【Linux系统】------ 进程切换&&进程优先级&&进程调度
- [1 进程切换](#1 进程切换)
-
- [1.1 死循环进程如何进行](#1.1 死循环进程如何进行)
- [1.2 简单知道寄存器](#1.2 简单知道寄存器)
- [1.3 进程如何进行切换](#1.3 进程如何进行切换)
- [2 进程优先级](#2 进程优先级)
-
- [2.1 优先级的基本概念](#2.1 优先级的基本概念)
-
- [2.1.1 什么是优先级](#2.1.1 什么是优先级)
- [2.1.2 为什么要有优先级](#2.1.2 为什么要有优先级)
- [2.1.3 优先级 vs 权限](#2.1.3 优先级 vs 权限)
- [2.2 Linux中的优先级](#2.2 Linux中的优先级)
-
- [2.2.1 基本特点](#2.2.1 基本特点)
- [2.2.2 查看进程优先级](#2.2.2 查看进程优先级)
- [2.2.3 调整优先级](#2.2.3 调整优先级)
- [2.2.4 优先级的极值](#2.2.4 优先级的极值)
- [2.3 补充概念:竞争、独立、并行、并发](#2.3 补充概念:竞争、独立、并行、并发)
- [3 进程调度](#3 进程调度)
-
- [3.1 运行队列 runqueue](#3.1 运行队列 runqueue)
- [3.2 queue140](#3.2 queue[140])
-
- [3.2.1 实时优先级](#3.2.1 实时优先级)
- [3.3 bitmap5](#3.3 bitmap[5])
- [3.4 活跃队列与过期队列](#3.4 活跃队列与过期队列)
1 进程切换
1.1 死循环进程如何进行
当我们写了一个死循环程序,其运行起来,我们会发现系统确实会卡一点,但绝对不会卡死。
所以问题来了:一个进程一旦占有CPU,它会把自己的代码直接跑完吗?
不会! 除非进程的代码很短,在一个时间片内就跑完了,否则不会跑完。
时间片:当代计算机都是分时操作系统 ,每个进程都有它合适的时间片(其实就是⼀个计数器)。时间片到达,进程就被操作系统从 CPU 中剥离下来。
系统会为每一个进程分配一个叫时间片的东西。当一个进程跑完了时间片比如时间片为 1 毫秒,就需要到运行队列中重新排队。系统允许进程单次的运行时间,我们称为时间片。关于时间片更具体的概念,后续文章会详细介绍。
这样每个进程都基于时间片去跑,就不会出现一个进程死占 CPU 的情况,时间片一到,操作系统就会切换它。
所以死循环进程不会打死系统,因为任何进程包括死循环进程不会一直占有CPU 。(除非系统中的进程全是死循环)
1.2 简单知道寄存器
当一个进程正在持有 CPU 时,此时与进程的 PCB 关系就不大了。
CPU 执行时,重点是访问进程对应的代码和数据。
CPU 不会将进程的代码和数据一股脑塞进来,而是一条条来。
为了能处理代码和数据,CPU 内存在很多寄存器。
常见寄存器:程序计算器pc/EIP 、栈底和栈顶ebp/esp 、通用寄存器eax/ebx/ecx/edx......
每一个寄存器在 CPU 内部都起着临时保存数据的任务,当 CPU 运行一个进程时,所有的寄存器都会被填上对应临时值,如:有的描述计算结果有无溢出、有的描述代码从哪开始、有的指向对应的 PCB......
总之,CPU 寄存器保存的是正在运行的进程执行过程中的临时数据
知识点:
寄存器就是 CPU 内部保存数据的临时空间 比如 CPU 计算 1 + 2,CPU 首先要 1 和 2 两个数据放到两个寄存器中,还要把执行的操作 ADD 放在另一个寄存器中
CPU 做某种计算,就需在内部有临时数据的保存能力。空间不大,但需要存在寄存器 != 寄存器里面的数据 CPU 中寄存器指保存临时数据的空间,而寄存器中的数据指的是内容,小伙伴们不要混淆。 就像 C语言 中 a = 20 ,表示把 20 这个数据放在 a 空间, b = a,表示将 a 空间的内容给 b 空间
空间只有一份,内容可以是变化的,可以有多份
1.3 进程如何进行切换
讲个故事:
大二学生小明要去当一年兵,因此他要休学,一年后再继续完成学业。
小明能直接就收东西跑路吗?如果这么干,当完兵回来就会发现自己已经被退学了。翘一年的课,考试全挂,你不退学谁退学?
所以小明第一件事就是:通知学校,找到辅导员,让学校保留学籍。
辅导员处理完相关手续后,将小明的学籍档案交给小明,让小明回来时再将档案交给学校
一年后,小明回来了,它能直接一屁股坐进教室吗?如果怎样,小明会发现自己连个宿舍都没有
小明回来后,要先恢复学籍。
小明找到辅导员,并将手中档案交还给学校,这份档案记录者小明离开之前的痕迹。
有了这份档案,小明就不用从大一开始修学分了,直接从大二开始。
上述例子中:
学校 == CPU
辅导员 == 调度器
小明 == 进程
学籍 == 进程运行的临时数据(CPU寄存器中的内容,也即当前进程的上下文数据)
保留学籍 == 保存上下文数据(本质:将CPU寄存器中的内容保存起来)
恢复学籍 == 恢复上下文数据(本质:将曾经的数据恢复到CPU寄存器中)
去当兵 == 进程被从CPU上剥离
从去当兵,再到回来复学,相当于进程做了一次切换
什么是上下文数据 呢?
