ES 安装使用教学
一、基本概述
1. 什么是 Elasticsearch
官网:https://www.elastic.co/cn/elasticsearch/
Elasticsearch 是一个开源的分布式搜索和分析引擎,基于 Apache Lucene 构建。它提供了对海量数据的快速全文搜索、结构化搜索和分析功能,是目前流行的大数据处理工具之一。主要特点即高效搜索、分布式存储、拓展性强
核心功能
- 全文搜索: 提供对文本数据的快速匹配和排名能力
- 实时数据处理: 支持实时写入、更新、删除和搜索
- 分布式存储: 能够将数据分片(shard)存储在多个节点中,具有高可用性和容错性
- 聚合分析: 支持对大数据进行复杂的统计分析,如平均值、最大值、分组统计等
2. Es 的核心特性
特性:分布式,零配Elasticsearch置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
- 它可以近乎实时的存储、检索数据
- 本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
- Es 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的
RESTfuI API来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
Elasticsearch 是 面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在 Elasticsearch 中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
| 特性 | 说明 |
|---|---|
| 分布式 | 自动分片(shard)和副本(replica),支持水平扩展 |
| 近实时(NRT) | 数据写入后 1 秒内可被搜索 |
| RESTful API | 使用 HTTP + JSON 操作,易于集成 |
| 全文搜索 | 支持中文分词、模糊匹配、高亮、相关性评分 |
| 结构化搜索 | 支持精确匹配、范围查询、布尔查询 |
| 聚合分析(Aggregations) | 类似 SQL 的GROUP BY,用于统计、报表 |
| 高可用 | 副本机制保证节点宕机不丢数据 |
| 可扩展性强 | 支持 PB 级数据,集群可扩展到数百节点 |
2.1 架构核心
Cluster(集群)
└── Node(节点)
└── Index(索引,如 user_index)
└── Type(类型,7.x 后废弃)
└── Document(文档,JSON 格式)
└── Field(字段)解释:
| 概念 | 类比关系型数据库 | 说明 |
|---|---|---|
| Cluster | 整个数据库集群 | 一组协同工作的节点 |
| Node | 一台数据库服务器 | 集群中的一个实例 |
| Index | 数据库(Database) | 一组相似文档的集合(如user,log) |
| Document | 一行记录(Row) | JSON 格式的数据,是基本存储单元 |
| Field | 列(Column) | 文档中的字段,如name,age |
| Shard(分片) | 分库分表 | 将索引拆分成多个部分,分布到不同节点 |
| Replica(副本) | 主从复制 | 每个分片可以有多个副本,提高容错和性能 |
2.2 关于 RESTfuI
RESTful 是一种 设计 Web API 的架构风格 ,全称是 Representational State Transfer(表现层状态转移)。
它不是协议,也不是标准,而是一种 设计原则,用来让 API 更清晰、易用、可维护
核心思想
-
一切皆资源(Resource)
-
把服务器上的数据看作"资源"
-
每个资源有一个唯一的 URL(URI)
-
-
用 HTTP 方法表示操作
-
使用 URL 定位资源,用 HTTP 方法表示动作
2.3 核心概念
① 索引(Index):一个索引就是一个拥有几分相似特征的文档的集合
- 索引是数据的逻辑组织单位,可以类比为数据库中的"数据库"。每个索引由多个文档组成,类似于一本书的目录
- 索引是查询的入口点,比如当你要查"小说类书籍",会直接到"小说书架"查找,而不是其他书架
② 文档 (document):文档是数据存储的基本单元,相当于关系型数据库中的"行"。每个文档是以 JSON 格式存储的键值对集合(这一点注意和MySQL进行区分)
一个文档是一个可被索引的基础信息单元
- 比如,你可以拥有某一个客户的文档,某 一个产品的一个文档或者某个订单的一个文档。
- 文档以 JSON(Javascript Object Notation)格式来表示,而 JSON 是一个到处存在的互联网数据交互格式。在一个 index/type 里面,你可以存储任意多的文档。
- 一个文档必须被索引或者赋予一个索引 的 type。
每本书可以看作一个文档。每本书有具体的属性,比如书名、作者、出版年份、ISBN 号等
cpp
{
"title": "The Catcher in the Rye",
"author": "J.D. Salinger",
"year": 1951,
"genre": "Fiction"
}③ 字段(Field):文档中的属性或键值对,比如书的"标题"、"作者"、"出版年份"等;可以简单理解为一本书的详细信息
- 注意:字段的类型可以指定(例如 text、keyword、integer 等),并决定了如何处理这些数据。例如,"标题"是 text 类型,支持全文搜索,而"ISBN" 是 keyword 类型,只支持精确匹配
| 分类 | 类型 | 备注 |
|---|---|---|
| 字符串 | test, keyword | text 会被分词生成索引; keyword 不会被分词生成索引,只能精确值 搜索 |
| 整形 | integer, long, short, byte | |
| 浮点 | double, float | |
| 逻辑 | boolean | true / false |
| 日期 | date, date_nanos | "2018-01-13" 或 "2018-01-13 12:10:30" 或者时间戳,即 1970 到现在的秒数/毫秒数 |
| 二进制 | binary | 二进制通常只存储,不索引 |
| 范围 | range |
④ 类型(Type):在一个索引中,你可以定义一种或多种类型。
- 一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。
- 通常,会为具有一组共同字段的文档定义一个类型。
- 比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,为评论数据定义另一个类型...
