本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
本文主要围绕 RAGFlow 的构建知识库、搜索、Agent、文件管理等核心应用功能模块,结合大模型 LLM,零基础如何实现在本地快速搭建RAG专属知识库、智能搜索问答系统、Agent智能助手应用,以及RAGFlow 在应用过程中的常见问题与解决方案。
1.RAGFlow 简介
RAGFlow 是一个开源的检索增强生成(RAG)引擎,其核心价值定位旨在高效地连接用户查询与知识库,通过检索相关文档片段,并结合大语言模型(LLM)生成精准、上下文相关的回答。
2.RAGFlow 系统架构
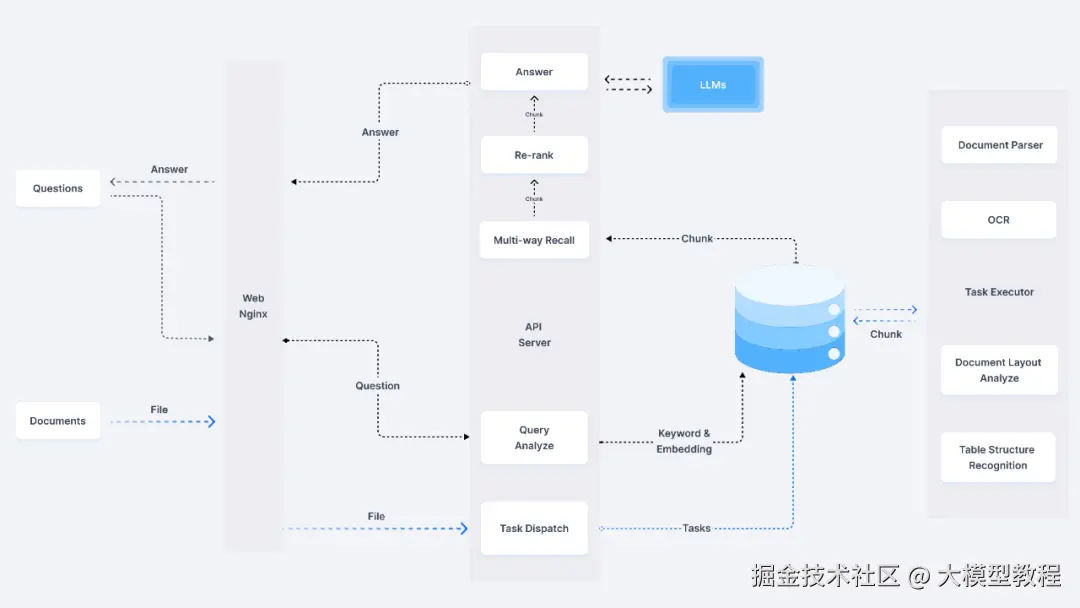
3.检查 RAGFlow 运行健康状态
在应用RAGFlow之前,我们需要先确保RAGFlow相关容器均已正常Up启起来了,且显示health健康状态。
在终端界面,检查RAGFlow运行健康状态,可执行命令行如下:
sudo docker ps -a | grep ragflow
如下图所示:

实时查看 RAGFlow 运行日志的最后200行详情,可执行命令行如下:
sudo docker logs -f ragflow-server --tail 200
此时,当我们成功登录 RAGFlow 后,就会自动跳转到如下界面:
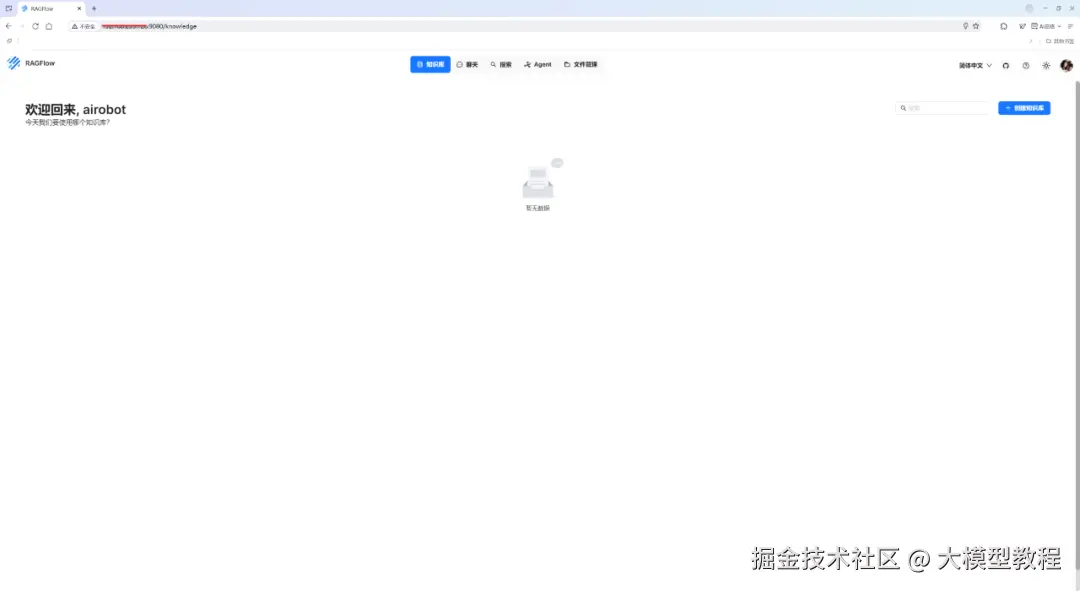
由上图可见,RAGFlow 的顶部导航菜单栏是其核心功能入口,集中展示了四大关键应用模块:知识库、搜索、Agent、文件管理。
知识库:主要是用于管理和展示已构建的知识库列表,其功能定位为企业级知识资产的管理中心,支撑 RAG 系统的数据基础。
搜索:精准检索引擎,连接用户查询与知识库内容的桥梁。
Agent:自动化任务执行器,基于知识库数据生成结构化输出或执行操作。
文件管理:数据生命周期管理,保障知识库数据的可追溯性与安全性。
4.默认模型设置
在应用 RAGFlow 之前,我们必须添加和设置默认的大模型 LLM 配置信息,以便在后续的 RAGFlow 应用过程中可以选择加载所需的模型。
具体操作如下:
步骤1:
登录成功后,先点击右上角"头像",如下图:
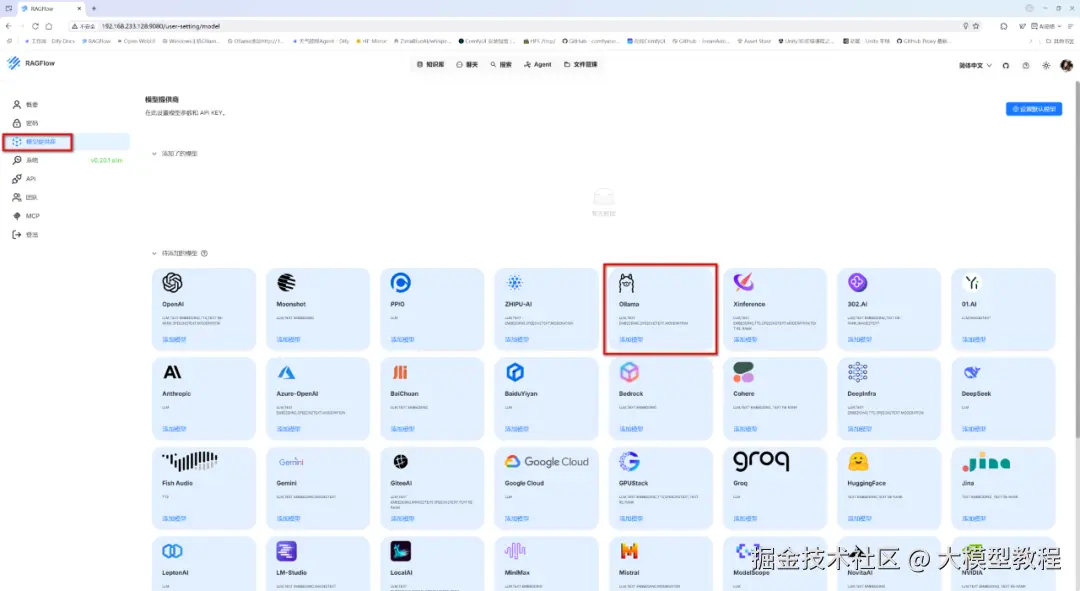
步骤2:
点击"模型供应商",选择Ollama,如下图:
步骤3:
添加模型,具体如下图:
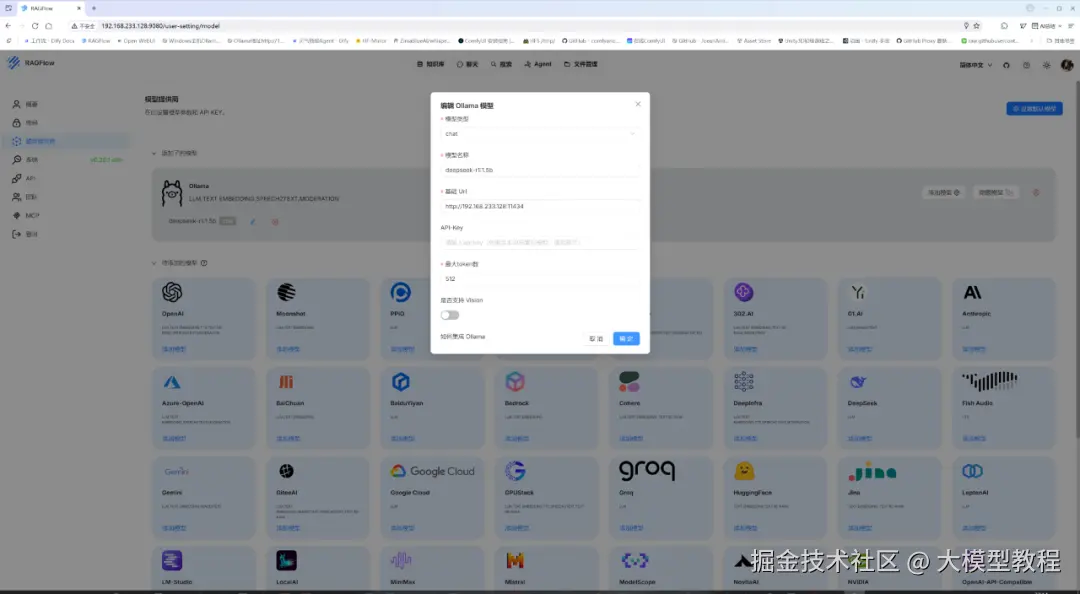
其中,模型配置参数说明如下:
-
模型类型:chat,表示是聊天模型。
RAGFlow支持的模型类型有:
(1)聊天模型(Chat):所有新创建的知识库都会使用默认的聊天模型。
(2)嵌入模型(Embedding):所有新创建的知识库使用的默认嵌入模型。如未显示可选模型,请检查你是否在使用 RAGFlow slim 版(不含嵌入模型)。
