一、概述
相较于基于强化学习的NAS,可微NAS能直接使用梯度下降更新模型结构超参数,其中较为有名的算法就是DARTS,其具体做法如下。
首先,用户需要定义一些**候选模块,**这些模块内部结构可以互不相同(如设置不同种类和数量的卷积,使用不同种类的连接结构等);其次,用户也需要指定神经网络的层数,每一层由候选模块的其中之一构成。
由于搜索空间 =(其中
为候选模块种类,
为预先指定的神经网络层数)巨大,为了从庞大的搜索空间中找到合适的结构,需要引入superNet。
二、SuperNet
2.1模型结构
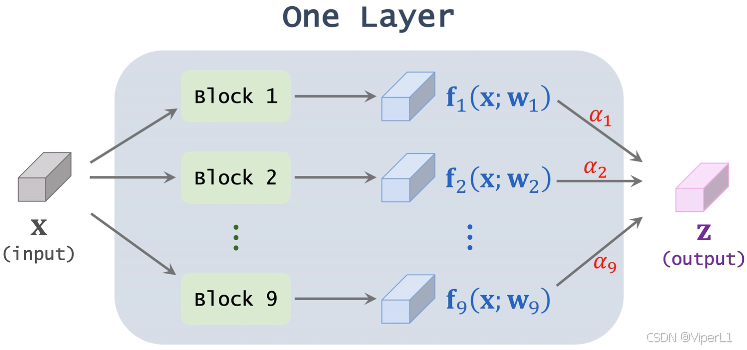
这里以SuperNet 中的某一层为例,设置候选模块一共9种,这层superNet由9种不同的模块并联而成。输入向量在候选模块处理后分别得到9个向量
,这个处理过程记作:
,其中
为模块中的权重。将这些向量
进行加权求和,这些权重记作
,所有
之和为1(由softmax计算得到),权重
就是模型要学习的神经网络结构超参数。
通过堆叠上述模块,组成一个完整的superNet,经过训练,每一层最终会保留一个模块。
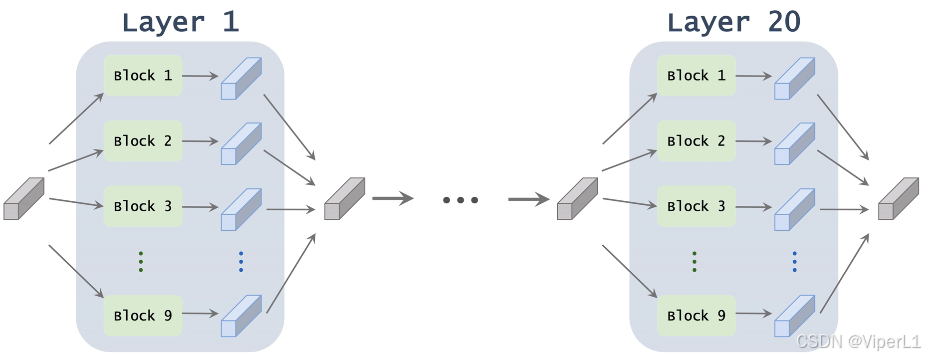
2.2训练
将superNet的候选模块一共9个,记作;设superNet一共20层,记作
;得第
层中第
个模块的参数记作
和
,故
,
,这两个即为需要训练并学习的参数。superNet做出的预测记作
。
交叉熵损失函数可以写作,在这个损失函数中,由于
是关于
的函数,且两者可微,故损失函数
能通过
传递给
,所以可以直接使用反向梯度传播更新模型。
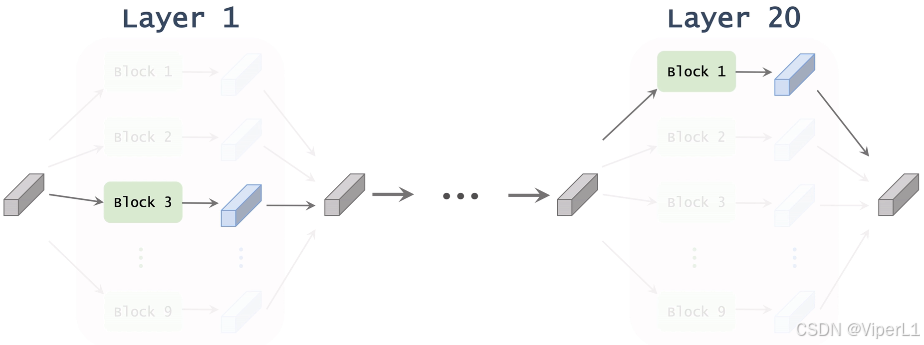
基于学习到的,我们可以计算出superNet中没一层中每个模块的权重
,对于每层而言,选取其中权重最大的模块作为该层的结构,这些模块串联即可得到整个模型的结构,如下图所示。
三、使用额外的性能指标优化superNet
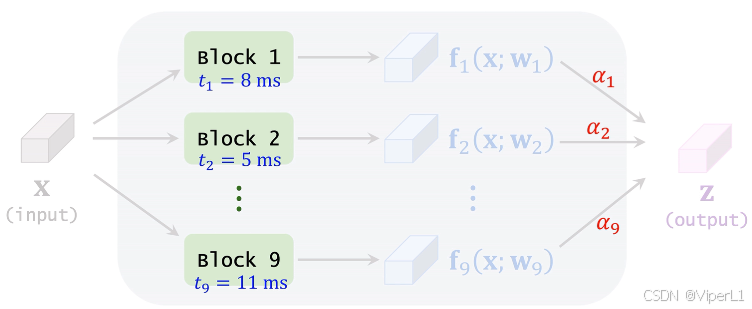
以应用于移动设备的轻量化神经网络举例,这类神经网络由于需要考虑移动设备的算力限制,往往需要延迟(latency,推理时间)越小越好。
可以事先测量每个候选模块的平均延迟,计算这一层中每个模块的延迟加权平均,如下图所示。
将20层网络中的延迟求和,得到:,其中
的定义在2.2节中已经给出,可以进一步记作
,其中的
为计算得到的常数。
损失函数为:,其中
可以决定牺牲多少准确率来换取计算速度。
另外也可以使用,作为损失函数,效果和上式相同。