⑤ 映射(mapping):映射是在处理数据的方式和规则方面做一些限制
- 如某个字段的数据类型、默认值、 分析器、是否被索引等等,这些都是映射里面可以设置的,
- 其它就是处理 es 里面数据 的一些使用规则设置也叫做 映射,按着最优规则处理数据对性能提高很大,因此才需 要建立映射,并且需要思考如何建立映射才能对性能更好。
| 名称 | 数值 | 备注 |
|---|---|---|
| enabled | true(默认) | false | 是否仅作存储,不做搜索和分析 |
| index | true(默认) | false | 是否构建倒排索引(决定了是否分词,是否 被索引) |
| index_option | ||
| dynamic | true(缺省) | false | 控制 mapping 的自动更新 |
| doc_value | true(默认) | false | 是否开启 doc_value,用户聚合和排序分 析,分词字段不能使用 |
| fielddata | fielddata": {"format": "disabled"} | 是否为 text 类型启动 fielddata,实现排序和 聚合分析 针对分词字段,参与排序或聚合时能提高性 能, 不分词字段统一建议使用 doc_value |
| store | true| false(默认) | 是否单独设置此字段的是否存储而从 _source 字段中分离, 只能搜索,不能获取值 |
| coerce | true(默认) | false | 是否开启自动数据类型转换功能, 比如:字符串转数字,浮点转整型 |
| analyzer | "analyzer": "ik" | 指定分词器,默认分词器为 standard analyzer |
| boost | "boost": 1.23 | 字段级别的分数加权,默认值是 1.0 |
| fields | "fields": { "raw": { "type": "text", "index": "not_analyz ed" } } | 对一个字段提供多种索引模:同一个字段的值,一个分词,一个不分词 |
| data_detection | true(默认) | false | 是否自动识别日期类型 |
Elasticsearch 与传统关系型数据库相比如下:

3. Elasticsearch vs 传统数据库
| 对比项 | Elasticsearch | MySQL |
|---|---|---|
| 搜索性能 | 极快(倒排索引) | 模糊查询慢 |
| 扩展性 | 分布式,易水平扩展 | 分库分表复杂 |
| 写入吞吐 | 高(适合日志) | 中等 |
| 事务支持 | 不支持 | 支持 |
| 一致性 | 最终一致性 | 强一致性 |
| 适用场景 | 搜索、分析、日志 | 事务、关系数据 |
4. ES 高性能原因
① 倒排索引:倒排索引是 Elasticsearch 搜索速度快的核心技术,它记录的是每个单词在文档中的位置,而不是逐个文档搜索所有内容。
例如有三个文档,记录的内容分别是:文档1: "猫喜欢鱼";文档2: "狗喜欢骨头";文档3: "鱼喜欢水",那么倒排索引就会建立如下索引
词语 文档ID
喜欢 1, 2, 3
猫 1
狗 2
鱼 1, 3
骨头 2
水 3当查找喜欢这个单词的时候,Elasticsearch就不会扫描全部的文档,而是直接从倒排索引中找到包含该单词的文档列表即可
综上所述:ES使用倒排索引避免了逐个扫描文档,直接定位到包含目标关键词的文档,查询时间随文档总量的增长几乎不变。
② 分布式架构 :Elasticsearch 将数据分成多个 分片 存储在不同的节点上,查询时,会并行搜索所有分片,最后合并结果返回。
场景还假设在上面文档的内容中,将索引分为3个分片中,分布在三个节点上
- 分片1: 包含文档 1~100
- 分片2: 包含文档 101~200
- 分片3: 包含文档 201~300
当用户查询"鱼",Elasticsearch 会同时向 3 个分片发出请求:
- 分片1 返回包含"鱼"的文档 1
- 分片2 无结果
- 分片3 返回包含"鱼"的文档 3
最后将结果合并返回给用户;就像超时收银的,不会将所有的客户都在一个收银节点,通过设置多个收银节点完成最后的收银工作
③ 缓存机制:Elasticsearch 使用内存缓存和文件系统缓存来存储常用的查询结果,如果相同的查询被多次请求,Elasticsearch 会直接从缓存中返回结果,而无需重新计算
⑤ 查询优化和分析器:lasticsearch 会对查询请求进行优化,比如避免不必要的计算、合并多个相同的查询条件等
- 分析器(Analyzer)是对文本数据的处理器,通常会对字段的内容进行分词、去停用词(如 "the"、"is")、小写化等操作;借助分词器和索引机制让全文搜索更加精准和迅速
5. 注意事项
| 问题 | 建议 |
|---|---|
| 不要当主数据库用 | 用于搜索和分析,核心数据仍用 MySQL |
| 分片数量合理 | 太多分片影响性能,建议每个分片 10-50GB |
| 避免深度分页 | 用search_after替代from/size |
| 中文分词 | 安装IK Analyzer插件 |
| 内存配置 | JVM 堆内存不要超过 32GB(避免指针压缩失效) |
二、安装
1. 安装 ES
① 添加仓库密钥
bash
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
# 警告
Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).注意:上边的添加方式会导致一个 apt-key 的警告,如果不想报警告使用下边这个
bash
curl -s https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --no-default-keyring --keyring gnupgring:/etc/apt/trusted.gpg.d/icsearch.gpg --import此时就可以查看,如下:
bash
lighthouse@VM-8-10-ubuntu:es$ ls /etc/apt/
apt.conf.d keyrings source.list sources.list.bak sources.list.d trusted.gpg.d
auth.conf.d preferences.d sources.list sources.list.curtin.old trusted.gpg
lighthouse@VM-8-10-ubuntu:es$ ls /etc/apt/trusted.gpg.d
ubuntu-keyring-2012-cdimage.gpg ubuntu-keyring-2018-archive.gpg② 添加镜像源仓库
bash
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elasticsearch.list
# 输出如下
deb https://artifacts.elastic.co/packages/7.x/apt stable main③ 正式安装
bash
# 更新软件包列表 -- 这里出现的警告没事
sudo apt update
# 安装 es
sudo apt-get install elasticsearch=7.17.21
# 启动 es
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearch # 开机启动
# 查看安装情况
lighthouse@VM-8-10-ubuntu:es$ ps -ef | grep elas
# ...
lightho+ 3692851 3677693 0 17:01 pts/1 00:00:00 grep --color=auto elas
# 安装 ik 分词器插件
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.17.21④ 查看安装情况
bash
# 重启服务
sudo systemctl restart elasticsearch
# 查看 es 服务状态
lighthouse@VM-8-10-ubuntu:es$ sudo systemctl status elasticsearch.service
● elasticsearch.service - Elasticsearch
Loaded: loaded (/lib/systemd/system/elasticsearch.service; disabled; vendor preset: enabled)
Active: active (running) since Mon 2025-09-08 17:00:34 CST; 4min 57s ago
Docs: https://www.elastic.co
Main PID: 3692208 (java)
Tasks: 61 (limit: 3943)
Memory: 2.0G
CPU: 1min 7.811s
CGroup: /system.slice/elasticsearch.service
├─3692208 /usr/share/elasticsearch/jdk/bin/java -Xshare:auto -Des.networkaddress.cache.ttl=60 -Des.networkaddre>
└─3692432 /usr/share/elasticsearch/modules/x-pack-ml/platform/linux-x86_64/bin/controller
# 验证是否成功
lighthouse@VM-8-10-ubuntu:es$ sudo netstat -antup | grep 9200
tcp6 0 0 ::1:9200 :::* LISTEN 3695244/java
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 3695244/java
ighthouse@VM-8-10-ubuntu:es$ curl -X GET "http://localhost:9200/"
{
"name" : "VM-8-10-ubuntu",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "2vF-QGFxQ3m2qnBvIquRTQ",
"version" : {
"number" : "7.17.21",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "d38e4b028f4a9784bb74de339ac1b877e2dbea6f",
"build_date" : "2024-04-26T04:36:26.745220156Z",
"build_snapshot" : false,
"lucene_version" : "8.11.3",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}设置外网访问:因为新配置默认只能在 本机上 进行访问
shell
sudo vim /etc/elasticsearch/elasticsearch.yml
# 新增配置
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]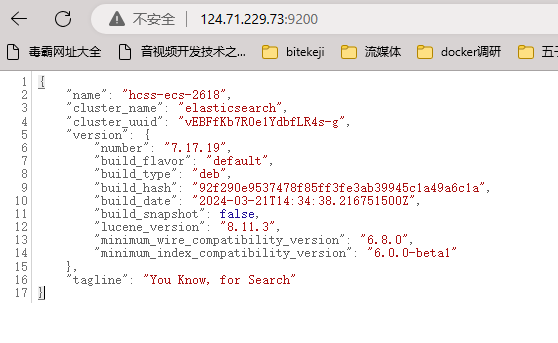
2. 报错解决
① 如果 apt update 更新源出错,解决办法如下:
bash
lighthouse@VM-8-10-ubuntu:~/workspace$ apt-key list
Warning: apt-key is deprecated. Manage keyring files in
trusted.gpg.d instead (see apt-key(8)).
/etc/apt/trusted.gpg ubuntu 希望将 apt-key 放到 /etc/apt/trusted.gpg.d/下而不是这个文件中
--------------------
pub rsa2048 2013-09-16 [SC]
4609 5ACC 8548 582C 1A26 99A9 D27D 666C D88E 42B4 注意最后这 8 个字符
uid [ unknown] Elasticsearch (Elasticsearch Signing Key) <dev_ops@elasticsearch.org>
sub rsa2048 2013-09-16 [E]
lighthouse@VM-8-10-ubuntu:~$ sudo apt-key export D88E42B4 | sudo gpg --dearmour -o /etc/apt/trusted.gpg.d/elasticsearch.gpg 完成后,查看/etc/apt/trusted.gpg.d/,应该已经将 apt-key 单独保存到目录下了
② 启动 es 的时候报错

解决办法如下:
bash
# 调整 ES 虚拟内存,虚拟内存默认最大映射数为 65530,无法满足 ES 系统要求,
需要调整为 262144 以上
sysctl -w vm.max_map_count=262144
# 增加虚拟机内存配置
vim /etc/elasticsearch/jvm.options
# 新增如下内容
-Xms512m
-Xmx512m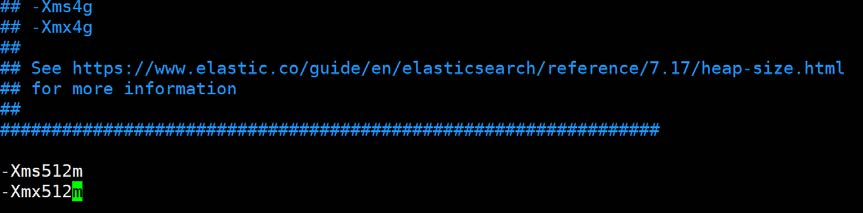
还有啥问题的可以参考这篇博客:ES使用过程中问题解决汇总
3. 安装 kibana
shell
sudo apt install kibana # 使用 apt 命令安装 Kibana。 配置 Kibana:配置文件通常位于 /etc/kibana/kibana.yml。可能要设置如服务器地址、端口、Elasticsearch URL等
shell
sudo vim /etc/kibana/kibana.yml 
安装完成后,开始进行 Kibana 服务
bash
sudo systemctl start kibana # 启动
sudo systemctl enable kibana # 设置开机自启(可选)
# 验证安装
lighthouse@VM-8-10-ubuntu:es$ sudo systemctl status kibana # 检查 Kibana 服务的状态
lines 1--1...skipping...
