)
如图 2 所示,STFA 模块的核心是建立多视角、跨时间域的信息关联:
- 多视角融合:AV 节点与基础设施节点持续交互,充分利用插值未用到的基础设施信息,学习双视角关系;
- 跨时间融合:将未来节点(自车规划、基础设施预测)与历史节点建立边连接,在特征聚合时融入未来信息。
注:AV 视角预处理后的目标节点与基础设施视角原始数据节点共同参与图构建,自车规划与基础设施预测结果作为未来节点,与历史节点建立边关系以建模未来交互。
3.4.2 Transformer 层
节点特征更新:分类型聚合边信息
节点特征更新的核心目标是,让每个节点从其不同类型的入边中精准提取有效信息,避免不同边类型的特征干扰。具体分为三步:
-
分类型多头注意力(MHA)计算 :针对节点
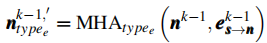
其中,
-
多类型边特征拼接与 MLP 融合 :将节点
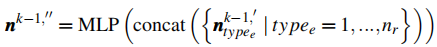
这一步解决了 "不同类型边特征如何协同作用于节点" 的问题,通过 MLP 将离散的分类型特征转化为统一的节点特征表示。
-
节点专属 FFN 更新 :将融合后的中间特征
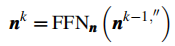
其中,
边特征更新:融合编码阶段与历史层信息
边特征更新需同时利用边在编码阶段的基础信息(确保边的属性不丢失)和前一层的边特征(确保时序连贯性),具体步骤为:
-
特征拼接 :提取边在编码阶段的两个关键输出 ------ 节点
-
MLP 更新 :将拼接后的特征输入一个与边起点节点

这一设计保证了边特征既保留了初始的空间坐标关系(
3.5 多模态解码器(Multimodal Decoder)
考虑到智能体运动的多模态特性(多种未来轨迹可能性共存),解码器设计如下:
-
特征复制与精炼:将 Transformer 输出的单组特征复制 K 次,通过交叉注意力与边特征融合,提取丰富表示;
-
模态交互建模:通过自注意力捕捉同一目标 K 种模态间的竞争关系(一种模态概率上升会导致其他模态下降);
-
轨迹解码:
- 分类头:MLP 输出 K 种模态的概率;
- 回归头:结合原始节点特征
-
损失函数:结合分类损失与回归损失:
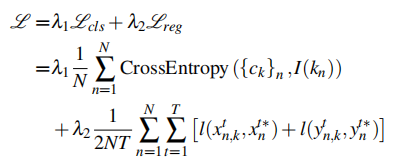
其中,
四、实验验证
4.1 实验设置
4.1.1 数据集与指标
- 数据集:V2X-Seq(真实世界 V2X 数据集),含 50,000 + 协同轨迹片段,每片段 10s(10Hz),切片为 20 个样本(3s 历史 + 5s 未来);
- 评价指标:最小平均位移误差(minADE)、最小最终位移误差(minFDE)、缺失率(MR),数值越小性能越优。
4.1.2 实现细节
- 轨迹下采样至 5Hz,地图片段用 21 个点表示,限定 250m 内地图范围;
- 模型配置:6 层 Transformer 编码器,隐藏层维度 256,多头注意力头数 8;
- 训练参数:初始学习率
4.2 对比实验
对比现有 V2X-Seq 数据集上的主流方法及基线模型,结果如表 1 所示:
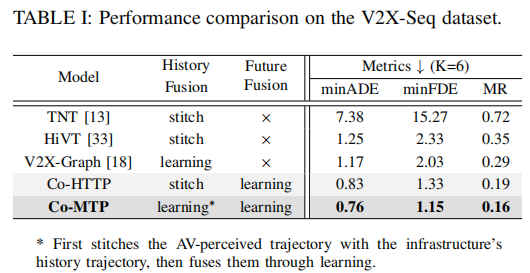
注:* 表示先通过 CBMOT 拼接 AV 与基础设施轨迹,再通过学习融合;stitch 表示 CBMOT 拼接方法。
关键结论:
- Co-MTP 在三项指标上均排名第一,minADE 较 V2X-Graph 降低 35%;
