🔥 本文专栏:c++
🌸作者主页:努力努力再努力wz



💪 今日博客励志语录 :
每一次抉择,都是将未来的自己轻轻推向某个方向
★★★ 本文前置知识:
红黑树
原理
那么在上一期博客中,我着重讲解了红黑树的原理以及如何用代码来实现红黑树,在有了红黑树的知识后,我们便又能掌握并且实现stl中的另外两个容器,其便是set和map,那么set和map的底层结构采取的就是红黑树,而set的是key模型的红黑树,而map则是key-value模型的红黑树
既然set以及map分别对应的是key模型的红黑树以及key-value模型的红黑树,这里便引出本文的第一个思考点:这里stl的设计者如果实现set以及map的话,那么他是会分别为set和map编写一份key模型的红黑树的代码和key-value模型的红黑树代码吗还是说两者共用一个红黑树的代码?
在揭晓答案之前,我们可以自己先推导一下,首先key模型的红黑树以及key-value模型的红黑树中对应的节点的定义是不一样的,那么key模型的红黑树节点的数据域则是存储一个键值即可,而key-value模型的红黑树则是存储一个键值对,也就是pair
其次就是对于红黑树相关操作的函数,比如以insert插入函数为例,那么key模型的红黑树的insert函数则是需要获取一个键值,然后拷贝到新插入的节点中,而对于key-value模型的红黑树的insert函数来说,其会接收一个键值对,也就是pair,然后拷贝到新插入的节点中
所以理论上,我们确实可以分别为set以及map各自分别编写适应其自身特性的红黑树代码,但是根据上文的分析,我们可以发现,其实set和map底层对应的红黑树代码的逻辑几乎是相同的,以红黑树的insert函数为例,set和map最多就是拷贝到新插入节点中的数据不同,其他逻辑都是一样的,而对于红黑树的节点的定义来说,其同样就只有存储的数据域的数据类型不同,其他都是相同的
所以我们没必要为map和set各自编写一份代码,而事实上,stl的设计者也确是没这么做,而上文所说的场景,也就是map和set底层的红黑树的代码逻辑几乎相同,唯一不同的就是处理的红黑树节点中的数据域的数据类型
而这个场景正是模版所应用的场景:模版只关心代码的逻辑,而不关心其处理的数据,那么具体处理什么类型的数据,则是由模版的实例化来决定
而模版的核心思想就是代码复用,所以这里stl的设计者实现map和set的核心思想就是复用同一个红黑树的模板类,而复用的这个红黑树的模板类,则是key-value模型的红黑树
而map和set这种复用已经实现好了的数据结构,而不用我们自己单独在为map和set重新完整编写适应其自身特性的一个数据结构的方式,便是我们熟悉的容器适配器模式,包括stl库中的栈和队列这两种容器,也是采取这种方式,直接复用库中已经实现好的vector和list
既然复用的是key-value模型的红黑树模板类,那么这里对于set来说,由于其是key模型,但是为了让key-value模型的红黑树支持set,所以这里将set底层的红黑树的k这两个模版参数key和value都实例化为key
但由于map本身就是key-value模型,那么这里是不是意味着map可以直接按照我们最熟悉的方式,也就是key模版参数实例化为键值key,而value模版参数则是实例化键值key对应的值value
这样做看似没有任何问题,但是事实上,由于这里set和map都是复用同一个红黑树的模板类,那么对于红黑树中某些成员函数来说,就会有影响,代表的就是insert函数,虽然map和set的insert函数的逻辑几乎相同:其都是先借助二叉搜索树的左小右大的性质,然后寻找定位到新插入节点的位置以及其父节点,然后再将insert接收到的参数也就是插入的值拷贝到创建好的新节点中,而该值对于map则是一个pair<key,val>类型,对于set则是一个key类型,最后一步则是调节平衡,会沿途往上遍历祖父节点,如果不平衡就变色或者旋转加变色来调整至平衡
但是如果这里对于map来说,其key和value就分队对应键值对的第一个元素和第二个元素的数据类型,那么接下来你将会面对一个问题,就是这里insert函数的原型你该怎么书写
由于这里map和set都是复用同一套红黑树的模板类,意味着这里insert函数需要能够同时接收key类型的参数以及pair<key,val>类型的参数
有的读者认为,这里我确实无法仅仅靠一个insert接口来同时接收并且处理两种数据类型,但我可以采取红黑树的模板类编写两个insert成员函数,一个接收key类型的参数,另一个接收pair<key,val>类型的模版参数,那么这两个成员函数的函数名相同,但参数列表不同,让它们构成函数重载,到时候根据传递的实参确定调用哪个成员函数
理论上,这种实现方式确实可行,但是这里我想说的是,这里实现map和set采取的是代码的复用的思想,所谓的代码的复用,其实是一种泛型编程,那么这里作为底层复用的红黑树模板类,它是不知道也不会关心上层要处理的数据类型是什么,而如果我们采取上文的方式,是与这里代码的复用完全相违背的,因为编写了处理特定数据类型的代码,而模版的核心思想正是忽略处理的数据类型,只关心代码的逻辑
所以这里stl的设计者巧妙的将key-value模型的红黑树模板类的第二个模版参数,也就是value,将其视作通用数据类型T,将key-value模型的红黑树变成key-T模型的红黑树
那么这里我在额外补充说明一下我刚才说的话,这里的红黑树模板类还是key-value模型,只不过,这里的第二个模版参数不再代表为键值key或者键值key对应的值val,而是代表一个红黑树节点数据域存储的数据类型,那么对于set来说,其红黑树节点中存储的数据域就是一个键,也就是key,那么这里的T就会被实例化为key,而对于map来说,其红黑树节点中存储的数据域则是一个pair,那么这里这里的T会被实例化为pair
而这里的第二个模版参数会被实例化为key或者pair的好处便是解决了上文我说的那个问题,这样我们让map和set复用同一个函数接口,比如insert函数,那么这里的insert的函数原型我们就可以写出:
cpp
void insert(const T& p);那么由于这里红黑树的第二个模版参数代表的就是红黑树节点中数据域存储的数据类型,所以这里我们也要对红黑树节点的模板类进行一个修改,那么原本的红黑树节点的模板类需要两个模版参数,那么现在其只需要一个模版参数T即可
cpp
enum color
{
BLACK,
RED
};
template<typename T>
class RBTreeNode
{
public:
RBTreeNode<T>* left;
RBTreeNode<T>* right;
RBTreeNode<T>* parent;
T data;
color _col;
RBTreeNode()
:_col(RED)
, left(nullptr)
, right(nullptr)
, parent(nullptr)
, data(T())
{
}
RBTreeNode(const T& p)
:_col(RED)
, left(nullptr)
, right(nullptr)
, parent(nullptr)
, data(p)
{
}
};而对于insert函数来说,我们就可以只用同一个接口来实现set以及map节点的插入,那么其接收的参数就是T类型的参数,那么该T类型的参数既可以代表一个键值key的数据类型,也可以代表pair元组的类型,那么具体什么含义,则是由于上层的实例化来决定:
cpp
template<typename key>
class set
{
priveate:
RBTree<key,key> tree;
...................
