背景
将大语言模型用于时间序列分析在近年来备受关注,但其仍然面临几个关键挑战没有被很好解决:
模态(modality)对齐问题:时间序列数据与语言文本是不同模态的。如何有效地把时间序列输入与自然语言提示(prompt)结合起来,让 LLM 能理解时间序列的语义或结构,而不仅仅是把时间序列当成一串数字强行塞进去?现有方法常用跨 attention 或 prompt 或 reprogramming module/tokenization,但仍未达到既高效高质量对齐的状态。
多变量时间序列效率和延迟问题:对于 multivariate time series(多个变量/通道的时间序列),当前很多方法把任务拆成多个 univariate 子任务来预测,这在 inference(推理/预测)阶段引起较大延迟,因为要对每个变量单独做预测。
LLM backbone 固定 vs 可调问题:已有工作常常把 LLM 的主干(backbone)冻结,只在其外增加模块/tokenization/prompting,这是节省参数、保持效率的一种方式,但也可能限制模型对时间序列预测任务的适应性。究竟是不是有可能在"参数有效率"的前提下,对 LLM 的部分内部进行调整,从而提升性能?这是一个未被完全解决的问题。
few-shot / zero-shot 情况下的性能:在很多实际应用里,时间序列数据可能稀缺,或者任务规格变化快,不可能为每个任务准备非常大规模的数据。一个有效的模型应当在 few-shot 或受限数据情况下也表现稳健。现有方法在这点还不一定都能很好。
为了解决这些问题,来自南洋理工大学等的研究团队提出了一种创新模型Time-LlaMA,一个将 LLM 用于时间序列预测的新框架。该文章已中稿ACL 2025。
我整理了ACL 2024-2025年时间序列领域相关论文,感兴趣的可以dd~
相关论文

论文标题:Adapting Large Language Models for Time Series Modeling via a Novel Parameter-efficient Adaptation Method
论文链接:https://arxiv.org/pdf/2502.13725
Time-LlaMA
Time-LlaMA的核心思想是通过引入高效的适配机制,让大语言模型能够自然地理解和处理时间序列数据。其设计有三个关键组件,时间序列 Tokenization 模块,模态对齐模块和动态低秩适配模块(D-LoRA)。框架如图1。
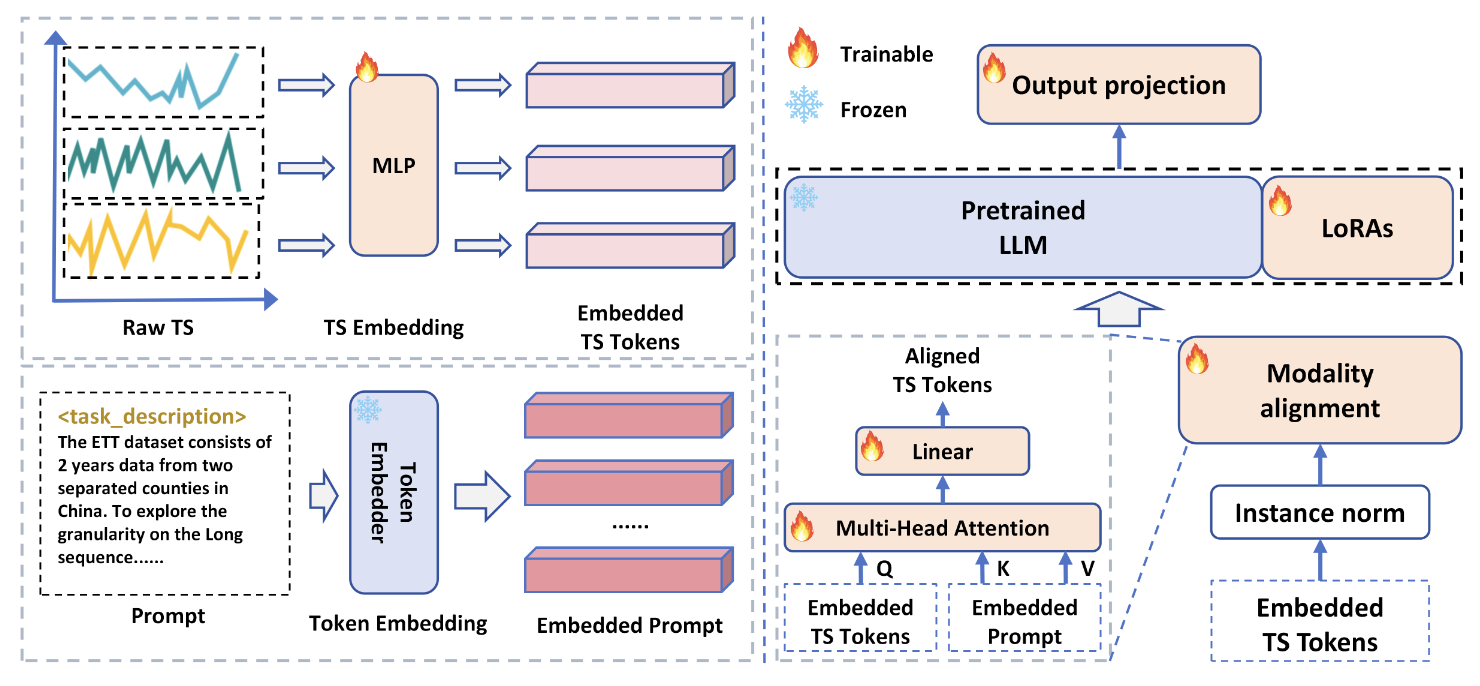
时间序列 Tokenization 模块
