💖💖作者:计算机编程小央姐
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持! 💜💜
💕💕文末获取源码
目录
食物营养数据可视化分析系统技术前沿解析-系统功能介绍
基于大数据的食物营养数据可视化分析系统是一个专门针对营养健康领域的综合性大数据分析平台,该系统采用Hadoop分布式存储架构和Spark大数据处理引擎作为核心技术支撑,通过Python和Java双语言开发环境,结合Django和Spring Boot后端框架,以及Vue+ElementUI+Echarts前端技术栈,构建了一个功能完善的营养数据分析生态系统。系统主要处理大规模食物营养数据集,运用HDFS进行分布式数据存储,利用Spark SQL和Pandas、NumPy等数据处理工具进行深度数据挖掘和统计分析,通过机器学习聚类算法发现食物营养模式,并通过多维度可视化图表展现分析结果。系统涵盖宏观营养格局分析、特定营养素排名筛选、食物分类对比分析、膳食健康风险评估以及基于算法的食物聚类探索等五大核心分析维度,为用户提供从基础营养统计到高级数据挖掘的全方位营养数据洞察服务,实现了大数据技术在营养健康领域的创新应用。
食物营养数据可视化分析系统技术前沿解析-系统技术介绍
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
食物营养数据可视化分析系统技术前沿解析-系统背景意义
随着现代生活节奏的加快和饮食结构的多样化,人们对食物营养成分的关注度日益提升,营养健康已成为影响生活质量的重要因素。传统的营养数据分析主要依赖人工统计和简单的表格处理,面对海量的食物营养数据时显得力不从心,无法有效挖掘数据背后的营养规律和关联性。现有的营养分析工具大多功能单一,缺乏系统性的多维度分析能力,难以满足用户对食物营养信息的深层次需求。大数据技术的快速发展为营养数据分析提供了新的技术路径,Hadoop和Spark等分布式计算框架能够高效处理大规模营养数据,机器学习算法可以发现隐藏在数据中的营养模式,数据可视化技术则能将复杂的分析结果以直观的形式呈现给用户。在这样的技术背景下,构建一个集数据存储、处理、分析、挖掘和可视化于一体的食物营养大数据分析系统具有重要的现实需求。
