目录
- 一、下载Hadoop
- 二、配置Hadoop环境
-
- 2.1设置SSH免密登录
- 2.2配置文件
-
- [` hadoop-env.sh 配置`](#
hadoop-env.sh 配置) - [`yarn-env.sh 配置`](#
yarn-env.sh 配置) - `core-site.xml配置`
- `hdfs-site.xml文件配置`
- `mapred-site.xml文件配置`
- `yarn-site.xml配置`
- [` hadoop-env.sh 配置`](#
- 三、创建文件夹
- 四、添加环境变量
- 五、验证
一、下载Hadoop
我们去官网下载:Hadoop下载地址

输入wget下载hadoop:
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
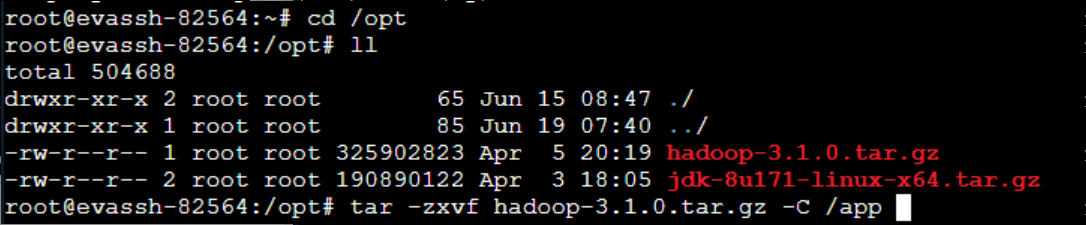
我已经下载好了在/opt目录下。
创建/app目录
mkdir /app
由于解压包有大概300M,所以我们已经预先帮你下载好了,切换到/opt目录下即可看到。
接下来解压Hadoop的压缩包,然后将解压好的文件移动到/app目录下。
二、配置Hadoop环境
2.1设置SSH免密登录
在后操作集群的时候我们需要经常登录主机和从机,所以设置SSH免密登录时有必要的。
输入以下代码:
powershell
ssh-keygen -t rsa -P ''生成无密码密钥对,询问保存路径直接输入回车,生成密钥对:id_rsa和id_rsa.pub,默认存储在~/.ssh目录下。
接下来:把id_rsa.pub追加到授权的key里面去。
powershell
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys然后修改权限
powershell