传统的时间序列数据是连续的数值信号,而 LLM 的输入需要被离散化为 token 表示。为此,Time-LlaMA 借鉴自然语言处理中 tokenizer 的思想,将时间序列切分成一系列可学习的片段,并通过向量化映射形成 token 表示。这样一来,连续的时间点被转化为离散的 token 序列,保证了数据格式与 LLM 输入的一致性,同时保留了原始序列的时序结构与局部变化特征。

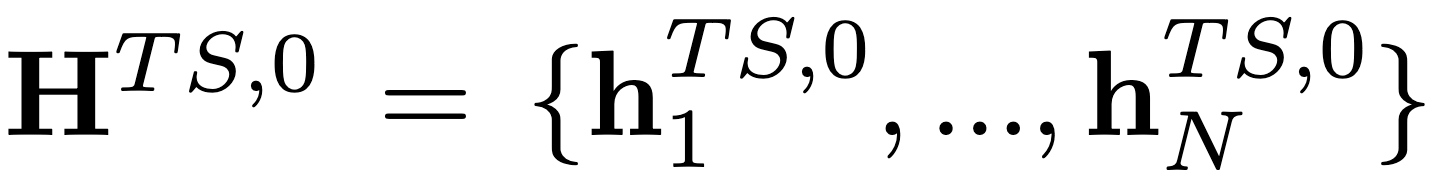
模态对齐模块
由于时间序列和自然语言在分布特性和表示空间上存在显著差异,直接把时间序列 token 喂入 LLM 会导致信息失真和语义错位。Time-LlaMA 为此设计了一个高效的投影网络,用于将时间序列 token 的表示映射到与语言 token 相容的嵌入空间中。
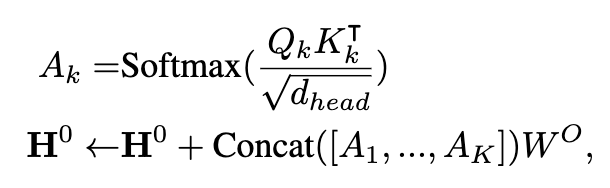
这个对齐过程不仅保证了数据在输入 LLM 时不会丢失关键的动态特征,还让时间序列与语言信息能够在同一个表示空间中自然融合,使得 LLM 能在"无缝衔接"的条件下接管预测任务。
动态低秩适配模块(D-LoRA)
为了进一步提升适配效率,Time-LlaMA 在参数更新策略上引入了 动态低秩适配模块(D-LoRA)。D‑LoRA 对传统 LoRA 进行了改进,引入了 动态选择机制,根据每条输入序列动态决定激活哪些低秩子模块,从而兼顾预测精度和计算效率
