摘要
本文深入探讨了现代人工智能开发全链路中的核心工具集,包括智能编码工具(以GitHub Copilot为代表)、数据标注平台和模型训练基础设施。通过详细的代码示例、流程图解、Prompt工程技巧、性能对比图表和应用场景分析,系统性地阐述了这些工具的技术原理、最佳实践和未来趋势。本文旨在为开发者、数据科学家和AI从业者提供一份全面的技术参考指南,以期提升AI项目开发效率与质量。
1. 引言:AI开发的新范式
人工智能项目的开发生命周期通常包含几个关键阶段:问题定义与规划、数据收集与处理、模型选择与训练、部署与监控。传统的开发模式中,每个阶段都依赖高度专业化的手动工作,存在效率瓶颈和高昂的沟通成本。
新一代AI工具的出现正在从根本上改变这一范式。它们通过自动化和智能辅助,将开发者从重复性劳动中解放出来,让其能更专注于创造性和战略性的工作。智能编码工具将AI融入IDE,成为开发者的"副驾驶";数据标注工具利用模型预标注和智能辅助,将标注效率提升数倍;模型训练平台则通过自动化的资源管理和实验跟踪,让模型迭代速度呈指数级增长。
这些工具共同构成了现代AI开发的基石,本文将逐一深入剖析。
2. 智能编码工具:AI副驾驶革命
智能编码工具,通常被称为"AI配对程序员"或"代码补全工具",利用大型语言模型(LLM)来理解代码上下文,并提供代码建议、函数补全、注释生成甚至漏洞检测功能。
2.1 核心代表:GitHub Copilot
GitHub Copilot是由GitHub、OpenAI和Microsoft联合开发的AI编程助手。它基于OpenAI的Codex模型,在 billions of lines of public code 上进行了训练。
2.1.1 技术原理与架构
Copilot的架构可以简化为以下流程:
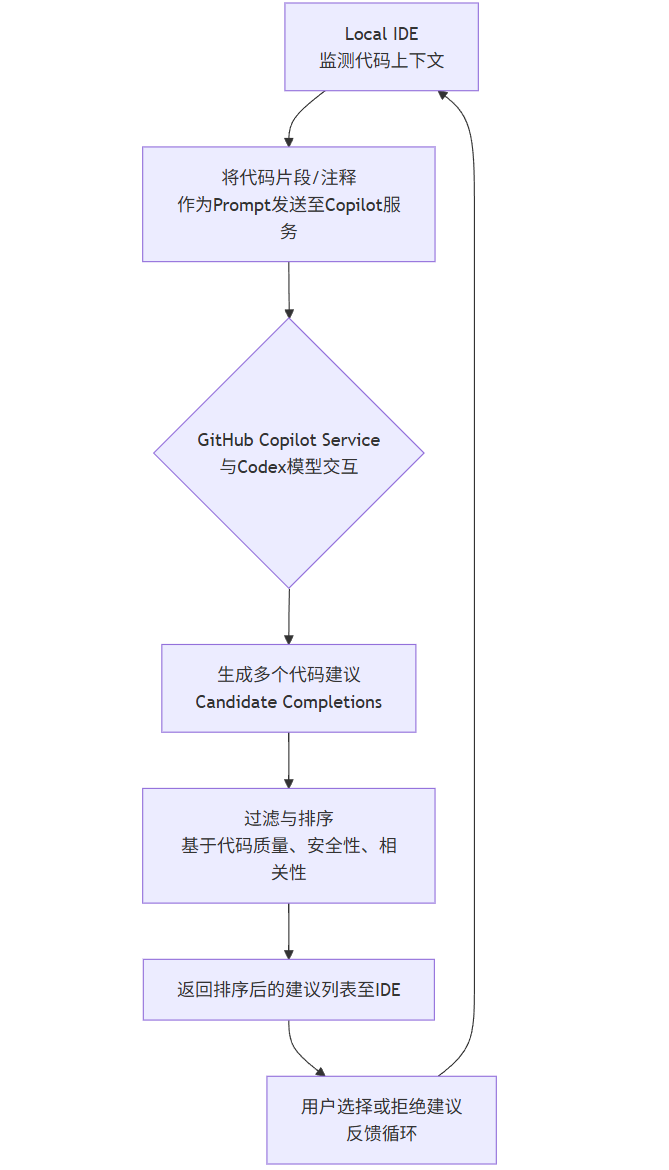
flowchart TD
A[Local IDE<br>监测代码上下文] --> B[将代码片段/注释<br>作为Prompt发送至Copilot服务]
B --> C{GitHub Copilot Service<br>与Codex模型交互}
C --> D[生成多个代码建议<br>Candidate Completions]
D --> E[过滤与排序<br>基于代码质量、安全性、相关性]
E --> F[返回排序后的建议列表至IDE]
F --> G[用户选择或拒绝建议<br>反馈循环]
G --> A2.1.2 代码示例与Prompt工程
Copilot的有效性高度依赖于用户提供的"Prompt",即代码上下文和注释。
示例1:从函数名和参数生成代码
当你开始输入一个函数定义时,Copilot会根据函数名和参数推断其意图。
python
# Prompt (你输入的代码)
def calculate_compound_interest(principal, rate, time, compounding_frequency):
"""
Calculate compound interest.
