容器化训练环境:Docker + Kubernetes + Slurm - 大模型训练的现代化基础设施
关键词:Docker容器化、Kubernetes集群、Slurm作业调度、GPU资源管理、分布式训练、容器编排、微服务架构、DevOps、云原生、资源隔离
摘要:本文深入探讨大模型训练中的容器化环境搭建,详细介绍Docker容器技术、Kubernetes集群管理和Slurm作业调度系统的集成应用。通过实战案例和代码示例,帮助读者构建高效、可扩展、易管理的现代化训练基础设施,实现资源的最优配置和任务的智能调度。
文章目录
- [容器化训练环境:Docker + Kubernetes + Slurm - 大模型训练的现代化基础设施](#容器化训练环境:Docker + Kubernetes + Slurm - 大模型训练的现代化基础设施)
-
- 引言:为什么需要容器化训练环境?
- 第一部分:Docker容器化基础
- 第二部分:Kubernetes集群管理
-
- Kubernetes在AI训练中的价值
- GPU节点配置与标签管理
- [NVIDIA Device Plugin部署](#NVIDIA Device Plugin部署)
- 训练任务Pod配置
- 分布式训练Job配置
- 存储配置与数据管理
- 第三部分:Slurm作业调度系统
- 第四部分:容器化训练最佳实践
- 第五部分:监控与运维
- 第六部分:故障处理与优化
- 总结与展望
引言:为什么需要容器化训练环境?
想象一下,你正在管理一个拥有数百个GPU的大模型训练集群。不同的研究团队需要使用不同版本的PyTorch、CUDA驱动,有些项目需要特定的Python库版本,还有些实验需要特殊的系统配置。如果没有容器化技术,这将是一场管理噩梦。
传统的训练环境面临着诸多挑战:
- 环境冲突:不同项目的依赖库版本冲突
- 资源浪费:GPU利用率低,资源分配不均
- 部署复杂:环境配置繁琐,难以复现
- 扩展困难:集群规模扩展时配置工作量巨大
容器化技术的出现,为这些问题提供了优雅的解决方案。通过Docker + Kubernetes + Slurm的组合,我们可以构建一个现代化的、高效的、易管理的大模型训练环境。
第一部分:Docker容器化基础
容器化的核心优势
容器化技术为大模型训练带来了革命性的改变:
1. 环境一致性
容器确保了从开发到生产环境的一致性,"在我的机器上能跑"的问题成为历史。
2. 资源隔离
每个训练任务运行在独立的容器中,避免了资源竞争和环境污染。
3. 快速部署
预构建的镜像可以在几秒钟内启动,大大提高了实验效率。
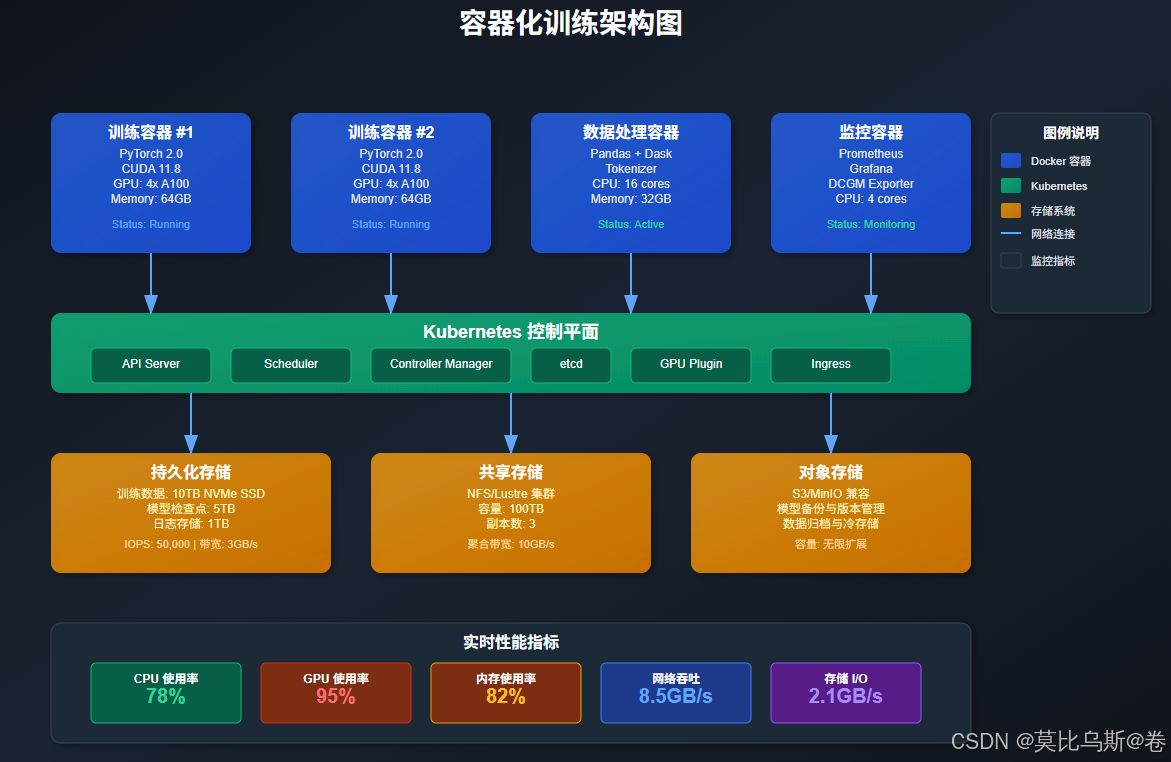
深度学习Docker镜像构建
让我们从构建一个专业的深度学习Docker镜像开始:
dockerfile
# 基础镜像选择:使用NVIDIA官方CUDA镜像
FROM nvidia/cuda:11.8-cudnn8-devel-ubuntu20.04
# 设置环境变量
ENV DEBIAN_FRONTEND=noninteractive
ENV PYTHONUNBUFFERED=1
ENV CUDA_HOME=/usr/local/cuda
ENV PATH=${CUDA_HOME}/bin:${PATH}
ENV LD_LIBRARY_PATH=${CUDA_HOME}/lib64:${LD_LIBRARY_PATH}
# 安装系统依赖
RUN apt-get update && apt-get install -y \
python3 python3-pip python3-dev \
git wget curl vim \
build-essential cmake \
libopenmpi-dev \
openssh-server \
&& rm -rf /var/lib/apt/lists/*
# 安装Python包管理工具
RUN pip3 install --upgrade pip setuptools wheel
# 安装深度学习框架
RUN pip3 install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 \
--index-url https://download.pytorch.org/whl/cu118
# 安装分布式训练相关包
RUN pip3 install \
transformers==4.30.0 \
datasets==2.12.0 \
accelerate==0.20.3 \
deepspeed==0.9.5 \
wandb==0.15.4 \
tensorboard==2.13.0
# 安装Horovod(分布式训练)
RUN HOROVOD_GPU_OPERATIONS=NCCL HOROVOD_WITH_PYTORCH=1 \
pip3 install horovod[pytorch]==0.28.1
# 创建工作目录
WORKDIR /workspace
# 设置SSH配置(用于多节点通信)
RUN mkdir /var/run/sshd && \
echo 'root:password' | chpasswd && \
sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
# 复制训练脚本和配置文件
COPY scripts/ /workspace/scripts/
COPY configs/ /workspace/configs/
# 设置入口点
CMD ["/bin/bash"]多阶段构建优化
为了减小镜像大小并提高安全性,我们可以使用多阶段构建:
dockerfile
# 构建阶段
FROM nvidia/cuda:11.8-cudnn8-devel-ubuntu20.04 AS builder
# 安装构建依赖
RUN apt-get update && apt-get install -y \
build-essential cmake git \
python3-dev python3-pip
# 编译自定义CUDA kernels
COPY kernels/ /tmp/kernels/
WORKDIR /tmp/kernels
RUN python3 setup.py build_ext --inplace
# 运行阶段
FROM nvidia/cuda:11.8-cudnn8-runtime-ubuntu20.04
# 只复制必要的运行时文件
COPY --from=builder /tmp/kernels/build/ /opt/kernels/
# 安装运行时依赖
RUN apt-get update && apt-get install -y \
python3 python3-pip \
&& rm -rf /var/lib/apt/lists/*
# 安装Python包
RUN pip3 install torch transformers datasets
WORKDIR /workspace容器资源限制与GPU访问
在训练环境中,合理的资源限制至关重要:
yaml
# docker-compose.yml
version: '3.8'
services:
llm-trainer:
build: .
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=0,1,2,3 # 指定GPU
- CUDA_VISIBLE_DEVICES=0,1,2,3
deploy:
resources:
limits:
memory: 64G
cpus: '16'
reservations:
devices:
- driver: nvidia
count: 4
capabilities: [gpu]
volumes:
- ./data:/workspace/data
- ./models:/workspace/models
- ./logs:/workspace/logs
shm_size: 8G # 增大共享内存,避免DataLoader问题
ulimits:
memlock: -1
stack: 67108864第二部分:Kubernetes集群管理
Kubernetes在AI训练中的价值
Kubernetes为大模型训练提供了强大的编排能力:
1. 自动化部署
通过声明式配置,自动化管理训练任务的生命周期。
2. 弹性伸缩
根据负载自动调整资源分配,提高集群利用率。
3. 故障恢复
自动检测和恢复失败的训练任务,保证训练的连续性。
4. 服务发现
简化分布式训练中节点间的通信配置。
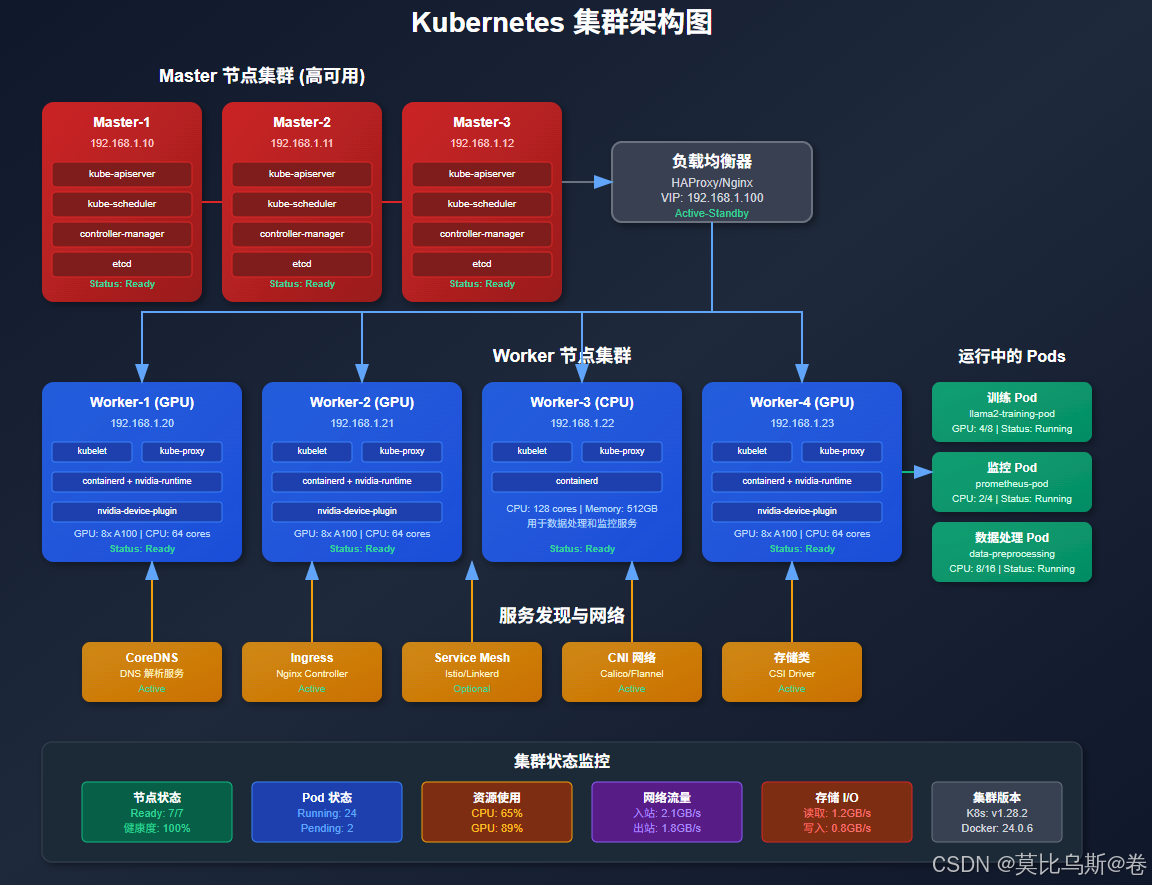
图2:Kubernetes集群架构图 - 展示了Master节点、Worker节点、Pod调度、服务发现等K8s核心组件,以及GPU设备插件、存储类和集群监控等关键功能模块
GPU节点配置与标签管理
首先,我们需要为GPU节点添加适当的标签和污点:
bash
# 为GPU节点添加标签
kubectl label nodes gpu-node-1 accelerator=nvidia-a100
kubectl label nodes gpu-node-1 gpu-memory=80Gi
kubectl label nodes gpu-node-1 node-type=gpu-worker
# 添加污点,确保只有GPU工作负载调度到GPU节点
kubectl taint nodes gpu-node-1 nvidia.com/gpu=true:NoSchedule
# 查看节点GPU资源
kubectl describe node gpu-node-1NVIDIA Device Plugin部署
为了让Kubernetes能够管理GPU资源,需要部署NVIDIA Device Plugin:
yaml
# nvidia-device-plugin.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
name: nvidia-device-plugin-ds
spec:
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
priorityClassName: "system-node-critical"
containers:
- image: nvcr.io/nvidia/k8s-device-plugin:v0.14.1
name: nvidia-device-plugin-ctr
args: ["--fail-on-init-error=false"]
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
nodeSelector:
accelerator: nvidia-a100训练任务Pod配置
创建一个完整的训练任务Pod配置:
yaml
# llm-training-job.yaml
apiVersion: v1
kind: Pod
metadata:
name: llm-training-job
labels:
app: llm-training
job-type: pretraining
spec:
restartPolicy: Never
nodeSelector:
accelerator: nvidia-a100
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
containers:
- name: trainer
image: your-registry/llm-trainer:latest
command: ["/bin/bash"]
args: ["-c", "python3 /workspace/scripts/train.py --config /workspace/configs/gpt-7b.yaml"]
resources:
limits:
nvidia.com/gpu: 4
memory: "64Gi"
cpu: "16"
requests:
nvidia.com/gpu: 4
memory: "32Gi"
cpu: "8"
env:
- name: CUDA_VISIBLE_DEVICES
value: "0,1,2,3"
- name: NCCL_DEBUG
value: "INFO"
- name: NCCL_IB_DISABLE
value: "1"
volumeMounts:
- name: training-data
mountPath: /workspace/data
- name: model-output
mountPath: /workspace/models
- name: shared-memory
mountPath: /dev/shm
volumes:
- name: training-data
persistentVolumeClaim:
claimName: training-data-pvc
- name: model-output
persistentVolumeClaim:
claimName: model-output-pvc
- name: shared-memory
emptyDir:
medium: Memory
sizeLimit: 8Gi分布式训练Job配置
对于多节点分布式训练,我们使用Job和Service:
yaml
# distributed-training-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: distributed-llm-training
spec:
parallelism: 4 # 4个worker节点
completions: 4
template:
metadata:
labels:
app: distributed-training
spec:
restartPolicy: Never
containers:
- name: worker
image: your-registry/llm-trainer:latest
command: ["/workspace/scripts/distributed_train.sh"]
env:
- name: WORLD_SIZE
value: "4"
- name: RANK
valueFrom:
fieldRef:
fieldPath: metadata.annotations['batch.kubernetes.io/job-completion-index']
- name: MASTER_ADDR
value: "distributed-training-master"
- name: MASTER_PORT
value: "23456"
resources:
limits:
nvidia.com/gpu: 8
memory: "128Gi"
requests:
nvidia.com/gpu: 8
memory: "64Gi"
volumeMounts:
- name: training-data
mountPath: /workspace/data
readOnly: true
- name: model-checkpoint
mountPath: /workspace/checkpoints
volumes:
- name: training-data
persistentVolumeClaim:
claimName: shared-training-data
- name: model-checkpoint
persistentVolumeClaim:
claimName: shared-checkpoints
---
apiVersion: v1
kind: Service
metadata:
name: distributed-training-master
spec:
selector:
app: distributed-training
ports:
- port: 23456
targetPort: 23456
clusterIP: None # Headless service存储配置与数据管理
高性能存储配置对训练性能至关重要:
yaml
# storage-class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp3
iops: "16000"
throughput: "1000"
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: training-data-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: fast-ssd
resources:
requests:
storage: 10Ti第三部分:Slurm作业调度系统
Slurm在AI集群中的作用
Slurm(Simple Linux Utility for Resource Management)是HPC领域最流行的作业调度系统,在AI训练集群中发挥着关键作用:
1. 资源管理
精确控制CPU、GPU、内存等资源的分配。
2. 队列管理
支持多优先级队列,合理安排训练任务执行顺序。
3. 公平调度
确保不同用户和项目的资源使用公平性。
4. 作业监控
提供详细的作业执行状态和资源使用统计。
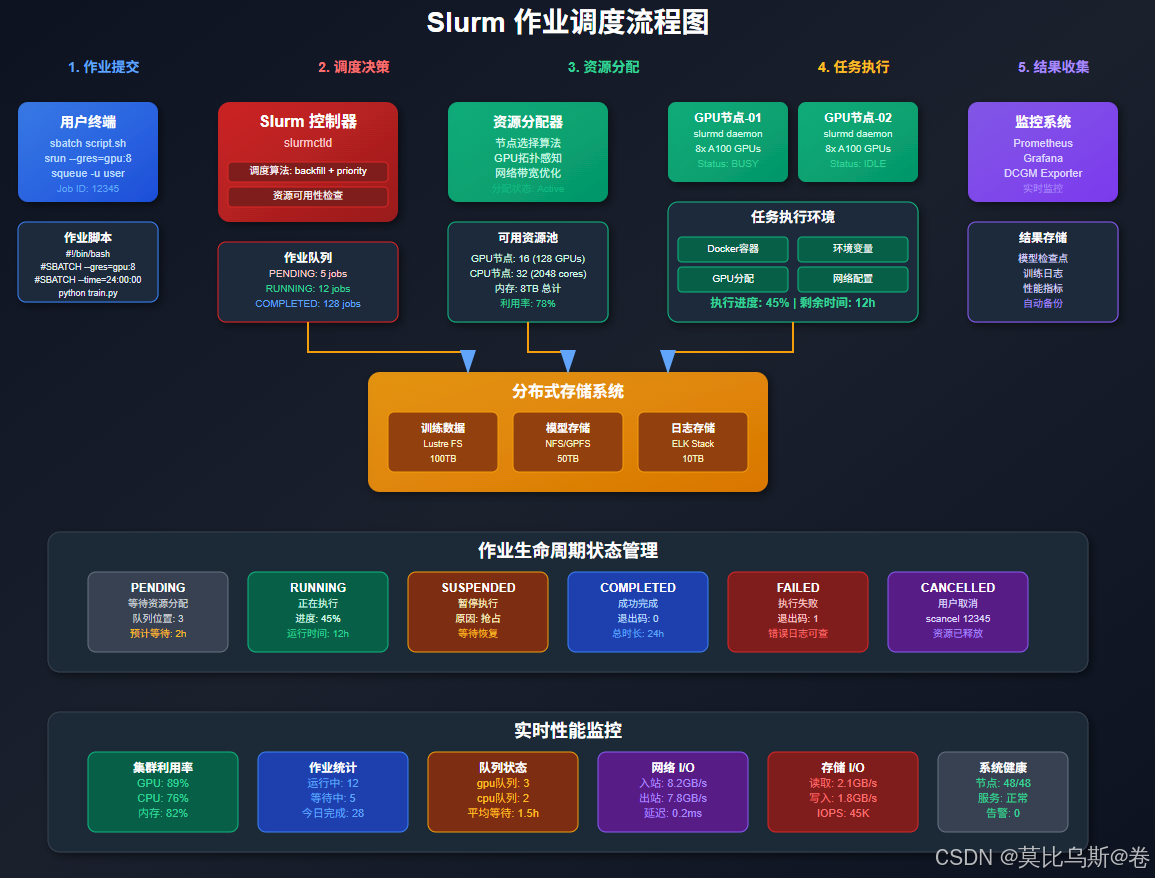
Slurm集群配置
首先配置Slurm控制节点:
bash
# /etc/slurm/slurm.conf
ClusterName=ai-cluster
ControlMachine=slurm-controller
ControlAddr=10.0.1.10
# 认证和安全
AuthType=auth/munge
CryptoType=crypto/munge
# 调度器配置
SchedulerType=sched/backfill
SelectType=select/cons_tres
SelectTypeParameters=CR_Core_Memory,CR_GPU
# 资源限制
DefMemPerCPU=4096
MaxJobCount=10000
MaxArraySize=1000
# 节点配置
NodeName=gpu-node[01-16] CPUs=64 Sockets=2 CoresPerSocket=32 ThreadsPerCore=1 \
RealMemory=512000 Gres=gpu:a100:8 State=UNKNOWN
# 分区配置
PartitionName=gpu Nodes=gpu-node[01-16] Default=YES MaxTime=7-00:00:00 State=UP
PartitionName=cpu Nodes=cpu-node[01-32] MaxTime=1-00:00:00 State=UP
PartitionName=interactive Nodes=gpu-node[01-04] MaxTime=04:00:00 State=UPGPU资源配置
配置GPU资源识别:
bash
# /etc/slurm/gres.conf
# GPU节点配置
NodeName=gpu-node01 Name=gpu Type=a100 File=/dev/nvidia0 CPUs=0-15
NodeName=gpu-node01 Name=gpu Type=a100 File=/dev/nvidia1 CPUs=16-31
NodeName=gpu-node01 Name=gpu Type=a100 File=/dev/nvidia2 CPUs=32-47
NodeName=gpu-node01 Name=gpu Type=a100 File=/dev/nvidia3 CPUs=48-63
NodeName=gpu-node01 Name=gpu Type=a100 File=/dev/nvidia4 CPUs=0-15
NodeName=gpu-node01 Name=gpu Type=a100 File=/dev/nvidia5 CPUs=16-31
NodeName=gpu-node01 Name=gpu Type=a100 File=/dev/nvidia6 CPUs=32-47
NodeName=gpu-node01 Name=gpu Type=a100 File=/dev/nvidia7 CPUs=48-63训练作业提交脚本
创建标准化的训练作业提交脚本:
bash
#!/bin/bash
# submit_training.sh
#SBATCH --job-name=llm-training
#SBATCH --partition=gpu
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=8
#SBATCH --gres=gpu:a100:8
#SBATCH --cpus-per-task=8
#SBATCH --mem=400G
#SBATCH --time=3-00:00:00
#SBATCH --output=logs/training_%j.out
#SBATCH --error=logs/training_%j.err
#SBATCH --exclusive
# 环境设置
module load cuda/11.8
module load nccl/2.18.1
module load python/3.9
# 激活虚拟环境
source /opt/conda/envs/pytorch/bin/activate
# 设置分布式训练环境变量
export MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
export MASTER_PORT=23456
export WORLD_SIZE=$SLURM_NTASKS
export RANK=$SLURM_PROCID
export LOCAL_RANK=$SLURM_LOCALID
# NCCL优化设置
export NCCL_DEBUG=INFO
export NCCL_IB_DISABLE=0
export NCCL_NET_GDR_LEVEL=2
export NCCL_P2P_LEVEL=NVL
# 启动训练
srun python3 /workspace/scripts/train_distributed.py \
--config /workspace/configs/gpt-7b-distributed.yaml \
--data-path /shared/datasets/pile \
--checkpoint-path /shared/checkpoints/$SLURM_JOB_ID \
--log-dir /shared/logs/$SLURM_JOB_ID高级调度策略
配置多队列和优先级调度:
bash
# /etc/slurm/slurm.conf 中的高级配置
# 多因子优先级
PriorityType=priority/multifactor
PriorityDecayHalfLife=7-0
