提示词工程:核心原理与实战指南
关于提示词工程(Prompt Engineering),有两个贯穿始终的核心观点:
观点 1 :
模型输出质量 = 提示词信息量 × 语境清晰度 × 约束明确度
观点 2 :优秀提示工程的本质是:控制概率分布。
为了真正理解这两句话的含义,我们需要先从大语言模型的底层运行机制说起。
一、 为什么提示词能控制人工智能?
大语言模型(如 GPT 系列)的架构源自经典的 Transformer 模型。
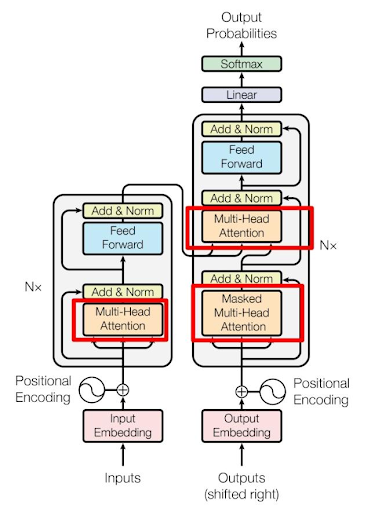
上图展示的是经典的 Encoder--Decoder(编码器-解码器) 结构,其工作原理大致如下:
- Encoder(编码器):负责理解和提取输入信息。
- Decoder(解码器):负责根据理解的信息生成输出。
- Attention(注意力机制):建立输入与输出之间信息关联的核心机制。
然而,现代大语言模型(如 GPT)只使用了 Decoder 部分。原因很简单:
GPT 的核心任务不是"先完整理解完所有内容,再进行输出",而是在已有文本的基础上,预测下一个最可能的 token(词元)。
它的主要目标函数可以表示为:
P(tokent∣token1,...,tokent−1) P(\text{token}_t \mid \text{token}1, \ldots, \text{token}{t-1}) P(tokent∣token1,...,tokent−1)
因此,输入的 Prompt 本身就构成了上下文(Context),模型不需要一个独立的 Encoder 来处理输入,直接利用 Decoder 进行自回归预测即可。
GPT 的实际运行流程
具体来说,GPT 是一个自回归循环系统。它的完整运行流程如下:
lisp
┌────────────────────────────┐
│ 初始 Prompt │
└──────────────┬─────────────┘
↓
Tokenizer 分词
↓
Embedding (向量化)
↓
+ Positional Encoding (位置编码)
↓
┌──────────────────────────┐
│ Decoder Blocks × N │
│ (Masked Multi-Head Attn)│
│ + Feed Forward │
└──────────────┬───────────┘
↓
Linear Projection (线性投影)
↓
Softmax (归一化)
↓
[采样策略 (Temp/Top-K/P)]
↓
预测下一个 Token (最终选择)
↓
┌──────────┴──────────┐
│ 是否结束?(EOS / max)│
└──────────┬──────────┘
│
否 ────────┘
↓
将新Token拼接到序列末尾
↓
回到 Decoder 继续循环二、 提示词作用机制的对比分析
为了更直观地展示提示词是如何影响模型内部运行的,下文我将以同任务的两种提示词例子,进行运行机制的对比分析。
实验设定
🧪 实验 A(简单 Prompt)
text
写个吹风机广告。🧪 实验 B(结构化 Prompt)
text
我们是一家新兴高端家电品牌,主打极简科技。
请写一段吹风机上市广告,风格参考苹果发布会,语气克制、高级、自信,
目标受众是25-35岁的职场女性。广告结构请包含:痛点、解决方案、
使用场景和收尾CTA。实验 B 解析:
- Context(背景): 新兴高端家电品牌,主打极简科技。
- Objective(目标): 写一段吹风机上市广告。
- Style(风格): 苹果发布会风格。
- Tone(语气): 克制、高级、自信。
- Audience(受众): 25-35岁职场女性。
- Response(响应): 结构包含痛点、解决方案、场景和收尾CTA。
Step 1:Tokenizer 分词
模型首先将文字切分为 token:
- 实验 A:
["写", "个", "吹风机", "广告", "。"] - 实验 B:
["我们", "是", "一", "家", "新兴", "高端", "家电", "品牌", ",", "主打", "极简", "科技", "。", "请", "写", "一", "段", "吹风机", "上市", "广告", ",", "风格", "参考", "苹果", "发布会", ",", "语气", "克制", "、", "高级", "、", "自信", ",", "目标受众", "是", "25-35", "岁", "的", "职场", "女性", "。", "广告", "结构", "请", "包含", ":", "痛点", "、", "解决方案", "、", "使用场景", "和", "收尾", "CTA", "。"]
Step 2:Embedding & Positional Encoding
接着,模型将这些 token 转化为可以计算的向量表示:
- 实验 A: 将
["写", "个", "吹风机", "广告", "。"]转为对应向量 embedding,并加入位置信息。 - 实验 B: 将长串 token 每个都转为向量 embedding,并精确叠加 positional encoding,以保留复杂的语序和逻辑结构信息。
Step 3:Decoder Blocks 处理(核心差异)
这是模型拉开差距的关键环节。每一层 Decoder Block 都在做两件事:
- 注意力机制(Attention): 决定当前的词应该"看"哪些词。它通过计算词与词之间的注意力权重,把散落的词拼凑成一个有意义的"特徵向量"。
- 前馈网络(FFN): 这是一个巨大的知识映射仓库。它根据 Attention 算出来的向量,去寻找概率空间中对应的知识表达。
Decoder Block 的核心任务就是通过 NNN 层循环,将原始的词汇信号不断叠加、过滤、增强,最终变成一个极具导向性的语义包。
对于 🧪 实验 A(简单 Prompt):陷入"概率稀释模式"
- 第一步:多头注意力(Attention)------ 「涣散的连线」
- 动作: 聚光灯只在"吹风机"和"广告"之间跳动。由于信息量 极低,Attention 在计算权重时,发现周围是巨大的信息真空。
- 结果: 它生成了一个极其单薄的"搜索指令"。它告诉模型:"我们要找点关于吹风机广告的东西,随便什么都行。"
- 第二步:前馈网络(Feed Forward)------ 「平庸的知识提取」
- 动作: FFN 接收到上述模糊的指令,开始在它数千亿参数的知识库里搜索。因为指令没有约束,它只能提取出**"最大公约数"**的常规语义。
- 结果(FFN 输出向量): FFN 吐出的结果指向了词表中最常见的、平庸的区域。它包含的信号无非是:"写写性能吧"、"夸夸好用吧"。
- 概率状态: 此时的语义包没有偏见,这意味着在下一步预测时,所有大众化词汇的概率是平均分布的。
对于 🧪 实验 B(结构化 Prompt):开启"概率收拢模式"
- 第一步:多头注意力(Attention)------ 「高密度的连线」
模型在训练过程中,多头注意力会自动演化出不同的关注逻辑 。在高质量 Prompt 的驱动下,分工往往极其明确:- 头 A(语义属性头): 负责**"定性"**。它在扫描到"吹风机"时,会立刻去 Prompt 寻找形容词,精准捕捉到"新兴高端、极简科技"。
- 头 B(用户画像头): 负责**"定人"**。它会过滤掉无关信息,专门寻找受众标签,建立"产品---职场女性"的逻辑关联。
- 头 C(风格/格式头): 负责**"定调"**。它对"风格参考、语气"等词汇极其敏感,确保生成的词元方向符合"苹果发布会"的特定分布。
- 结果: 最终生成了一个高度压缩的、带有强烈目的性的"搜索指令"。
- 第二步:前馈网络(Feed Forward)------ 「高溢价的语义包」
- 动作: 面对如此复杂的坐标,FFN 无法再敷衍了事。它被迫绕过那些大众化的语料,去挖掘那些深层的、特定审美语境下的知识映射。
- 结果(FFN 输出向量): 它吐出了一个精准、高溢价的语义包 。它自动屏蔽 了"买一送一"、"大促"等低质量语义,同时强化了"从容、质感、定义"等符合特定风格的核心语义特征。
- 逻辑执行: 此时,FFN 不仅找到了好词,还根据 Response 的约束,将生成概率精准地引导在了"痛点"所在的语义区域。
Step 4:预测输出(Linear Projection + Softmax)
