前言
又是一年"金九银十"秋招季,大模型相关的技术岗位竞争也到了白热化阶段。为满足大家碎片化时间复习补充面试知识点的需求(泪目,思绪回到前两年自己面试的时候),笔者特开设 《大模型工程面试经典》 专栏,持续更新工作学习中遇到大模型技术与工程方面的面试题及其讲解。每个讲解都由一个必考题和相关热点问题组成,小伙伴们感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。
一、面试题:如何评估大模型微调效果?
1.1 问题浅析
"如何评估大模型微调效果?"这个问题在面试中出现的频率极高,在真实的工业场景下微调好的模型不一定能够达到使用标准,因此评估微调模型的效果几乎是每个大模型技术人的必备技能。在真实的工业环境中微调效果的评估往往都是人工评估+自动化评估两条腿走路。
1.2 标准答案
第一段先简明扼要的说明微调效果评估的整体思路以及人工评估的一般方法:
评估大模型微调效果,通常需要结合人工评估与自动化评估两条路径。人工评估的核心,是让专业人员或者目标用户直接去体验模型的输出效果,通过打分、对比和主观判断来衡量模型是否更贴近人类偏好。比如在法律场景中,可以邀请律师对模型的答复进行专业性和准确性评分;在金融场景中,则由分析师判断回答是否具备实用价值。人工评估的优势在于它能真实反映"模型的回答是否符合预期场景',而不是单纯依赖指标。现在人工评估的门槛已经变低,例如开源的openwebui就内置了模型对比功能,让用户在不知情的情况下同时体验两个不同模型的回答,然后通过选择"更喜欢哪一个"来收集偏好反馈,这种盲测机制非常有效,能真实反映模型优劣。
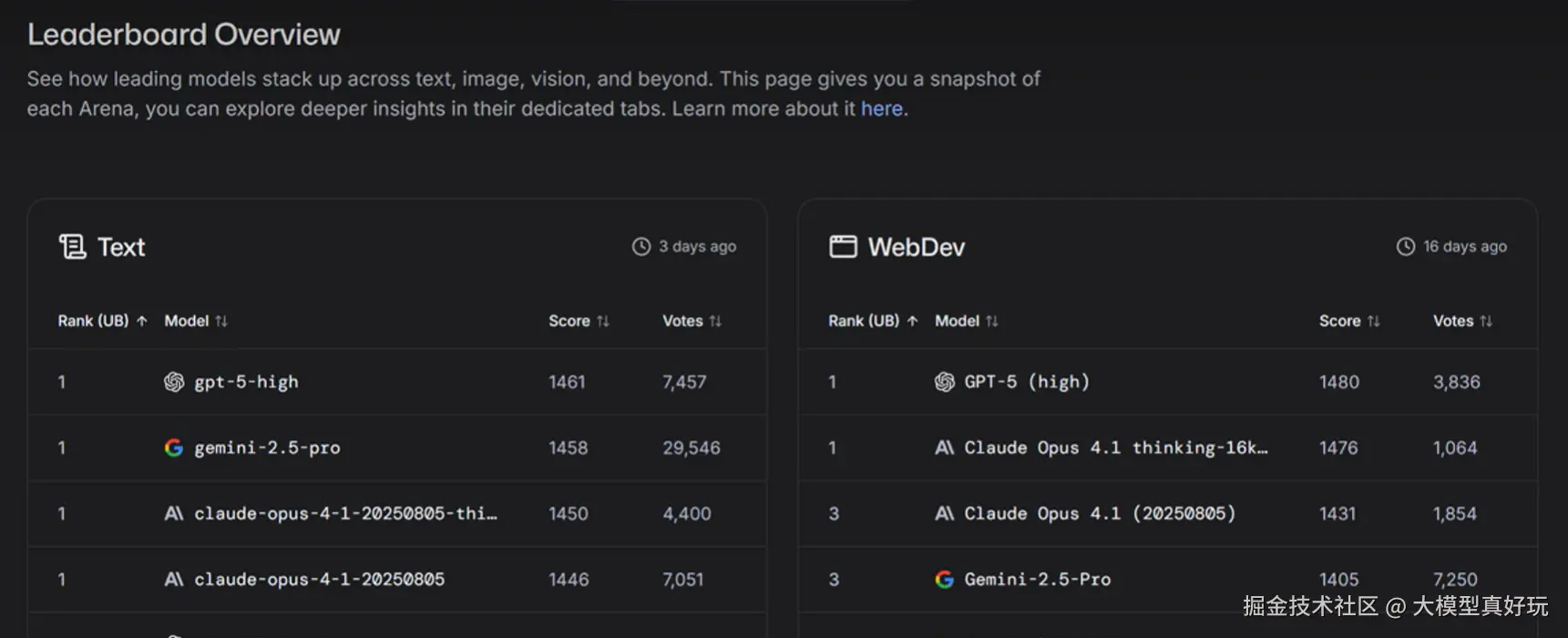
同时现在还有很多权威模型评测榜单,例如LM ARENA,它的排行榜就是通过成千上万用户的匿名打分累计出来的。
人工评估存在很大局限性,例如会存在主观偏见的问题,对于数学、推理、编程类问题人工评估成本太高。因此模型评估往往还需要借助数据集进行全自动的评估。
第二段主要介绍如何进行数据驱动的评估:
除了人工评估外,我们往往还需要依靠数据集驱动的系统化评估,来评估模型的数学、推理、代码、Agent性能。常见做法是构建一套独立的验证数据集,在微调前后对比模型的各项指标是否发生变化。例如想要验证模型的在数学和推理方面性能,可以使用AIME、GPOA等数据集进行评估,如果想要验证模型的代码能力,可以使用SWE-Bench数据集进行评估,而如果希望验证模型指令跟随或者Function calling能力,则可以IFEval数据集。总的来说,只有把人工评估的主观体验与这些客观数据指标结合起来,我们才能真正全面可靠地判断微调是否达到效果。
第三段还可以补充当前流行的评估框架 ,例如OpenCompass,EvalScope来表明自己的工程化经验。关于评估工具的使用可参考笔者文章:最强大模型评测工具EvalScope------模型好不好我自己说了算!
二、相关热点问题
2.1 在人工评估微调结果过程中,如何尽量避免偏差?
答案: 人工评估不可避免会受到主观因素的影响,因此要尽量通过多评审员+盲测来降低评审员之间的尺度一致 偏差。多评审员能平衡个体差异,取平均或投票结果更可靠;盲测则可以避免因对模型身份的预期而影响判断。此外,还可以制定统一的评分标准和示例,保证不同评审员之间的尺度一致。
2.2 如何构建用于评估微调效果的验证集或者测试集?
答案: 首先,验证集或者测试集数据需要覆盖模型未来可能面对的各类典型任务场景,例如金融模型就要包含行情解读、风险分析、投资建议等多种类型的问题;其次,要保证样本多样性,避免模型只在某一种题型上表现良好而在真实应用中失效。
2.3 请问通常有哪些工具可以用于快速构建模型评估数据集?
答案: 工程化场景下,往往会考虑使用魔搭社区EvalScope项目,来自动地构建测试数据集,自动评估模型性能并产出分析报告
三、总结
本期分享详细介绍了如何验证模型微调性能的方法包括人工+数据集自动化,以及扩展了模型评估相关的热点面试问题。总的来说,评估微调效果不仅仅是模型研发的最后一环,更是决定模型能否真正落地应用的关键环节。回答好这个问题可以让面试官清晰看到大家是否具备全局视角和工程化思维,也能直接体现你对大模型从训练到应用的完整把控能力。大家按模板回答一定是加分项!小伙伴们阅读后感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。