(3)Img2txt模型(Img2txt):所有新创建的知识库都将使用默认的 img2txt 模型。 它可以描述图片或视频。
(4)Speech2txt模型(Speech2txt):所有新创建的知识库都将使用默认的 ASR 模型。 使用此模型将语音翻译为相应的文本。
(5)Rerank模型(Rerank):重排序模型,是检索增强生成(RAG)系统中的核心组件,用于对初步检索到的文档片段(如向量检索返回的Top-K结果)进行二次精准排序,筛选出与用户查询最相关的内容。其目标是提升最终输入给大语言模型(LLM)的上下文质量,从而优化生成答案的准确性和相关性。
(6)TTS模型(TTS):默认的tts模型会被用于在对话过程中请求语音生成时使用。
-
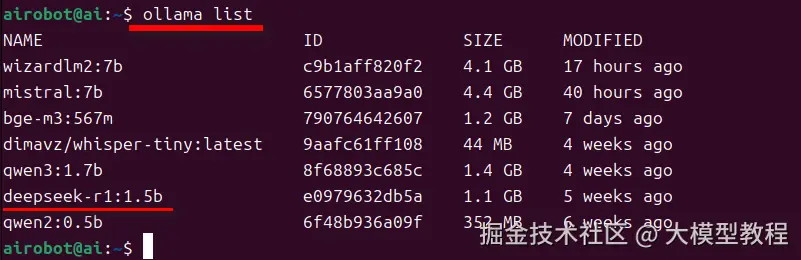
模型名称:这里配置为 deepseek-r1:1.5b,注意:必须与执行命令行 ollama list 输出的大模型名称Name保持一致。具体查看ollama已安装的大模型列表,如下图所示:
-
基础Url:因为此处选择了模型提供商Ollama,所以这里配置为在局域网内Ollama访问地址(默认端口11434),即:http://${IP_OF_OLLAMA_MACHINE}:11434
或者
http://${IP_OF_OLLAMA_MACHINE}:11434/v1。
-
API-Key:API访问密钥。在局域网内使用时,可以忽略。
-
最大token数:取值512。
大模型的最大token数的配置,主要依据以下因素:
(1)模型特性
不同模型支持的最大token数不同。例如,GPT-4支持约1047576个token,而其他模型可能限制在2048或更少。
(2)任务需求
长文档处理:处理长文本(如论文、书籍)时,需增大token数以保留上下文,建议设置为512-2048。
实时响应:对响应速度要求高的场景,应减小token数,以提升效率。
(3)性能与成本平衡
更大的token数会增加计算资源消耗和成本。需根据硬件条件和预算调整,避免资源浪费。
(4)分块策略
文档分块时,token数影响分块粒度。例如,学术论文建议512-768,法律文档建议256-512。
(5)实际测试与优化
通过实验确定最佳token数,观察对模型输出质量和性能的影响,进行动态调整。
在RAGFlow中,模型默认的最大 answer token数,取决于具体的模型配置。常见的设置如下:
通用模型:默认的answer token数通常为512。
长文本处理模型:可能会设置更高的数值,如1024或2048。
特定模型配置:某些模型可能有预设的最大token数,例如:GPT-4:约10475761。
其他模型:如2048或更少。
总之,RAGFlow的token数配置需综合模型能力、任务需求、性能成本等多方面因素,以实现最佳效果。
- 是否支持Vision:这里,设置否。
在检索增强生成(RAG)系统中,Vision 通常指以下两类能力:
(1)图像内容理解(Image Understanding)
- 功能:让 AI 系统能"看懂"图像内容,例如:
----识别图片中的物体、文字、场景(如识别发票金额、产品型号)。
----理解图表信息(如从流程图中提取步骤)。
- 技术依赖:
----OCR(光学字符识别):提取图像中的文字(如 Tesseract、百度 OCR)。
----多模态大模型:直接理解图像语义(如 GPT-4V、Claude 3、LLaVA)。
(2)跨模态检索(Multimodal Retrieval)
- 功能:支持用 文本查询检索图像,或用 图像查询检索文本/图像。
示例:用户上传一张电路板照片,系统返回知识库中相关的维修手册文本。
- 技术依赖:
----多模态嵌入模型:将图像和文本映射到同一向量空间(如 OpenAI CLIP、ViT-BERT)。
----多模态向量数据库:支持存储和检索图像向量(如 Milvus、Qdrant 的多模态扩展)。
小伙伴们还可以点击上图中的模型配置界面的左下角处"如何集成Ollama",具体查看RAGFlow官方提供的相关内容。
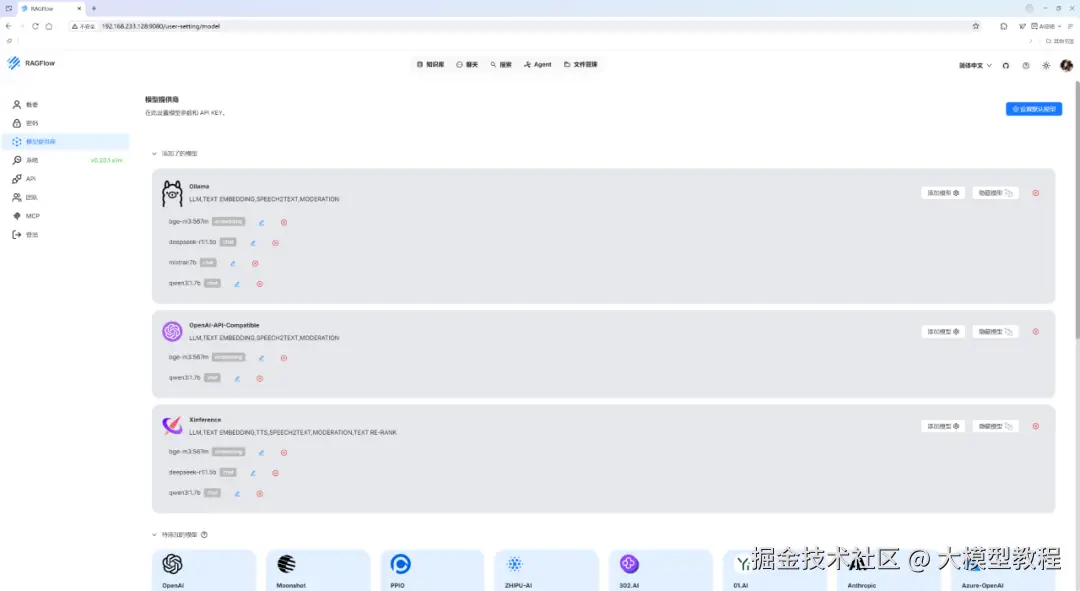
同理,我们可添加其他模型提供商和大模型 LLM,如下图所示:
RAGFlow支持的大模型完整清单列表,具体如下图所示:
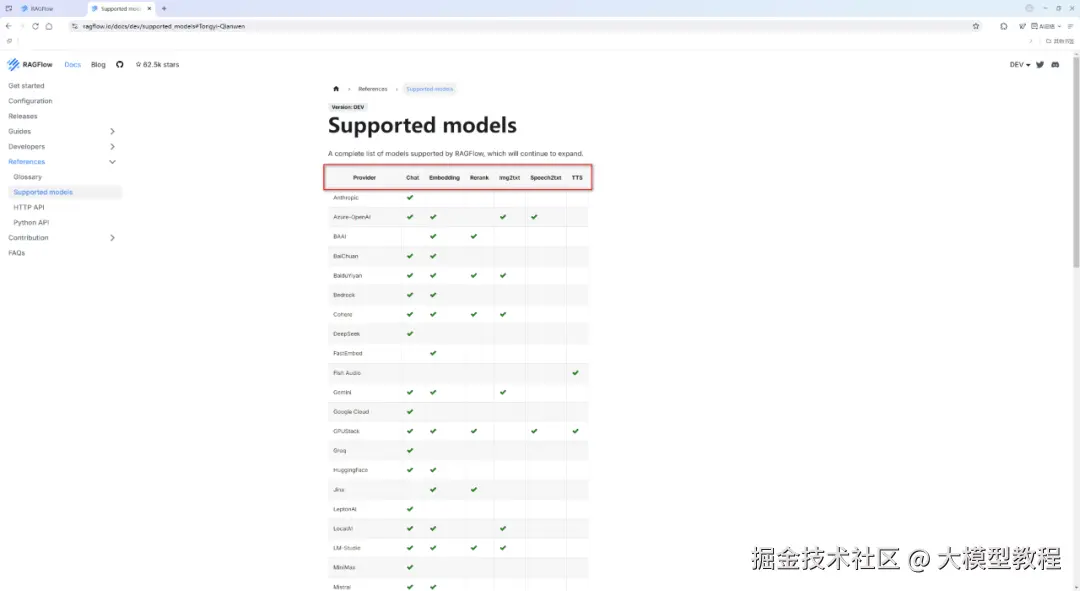
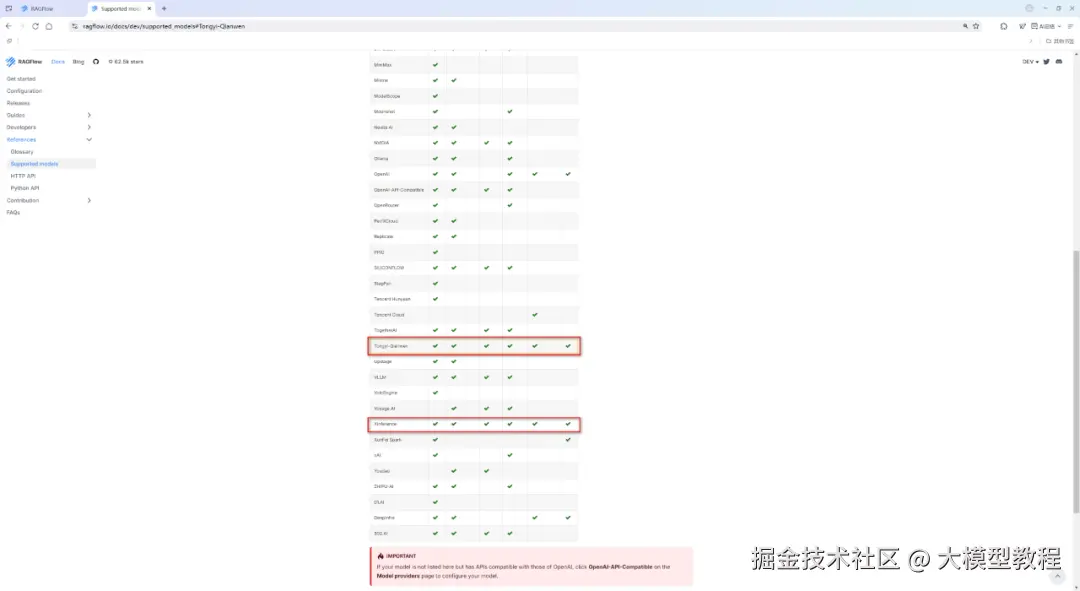
由上图可见, 目前仅有模型提供商 Tongyi-Qianwen 和 Xinference均已支持 RAGFlow的Chat、Embedding、Rerank、Img2txt、Speech2txt、TTS 这六种类型的大模型。
备注:
OpenAI-API-Compatible(OpenAI API 兼容性)不是一个具体的软件或工具,而是一套接口规范和约定。它规定了应用程序应该如何向一个AI服务发送请求,以及该服务应该如何返回响应,其格式与 OpenAI 官方的 API 完全一致。
Xinference 是一个开源的分布式模型推理框架,专注于本地化部署高性能模型服务,作为 RAGFlow 的"模型引擎",提供 LLM、Embedding、Rerank 等模型的本地化推理能力,是企业构建私有化 RAG 系统的理想选择。
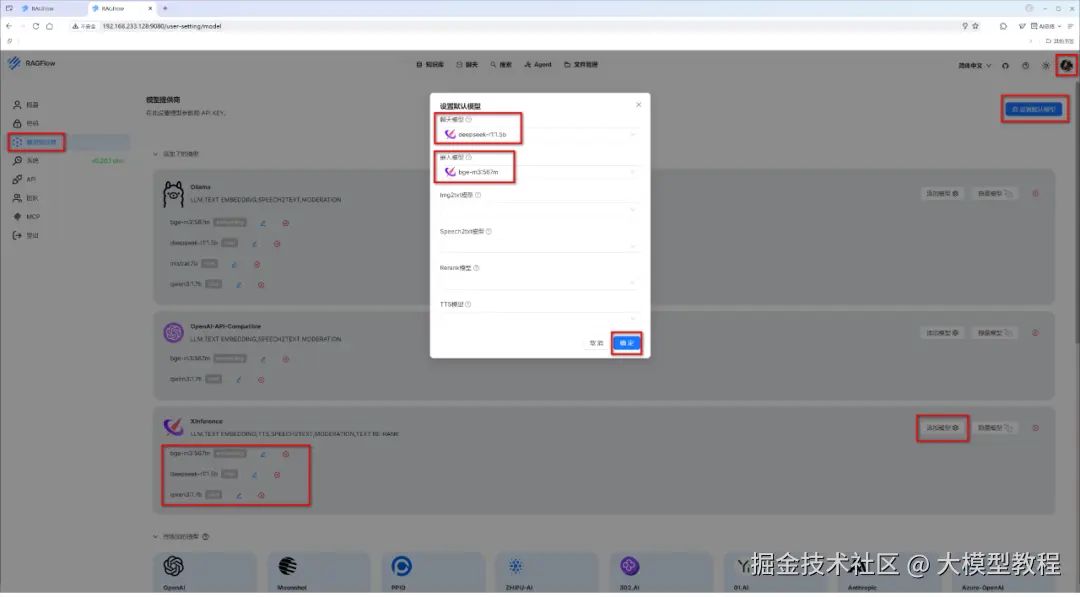
步骤4:设置默认模型
在添加了模型提供商及其模型配置项之后,点击右上角处的"设置默认模型",即可随时选择或者变更切换 RAGFlow 默认使用的大模型 LLM,如下图所示:
1.构建本地RAG专属知识库
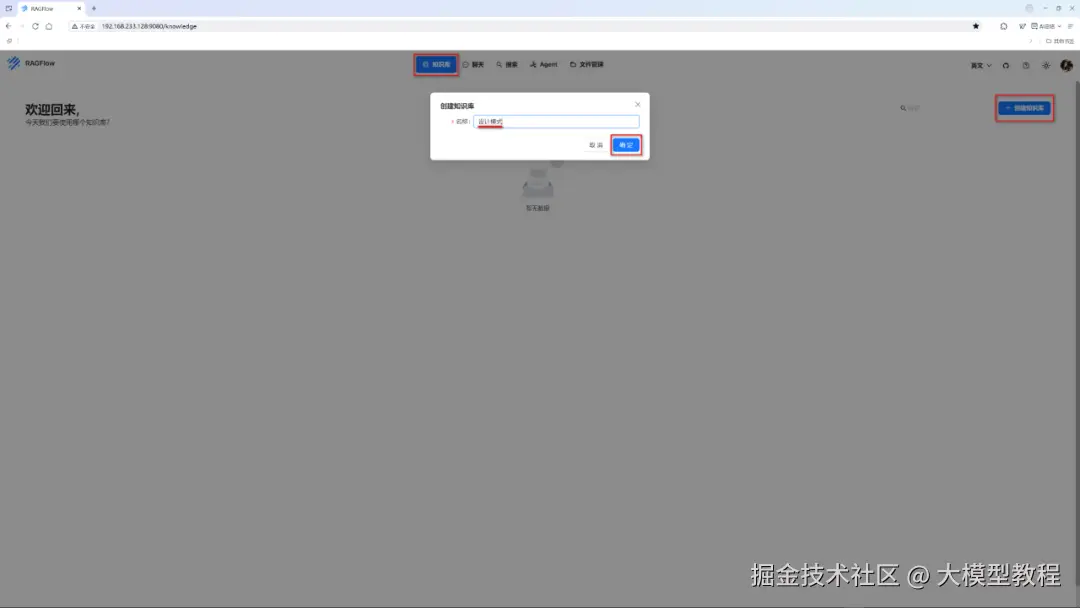
这里,以构建一个自定义名称为"设计模式"的本地RAG专属知识库为例,来演示说明。
步骤1:创建知识库