"""
# Copilot 自动补全的建议
return principal * (1 + rate / compounding_frequency) ** (compounding_frequency * time)
# 使用示例
result = calculate_compound_interest(1000, 0.05, 10, 12)
print(f"Compound interest is: ${result:.2f}")示例2:通过注释生成复杂函数
更详细的注释可以引导Copilot生成更复杂、更准确的代码。
python
# Prompt (你输入的代码)
# Import necessary libraries for data analysis and visualization
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load the customer data from a CSV file named 'customers.csv'
df = pd.read_csv('customers.csv')
# Create a function to plot the distribution of customer ages
# and overlay a kernel density estimate (KDE)
def plot_age_distribution(dataframe):
"""
Plots a histogram and KDE for the 'age' column in the dataframe.
Args:
dataframe (pd.DataFrame): The dataframe containing the 'age' column.
"""
# Copilot 根据注释和函数名生成的完整代码
plt.figure(figsize=(10, 6))
sns.histplot(data=dataframe, x='age', kde=True, bins=20, stat='density')
plt.title('Distribution of Customer Ages')
plt.xlabel('Age')
plt.ylabel('Density')
plt.show()
# Call the function
plot_age_distribution(df)示例3:跨文件上下文与测试生成
Copilot可以利用同一项目中的其他文件作为上下文。例如,如果你有一个 models.py 文件定义了 User 类,在 test_models.py 中,你只需输入:
python
# Prompt in test_models.py
from models import User
def test_user_creation():
# Copilot 可能会生成
user = User(name="John Doe", email="john@example.com")
assert user.name == "John Doe"
assert user.email == "john@example.com"
def test_user_save_to_database():
# Copilot 可能会生成
user = User(name="Jane Doe", email="jane@example.com")
user.save()
assert user.id is not None # Assuming save() assigns an ID2.2 最佳实践与局限性
-
最佳实践:
-
编写清晰的注释和函数名:这是最有效的Prompt工程。
-
迭代式提示:如果第一次建议不理想,可以进一步修改注释或代码结构,引导Copilot生成更好的版本。
-
代码审查:始终将Copilot视为助手,而非替代品。仔细审查生成的代码,确保其正确性和安全性。
-
-
局限性:
-
可能生成错误或过时的代码:模型基于训练数据,可能无法总是提供最佳或最新的实践。
-
安全风险:可能会建议使用不安全的函数或存在已知漏洞的代码模式。
-
版权模糊性:有极小的概率生成与训练数据中受版权保护代码非常相似的片段。
-
2.3 生态与其他工具
-
Amazon CodeWhisperer:AWS推出的类似工具,深度集成AWS服务,并提供源代码跟踪功能。
-
Tabnine:另一款强大的代码补全工具,支持完全本地化部署,注重代码隐私和安全。
-
CodiumAI / CodeT5+:更侧重于测试生成和代码分析。
3. 数据标注工具:模型燃料的加工厂
高质量的标注数据是监督学习模型的基石。数据标注通常占到一个AI项目70%以上的时间和成本。智能数据标注平台通过人机协作(Human-in-the-Loop, HITL)极大提升了效率。
3.1 核心功能与工作流程
一个现代化的数据标注平台(如LabelStudio、Scale AI、Supervisely、CVAT)通常包含以下功能:
-
支持多种数据类型(图像、文本、音频、视频)
-
提供丰富的标注工具( bounding box, polygon, segmentation, NER, classification)
-
项目管理与人员协作
-
智能辅助标注(基于预训练模型进行预标注)
-
质量控制和一致性检查
其工作流程如下图所示:

flowchart LR
A[Raw Data Ingestion] --> B[Project Setup &<br>Template Definition]
B --> C[Assignment &<br>Distribution to Annotators]
C --> D[Human Annotation<br>Manual Labeling]
D <--> E[AI-Assisted Labeling<br>Pre-labeling & Suggestions]
D --> F[Quality Assurance<br>Review & Adjudication]
F --> G{Meets Quality Standard?}
G -- No --> D
G -- Yes --> H[Export Labeled Dataset<br>COCO, YOLO, Pascal VOC, etc.]
H --> I[Model Training]
I --> J[New Model Version]
J -- Feedback Loop --> E3.2 智能辅助标注详解
这是提升效率的核心。平台会使用一个在类似数据上预训练好的模型(或用户自己上传的模型)对未标注的数据进行预标注。
-
图像示例:对于目标检测任务,用户上传1000张车辆图片。平台使用一个通用的COCO预训练模型(如YOLO或Faster R-CNN)先进行一轮推理,生成初步的 bounding box 和类别标签。标注员的工作从"从零开始画框"变为"修正和调整不准确的框",效率提升可达50%-70%。
-
文本示例(NER):对于命名实体识别任务,平台可以使用spaCy或BERT等模型预识别出文本中的"人名"、"地点"、"组织"等实体。标注员只需删除错误标签或添加遗漏的实体。
3.3 代码集成示例
大多数标注平台都提供丰富的API,允许将标注流水线集成到自动化脚本中。
示例:使用Label Studio Python SDK创建项目并导入数据
python
from label_studio_sdk import Client
import json
# 1. 连接到Label Studio服务器
LS_URL = "http://localhost:8080"
API_KEY = "your_api_key_here"
ls = Client(url=LS_URL, api_key=API_KEY)
ls.check_connection() # 检查连接是否成功
# 2. 创建一个新项目
project = ls.start_project(
title="Vehicle Detection Project - SDK Example",
label_config="""
<View>
<Image name="image" value="$image"/>
<RectangleLabels name="object" toName="image">
<Label value="Car" background="green"/>
<Label value="Truck" background="blue"/>
<Label value="Motorcycle" background="red"/>
</RectangleLabels>
</View>
"""
)
print(f"Project created with ID: {project.id}")
# 3. 导入任务(待标注的图片列表)
tasks = []
image_urls = [
"https://example.com/data/image1.jpg",
"https://example.com/data/image2.jpg",
# ... more image URLs
]
for img_url in image_urls:
tasks.append({"image": img_url})
# 分批导入任务
project.import_tasks(tasks)
print(f"Imported {len(tasks)} tasks into the project.")
# 4. (可选)连接机器学习后端进行预标注
# 需要先在LS后台设置好ML后端,此处获取其ID
ml_backends = project.get_ml_backends()
if ml_backends:
ml_backend_id = ml_backends[0]['id']
print(f"ML backend connected: {ml_backend_id}")3.4 平台对比
| 特性 | Label Studio (开源) | Scale AI (企业) | CVAT (开源) | Supervisely (企业) |
|---|---|---|---|---|
| 核心优势 | 灵活性高,支持多数据类型 | 高质量标注,全球标注员网络 | 强大的计算机视觉标注 | 端到端CV平台,自动化强 |
| 部署方式 | 云/本地 | 云API | 云/本地 | 云/本地 |
| 智能辅助 | 需自行集成模型 | 内置高质量模型 | 内置CV模型,Interpolation | 内置强大的CV自动化 |
| 成本 | 免费(开源版) | $$$ | 免费(开源版) | $$ |
| 最佳场景 | 研究、原型开发、定制化需求 | 大规模、生产级高质量数据 | 专业的计算机视觉团队 | 计算机视觉全流程项目 |
4. 模型训练平台:规模化机器学习的核心引擎
模型训练平台(如Google Vertex AI, Azure Machine Learning, Amazon SageMaker, Weights & Biases, Hugging Face Transformers)旨在简化和管理从数据到可部署模型的复杂过程。
4.1 核心功能与价值主张
-
自动化机器学习 (AutoML):允许用户只需提供数据,平台自动进行特征工程、模型选择、超参数调优和模型部署。极大降低了机器学习的门槛。
-
分布式训练:无缝支持跨多个GPU或多台机器的分布式训练,大幅缩短训练时间。
-
实验跟踪 (Experiment Tracking) :系统化地记录每一次训练的超参数 、代码版本 、评估指标 和产出模型,保证可复现性。
-
超参数优化 (HPO):使用贝叶斯优化等算法自动搜索最佳超参数组合。
-
模型管理与注册:对训练出的模型进行版本控制、元数据存储和阶段管理(如开发、测试、生产)。
-
协作:团队共享实验结果、数据和模型。
4.2 端到端工作流示例(以Google Vertex AI为例)
Vertex AI的工作流清晰地展示了现代MLOps平台的自动化能力:
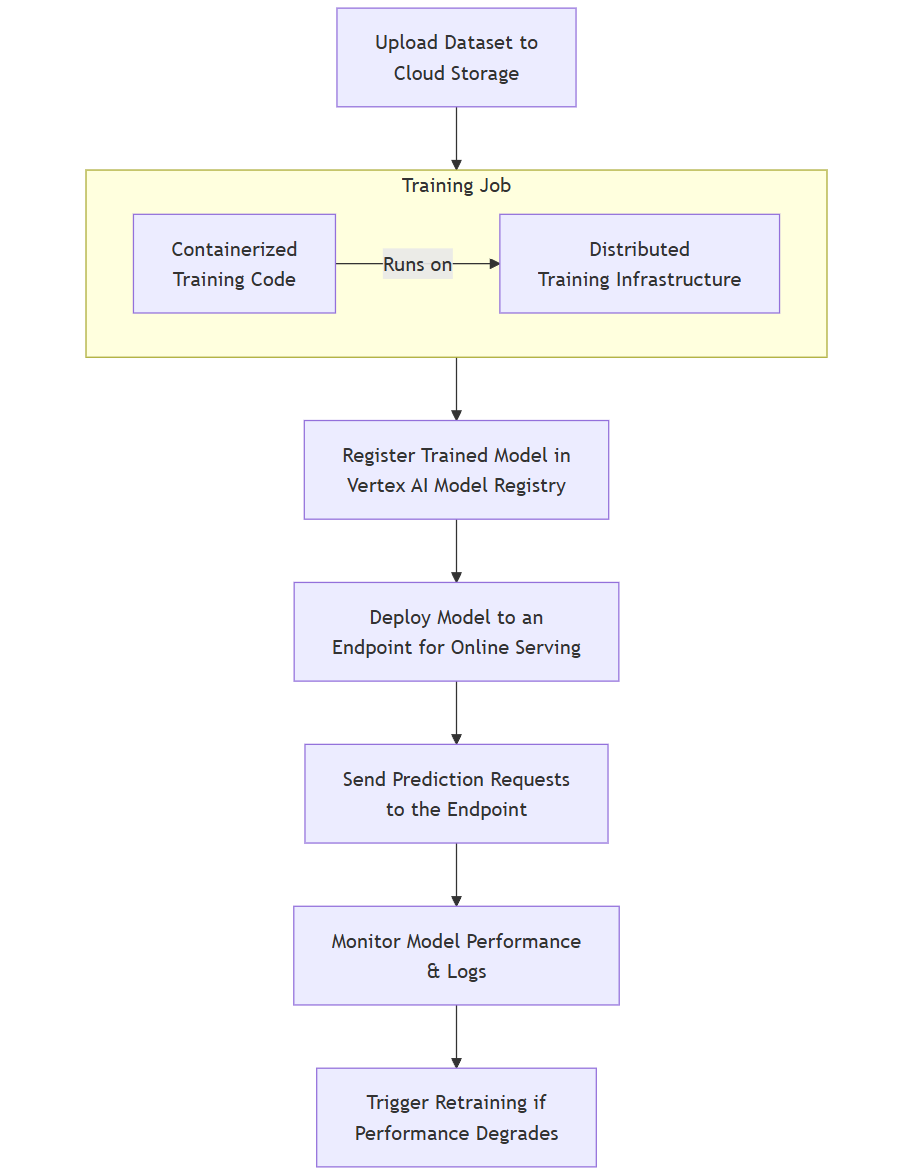
flowchart TD
A[Upload Dataset to<br>Cloud Storage] --> B[Create & Run a<br>Training Job]
subgraph B [Training Job]
direction LR
B1[Containerized<br>Training Code] -- Runs on --> B2[Distributed<br>Training Infrastructure]
end
B --> C[Register Trained Model in<br>Vertex AI Model Registry]
C --> D[Deploy Model to an<br>Endpoint for Online Serving]
D --> E[Send Prediction Requests<br>to the Endpoint]
E --> F[Monitor Model Performance<br>& Logs]
F --> G[Trigger Retraining if<br>Performance Degrades]4.3 代码集成与实践
以下示例展示如何使用Python SDK与平台交互,完成一个完整的训练与部署周期。
示例:使用Azure ML SDK训练并部署一个Scikit-learn模型
python
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment, Model, OnlineEndpoint, OnlineDeployment
from azure.ai.ml.constants import AssetTypes
# 1. 连接到Azure ML工作区
credential = DefaultAzureCredential()
ml_client = MLClient(credential, "<subscription-id>", "<resource-group-name>", "<workspace-name>")
# 2. 准备一个训练脚本 train.py
# 这个脚本会在云端执行,包含数据加载、训练和模型保存逻辑。
train_script = """
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import joblib
import os
# 输入数据路径由Azure ML通过参数传入
parser = argparse.ArgumentParser()
parser.add_argument('--training_data', type=str, dest='training_data', help='Path to training data')
args = parser.parse_args()
df = pd.read_csv(args.training_data)
X = df.drop('target', axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 保存模型到输出目录,Azure ML会自动捕获这个目录
os.makedirs('./outputs', exist_ok=True)
joblib.dump(clf, './outputs/model.joblib')
"""
# 将脚本写入文件
with open('train.py', 'w') as f:
f.write(train_script)
# 3. 配置并提交训练任务
env = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="scikit-learn-env.yaml" # 一个定义依赖项的环境文件
)
job = command(
code="./", # 当前目录,包含train.py
command="python train.py --training_data ${{inputs.training_data}}",
inputs={"training_data": Input(type=AssetTypes.URI_FILE, path="https://myaccount.blob.core.windows.net/mycontainer/mydata.csv")},
environment=env,
compute="cpu-cluster", # 指定计算集群名称
display_name="sklearn-rf-iris-training",
experiment_name="iris-classification-experiment",
outputs={"model": Output(type=AssetTypes.URI_FOLDER, mode="rw_mount", path="./outputs")}
)
# 提交作业
returned_job = ml_client.jobs.create_or_update(job)
ml_client.jobs.stream(returned_job.name) # 流式传输日志
# 4. 注册训练好的模型
run_model = Model(
path=f"azureml://jobs/{returned_job.name}/outputs/model",
name="iris-rf-model",
description="Random Forest model trained on Iris dataset.",
type=AssetTypes.CUSTOM_MODEL
)
ml_client.models.create_or_update(run_model)
# 5. 创建在线端点并部署模型
endpoint_name = "iris-endpoint"
endpoint = OnlineEndpoint(name=endpoint_name)
ml_client.online_endpoints.begin_create_or_update(endpoint).wait()
deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model="iris-rf-model",
environment=env,
instance_type="Standard_F2s_v2",
instance_count=1,
)
ml_client.online_deployments.begin_create_or_update(deployment).wait()
# 将流量切换到新部署
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).wait()
# 6. 测试在线预测
sample_request = {