CPU 上下文切换:其实际含义是任务切换 ,或者 CPU 寄存器切换 。当多任务内核决定运行另外的任务时,它保存正在运行任务的当前状态,也就是CPU寄存器中的全部内容。这些内容被保存在任务自己的堆栈中,入栈工作完成后就把下⼀个将要运行的任务的当前状况从该任务的栈中重新装入CPU寄存器,并开始下⼀个任务的运性,这⼀过程就是 context switch
简单来说:CPU寄存器中的内容表示的就是当前进程上下文数据
保留学籍的目的就是为了恢复学籍,恢复学籍的目的就是为了继续历史任务再运行。
那么进程具体是如何进行切换的呢?
如图:
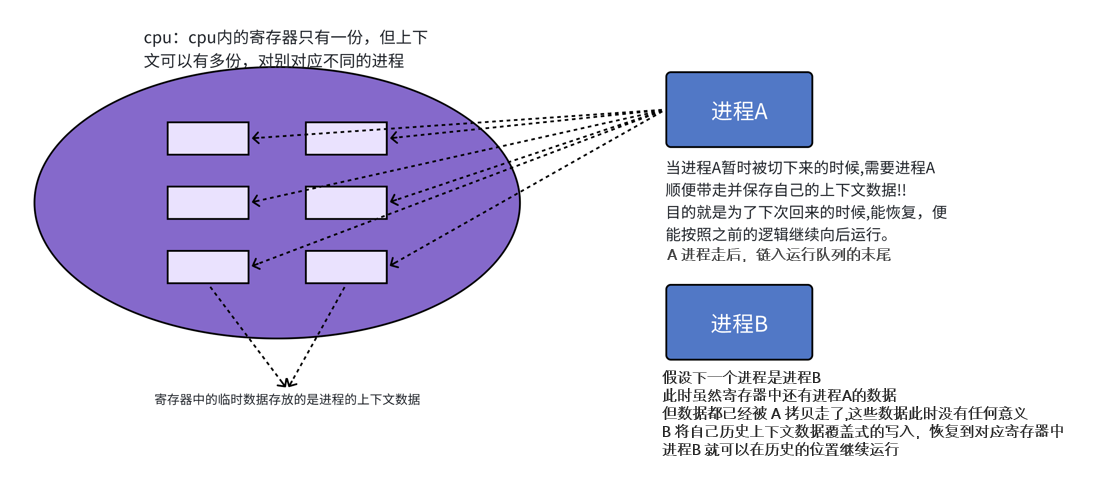
进程切换,最核心的就是保存和恢复当前进程的硬件上下文数据,即 CPU 寄存器内的内容。
所以,当前进程要把自己的进程硬件上下文数据保存起来,保存到哪里了呢?
数据保存的位置我们可以理解成:保存到进程的 task_struct 里
扩展:但如今要保存的上下文数据太大了,如今每个进程都会有一个 TSS 的字段来单独保存上下文数据,我们称为任务状态段(本质也是一个结构体)

注:老内核的 tss_struct 还在 task_struct 中,新内核已经将 tss_struct 从 task_struct 中移除了
全新的进程 VS 已经被调度过的进程
全新的进程不用回复上下文,也即寄存器中的值全为空。那操作系统如何区分全新的进程和已经被调度过的进程呢?
很简单,在 task_struct 中新增一个标记位即可。
还没调度时,标记位为 0; 一旦被调度了,标记位置 1,从此往后一直是 1
2 进程优先级
2.1 优先级的基本概念
2.1.1 什么是优先级
先不谈进程的优先级,我们谈谈生活中的例子。
中午一下课,大家都飞速跑向饭堂,为的就是排队能排的更靠前一点,能够更早的吃上饭。
排队的本质就是确认优先级!
什么是优先级?
优先级的本质就是衡量你得到某种资源的先后顺序。
对进程来讲,优先级是进程CPU资源的先后顺序
2.1.2 为什么要有优先级
为什么要有优先级呢?
换句话说:你为什么打饭要排队呢?进程为什么要在 CPU上排队呢?
本质是因为目标资源稀缺 ,导致要通过优先级确认先后的问题。
打饭的窗口就那几个,可学生有上千。CPU 就只有 1 或 2 个,可进程有几十上百个。
2.1.3 优先级 vs 权限
有些小伙伴可能混淆优先级和权限这两个概念,这里讲解一下。
优先级是已经确定能得到某种资源,确定的是得到这种资源的先后 问题
权限决定的是否够能得到某种资源。
你在学生窗口排队打饭,前提是你已经有了再这个窗口打饭的权限,排个队只是确定你打饭的先后顺序而已。你为什么不去教师窗口排队?因为你没有在教师窗口打饭的权限
2.2 Linux中的优先级
2.2.1 基本特点
在操作系统中,优先级本质是一种数字 (int),它是 PCB(task_struct)中的一个属性。
优先级数字值越低,表明优先级越高;反之越低。
包括 Linux 在内的大部分操作系统,都是基于时间片的分时操作系统 。
每一个进程都会分有自己的时间片。时间片:每个进程占有CPU不是一直占的,假设每个进程每次只有 10纳秒 时间,跑完 10纳秒 就要等待下一轮。
这一类的操作系统的一个特点:必须考虑一定的公平性!