chmod 600 ~/.ssh/authorized_keys接着需要启用RSA认证,启动公钥私钥配对认证方式:
vim /etc/ssh/sshd_config 如果提示权限不足在命令前加上sudo;

powershell
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径重新启动SSH
powershell
service ssh restart2.2配置文件
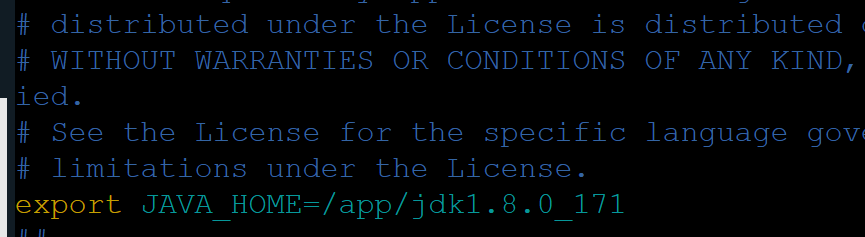
hadoop-env.sh 配置
两个env.sh文件主要是配置JDK的位置
提示:如果忘记了JDK的位置了,输入echo $JAVA_HOME就可以看到哦。

首先我们切换到hadoop目录下:
powershell
cd /app/hadoop3.1/etc/hadoop/编辑 hadoop-env.sh在文件中插入如下代码:
powershell
export JAVA_HOME=/app/jdk1.8.0_171插入如下:
yarn-env.sh 配置
插入以下代码:
powershell
export JAVA_HOME=/app/jdk1.8.0_171core-site.xml配置
这个是核心配置文件我们需要在该文件中加入HDFS的URI和NameNode的临时文件夹位置,这个临时文件夹在下文中会创建。
在文件末尾的configuration标签中添加代码如下:
powershell
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>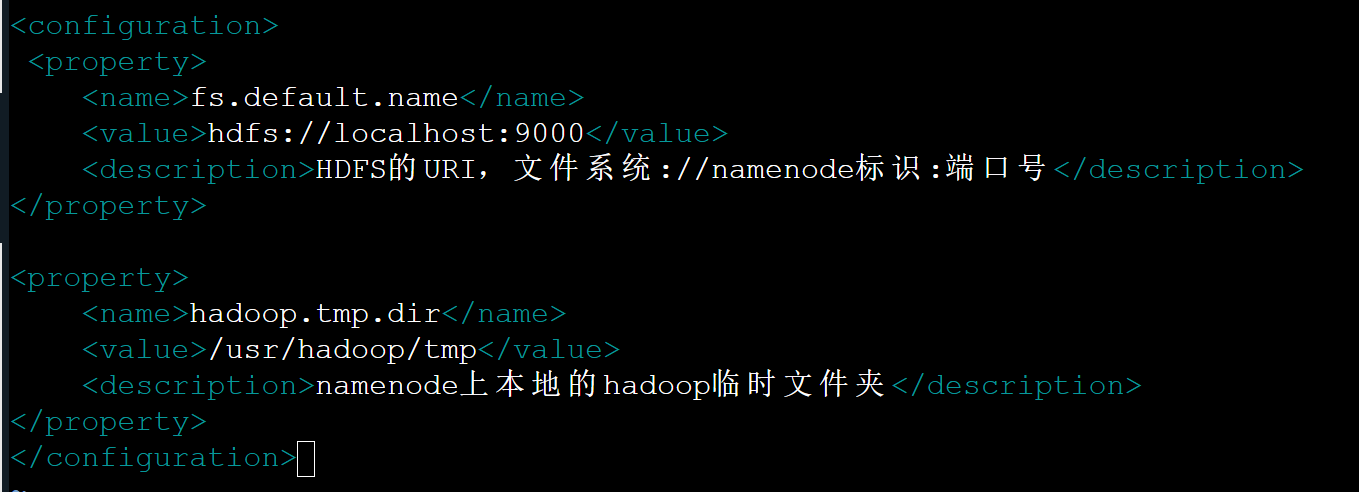
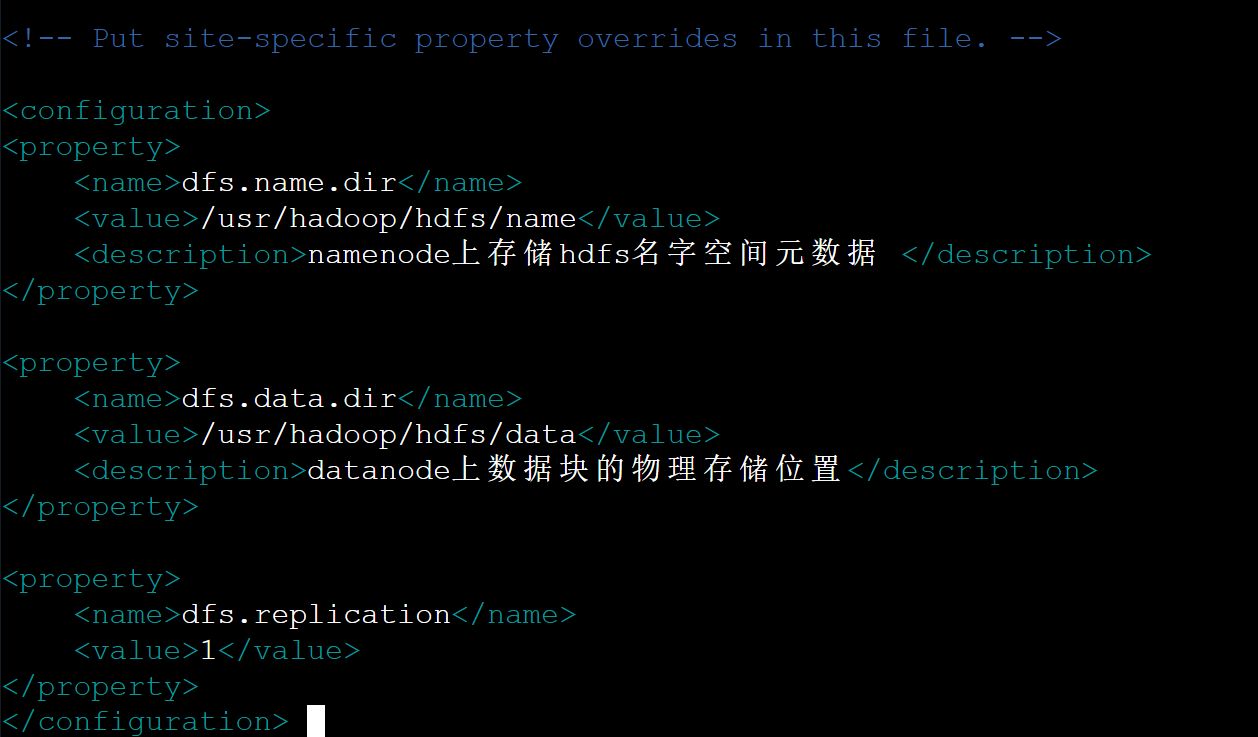
hdfs-site.xml文件配置
replication指的是副本数量,我们现在是单节点,所以是1。