public:
void insert(const T& k)
{
tree,insert(k);
}
};对于set来说,这里的第二个模版参数T会被实例化为key,那么这时候set复用底层红黑树的insert函数的时候,就只需要传递给T类型的参数,然后底层的红黑树的inser函数接收到这里的T类型的参数,创建完新节点之后,直接拷贝到新节点即可
对于map来说,这里上层的map类就需要将这里RBTree的第二个模版参数给实例化为pair<key,val>,然后上层在复用底层红黑树实现的insert函数,那么给红黑树的insert函数传递T类型的参数,然后底层的红黑树的insert函数直接将T类型的参数给拷贝到新插入的节点当中即可
cpp
template<typename key,val>
class map
{
private:
RBTree<key,std::pair<key,val>> tree;
.....
public:
void insert(const T& k)
{
tree.insert(k);
}
}所以这就是map和set借助第二个模版参数来,从而能让同一个函数接口来处理不同的数据类型
有的读者事先知道库的map和set的insert函数的返回值的话,事实上库的map和set的insert函数的返回值不是void,而是一个pair元组,那么之所以这里我选择先写成void,是因为返回的pair元组的first,也就是第一个元素是一个迭代器,而当前还没有讲解迭代器,会在后文讲解,所以这里我先把insert函数的返回值设置为void,然后回在后文会逐渐补充完善map和set类的细节,完善这里的insert函数的实现
但话又说回来了,既然这里我们知道了红黑树的第二个模版参数代表红黑树节点中数据域存储的数据类型,当前是set,就将其实例化为键值key,如果是map,就将其实例化为键值对pair,而这里的红黑树是一个key-T模型,意味着这里还有第一个模版参数key,而set和map则会将这第一个模版参数给实例化为各自的键的类型
对于set来说,其红黑树节点只需要存储一个键值key即可,那么这里set将第二个模版参数T已经实例化为键值key,但这里第一个模版参数其也会被实例化为键值key,那么既然这里的key-T模型的红黑树的两个模版参数都会被实例化同一个键值的数据类型,这样是否会显得有点冗余呢
而对于map来说,其第二个模版参数代表就是一个pair元组,这里既然第二个模版参数会被实例化为元组,那么为什么其也需要红黑树的第一个模版参数,将其实例化为键值对中的键的数据类型?根据上文,insert函数在获取到T类型的参数,也就是接收到一个pair元组之后,那么就会直接将元组给拷贝到新插入的节点中即可
所以,这里对于set和map来说,那么红黑树的第一个模版参数到底有什么作用?那么要解释清楚它的作用,就和接下来我要讲的仿函有关,这里我先埋下一个伏笔
仿函数对象keyofT
这里虽然我们将第二个模版参数设置为了红黑树节点的数据域存储的数据类型,从而可以统一并且维护一个函数接口,其中就包括insert函数,但是对于insert函数,确实这里insert函数能够同时接收以及处理键值以及键值对,那么获取到键值以及键值对之后,将其直接拷贝到新插入的节点之中
但是这里又会面临另一个问题,根据insert函数的原理,那么在创建新插入的节点之前,首先需要定位新插入节点的位置以及其父节点,那么这里需要借助二叉搜索树左小右大的性质,从根节点往下遍历,每次遍历都会排除一个子树,确定往下遍历的分支,其中就需要新插入的数据的键与当前节点的键比较
那么如果新插入的数据的键比当前遍历的节点的键小就往左分支继续遍历,如果比当前节点的键大就往右分支继续遍历,那么对于set来说,由于其T会被直接实例化为键值key,那么set的insert函数接收到T类型的参数p,那么其可以直接用p去与节点的键去进行比较,但是对于map来说,那么其会将T实例化为pair类型,那么insert函数接收到T类型的参数p,而这里的T代表的其实是一个pair类型,这里如果我们将参数P还是按之前一样,直接与节点的键去比较:
cpp
void insert(const T& p)
{
.................
Node* cur=root;
Node* parent=nullptr;
while(cur)
{
if(p<cur->data)
{
cur=cur->left
}else if(p>cur->data)
{
cur=cur->right;
}else
{
return;
}
}
..................
}对于set来说,其没有任何问题,因为到时候实例化之后的P代表的就是键值key,但是对于map来说,其实例化的p代表的是一个pair对象,而pair类一个自定义类型,而pair模板类的内部也确实定义了比较运算符重载函数,但是其比较运算符重载函数的逻辑则是:先比较pair的first元素的大小,如果pair的first的大小相同,那么在比较pair的second的元素的大小
而这里我们只需要比较pair的first,也就是键值,不需要比较pair的second,所以这里我们不能用pair自带的运算符重载函数,而这里map和set都是共用同一个insert函数接口,这里我们也不可能对数据的类型做判断,编写这样的代码:if(T == key)
首先这里语法上就不通过,其次就算语法上允许,这里也与模版的泛型编程的思想相违背
所以这里我们就得准备一个仿函数,所谓的仿函数,就是在map以及set中定义一个内部类keyofT,然后这个内部类中定义了一个()运算符重载函数,而map的keyofT的()运算符重载函数的逻辑则是会接收一个T类型的参数,而这里的T会被实例化为pair类型,然后接收到pair对象之后,直接返回pair对象的first即可,而对于set的()运算符重载函数的逻辑则是接收一个T类型的参数,这里的T会被实例化为键值key类型,然后直接返回这里接收到的参数即可
cpp
template<typename key,typename val>
class map
{
private:
class keofMapT{
public:
const key& operator()(const T& p)
{
return p.first;
}
};
RBtree<key,std::pair<key,val>,keyofMapT> tree;
public:
.......................................
};
template<typename key>
class set
{
private:
class keyofSetT{
const key& operator()(const T& p)
{
return p;
}
};
RBtree<key,key,keyofSetT> tree;
public:
.....................................
};那么有了这里的内部类后,这里复用的底层的红黑树的模版类,除了有之前所说的两个模版参数key和T之外,还得额外定义一个模版参数keyofT,这里的keyofT模版参数代表的就是带有()运算符重载函数的内部类类型,那么这里我们就只需要在insert函数中创建一个keyofT对象,也就是仿函数对象,然后再遍历红黑树比较节点时,那么就调用仿函数对象的()运算符重载函数,对于set就直接返回键值,对于map就返回的是pair的first元素
cpp
template<typename key,typename T,typename keyofT>
class RBtree{
private:
........
public:
void insert(const T& p)
{
.............
Node* cur = root;
Node* parent = nullptr;
KeyofT returnKey;
while (cur)
{
if (returnKey(p) < returnKey(cur->data))
{
parent = cur;
cur = cur->left;
}
else if (returnKey(p) > returnKey(cur->data))
{
parent = cur;
cur = cur->right;
}
else
{
return ;
}
}
.............................
}
..............
};所以这种方式,就很好实现了解耦,虽然这里红黑树引入了第三个模版参数并且这会在insert函数内部会创建一个仿函数对象,但是对于底层的红黑树的insert函数来说,其还是不知道也不关心处理的具体是哪种数据类型,也不知道这里的仿函数对象是map的仿函数对象还是set的
不仅维护了泛型处理的思想,并且正是这里的仿函数对象,能够让insert函数支持map的pair对象的比较以及set的键值的比较,让set的比较逻辑和map的比较逻辑分开,实现了解耦
而这里就能解答上文埋下的伏笔,也就是此时红黑树的第一个模版参数究竟有什么用,那么就和这里的map和set的内部类定义的()运算符重载函数有关,那么这里()运算符重载函数要返回的是键,那么在声明()运算符重载函数的时候,其中就要声明返回值的类型,而这里的返回值就是键的类型,那么对于set来说,由于其只有一个键值,那么这里可以直接用T来作为()运算符重载函数的返回值类型,这是没问题的
但是对于map来说,假设这里我们没有第一个模版参数,也就是只有一个模版参数T和一个代表仿函数对象的模版参数keyofT,那么此时你该如何声明map这里的()运算符重载函数呢?