本课题的实际意义主要体现在技术实践和应用探索两个层面。从技术角度来看,该系统为大数据技术在营养健康领域的应用提供了一个具体的实践案例,展示了Hadoop分布式存储和Spark大数据处理技术在处理营养数据时的优势和可行性,为相关技术在健康医疗领域的推广应用积累了经验。从应用价值来看,系统通过多维度的营养数据分析,能够为普通用户提供科学的食物营养参考,帮助用户更好地了解不同食物的营养特点和健康价值,在一定程度上促进合理膳食搭配的形成。对于营养研究人员而言,系统提供的聚类分析和关联分析功能可以辅助发现食物营养的潜在规律,为营养科学研究提供数据支撑。虽然作为毕业设计项目,系统在功能完整性和数据规模上存在一定局限性,但其展现的技术架构设计思路和大数据处理流程对于类似项目的开发具有一定的参考价值,同时也为开发者积累了大数据项目开发的实践经验。
食物营养数据可视化分析系统技术前沿解析-系统演示视频
跟上大数据时代步伐:食物营养数据可视化分析系统技术前沿解析
食物营养数据可视化分析系统技术前沿解析-系统演示图片
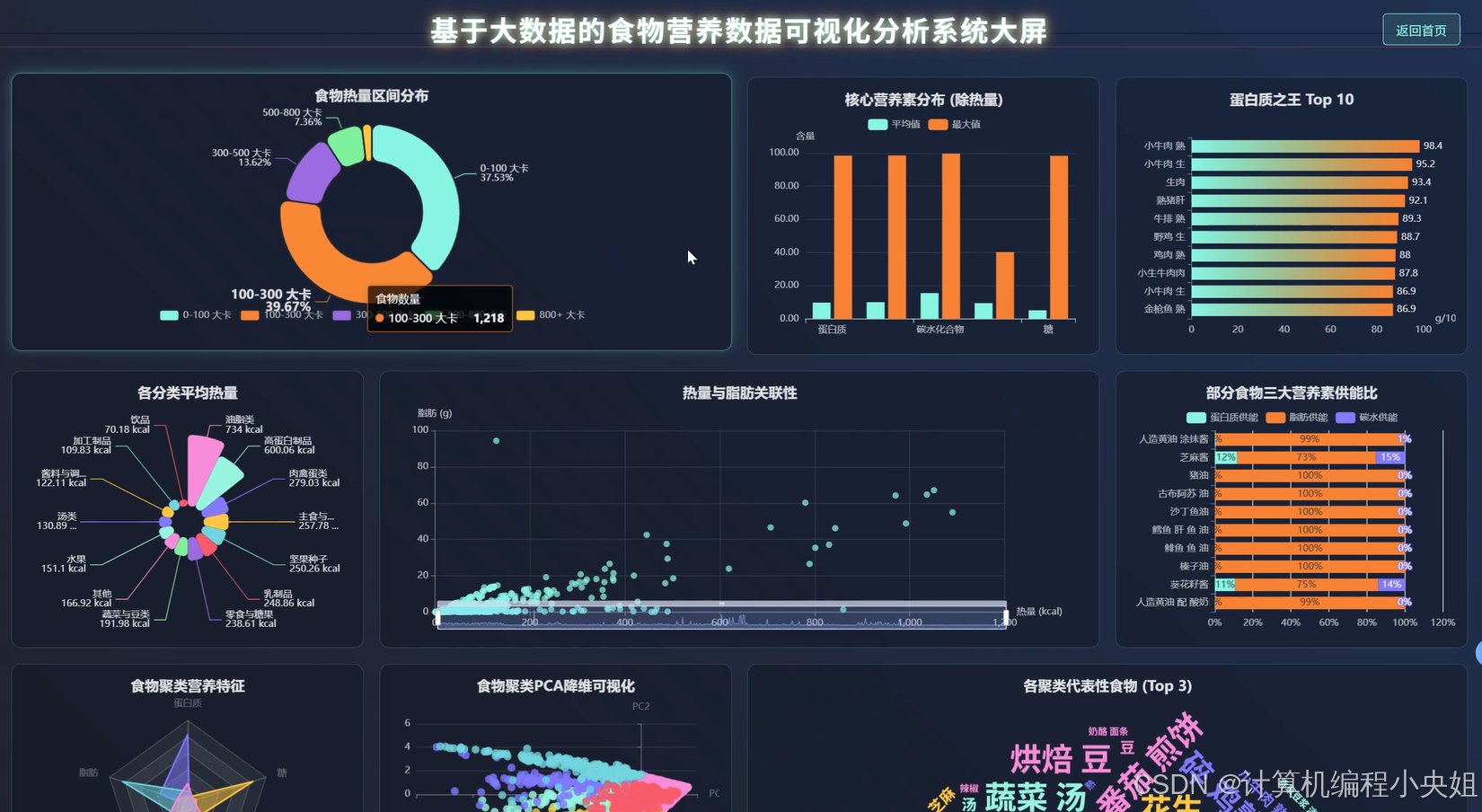
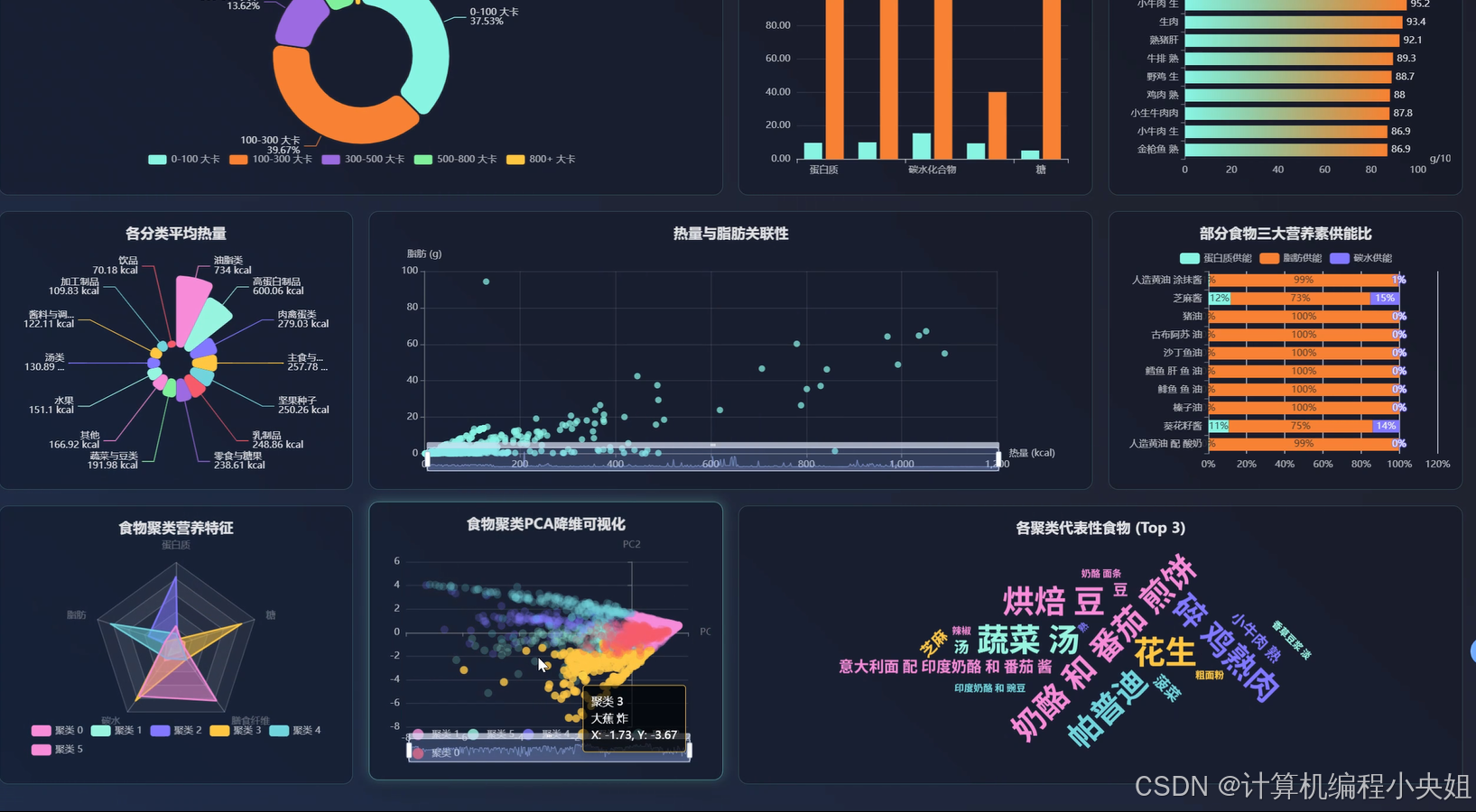
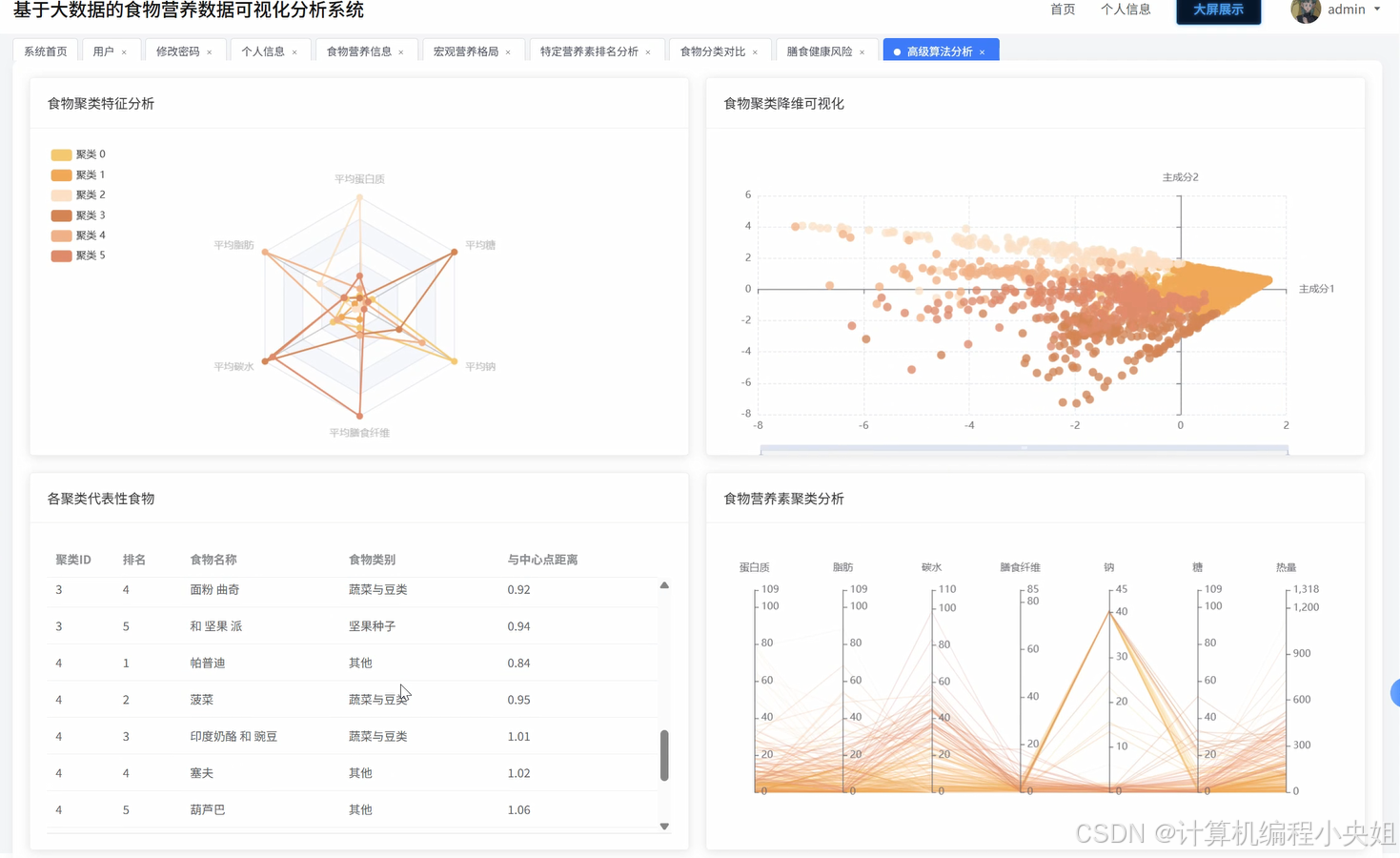
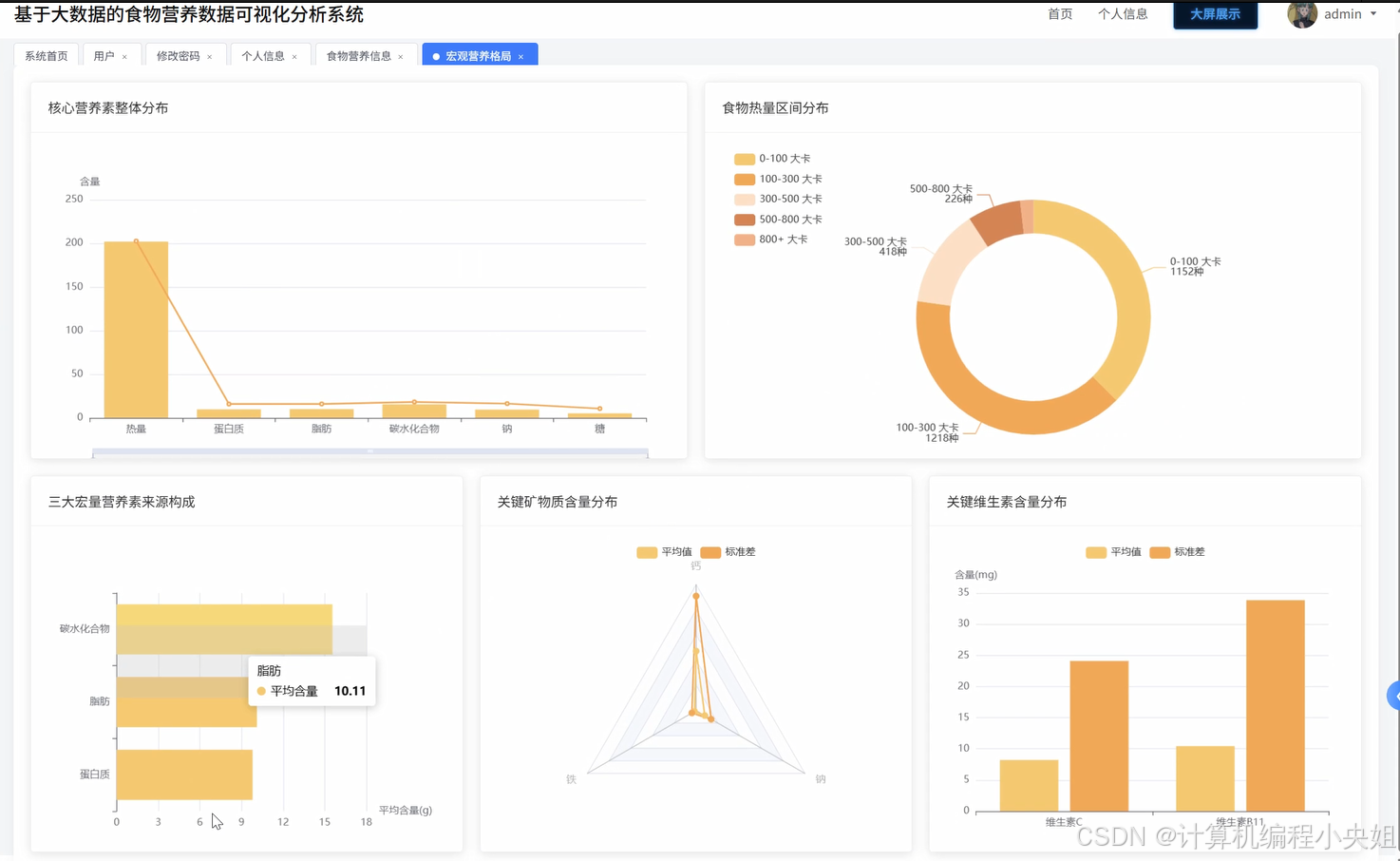
食物营养数据可视化分析系统技术前沿解析-系统部分代码
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, sum, count, desc, asc, when, round
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import pandas as pd
import numpy as np
