企业每天都会接收海量的客户建议、反馈及信息数据。这些数据中,大量重复或高度相似的内容不仅会占用冗余的存储资源,更会导致相关工作人员在处理时做无用功 、决策层难以快速捕捉核心需求,严重影响业务效率与客户体验。
传统基于关键词匹配的去重方法,往往因无法理解文本深层语义而频频失效------它只能发现相同的文字,却看不懂不同表述背后的相同含义。比如 "希望延长晚上客服时间" 与 "建议增加夜间服务" 这类表述不同但意图一致的内容,很容易被误判为非重复信息。这正是企业面临的信息管理痛点:
大量的客户建议存在语义重复
人工审核耗时占客服团队许多精力
相同需求因表述差异被分散处理
为此,借助 BERT 等模型强大的语义理解能力,实现对重复信息的精准识别 ,已成为提升数据治理效率、优化服务质量的关键技术路径。基于 BERT 的语义分析能"理解语言真意",能洞悉"APP登录慢"和"手机银行开启卡顿"是同一问题、"增加夜间人工"和"延长服务到晚10点"是相同诉求。本文将从场景痛点出发,详细阐述基于 BERT 的语义分析方案,解决重复信息识别问题。
目录
[1 场景与痛点](#1 场景与痛点)
[2 业务目标](#2 业务目标)
[3 解决方案](#3 解决方案)
[3.1 核心流程](#3.1 核心流程)
[3.2 优化策略](#3.2 优化策略)
[3.2.1 模型质量优化--提升模型准确性和业务适应性](#3.2.1 模型质量优化--提升模型准确性和业务适应性)
[3.2.2 计算资源优化--提高系统运行效率](#3.2.2 计算资源优化--提高系统运行效率)
[3.3 适配业务场景](#3.3 适配业务场景)
[3.4 特殊情况](#3.4 特殊情况)
[3.5 效果评估指标](#3.5 效果评估指标)
[4 实例:客户服务系统中的重复建议识别](#4 实例:客户服务系统中的重复建议识别)
1 场景与痛点
典型场景:
-
客户服务中心:用户通过多个渠道(电话/在线/邮件)提交重复建议
-
产品反馈系统:用户用不同表述提交相同功能请求(如"增加夜间模式" vs "需要深色主题")
核心痛点:
-
传统规则匹配失效:"提高转账额度" ≠ "增加汇款限额"(同义但用词不同)
-
人工审核成本高:如某银行每月需10人天审核1万条建议,错误率>15%
-
跨渠道信息孤岛:客服电话记录与在线表单无法自动关联相同客户
-
语义鸿沟问题:"登录太慢"和"APP卡在启动页面"表述不同但本质相同
2 业务目标
| 目标类型 | 具体指标(示例) |
|---|---|
| 效率提升 | 重复信息识别速度提升10倍(秒级响应) |
| 成本优化 | 人工审核工作量减少70% |
| 体验改善 | 客户建议响应时间从24h缩短至3h |
| 数据治理 | 客户信息合并准确率>95% |
| 决策支持 | 真实需求识别准确度提升50% |
3 解决方案
3.1 核心流程
1. 数据预处理:收集客户的建议或信息文本数据,对其进行清洗,去除噪声数据,如特殊字符、标点符号等,同时进行分词等基础处理,以便后续输入 BERT 模型。
-
清洗文本:去除特殊字符、停用词、统一大小写
-
关键信息提取(可选):姓名+联系方式组合,或建议中的核心动词+名词(如"降低手续费"→降低, 手续费)
-
文本标准化:缩写扩展("APP"→"应用程序")、纠错
2. 文本向量化:利用 BERT 模型将预处理后的文本映射到向量空间。BERT 模型可以生成上下文相关的语义表示,通常会输出 768 维或 1024 维的向量。例如,使用 Hugging Face Transformers 库加载 BERT 模型和分词器,将文本转换为模型可接受的输入格式,然后获取其对应的向量表示。
python
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
def get_bert_embedding(text):
inputs = tokenizer(text, return_tensors="pt", max_length=128, truncation=True, padding="max_length")
with torch.no_grad():
outputs = model(**inputs)
return outputs.last_hidden_state[:,0,:].numpy() # 取[CLS]向量3. 相似度计算:计算不同文本向量之间的相似度,常用的方法有余弦相似度、欧式距离等。余弦相似度通过计算两个向量的夹角余弦值来衡量它们的相似程度,取值范围在 -1, 1 之间,值越接近 1 表示两个文本越相似。
- 使用余弦相似度(Cosine Similarity):
python
from sklearn.metrics.pairwise import cosine_similarity
sim = cosine_similarity(vec1.reshape(1,-1), vec2.reshape(1,-1))[0][0]4. 设定阈值判断:根据业务需求和数据特点,设定一个相似度阈值。当两个文本向量的相似度超过该阈值时,就可以判断这两条建议或客户信息为重复内容。例如,将阈值设定为 0.9,若两个文本的余弦相似度大于 0.9,则认为它们是重复的。
5. 重复判定逻辑
python
if sim > threshold:
return "重复"
else:
return "非重复"3.2 优化策略
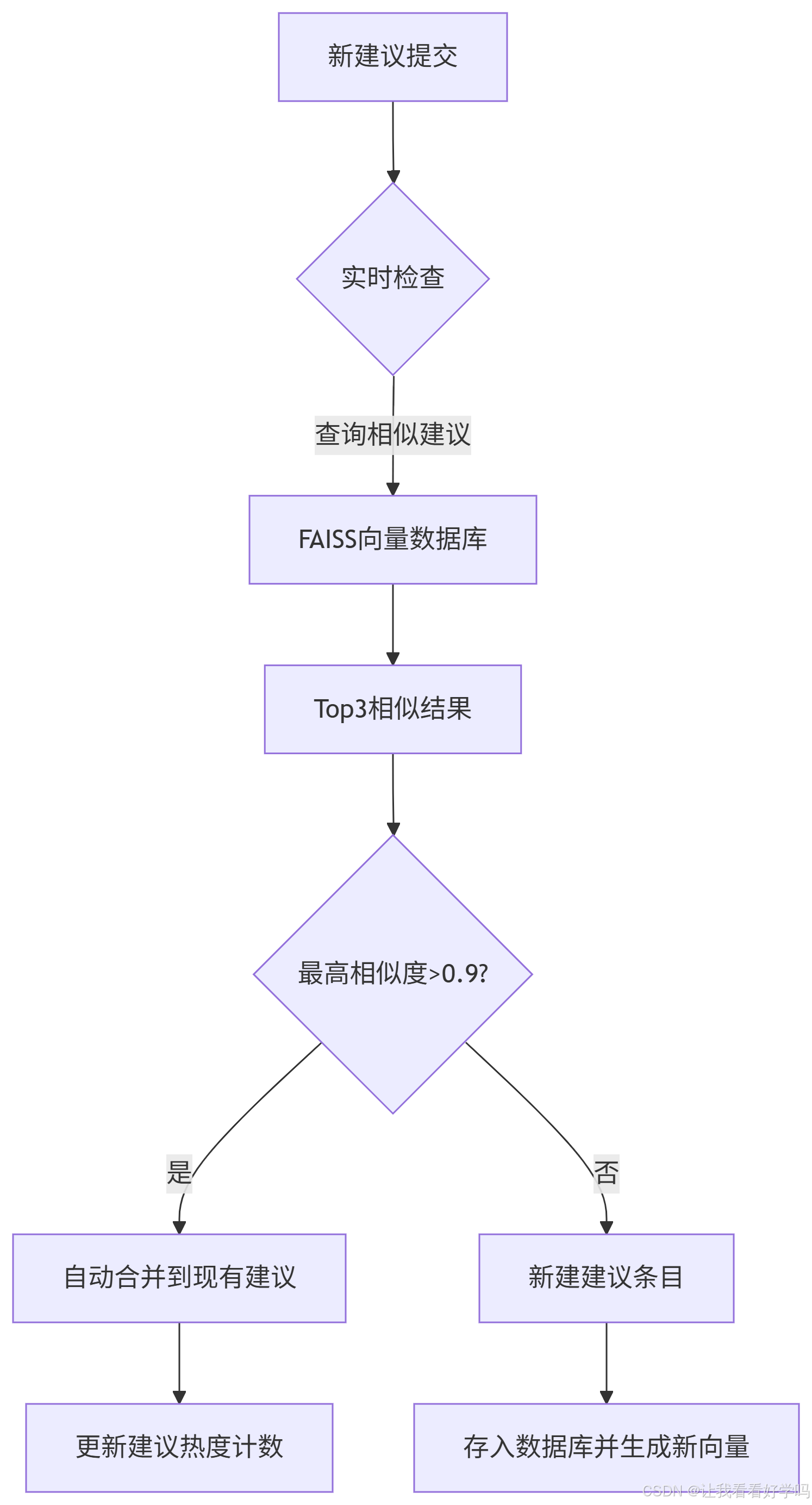
批量处理与优化:对于大规模的客户建议或信息数据,可以采用批量处理的方式提高效率。同时,为了进一步提升性能,可以结合一些高效的相似度搜索工具,如 FAISS(Facebook AI Similarity Search),它可以快速地在大规模向量数据中进行相似度检索。此外,还可以定期对模型进行更新和优化,以适应新的文本数据和业务场景。
模型微调(可选):如果有标注好的重复与非重复数据,可以对 BERT 模型进行微调,使其更适应特定的业务数据和任务需求。例如,使用对比损失函数(ContrastiveLoss)或多负样本排序损失函数(MultipleNegativesRankingLoss)来训练模型,让模型更好地学习文本之间的相似性和差异性。
3.2.1 模型质量优化--提升模型准确性和业务适应性
1. 微调BERT(针对领域数据)
目的是让模型在特定领域的数据上表现更好,提高准确性。
python
from transformers import BertForSequenceClassification, Trainer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
trainer = Trainer(model=model, train_dataset=dataset, ...)
trainer.train()-
训练数据示例:
文本1 文本2 标签 "建议增加夜间客服" "希望提供晚上人工服务" 1 (重复) "登录太慢" "支付失败" 0 (不同)
2. 聚类批量处理(海量数据)
通过聚类算法处理大量数据,属于算法层面的优化,可以更好地发现重复组(不仅仅是两两比较)。
-
用BERT生成所有文本向量
-
执行DBSCAN聚类:
python
from sklearn.cluster import DBSCAN
clusters = DBSCAN(eps=0.3, min_samples=2).fit(embeddings)3. 集成规则引擎
结合业务规则和语义相似度,提高判断的准确性和鲁棒性(比如在语义相似度基础上增加业务逻辑)。
python
if 电话号码相同 or (姓名相同 and 地址相似度>0.9):
标记为重复客户
elif 语义相似度>0.9 and 建议类型相同:
标记为重复建议3.2.2 计算资源优化--提高系统运行效率
1. 向量化加速
使用更快的模型(如Sentence-Transformers中的轻量模型)和利用FAISS进行高效相似度搜索,这些主要是为了提升计算速度。
- 使用 Sentence-Transformers 库(更轻量):
python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2') # 比BERT快5倍- 预计算向量存入FAISS索引:
python
import faiss
index = faiss.IndexFlatIP(768)
index.add(embeddings)2. 实时去重架构
设计实时处理流程,确保系统能够快速响应(比如使用FAISS进行实时检索)。

3.3 适配业务场景
| 场景 | 特殊处理 |
|---|---|
| 客户投诉去重 | 加入时间窗口(7天内相似视为重复) |
| 产品建议合并 | 提取关键词+语义组合(如"功能请求:搜索优化") |
| 金融风控场景 | 结合设备ID/IP地址强化判断 |
3.4 特殊情况
-
短文本问题:添加上下文(如将"登录问题"扩展为"用户反馈登录问题:频繁闪退")
-
跨语言场景:使用多语言BERT(bert-base-multilingual-cased)
-
阈值漂移:如每月人工审核100条边界样本(相似度0.8-0.9)以调整阈值
-
隐私保护:若涉及隐私问题,需在对客户信息向量化前做匿名化处理(如替换电话号码为<PHONE>)
3.5 效果评估指标
-
业务指标:客服工单减少量、建议合并覆盖率等。
-
准确率:随机采样验证,减少误判。
-
召回率 :确保不漏判真实重复项。低召回率意味着大量真实重复项未被发现,如未识别"APP登录慢"和"手机银行卡顿"的语义相似性,会造成 重复处理相同问题 → 资源浪费 → 效率降低 的业务影响。
- 建议初期采用混合模式:BERT筛选+人工复核,逐步过渡到全自动。
4 实例:客户服务系统中的重复建议识别
场景:某银行客服系统收到大量用户建议,需要自动合并重复建议(如"延长客服时间"和"增加夜间服务"应视为同一建议)。
数据准备
python
import pandas as pd
# 模拟客户建议数据
data = [
{"id": 1, "text": "希望延长客服工作时间到晚上10点", "type": "服务时间"},
{"id": 2, "text": "建议增加夜间人工客服", "type": "服务时间"},
{"id": 3, "text": "手机银行登录太慢需要优化", "type": "系统性能"},
{"id": 4, "text": "APP登录速度太卡顿", "type": "系统性能"},
{"id": 5, "text": "信用卡年费减免政策不明确", "type": "费用问题"}
]
df = pd.DataFrame(data)完整实现代码
python
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import pandas as pd
# 1. 加载轻量级BERT模型
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# 2. 生成文本嵌入向量
embeddings = model.encode(df['text'].tolist(), convert_to_tensor=True)
# 3. 创建相似度矩阵
sim_matrix = cosine_similarity(embeddings)
# 4. 识别重复建议
THRESHOLD = 0.88 # 经过业务测试的最佳阈值
duplicate_pairs = []
for i in range(len(sim_matrix)):
for j in range(i+1, len(sim_matrix)):
if sim_matrix[i][j] > THRESHOLD and df.iloc[i]['type'] == df.iloc[j]['type']:
duplicate_pairs.append({
"source_id": df.iloc[i]['id'],
"source_text": df.iloc[i]['text'],
"target_id": df.iloc[j]['id'],
"target_text": df.iloc[j]['text'],
"similarity": round(sim_matrix[i][j], 3)
})
# 5. 输出结果
duplicates_df = pd.DataFrame(duplicate_pairs)
print("识别到的重复建议:")
print(duplicates_df[['source_id', 'target_id', 'similarity', 'source_text', 'target_text']])输出结果示例
python
识别到的重复建议:
source_id target_id similarity source_text target_text
0 1 2 0.912 希望延长客服工作时间到晚上10点 建议增加夜间人工客服
1 3 4 0.896 手机银行登录太慢需要优化 APP登录速度太卡顿语义相似对:
- 文本1:希望延长客服工作时间到晚上10点;文本2:建议增加夜间人工客服
- 相似度 :0.912 → 判定为重复,尽管用词不同("延长" vs "增加"、"晚上10点" vs "夜间"),BERT捕捉到核心意图都是"扩展晚间服务"。
非重复案例:
-
文本3:信用卡年费减免政策不明确
-
与其他建议相似度均<0.3,主题完全不同(费用问题 vs 服务时间/系统性能)
阈值效果验证:
| 相似度 | 判定结果 | 实际关系 |
|---|---|---|
| >0.9 | 重复 | 同意图不同表述 |
| 0.85-0.89 | 需复核 | 相关但不完全相同 |
| <0.8 | 不重复 | 不同主题 |
业务应用流程
业务效果
降低重复建议率、减少建议处理时间、提升用户满意度。