那么有的读者认为,这里pair的模板类内部,其将first元素的类型给typedef为了first_type,那么我们可以通过first_type获取pair对象的first元素的类型
cpp
#include<iostream>
using namespace std;
int main()
{
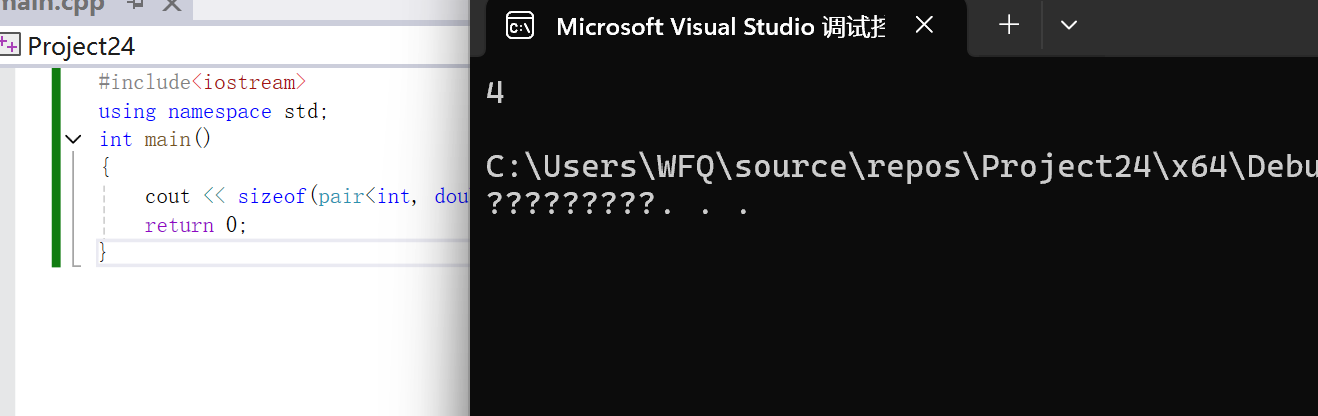
cout<<sizeof(pair<int,double>::first_type)<<endl;
return 0;
}
意味着这里我们可以采取first_type来声明map的()运算符重载函数的返回值的数据类型:
cpp
T.first_type operator()(const T& p);如果是这么思考的读者,那么就对模版的实例化过程不太熟悉,那么在模版被实例化之前,那么编译器会先对模板类以及模版函数进行检查,其中就包括依赖模版参数的检查和非依赖模版参数的名称的查找,那么编译器在检查()运算符重载函数的时候,由于还没有实例化的缘故,编译器是不知道T的含义,也就是其代表的数据类型,那么其可能代表int,也可能代表pair,正是因为编译器不知道T的具体含义,所以其不知道T.first_type是否合法,所以这里编译是无法通过的,而这里之所以需要红黑树的一个模版参数,那么其原因及在这里
那么第一个模版参数代表的就是键的数据类型,第二个模版参数代表的则是红黑树节点数据域存储的数据类型,那么有了这第一个模版参数之后,我们才能够正确声明某些函数的原型,其中就包括这里的()运算符重载函数
迭代器RBTree_iterator
接下来的内容便是完善map和set底层的红黑树的最后一个部分,便是迭代器,这里map和set肯定会提供迭代器,因为这里需要访问容器中的元素,而由于map和set底层都是红黑树,所以这里的迭代器本质上其实就是一个指向红黑树节点的原生指针,那么我们用迭代器遍历map和set的容器的时候,采取的就是通过自增以及自减运算符来遍历整个容器,但是这里map和set底层是一棵红黑树,其不像vector那样,其底层是一个线性并且物理内存连续的动态数组,所以这里就不能利用原生指针的自增以及自减运算符,意味着这里我们需要对红黑树的迭代器进行一个封装,那么封装的目的就包括重载其原生指针的自增以及自减运算符的行为
所以这里我们得准备一个RBTree_iterator模板类,那么模板类内部就会封装一个指向节点的原生指针_Node,而由于这里的迭代器有const版本的迭代器和非const版本的迭代器,那么这里要实现const版本和非const版本的迭代器的第一个做法,就是直接分别为const版本的迭代器以及非const版本的迭代器各自编写一个模板类
而这里由于map和set都是复用同一个红黑树模版,那么对于const版本和非const版本的迭代器,最优的方式也是复用同一个模板类,那么通过不同的实例化来得到const版本的迭代器以及非const版本的迭代器,所以这里我们将RBTree_iterator设置了三个模版参数:
cpp
template<typename T,typename ptr,typename ref>
class RBtree_iterator
{
private:
typedef RBTree_Node<T> Node;
Node* _Node;
.......................
};那么这里的第一个模版参数代表的就是红黑树节点数据域存储的数据类型,而第一个模版参数则是代表的指向红黑树节点的数据域的指针,第三个参数则代表指向红黑树节点的数据域的引用
由于迭代器模拟的就是原生指针,那么意味着这里的迭代器也支持*运算符和-> 运算符,意味着这里RBTree_iterator模板类要重载 *运算符和->运算符,那么 *运算符的作用就是为了访问红黑树节点中的数据域,所以这里的 *运算符就会返回红黑树节点中的数据域,其返回值就是红黑树节点的数据域的引用
而->运算符则是返回的是红黑树节点的数据域的指针
而这里的第二个模版参数以及第三个模版参数分别表示红黑树节点的数据域的指针以及引用,所以这里我们可以直接用第二个以及第三个模版参数作为* 运算符重载函数以及-> 运算符重载函数的返回值类型的声明
cpp
ref operator*()
{
return _Node->data;
}
ref operator*() const
{
return _Node->data;
}
ptr operator->()
{
return &_Node->data;
}
ptr operator->() const
{
return &_Node->data;
}当然这里我们也得提供* 运算符和-> 运算符的const版本,而这里我们知道由于* 运算符以及-> 运算符返回就是节点的数据域的指针以及引用,那么意味着我们可以通过*以及->运算符来访问并且能够修改红黑树节点中的数据域,而const版本的迭代器就是禁止修改迭代器指向的节点中的数据,所以这里对于常量迭代器来说,那么 *以及->返回值就应该是const修饰的指针以及引用,所以这里我们就能够知道如何得到const版本的迭代器了,那么就是将第二个参数实例化为const T * 并且将第三个参数实例化为const T&,那么就能够得到const版本的迭代器
cpp
template<typename key,typename T,typename keyofT>
class RBTree{
public:
typedef RBTree_iterator<T, T*, T&> iterator;
typedef RBTree_iterator<T, const T*, const T&> const_iterator;
.............