- 基线模型 Co-HTTP 的性能验证了异构图与跨时间融合策略的有效性;
- 未来融合对性能提升至关重要,仅依赖历史融合的方法(如 V2X-Graph)性能显著落后。
4.3 消融实验
为验证各模块有效性,设计历史域与未来域的消融变体,结果如表 2 所示:

注:full-infra 表示将所有基础设施信息作为图节点参与融合。
关键结论:
- 历史域融合:
- 基础设施视角(变体 2)优于单自车视角(变体 1),验证了多视角互补价值;
- 融合全量基础设施信息(变体 4)优于单纯拼接(变体 3),说明冗余信息可提升抗噪能力与融合效果;
- 未来域融合:
- 所有含未来融合的模型均优于仅考虑历史域的模型;
- 同时融入自车规划与其他目标未来轨迹(Co-MTP)性能最优,证明双未来信息的必要性;
- Co-MTP 的融合方法(stitch+full-infra)优于 Co-HTTP 的单纯拼接,验证了学习型融合的优势。
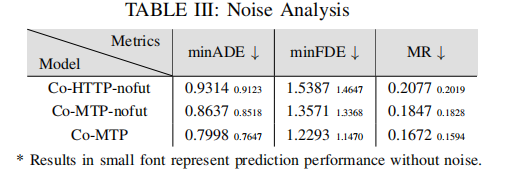
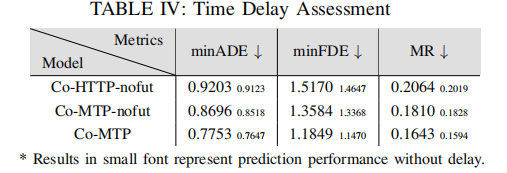
4.4 鲁棒性评估
针对 V2X 场景常见的通信噪声(位置偏差 0.2m)与延迟(0.5s),测试模型鲁棒性,对比模型包括 Co-MTP、Co-MTP-nofut(无未来融合)、Co-HTTP-nofut(无未来融合的拼接模型),结果如表 3 和表 4 所示:
噪声鲁棒性分析:
时间延迟鲁棒性评估:
关键结论:
- 所有模型在噪声与延迟下性能下降幅度极小,证明多智能体共享的丰富时间信息显著提升系统鲁棒性;
- Co-MTP 即使在噪声 / 延迟场景下,仍保持最优性能,验证了双时间域融合的稳定性;
- 延迟对模型影响小于噪声,因系统可利用历史时间线索补偿延迟带来的信息滞后。
4.5 定性结果
图 3 展示了 Co-MTP 在四种典型驾驶场景(跟车、高速行驶、加速通过路口、等待转弯)的预测效果:
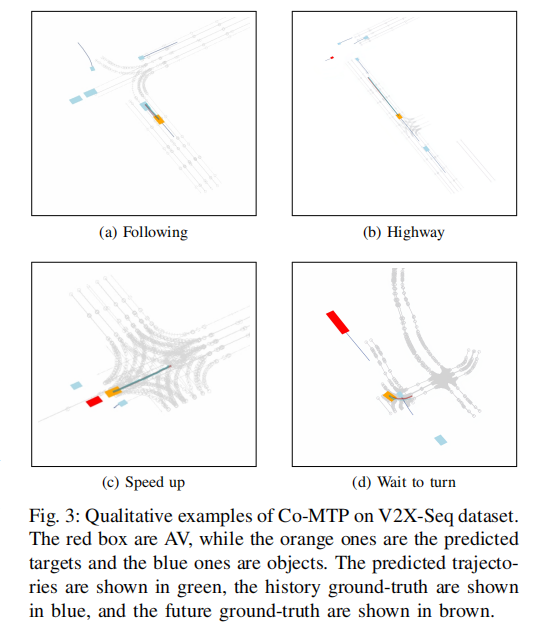
注:红色框为自车,橙色框为预测目标,蓝色框为其他目标;绿色为预测轨迹,蓝色为历史真实轨迹,棕色为未来真实轨迹。
关键观察:
- 预测轨迹严格遵循道路结构与交通规则;
- 场景(d)中,目标车辆因前方直行车未减速,预测轨迹为等待转弯,体现了未来交互建模的有效性 ------ 模型准确捕捉了多智能体间的行为影响。
五、结论与展望
5.1 核心结论
本文提出的 Co-MTP 框架,通过历史 - 未来双时间域的协同融合,解决了单车感知轨迹不完整与未来交互缺失两大核心问题:
- 异构图 Transformer 有效融合多智能体不完整历史轨迹,提升了历史信息的完整性与交互捕捉能力;
- 未来域扩展模块建模自车规划与周边目标意图的交互,避免了过度保守或激进的预测偏差;
- 在真实数据集上实现当前最优性能,且对 V2X 场景的噪声与延迟具有强鲁棒性。
5.2 未来方向
- 优化噪声鲁棒性:针对历史与未来域信息同时受噪声影响的情况,探索更有效的抗噪融合策略;
- 扩展多模态交互:进一步建模行人、非机动车等异构交通参与者的交互模式;
- 端到端规划集成:将预测模块与规划模块深度耦合,实现更高效的闭环决策;
- 动态场景适配:探索在极端天气、突发事故等复杂场景下的模型自适应能力。
附录:主页与数据集
- 论文主页:https://xiaomiaozhang.github.io/Co-MTP/
- 数据集:V2X-Seq(https://github.com/hustvl/V2X-Seq)