在点击顶部 "知识库" 菜单栏后,接着点击右侧"构建知识库"菜单项,输入自定义的知识库名称,如下图所示:
步骤2:上传文档
添加上传本地文件,如下图所示:
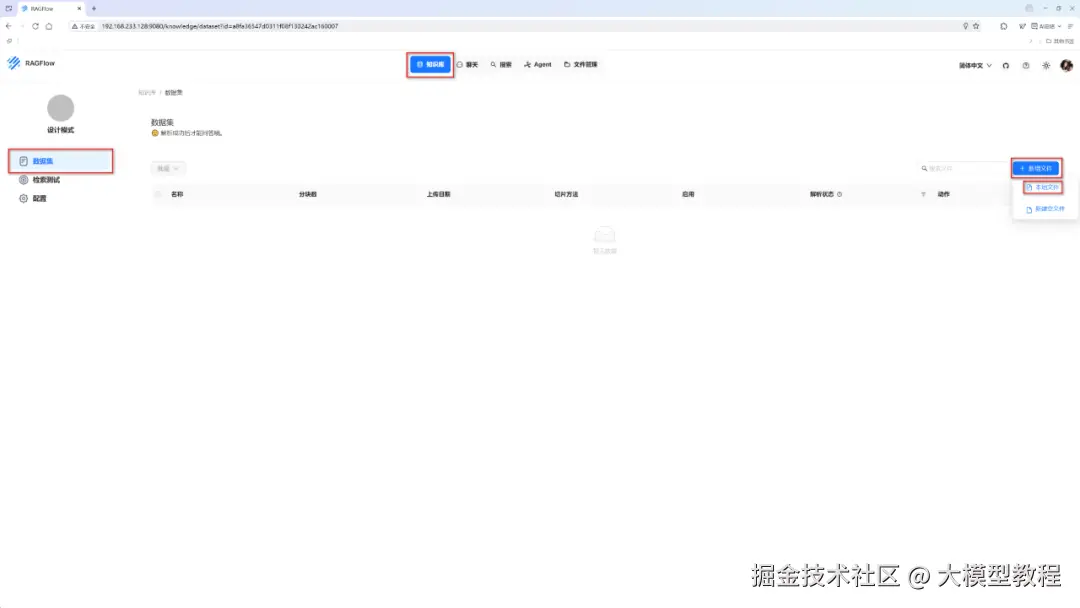
在这里,为了演示方便,我们将提前准备好的一份PDF文档(名称为"java设计模式.pdf"),鼠标点击方框区域内,选中目标文档即可自动上传。
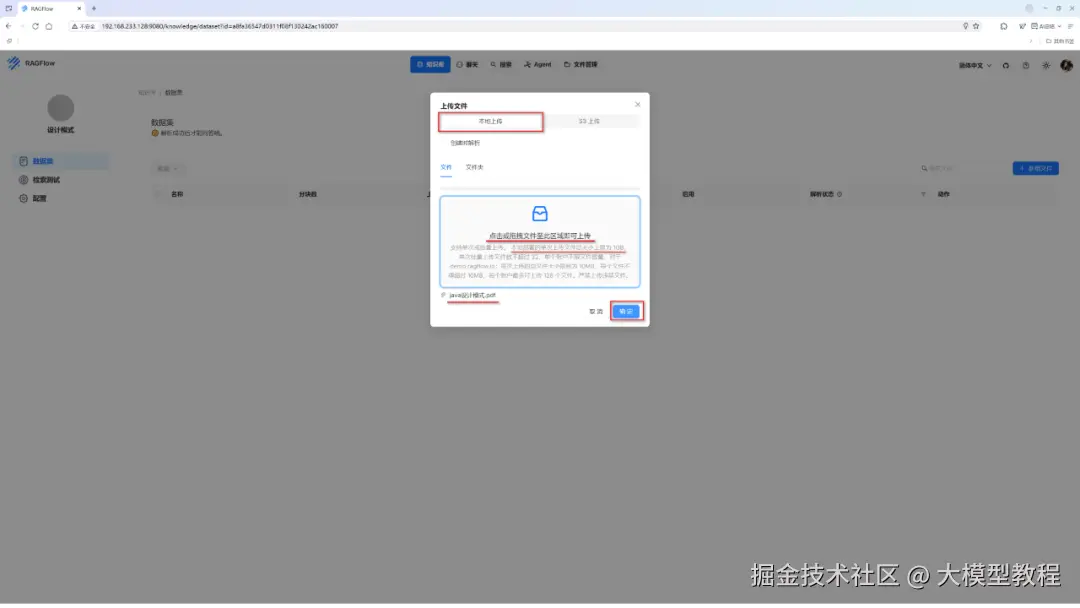
上传成功后,我们会看到在下图中有一个绿色的小三角图标,它就是"解析"按钮。
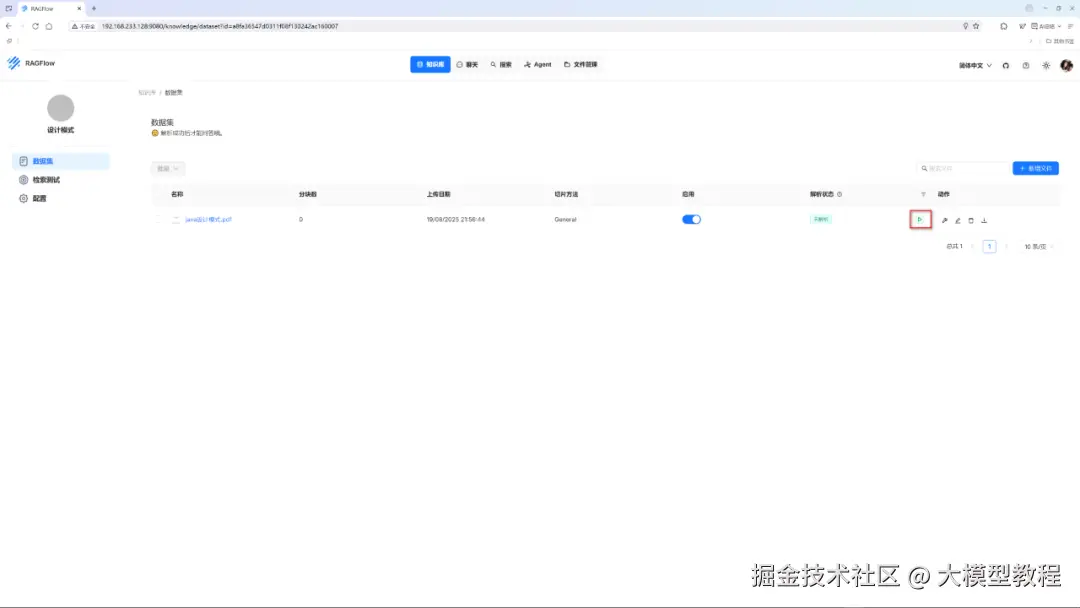
步骤3:知识库配置
在点击"解析"按钮之前,我们需要先对准备构建的本地专属RAG知识库进行配置,这主要是为了预先设置告诉 RAGFlow:你具体将如何解析处理用户上传的文档数据,包括:PDF解析器、嵌入模型、切片方法、文本分段标识等关键点。
如果对上述这些关键点的用途不清楚的小伙伴,也不用担心哈,我们只需把鼠标悬放到对应的问号小图标上,即可看到相应的提示说明,如下图所示:
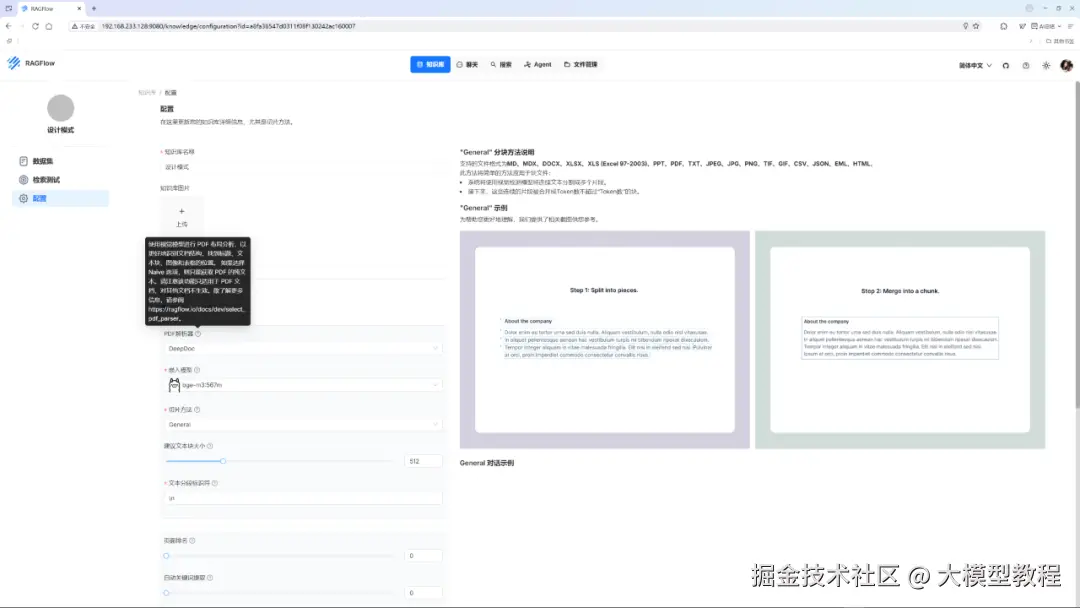
步骤4:解析
在上述配置完毕后,我们就可以点击"解析"按钮,此时会弹出一个"操作成功"的提示,RAGFlow 就正式开始处理上传的文档了。具体如下图所示:
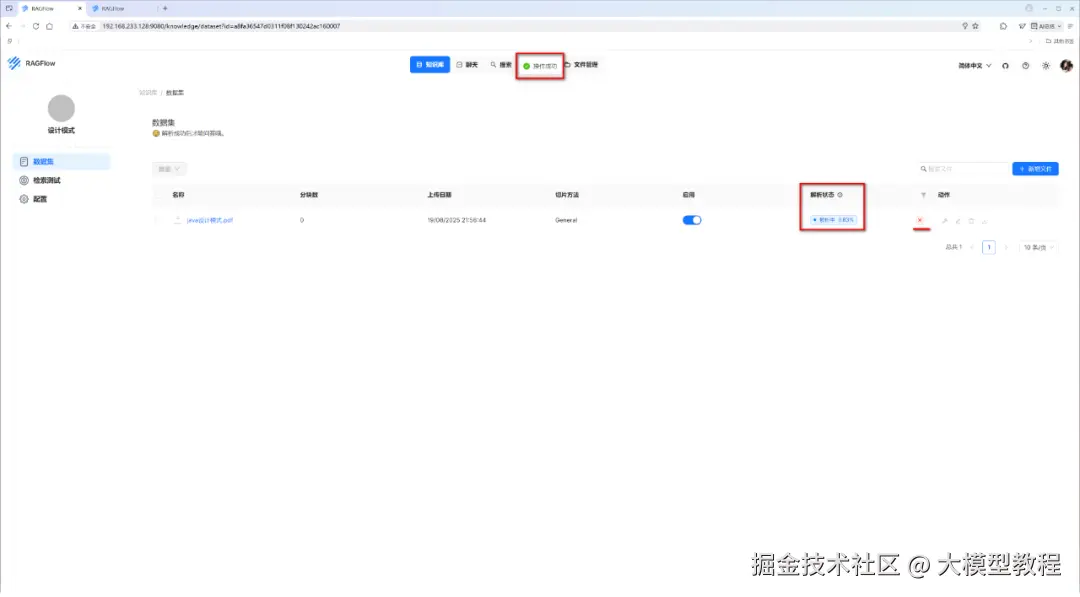
此时,我们把鼠标悬放在"解析进度"上,就可以实时查看解析日志,见下图:
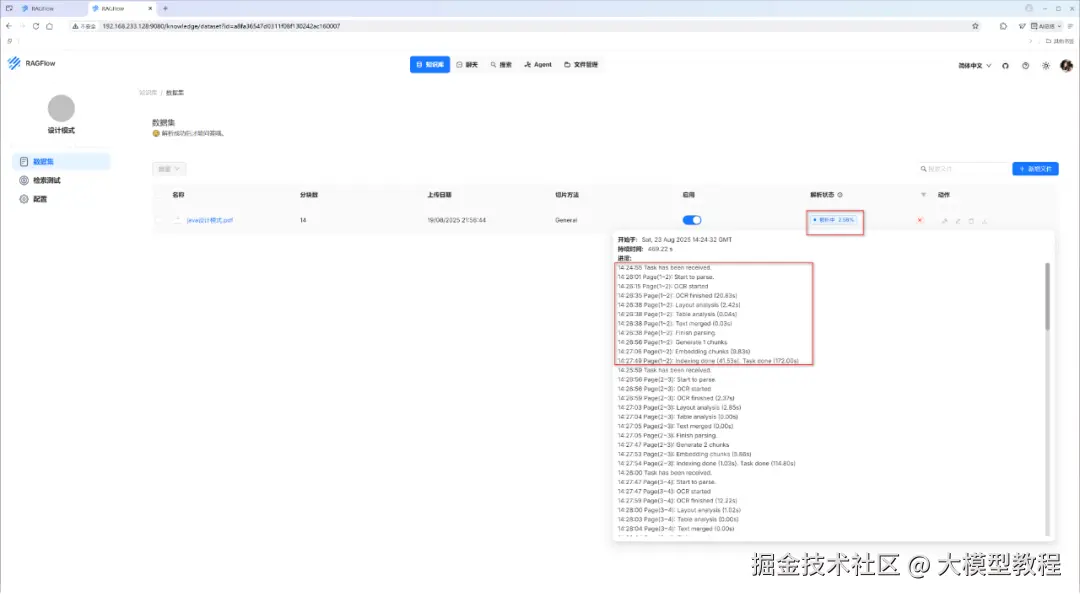
当然,我们也可以实时查看 RAGFlow 后台运行日志的最后200行详情,执行命令行如下:
sudo docker logs -f ragflow-server --tail 200
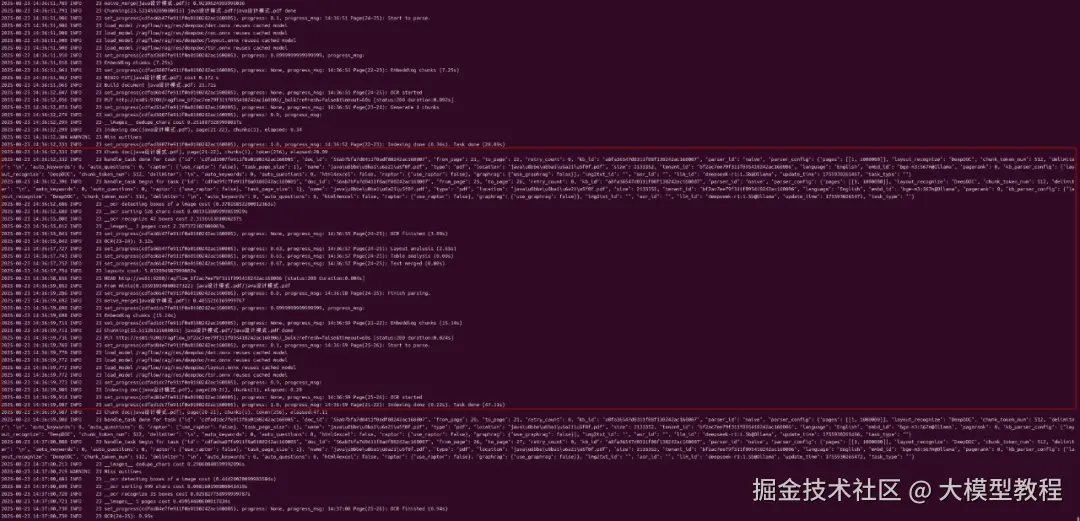
查看解析处理过程的详情日志内容,如下图所示:
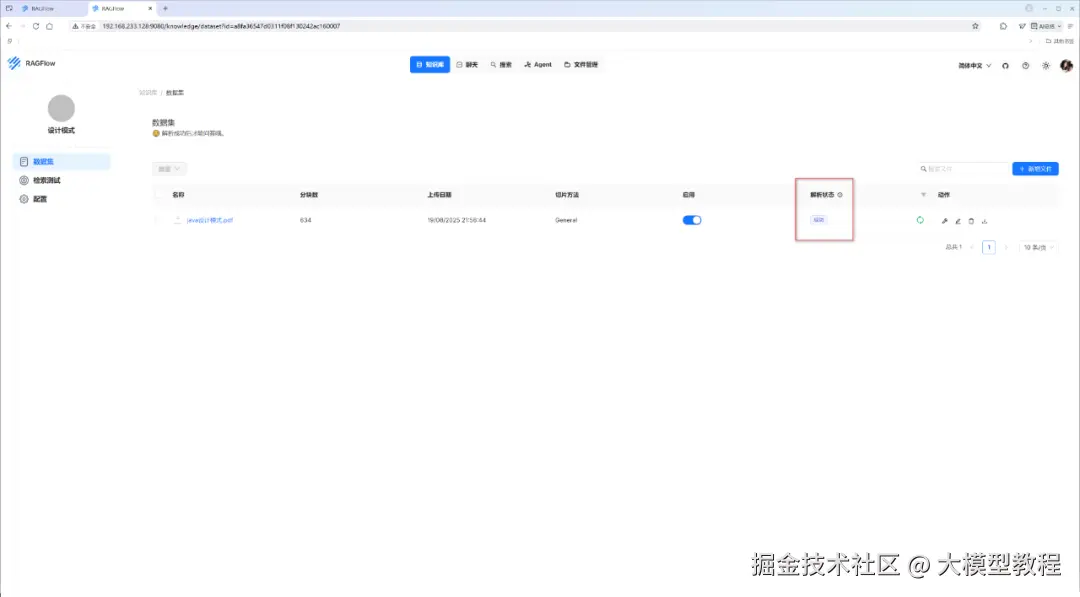
等待文档解析处理完毕后,解析状态就会出现"成功"标志,如下图所示:
步骤5:检索测试
当解析成功后,我们就可以进行检索测试,初步验证 RAGFlow 配置参数的实际效果如何,效果如下图所示:
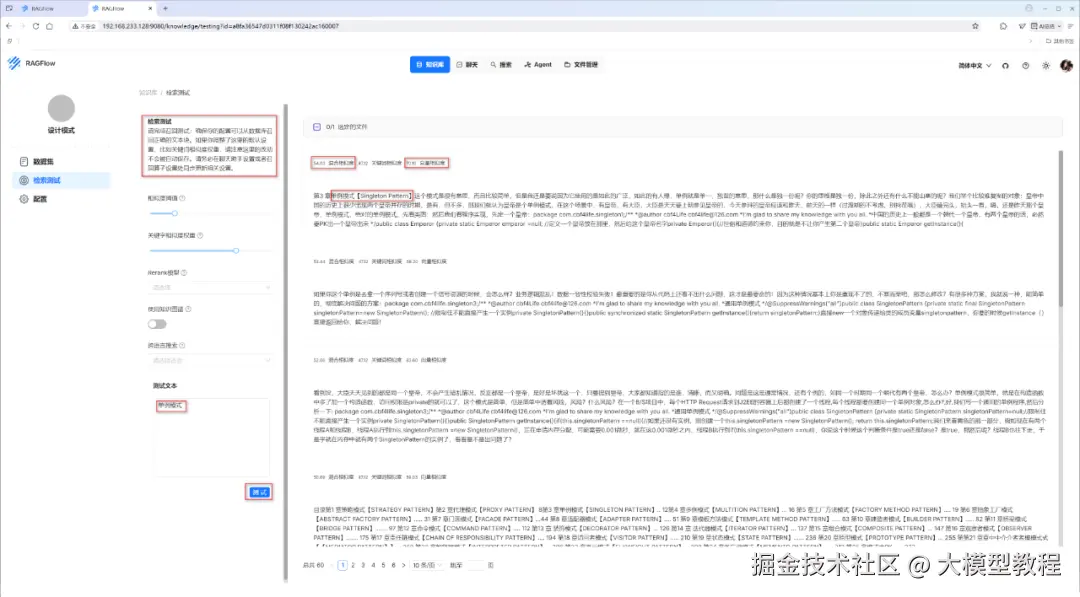
如上图可见,我们搜索"单例模式",成功检索到了相关的文档片段,看起来效果还可以。
需要注意的是,如果检索测试的效果不佳,比如,返回的检索结果与查询内容驴头不对马嘴,严重不相关的话,则需要及时重新返回到 步骤3 进行调参。
至此,我们已成功构建了一个本地RAG专属知识库------设计模式,搞定!
接下来,我们就可以在 RAGFlow 的搜索、聊天、Agent 应用模块中,正式使用本地RAG专属知识库啦。。。
2.知识库专属聊天助理
要实现一个知识库专属聊天助理,非常简单!