即进程虽然有优先级的差别,但差别不能太大!优先级可以变化,但是变化的幅度不能太大
2.2.2 查看进程优先级
我们写一段代码来查看其可执行的优先级
c
#include<stdio.h>
#include<unistd.h>
int main()
{
while(1)
{
printf("I am a process,pid:%d\n",getpid());
sleep(1);
}
return 0;
}命令行代码:
ps -al 查看所有进程信息
我们也可以进行过滤:
ps -al | head -1 ; ps -al | grep code

UID(user id):Linux 系统时如何识别 root用户 和其他 普通用户 的?
每一个用户都有自己的用户 id(UID) 。
显示 UID 我们可以在ls指令加 -n 命令行选项。
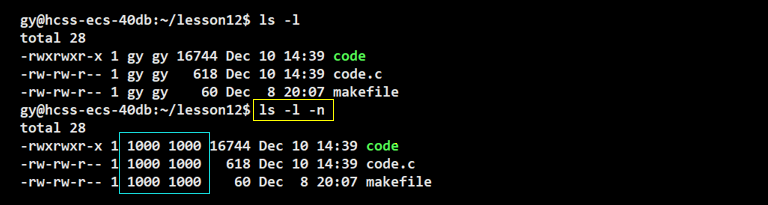
前面我们学习权限的时候,讲到系统要区分当前用户的身份(拥有者、所属组、other),以判断该用户有没有对该文件的相关权限。
系统是如何知道我们的身份的?
现在我们已经知道了,所有的指令都是进程,所以访问文件本质就是进程在访问文件。
进程在启动时,会记录启动自己的用户的 UID ,所以进程只需和自己的 UID 和文件的 UID 做对比就能判断用户的身份。
Linux中访问任何资源都是进程访问,进程就代表用户
- PRI:进程的优先级 ,默认:
80- NI:进程优先级的修正数据,也称 nice 值,默认为 0
2.2.3 调整优先级
Linux 中,进程的优先级是可以调整的。
不管是启动进程前还是启动进程中都可以调整
虽然优先级可以改,但是不建议大家去修改
我们不能通过修改 PRI 来修改进程优先级
修改优先级我们是通过修改 NI 只来修改
进程真实的优先级 = PRI的默认值(80) + NI
下面,我来演示如何修改优先级。代码同上
c
#include<stdio.h>
#include<unistd.h>
int main()
{
while(1)
{
printf("I am a process,pid:%d\n",getpid());
sleep(1);
}
return 0;
}首先将可执行文件(进程)启动
在 shell 中输入 top 指令
在 top 指令中直接输入 r(renice) 指令后,输入要修改进程的 pid
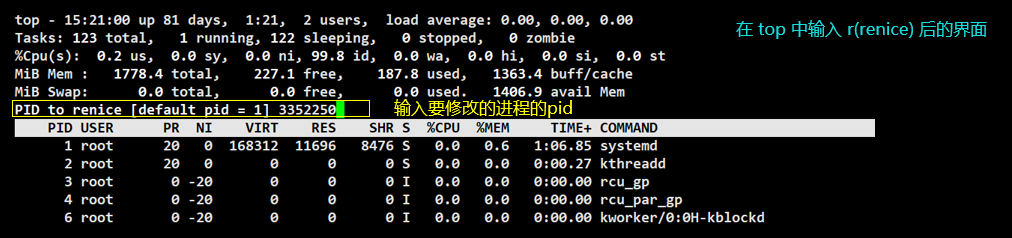
再输入修改后的 NI 值,这里我们将 NI 值改为 10
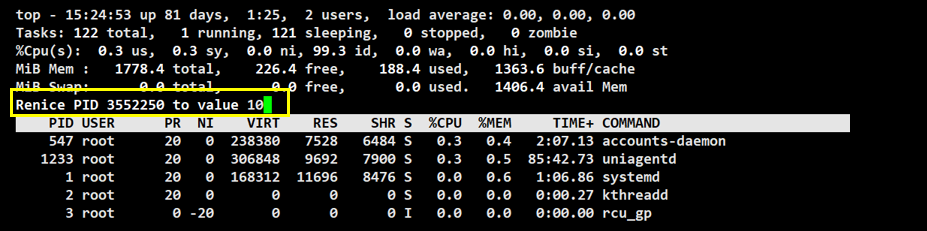
此时再来查看进程的优先级

此时该进程的优先级等于 PRI的默认值(80) + NI 值 == 90 ,优先级调低了。
也可以看出,Linux 中 PRI 的值才是该进程最终的优先级
我们现在将 NI 改为 -10
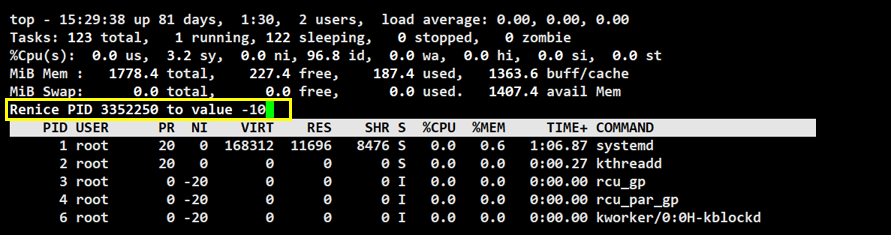
注:Linux 中不允许频繁修改优先级,此次修改可能失败,可以切换成 root 修改

此时的优先级 PRI 是 70,并不是上一次的优先级 90 + NI(-10)== 80。
进程的优先级 == PRI的默认值 + NI
为什么要这么定义优先级呢?