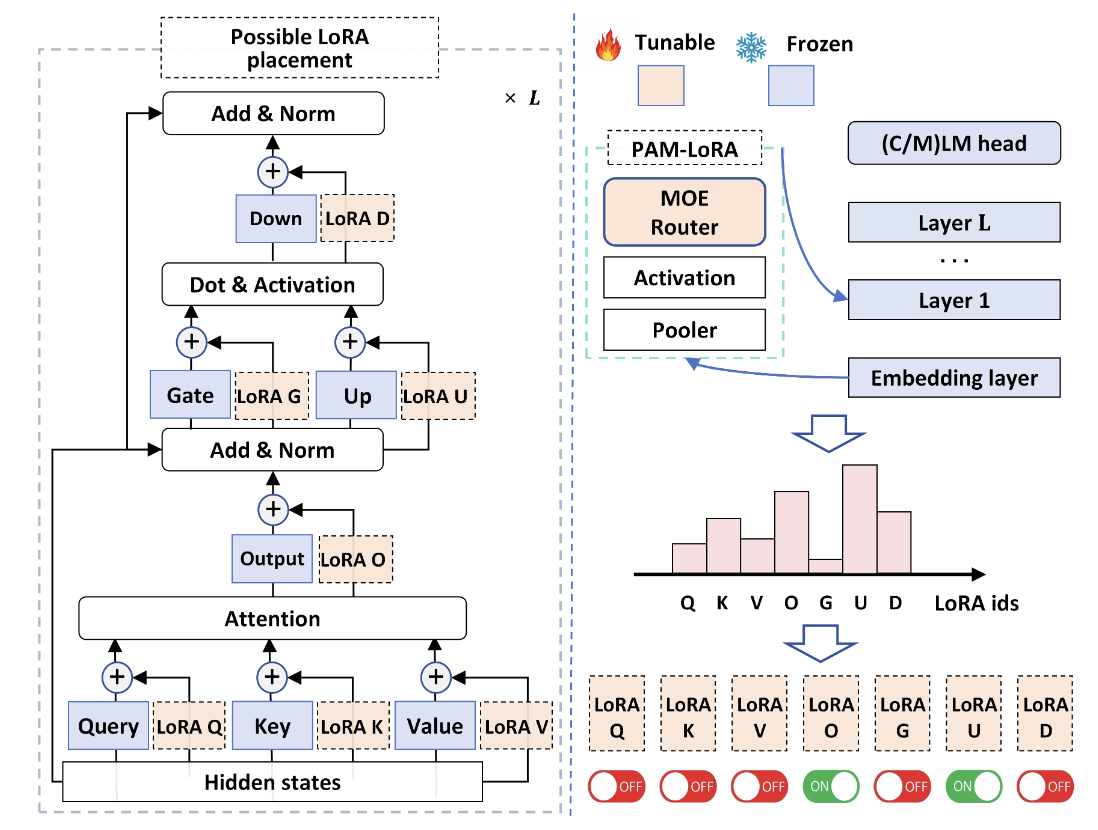
如图2,Time-LlaMA 则提出了动态调整的思路:模型会根据输入序列的复杂度自适应地决定秩的大小。如果当前序列包含更复杂的非线性模式,D-LoRA 会分配更高的秩以保证表达能力;而在模式相对简单的序列中,则通过低秩来减少计算开销。
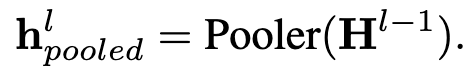
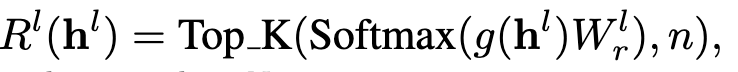
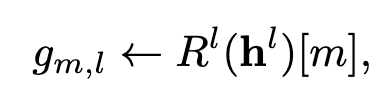
这种自适应的机制使得 Time-LlaMA 在预测精度和计算效率之间取得了理想平衡,让大语言模型能够在时间序列任务中实现既强大又高效的适配。
预测输出
预测头通过一个专门的线性投影层,将 LLM 的高维语义表示转化为具体的数值预测结果,从而完成从"语言式理解"到"时间序列输出"的闭环
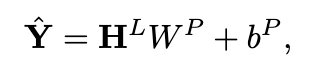
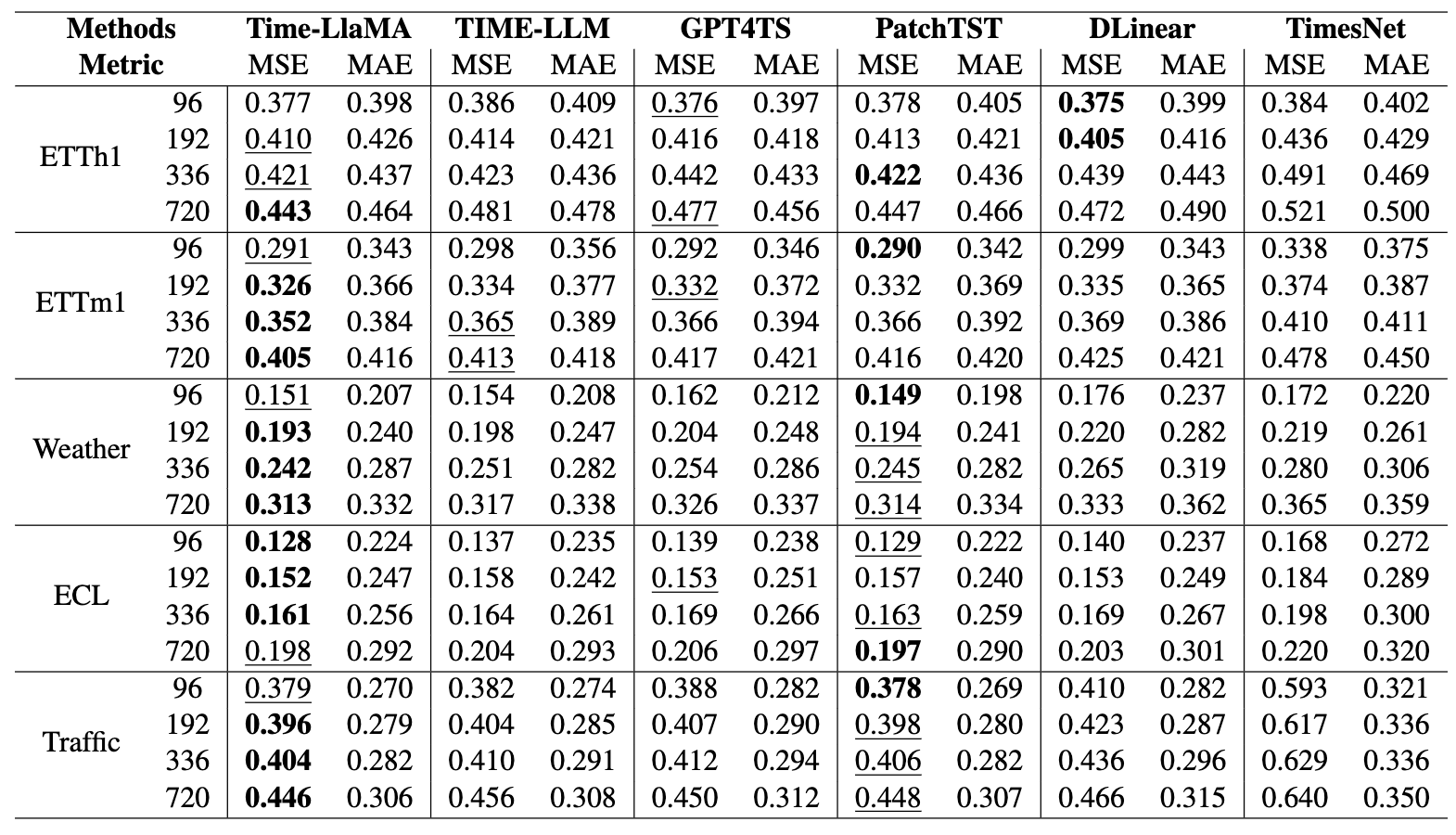
实验分析
长期预测
在这些任务中 Time-LlaMA 多数情况下优于所有基线模型,包括最近的 LLM-based 方法如 Time-LLM 和 GPT4TS,也优于传统强基线如 PatchTST、DLinear、TimesNet