PriorityCalcPeriod=5
PriorityFavorSmall=NO
PriorityMaxAge=14-0
PriorityUsageResetPeriod=NONE
PriorityWeightAge=1000
PriorityWeightFairshare=10000
PriorityWeightJobSize=1000
PriorityWeightPartition=10000
PriorityWeightQOS=2000
# QOS配置
AccountingStorageType=accounting_storage/slurmdbd
JobAcctGatherType=jobacct_gather/linux
JobAcctGatherFrequency=30作业监控与管理
创建作业监控脚本:
python
#!/usr/bin/env python3
# slurm_monitor.py
import subprocess
import json
import time
from datetime import datetime
def get_job_info():
"""获取作业信息"""
cmd = ['squeue', '--format=%i,%j,%t,%M,%l,%D,%C,%m,%b', '--noheader']
result = subprocess.run(cmd, capture_output=True, text=True)
jobs = []
for line in result.stdout.strip().split('\n'):
if line:
parts = line.split(',')
jobs.append({
'job_id': parts[0],
'name': parts[1],
'state': parts[2],
'time': parts[3],
'time_limit': parts[4],
'nodes': parts[5],
'cpus': parts[6],
'memory': parts[7],
'gres': parts[8]
})
return jobs
def get_node_info():
"""获取节点信息"""
cmd = ['sinfo', '--format=%n,%t,%c,%m,%G,%O', '--noheader']
result = subprocess.run(cmd, capture_output=True, text=True)
nodes = []
for line in result.stdout.strip().split('\n'):
if line:
parts = line.split(',')
nodes.append({
'name': parts[0],
'state': parts[1],
'cpus': parts[2],
'memory': parts[3],
'gres': parts[4],
'cpu_load': parts[5]
})
return nodes
def monitor_cluster():
"""集群监控主函数"""
while True:
timestamp = datetime.now().isoformat()
# 获取作业和节点信息
jobs = get_job_info()
nodes = get_node_info()
# 统计信息
running_jobs = len([j for j in jobs if j['state'] == 'R'])
pending_jobs = len([j for j in jobs if j['state'] == 'PD'])
idle_nodes = len([n for n in nodes if n['state'] == 'idle'])
print(f"[{timestamp}] Running: {running_jobs}, Pending: {pending_jobs}, Idle Nodes: {idle_nodes}")
# 检查长时间等待的作业
for job in jobs:
if job['state'] == 'PD' and 'days' in job['time']:
print(f"Warning: Job {job['job_id']} ({job['name']}) has been pending for {job['time']}")
time.sleep(60) # 每分钟检查一次
if __name__ == '__main__':
monitor_cluster()第四部分:容器化训练最佳实践
数据管理策略
在容器化环境中,数据管理是关键挑战之一:
yaml
# 数据预处理Job
apiVersion: batch/v1
kind: Job
metadata:
name: data-preprocessing
spec:
template:
spec:
containers:
- name: preprocessor
image: your-registry/data-processor:latest
command: ["python3", "/scripts/preprocess.py"]
env:
- name: INPUT_PATH
value: "/raw-data"
- name: OUTPUT_PATH
value: "/processed-data"
- name: TOKENIZER_PATH
value: "/tokenizers/gpt2"
volumeMounts:
- name: raw-data
mountPath: /raw-data
readOnly: true
- name: processed-data
mountPath: /processed-data
- name: tokenizer
mountPath: /tokenizers
resources:
requests:
cpu: "16"
memory: "64Gi"
limits:
cpu: "32"
memory: "128Gi"
volumes:
- name: raw-data
persistentVolumeClaim:
claimName: raw-data-pvc
- name: processed-data
persistentVolumeClaim:
claimName: processed-data-pvc
- name: tokenizer
configMap:
name: tokenizer-config
restartPolicy: Never模型检查点管理
实现自动化的检查点管理:
python
# checkpoint_manager.py
import os
import shutil
import glob
from datetime import datetime, timedelta
class CheckpointManager:
def __init__(self, checkpoint_dir, max_checkpoints=5, backup_interval=24):
self.checkpoint_dir = checkpoint_dir
self.max_checkpoints = max_checkpoints
self.backup_interval = backup_interval # hours
def save_checkpoint(self, model, optimizer, epoch, loss, metrics):
"""保存检查点"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