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
import json
spark = SparkSession.builder.appName("FoodNutritionAnalysis").master("local[*]").config("spark.executor.memory", "2g").config("spark.driver.memory", "2g").getOrCreate()
@csrf_exempt
def nutrition_statistics_analysis(request):
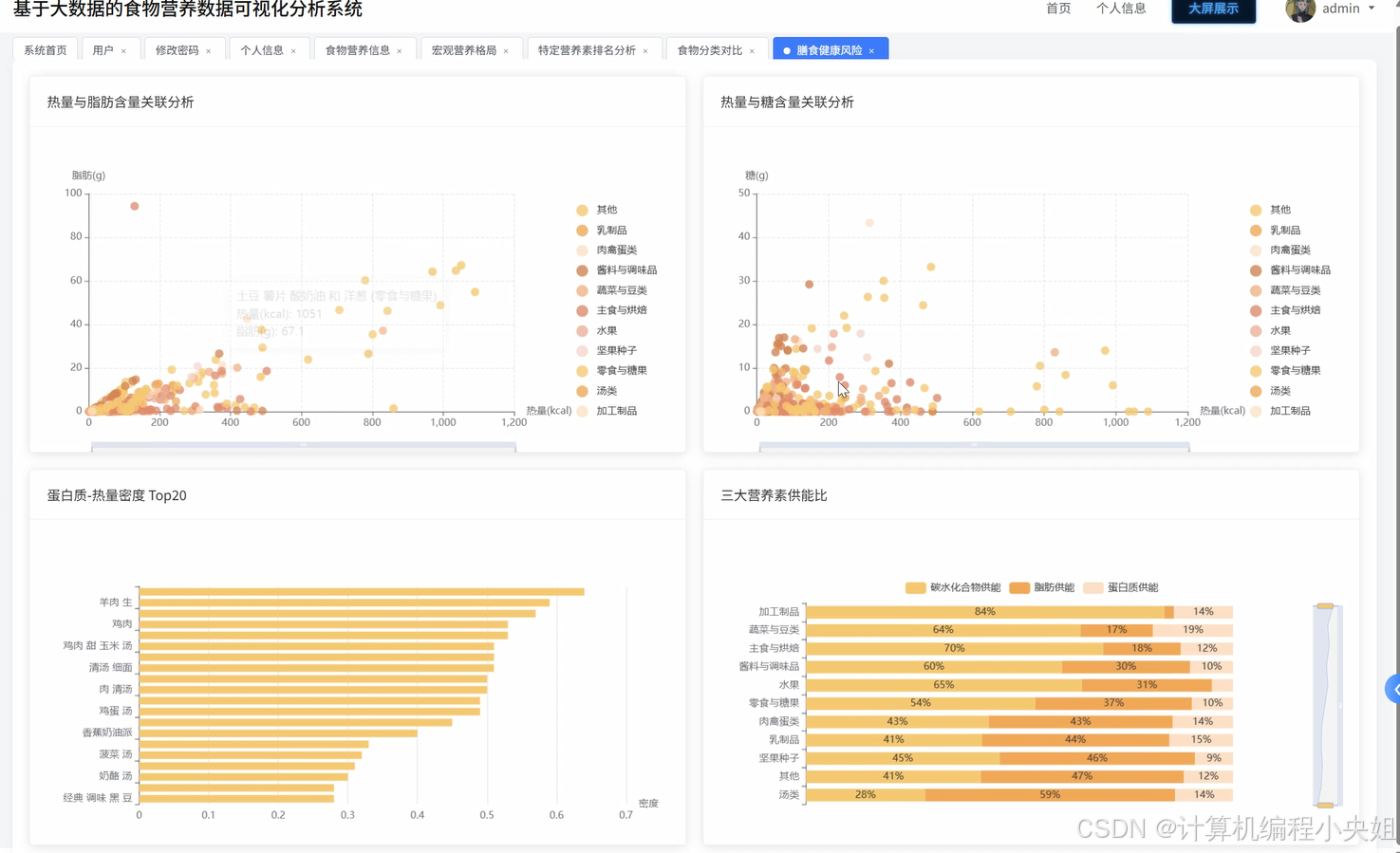
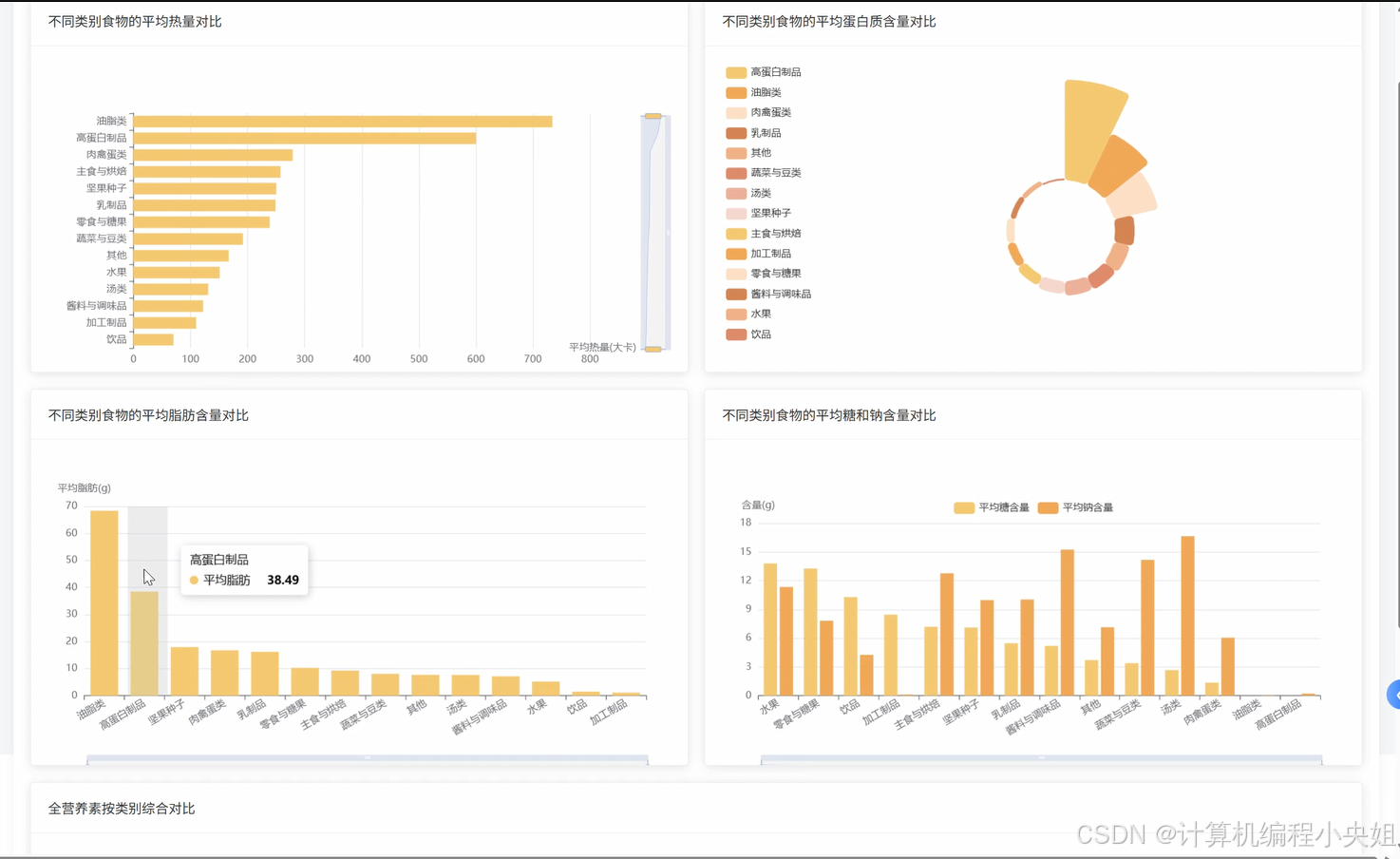
"""宏观营养格局分析 - 核心营养素整体分布统计"""
df = spark.read.option("header", "true").option("inferSchema", "true").csv("data/cleaned_nutrition_dataset_per100g.csv")
nutrition_stats = df.select(
avg("热量").alias("平均热量"),
avg("蛋白质").alias("平均蛋白质"),
avg("脂肪").alias("平均脂肪"),
avg("碳水化合物").alias("平均碳水化合物"),
avg("钠").alias("平均钠"),
avg("糖").alias("平均糖")
).collect()[0]
calorie_distribution = df.select(
sum(when(col("热量") <= 100, 1).otherwise(0)).alias("低热量_0_100"),
sum(when((col("热量") > 100) & (col("热量") <= 300), 1).otherwise(0)).alias("中热量_100_300"),