"input_data": {
"columns": ["sepal_length", "sepal_width", "petal_length", "petal_width"],
"data": [[5.1, 3.5, 1.4, 0.2], [6.7, 3.0, 5.2, 2.3]]
}
}
response = ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_body=sample_request
)
print(f"Predictions: {response}")4.4 平台对比与选型建议
| 特性 | Google Vertex AI | Azure Machine Learning | Amazon SageMaker | Weights & Biases (W&B) |
|---|---|---|---|---|
| 核心优势 | 强大的AutoML和集成Google云服务 | 深度集成微软生态,企业级安全 | 全面的功能,成熟的AWS生态 | 极致的实验跟踪与协作体验 |
| AutoML | 非常强大,支持多种数据类型 | 强大 | 强大 | 无,专注于跟踪 |
| 实验跟踪 | 良好 | 良好(集成MLflow) | 良好(集成MLflow) | 业界标杆,极其强大 |
| 分布式训练 | 优秀(支持TPU) | 优秀 | 优秀 | 无,但可与任何训练平台集成 |
| 最佳场景 | 使用GCP,青睐AutoML的用户 | 使用Azure,企业级用户 | 使用AWS,需要全面控制的用户 | 任何环境下的研究和实验 |
选型建议:
-
优先考虑与现有云供应商一致的平台,以获得最佳集成度和可能的价格优惠。
-
如果团队极度依赖精细化的实验跟踪和协作,W&B几乎是必不可少的,它可以与任何训练基础设施(包括本地服务器)搭配使用。
-
Hugging Face生态系统对于NLP项目是事实上的标准,其
transformers、datasets和accelerate库极大地简化了训练流程。
5. 工具链整合与未来趋势
5.1 构建一体化AI开发流水线
最强大的力量来自于将这些工具整合成一个自动化的、端到端的MLOps流水线。
-
数据流水线 :数据标注平台生成的新数据集自动触发数据验证和版本控制流程(如使用
Great Expectations或TensorFlow Data Validation)。 -
训练流水线:新数据或代码提交自动触发模型重新训练或超参数搜索(使用Airflow, Kubeflow Pipelines,或云平台的Pipeline工具)。
-
部署流水线:通过CI/CD(如Jenkins, GitLab CI, GitHub Actions)自动测试新模型性能,若达标则自动部署到预生产或生产环境。
-
监控与反馈循环:线上模型的服务日志和性能监控数据(如预测偏差、数据漂移)被收集分析,一旦发现性能退化,自动触发重新标注或重新训练。
5.2 未来趋势
-
AI for AI (AI4AI):工具本身将变得更加智能。例如,Copilot未来可能不仅能补全代码,还能根据整个代码库的上下文建议更好的软件架构。
-
低代码/无代码机器学习 (Low-Code/No-Code ML):AutoML和可视化拖拽工具将使业务分析师等非专业程序员也能构建和部署简单的模型, democratizing AI。
-
生成式AI融入全流程:除了代码生成,生成式AI将用于生成合成训练数据、编写文档、生成测试用例、解释模型决策等。
-
更加注重责任型AI (Responsible AI):工具将内置更多关于模型公平性(Fairness)、可解释性(Explainability)、透明度(Transparency)和隐私(Privacy)的检查和缓解措施。
-
多模态统一平台:平台将不再局限于处理单一类型的数据,而是能够自然地处理和理解图像、文本、音频等多种信息的组合。
6. 结论
智能编码工具、数据标注平台和模型训练平台共同构成了现代AI应用开发的"铁三角"。它们分别从开发效率 、数据质量 和模型迭代速度三个核心维度,极大地推动了人工智能产业的工业化进程。
-
GitHub Copilot等工具将开发者从重复编码中解放出来,提高了创造流的状态占比。
-
智能数据标注平台通过人机协作,破解了高质量数据获取的成本和效率瓶颈,为模型提供了更优质的"燃料"。
-
模型训练平台通过自动化、规模化和系统化的管理,使得构建、试验和部署模型变得前所未有的高效和可靠。
对于任何严肃的AI团队或个人而言,熟练掌握并有效集成这些工具,不再是可选项,而是保持竞争力的必需品。未来的赢家,将是那些能够最好地利用人类智能(HI)和人工智能(AI)协同效应的团队。