● kibana.service - Kibana
Loaded: loaded (/etc/systemd/system/kibana.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2025-09-08 17:25:36 CST; 1min 7s ago
Docs: https://www.elastic.co
Main PID: 3698643 (node)
Tasks: 11 (limit: 3943)
Memory: 569.8M
CPU: 27.697s
CGroup: /system.slice/kibana.service
lighthouse@VM-8-10-ubuntu:es$ sudo netstat -antup | grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 3698643/node我们还可以在浏览器中访问 Kibana,通常是 http://<your-ip>:5601
如果启动之后,结果如下:
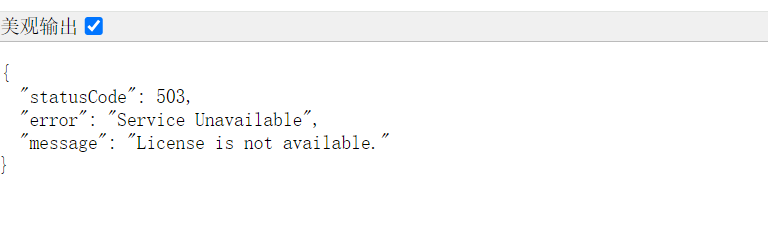
此时再查看状态,如下:
bash
lighthouse@VM-8-10-ubuntu:~$ sudo systemctl status elasticsearch
○ elasticsearch.service - Elasticsearch
Loaded: loaded (/lib/systemd/system/elasticsearch.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Mon 2025-09-08 23:41:40 CST; 23h ago
Docs: https://www.elastic.co
Process: 863 ExecStart=/usr/share/elasticsearch/bin/systemd-entrypoint -p ${PID_DIR}/elasticsearch.pid --quiet (code=exited, status=143)
Main PID: 863 (code=exited, status=143)
CPU: 1min 13.140s
Sep 08 23:37:55 VM-8-10-ubuntu systemd-entrypoint[863]: Sep 08, 2025 11:37:55 PM sun.util.locale.provider.LocaleProviderAdapter <clinit>
Sep 08 23:37:55 VM-8-10-ubuntu systemd-entrypoint[863]: WARNING: COMPAT locale provider will be removed in a future release
Sep 08 23:38:23 VM-8-10-ubuntu systemd[1]: Started Elasticsearch.
Sep 08 23:41:20 VM-8-10-ubuntu systemd[1]: Stopping Elasticsearch...
Sep 08 23:41:40 VM-8-10-ubuntu systemd-entrypoint[863]: uncaught exception in thread [Thread-3]
Sep 08 23:41:40 VM-8-10-ubuntu systemd-entrypoint[863]: java.lang.IllegalStateException: Node didn't stop within 10 seconds. Any outstanding requests or>
Sep 08 23:41:40 VM-8-10-ubuntu systemd-entrypoint[863]: at org.elasticsearch.bootstrap.Bootstrap$4.run(Bootstrap.java:202)
Sep 08 23:41:40 VM-8-10-ubuntu systemd[1]: elasticsearch.service: Deactivated successfully.
Sep 08 23:41:40 VM-8-10-ubuntu systemd[1]: Stopped Elasticsearch.
Sep 08 23:41:40 VM-8-10-ubuntu systemd[1]: elasticsearch.service: Consumed 1min 13.140s CPU time.- Elasticsearch 昨天启动 3 分钟后就自己崩了,现在处于
inactive (dead)状态,所以 9200 端口没人听,Kibana 拿不到 license 报 503
此时重启一下就行了,但是如果状态是正常的话,原因如下:
503 License is not available 并不是 Kibana 没启动,而是 Kibana 8.x 默认启用了 Elastic Stack 的安全与许可证检查 ,而你的集群里 没有有效的 Elasticsearch 许可证(License),Kibana 在启动时会尝试从 ES 获取 license,拿不到就拒绝服务,于是:
- 进程还在(
systemctl显示 running,5601 也在监听) - 但所有 HTTP 请求都被拦下,直接返回 503
"License is not available"
这个时候就需要在 elasticsearch.yml 末尾加
bash
# 禁用安全特性,允许 Basic License
xpack.security.enabled: false
xpack.security.enrollment.enabled: false4. Es 客户端安装
代码:https://github.com/seznam/elasticlient
官网:https://seznam.github.io/elasticlient/index.html
ES C++的客户端选择并不多, 我们这里使用 elasticlient 库, 下面进行安装
shell
# 注意: 下面这个开发包不能直接去 github 下载安装, 因为其内部的子模块
git clone https://github.com/seznam/elasticlient
# 切换目录
cd elasticlient
# 更新子模块
git submodule update --init --recursive
# 编译运行
mkdir build && cd build
cmake -DCMAKE_INSTALL_PREFIX=/usr ..
make
# 安装
make install然后 git clone 我出现了失败的情况,这个时候我就是让我朋友给我远程给我传过来它的 elasticlient,然后 编译的时候 cmake 也报错了,一直卡着下载那个 .zip 没结果,这个时候就可以去手动下载下来,然后看它上面说把这个文件放哪个路径下,然后手动放过去,此时再编译运行安装即可
三、使用
1. Kibana 访问 es 进行测试
通过网页访问 kibana
① 创建索引库
cpp
POST /user/_doc
{
"settings" : {
"analysis" : {
"analyzer" : { // 分词器
"ik" : { // 中文分词器
"tokenizer" : "ik_max_word" // 分词粒度描述 - 以最大粒度进行分词
}
}
}
},
"mappings" : {
"dynamic" : true,
"properties" : {
"nickname" : {
"type" : "text", // 这个字段是一个文本分词器
"analyzer" : "ik_max_word" // 使用中文分词器
},
"user_id" : {
"type" : "keyword", // 也是一个文本类型 关键字但不进行分词
"analyzer" : "standard" // 使用默认标准分词器
},
"phone" : {
"type" : "keyword",
"analyzer" : "standard"
},
"description" : {
"type" : "text",
"enabled" : false // 仅作存储 不作搜索
},
"avatar_id" : {
"type" : "keyword",
"enabled" : false
}
}
}
}结果如下:
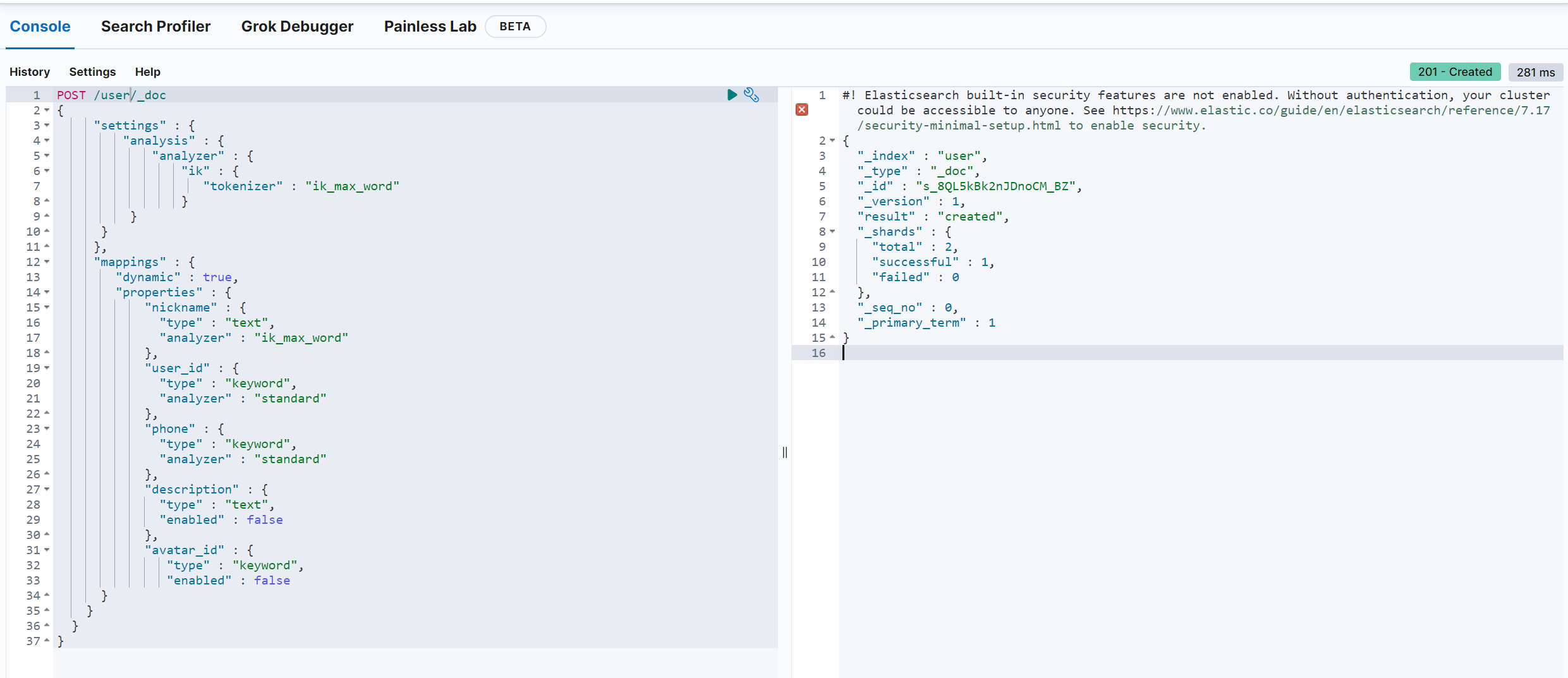
② 新增数据
cpp
POST /user/_doc/_bulk
{"index":{"_id":"1"}}
{"user_id" : "USER4b862aaa-2df8654a-7eb4bb65-e3507f66","nickname" : "昵称 1","phone" : "手机号 1","description" : "签名 1","avatar_id" : "头像 1"}
{"index":{"_id":"2"}}
{"user_id" : "USER14eeeaa5-442771b9-0262e455-e4663d1d","nickname" : "昵称 2","phone" : "手机号 2","description" : "签名 2","avatar_id" : "头像 2"}
{"index":{"_id":"3"}}
{"user_id" : "USER484a6734-03a124f0-996c169dd05c1869","nickname": "昵称 3","phone" : "手机号 3","description" : "签名 3","avatar_id" : "头像 3"}
{"index":{"_id":"4"}}
{"user_id" : "USER186ade83-4460d4a6-8c08068f83127b5d","nickname": "昵称 4","phone" : "手机号 4","description" : "签名 4","avatar_id" : "头像 4"}
{"index":{"_id":"5"}}
{"user_id" : "USER6f19d074-c33891cf-23bf5a83-57189a19","nickname" : "昵称 5","phone" : "手机号 5","description" : "签名 5","avatar_id" : "头像 5"}
{"index":{"_id":"6"}}
{"user_id" : "USER97605c64-9833ebb7-d0455353-35a59195","nickname" : "昵称 6","phone" : "手机号 6","description" : "签名 6","avatar_id" : "头像 6"} ③ 搜索所有数据
cpp
POST /user/_doc/_search
{
"query": {
"match_all": {}
}
}④ 查找并搜索数据
cpp
GET /user/_doc/_search?pretty
{
"query" : {
"bool" : {
"must_not" : [
{
"terms" : {
"user_id.keyword" : [
"USER4b862aaa-2df8654a-7eb4bb65-e3507f66",
"USER14eeeaa5-442771b9-0262e455-e4663d1d",
"USER484a6734-03a124f0-996c169dd05c1869"
]
}
}
],
"should" : [
{
"match" : {
"user_id" : "昵称"
}
},
{
"match" : {
"nickname" : "昵称"
}
},
{
"match" : {
"phone" : "昵称"
}
}
]
}
}
}删除索引
cpp
DELETE /user2. JsonCpp 介绍和样例编写
这里我们在安装 Es 客户端的子模块的的时候,就已经有了 JsonCpp 库的安装,如下:
bash
lighthouse@VM-8-10-ubuntu:~$ ls /usr/include/json/
allocator.h assertions.h autolink.h config.h features.h forwards.h json.h reader.h value.h version.h writer.h使用 Jsoncpp 库完成数据的序列化和反序列化
Json::Value 用于进行中间数据存储,将多个字段数据进行序列化
cpp
Value& operator=(Value other);
Value& operator[](const char* key); Value["姓名"] = "张三";
Value& append(const Value& value); Value["成绩"].append(88); // 新增数据
std::string asString() const; Value["姓名"].asString(); // 获取数据Writer 类
cpp
class JSON_API StreamWriter{
virtual int write(Value const& root, JSONCPP_OSTREAM* sout) = 0; // 序列化接口
};
class JSON_API StreamWriterBuilder{
StreamWriter* newStreamWriter(); // StreamWriter 对象的生产接口
};Reader 类
cpp
class JSON_API CharReader{
virtual bool parse(char const* beginDoc, char const* endDoc, Value* root, JSONCPP_STRING* errs) = 0;
};
class JSON_API CharReaderBuilder{
CharReader* newCharReader(); // CharReader 工接口
};样例代码
cpp
#include <iostream>
#include <json/json.h>
#include <sstream>
#include <memory>
bool Serialize(const Json::Value &val, std::string& dst){
Json::StreamWriterBuilder swb;
swb.settings_["emitUTF8"] = true;
// 构造对象
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
// auto sw = std::make_unique<Json::StreamWriter>(swb.newStreamWriter());
std::stringstream ss;
if(sw->write(val, &ss) != 0){
std::cout << "Json 序列化失败 \n";
return false;
}
dst = ss.str();
return true;
}
bool UnSerialize(Json::Value &val, const std::string& src){
Json::CharReaderBuilder crb;
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
// auto cr = std::make_unique<Json::CharReader>(crb.newCharReader());
std::string err;
if(!cr->parse(src.c_str(), src.c_str() + src.size(), &val, &err)){
std::cout << "Json 反序列化失败: " << err << std::endl;
return false;
}
return true;
}
int main(){
Json::Value stu;
stu["姓名"] = "张三"; stu["年龄"] = 18;
stu["成绩"].append(78); stu["成绩"].append(99); stu["成绩"].append(89);
std::string str;
if(!Serialize(stu, str)){
return -1;
}
std::cout << str << std::endl;
Json::Value val;
if(!UnSerialize(val, str)){
return -1;
}
std::cout << val["姓名"].asString() << std::endl;
std::cout << val["年龄"].asInt() << std::endl;
int sz = val["成绩"].size();
for (int i = 0; i < sz; i++) {
std::cout << val["成绩"][i].asFloat() << std::endl;
}
return 0;
}输出
bash
{
"\u59d3\u540d" : "\u5f20\u4e09",
"\u5e74\u9f84" : 18,
"\u6210\u7ee9" :
[
78,
99,
89
]
}
张三
18
78
99
893. Es 客户端端口介绍及样例编写
可以在 /usr/include/elasticlient/client.h 查看对应端口
参数说明
- indexName:指定 Elasticsearch 的索引名称