};而接下来就是自增运算符的实现,那么我们知道map和set底层采取的红黑树本质是一棵二叉搜索树,其满足左小右大的性质,所以这里自增运算符遍历出来的序列就是有序的,因为其是按照中序遍历,也就是左-根-右,所以RBTree的begin()函数返回的迭代器的位置就是红黑树的左子树的最左侧的节点,也就是整棵树值键值最小的节点作为起始位置
那么这里接下来实现自增运算符的核心就是确定移动的下一个节点的位置,那么在移动之前,我们知道当前迭代器指向的当前节点,其很可能是经过前面的遍历到达到当前指向的节点,所以这里我们就需要判断,如果当前迭代器指向的节点,其右子树存在,那么我们就直接移动到右子树中的最左侧节点
那么这里为什么我们只关心当前迭代器指向节点的右子树而不关心左子树呢,是因为如果当前节点有左子树,那么根据中序遍历的顺序,也就是左-根-右,那么迭代器能够指向当前节点,一定是已经遍历完了其左子树才会指向当前作为局部搜索树二叉树的根节点,所以这里我们不需要关心左子树,那么如果其有右子树,说明右子树还没有被遍历,所以我们就知道迭代器自增后的下一个位置就是右子树中的最左节点
但是如果当前节点没有右子树,那么意味着当前迭代器指向的节点就是其所处的局部搜索二叉树的右子树中的最右侧的节点,也就是右子树中的最大值,说明其所处的局部搜索二叉树左和根和右子树都被遍历完了,那么就得往上回溯,确定当前的局部搜索二叉树整体是作为上层的根节点的左子树还是右子树,那么就得向上回溯,如果当前节点位于父节点的右侧,说明当前局部搜索二叉树整体位于父节点的右子树,意味着以父节点为根节点的局部二叉搜索树也被遍历完,而这里遍历的时候,我会定义两个指针分别是cur和parent,此时就让cur指针移到parent指向的父节点位置,然后parent移到父节点的父节点,继续重复判断,如果当前节点位于父节点的左侧,说明其父节点的左子树遍历完了,那么其parent指向的父节点就是迭代器指向的下一个节点的位置
而如果此时cur都到根节点了,那么说明整棵红黑树都被遍历完了,那么就不用再往上回溯了
cpp
self& operator++()
{
if (_Node == nullptr)
{
return *this;
}
if (_Node->right)
{
Node* cur = _Node->right;
while (cur->left)
{
cur = cur->left;
}
_Node = cur;
}
else
{
Node* cur = _Node;
Node* parent = cur->parent;
while (parent && cur == parent->right)
{
cur = parent;
parent = cur->parent;
}
_Node = parent;
}
return *this;
}而这里由于自增运算符返回的是一个迭代器,所以这里在RBTree_iterator内部又将迭代器本身typedef取了一个别名,为self:
cpp
typedef RBTree_iterator<T, ptr, ref> self;而这里实现的是前置自增运算符重载函数,而后置自增的话,这是需要准备一个变量来保存之前的位置即可
而自减运算符重载函数则是和自增运算符是对称的,那么自减运算符的遍历的顺序就是右-根-左,那么原理其实都差不多,只不过这里得判断当前迭代器指向的节点的左子树是否存在,如果存在,那么就确认下一个节点就是左子树的最右节点,不存在,说明当前迭代器指向的节点就是局部二叉搜索树的左子树的最左侧节点,就需要往上回溯
cpp
self& operator--()
{
if (_Node == nullptr)
{
return *this;
}
if (_Node->left)
{
Node* cur = _Node->left;
while (cur->right)
{
cur = cur->right;
}
_Node = cur;
}
else
{
Node* cur = _Node;
Node* parent = cur->parent;
while (parent && cur == parent->left)
{
cur = parent;
parent = cur->parent;
}
_Node = parent;
}
return *this;
}最后则是== 运算符重载函数以及!=重载运算符函数,那么其实现的逻辑就是会接收一个迭代器,然后比较迭代器中的封装的指针是否指向同一个位置,如果指向同一个节点,那么就返回true,反之则返回false
而这里的 == 运算符重载函数以及!=运算符重载函数的后面都采用const修饰,因为这里只是比较而不会涉及到迭代器的指向的修改
cpp
bool operator==(const self& it) const
{
return _Node == it._Node;
}
bool operator!= (const self& it) const
{
return _Node != it._Node;
}map和set的封装
有了上文的仿函数对象以及迭代器的知识,那么这里我们就可以封装红黑树RBTree模板类以及迭代器来实现map和set了,首先map和set中就得封装以及维护一个红黑树对象,因为map和set的实现采取的是容器适配器模式,那么其中map和set的各种成员函数的实现则是会复用底层的红黑树的成员函数
其次就是迭代器,那么这里map和set也是直接复用底层红黑树的迭代器类型,那么对于set来说,那么其是key模型,那么意味着存储在红黑树节点中的键是不能被修改的,而我们访问set以及map容器中的元素就是通过迭代器,所以这里我们就得将set中的iterator和const_iterator都得设置为RBtree中const_iterator的别名,这样你无论使用的是那种类型的set的迭代器,那么都无法修改红黑树节点中存储的键值
cpp
template<typename key>
class set{
public:
typedef typename RBTree<key, key, KeyofSetT>::const_iterator iterator;
typedef typename RBTree<key, key, KeyofSetT>::const_iterator const_iterator;
..........
private:
class keyofSetT
{
const key& operator(const key& p)
{
return p;
}
};
RBtree<key,key,keyofSetT> tree;
};而对于map来说,那么map的迭代器则是正常将RBTree中const版本的迭代器typedef定义为map的const版本的迭代器,将RBTree中非const版本的迭代器typedef定义为map的非const版本的迭代器
cpp
template<typename key, typename val>
class map
{
private:
class KeyofMapT
{
public:
const key& operator()(const std::pair<const key, val>& p)
{
return p.first;
}
};
RBTree<key, std::pair<const key, val>, KeyofMapT> tree;
public:
typedef typename RBTree<key, std::pair<const key, val>, KeyofMapT>::iterator iterator;
typedef typename RBTree<key, std::pair<const key, val>, KeyofMapT>::const_iterator const_iterator;
.............................