如果我们每次基于上一次的优先级进行调整,我们还需先查上一次的优先级。而这么设计,我们就可以不关系历史值,可以直接调整到预期的优先级
2.2.4 优先级的极值
优先级最高是多少?最低又是多少?:
修改 NI 值为 100:

修改 NI 值为 -100:

NI 值的范围:【-20,19】,则Linux中进程优先级范围【60,99】,中间一共40个优先级。
可以看到 Linux 中的优先级的范围并不大,一共 40 个级别。因为进程调度要考虑公平性,虽然优先级能决定谁先谁后,但这幅度不能太大。
为什么优先级的幅度不能太大。
如果幅度太大的话,用户有可能恶意修改自己进程的优先级,让自己进程总是优先得到资源。且会导致优先级低的进程长时间得不到 CPU 资源,进而导致:进程饥饿 。
2.3 补充概念:竞争、独立、并行、并发
- 竞争性:系统进程数目众多,而 CPU 资源只有少量,甚至 1 个,所以进程之间时具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
- 独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰
- 并行:多个 进程在多个 CPU 下分别,同时运行,称之为并行
- 并发:多个 进程在一个 CPU 下采用进程切换的方式,在一段时间内,让多个进程都得以推进,称之为并发
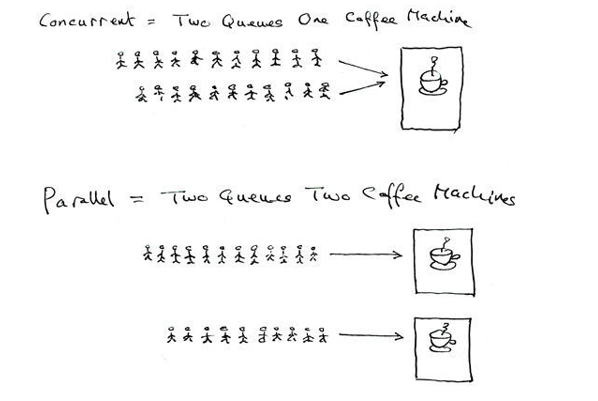
我们大部分计算机都一个 1 个 CPU,但计算机往往有多个进程。我们感官上的多个进程同时在跑(同时打开多个软件),但这只是错觉。理论上,任何一个时刻,只有一个进程在CPU运行。但如果采取多个进程在一个 CPU 上快速切换的方式,在一个时间段内,让多个进程的代码同时得以推进,这种现象我们称为并发。
并行指任何时刻都有多个进程在跑;并发指在一个时间段内,多个进程得以同时推进
3 进程调度
3.1 运行队列 runqueue
前文所说的切换解决的是将当前上下文保存的问题,可如何选择下一个进程呢?这就是进程调度需要解决的
切换和调度共同构成调度器(辅导员)
调度器完成进程切换和选择进程的工作。
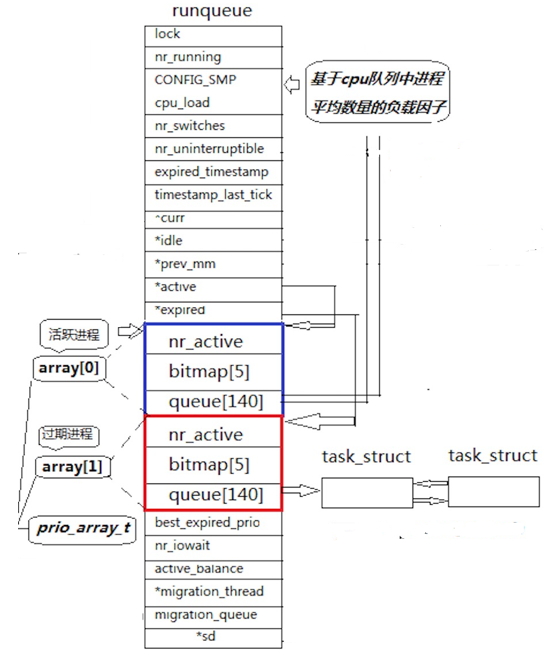
每个 CPU 都有一个运行队列,在 Lunix 内核中,这个运行队列叫:runqueue。两个CPU就两个运行队列
3.2 queue140
我们先把目光放在上图蓝色框的 queue140 身上。
queue140 的类型是:struct task_struct *queue[140],它就是一个指针数组