checkpoint_path = os.path.join(self.checkpoint_dir, f'checkpoint_epoch_{epoch}_{timestamp}')
os.makedirs(checkpoint_path, exist_ok=True)
# 保存模型状态
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
'metrics': metrics,
'timestamp': timestamp
}, os.path.join(checkpoint_path, 'model.pt'))
# 保存配置文件
with open(os.path.join(checkpoint_path, 'config.json'), 'w') as f:
json.dump({
'epoch': epoch,
'loss': loss,
'metrics': metrics,
'timestamp': timestamp
}, f, indent=2)
# 清理旧检查点
self._cleanup_old_checkpoints()
# 备份到远程存储
if self._should_backup(checkpoint_path):
self._backup_to_remote(checkpoint_path)
def _cleanup_old_checkpoints(self):
"""清理旧检查点"""
checkpoints = glob.glob(os.path.join(self.checkpoint_dir, 'checkpoint_epoch_*'))
checkpoints.sort(key=os.path.getctime, reverse=True)
# 保留最新的N个检查点
for checkpoint in checkpoints[self.max_checkpoints:]:
shutil.rmtree(checkpoint)
print(f"Removed old checkpoint: {checkpoint}")
def _should_backup(self, checkpoint_path):
"""判断是否需要备份"""
last_backup_file = os.path.join(self.checkpoint_dir, '.last_backup')
if not os.path.exists(last_backup_file):
return True
with open(last_backup_file, 'r') as f:
last_backup_time = datetime.fromisoformat(f.read().strip())
return datetime.now() - last_backup_time > timedelta(hours=self.backup_interval)
def _backup_to_remote(self, checkpoint_path):
"""备份到远程存储"""
# 这里可以实现S3、GCS等云存储备份
remote_path = f"s3://model-backups/{os.path.basename(checkpoint_path)}"
# 使用AWS CLI或SDK上传
os.system(f"aws s3 sync {checkpoint_path} {remote_path}")
# 记录备份时间
with open(os.path.join(self.checkpoint_dir, '.last_backup'), 'w') as f:
f.write(datetime.now().isoformat())分布式训练协调
实现健壮的分布式训练协调机制:
python
# distributed_coordinator.py
import torch
import torch.distributed as dist
import os
import time
import socket
from contextlib import contextmanager
class DistributedCoordinator:
def __init__(self):
self.rank = int(os.environ.get('RANK', 0))
self.local_rank = int(os.environ.get('LOCAL_RANK', 0))
self.world_size = int(os.environ.get('WORLD_SIZE', 1))
self.master_addr = os.environ.get('MASTER_ADDR', 'localhost')
self.master_port = os.environ.get('MASTER_PORT', '23456')
def setup_distributed(self, backend='nccl'):
"""初始化分布式环境"""
if self.world_size > 1:
# 等待master节点就绪
if self.rank == 0:
self._wait_for_port(self.master_addr, int(self.master_port))
# 初始化进程组
dist.init_process_group(
backend=backend,
init_method=f'tcp://{self.master_addr}:{self.master_port}',
world_size=self.world_size,
rank=self.rank
)
# 设置CUDA设备
torch.cuda.set_device(self.local_rank)
print(f"Rank {self.rank}/{self.world_size} initialized on {socket.gethostname()}")
def _wait_for_port(self, host, port, timeout=300):
"""等待端口可用"""
start_time = time.time()
while time.time() - start_time < timeout:
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(1)
result = sock.connect_ex((host, port))
sock.close()
if result == 0:
return True
except:
pass
time.sleep(1)
raise TimeoutError(f"Port {port} on {host} not available after {timeout}s")
@contextmanager
def distributed_context(self):
"""分布式训练上下文管理器"""
try:
self.setup_distributed()
yield
finally:
if self.world_size > 1:
dist.destroy_process_group()
def barrier(self):
"""同步所有进程"""
if self.world_size > 1:
dist.barrier()
def all_reduce(self, tensor, op=dist.ReduceOp.SUM):
"""全局归约操作"""
if self.world_size > 1:
dist.all_reduce(tensor, op=op)
tensor /= self.world_size
return tensor
def broadcast(self, tensor, src=0):
"""广播操作"""
if self.world_size > 1:
dist.broadcast(tensor, src=src)
return tensor
def is_master(self):
"""判断是否为主进程"""
return self.rank == 0
def save_checkpoint_distributed(self, model, optimizer, epoch, checkpoint_path):
"""分布式检查点保存"""
if self.is_master():
# 只有主进程保存检查点
torch.save({
'epoch': epoch,
'model_state_dict': model.module.state_dict() if hasattr(model, 'module') else model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, checkpoint_path)
# 同步所有进程
self.barrier()第五部分:监控与运维
全方位监控体系
构建完整的监控体系对于大规模训练至关重要:
yaml
# monitoring-stack.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
- "alert_rules.yml"
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- job_name: 'nvidia-dcgm'
static_configs:
- targets: ['dcgm-exporter:9400']
- job_name: 'slurm-exporter'
static_configs:
- targets: ['slurm-exporter:8080']
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
containers:
- name: prometheus
image: prom/prometheus:latest
ports:
- containerPort: 9090
volumeMounts:
- name: config
mountPath: /etc/prometheus
- name: storage
mountPath: /prometheus
args:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/consoles'
- '--storage.tsdb.retention.time=30d'
- '--web.enable-lifecycle'
volumes:
- name: config
configMap:
name: prometheus-config
- name: storage
persistentVolumeClaim:
claimName: prometheus-storageGPU监控配置
部署NVIDIA DCGM Exporter进行GPU监控:
yaml
# dcgm-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: dcgm-exporter
spec:
selector:
matchLabels:
app: dcgm-exporter
template:
metadata:
labels:
app: dcgm-exporter
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9400"
spec:
hostNetwork: true
hostPID: true
containers:
- name: dcgm-exporter
image: nvcr.io/nvidia/k8s/dcgm-exporter:3.1.7-3.1.4-ubuntu20.04
ports:
- containerPort: 9400
name: metrics
env:
- name: DCGM_EXPORTER_LISTEN
value: ":9400"
- name: DCGM_EXPORTER_KUBERNETES
value: "true"
securityContext:
runAsNonRoot: false
runAsUser: 0
volumeMounts:
- name: proc
mountPath: /host/proc
readOnly: true
- name: sys
mountPath: /host/sys
readOnly: true
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
nodeSelector:
accelerator: nvidia-a100训练任务监控
创建自定义的训练监控指标:
python
# training_metrics.py
import time
import psutil
import GPUtil
from prometheus_client import start_http_server, Gauge, Counter, Histogram
import torch
class TrainingMetrics:
def __init__(self, port=8000):
# 定义监控指标
self.training_loss = Gauge('training_loss', 'Current training loss')
self.training_accuracy = Gauge('training_accuracy', 'Current training accuracy')
self.learning_rate = Gauge('learning_rate', 'Current learning rate')
self.gpu_utilization = Gauge('gpu_utilization_percent', 'GPU utilization percentage', ['gpu_id'])
self.gpu_memory_used = Gauge('gpu_memory_used_bytes', 'GPU memory used in bytes', ['gpu_id'])
self.cpu_utilization = Gauge('cpu_utilization_percent', 'CPU utilization percentage')
self.memory_used = Gauge('memory_used_bytes', 'Memory used in bytes')
self.training_samples_processed = Counter('training_samples_processed_total', 'Total training samples processed')
self.batch_processing_time = Histogram('batch_processing_seconds', 'Time spent processing each batch')
# 启动HTTP服务器
start_http_server(port)
print(f"Metrics server started on port {port}")
def update_training_metrics(self, loss, accuracy, lr, samples_processed):
"""更新训练指标"""
self.training_loss.set(loss)
self.training_accuracy.set(accuracy)
self.learning_rate.set(lr)
self.training_samples_processed.inc(samples_processed)
def update_system_metrics(self):
"""更新系统指标"""
# CPU和内存使用率
self.cpu_utilization.set(psutil.cpu_percent())
memory = psutil.virtual_memory()
self.memory_used.set(memory.used)
# GPU指标
try:
gpus = GPUtil.getGPUs()
for i, gpu in enumerate(gpus):
self.gpu_utilization.labels(gpu_id=str(i)).set(gpu.load * 100)
self.gpu_memory_used.labels(gpu_id=str(i)).set(gpu.memoryUsed * 1024 * 1024) # MB to bytes
except Exception as e:
print(f"Error updating GPU metrics: {e}")
def record_batch_time(self, processing_time):
"""记录批次处理时间"""
self.batch_processing_time.observe(processing_time)
# 在训练脚本中使用
metrics = TrainingMetrics(port=8000)
# 训练循环中
for epoch in range(num_epochs):
for batch_idx, (data, target) in enumerate(train_loader):
start_time = time.time()
# 训练步骤
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 更新指标
batch_time = time.time() - start_time
metrics.record_batch_time(batch_time)
metrics.update_training_metrics(
loss=loss.item(),
accuracy=calculate_accuracy(output, target),
lr=optimizer.param_groups[0]['lr'],
samples_processed=len(data)
)
# 定期更新系统指标
if batch_idx % 10 == 0:
metrics.update_system_metrics()第六部分:故障处理与优化
常见问题诊断
建立系统化的故障诊断流程:
bash
#!/bin/bash
# diagnose_training_issues.sh
echo "=== 训练环境诊断工具 ==="
echo "时间: $(date)"
echo
# 检查GPU状态
echo "1. GPU状态检查:"
nvidia-smi
echo
# 检查CUDA版本兼容性
echo "2. CUDA版本信息:"
nvcc --version
echo "PyTorch CUDA版本: $(python3 -c 'import torch; print(torch.version.cuda)')"
echo
# 检查容器资源限制
echo "3. 容器资源限制:"
if [ -f /sys/fs/cgroup/memory/memory.limit_in_bytes ]; then
echo "内存限制: $(cat /sys/fs/cgroup/memory/memory.limit_in_bytes | numfmt --to=iec)"
echo "内存使用: $(cat /sys/fs/cgroup/memory/memory.usage_in_bytes | numfmt --to=iec)"
fi
echo
# 检查网络连通性
echo "4. 网络连通性检查:"
if [ ! -z "$MASTER_ADDR" ]; then
echo "Master地址: $MASTER_ADDR:$MASTER_PORT"
nc -zv $MASTER_ADDR $MASTER_PORT 2>&1 | head -1
fi
echo
# 检查存储挂载
echo "5. 存储挂载状态:"
df -h | grep -E '(workspace|data|models)'
echo
# 检查进程状态
echo "6. 训练进程状态:"
ps aux | grep -E '(python|train)' | grep -v grep
echo
# 检查日志错误
echo "7. 最近的错误日志:"
if [ -d "/workspace/logs" ]; then
find /workspace/logs -name "*.log" -mtime -1 -exec grep -l "ERROR\|CUDA\|OOM" {} \; | head -5 | while read logfile; do
echo "文件: $logfile"
grep -E "ERROR|CUDA|OOM" "$logfile" | tail -3
echo
done
fi
echo "=== 诊断完成 ==="自动恢复机制
实现智能的训练任务自动恢复:
python
# auto_recovery.py
import os
import time
import subprocess
import logging
from datetime import datetime, timedelta
class TrainingRecoveryManager:
def __init__(self, config):
self.config = config
self.logger = self._setup_logging()
self.max_retries = config.get('max_retries', 3)
self.retry_delay = config.get('retry_delay', 300) # 5分钟
def _setup_logging(self):
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('/workspace/logs/recovery.log'),
logging.StreamHandler()
]
)
return logging.getLogger(__name__)
def monitor_training_job(self, job_id):
"""监控训练任务状态"""
retry_count = 0
while retry_count < self.max_retries:
try:
# 检查作业状态
status = self._get_job_status(job_id)
if status == 'COMPLETED':
self.logger.info(f"Job {job_id} completed successfully")
break
elif status == 'FAILED':
self.logger.warning(f"Job {job_id} failed, attempting recovery...")
# 分析失败原因
failure_reason = self._analyze_failure(job_id)
# 尝试恢复
if self._attempt_recovery(job_id, failure_reason):
retry_count += 1
self.logger.info(f"Recovery attempt {retry_count} initiated")
time.sleep(self.retry_delay)
else:
self.logger.error(f"Recovery failed for job {job_id}")
break
elif status == 'RUNNING':
# 检查是否卡住
if self._is_job_stuck(job_id):
self.logger.warning(f"Job {job_id} appears to be stuck")
self._restart_job(job_id)
retry_count += 1
time.sleep(60) # 每分钟检查一次
except Exception as e:
self.logger.error(f"Error monitoring job {job_id}: {e}")
time.sleep(60)
def _get_job_status(self, job_id):
"""获取作业状态"""
try:
result = subprocess.run(
['squeue', '-j', str(job_id), '-h', '-o', '%T'],
capture_output=True, text=True, timeout=30
)
return result.stdout.strip() if result.returncode == 0 else 'UNKNOWN'
except subprocess.TimeoutExpired:
return 'TIMEOUT'
def _analyze_failure(self, job_id):
"""分析失败原因"""
log_file = f"/workspace/logs/slurm-{job_id}.out"
error_file = f"/workspace/logs/slurm-{job_id}.err"
failure_patterns = {
'OOM': ['out of memory', 'CUDA out of memory', 'RuntimeError: CUDA error'],
'NETWORK': ['NCCL', 'connection refused', 'timeout'],
'STORAGE': ['No space left', 'I/O error', 'disk full'],
'NODE_FAILURE': ['node failure', 'slurm_load_jobs error'],
'PREEMPTION': ['DUE TO PREEMPTION', 'job preempted']
}
for failure_type, patterns in failure_patterns.items():
for log_path in [log_file, error_file]:
if os.path.exists(log_path):
with open(log_path, 'r') as f:
content = f.read().lower()
for pattern in patterns:
if pattern.lower() in content:
return failure_type
return 'UNKNOWN'
def _attempt_recovery(self, job_id, failure_reason):
"""尝试恢复训练"""
recovery_strategies = {
'OOM': self._recover_from_oom,
'NETWORK': self._recover_from_network_issue,
'STORAGE': self._recover_from_storage_issue,
'NODE_FAILURE': self._recover_from_node_failure,
'PREEMPTION': self._recover_from_preemption
}
strategy = recovery_strategies.get(failure_reason, self._generic_recovery)
return strategy(job_id)
def _recover_from_oom(self, job_id):
"""从内存不足错误中恢复"""
self.logger.info("Attempting OOM recovery: reducing batch size")
# 修改配置文件,减少批次大小
config_file = f"/workspace/configs/job_{job_id}.yaml"
if os.path.exists(config_file):
# 这里可以实现配置文件修改逻辑
pass
return self._resubmit_job(job_id)
def _recover_from_network_issue(self, job_id):
"""从网络问题中恢复"""
self.logger.info("Attempting network recovery: restarting with different nodes")
# 排除有问题的节点
exclude_nodes = self._get_problematic_nodes()
return self._resubmit_job(job_id, exclude_nodes=exclude_nodes)
def _resubmit_job(self, job_id, exclude_nodes=None):
"""重新提交作业"""
try:
# 取消当前作业
subprocess.run(['scancel', str(job_id)], check=True)
# 构建新的提交命令
submit_cmd = ['sbatch']
if exclude_nodes:
submit_cmd.extend(['--exclude', ','.join(exclude_nodes)])
submit_cmd.append(f'/workspace/scripts/submit_job_{job_id}.sh')
# 重新提交
result = subprocess.run(submit_cmd, capture_output=True, text=True)
if result.returncode == 0:
new_job_id = result.stdout.strip().split()[-1]
self.logger.info(f"Job resubmitted with new ID: {new_job_id}")
return True
else:
self.logger.error(f"Failed to resubmit job: {result.stderr}")
return False
except Exception as e:
self.logger.error(f"Error resubmitting job: {e}")
return False总结与展望
通过本文的深入探讨,我们构建了一个完整的容器化大模型训练环境。这个现代化的基础设施具有以下核心优势:
技术优势:
- 标准化环境:Docker容器确保了训练环境的一致性和可移植性
- 智能调度:Kubernetes提供了强大的容器编排和资源管理能力
- 高效调度:Slurm实现了HPC级别的作业调度和资源分配
- 自动化运维:完整的监控和自动恢复机制保证了系统的稳定性
实践价值:
- 提升效率:自动化的部署和管理大大减少了人工干预
- 降低成本:优化的资源利用率和智能调度减少了硬件浪费
- 增强可靠性:多层次的故障检测和恢复机制保证了训练的连续性
- 便于扩展:云原生架构支持集群的弹性伸缩
未来发展方向:
随着大模型规模的不断增长和训练需求的日益复杂,容器化训练环境将朝着更加智能化、自动化的方向发展:
- AI驱动的资源调度:利用机器学习算法预测资源需求,实现更精准的调度
- 边缘-云协同训练:支持边缘设备与云端的协同训练模式
- 绿色计算优化:集成碳排放监控,优化能耗效率
- 安全增强:加强容器安全和数据隐私保护
容器化技术为大模型训练带来了革命性的改变,它不仅解决了传统训练环境的痛点,更为未来的AI基础设施发展奠定了坚实基础。掌握这些技术,将帮助我们在AI时代的竞争中占据有利地位。