- docType::指定文档的类型(在 Elasticsearch 7.x+ 中已被弃用)
- id:文档的唯一标识符,用于获取、索引或删除
- body:Elasticsearch 的请求体,通常为 JSON 格式
- routing:路由参数,如果为空,则使用默认的路由规则
常用接口功能
① search(搜索)
- 在 Elasticsearch 集群中搜索指定的索引,直到成功为止
- 如果所有节点都未响应,则抛出
ConnectionException
cpp
cpr::Response search(
const std::string &indexName,
const std::string &docType,
const std::string &body,
const std::string &routing = std::string());② get(获取文档)
- 从集群中获取指定 ID 的文档
- 如果所有节点都未响应,则抛出
ConnectionException
cpp
cpr::Response get(
const std::string &indexName,
const std::string &docType,
const std::string &id = std::string(),
const std::string &routing = std::string());③ index(索引文档)
- 在集群中新增或更新文档
- 如果 ID 未提供,Elasticsearch 将自动生成 ID
- 如果所有节点都未响应,则抛出
ConnectionException
cpp
cpr::Response index(
const std::string &indexName,
const std::string &docType,
const std::string &id,
const std::string &body,
const std::string &routing = std::string());⑤ remove(删除文档)
- 从集群中删除指定 ID 的文档
- 如果所有节点都未响应,则抛出
ConnectionException
cpp
cpr::Response remove(
const std::string &indexName,
const std::string &docType,
const std::string &id,
const std::string &routing = std::string());样例
cpp
#include <elasticlient/client.h>
#include <iostream>
#include <cpr/cpr.h>
int main(){
// 1. 构造 ES 客户端 -- 后面 / 不能忘, 不然会出错
elasticlient::Client client({"http://127.0.0.1:9200/"});
// 2. 发起打印请求
try{
auto rsp = client.search("user", "_doc", "{\"query\": { \"match_all\":{} }}");
std::cout << rsp.status_code << std::endl;
std::cout << rsp.text << std::endl;
}catch(std::exception &e){
std::cout << "请求失败: " << e.what() << std::endl;
return -1;
}
// 3. 打印响应状态码和响应正文
return 0;
}ES客户端API使用注意:
- 地址后边不要忘了相对根目录:
http://127.0.0.1:9200/ - ES 客户端API使用,要进行异常捕捉,否则操作失败会导致程序异常退出
4. Es 客户端API 二次封装
操作:索引创建、数据新增、数据查询、数据删除
封装最重要完成的是 请求正文的构造过程: Json::Value 对象数据的新增过程
封装思路
- 索引创建
- 动态设置索引名称、索引类型
- 添加字段、设置字段类型及分词器设置
- 构造的核心逻辑则通过
Json::Value构造对应的请求正文
- 数据新增
- 特定索引中插入文档
- 文档格式以JSON构造,灵活支持动态字段和值
- 数据查询
- 封装搜索语法 ,生成符合ES查询语法的JSON格式请求体
- 支持复杂的查询条件,例如多条件组合
- 数据删除:封装删除请求接口,可以按索引或文档 ID 进行删除
具体实现
这里的工具函数 Serialize 和 UnSerialize 均采用之前实现的
① 创建索引
cpp
class ESIndex{
public:
ESIndex(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client)
{
// 拼装 settings 部分的 JSON
Json::Value analysis;
Json::Value analyzer;
Json::Value ik;
Json::Value tokenizer;
tokenizer["tokenizer"] = "ik_max_word"; // 使用中文分词
ik["ik"] = tokenizer; // {"ik":{"tokenizer":"ik_max_word"}}
analyzer["analyzer"] = ik; // {"analyzer":{"ik":{...}}}
analysis["analysis"] = analyzer; // {"analysis":{"analyzer":{...}}}
_index["settings"] = analysis; // 根节点 _index 先放好 settings
}
// 提供链式 DSL写法,一口气把字段全部列完:
// 如: ESIndex(...).append("title").append("content", "text", "ik_smart", true).create();
ESIndex& append(const std::string &key,
const std::string &type = "text",
const std::string &analyzer = "ik_max_word",
bool enabled = true)
{
// 每个字段只维护 {"type":..., "analyzer":..., "enabled":...} 挂到 _properties[key] 下
Json::Value fields;
fields["type"] = type;
fields["analyzer"] = analyzer;
// 跳过该字段的倒排索引,节省磁盘但无法搜索,不要对需要检索的字段设置 false。
if (enabled == false) fields["enabled"] = enabled;
_properties[key] = fields;
// 返回 *this 实现链式调用,不用让用户多写临时变量
return *this;
}
bool create(const std::string &index_id = "default_index_id")
{
// 1. 把 _properties 挂到 mappings.properties,再把 mappings 挂到 _index,形成完整请求体:
// settings + mappings → 发送 PUT /index_name/_doc/index_id
Json::Value mappings;
mappings["dynamic"] = true; // 允许动态字段
mappings["properties"] = _properties;
_index["mappings"] = mappings;
std::string body;
if (!Serialize(_index, body)) { // 把 Json 压成字符串
LOG_ERROR("索引序列化失败!");
return false;
}
LOG_DEBUG("{}", body);
// 2. 使用 elasticlient::Client->index() 发送 索引请求,成功返回 200-299,其余都算失败
try {
auto rsp = _client->index(_name, _type, index_id, body);
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("创建ES索引 {} 失败,响应状态码异常: {}", _name, rsp.status_code);
return false;
}
} catch(std::exception &e) {
