LangSmith:大模型应用开发的得力助手
- 大语言模型(LLM)快速发展,构建高效、可靠的 LLM 应用成为开发者核心需求;
- 但开发过程中,缺乏对应用内部运行的洞察,导致调试和优化难度显著增加;
- LangSmith 针对这一痛点,为 LLM 应用开发全流程提供支持。
1. LLM 应用开发的困境
- LLM 应用开发中,常见场景是:编写完 Chains、发送 Prompts、获取输出后,对背后执行逻辑缺乏了解;
- 当应用表现异常(如回答不准确、响应慢、出现错误)时,无法精准定位问题 ------ 是 Prompts 设计不合理、Chains 调用 LLM 出错,还是网络超时?
- 这种不确定性严重拖慢开发进度,阻碍迭代优化。
2. LangSmith 来助力
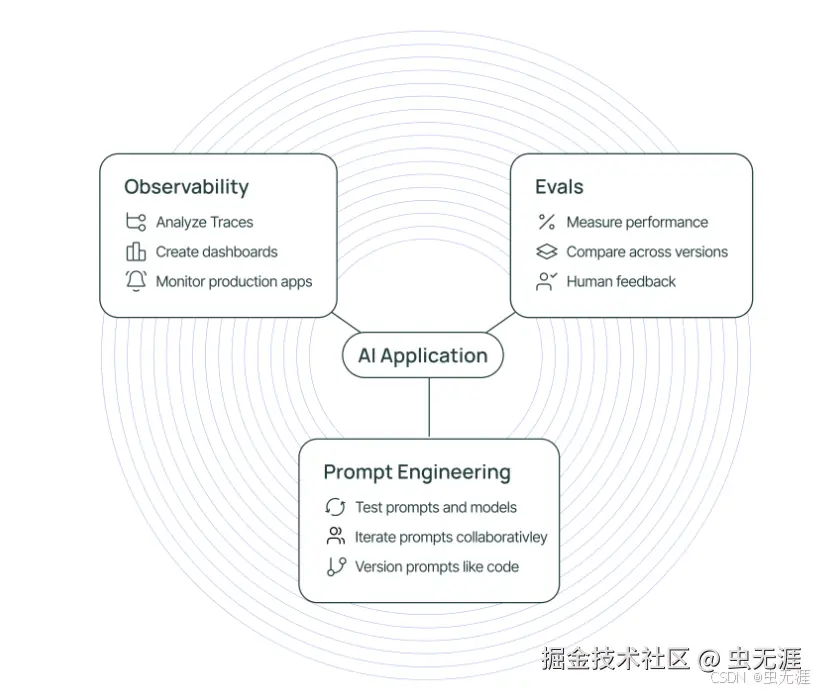
2.1 可观察性:让黑箱变透明
- LangSmith 的核心价值之一是为 LLM 应用提供强可观察性;
- LLM 领域的可观察性远超传统监控:由于 LLM 本身的非确定性,开发者不仅需要知道应用是否正常运行,更需了解其运行过程及输出产生的原因;
- 以 LangChain 构建的复杂应用为例,执行流程可能是:用户提示词→链→工具调用→子链→LLM→输出→LLM→最终输出;
- 无 LangSmith 时,该流程如同黑箱,调试难度大;
- LangSmith 通过挂钩 LangChain 应用执行流程,自动捕获每步操作,将信息转化为有序、可视化的数据流,帮助开发者清晰掌握执行细节。
2.2 追踪树:清晰展现执行逻辑
- LangSmith 的追踪能力是实现可观察性的关键;
- 每次应用完整执行(从接收输入到返回结果)会被记录为一个 Trace(调用链),Trace 内部由层级分明的 Run(运行步骤)构成,形成可无限展开的 "追踪树"(Trace Tree);
- 示例:
css
(Run) 🟢 LLMChain: QA Chain
├── (PromptTemplate) 📄 Final prompt rendered
└── (LLM Call) 🤖 Model: gpt-4
  └── Tokens used: 107
  └── Time taken: 2.1s
  └── Response: "Paris is the capital of France."
- 追踪树每个节点代表一个 Run,清晰呈现执行逻辑:根节点(RunnableSequence)是应用顶层调用;
- 父节点(LLMChain)是具体链或代理;子节点展示父节点组件的执行细节 ------(PromptTemplate) 显示填充变量后的完整提示;
- (LLM Call) 记录模型调用的名称、耗时、Token 消耗;
- Agent 应用还会显示工具调用及输入输出;(OutputParser) 展示输出解析步骤。
这种结构与 LangChain 表达式语言(LCEL)执行图直接对应,代码逻辑结构与追踪可视化结构同构。开发者使用 LangSmith 调试时,不仅能查看日志,还能直观验证代码逻辑是否符合预期,提升调试效率。
3. 实践之旅:构建可观测的 LLM 应用
3.1 准备工作
-
注册与密钥获取 :访问 LangSmith 官网(smith.langchain.com),用 GitHub 或 Google 账号登录。进入 "Settings" 页面,在 "API Keys" 选项卡创建并保存 API 密钥。
-
项目环境搭建:
-
本地创建项目文件夹并进入:
bash
mkdir langsmith - translator
cd langsmith - translator- 创建 Python 虚拟环境隔离依赖:
bash
\# Mac/Linux
python3 -m venv venv
source venv/bin/activate
\# Windows
python -m venv venv
venv\Scripts\activate3.2 代码实现
以简单翻译应用为例,展示 LangSmith 的代码集成方式,基于 LangChain 的 LLMChain 实现翻译功能:
python
import os
from langchain import LLMChain, PromptTemplate
from langchain.chat\_models import ChatOpenAI
from langsmith import Client
from langsmith.run\_helpers import traceable
\# 设置环境变量
os.environ\["LANGCHAIN\_API\_KEY"] = "YOUR\_API\_KEY"
os.environ\["OPENAI\_API\_KEY"] = "YOUR\_OPENAI\_KEY"
os.environ\["LANGCHAIN\_PROJECT"] = "translation\_project"
\# 初始化LangSmith client
client = Client()
\# 定义翻译模板
template = """Translate the following English text to French: {text}"""
prompt = PromptTemplate(input\_variables=\["text"], template=template)
\# 创建LLMChain
@traceable(run\_type="translation")
def translate\_text(text):
  llm = ChatOpenAI(temperature=0)
  chain = LLMChain(llm=llm, prompt=prompt)
  result = chain.run(text)
  return result
\# 调用翻译函数
text\_to\_translate = "Hello, world!"
translation = translate\_text(text\_to\_translate)
print(translation)上述代码中,通过环境变量建立与 LangSmith 的连接,用
@traceable装饰器标记翻译函数,实现函数运行情况的 LangSmith 追踪。
4. 高级功能探索
4.1 评估(Evaluation):衡量应用质量
- LangSmith 提供丰富评估功能,帮助衡量 LLM 应用性能与质量;
- 开发者可定义包含输入和预期输出的评估数据集,使用 LangSmith 评估器对应用输出打分;
- 例如,用精确匹配评估器检查输出与预定义答案的一致性,或用 LLM 作为裁判评估器判断输出合理性;
- 通过这些评估,可精准掌握应用在不同场景的表现,定位问题并优化。
4.2 监控(Monitoring):实时掌握运行状态
- 应用部署后,实时监控至关重要;
- LangSmith 实时收集运行数据(Token 消耗、响应时间、错误率等),通过仪表盘可视化展示;
- 开发者可依据实时数据,及时发现性能瓶颈与异常(如 Token 消耗异常增加,可能是无效请求或模型调用问题),采取调整措施保障应用稳定运行。
4.3 提示词工程(Prompt Engineering):优化提示词效果
- 提示词质量直接影响 LLM 应用输出;
- LangSmith 支持开发者在平台测试、比较不同提示词,通过观察输出准确性、相关性等指标,调整优化提示词;
- 同时,LangSmith 记录提示词历史版本及对应运行结果,方便回溯分析,提升提示词设计能力。