};但是这里要注意的就是,虽然我们可以用map的迭代器去访问map容器中的元素,甚至去修改map容器中的元素,但是要注意的就是这里修改只能修改元组中的second,而不能修改元组中的first,而这里map不能采取set那样的做法,也就是将RBTree中的const_iterator都设置为map的iterator和const_iterator,那么采取这种方式的话,那么就会导致map既不能修改元组中的first,也不能修改元组中的second
所以这里采取的做法就是将实例化的pair中的first元素的属性给设置为const,那么采取这种做法,虽然我们可以通过迭代器访问到pair中的const元素,但是我们如果尝试修改它,那么在编译阶段就会报错,所以这种方式是一个更合理的方式
insert函数
那么既然知道了红黑树的迭代器之后,那么我们就可以完善我们红黑树的insert函数以及find函数了,那么事实上,红黑树的insert函数的返回值并不是void,而是一个元组,那么元组的第一个元素就是一个迭代器,第二个元素则是一个bool值,那么如果插入失败,也就是红黑树已经有该键值的节点,返回的元组的第一个元素就是指向红黑树当前已存在该键值的节点的迭代器,然后第二个元素设置为false
而如果插入成功,那么返回的元素的第一个元素就是指向新插入的节点的迭代器,然后第二个元素设置为true
cpp
std::pair<iterator, bool> insert(const T& p)
{
if (root == nullptr)
{
root = new Node(p);
root->_col = BLACK;
return std::make_pair(iterator(root), true);
}
Node* cur = root;
Node* parent = nullptr;
KeyofT returnKey;
while (cur)
{
if (returnKey(p) < returnKey(cur->data))
{
parent = cur;
cur = cur->left;
}
else if (returnKey(p) > returnKey(cur->data))
{
parent = cur;
cur = cur->right;
}
else
{
return std::make_pair(iterator(cur), false);
}
}
cur = new Node(p);
Node* newnode = cur;
if (returnKey(p) < returnKey(parent->data))
{
parent->left = cur;
cur->parent = parent;
}
else
{
parent->right = cur;
cur->parent = parent;
}
while (parent && parent->_col == RED)
{
Node* grandfather = parent->parent;
if (parent == grandfather->left)
{
Node* uncle = grandfather->right;
if (uncle && uncle->_col == RED)
{
parent->_col = BLACK;
uncle->_col = BLACK;
grandfather->_col = RED;
cur = grandfather;
parent = cur->parent;
}
else
{
if (cur == parent->left)
{
RotationR(grandfather);
grandfather->_col = RED;
parent->_col = BLACK;
break;
}
else
{
RotationL(parent);
RotationR(grandfather);
grandfather->_col = RED;
cur->_col = BLACK;
break;
}
}
}
else
{
Node* uncle = grandfather->left;
if (uncle && uncle->_col == RED)
{
parent->_col = BLACK;
uncle->_col = BLACK;
grandfather->_col = RED;
cur = grandfather;
parent = cur->parent;
}
else
{
if (cur == parent->right)
{
RotationL(grandfather);
grandfather->_col = RED;
parent->_col = BLACK;
break;
}
else
{
RotationR(parent);
RotationL(grandfather);
grandfather->_col = RED;
cur->_col = BLACK;
break;
}
}
}
}
root->_col = BLACK;
return std::make_pair(iterator(newnode), true);
}那么对于上层封装红黑树的map类来说,那么直接复用底层实现好的insert函数即可
cpp
std::pair<iterator, bool> insert(const std::pair<const key, val>& p)
{
return tree.insert(p);
}但是对于set来说,那么这里会有一个小坑,因为这里set类将iterator和const_iterator都设置为了RBTree的const_iterator的类型的别名,那么这里上层的set的insert函数的返回值,第一个元素的声明虽然是iterator类型,但事实上其是一个const_iterator类型,而这里底层调用红黑树的insert函数的时候,那么其返回的是RBTree_iterator<T,T*,T&>类型,那么这里返回到上层的set的insert函数中的时候,在由set中的insert函数再返回到外部的函数调用处,由于这里set的insert函数要返回的元组中的第一个元素的类型是一个RBTree_iterator<T,const T *,const T&>
那么这里底层的insert函数返回RBtree_iterator<T,T*,T&>是无法转化为RBTree_iterator<T,const T *,const T&>,所以这里编译器会报一个类型转化的错误
那么要解决这个问题,那么我们就只能利用隐式类型转化,也就是将非const版本的迭代器类型转化为const版本的迭代器类型,那么要实现隐式类型转化,我们就得在RBTree-iterator模板类中定义一个接收非const版本迭代器的单参数的构造函数
所以这里我在RBTree_iterator中将非const版本的迭代器typedef为了iterator:
cpp
template<typename T,typename ptr,typename ref>
class RBTree_iteratro{
private:
typedef RBTreeNode<T> Node;
typedef RBTree_iterator<T, ptr, ref> self;
typedef RBTree_iterator<T, T*, T&> iterator;
Node* _Node;
.......................................................................
};然后这里在编写一个接收非const版本的迭代器的构造函数:
cpp
RBTree_iterator(const iterator& p)
:_Node(p._Node)
{
}但是这里还没有结束,那么编写完该构造函数的时候,事实上,你去实际运行,发现编译还是无法通过,原因就是这里const版本的迭代器和非const版本的迭代器,虽然他们都是来自同一个模板类,但是一旦实例化之后,实例化生成的const版本的迭代器的类和非const版本的迭代器的类是属于两个不同的类,而这里的_Node成员变量是私有的,所以会报一个无法访问另一个类的私有的成员变量的编译错误
所以这里就需要我们定义一个共有的getNode接口,那么该接口就是返回当前迭代器中封装的指向红黑树节点的指针,那么该接口后面要被const修饰,因为这里构造函数接收的参数前面是被const修饰了,这里我们在构造函数内部调用该接口来初始化当前迭代器的成员变量
cpp
RBTree_iterator(const iterator& p)
:_Node(p.getNode())
{
}
Node* getNode() const
{
return _Node;
}那么该构造函数如果当前是一个const版本的迭代器,并且其接收的是一个const版本的迭代器对象,那么此时就会变成拷贝构造函数,而如果接收到是非const版本的迭代器对象,那么其就是构造函数,那么这样set就可以直接复用底层的insert函数了
cpp
std::pair<iterator, bool> insert(const key& p)
{
return tree.insert(p);
}begin/end函数
那么这里map和set的底层的begin和end函数都是复用底层红黑树实现的begin和end函数,这里就注意底层红黑树的begin和end函数的实现,那么begin函数则是首先遍历红黑树的左子树,得到红黑树的左子树最左侧的节点,然后返回指向给节点的迭代器,而end函数则是返回指向空节点的迭代器即可,注意begin和end都要提供const版本和非const版本
cpp
template<typename key,typename T,typename keyofT>
class RBTree
{
public:
const_iterator begin() const
{
if (root == nullptr)
{
return end();
}
Node* cur = root;
while (cur->left)
{
cur = cur->left;
}
return const_iterator(cur);
}
iterator end()
{
return iterator(nullptr);
}
const_iterator end() const
{
return const_iterator(nullptr);
}
........................