具体如下:
首先点击 RAGFlow 应用页面顶部导航菜单栏中的"聊天",接着点击左侧的"新建助理"按钮,然后点击"编辑",开始为你的知识库配置专属聊天助理。
步骤1:编辑
步骤2:助理设置
注意:在最下面的"知识库"选项中,选择我们在前面已构建成功的本地RAG专属知识库------设计模式。
步骤3:提示引擎
步骤4:模型设置
至此,点击"确定"即可。
步骤5:新建聊天
点击"新建助理"右侧的加号小图标,即可开启一个聊天会话窗口。此时,我们尝试输入一个简单的问题"什么是设计模式",看看本地知识库专属聊天助理的实际效果如何。
应用效果如下图所示:
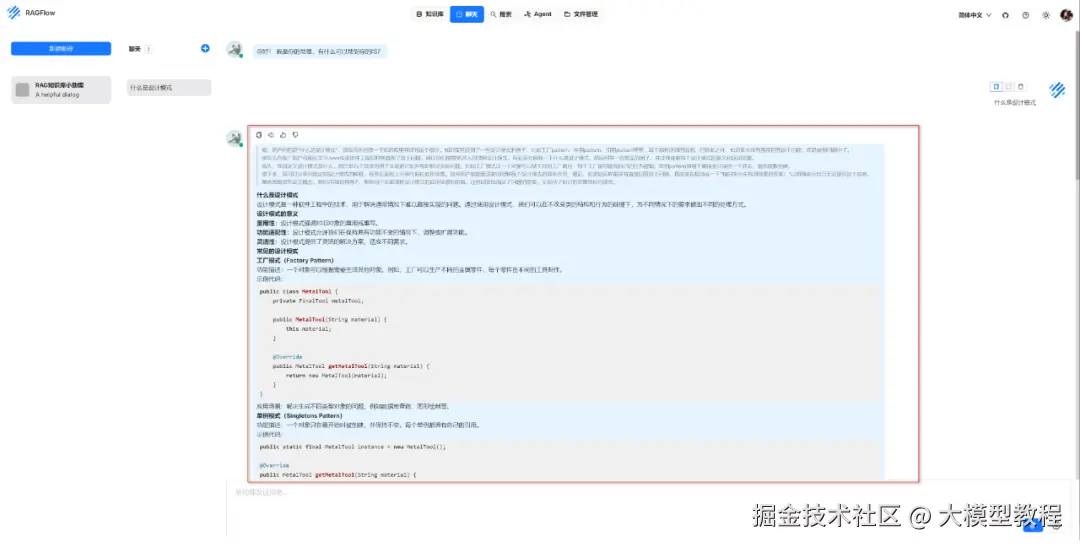
由上图可见,这个本地RAG知识库专属聊天助理,在回答问题思考时,确实有使用到本地知识库------设计模式里的内容。
至此,基于本地RAG知识库的专属聊天助理,已搞定!
接下来,让我们看看 RAGFlow 的智能搜索问答系统的表现如何吧。
3.智能搜索问答系统
步骤1:输入搜索关键词
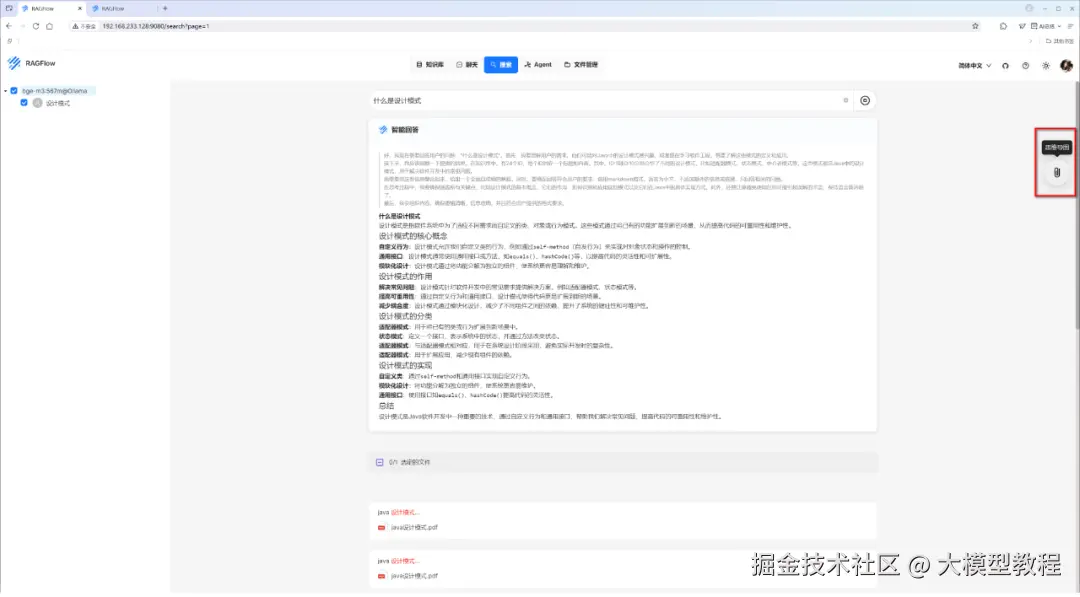
我们点击顶部导航栏中的"搜索"菜单项,确保左侧已勾选了本地RAG知识库------设计模式,此时我们提出相同的一个问题:什么是设计模式,点击"搜索"图标,如下图所示:
步骤2:查看检索结果
检索结果如下:
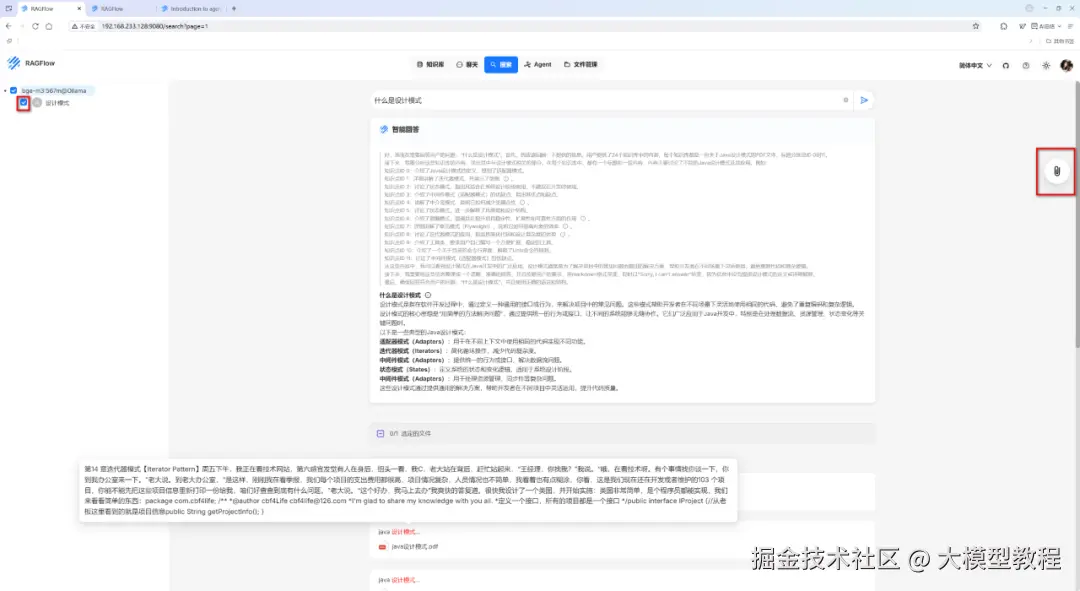
显而易见,智能搜索问答系统,不仅结合本地RAG知识库,给出了回答,并且提供了具体引用的知识库文档内容片段,已基本符合知识库检索预期。
步骤3:查看思维导图
此时,我们可以点击右侧"思维导图",看看效果如何,如下图所示:
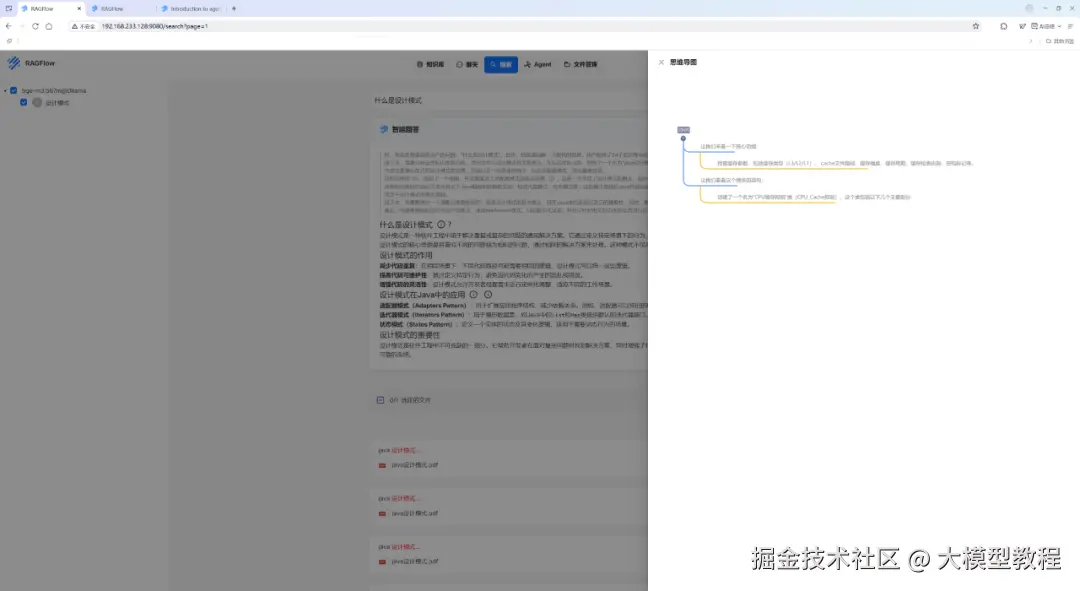
由上图可见,思维导图虽然成功自动生成了,但是思维导图内容与搜索结果内容严重不符,哈哈哈,翻车现场。。。
