目录
[b、step 和 epoch的核心关系](#b、step 和 epoch的核心关系)
最近项目在搞一个音色克隆功能,具体来说就是用户上传一段自己的音频,然后上传一首歌,可以将这首歌人声 音色转化为 用户自己的音色,实现唱歌功能,一般可以用自己喜欢的动漫角色训练然后唱歌,都非常不错~
说在前面的话
本人在经历了一番痛苦的环境依赖折磨后,又经历了模型生成效果差,有电音,杂音等,真的测试付出了不少精力,测试不同的测试集的质量的影响,比如去混声,底噪,杂声后,又测试不同推理源对于结果的影响,然后调整模型的不同参数的影响。
最后得出的一个结论:
SO-VITS-SVC4.1模型对于训练集和推理源的音频质量要求极高,不能混有任何杂声,底噪,否则效果将会出现哑音,电音,杂音等;
DDSP-SVC 6.3 基于rectified-flow模型,对训练集和推理源质量要求低,训练时间低(快SO-VITS-SVC 10倍左右,平常的人声训练100步左右就有很好的结果) ,而且推理效果极佳。
但这个DDSP也不是平常的开源项目DDSP-SVC,而是SVC Fusion整合包下的DDSP-SVC,我试过原本的,效果就不是不太可以,哪怕加上扩散模型,也是不太可以。对于我们这种需要快速克隆出音色效果的功能来说是不合适的。
但是带有UI界面的整合包,合成的效果很快,效果也很好。因此我从整合包界面开始,深扒背后执行的源码,py脚本文件,然后再总结脚本的作用,执行命令,梳理出了一套基于SVC整合包的DDSP-SVC6.3的音色克隆流程 ,该模型在一张NVIDIA A100-SXM4显卡,80GB显存的情况下,只需要1分钟(训练100steps)即可生成非常好的效果。 整合包里面我拿我自己的也试过(RTX 4070ti,16GB显存),差不多2分钟左右也很快。
我觉得这应该是全网首位把SVC整合包里的内容,整合部署到服务器上了,我还写了脚本完成了自动化的全流程和基于Flask框架,封装成api格式供外部调用,稳定性也很不错。那么接下来,我就记录下我的所有工作流程,以及一些命令。注意:教程不会特别详细,有不懂的欢迎私信~
下载代码到服务器本地
进入这个整合包官网,下载好后,先自己本地启动一下试一试,差不多这个样子,感兴趣的可以先UI试试效果,再进行后面的部署工作(非常建议,因为一套流程下来你所需要的模型文件,编码器等等,底模都给你安装好了)
把基本的代码和编码器模型,底模等等装一装,省的后面部署到服务器上时,缺什么模型还得去官网手动下载,再拖上去
把这个目录,上一级整体打包成zip压缩文件
然后将该压缩文件上传到服务器上,然后解压缩

然后cd 到 project 目录,我们后续主要在这个目录进行代码的执行

我这里装了两个模型,ddsp-svc6.3和sovits-svc,但我们主要使用第一个模型
整体流程
整体的训练流程分为以下几步
预处理 ------> 训练 ------> 推理 ------> 混音
预处理又分为以下几步:
上传音频文件 ------> ffmpeg转wav格式 ------> 数据集切片 ------> 划分训练集和验证集 ------> 生成音频特征文件(如f0,volume等等)
环境安装
我这里不会用过多时间讲解,因为这东西怎么说呢,按照requirements.txt安装的时候各种依赖报错,我的建议是 照着这个安装好大部分依赖后,直接按照我后面的步骤运行,缺什么模型再补什么就好了,这个我感觉比盲目解决依赖冲突高效多了,建议搭配着豆包或GPT解决,把报错信息复制,直接给你好的命令运行即可
还有最好(强烈建议) 在docker中安装环境,这样搞坏了方便从头再来,镜像源找一个带有cuda的即可,我早忘了一开始的镜像源使用了哪个了,因为最初的镜像源在我打包好新的镜像之后被我删了...