};上层:
cpp
iterator begin()
{
return tree.begin();
}
const_iterator begin() const
{
return tree.begin();
}
iterator end()
{
return tree.end();
}那么这里我们实现begin函数则是直接遍历得到红黑树左子树的最左侧节点,而实际上库的实现和这里有所不同,那么对于库来说,那么整棵树的根节点的指向父节点的指针不是指向nullptr,而是指向一个哨兵为节点header,库的底层实现的红黑树,是维护一个带有哨兵位节点的红黑树,那么这里的哨兵位节点的父节点指针则是指向整棵树的根节点
而哨兵位节点的左指针则是指向红黑树的左子树的最左侧的节点,而右指针则是指向红黑树的右子树的最右侧的节点,那么这里实现begin的时候,由于有哨兵位节点header的存在,那么直接解引用header的左指针即可得到左子树的最左侧节点,那么不用往下遍历,那么这样看似提高了效率,但是对于带有哨兵节点的红黑树来说,那么其插入和删除的实现就变得复杂,因为这里插入和删除会涉及到旋转,那么旋转玩之后,还要将旋转后的左子树的最左侧节点以及最右侧节点与哨兵节点header连接,那么可以采取库的实现方式,那么也可以采取我这种,直接遍历得到begin要指向的左子树的最左节点
父指针 左指针 右指针 父指针 左指针 右指针 父指针 左指针 右指针 父指针 左指针 右指针 父指针 左指针 右指针 父指针 左指针 右指针 父指针 左指针 右指针 父指针 左指针 右指针 Header
哨兵节点 4
黑色 2
黑色 6
红色 1
红色 3
红色 5
黑色 7
黑色
find函数
对于map和set的find函数还是复用红黑树底层的find函数,其中红黑树底层的find函数则是会接收一个键,然后利用二叉搜索树左小右大的性质,来遍历二叉树,看是否有该键值的节点存在,如果找到,就返回指向该节点的迭代器,如果没找到就返回end(),其中find函数也支持const版本和非const版本
cpp
iterator find(const key& k)
{
KeyofT returnKey;
Node* cur = root;
while (cur)
{
if (k < returnKey(cur->data))
{
cur = cur->left;
}
else if (k > returnKey(cur->data))
{
cur = cur->right;
}
else
{
return iterator(cur);
}
}
return end();
}
const_iterator find(const key& k) const
{
KeyofT returnKey;
Node* cur = root;
while (cur)
{
if (k < returnKey(cur->data))
{
cur = cur->left;
}
else if (k > returnKey(cur->data))
{
cur = cur->right;
}
else
{
return const_iterator(cur);
}
}
return end();
}那么对于上层来说,直接复用即可
cpp
iterator find(const key& k)
{
return tree.find(k);
}
const_iterator find(const key& k) const
{
return tree.find(k);
}\[\]运算符重载函数
那么对于map来说,这里还需要额外定义一个\[\]运算符重载函数,因为这里map支持用\[\]访问红黑树中特定键值的节点,并且可以修改其key对应的值,那么这里\[\]运算符重载函数的返回值就是指向元组的第二个元素的引用,那么其实现原理,就是利用insert函数的特性
因为\[\]运算符重载函数的行为就是如果该键存在,那么可以修改该键对应的值,如果不存在,相当于新插入了该键对应的节点,只不过其对应的值设置为默认值,这个行为正符合insert函数的特性,因为insert函数如果发现红黑树中已经有该键的节点存在,那么会返回一个元组,其中元组的first就是指向已存在节点的迭代器,不存在就插入,并且返回一个元组,其中元组的first就是指向新插入节点的迭代器
cpp
val& operator[](const key& k)
{
auto p = tree.insert(std::make_pair(k, val()));
return p.first->second;
}源码
myset.h:
cpp
#pragma once
#include"RBTree.h"
namespace wz
{
template<typename key>
class set
{
private:
class KeyofSetT
{
public:
const key& operator()(const key& p)
{
return p;
}
};
my_std::RBTree<key, key, KeyofSetT> tree;
public:
typedef typename my_std::RBTree<key, key, KeyofSetT>::const_iterator iterator;
typedef typename my_std::RBTree<key, key, KeyofSetT>::const_iterator const_iterator;
std::pair<iterator, bool> insert(const key& p)
{
return tree.insert(p);
}
iterator find(const key& k)
{
return iterator(tree.find(k));
}
const_iterator find(const key& k) const
{
return tree.find(k);
}
const_iterator begin() const
{
return tree.begin();
}
const_iterator end() const
{
return tree.end();
}
};
}mymap.h:
c
#pragma once
#include"RBTree.h"
namespace wz
{
template<typename key, typename val>
class map
{
private:
class KeyofMapT
{
public:
const key& operator()(const std::pair<const key, val>& p)
{
return p.first;
}
};
my_std::RBTree<key, std::pair<const key, val>, KeyofMapT> tree;
public:
typedef typename my_std::RBTree<key, std::pair<const key, val>, KeyofMapT>::iterator iterator;
typedef typename my_std::RBTree<key, std::pair<const key, val>, KeyofMapT>::const_iterator const_iterator;
std::pair<iterator, bool> insert(const std::pair<const key, val>& p)
{
return tree.insert(p);
}
iterator find(const key& k)
{
return tree.find(k);
}
const_iterator find(const key& k) const
{
return tree.find(k);
}
iterator begin()
{
return tree.begin();
}
const_iterator begin() const
{
return tree.begin();
}
iterator end()
{
return tree.end();
}
const_iterator end() const
{
return tree.end();
}
val& operator[](const key& k)
{
auto p = tree.insert(std::make_pair(k, val()));
return p.first->second;
}
};
}RBTree.h
cpp
#pragma once
namespace my_std {
enum color
{
BLACK,
RED
};
template<typename T>
class RBTreeNode
{
public:
RBTreeNode<T>* left;
RBTreeNode<T>* right;
RBTreeNode<T>* parent;
T data;
color _col;
RBTreeNode()
:_col(RED)
, left(nullptr)
, right(nullptr)
, parent(nullptr)
, data(T())
{
}
RBTreeNode(const T& p)
:_col(RED)
, left(nullptr)
, right(nullptr)
, parent(nullptr)
, data(p)
{
}
};
template<typename T, typename ptr, typename ref>
class RBTree_iterator
{
private:
typedef RBTreeNode<T> Node;
typedef RBTree_iterator<T, ptr, ref> self;
typedef RBTree_iterator<T, T*, T&> iterator;
Node* _Node;
public:
RBTree_iterator()
:_Node(nullptr)
{
}
RBTree_iterator(Node* ptr)
:_Node(ptr)
{
}
RBTree_iterator(const iterator& p)
:_Node(p.getNode())
{
}
Node* getNode() const
{
return _Node;
}
ref operator*()
{
return _Node->data;
}
ref operator*() const
{
return _Node->data;
}
ptr operator->()
{
return &_Node->data;
}
ptr operator->() const
{
return &_Node->data;
}
self& operator++()
{
if (_Node == nullptr)
{
return *this;
}
if (_Node->right)
{
Node* cur = _Node->right;
while (cur->left)
{
cur = cur->left;
}
_Node = cur;
}
else
{
Node* cur = _Node;
Node* parent = cur->parent;
while (parent && cur == parent->right)
{
cur = parent;
parent = cur->parent;
}
_Node = parent;
}
return *this;
}
self& operator--()
{
if (_Node == nullptr)
{
return *this;
}
if (_Node->left)
{
Node* cur = _Node->left;
while (cur->right)
{
cur = cur->right;
}
_Node = cur;
}
else
{
Node* cur = _Node;
Node* parent = cur->parent;