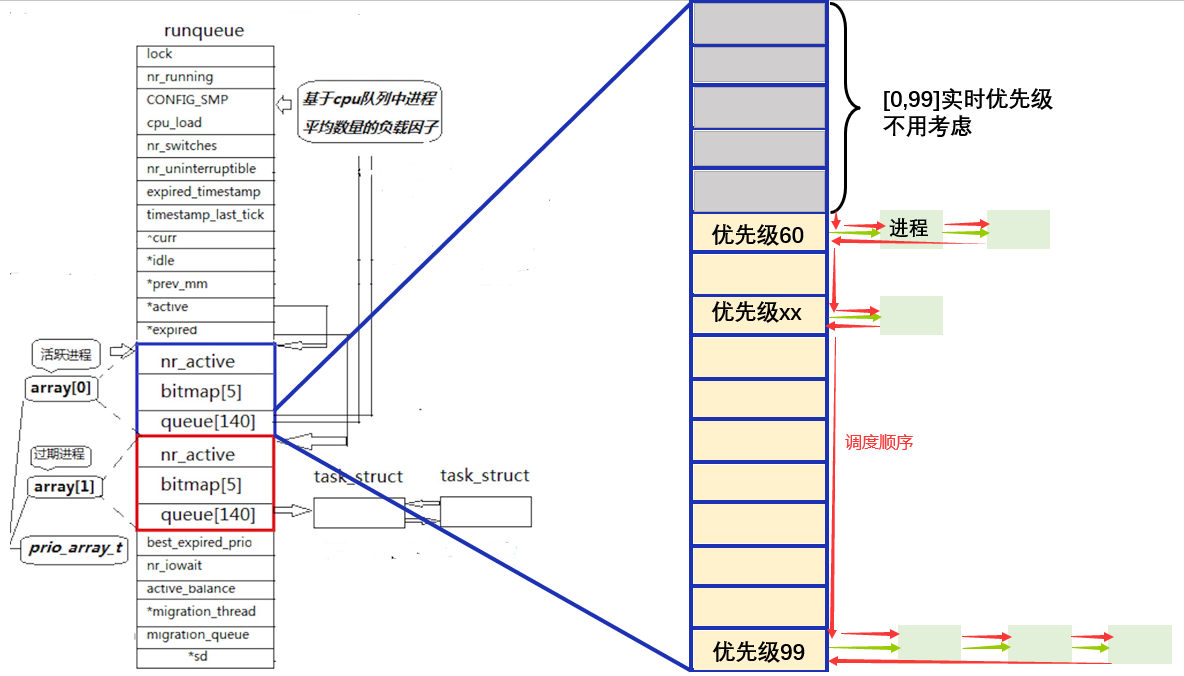
0, 99 这一百个优先级我们称为实时优先级。这个优先级我们一般不考虑
不算 100 个实时优先级,此时还剩 100, 139 共 40 个优先级,这 40 个和前文讲的进程优先级一一对应。
每一个 queue140 指针数组中一共有 140 个小队列,我们关心后 40 个,每一个小队列放着的都是 task_struct*。当有多个进程优先级相同时,比如都为 60,那么这些队列就可以整体上链入 queue140 中下标为 100 的小队列中
我们要挑选进程时,只需在 queue140 指针数组中从上往下遍历,指针不为空,就调度队列中的第一个进程,先进先出,该下标队列中所有进程调度完再继续往下遍历。
即先看优先级,优先级相同的,先进先出
当有新的进程创建时,操作系统执行根据其优先级链入 queue140 对应下标的队列中
所以 queue140 本质就是一个哈希表 。队列底层是用链表实现的,因此该哈希表是用链地址法实现的。
所以他的插入删除是 O(1)。
可是操作系统要按优先级选择一个进程,依然要遍历 queue140 指针数组,最坏的情况是前面都没有,一直到优先级 99 才有进程。算法的复杂度是 O(n)
3.2.1 实时优先级
实时优先级是什么呢?我们简单介绍一下:
操作系统分为两大类别:分时操作系统和实时操作系统。
分时操作系统 :按照时间片为单位进行公平调度
实时操作系统 :一旦来了进程,这个进程必须立即被响应
实时操作系统一般在工业领域和制造业领域应用较多。
举个例子:像是自动驾驶汽车,当需要紧急刹车时,系统必须立即相应刹车进程。想想要是分时操作系统,需要刹车时,CPU说:不行,这音乐进程的时间片还没到,还轮不到你刹车
而互联网领域几乎全都是分时操作系统
为什么?举个例子:我现在要听歌,要是是实时操作系统,CPU 说:不行,你要把代码写完才能听。这样还有用户愿意用这样的操作系统吗?
为什么 Linux 还要有实时优先级呢?Linux 不是主要做服务器的吗?
谁不想让自己的操作系统被更多人用。虽然 Linux 是在后端服务器领域应用最广泛,并不代表 Linux 只能在该领域被使用,它在某些工业领域业可以被使用。
所以大部分操作系统为了能被更多人用,都是即支持实时,又支持分时的。只是实时的部分一般被条件编译裁掉了
3.3 bitmap5
调度器挑选一个进程要遍历 queue140 数组,虽然只有 40 个,可复杂度依然是 O(n)
如何进行优化呢?