我容器内的配置主要的:python 3.10,pytorch 2.9.1 ,cuda 12.8
不过貌似整合包里没有requirements.txt,直接去ddsp-svc官网:yxlllc/DDSP-SVC: Real-time end-to-end singing voice conversion system based on DDSP (Differentiable Digital Signal Processing)
找到requirements.txt下载下来,或者自己新建文件复制进去
einops
fairseq
flask
flask_cors
gin
gin_config
librosa
local_attention
matplotlib
numpy==1.26.4
praat-parselmouth
pyworld
PyYAML
resampy
scikit_learn
scipy
SoundFile
tensorboard
torchcrepe
torchfcpe
tqdm
transformers
wave
FreeSimpleGUI
sounddevice
gradio然后运行以下命令,安装所需的依赖
bash
pip install -r requirements.txt 如果有报错,能解决就解决,解决不了到时候就按正常流程执行,缺什么模块 pip install 安装什么就行,结合着ai,很管用的。
一、数据预处理
1.上传训练文件
这一步,我们需要把我们需要克隆的音频文件,放到固定的目录下,ddsp默认为dataset_raw目录下,一定要是wav格式音频文件,如果不是也没关系,就看下一步就行
2.批量转wav格式
上一步上传为音频后,如果音频文件格式不是wav格式,执行以下指令转化为wav格式,此命令需要安装ffmpeg工具
注意在project目录下执行
bash
python3.10 fap/__main__.py to-wav "./dataset_raw/hyx/" "./dataset_raw/hyx/"第一个路径"./dataset_raw/hyx/" 表示待转化wav的目录下的所有文件
第二个路径"./dataset_raw/hyx/" 表示转化后的wav文件输出目录
3.切片
转化好以后,音频可能比较长,我们需要对音频文件进行切分,会自动识别静音段和说话声,切分成几秒左右的片段,当然最大最小切片时长我们可以手动控制,命令如下
在project目录下执行
bash
python3.10 fap/__main__.py slice-audio-v2 "./dataset_raw/" "./data/train/audio/" --max-duration 15.0 --num-workers 4 --flat-layout --merge-short --clean --min-duration 1.0**"./dataset_raw/":**为要切片的目录下的文件,我要切./dataset_raw/目录下的所有音频文件
"./data/train/audio/":为切片后的音频文件输出目录,这个同时也作为训练集的目录
**--min-duration 1.0:**最小的切片时长为 1s,小于这个时长的会被skip
**--max-duration 15:**最大的切片时长为15s,大于这个时长会被强制切片
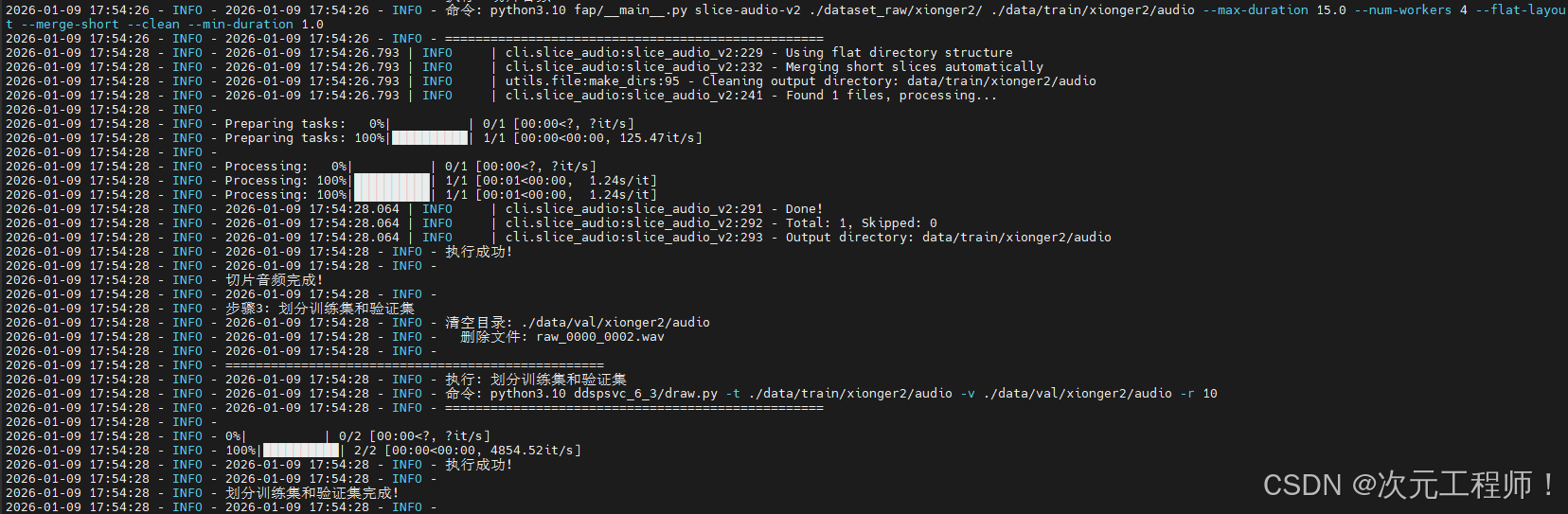
里面的日志是我自己改代码输出的,正常一些东西会没有,属于正常的
4.划分训练集和验证集
我们看一下训练集和验证集的目录,存在于data目录下
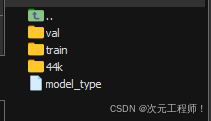
**train是训练集目录, val 是验证集目录。**44k是so-vits-svc模型的目录,我们不用管,你如果没下载这个模型,也不会有的
我们上一步将切片后的所有音频放到了data/train/audio下,所以本步是从这些训练集中的音频文件抽取一些放到验证集中
bash
python3.10 ddspsvc_6_3/draw.py -t ./data/train/audio/ -v ./data/val/audio/ -r 10**./data/train/audio/ :**需要抽取的训练集目录
**./data/val/audio/ :**抽取的验证集的目录存放的位置,默认就好
-r 10 : -r 参数是【百分比】,代码会自动除以 100 转成**小数比例,**即10%的比例,也就说如果有10个训练集文件,那么就会抽1个音频文件作为训练集。
但是该脚本有规则!验证集的抽取区间在2,10个之间,所以你如果计算出来得到1个验证集文件,那么也会抽取2个文件来放入验证集。所以当训练集数量只有2个时,会全部抽完作为验证集,会导致训练集为空,会导致训练时完全没用,这点注意!!!
解决办法自己去改源代码,不难,改一下文件头部的变量;或者传一些长的音频文件,多切片即可。
还有两个风险:
风险 1: 训练集文件数 = 3 个 → 会被抽走 2 个,训练集仅剩 1 个,同样的逻辑,max(2, 计算值) 强制抽 2 个,训练集几乎被掏空,样本量完全不够训练。
风险 2: 原脚本用的是 shutil.move() 【剪切】,不是复制 → 抽走的文件彻底从训练集消失,无法恢复
这个是叠加风险!如果是copy复制,训练集还在;但原脚本是move剪切,文件从训练集「消失」并出现在验证集,一旦抽空,训练集就真的空了,数据不可逆丢失!
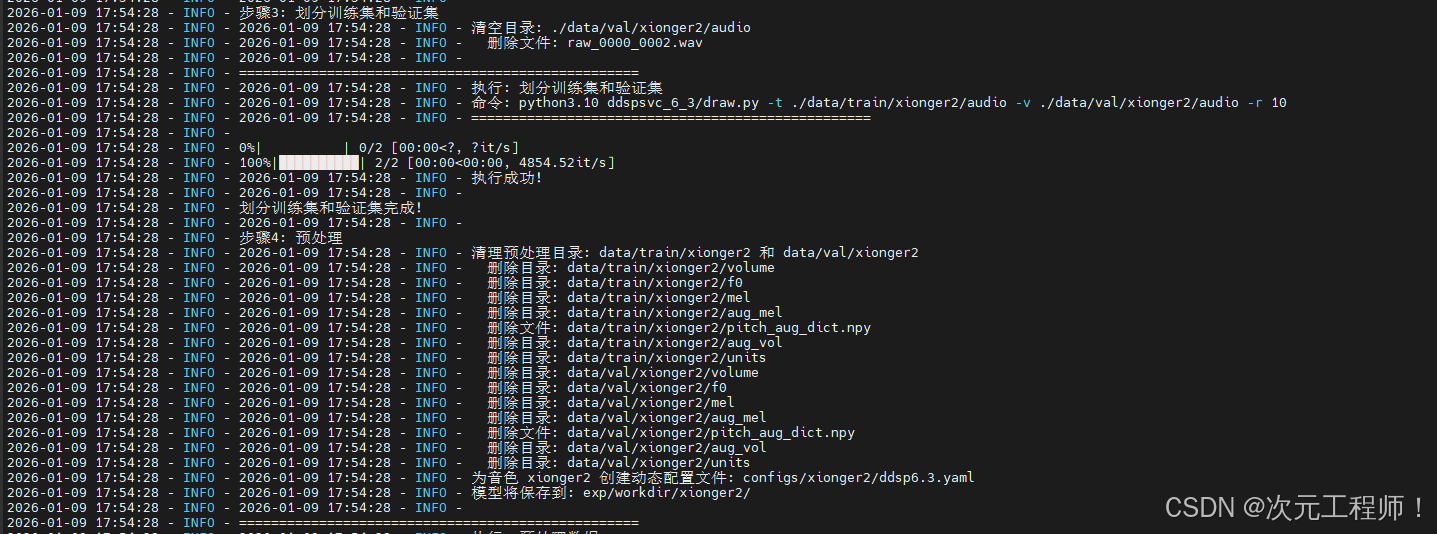
5.预处理
该过程是对训练集和验证集进行预处理
自动遍历指定目录下的训练集+验证集 原始音频文件(默认 wav 格式),分别执行预处理逻辑,训练集带数据增强,验证集纯提取无增强,保证验证集纯净。
核心提取的声学特征(最终生成 .npy 格式特征文件,供模型训练读取)
✅ 提取基频 (F0):音频的音调 / 音高特征,决定语音的声调高低;
✅ 提取音量 (Volume):音频的响度特征,含原始音量 + 增强后音量;
✅ 提取语义单元 (Units):音频的文本语义特征(核心特征,由预训练编码器生成);
✅ 提取梅尔频谱 (Mel):音频的频谱特征,还原语音的音色 / 音质细节,含原始梅尔谱 + 增强后梅尔谱;
命令:
bash
python3.10 -m ddspsvc_6_3.preprocess -c configs/ddsp6.3.yaml -d cuda:0 执行后,会在data/train/ 和 data/val目录下生成以下目录:
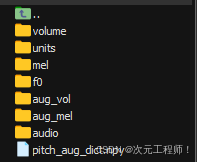
这样训练的条件就具备了,我们可以开始进行训练了,但在此之前需要解释下配置文件
6.额外补充:配置文件
配置文ddsp6.3.yaml内容如下,在configs目录下
XML
data:
block_size: 512 # 音频分帧步长
cnhubertsoft_gate: 10 # cnhubertsoft编码器门限值
duration: 2 # 音频片段截取时长,单位秒
encoder: contentvec768l12tta2x # 语义特征编码器类型
encoder_ckpt: pretrain/contentvec/checkpoint_best_legacy_500.pt # 编码器预训练权重文件路径
encoder_hop_size: 160 # 编码器分帧步长
encoder_out_channels: 768 # 编码器输出特征维度
encoder_sample_rate: 16000 # 编码器输入音频采样率
extensions: # 支持处理的音频文件格式
- wav
f0_extractor: rmvpe # 基频提取算法类型
f0_max: 800 # 提取基频的最大值,单位Hz
f0_min: 65 # 提取基频的最小值,单位Hz
sampling_rate: 44100 # 音频采样率
train_path: data/train # 训练集数据路径
valid_path: data/val # 验证集数据路径
volume_smooth_size: 1024 # 音量特征平滑窗口大小
device: cuda:0 # 指定训练使用的计算设备
env:
expdir: exp/workdir # 实验日志与模型权重保存目录
gpu_id: 0 # 训练使用的GPU编号
infer:
infer_step: 50 # 推理阶段的采样步数
method: euler # 推理阶段的采样方法
model:
n_aux_chans: 512 # 模型辅助特征通道数
n_aux_layers: 6 # 模型辅助特征网络层数
n_chans: 1024 # 模型主特征通道数
n_layers: 6 # 模型主网络层数
n_spk: 1 # 说话人数量
t_start: 0.0 # 模型起始时间步
type: RectifiedFlow # 模型架构类型
use_attention: false # 是否启用注意力机制
use_norm: true # 是否启用层归一化
use_pitch_aug: true # 是否启用音调数据增强
win_length: 2048 # 梅尔频谱计算窗长
model_type_index: 4 # 模型类型索引标记
spks:
- hyx # 说话人名称列表
train:
amp_dtype: fp16 # 混合精度训练的数据类型
batch_size: 30 # 训练批次大小
cache_all_data: false # 是否将全部数据缓存至内存
cache_device: cpu # 数据缓存的设备
cache_fp16: true # 缓存数据是否采用fp16精度
decay_step: 4000 # 学习率衰减的步数阈值
epochs: 100 # 训练总轮数
gamma: 0.9 # 学习率衰减系数
interval_force_save: 10000 # 强制保存模型的步数间隔
interval_log: 1 # 日志打印的轮数间隔
interval_val: 100 # 模型验证的轮数间隔
lambda_ddsp: 1 # ddsp损失项的权重系数
lr: 0.0002 # 模型训练学习率
num_workers: 2 # 数据加载的工作线程数
save_opt: false # 是否保存优化器的状态信息
save_tensorboard: false # 是否保存tensorboard日志文件
weight_decay: 0.1 # 权重衰减系数
use_pretrain: true # 是否启用预训练权重进行训练
vocoder:
ckpt: pretrain/nsf_hifigan/model # 声码器预训练权重路径
type: nsf-hifigan # 声码器类型我们需要关注的几个属性即可:
**train_path:**训练集路径
valid_path: 验证集路径
**epochs:**训练总轮数
interval_val 100: 每训练 100 个 epoch,执行一次验证集评估,评估完成后自动保存一次模型权重
interval_force_save 10000: 每训练1000步强制保存一次权重文件
我们训练就是为了得到这个权重文件,一定要关心什么时候保存
a、权重文件保存规则
① 按【步数 (step)】强制保存权重:train -> interval_force_save: 10000
含义:每训练 10000 个 step,无条件强制保存一次模型权重文件
② 按【轮数 (epoch)】验证后保存权重:train -> interval_val: 100
含义:每训练 100 个 epoch,执行一次验证集评估,评估完成后自动保存一次模型权重(训练类模型的常规保存逻辑,保存的是该阶段最优权重)
b、step 和 epoch的核心关系
1. 各自的定义
-
epoch(训练轮数) :把 训练集里的【全部数据】完整的训练一遍 ,就记作
1个epoch。比如你的训练集有 3000 条音频,模型把这 3000 条全部跑完一次 = 训练了 1 epoch。 -
step(训练步数 / 迭代步) :模型读取 1 个批次(batch)的数据 ,完成「前向计算 + 损失计算 + 反向传播 + 参数更新」这一整套流程,就记作
1个step。配置里train -> batch_size: 30,代表 每读取 30 条音频 = 训练了 1 step。

补充说明:
epoch是「宏观训练进度」,step是「微观训练进度」,训练日志里一般会这样显示:epoch: [7/100], step: [700/xxxx],代表「第 7 轮训练,当前训练到第 700 步」。- 你的配置里所有带
step的参数,都是按「微观步数」计算,和epoch无关:interval_force_save:10000→ 纯按步数,不管跑了几轮decay_step:4000→ 训练到 4000step 时,学习率开始按系数衰减
- 你的配置里所有带
interval的参数,带log/val后缀的是按epoch计算:interval_log:1→ 每 1 个 epoch 打印一次训练日志interval_val:100→ 每 100 个 epoch 跑一次验证
二、训练
我们利用刚才划分好的训练集特征文件,开始进行训练,训练后会生成一个.pt权重文件,存放在exp/workdir目录下,注意!一定要事先把基模(model_0.pt)放入该目录下,不然训练效果会非常差,一定要加!!!
执行命令
XML
python3.10 -m ddspsvc_6_3.train_reflow -c configs/ddsp6.3.yaml模型便开始执行训练过程

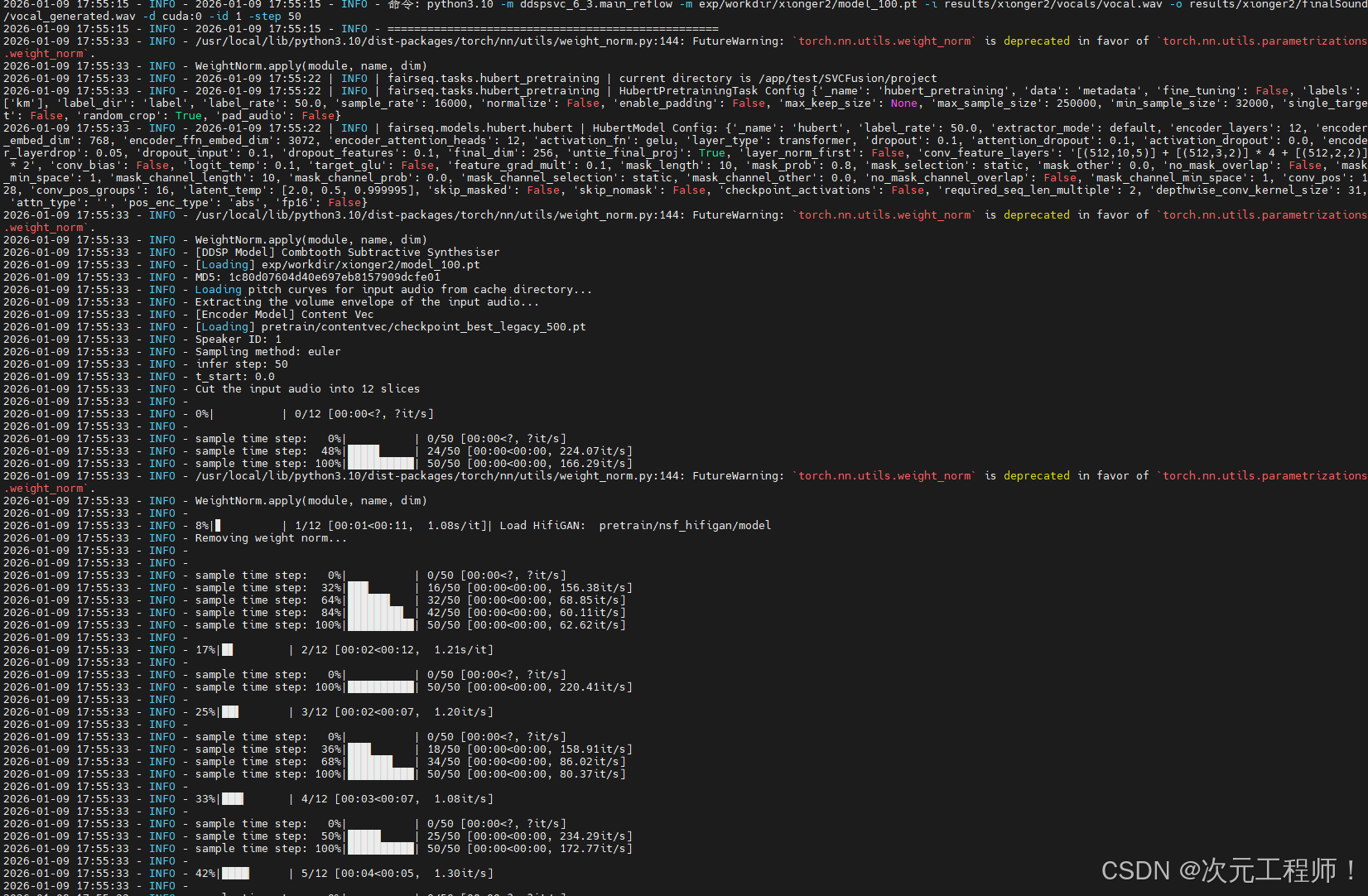
这张图是我封装为api后输出的日志,主要看后面就行,可能和你正常执行命令的输出不一样,但不影响
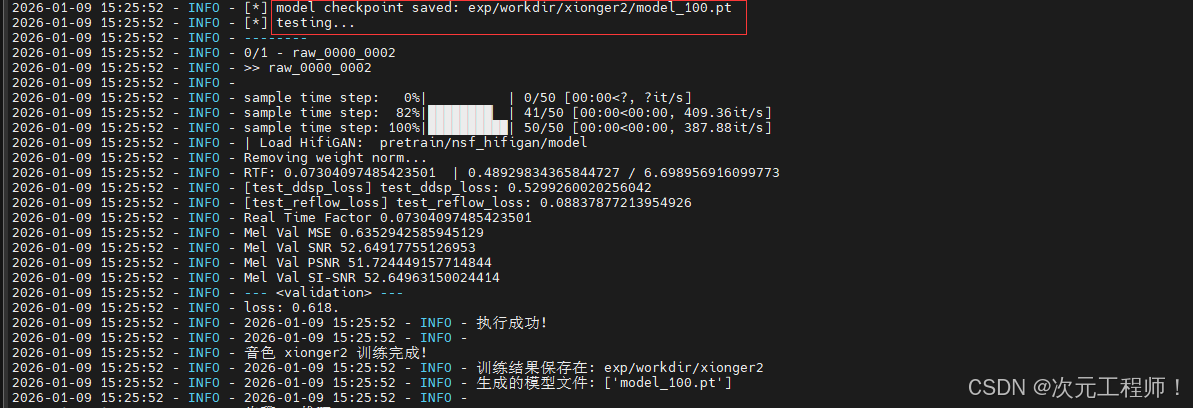
可以看到第一行,训练好的权重模型已经保存到对应的目录下,这个目录我有修改过,所以以你的为准即可
其他属性:
1. test_ddsp_loss: 0.5299260020256042
- 含义:DDSP 声码器的损失值,衡量「模型生成的声学特征」与「真实音频声学特征」的差距
- 判定:该值 0.53 → ✅【优秀】,语音合成中该损失值 < 1 就是合格,< 0.6 就是非常好,越小代表特征拟合越精准
2. test_reflow_loss: 0.08837877213954926
- 含义:RectifiedFlow 整流流模型的核心损失值,这个模型主架构是 RectifiedFlow,这个值是核心核心指标
- 判定:该值 0.088 → ✅【极佳】,该损失值 < 0.2 为合格,< 0.1 为优秀,看到我的数值已经接近 0,说明模型的流匹配效果拉满,合成的音频会非常贴合原声
3. 综合验证损失 loss: 0.618.
- 含义:上述两个损失的加权综合值(对应配置里
lambda_ddsp:1权重) - 判定:该值 0.618 → ✅【优秀】,综合损失 < 1 就是合格,这个数值证明你的模型对训练数据的拟合程度非常高,没有过拟合 / 欠拟合问题
-
Mel Val MSE(梅尔频谱均方误差) → 数值:0.635
- 含义:衡量「合成梅尔谱」与「真实梅尔谱」的像素级误差,越小越好
- 判定:【优秀】,MSE < 1 为合格,< 0.7 为优秀,值 0.635,说明合成的梅尔谱和真实的几乎一致,音色还原度极高
-
Mel Val SNR(梅尔频谱信噪比) → 数值:52.65
- 含义:衡量合成音频的「有效语音信号」和「杂音 / 噪声」的比值,越大越好
- 判定:✅【极佳】,SNR > 30 为合格,> 40 为优秀,> 50 为顶级,值 52+,说明合成的音频几乎无杂音、无电音、无失真,纯净度拉满
-
Mel Val PSNR(梅尔频谱峰值信噪比) → 数值:51.72
- 含义:在 SNR 基础上,侧重「音频峰值信号」的还原度,越大越好
- 判定:✅【极佳】,PSNR > 40 为优秀,值 51+,说明合成音频的音量、音调、峰值细节和原声完全一致,不会出现音量忽大忽小、破音等问题
-
Mel Val SI-SNR(梅尔频谱尺度不变信噪比) → 数值:52.65
- 含义:语音合成专属核心指标 ,专门针对人声设计,剔除了音量、尺度等无关因素,只衡量「语音内容 + 音色」的还原度,这个指标的优先级最高!
- 判定:✅【顶级】,SI-SNR > 40 为优秀,> 50 为顶级,值 52+,这个数值代表模型合成的音频,在「音色、语调、语音细节」上和你的训练集原声几乎一模一样,这是语音合成的顶级效果
还有个tensorboard ,可以可视化的看训练的曲线,通过configs中配置文件的save_tensorboard改为true,然后运行tensorboard会有一个界面,访问即可。
最终效果会生成一个以训练步数为后缀的权重文件,model_100.pt 代表我训练了100step

你可以用 Tensorboard 来查看训练过程中的损失函数值 (loss) 趋势,试听音频,从而辅助判断模型训练状态。但是,就 So-VITS-SVC 这个项目而言,损失函数值(loss)并没有什么实际参考意义(你不用刻意对比研究这个值的高低),真正有参考意义的还是推理后靠你的耳朵来听!
后续我们就使用该权重文件进行推理
三、推理
用刚才的权重文件进行推理,命令如下:
bash
python3.10 -m ddspsvc_6_3.main_reflow -m exp/workdir/model_100.pt -i ../../../qinghuaci2.wav -o ./qinghuaci2_output.wav -d cuda:0 -id 1 -step 50exp/workdir/model_100.pt : 模型权重文件路径
../../../qinghuaci2.wav: 要转化的歌曲人声,比如我要翻唱周杰伦的青花瓷,这个就是青花瓷的纯人声,是纯人声,没有伴奏,需要自己手动去除,我们是刚好有一个人声分离的接口,所以直接调用那个接口分离的,如果需要代码里应该也有,我看到过但没太细看,感兴趣的可以找下
./qinghuaci2_output.wav: 输出路径
-step : 推理步数
推理好以后便在指定目录下生成我唱的青花瓷人声了

四、混音
这个整合包竟然自带自动混音功能,真是感动至极,非常感谢开源作者大大
可以写个脚本文件run_mix.py
python
from automix import automix, ReverbLevel, MusicGenre, VoiceType, DeEsserStrength, CompressionStrength, EQStyle, EchoLevel
# ========== 只需要修改这两行路径 ==========
VOCAL_PATH = "你的人声文件.wav"
BGM_PATH = "你的伴奏文件.wav"
# ========== 调用混音函数,参数和你最初的完全一致 ==========
out_path = automix(
voc_path=VOCAL_PATH,
inst_path=BGM_PATH,
sample_rate=44100,
reverb_gain=0,
headroom=-8,
voc_input=-4,
reverb_level=ReverbLevel.MODERATE,
music_genre=MusicGenre.POP,
voice_type=VoiceType.FEMALE,
deesser_strength=DeEsserStrength.MODERATE,
compression_strength=CompressionStrength.MODERATE,
eq_style=EQStyle.NEUTRAL,
echo_level=EchoLevel.OFF,
)
print(f"混音完成!输出文件路径: {out_path}")然后运行即可
bash
python run_mix.py这个命令把伴奏文件和刚才推理后生成的人声混合在一起,最终生成一个完整的歌曲
不知道其他环境下能不能运行。。。
至此,将DDSP-SVC6.3模型部署到Ubuntu服务器的大概流程就结束了,也是花了不少时间来部署并研究使用的,我也针对于此,写了一套全流程自动化执行的代码,并且封装为api的格式,
只需要上传对应的音色id,用户音频,伴奏音频,人声(干声)音频,即可自动完成推理和混音之后的结果,并返回对应的url,返回响应:

写在这里只是说明这些代码改造和拓展性是很强的,可以自己发挥能力改造
写了这点博客也写了好久,真快累死了,不过最后听到自己的声音完整自动化的克隆出了一首歌,成就感还是很高的,作者也是从0开始接触的,到最后可以完整使用,不乏元旦放假从下午搞到凌晨五点小姑还是不行的绝望感,绝望的扒拉着源码看,希望有突破口,等后面突然灵光一闪,才想到了把整个整合包放进去,既然是UI界面,那么背后依赖的肯定还是那些py脚本,便深入了解如何执行的那些脚本,最后经过自己的改进,最终有个不错的效果,希望大家遇到问题也不要放弃,不要提到源码就害怕,勇于改进,每个脚本不过是实现了一些功能,大不了重新还原脚本就行了。
从一开始的so-vits-svc模型实验了各种参数不行,到最后勇敢换模型到ddsp-svc6.3模型还是不符合要求后,又大胆的直接使用整合包那些复杂的代码来使用,到最后生成出不错的效果,每次都是大胆的尝试。 怎么发现的呢,我一开始部署的是ddsp-svc6.3模型,但是生成的声音效果不好,奇怪的是整合包的就很好,我便把整合包生成的权重文件 copy到我的项目文件里使用,发现运行不起来,可能是参数配置那里有问题,深入看源码,才发现整合包有自己的一套流程和配置,所以直接copy下来,太阴了哈哈,不过非常感谢作者大大!