powershell
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration> 效果如下:
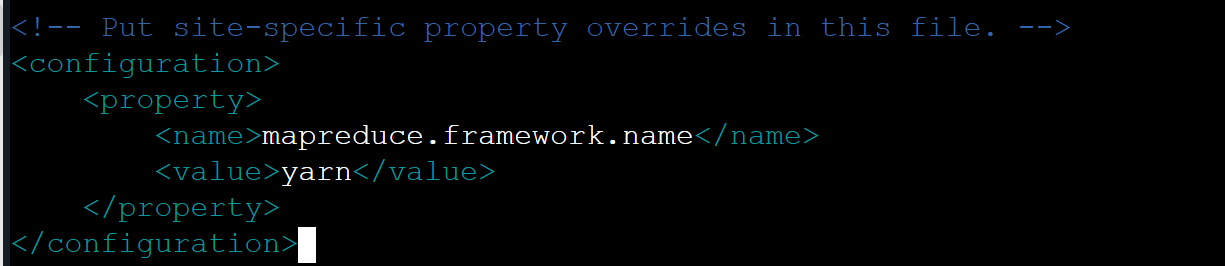
mapred-site.xml文件配置
powershell
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>效果如下:
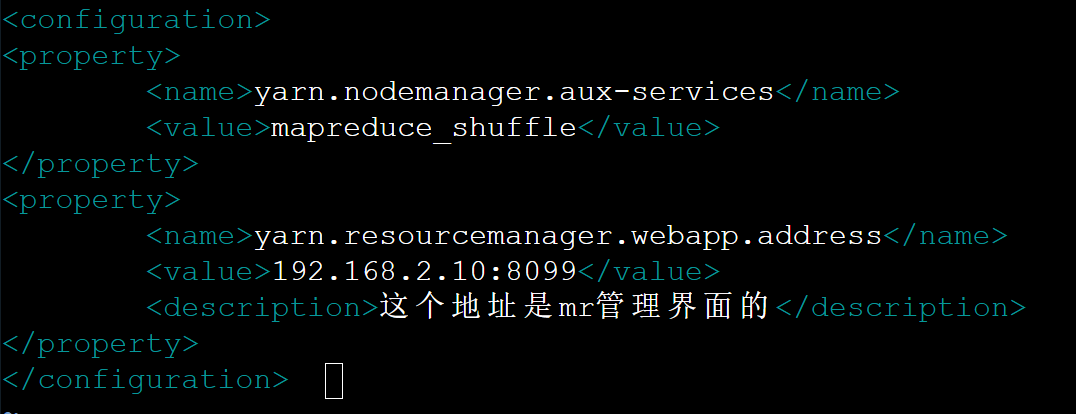
yarn-site.xml配置
powershell
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.2.10:8099</value>
<description>这个地址是mr管理界面的</description>
</property>
</configuration> 效果如下:
三、创建文件夹
我们在配置文件中配置了一些文件夹路径,现在我们来创建他们,在/usr/hadoop/目录下使用hadoop用户操作,建立tmp、hdfs/name、hdfs/data目录,执行如下命令:
powershell
mkdir -p /usr/hadoop/tmp
mkdir /usr/hadoop/hdfs
mkdir /usr/hadoop/hdfs/data
mkdir /usr/hadoop/hdfs/name将Hadoop添加到环境变量中
powershell
vim /etc/profile在文件末尾插入如下代码:

最后使配置生效:
powershell
source /etc/profile四、添加环境变量
Hadoop 是一个分布式系统,包含多个核心组件(如 NameNode、DataNode、ResourceManager 等)。在生产环境中,为了安全和权限管理,通常会为不同组件分配不同的系统用户(而非全部使用 root 用户)。这些环境变量的作用是指定启动 / 停止对应组件时使用的系统用户,确保组件运行在正确的权限上下文下。