我们将目光放到蓝色框中的 bitmap[5] 中
bitmap5 是一个位图,他是由 5 个无符号整数(unsigned int)组成
unsigned int 占 32 个比特位,一共 160 个比特位。
每个比特位和 queue140 的每个位置是一一对应的(多出的20位不要)。
比特位的内容(1/0)表示的是是否存在进程!即指针是否为空。
所以调度器快速挑选一个进程一个分为两步:
- 挑队列
- 挑进程
有了 bitmap,挑队列不需要再遍历数组,只需查看对应的位图即可。以前需检测 40 位,现在只需检测 5 位。
这样就做到了以接近 O(1) 的时间复杂度挑选一个进程。
蓝色框中,还有一个成员:nr_active,表示的是整个运行队列中一个有多少个进程。
完整的调度过程是:
- 查 nr_active
- 当 nr_active > 0 ,查 bitmap 确认下标
- 找到目标队列,从目标队列头部开始调度
3.4 活跃队列与过期队列
如果操作系统的调度算法就是上面所讲的那样,你会发现一个很尴尬的问题:
假设一个进程优先级为 60,进程的时间片到了,它仅仅是链入优先级为 60 的队列的最后位置,这样仅仅是优先级为 60 的队列的那几个进程在不断循环,操作系统永远只执行优先级为 60 的进程,其他优先级的进程操作系统看都不看。