LOG_ERROR("创建ES索引 {} 失败: {}", _name, e.what());
return false;
}
return true;
}
private:
std::string _name;
std::string _type;
Json::Value _properties;
Json::Value _index; // 用 _index 这个 Json::Value 当 总集装箱
std::shared_ptr<elasticlient::Client> _client;
};- append -- 链式追加字段
- **作用:**给索引字段添加映射配置(字段名称,字段类型,分析器名称,是否启用该字段)
- **实现逻辑:**创建字段的JSON配置,然后将其添加到
_properties中,然后字段映射以键值对的形式进行存储
- create
- **作用:**根据settings和mappings配置,通过客户端发送HTTP请求创建Elasticsearch索引
- 逻辑
- 设置索引的mappins配置
- 序列化索引配置为JSON字符串
- 通过_client调用
Elasticsearch的接口创建索引
② 新增数据
cpp
class ESInsert{
public:
ESInsert(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client){}
template<typename T>
ESInsert &append(const std::string& key, const T& val){
_item[key] = val;
return *this;
}
bool insert(const std::string id = ""){
std::string body;
if(!Serialize(_item, body)){
LOG_ERROR("索引序列化失败!");
return false;
}
try{
auto rsp = _client->index(_name, _type, id, body);
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("新增数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return false;
}
}catch(std::exception& e){
LOG_ERROR("新增数据 {} 失败: {}", body, e.what());
return false;
}
return true;
}
private:
std::string _name;
std::string _type;
Json::Value _item;
std::shared_ptr<elasticlient::Client> _client;
};③ 删除数据
cpp
class ESRemove{
public:
ESRemove(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc")
:_name(name), _type(type), _client(client){}
bool remove(const std::string &id){
try {
auto rsp = _client->remove(_name, _type, id);
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("删除数据 {} 失败,响应状态码异常: {}", id, rsp.status_code);
return false;
}
} catch(std::exception &e) {
LOG_ERROR("删除数据 {} 失败: {}", id, e.what());
return false;
}
return true;
}
private:
std::string _name;
std::string _type;
std::shared_ptr<elasticlient::Client> _client;
};- **作用:**删除指定ID的文档
- 逻辑:
- 调用客户端的remove方法,向Elasticsearch发送删除请求
- 判断是否成功,同时对错误进行捕捉,防止被其他错误中断
④ 数据查询
| 方法 | 生成的 ES 子句 | 语义/典型场景 | 坑点 |
|---|---|---|---|
append_must_term |
{"term":{key:val}} |
精确过滤(keyword、数字、日期) | 对 text 字段使用 term 会查不到,因为 text 会被分词,存进去的是小写词干 |
append_must_match |
{"match":{key:val}} |
全文检索,支持分词、TF/IDF 打分 | 默认 operator=or,多个词只要匹配一个就得分;想"全匹配"需改 match_phrase 或 operator=and |
append_should_match |
同上,只是放进 should | 相关性提升 或或条件 | 如果 bool 里只有 should ,则默认"至少一个匹配";一旦有了 must/must_not,should 就变成可选加分项,不再影响召回 |
append_must_not_terms |
{"terms":{key:[v1,v2]}} |
批量排除 | terms 对 text 字段同样不生效;而且 ES 7.x 以后单个数组元素上限 65536 |
代码如下
cpp
class ESSearch {
public:
ESSearch(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client){}
ESSearch& append_must_not_terms(const std::string &key, const std::vector<std::string> &vals) {
Json::Value fields;
for (const auto& val : vals){
fields[key].append(val);
}
Json::Value terms;
terms["terms"] = fields;
_must_not.append(terms);
return *this;
}
ESSearch& append_should_match(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val;
Json::Value match;
match["match"] = field;
_should.append(match);
return *this;
}
ESSearch& append_must_term(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val;
Json::Value term;
term["term"] = field;
_must.append(term);
return *this;
}
ESSearch& append_must_match(const std::string &key, const std::string &val){
Json::Value field;
field[key] = val;
Json::Value match;
match["match"] = field;
_must.append(match);
return *this;
}
Json::Value search(){
Json::Value cond;
if (_must_not.empty() == false) cond["must_not"] = _must_not;
if (_should.empty() == false) cond["should"] = _should;
if (_must.empty() == false) cond["must"] = _must;
Json::Value query;
query["bool"] = cond;
Json::Value root;
root["query"] = query;
std::string body;
if(!Serialize(root, body)){
LOG_ERROR("索引序列化失败!");
return Json::Value();
}
LOG_DEBUG("{}", body);
// 搜索请求
cpr::Response rsp;
try{
rsp = _client->search(_name, _type, body);