转到 sbin
powershell
cd /app/hadoop3.1/sbin下面的vim均在文件头部插入。如下:
vim start-dfs.sh
powershell
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root vim stop-dfs.sh
powershell
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootvim start-yarn.sh
powershell
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=rootvim stop-yarn.sh
powershell
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root五、验证
现在配置工作已经基本搞定,接下来只需要完成:1.格式化HDFS文件、2.启动hadoop、3.验证Hadoop 即可。
格式化
在使用Hadoop之前我们需要格式化一些hadoop的基本信息。
使用如下命令:
powershell
hadoop namenode -format出现以下界面就代表格式化成功了

启动:
powershell
start-dfs.sh
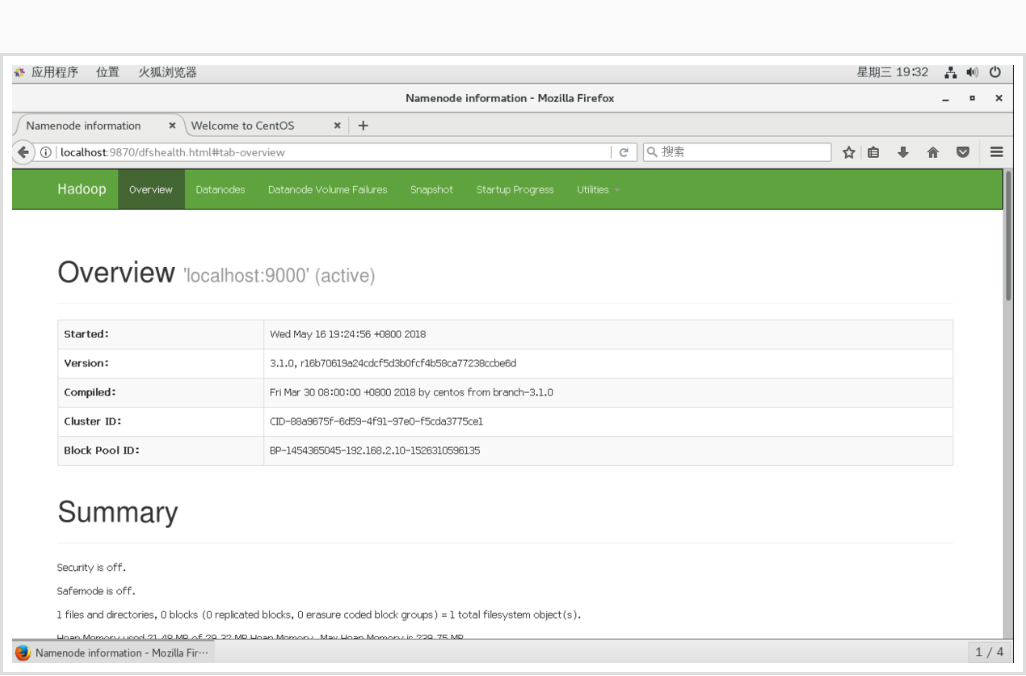
jps之后如果你本地虚拟机是图形化界面,可以在你虚拟机的图形化界面中打开火狐浏览器输入:
http://localhost:9870/或者在你本地windows机器上输入http://虚拟机ip地址:9870/也可以访问hadoop的管理页面。
到这里就搭建完成了,效果如下: