在大模型重塑人工智能格局的今天,语音作为最自然的人机交互方式,其技术演进正从"能用"迈向"好用"。企业对语音识别系统提出了前所未有的综合要求:不仅要在复杂场景下保持高准确率,还需满足实时性、高并发与工程落地的严苛挑战。
在此背景下,由阿里达摩院语音团队主导研发的 FunASR 应运而生。它并非一个孤立的模型或工具,而是一个面向产业落地的端到端语音识别统一框架 ,集成了从语音前端处理、核心识别、标点恢复到热词增强的完整链路,尤其以创新的 Paraformer 非自回归模型为核心,在精度、速度与部署效率之间实现了前所未有的平衡。
蒙帕基于 FunASR 的先进技术架构,深度融合于自研的智能机房巡检机器人系统 ,成功实现了在高噪声、多干扰的工业环境下,机器人与运维人员之间的实时语音交互能力 。传统巡检场景中,操作人员需通过手持终端或远程平台查看设备状态,响应流程繁琐、交互效率低。而蒙帕机器人通过集成 FunASR 的流式语音识别与端点检测(VAD)能力,支持"边说边识别"的自然对话模式,运维人员可随时通过语音指令查询设备温度、环境情况、告警状态等关键信息,实现"即问即答"的高效交互体验。

一、从碎片化到一体化:FunASR 的系统级设计理念
长期以来,语音识别系统的搭建往往依赖多个独立模块的拼接:VAD 切分语音、ASR 模型识别、标点模型后处理、热词干预等。这种"积木式"架构不仅开发成本高,且各模块间误差累积严重,难以保证端到端的稳定性。
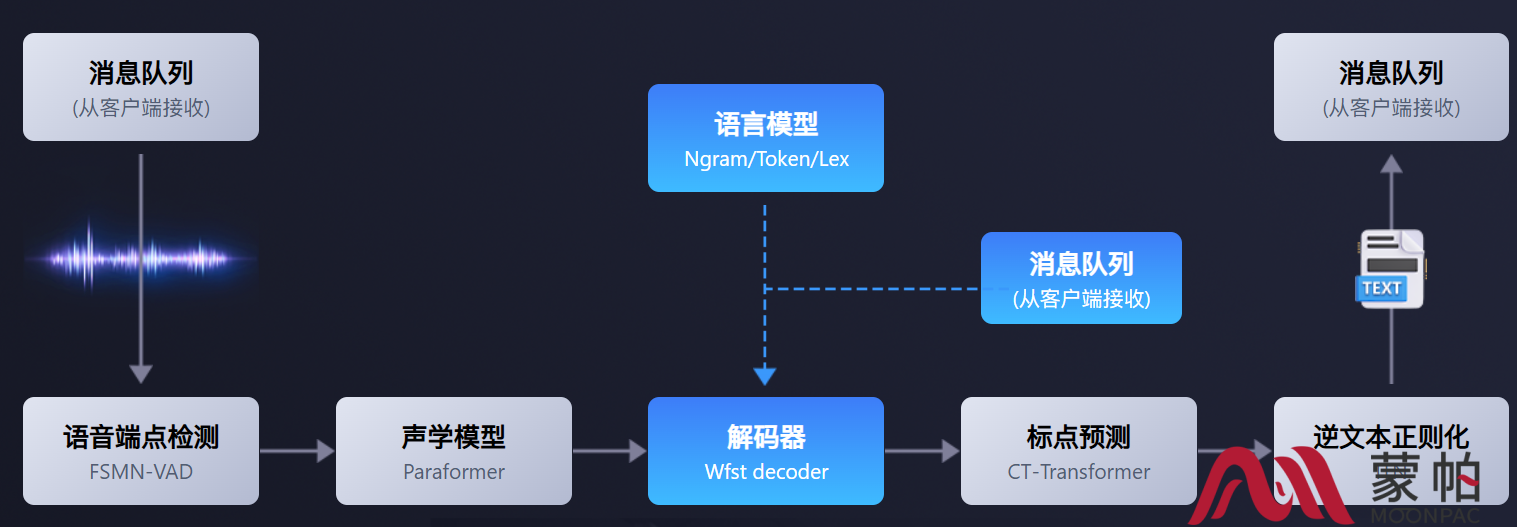
FunASR 的核心目标,是打破这种割裂状态,构建一个功能完整、接口统一、可扩展性强的语音智能平台。其整体架构涵盖以下关键能力:
语音识别(ASR):支持中文、英文及多语种识别,覆盖流式与离线两种模式。
语音活动检测(VAD):自动识别语音起止点,过滤静音段,提升处理效率。
标点与格式恢复(PUNC):将原始识别文本转化为具备可读性的自然语言输出。
热词与领域适配:支持动态注入关键词,显著提升专有名词、新词和术语的识别准确率。
模型服务化支持:提供 HTTP、WebSocket 接口,支持 ONNX、TensorRT 等格式导出,便于部署至 GPU、CPU 或边缘设备。
通过这一集成化设计,FunASR 显著降低了语音识别系统的开发门槛,使得企业能够快速构建稳定、高效的语音处理流水线。
二、核心技术突破:Paraformer 实现速度与精度的双重跃升
在传统语音识别模型中,自回归架构(如 Transformer、RNN-T)虽然识别精度高,但其逐字生成的机制导致推理过程串行化,难以满足低延迟、高吞吐的工业需求。
FunASR 的核心创新在于引入了 Paraformer(Parallel Transformer) ------一种基于非自回归范式的端到端语音识别模型。该模型通过结构设计与训练策略的协同优化,在保持高识别精度的同时,实现了数量级的推理加速。
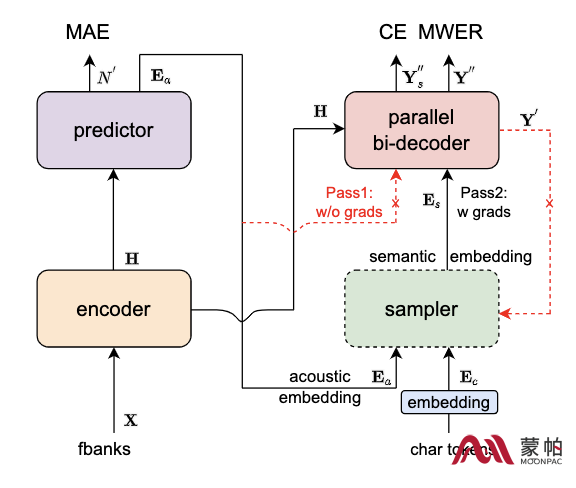
Paraformer模型结构如上图所示,由 Encoder、Predictor、Sampler、Decoder 与 Loss function 五部分组成。Encoder可以采用不同的网络结构,例如self-attention,conformer,SAN-M等。Predictor 为两层FFN,预测目标文字个数以及抽取目标文字对应的声学向量。Sampler 为无可学习参数模块,依据输入的声学向量和目标向量,生产含有语义的特征向量。Decoder 结构与自回归模型类似,为双向建模(自回归为单向建模)。Loss function 部分,除了交叉熵(CE)与 MWER 区分性优化目标,还包括了 Predictor 优化目标 MAE。
1. 非自回归架构的本质优势
与自回归模型逐词预测不同,Paraformer 采用并行解码机制,能够在一次前向传播中生成整句文本。这一特性从根本上消除了生成过程中的序列依赖,大幅降低了尾延迟,尤其适用于实时字幕、会议转录等对响应速度敏感的场景。
然而,非自回归模型也面临两大挑战:
如何准确预测输出序列的长度?
如何在缺乏上下文依赖的情况下保持语义连贯性?
Paraformer 通过以下三个关键组件系统性地解决了这些问题。
2. 长度预测与声学对齐:Predictor 模块的设计
Paraformer 引入了一个轻量级的 Predictor 网络,用于预测目标文本的长度。该模块基于编码器输出的声学特征,通过累加机制(CIF, Continuous Integrate-and-Fire)实现语音帧到子词单元的软对齐。
在训练阶段,Predictor 通过监督信号(如真实文本长度)进行优化,确保在推理时能够稳定地生成合理的输出长度。这一机制有效缓解了传统非自回归模型因长度误判导致的插入或删除错误。
3. 上下文语义建模:Sampler 模块的引入
为克服非自回归模型在语义一致性上的短板,Paraformer 设计了 Sampler 模块,其灵感来源于机器翻译中的 Glancing Language Model(GLM)。该模块在训练过程中,通过采样真实标签的上下文信息,生成富含语义的特征向量,作为解码器的输入。
这一设计使得模型在训练阶段"看到"了上下文依赖,而在推理阶段仍保持并行解码的高效性,从而在不牺牲速度的前提下增强了语义建模能力。
4. 多任务联合训练:CTC 与非自回归目标的协同优化
Paraformer 采用 CTC + NAR 解码损失 的联合目标函数进行训练。CTC 作为辅助任务,提供了强对齐信号,有助于稳定训练过程,尤其是在长语音和噪声环境下提升鲁棒性。
此外,模型还支持 MWER(Minimum Word Error Rate)等区分性训练准则,进一步优化最终的识别性能。
三、工程优化:从实验室到生产环境的全栈支持
FunASR 不仅在算法层面领先,更在工程实现上充分考虑了工业部署的实际需求。
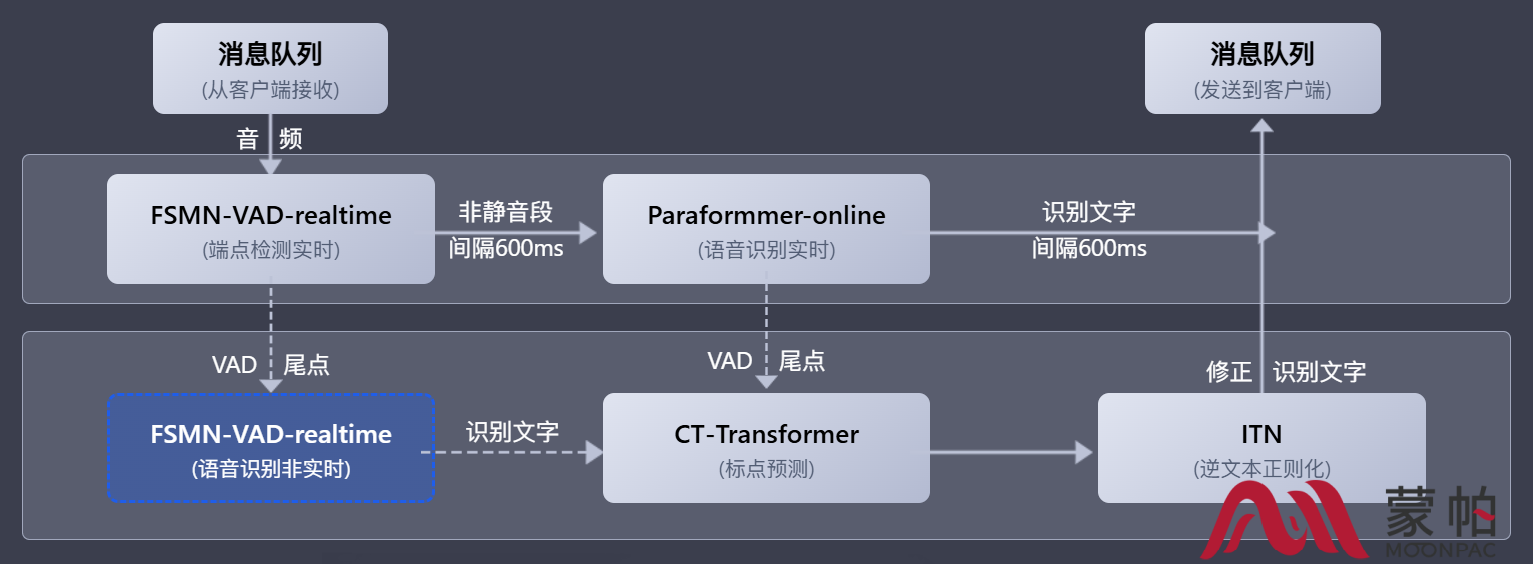
1. 流式与离线统一的推理架构
FunASR 支持流式识别 与离线批处理两种模式,并通过统一的接口进行调用。在流式场景中,系统采用分块编码与右看上下文缓存机制,确保在低延迟的同时维持较高的识别准确率。
对于长语音转写任务,系统支持自动分段、上下文拼接与一致性控制,避免跨段落的语义断裂。
2. 高吞吐与低资源消耗
得益于 Paraformer 的并行解码特性,FunASR 在相同硬件条件下可承载的并发请求数远超传统自回归模型。实验表明,在 GPU 环境下,其吞吐量可达自回归模型的 8--10 倍。
同时,框架支持模型量化(INT8/FP16)、剪枝与 ONNX/TensorRT 导出,显著降低推理资源消耗,适用于云端高并发服务与边缘端轻量部署。
3. 可配置的后处理能力
FunASR 内置了丰富的后处理模块,包括:
自动标点添加
数字格式化(如"2025"转为"二零二五"或保持阿拉伯数字)
大小写还原
热词强制对齐
这些功能可根据业务需求灵活开启或关闭,确保输出结果符合实际应用场景。
四、结语:语音识别的工业化之路
蒙帕结合机房特有的专业术语,利用 FunASR 的热词增强与领域适配机制,显著提升了专有名词与缩略语的识别准确率。同时,通过模型轻量化与本地化部署,确保语音处理全程在边缘端完成,无需联网,兼顾低延迟与数据安全性,满足数据中心对稳定性和隐私保护的严苛要求。
这一融合不仅让巡检机器人从"自动行走的摄像头"进化为"可对话的智能助手",更推动了机房运维向智能化、人性化迈出了关键一步。未来,蒙帕将持续深化与前沿语音技术的融合,拓展语音指令控制、异常语音告警识别等新功能,打造真正具备"听、看、判、报"一体化能力的下一代智能巡检终端。