其实,这是很典型的检索阶段的相关性偏差问题,具体问题表现为:思维导图包含大量低相关甚至无关内容。其原因可能有以下几点:
(1)Embedding 模型不匹配:通用模型(如 text-embedding-ada-002)对专业术语(如医疗、法律)理解不足,检索到错误片段。
(2)Rerank 模型失效:未启用 Rerank 或模型选择不当(如用轻量模型处理复杂查询),导致噪声片段未被过滤。
(3)混合检索未配置:仅依赖向量检索,忽略关键词匹配(如用户搜索"API 调用失败",但向量检索返回"API 设计原则")。
很显然,大概率是因为我们未启用Rerank模型选项所导致的。Rerank模型负责二次精排,显著提升相关性。
rerank 模型,为非必选项:若不选择 rerank 模型,系统将默认采用关键词相似度与向量余弦相似度相结合的混合查询方式;如果设置了 rerank 模型,则混合查询中的向量相似度部分将被 rerank 打分替代。请注意:采用 rerank 模型会非常耗时。如需选用 rerank 模型,建议使用 SaaS 的 rerank 模型服务;如果你倾向使用本地部署的 rerank 模型,请务必确保你使用 docker-compose-gpu.yml 启动 RAGFlow。
接下来,让我们赶快看看 RAGFlow 的Agent智能助手如何应用吧。
4.Agent 智能助手
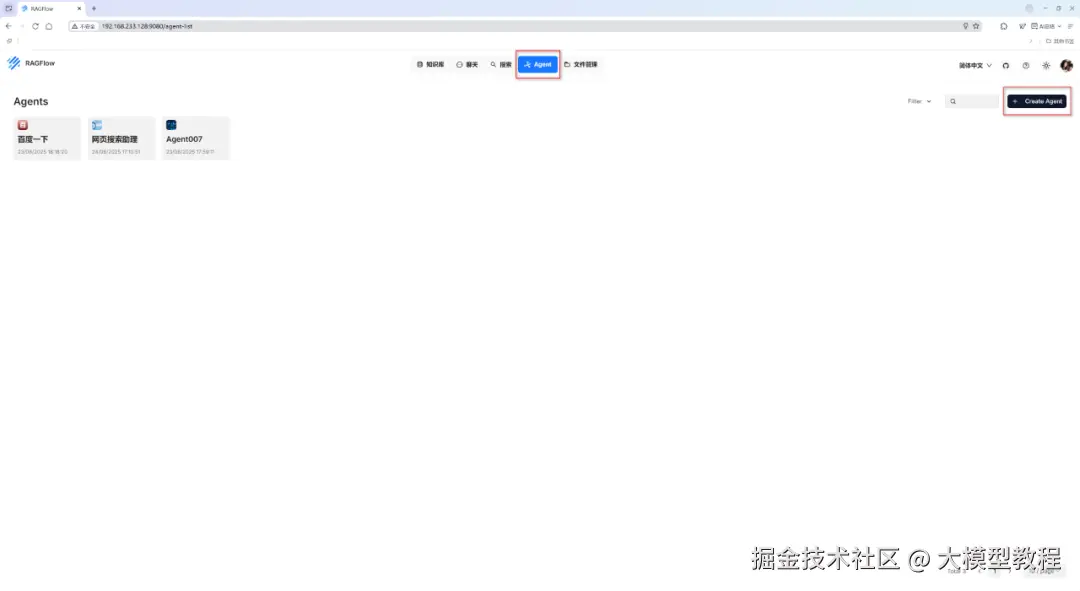
步骤1:创建Agent
首先,我们选中顶部导航栏中的"Agent"菜单项,点击右上角的"Create Agent",如下图所示:
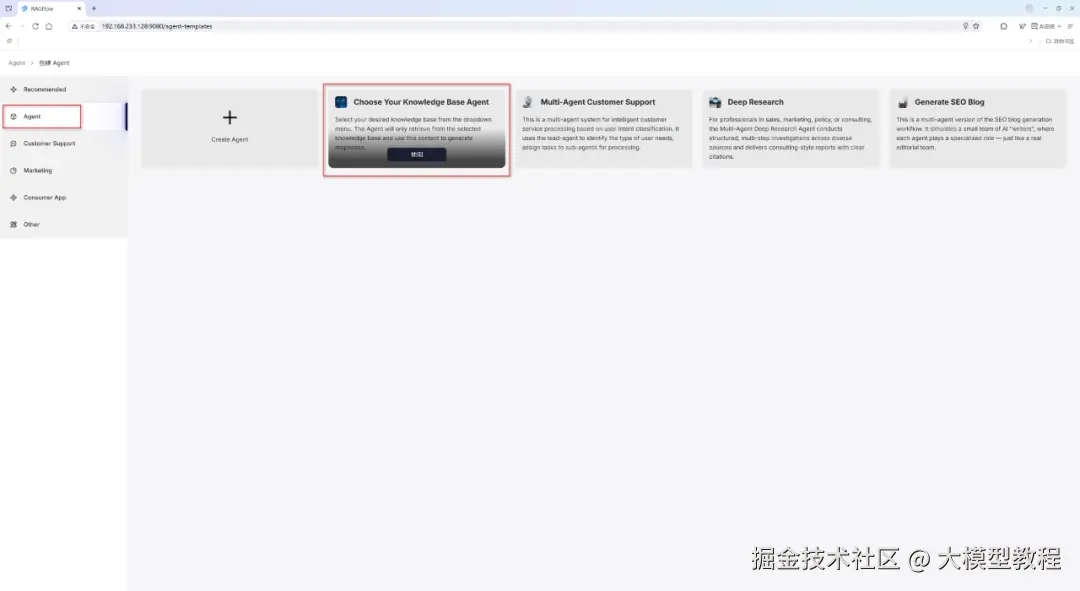
接着,我们选择 RAGFlow 内置的一个基于知识库检索问答Agent模版,如下图所示:
点击Agent版本,输入Agent名称,比如test,即可自动创建出来一个Agent。
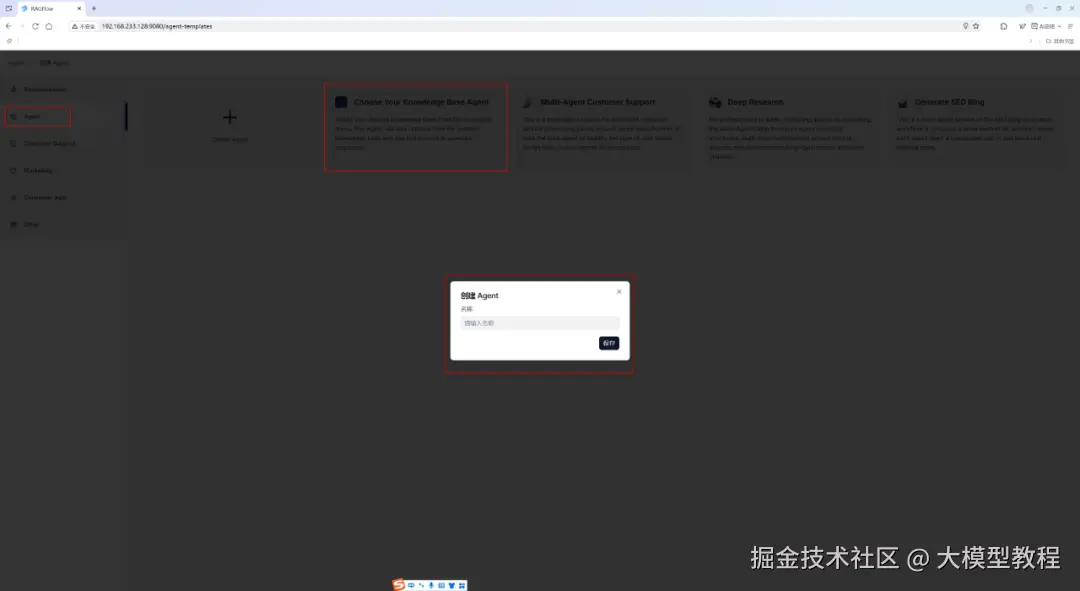