在经过 N 层 Decoder Block 的精细加工后,模型手中的数据仍然是一堆高度抽象的向量(特征信号)。要把这些信号变成看得见的文字,必须经过两道关卡:
-
Linear Projection(线性投影):从"思想"到"词表"
- 物理动作: 这一步就像是一个巨大的转换接口 。模型将 Decoder 输出的高维向量映射到一张巨大的词表上(通常包含数万个词元,如"吹風"、"機"、"從容"等)。
- 本质: 就是在给词表里的每一个可能的下一个词打分(Logits)。
-
Softmax:从"分数"到"概率"
- 物理动作: 所有的原始分数量尺不一且杂乱,Softmax 的作用是进行归一化 ,将分值转化为 0 到 100% 之间的概率,且所有词的概率之和等于 1。这便是模型最终决定输出结果的"选票统计站"。
此时再看两者的差异:
-
🧪 实验 A(简单 Prompt)的概率稀释:分布"扁平化"
由于前期 Attention 没能锁定语境(没有高端、苹果风等约束),映射出来的分值非常接近。Softmax 的表现会非常"纠结":
- "好用":15%
- "便宜":12%
- "不错":11%
- "买它":10%
- ...其余 50% 散落在几千个无关词汇上。
后果: 没有任何一个词具有绝对优势。模型在生成时就像在"抓阄",输出的内容自然显得随意且平庸,缺乏逻辑的连贯性。
-
🧪 实验 B(结构化 Prompt)的概率聚焦:分布"尖峰化"
得益于前期 Attention(找关联)建立的精密网络和 Feed Forward(找答案)的精准过滤,向量信号带有极强的"指向性"。Softmax 的表现会极其"自信":
- "从容":65%(受苹果风+职场女性约束)
- "优雅":15%
- "定义":10%
- ...其他平庸词汇(如"便宜")的概率被极限挤压到了 0.001% 以下。
后果: 概率空间被极限挤压,模型几乎"别无选择"地走向了你预设的高级词汇。这就印证了"优秀提示工程的本质是控制概率分布"的观点。
Step 5:采样策略 ------ 概率迷宫中的"最后筛选"
在 Softmax 算出了一张概率表后,AI 并不会机械地只选概率最大的词。为了让对话更自然,它会引入三个关键参数来控制"随机性"。
1. 参数原理拆解
- Temperature (温度):概率的"贫富差距调节器"
- 核心公式 :P(xi)=exp(zi/T)∑jexp(zj/T) P(x_i) = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)} P(xi)=∑jexp(zj/T)exp(zi/T)(其中 ziz_izi 为模型输出的原始分数 Logit,TTT 为温度参数)
- 低温度 (T<1T < 1T<1):拉大差距。原本 60% 的概率会变成 99%,让 AI 变得极其保守、稳定。
- 高温度 (T>1T > 1T>1):缩小差距。让原本 10% 的词也有机会露脸,让 AI 变得更有创意(但也更容易胡言乱语)。
- Top-K:候选项的"末位淘汰制"
- 核心计算逻辑 :设定候选集合 V(K)V^{(K)}V(K) 为概率排名前 KKK 个词的集合,随后在集合内重新计算归一化概率:P′(xi)=P(xi)∑xj∈V(K)P(xj) P'(x_i) = \frac{P(x_i)}{\sum_{x_j \in V^{(K)}} P(x_j)} P′(xi)=∑xj∈V(K)P(xj)P(xi)(不在集合中的词概率直接设为 0)。
- 强制只在概率排名前 K 个词中选择。哪怕剩下的词概率再接近,只要不在前 K 名,就直接出局。
- Top-P (核采样/Nucleus Sampling):动态的"朋友圈"
- 核心计算逻辑 :将词汇表按原始概率从大到小降序排列,寻找最小的词汇集合 V(P)V^{(P)}V(P) 使得它们的累加概率满足:∑xi∈V(P)P(xi)≥p \sum_{x_i \in V^{(P)}} P(x_i) \ge p xi∈V(P)∑P(xi)≥p 找到后,同样在该集合内重新归一化概率。
- 不固定人数,而是根据累加概率来切分。它只看那些"撑起大局"的词,直到它们的概率加起来达到 P 为止。
2. 🧪 实验 B 的场景模拟:翻哪张牌?
我们以 实验 B(结构化 Prompt) 中,AI 准备生成**"痛点"**部分的第一个词为例。假设 Softmax 算出的原始概率如下:
- A:「清晨」 (60%) ------ 符合职场、场景要求
- B:「发丝」 (20%) ------ 符合产品要求
- C:「焦虑」 (10%) ------ 符合受众心理要求
- D:「买它」 (1%) ------ 低质量、非苹果风词汇
情况 1:低温度 (Temp=0.1) + Top-K=1
- AI 的选择:「清晨」。
- 效果:概率差距被无限放大,「清晨」几乎成了唯一答案。AI 极其稳健,完全按照最可能的路径行驶,但每次生成的结果几乎一模一样。
情况 2:中温度 (Temp=0.7) + Top-P=0.9
- AI 的选择:在 {清晨, 发丝, 焦虑} 中随机抽取。
- 效果:因为这三个词加起来正好 90%,它们都在候选池里。AI 这次可能选「发丝」,下次可能选「清晨」,输出变得灵动且有文采,且因为 Top-P 过滤了概率仅 1% 的「买它」,文案依然保持着高级感。
情况 3:高温度 (Temp=1.5) + 无过滤
- AI 的选择:可能选中 「买它」 甚至其他无关词。
- 效果:概率差距被抹平,低概率词"翻身农奴把歌唱"。输出变得不可控,虽然可能有惊喜,但极易跑题。
3. 🧪 实验 A 的对比:失控的概率
在 实验 A(简单 Prompt) 中,因为没有约束,原始概率是散乱的:
「吹风机」(10%)、「不错」(9%)、「好用」(8%)......
后果:由于底层概率分布本身就很平庸,无论你怎么调 Top-P 或温度,AI 都在一堆"平庸词汇"里打转。调高温度,它会因为缺乏地心引力而迅速滑向幻觉和胡言乱语。
📝 抽象总结:参数在 Prompt 工程中的定位
你可以用这段话来深刻理解参数与提示词的关系:
"提示词工程(Prompt)建设'三观',采样参数(Parameters)调整'性格'。"
- 温度(Temperature) ≈ AI 的创造力
它决定了 AI 是做一个循规蹈矩的教书匠(低温),还是一个天马行空的艺术家(高温)。 - Top-K/P ≈ AI 的理智线
它决定了 AI 的朋友圈有多大,是否允许那些"荒谬但可能"的想法进入最终决策。
💡 底层真理:
如果没有实验 B 提供的强力「语义约束」,AI 的创造力就是脱缰的野马;
只有当你的 Prompt 提供了足够的信息量与语境,这种「创造力」才会变成我们想要的高级质感。
Step 6 ~ 8:循环生成与最终结果
- Step 6 检测结束条件与生成逻辑(是否结束 EOS / max token):
- 实验 A: 因为没有框架约束,生成句子长度不固定,很可能生成单句或随机多句,极其容易跑题。
- 实验 B: 只有在完成结构化目标(痛点-解决方案-场景-CTA)并生成到 EOS(结束符)后才会停止,从而保证了完整性和逻辑性。
- Step 7 回到 Decoder 拼接新 Token:
- 实验 A: 每次生成的 token 回到系统后,注意力依旧只能关注"吹风机"和"广告"核心词,生成路径极其散漫自由。
- 实验 B: 每次新 token 回锅,模型都会持续更新注意力权重,牢牢锁住品牌定位、风格、受众和结构框架,保持高度一致性。
- Step 8 生成结果示例对比:
- 实验 A 最终生成可能为:"这款吹风机很轻巧,使用方便,适合日常。"
- 实验 B 最终生成可能为:"早晨的匆忙,让打结的发丝成为你的困扰。这款极简科技吹风机,智能调节风温,让头发快速顺滑。无论是赶往办公室的早高峰,还是周末的约会时光,它都让你自信从容。立即拥有,让每一天从发丝开始精致。"
三、 深度解析核心公式
通过以上的运行机制拆解,我们再回过头来看第一个核心观点:
核心公式:
模型输出质量 = 提示词信息量 × 语境清晰度 × 约束明确度
这三个维度分别在大模型生成中扮演着无可替代的角色:
1. 提示词信息量 (Information Volume) ------ 定位:内容的"燃料" (The Fuel)
- 普适性定义: 消除事实真空 。指你提供给 AI 的原始素材、背景事实、核心数据。
- 它的角色: 决定了输出内容的**"厚度"**。
- 诊断标准: 如果 AI 输出的内容空洞、净说废话、逻辑推导没有依据,那就是信息量不足。你没有喂够"料",导致注意力机制找不到焦点,AI 只能靠平庸的概率分布自行脑补。