短期预测
在 M4 基准的评测中,Time-LlaMA 用短期预测(horizon 如 6 步,48 步等)也显著优于其他方法,在指标 SMAPE、MSAE、OWA 上均是最优或接近最优

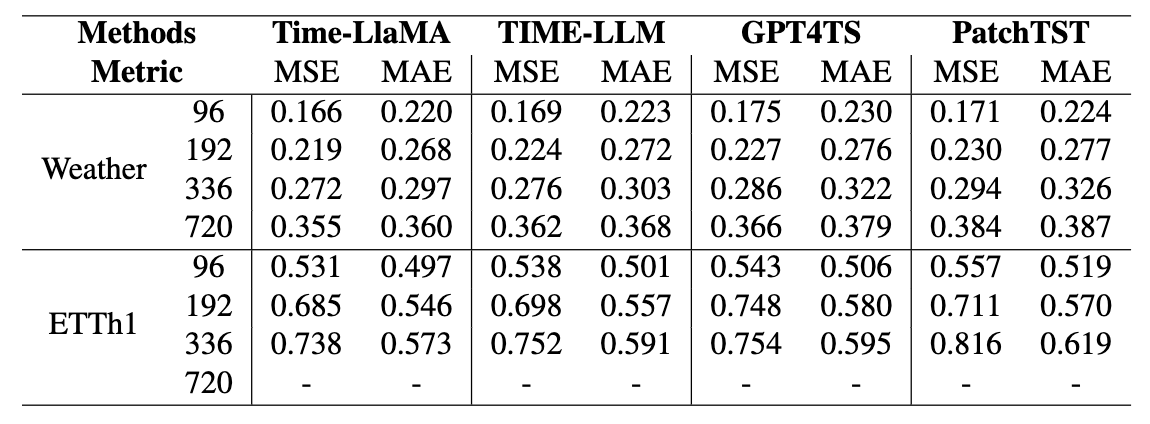
Few-shot 场景
在训练数据非常稀少的情况下(例如只用训练集的 5% 时间步),在 Weather、ETTh1 等数据集上,Time-LlaMA 依然比其他强基线保持明显优势。显示出其在少样本设置上的泛化能力
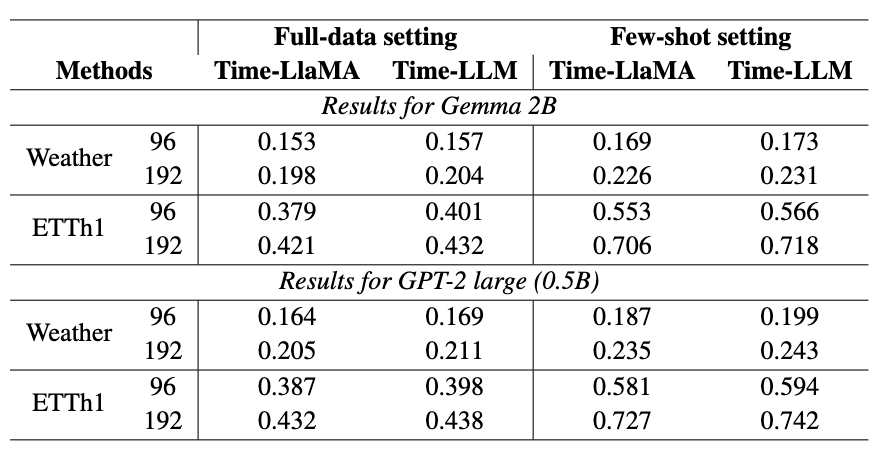
对比不同 backbone 的实验
作者也在 Gemma 2B、GPT-2 large 等不同的预训练模型上做对比。结果表明,Time-LlaMA 方法在这些 backbone 上依然优于 Time-LLM 等,仅用少量额外参数就达到或超过 baselines。表明方法具有普适性
结论
Time-LlaMA 显示:大语言模型 不必仅局限于语言任务,可以通过恰当的 tokenization + 模态对齐 + 参数高效的内部适配(如动态低秩 LoRA)有效地迁移到时间序列预测任务。如果你对时间序列/大模型/跨模态学习/少样本学习有兴趣,这篇论文值得仔细研究。