基于该 Agent 模板,我们稍加修改,开始节点编排,如下图所示:
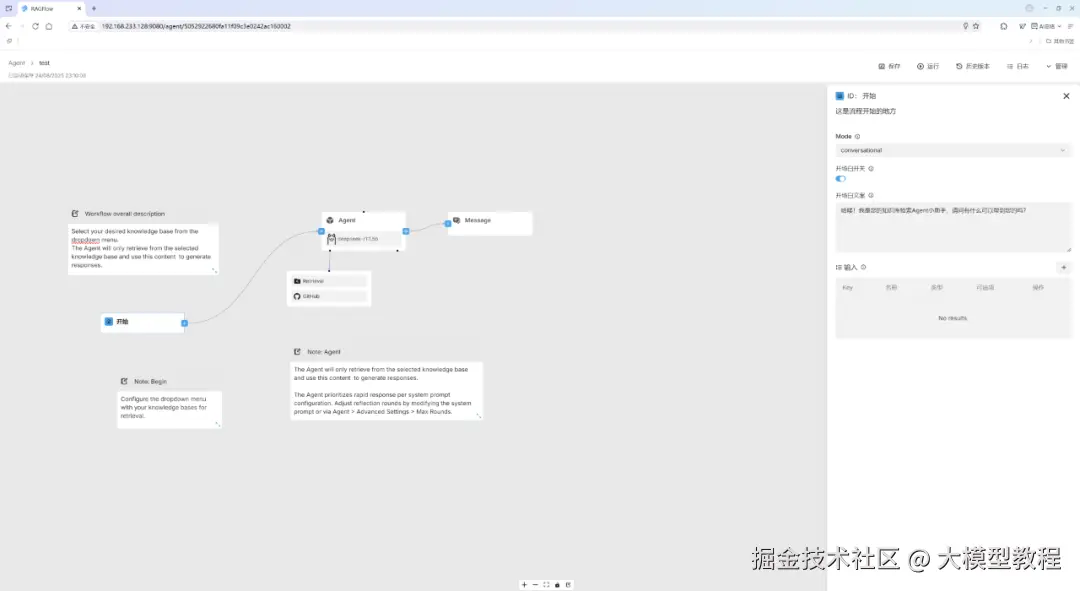
点击加号,即可添加选择任意一个新节点,如下图所示:
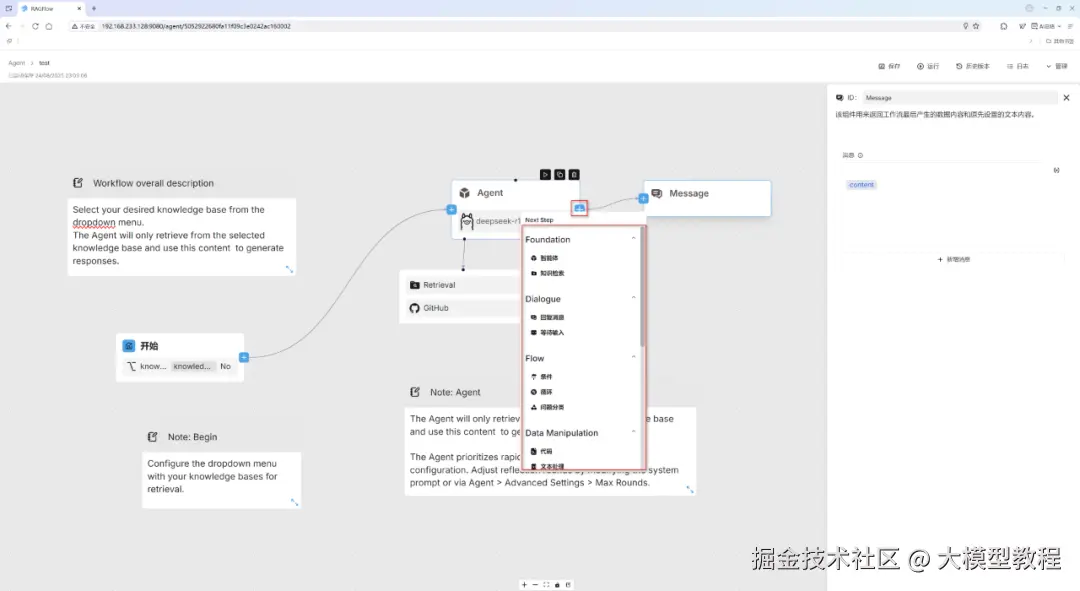
搜索Agent编排,如下图所示:
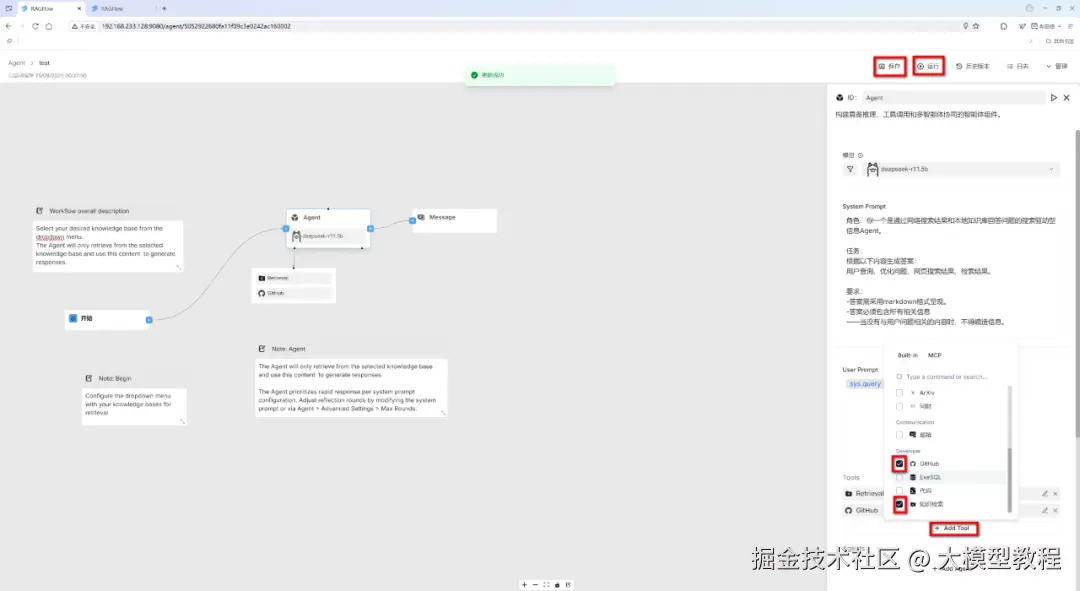
检索本地知识库编排,如下图所示:
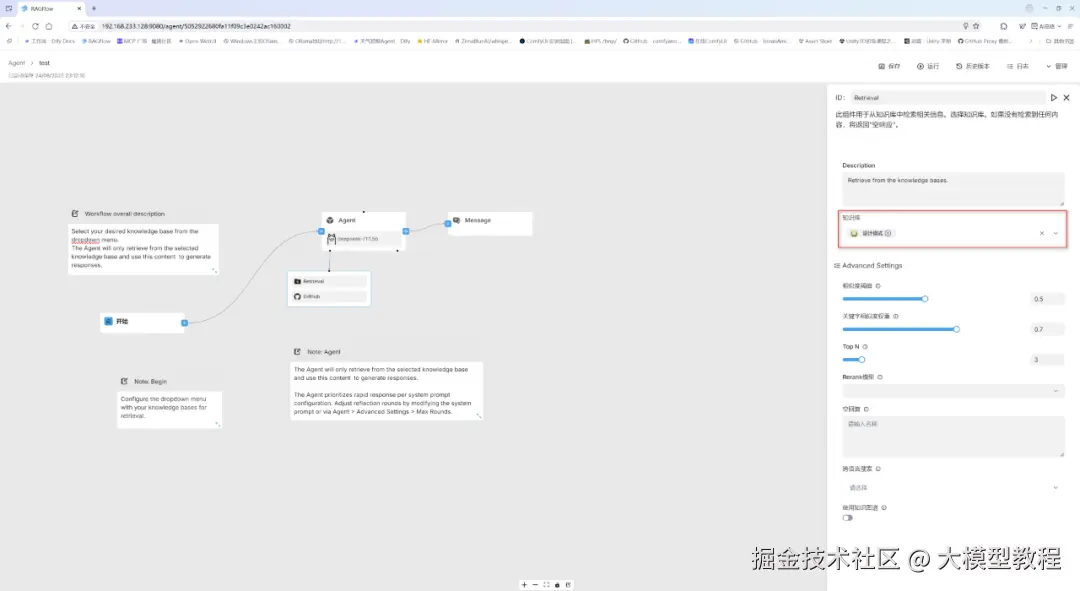
除了在上图中添加本地已构建的专属知识库------设计模式以外,我们再尝试添加一个Github网站搜索工具,并设置高级参数,如下图所示:
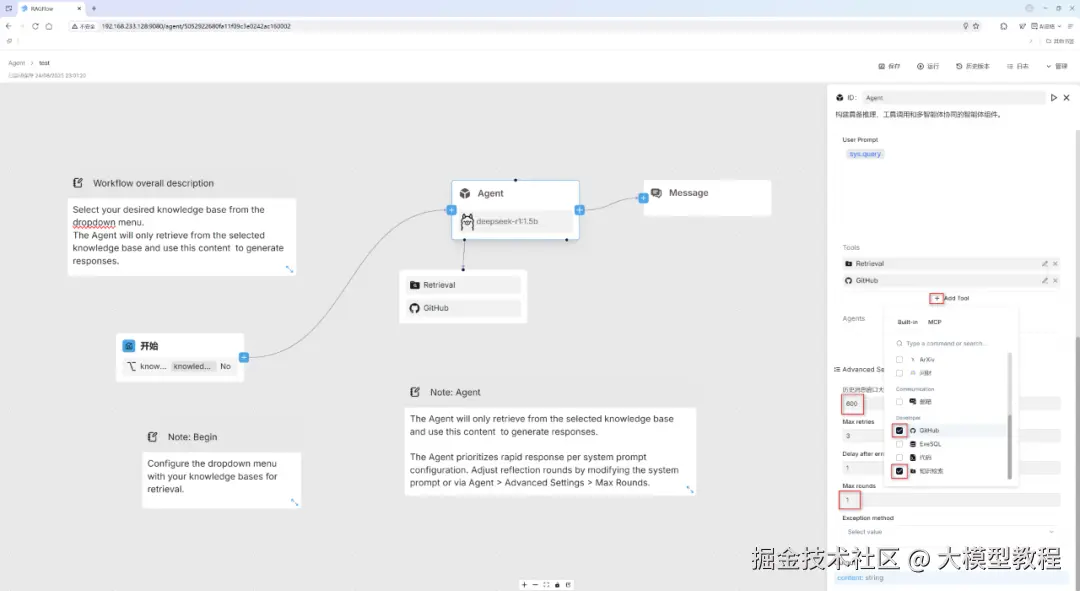
然后,在右上角顶部的点击"保存"按钮。
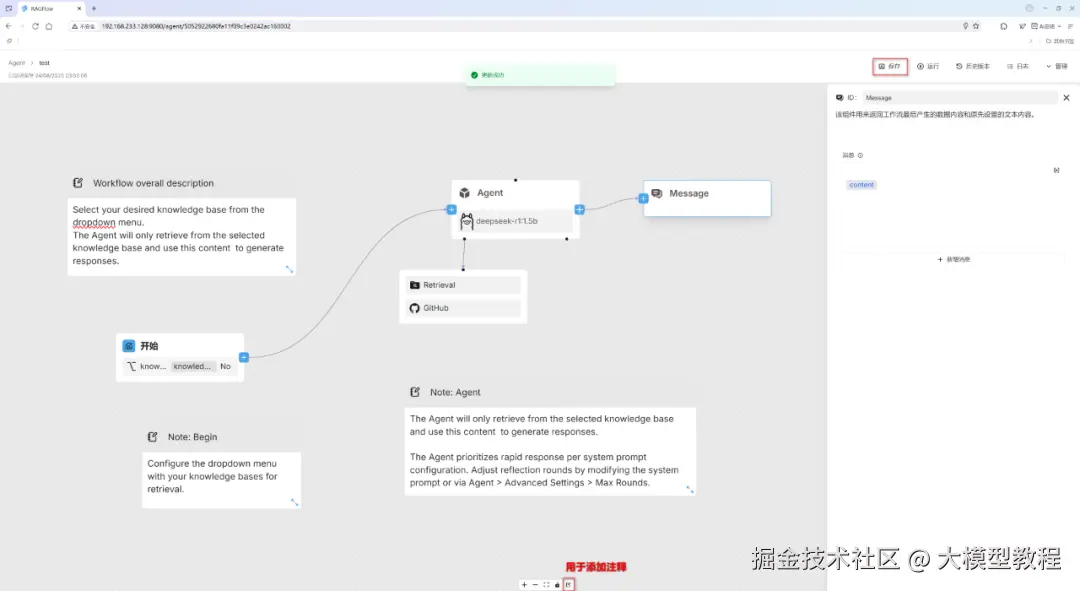
此时,就可以点击"运行",开始尝试运行Agent应用啦。。。
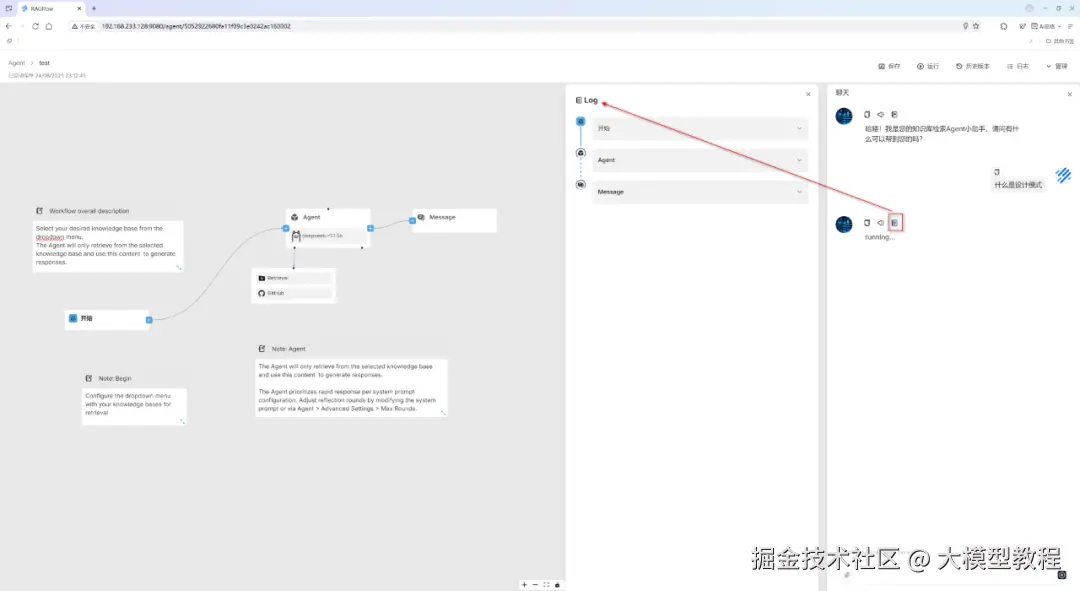
在右下角我们输入提示词:什么是设计模式,按Enter回车键 或者 点击右下角的"搜索"小箭头图标,看看Agent表现效果如何,具体如下图所示:
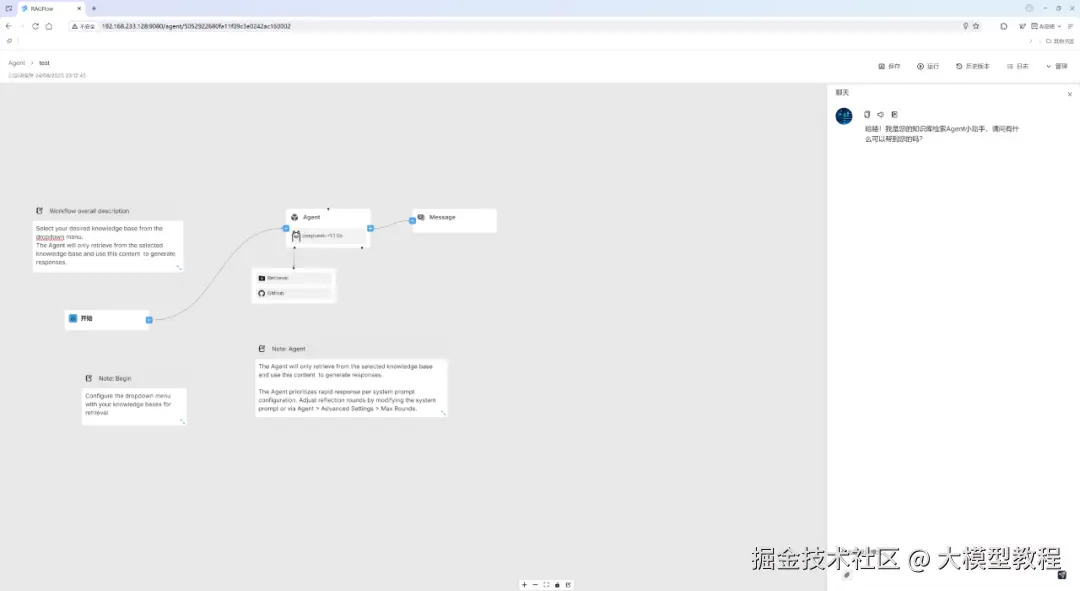
在running...的紧挨着的上方右侧第一个"笔记本"小图标按,支持点击查看Agent实时运行日志Log,如下图所示:
温馨提示:
关于 Agent 节点(即,大模型 LLM)的系统提示词,小伙伴们可以根据各自需求自定义编写哈,这里我建议大家可以先参考一些开源的系统提示词 Prompt 模版,等自己熟练掌握了系统提示词 Prompt 之后,自己再按照自己的想法来自由编写。简而言之,我们要站在巨人的肩膀上,先模仿,再超越嘛!切忌闭门造车!
