本篇文章Back to Basics: Isotonic Regression in Sklearn适合初学者了解等距回归。文章的亮点在于它能够强制模型输出保持单调性,适用于需要遵循单调业务规则的场景,如收入与风险评分的关系。
文章目录
- [1 什么是保序回归?](#1 什么是保序回归?)
- [2 为什么使用保序回归?](#2 为什么使用保序回归?)
- [3 示例:在 Python 中拟合保序回归](#3 示例:在 Python 中拟合保序回归)
- [4 实际用例:概率校准](#4 实际用例:概率校准)
- [5 关键要点](#5 关键要点)
你的模型是否有点过于"跳跃",能够拟合所有的起伏和变化?但你知道这种关系应该始终朝着某个特定方向发展------比如,更高的输入值绝不应该导致更低的输出?
这就是保序回归(Isotonic Regression)发挥作用的地方。
1 什么是保序回归?
保序回归 (Isotonic Regression)是一种非参数方法,用于将非递减(或非递增)函数拟合到一维数据。与线性回归不同,它不假设直线关系------相反,它强制执行单调性。
形式上,它解决的是:
min y ^ ∑ i = 1 n w i ( y i − y ^ i ) 2 \min_{\hat{y}} \sum_{i=1}^n w_i (y_i - \hat{y}_i)^2 y^mini=1∑nwi(yi−y^i)2
受限于:
y ^ 1 ≤ y ^ 2 ≤ ⋯ ≤ y ^ n (对于非递减) \hat{y}_1 \le \hat{y}_2 \le \dots \le \hat{y}_n \quad \text{(对于非递减)} y^1≤y^2≤⋯≤y^n(对于非递减)
其中 w i > 0 w_i > 0 wi>0 是权重, x x x 和 y y y 是实数值。
- 如果
increasing=True,拟合的函数是非递减的。 - 如果
increasing=False,函数是非递增的。 - 如果
increasing='auto',scikit-learn 会根据斯皮尔曼等级相关系数(Spearman's rank correlation)选择方向。
拟合的曲线是分段线性的,这使得它既灵活又可解释。
2 为什么使用保序回归?
- 概率校准:确保逻辑回归或随机森林等模型预测的概率保持良好校准。
- 单调业务规则:例如,当收入增加时,风险评分不应降低。
- 医学研究:剂量-反应曲线通常假设更高的剂量不应降低效果。
3 示例:在 Python 中拟合保序回归
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.isotonic import IsotonicRegression
from sklearn.linear_model import LinearRegression
np.random.seed(42)
x = np.linspace(0, 100, 100)
y = np.log(x + 1) + np.random.normal(0, 0.2, size=100)
iso_reg = IsotonicRegression(increasing=True)
y_iso = iso_reg.fit_transform(x, y)
lin_reg = LinearRegression().fit(x.reshape(-1, 1), y)
y_lin = lin_reg.predict(x.reshape(-1, 1))
plt.scatter(x, y, label="Data", alpha=0.5)
plt.plot(x, y_iso, color="red", label="Isotonic Regression", linewidth=2)
plt.plot(x, y_lin, color="green", linestyle="--", label="Linear Regression")
plt.legend()
plt.title("Isotonic vs Linear Regression")
plt.show()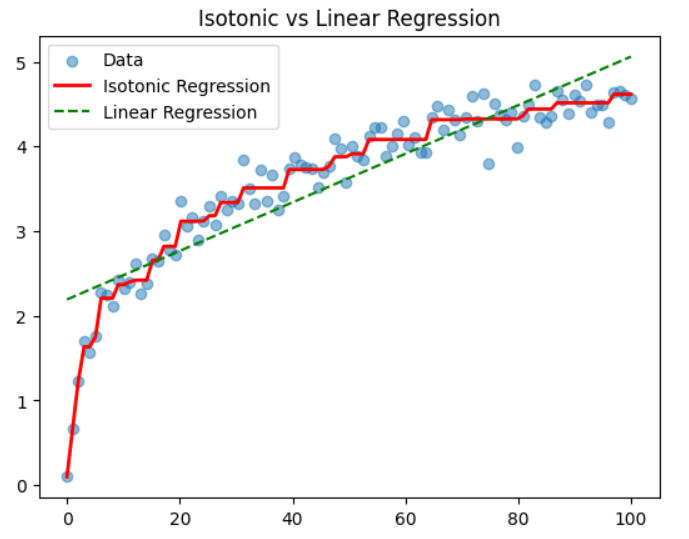
- 蓝色点:带噪声的观测值。
- 红色线:保序回归(分段线性,非递减)。
- 绿色虚线:线性回归拟合。
保序回归能更灵活地适应数据的形状,同时强制执行单调性。
4 实际用例:概率校准
分类模型通常会输出未校准的概率。例如,一个模型可能预测生存概率为0.8,但实际上在该分数下只有约70%的人存活。
保序回归可以通过将预测概率映射到真实似然来解决这个问题。
python
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.isotonic import IsotonicRegression
from sklearn.calibration import calibration_curve
X, y = make_classification(n_samples=5000, n_features=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
probs = clf.predict_proba(X_test)[:, 1]
iso_cal = IsotonicRegression(out_of_bounds="clip")
probs_cal = iso_cal.fit_transform(probs, y_test)
fop, mpv = calibration_curve(y_test, probs, n_bins=10)
fop_cal, mpv_cal = calibration_curve(y_test, probs_cal, n_bins=10)
plt.plot(mpv, fop, label="Uncalibrated", marker="o")
plt.plot(mpv_cal, fop_cal, label="Isotonic Calibrated", marker="o")
plt.plot([0, 1], [0, 1], "k--")
plt.xlabel("Mean predicted value")
plt.ylabel("Fraction of positives")
plt.title("Calibration with Isotonic Regression")
plt.legend()
plt.show()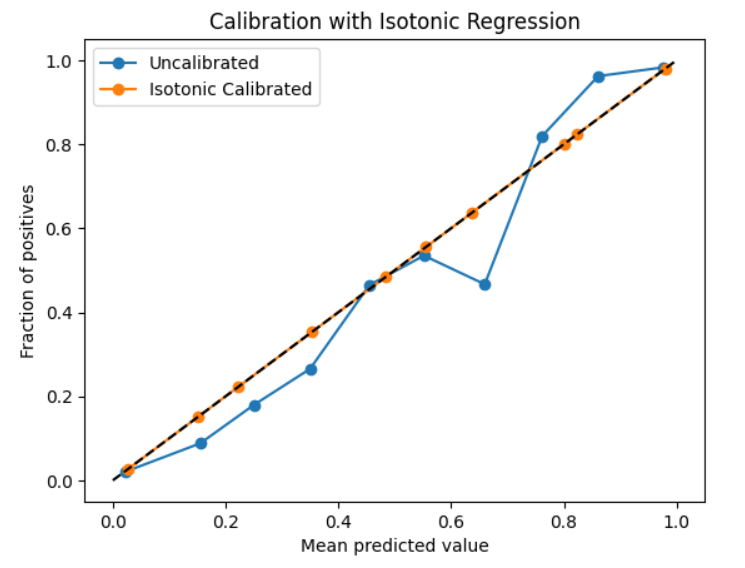
在这里,保序回归校正了概率估计,使其更接近理想的对角线。
5 关键要点
- 保序回归强制执行输入和输出之间的单调关系。
- 它是非参数的,并能适应数据的形状。
- 广泛用于概率校准 和需要单调性的业务约束。
- 在 scikit-learn 中,它通过
IsotonicRegression实现。