while (parent && cur == parent->left)
{
cur = parent;
parent = cur->parent;
}
_Node = parent;
}
return *this;
}
bool operator==(const self& it) const
{
return _Node == it._Node;
}
bool operator!= (const self& it) const
{
return _Node != it._Node;
}
};
template<typename key, typename T, typename KeyofT>
class RBTree
{
private:
typedef RBTreeNode<T> Node;
Node* root;
void RotationL(Node* parent)
{
Node* cur = parent->right;
Node* curleft = cur->left;
Node* pparent = parent->parent;
parent->parent = cur;
parent->right = curleft;
cur->parent = pparent;
cur->left = parent;
if (curleft)
curleft->parent = parent;
if (pparent)
{
if (pparent->left == parent)
{
pparent->left = cur;
}
else
{
pparent->right = cur;
}
}
else
{
root = cur;
}
}
void RotationR(Node* parent)
{
Node* cur = parent->left;
Node* curright = cur->right;
Node* pparent = parent->parent;
parent->parent = cur;
parent->left = curright;
cur->right = parent;
if (curright)
curright->parent = parent;
cur->parent = pparent;
if (pparent)
{
if (pparent->left == parent)
{
pparent->left = cur;
}
else
{
pparent->right = cur;
}
}
else
{
root = cur;
}
}
void copy(Node*& parent1, Node* const& parent2)
{
if (parent2 == nullptr)
{
parent1 = nullptr;
return;
}
parent1 = new Node(parent2->data);
parent1->_col = parent2->_col;
copy(parent1->left, parent2->left);
copy(parent1->right, parent2->right);
if (parent1->left)
{
parent1->left->parent = parent1;
}
if (parent1->right)
{
parent1->right->parent = parent1;
}
}
void destroyTree(Node* parent)
{
if (parent == nullptr)
{
return;
}
destroyTree(parent->left);
destroyTree(parent->right);
delete parent;
}
bool checkBlacknum(Node* parent, int num, int basic)
{
if (parent == nullptr)
{
if (num != basic)
{
return false;
}
return true;
}
if (parent->_col == BLACK)
{
num++;
}
return checkBlacknum(parent->left, num, basic) && checkBlacknum(parent->right, num, basic);
}
bool checkRed(Node* parent)
{
if (parent == nullptr)
{
return true;
}
if (parent == root && parent->_col != BLACK)
{
return false;
}
if (parent->_col == RED && parent->parent->_col == RED)
{
return false;
}
return checkRed(parent->left) && checkRed(parent->right);
}
bool isbalanced(Node* parent)
{
if (parent == nullptr)
{
return true;
}
if (parent == root && parent->_col != BLACK)
{
return false;
}
int basic = 0;
Node* cur = parent;
while (cur)
{
if (cur->_col == BLACK)
{
basic++;
}
cur = cur->left;
}
if (checkBlacknum(parent, 0, basic) == false)
{
return false;
}
if (checkRed(parent) == false)
{
return false;
}
return isbalanced(parent->left) && isbalanced(parent->right);
}
public:
typedef RBTree_iterator<T, T*, T&> iterator;
typedef RBTree_iterator<T, const T*, const T&> const_iterator;
RBTree()
:root(nullptr)
{
}
RBTree(const T& p)
:root(new Node(p))
{
root->_col = BLACK;
}
RBTree(const RBTree<key, T, KeyofT>& p)
{
copy(root, p.root);
}
~RBTree()
{
destroyTree(root);
}
std::pair<iterator, bool> insert(const T& p)
{
if (root == nullptr)
{
root = new Node(p);
root->_col = BLACK;
return std::make_pair(iterator(root), true);
}
Node* cur = root;
Node* parent = nullptr;
KeyofT returnKey;
while (cur)
{
if (returnKey(p) < returnKey(cur->data))
{
parent = cur;
cur = cur->left;
}
else if (returnKey(p) > returnKey(cur->data))
{
parent = cur;
cur = cur->right;
}
else
{
return std::make_pair(iterator(cur), false);
}
}
cur = new Node(p);
Node* newnode = cur;
if (returnKey(p) < returnKey(parent->data))
{
parent->left = cur;
cur->parent = parent;
}
else
{
parent->right = cur;
cur->parent = parent;
}
while (parent && parent->_col == RED)
{
Node* grandfather = parent->parent;
if (parent == grandfather->left)
{
Node* uncle = grandfather->right;
if (uncle && uncle->_col == RED)
{
parent->_col = BLACK;
uncle->_col = BLACK;
grandfather->_col = RED;
cur = grandfather;
parent = cur->parent;
}
else
{
if (cur == parent->left)
{
RotationR(grandfather);
grandfather->_col = RED;
parent->_col = BLACK;
break;
}
else
{
RotationL(parent);
RotationR(grandfather);
grandfather->_col = RED;
cur->_col = BLACK;
break;
}
}
}
else
{
Node* uncle = grandfather->left;
if (uncle && uncle->_col == RED)
{
parent->_col = BLACK;
uncle->_col = BLACK;
grandfather->_col = RED;
cur = grandfather;
parent = cur->parent;
}
else
{
if (cur == parent->right)
{
RotationL(grandfather);
grandfather->_col = RED;
parent->_col = BLACK;
break;
}
else
{
RotationR(parent);
RotationL(grandfather);
grandfather->_col = RED;
cur->_col = BLACK;
break;
}
}
}
}
root->_col = BLACK;
return std::make_pair(iterator(newnode), true);
}
iterator begin()
{
if (root == nullptr)
{
return end();
}
Node* cur = root;
while (cur->left)
{
cur = cur->left;
}
return iterator(cur);
}
const_iterator begin() const
{
if (root == nullptr)
{
return end();
}
Node* cur = root;
while (cur->left)
{
cur = cur->left;
}
return const_iterator(cur);
}
iterator end()
{
return iterator(nullptr);
}
const_iterator end() const
{
return const_iterator(nullptr);
}
iterator find(const key& k)
{
KeyofT returnKey;
Node* cur = root;
while (cur)
{
if (k < returnKey(cur->data))
{
cur = cur->left;
}
else if (k > returnKey(cur->data))
{
cur = cur->right;
}
else
{
return iterator(cur);
}
}
return end();
}
const_iterator find(const key& k) const
{
KeyofT returnKey;
Node* cur = root;