sum(when((col("热量") > 300) & (col("热量") <= 500), 1).otherwise(0)).alias("高热量_300_500"),
sum(when(col("热量") > 500, 1).otherwise(0)).alias("超高热量_500以上")
).collect()[0]
macro_composition = df.select(
(avg("蛋白质") * 4).alias("蛋白质供能"),
(avg("脂肪") * 9).alias("脂肪供能"),
(avg("碳水化合物") * 4).alias("碳水化合物供能")
).collect()[0]
total_energy = macro_composition["蛋白质供能"] + macro_composition["脂肪供能"] + macro_composition["碳水化合物供能"]
macro_ratios = {
"蛋白质供能比": round(macro_composition["蛋白质供能"] / total_energy * 100, 2),
"脂肪供能比": round(macro_composition["脂肪供能"] / total_energy * 100, 2),
"碳水化合物供能比": round(macro_composition["碳水化合物供能"] / total_energy * 100, 2)
}
mineral_stats = df.select(
avg("钙").alias("平均钙含量"),
avg("铁").alias("平均铁含量"),
avg("钠").alias("平均钠含量")
).collect()[0]
result_data = {
"营养素统计": dict(nutrition_stats.asDict()),
"热量分布": dict(calorie_distribution.asDict()),
"宏量营养素供能比": macro_ratios,
"矿物质统计": dict(mineral_stats.asDict())
}