如何解决这个问题呢?
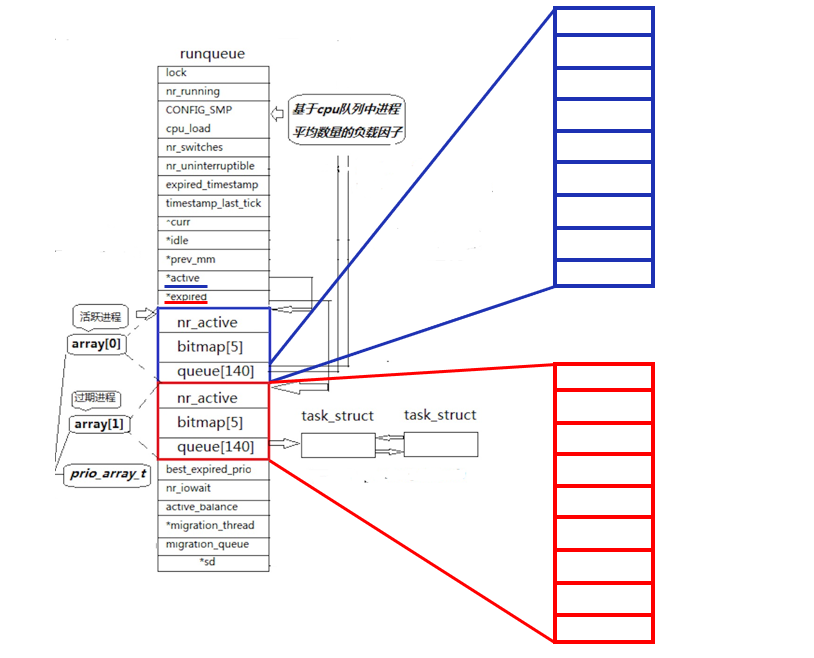
Linux 中将蓝框和红框的内容整理成结构体,假设该结构体名 struct rqueue_elem ,成员如下
c
struct rqueue_elem
{
int nr_active;
bitmap[5];
queue[140];
}。 同时又定义了一个数组,struct rqueue_elem prio_array[2],数组中只有两个元素,放的是两个 struct rqueue_elem 类型对象
runqueue 中还定义了两个指针:* active 和 * expired,他们的类型是 struct rqueue_elem。
默认*active 指向 prio_array0,*expired 指向 prio_array1。
CPU 挑队列挑进程,永远只从 *active 中找到对应结构体对象中的 queue140 队列,根据上文所说的 O(1) 调度算法进行进程的调度。
当一个进程时间片结束,从 CPU 上剥离下来后,不能放回 *active 指向的活动队列中,而是链入 *expired 所指向的过期队列中。