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("检索数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return Json::Value();
}
}catch(std::exception &e){
LOG_ERROR("检索数据 {} 失败: {}", body, e.what());
return Json::Value();
}
// 对响应正文进行反序列化
LOG_DEBUG("检索响应正文: [{}]", rsp.text);
Json::Value json_res;
if(!UnSerialize(rsp.text, json_res)){
LOG_ERROR("检索数据 {} 反序列化失败", rsp.text);
return Json::Value();
}
return json_res["hits"]["hits"];
}
private:
std::string _name;
std::string _type;
Json::Value _must_not;
Json::Value _should;
Json::Value _must;
std::shared_ptr<elasticlient::Client> _client;
};- 主要功能
- 提供接口构建多条件的Elasticsearch布尔查询
- 将查询条件序列化为JSON格式的请求体
- 调用Elasticsearch客户端执行查询
- 解析查询结果并返回文档数据
测试
cpp
#include "../../common/icsearch.hpp"
#include <gflags/gflags.h>
DEFINE_bool(run_mode, false, "程序的运行模式,false-调试; true-发布;");
DEFINE_string(log_file, "", "发布模式下,用于指定日志的输出文件");
DEFINE_int32(log_level, 0, "发布模式下,用于指定日志输出等级");
int main(int argc, char *argv[])
{
google::ParseCommandLineFlags(&argc, &argv, true);
init_logger(FLAGS_run_mode, FLAGS_log_file, FLAGS_log_level);
// 这样会创建 ES 索引失败
// std::shared_ptr<elasticlient::Client> client(new elasticlient::Client({"http://127.0.0.1:9200"}));
std::vector<std::string> host_list = {"http://127.0.0.1:9200/"};
auto client = std::make_shared<elasticlient::Client>(host_list);
// ESIndex index(client, "test_user", "_doc");
// index.append("nickname").append("phone", "keyword", "standard", true).create();
std::cout << (uint64_t)client.get() << std::endl;
// 1, 索引数据
if(!ESIndex(client, "test_user").append("nickname")
.append("phone", "keyword", "standard", true).create()){
LOG_INFO("索引创建失败");
return -1;
}
LOG_INFO("索引创建成功");
// 2, 新增数据
if(!ESInsert(client, "test_user")
.append("nickname", "张三")
.append("phone", "15566667777")
.insert("00001"))
{
LOG_ERROR("数据插入失败!");
return -1;
}
LOG_INFO("数据新增成功");
// 3, 更新数据
if(!ESInsert(client, "test_user")
.append("nickname", "张三")
.append("phone", "13344445555")
.insert("00001"))
{
LOG_ERROR("数据更新失败!");
return -1;
}
LOG_INFO("数据更新成功");
// 4, 搜索数据
Json::Value user = ESSearch(client, "test_user")
.append_should_match("phone.keyword", "13344445555")
//.append_must_not_terms("nickname.keyword", {"张三"})
.search();
if (user.empty()) {
LOG_ERROR("结果为空");
return -1;
}else if(!user.isArray()){
LOG_ERROR("结果不是数组类型");
return -1;
}
LOG_INFO("数据检索成功!");
int sz = user.size();
LOG_DEBUG("检索结果条目数量:{}", sz);
for (int i = 0; i < sz; i++) {
LOG_INFO("nickname: {}", user[i]["_source"]["nickname"].asString());
}
// 5, 删除数据
if (!ESRemove(client, "test_user").remove("00001")) {
LOG_ERROR("删除数据失败");
return -1;
}
LOG_INFO("数据删除成功!");
return 0;
}结果输出如下:
bash
94141757809504
[default-logger][11:24:58][1520237][debug ][../../common/icsearch.hpp:151] {
"mappings" :
{
"dynamic" : true,
"properties" :
{
"nickname" :
{
"analyzer" : "ik_max_word",
"type" : "text"
},
"phone" :
{
"analyzer" : "standard",
"type" : "keyword"
}
}
},
"settings" :
{
"analysis" :
{
"analyzer" :
{
"ik" :
{
"tokenizer" : "ik_max_word"
}
}
}
}
}
[default-logger][11:24:58][1520237][info ][main.cc:29] 索引创建成功
[default-logger][11:24:58][1520237][info ][main.cc:40] 数据新增成功
[default-logger][11:24:58][1520237][info ][main.cc:51] 数据更新成功
[default-logger][11:24:58][1520237][debug ][../../common/icsearch.hpp:294] {
"query" :
{
"bool" :
{
"should" :
[
{
"match" :
{
"phone.keyword" : "13344445555"
}
}
]
}
}
}
[default-logger][11:24:58][1520237][debug ][../../common/icsearch.hpp:309] 检索响应正文: [{"took":10,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":0.6931471,"hits":[{"_index":"test_user","_type":"_doc","_id":"00001","_score":0.6931471,"_source":{
"nickname" : "\u5f20\u4e09",
"phone" : "13344445555"
}}]}}]
[default-logger][11:24:58][1520237][info ][main.cc:65] 数据检索成功!
[default-logger][11:24:58][1520237][debug ][main.cc:68] 检索结果条目数量:1
[default-logger][11:24:58][1520237][info ][main.cc:70] nickname: 张三
[default-logger][11:24:58][1520237][info ][main.cc:78] 数据删除成功!