return JsonResponse({"code": 200, "data": result_data})
@csrf_exempt
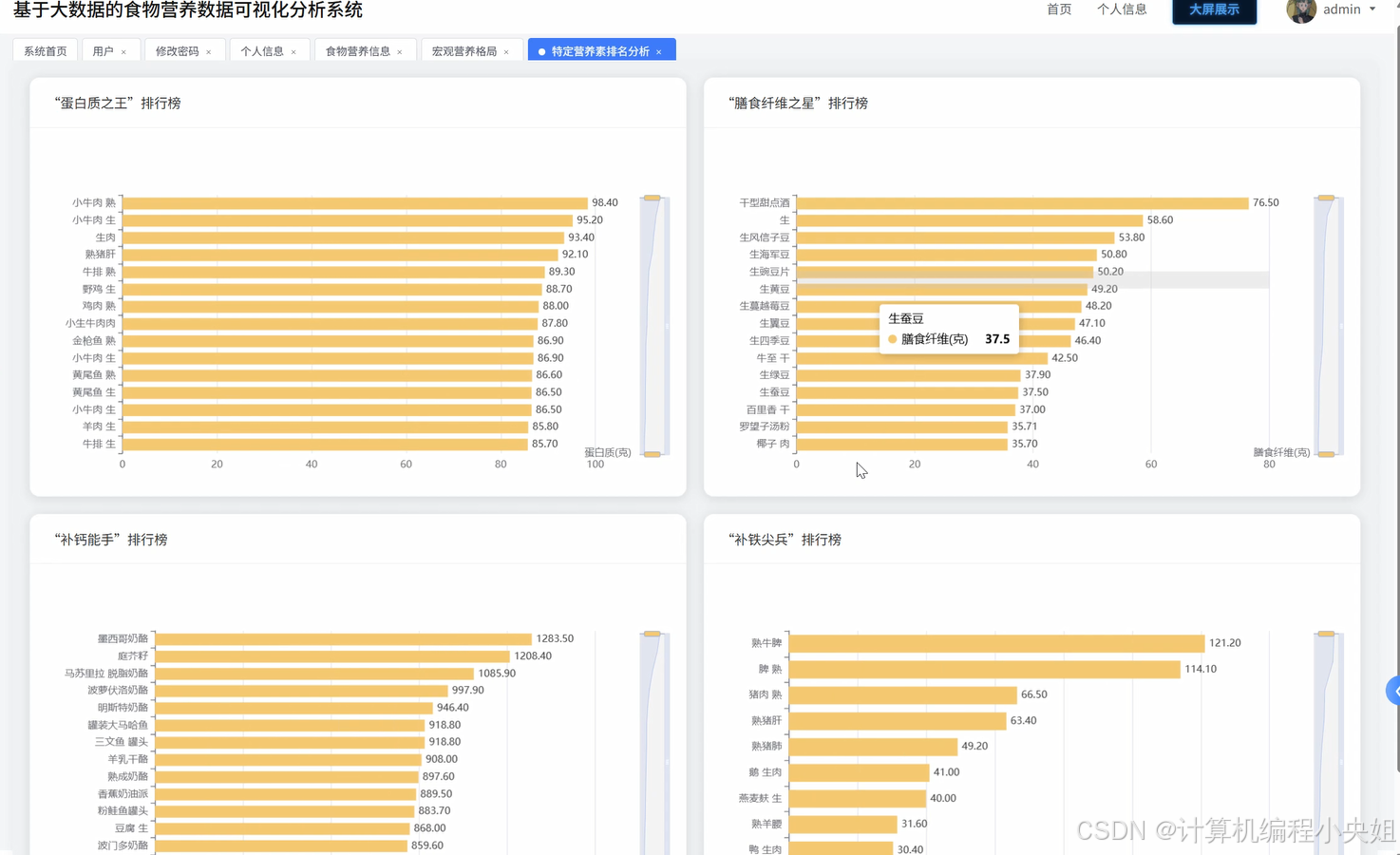
def nutrition_ranking_analysis(request):
"""特定营养素排名与筛选分析 - 各营养素排行榜"""
data = json.loads(request.body.decode('utf-8'))
nutrient_type = data.get('nutrient_type', '蛋白质')
top_count = data.get('top_count', 20)
df = spark.read.option("header", "true").option("inferSchema", "true").csv("data/cleaned_nutrition_dataset_per100g.csv")
df_filtered = df.filter(col(nutrient_type).isNotNull() & (col(nutrient_type) > 0))
if nutrient_type in ['热量', '钠']:
ranking_df = df_filtered.select("食物名称", nutrient_type).orderBy(asc(nutrient_type)).limit(top_count)
ranking_type = "最低"
else:
ranking_df = df_filtered.select("食物名称", nutrient_type).orderBy(desc(nutrient_type)).limit(top_count)
ranking_type = "最高"
ranking_list = []
for idx, row in enumerate(ranking_df.collect()):
ranking_list.append({
"排名": idx + 1,
"食物名称": row["食物名称"],