2. 语境清晰度 (Context Clarity) ------ 定位:理解的"滤镜" (The Filter)
- 普适性定义: 消除认知歧义 。指你设定的身份角色、情感基调、受众对象、场景氛围。
- 它的角色: 决定了输出内容的**"调性"**。
- 诊断标准: 如果 AI 输出的内容虽然正确但"感觉不对"(比如太死板、太轻浮、不专业),那就是语境模糊。此时 AI 的多头注意力(Attention)不知道该去调取哪个特定领域的词汇库。
3. 约束明确度 (Constraint Precision) ------ 定位:结果的"模具" (The Mold)
- 普适性定义: 消除运行偏差 。指你对格式、结构、字数、禁止项、步骤流程的硬性要求。
- 它的角色: 决定了输出内容的**"良品率"**。
- 诊断标准: 如果 AI 输出的内容逻辑混乱、缺项漏项、格式不符,那就是约束不够。你给了它太大的自由度,导致 Feed Forward 在生成时跑出了你预设的轨道。
| 参数 | 它回答了什么问题? | 它在 AI 内部的作用 | 如果缺失会怎样? |
|---|---|---|---|
| 信息量 | "写什么?" | 提供 Attention 扫描的素材依据 | 空洞: 全是车轱辘话 |
| 语境 | "像谁写?" | 锁定特定审美或垂直领域的概率分佈 | 违和: 身份感与基调缺失 |
| 约束 | "怎么长?" | 强制 Feed Forward 的运行路径和边界 | 失控: 格式框架与逻辑混乱 |
🎤 为什么是"乘法"而不是加法?
在这个系统中,这三者是相乘的关系,这意味着任何一个维度缺失或极其薄弱,整体效果就会大打折扣,甚至归零:
- 有信息量、有约束,但 没语境:出来的东西往往是"对的废话",像干燥的说明书一般,冷冰冰没有灵魂。
- 有语境、有约束,但 没信息量:出来的东西极容易变成"华丽的辞藻堆砌",金玉其外败絮其中,经不起实际业务推敲。
- 有信息量、有语境,但 没约束:出来的东西常常表现为"失控的才华",文采甚至内容都很好,但往往逻辑结构散漫,你没法直接排版套用。
总结来说,提示词工程的本质,就是通过这三个维度的协同发力,实现对模型输出概率的"极限挤压",让 AI 只能朝着你预设的高质量方向生成。
四、 提示词实战指南与工具
基于大模型的底层工作逻辑,当 AI 的输出不如预期时,我们可以进行标准化的**"三步诊断"**:
- 缺料吗? (检查 信息量:事实与素材是否充足?)
- 跑调吗? (检查 语境:身份与对象设定是否明确?)
- 乱套吗? (检查 约束:格式与框架结构是否具体?)
🛠️ 实战工具:CO-STAR 模型映射表
为了更好地落地实战,我们可以将这套核心公式完美应用于现今最流行的 CO-STAR 框架中,借此精准控制 AI 内部的概率分布:
| 公式维度 | CO-STAR 元素 | 填写指南 |
|---|---|---|
| 1. 信息量 (Input) | C - Context (背景) O - Objective (目标) | 提供燃料: 描述目前的具体情况、面临的问题、以及你最终想达成的具体结果。 |
| 2. 语境度 (Clarity) | S - Style (风格) T - Tone (语气) A - Audience (受众) | 精准滤镜: 指定模仿对象(如:资深架构师)、口吻(如:冷静专业)以及内容重点是给谁看的。 |
| 3. 约束力 (Constraint) | R - Response (响应) | 打造模具: 明确规定输出格式(表格、JSON、Markdown)以及必须包含的章节或步骤要求。 |
📝 终极秘籍:写出顶级 Prompt 的三步法
无论你的需求多么复杂,只需要牢记并执行以下三步,就能写出能够锁定"概率尖峰"的优质提示词:
- 堆素材 (C+O) ------ 消除事实真空:别让 AI 猜。把业务背景、具体事实和核心目标写清楚,提供充足的信息量。
- 定调子 (S+T+A) ------ 消除理解歧义:像导演讲戏一样给 AI 定戏路。明确模仿对象的视角、情感基调和受众的身份偏好。
- 设护栏 ® ------ 消除逻辑盲目:不要给出开放式的要求。提供明确的模块清单、结构要求和格式示例,确保生成路径始终按规矩前行。
理解并应用了这些核心原理,你不仅掌握了写好提示词的表面技巧,更是真正掌握了驾驭大模型的底层思维引擎。