5.文件管理
文件管理应用模块,主要是用于下载和预览已经上传的文件资料。
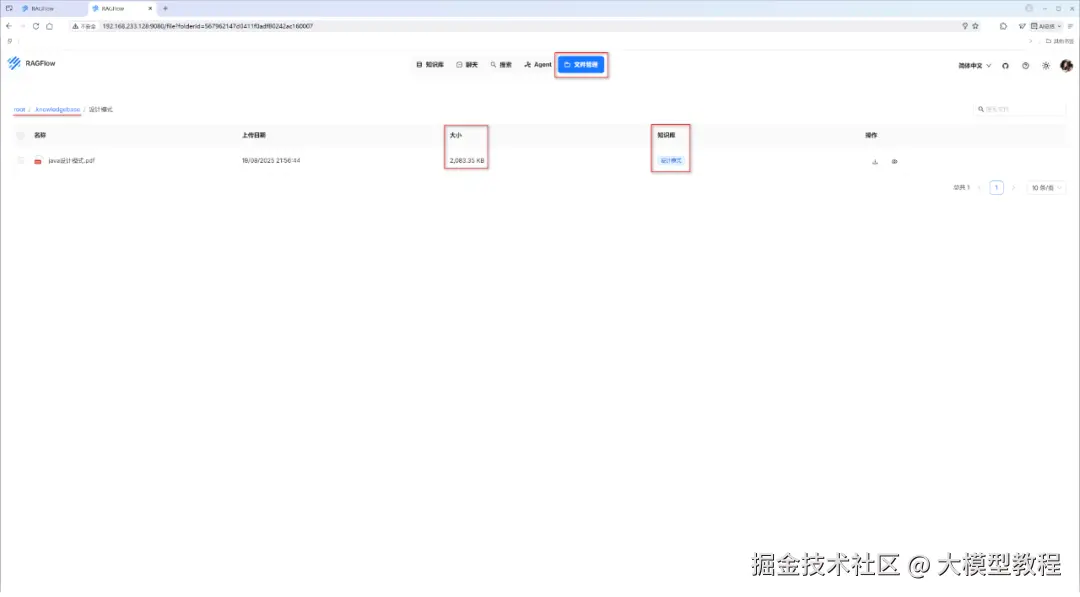
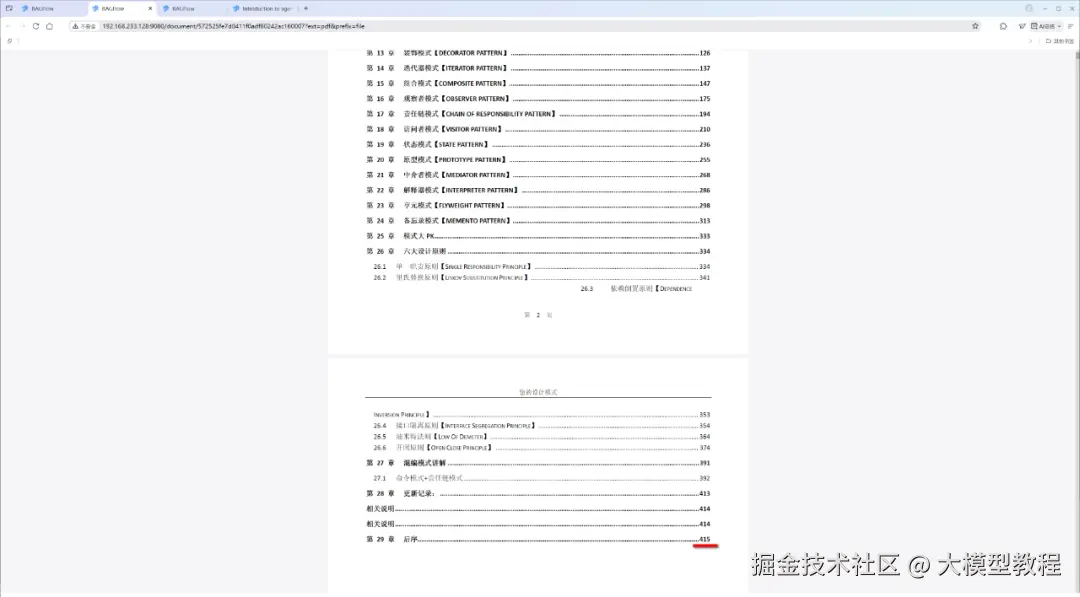
点击上图中"操作"这一列下面的小眼睛图标,即可支持在线预览已上传的文件内容,如下图我们可以清楚的看到,已上传解析处理的《java设计模式》pdf文档,共计有415页。
6.常见问题与解决方案
问题1:RAGFlow 登录报错502(Bad Gateway)
如下图所示:
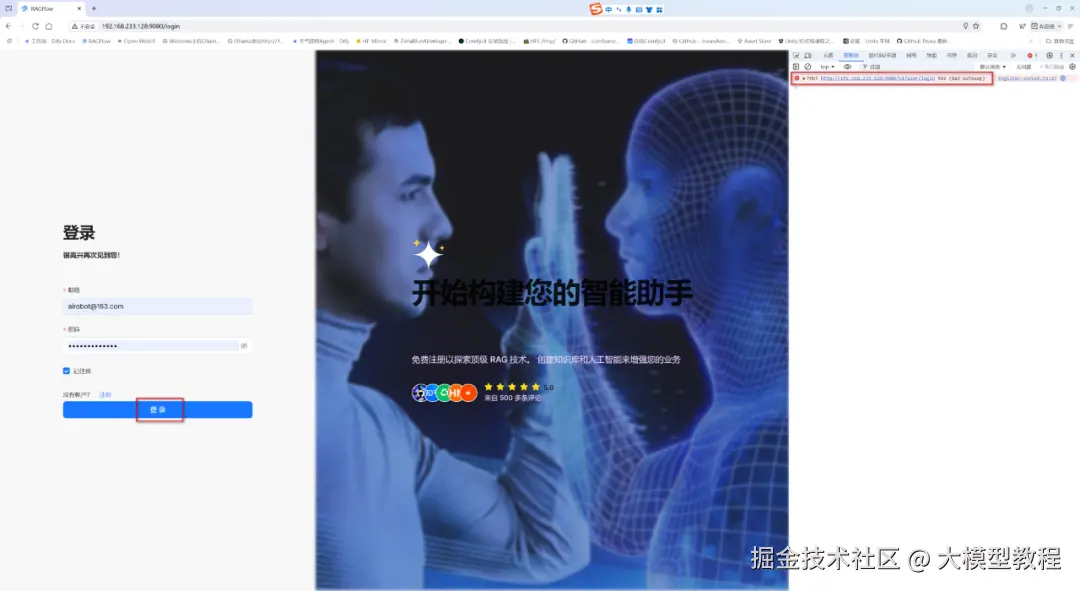
原因分析:
502状态码(Bad Gateway)是一种HTTP协议的服务端错误状态代码,表示作为网关或代理的服务器从上游服务器接收到的响应无效。
这说明RAGFlow有个Base基础服务没有成功启动,我们需要检测一下后端是否正常。
解决方案:
进入docker目录下,重启执行安装基础服务,命令行如下:
sudo docker-compose -f docker-compose-base.yml --profile infinity up -d
其中,使用 --profile infinity参数时,只有里配置了infinity配置文件的服务会被启动。
具体如下图所示:
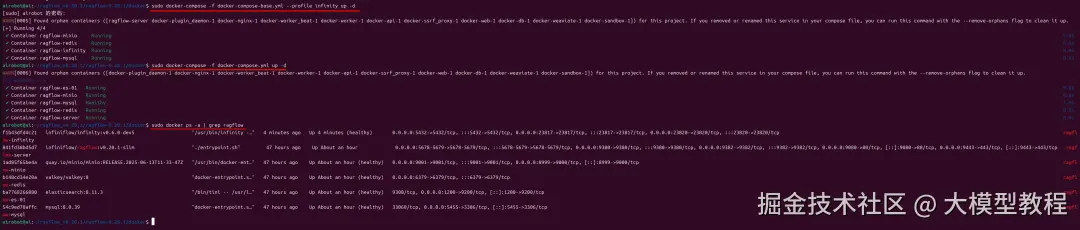
问题2:构建知识库时,上传文档在解析过程中报错:Page(109~121): ERRORGenerate embedding error:Function 'batch_encode' timed out after 5 seconds and 2 attempts.
如下图所示:
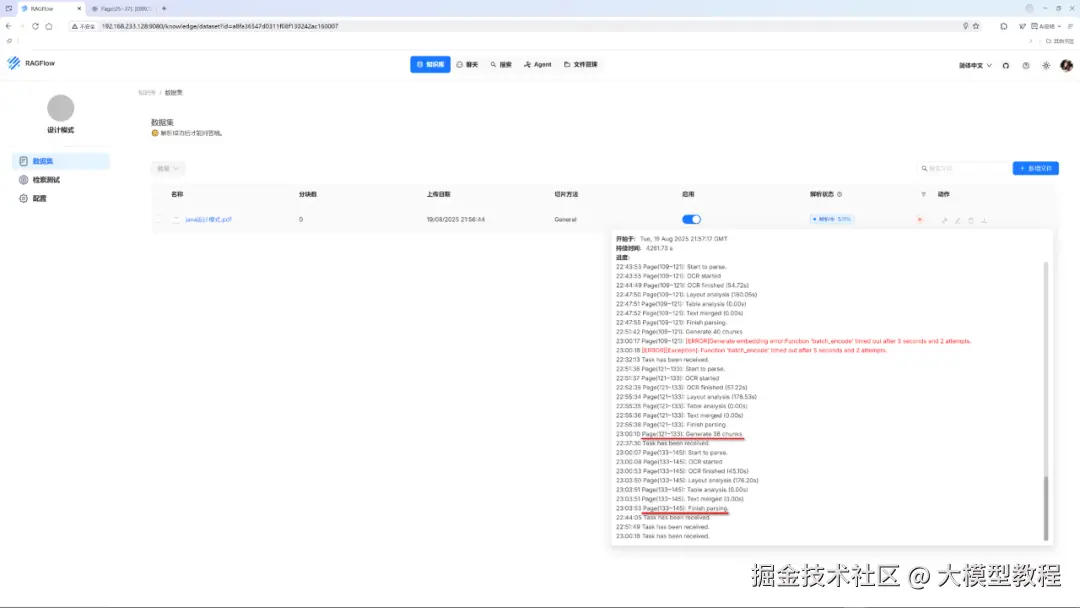
原因分析:
从错误信息来看,batch_encode 函数在尝试生成嵌入时超时了。这可能是由于处理的数据量较大,或者函数本身的性能问题导致的。
解决方案:
在"切片方法"中,结合硬件性能,适当调小"任务页面大小"数值。这里,我设置为1,成功解决了该问题。小伙伴们可供参考。
关于"General" 分块方法说明:
支持的文件格式为MD、MDX、DOCX、XLSX、XLS (Excel 97-2003)、PPT、PDF、TXT、JPEG、JPG、PNG、TIF、GIF、CSV、JSON、EML、HTML。
此方法将简单的方法应用于块文件:
系统将使用视觉检测模型将连续文本分割成多个片段。
接下来,这些连续的片段被合并成Token数不超过"Token数"的块。
关于"任务页面大小"参数说明:如果使用布局识别,PDF 文件将被分成连续的组。 布局分析将在组之间并行执行,以提高处理速度。 "任务页面大小"决定组的大小。 页面大小越大,将页面之间的连续文本分割成不同块的机会就越低。
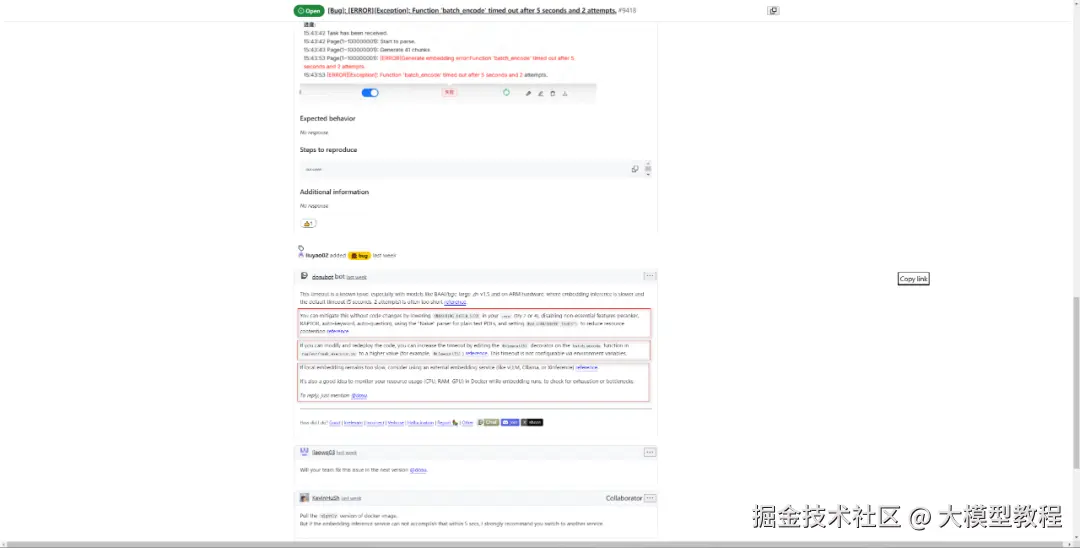
当然,GitHub官网上关于该问题也有一些其他的解决方案可供小伙伴们参考,具体如下图所示:
7.小结
本文带领小伙伴们一起初步探索体验了 RAGFlow 的强大功能。
总体而言,RAGFlow 是一个开源的检索增强生成(RAG)引擎,目前已构建提供了一个轻量级且相对完整的AI应用框架,通过知识库管理、智能搜索、Agent编排、文件处理四大核心模块,实现企业级知识驱动应用。其架构融合向量检索、Rerank重排序与LLM生成,精准匹配用户查询与知识库内容,支持多模态文档解析与自定义工作流。通过优化检索-生成链路,显著提升答案准确率、降低幻觉,并保障数据安全与可扩展性,适用于智能客服、文档分析等场景。
当然,RAGFlow 仍有提升空间:一是内置的工具插件与 Agent 模板数量还不够丰富;二是Agent编排界面的操作便捷性,相较于Dify工作流编排稍显逊色。当然,每个产品定位和在不同发展阶段各有侧重点,RAGFlow 当前的核心优势在于构建知识库,并深度结合大模型(如DeepSeek-R1)生成精准、上下文相关的回答。
好啦,今天的内容就先介绍到这里,对本地搭建 RAG 专属知识库与智能助手感兴趣的小伙伴们,不妨亲自体验一下 RAGFlow,赶快开启你的专属知识库与智能应用探索之旅吧!
Come on,Baby!
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。