while (cur)
{
if (k < returnKey(cur->data))
{
cur = cur->left;
}
else if (k > returnKey(cur->data))
{
cur = cur->right;
}
else
{
return const_iterator(cur);
}
}
return end();
}
bool Isbalanced()
{
return isbalanced(root);
}
};
}main.cpp:
cpp
#include <iostream>
#include <string>
#include <vector>
#include <cassert>
#include "mymap.h"
#include "myset.h"
void test_map() {
std::cout << "===== Testing map =====" << std::endl;
wz::map<std::string, int> wordCount;
// 测试空map
assert(wordCount.begin() == wordCount.end());
std::cout << "Empty map test passed." << std::endl;
// 测试插入
auto result1 = wordCount.insert(std::make_pair("apple", 5));
assert(result1.second == true); // 插入成功
assert(result1.first != wordCount.end());
auto result2 = wordCount.insert(std::make_pair("banana", 3));
assert(result2.second == true);
auto result3 = wordCount.insert(std::make_pair("apple", 10)); // 重复插入
assert(result3.second == false); // 插入失败
assert(result3.first->second == 5); // 值未改变
std::cout << "Insert test passed." << std::endl;
// 测试遍历和顺序
std::vector<std::string> keys;
for (auto it = wordCount.begin(); it != wordCount.end(); ++it) {
keys.push_back(it->first);
}
assert(keys.size() == 2);
assert(keys[0] == "apple");
assert(keys[1] == "banana");
std::cout << "Traversal test passed." << std::endl;
// 测试operator[]
wordCount["orange"] = 8; // 新键
wordCount["apple"] = 7;
assert(wordCount["apple"] == 7);
assert(wordCount["banana"] == 3);
assert(wordCount["orange"] == 8);
assert(wordCount["grape"] == 0); // 自动创建
std::cout << "Operator[] test passed." << std::endl;
// 测试查找
auto it1 = wordCount.find("apple");
assert(it1 != wordCount.end());
assert(it1->second == 7);
auto it2 = wordCount.find("mango");
assert(it2 == wordCount.end());
std::cout << "Find test passed." << std::endl;
// 测试const map
const auto& constMap = wordCount;
auto cit = constMap.find("banana");
assert(cit != constMap.end());
assert(cit->second == 3);
// 测试const迭代器遍历
int count = 0;
for (auto it = constMap.begin(); it != constMap.end(); ++it) {
count++;
}
assert(count == 4); // apple, banana, orange, grape
std::cout << "Const map test passed." << std::endl;
// 测试大量数据
wz::map<int, std::string> numberMap;
for (int i = 0; i < 1000; i++) {
numberMap[i] = "Number " + std::to_string(i);
}
// 验证顺序
int prev = -1;
for (const auto& kv : numberMap) {
assert(kv.first > prev);
prev = kv.first;
}
assert(prev == 999);
std::cout << "Large data test passed." << std::endl;
std::cout << "All map tests passed!\n" << std::endl;
}
void test_set() {
std::cout << "===== Testing set =====" << std::endl;
wz::set<int> numbers;
// 测试空set
assert(numbers.begin() == numbers.end());
std::cout << "Empty set test passed." << std::endl;
// 测试插入
auto result1 = numbers.insert(5);
assert(result1.second == true);
auto result2 = numbers.insert(10);
assert(result2.second == true);
auto result3 = numbers.insert(5); // 重复插入
assert(result3.second == false);
std::cout << "Insert test passed." << std::endl;
// 测试遍历和顺序
std::vector<int> values;
for (auto it = numbers.begin(); it != numbers.end(); ++it) {
values.push_back(*it);
}
assert(values.size() == 2);
assert(values[0] == 5);
assert(values[1] == 10);
std::cout << "Traversal test passed." << std::endl;
// 测试查找
auto it1 = numbers.find(5);
assert(it1 != numbers.end());
assert(*it1 == 5);
auto it2 = numbers.find(15);
assert(it2 == numbers.end());
std::cout << "Find test passed." << std::endl;
// 测试const set
const auto& constSet = numbers;
auto cit = constSet.find(10);
assert(cit != constSet.end());
assert(*cit == 10);
// 测试const迭代器遍历
int count = 0;
for (auto it = constSet.begin(); it != constSet.end(); ++it) {
count++;
}
assert(count == 2);
std::cout << "Const set test passed." << std::endl;
// 测试大量数据
wz::set<int> largeSet;
for (int i = 0; i < 1000; i++) {
largeSet.insert(i);
}
// 验证顺序
int prev = -1;
for (int num : largeSet) {
assert(num > prev);
prev = num;
}
assert(prev == 999);
// 验证所有值都存在
for (int i = 0; i < 1000; i++) {
assert(largeSet.find(i) != largeSet.end());
}
assert(largeSet.find(1000) == largeSet.end());
std::cout << "Large data test passed." << std::endl;
std::cout << "All set tests passed!\n" << std::endl;
}
void test_edge_cases() {
std::cout << "===== Testing edge cases =====" << std::endl;
// 测试空容器的迭代器
wz::map<std::string, int> emptyMap;
for (auto it = emptyMap.begin(); it != emptyMap.end(); ++it) {
assert(false); // 不应该执行到这里
}
wz::set<int> emptySet;
for (auto it = emptySet.begin(); it != emptySet.end(); ++it) {
assert(false); // 不应该执行到这里
}
std::cout << "Empty container iteration test passed." << std::endl;
// 测试字符串键
wz::map<std::string, std::string> stringMap;
stringMap["hello"] = "world";
stringMap["foo"] = "bar";
stringMap["abc"] = "def";
std::vector<std::string> keys;
for (const auto& kv : stringMap) {
keys.push_back(kv.first);
}
assert(keys.size() == 3);
assert(keys[0] == "abc");
assert(keys[1] == "foo");
assert(keys[2] == "hello");
std::cout << "String key test passed." << std::endl;
}
int main() {
test_map();
test_set();
test_edge_cases();
std::cout << "All tests passed!" << std::endl;
return 0;
}运行截图:
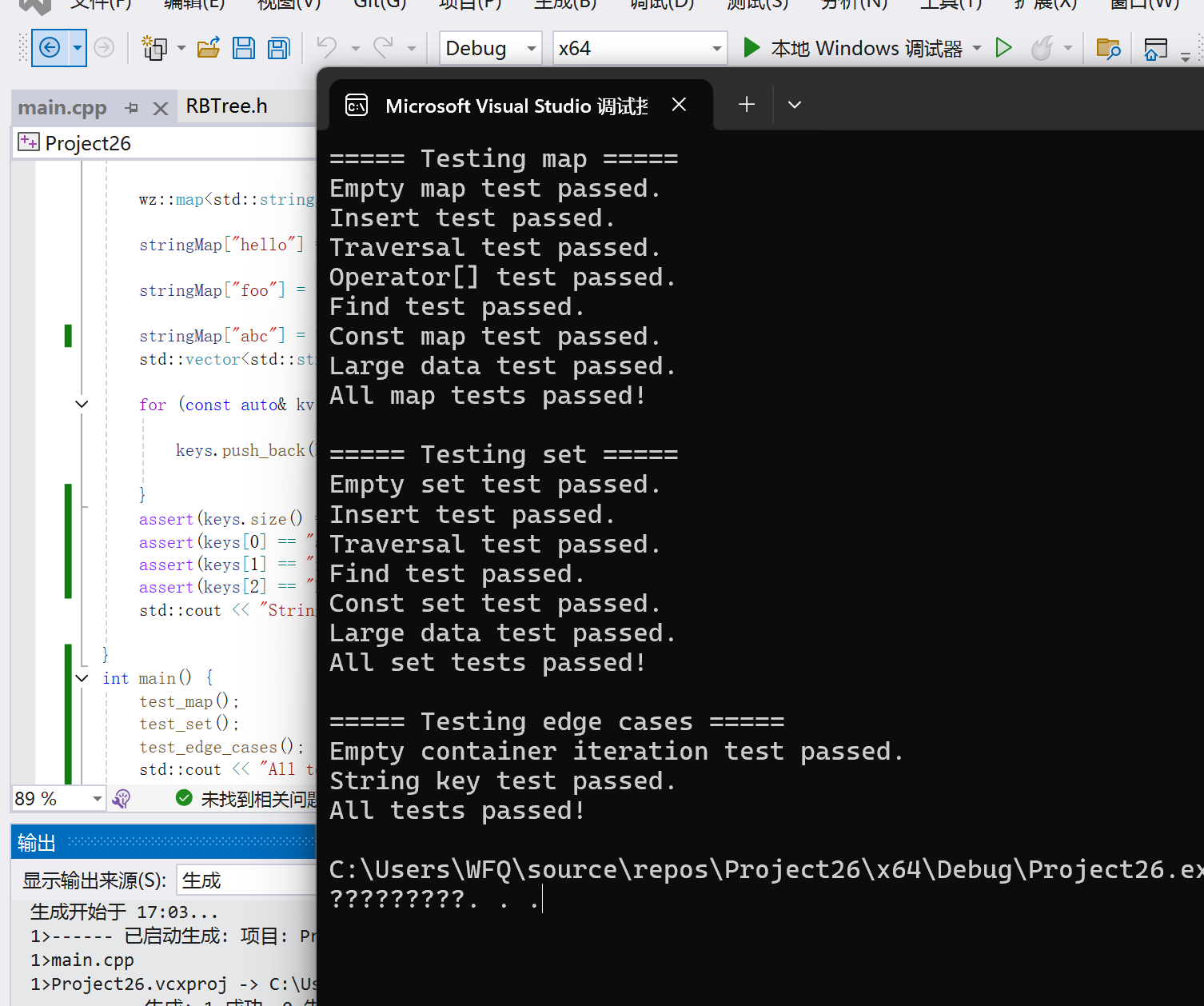
结语
那么这就是本文关于map和set的模拟实现的全部内容,那么下一期博客我会介绍unordered_map,我会持续更新,希望你能够多多关注,如果本文有帮助到你的话,还请三连加关注哦,你的支持就是我创作的最大的动力!