f"{nutrient_type}含量": round(row[nutrient_type], 2)
})
nutrient_avg = df_filtered.select(avg(nutrient_type).alias("平均值")).collect()[0]["平均值"]
nutrient_count = df_filtered.count()
percentile_values = df_filtered.select(nutrient_type).rdd.map(lambda x: x[0]).collect()
percentile_values.sort()
p25_idx = int(len(percentile_values) * 0.25)
p75_idx = int(len(percentile_values) * 0.75)
analysis_summary = {
"营养素类型": nutrient_type,
"排名类型": ranking_type,
"数据总量": nutrient_count,
"平均含量": round(nutrient_avg, 2),
"25分位数": round(percentile_values[p25_idx], 2),
"75分位数": round(percentile_values[p75_idx], 2)
}
return JsonResponse({
"code": 200,
"data": {
"排行榜": ranking_list,
"分析摘要": analysis_summary
}
})
@csrf_exempt
def food_clustering_analysis(request):
"""高级算法探索分析 - 基于主要营养素的食物聚类"""
df = spark.read.option("header", "true").option("inferSchema", "true").csv("data/cleaned_nutrition_dataset_per100g.csv")
feature_cols = ["蛋白质", "脂肪", "碳水化合物", "膳食纤维", "钠", "糖"]
df_clean = df.select("食物名称", *feature_cols).na.drop()
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
df_features = assembler.transform(df_clean)
scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures", withStd=True, withMean=True)
scaler_model = scaler.fit(df_features)
df_scaled = scaler_model.transform(df_features)
optimal_k = 5
silhouette_scores = []
for k in range(2, 8):
kmeans = KMeans(k=k, seed=42, featuresCol="scaledFeatures")
model = kmeans.fit(df_scaled)
predictions = model.transform(df_scaled)
evaluator = ClusteringEvaluator(featuresCol="scaledFeatures")
silhouette = evaluator.evaluate(predictions)
silhouette_scores.append({"k": k, "silhouette": silhouette})
if k == optimal_k:
best_model = model
best_predictions = predictions
cluster_centers = best_model.clusterCenters()
cluster_analysis = []
for i, center in enumerate(cluster_centers):
cluster_foods = best_predictions.filter(col("prediction") == i).select("食物名称").collect()
food_count = len(cluster_foods)
representative_foods = [row["食物名称"] for row in cluster_foods[:5]]
cluster_profile = {}
for j, feature in enumerate(feature_cols):
cluster_profile[feature] = round(float(center[j]), 2)
cluster_analysis.append({
"聚类编号": i,
"食物数量": food_count,
"营养特征": cluster_profile,
"代表性食物": representative_foods
})
total_foods = df_clean.count()
clustering_summary = {
"最优聚类数": optimal_k,
"食物总数": total_foods,
"聚类质量评分": round(max([score["silhouette"] for score in silhouette_scores]), 3),
"聚类分布": [{"聚类": item["聚类编号"], "占比": round(item["食物数量"]/total_foods*100, 1)} for item in cluster_analysis]
}
return JsonResponse({
"code": 200,
"data": {
"聚类分析结果": cluster_analysis,
"聚类摘要": clustering_summary,
"轮廓系数评估": silhouette_scores
}
})食物营养数据可视化分析系统技术前沿解析-结语
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。