在一个调度周期, *active 指向的队列(活动队列)中的进程会越来越少,*expired 指向的队列(过期队列)的进程会越来越多。只有将活动队列的进程全部调度完才能做后续动作。
活动队列的进程全部被掉完后,只需要交换 *active和*expired指针,这样过期队列就成了新的活动队列。进行新一轮的调度。
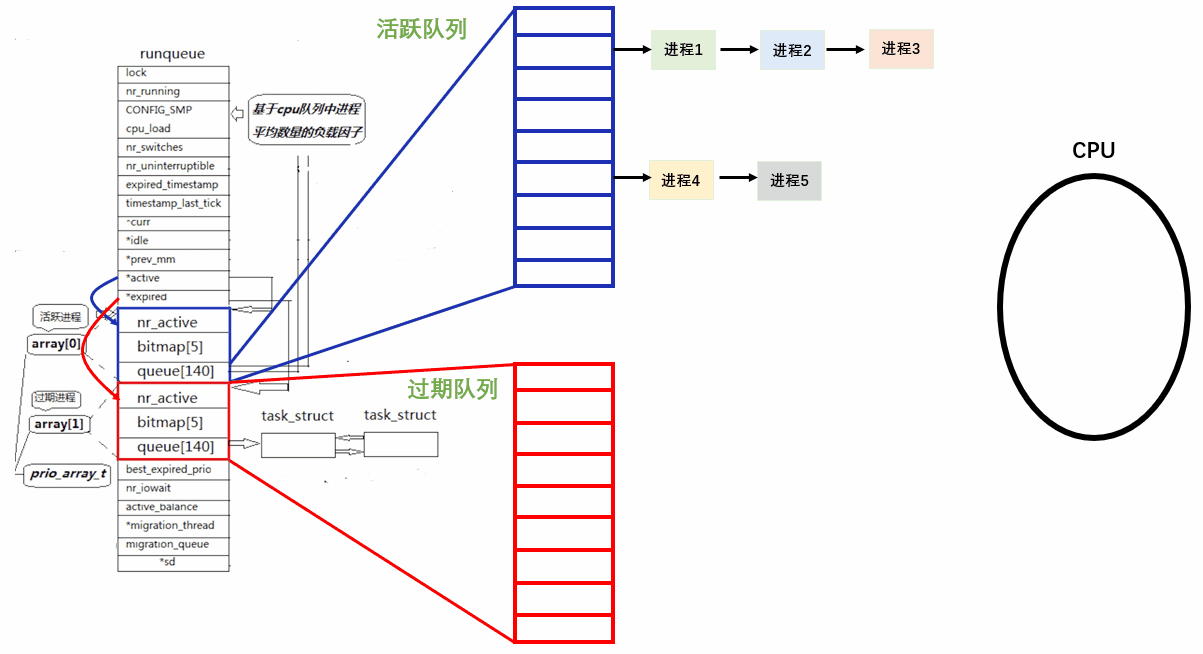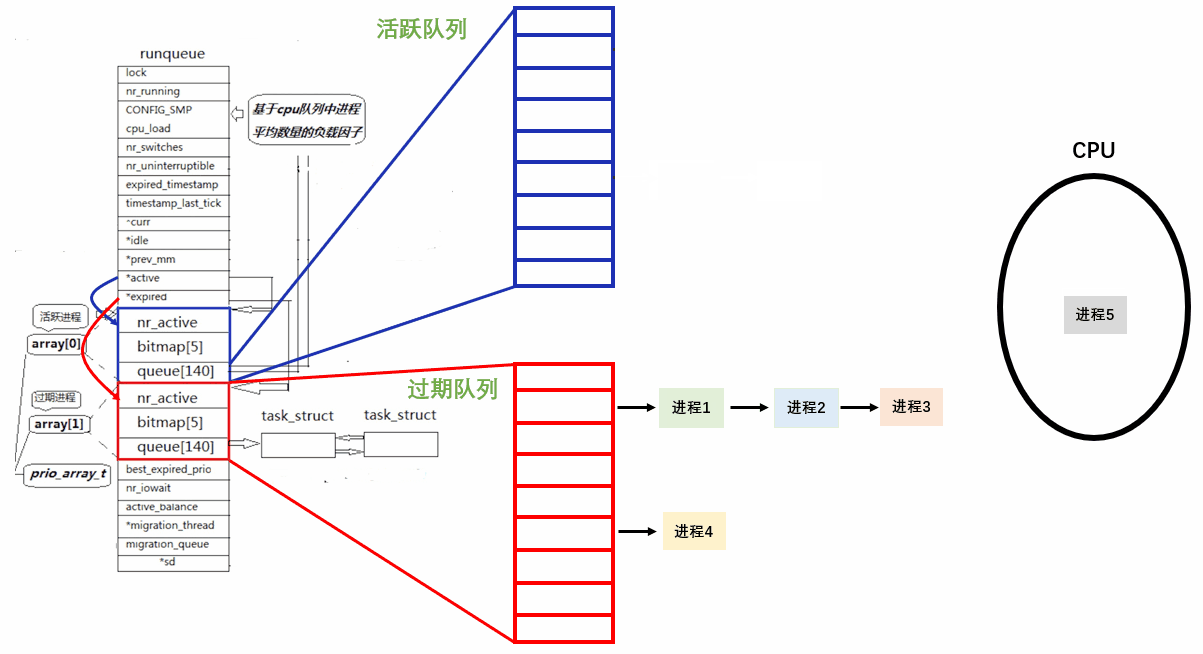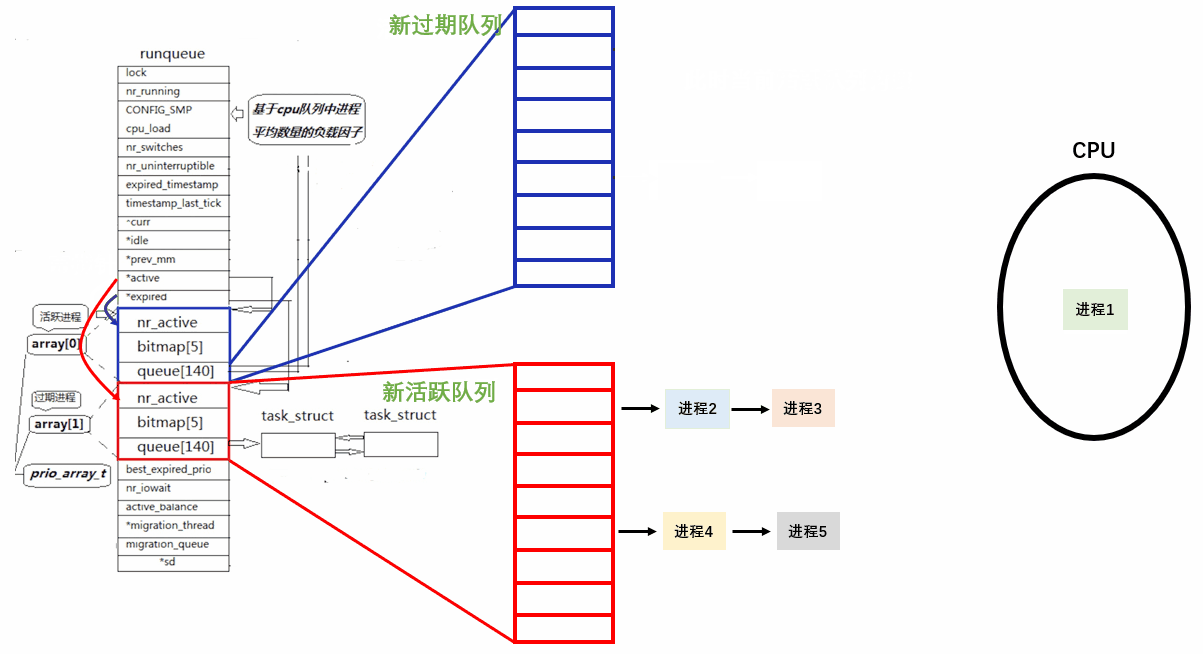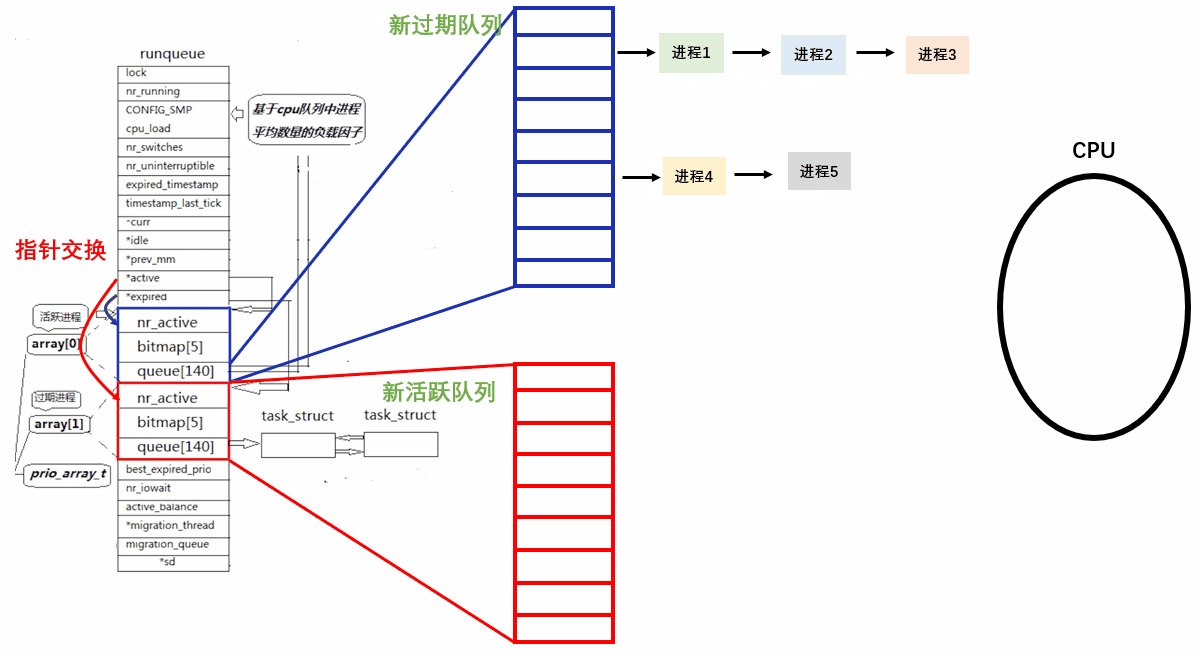
如果来了一个新进程,那新进程是链入过期队列还是活跃队列呢?
分时操作系统支持内核抢占。新进程我们要给它一个特权,要让其尽快运行,因此运行新进程插队。插在过期队列算插队吗?不算。因此我们会把新进程根据优先级链入活跃队列中。
好啦,本期关于进程切换与进程调度的知识就介绍到这里啦,希望本期博客能对你有所帮助。同时,如果有错误的地方请多多指正,让我们在 L i n u x Linux Linux 的学习路上一起进步!