目录
[1. 随机裁剪:让模型学习更有"弹性"](#1. 随机裁剪:让模型学习更有“弹性”)
[2. 中心裁剪:让测试更加"稳定可靠"](#2. 中心裁剪:让测试更加“稳定可靠”)
[1. 为什么训练时要使用随机裁剪?](#1. 为什么训练时要使用随机裁剪?)
[2. 为什么测试时要使用中心裁剪?](#2. 为什么测试时要使用中心裁剪?)
看似相似的两种裁剪技术,却在模型训练与测试中扮演着截然不同的角色。
在计算机视觉和深度学习领域,图像预处理是模型成功的关键一步。今天我们将深入探讨两种最常用且最重要的裁剪技术:随机裁剪(Random Crop) 和中心裁剪(Center Crop)。虽然它们都名为"裁剪",但背后的设计理念和应用场景却大相径庭。
一、核心区别:一张图看懂两种裁剪技术
| 特性 | 随机裁剪 (Random Crop) | 中心裁剪 (Center Crop) |
|---|---|---|
| 核心原理 | 在图像随机位置选取起点进行裁剪 | 从图像正中心开始进行裁剪 |
| 主要目的 | 数据增强,提升模型泛化能力 | 标准化处理,确保测试结果一致性 |
| 输出结果 | 不固定,同一张图每次裁剪可能不同 | 固定,同一张图每次裁剪结果相同 |
| 使用场景 | 模型训练阶段的主力军 | 模型测试/推理阶段的标准流程 |
| 本质 | 引入随机性的正则化技术 | 消除随机性的标准化技术 |
二、工作原理:一图胜千言
让我们通过一个流程图,直观地理解两种裁剪方式的工作过程:
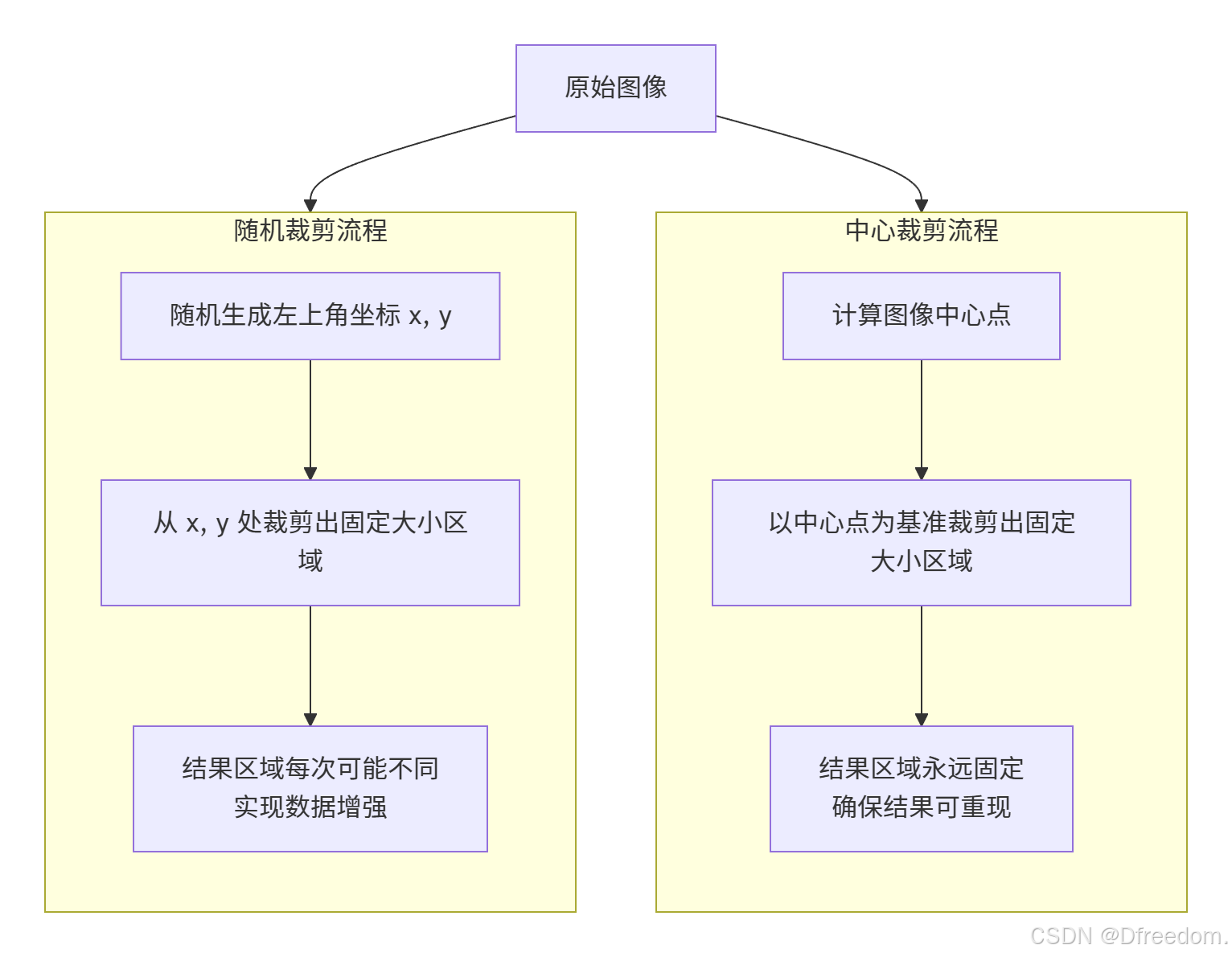
1. 随机裁剪:让模型学习更有"弹性"
想象一下,如果老师教你识别狗狗,每次都展示同一张正脸照片,你可能只会识别这种特定角度的狗。但如果老师向你展示狗的侧脸、背影甚至局部特征,你就能学会从各种角度识别狗。
随机裁剪就是这样一位"老师",它的工作流程如下:
随机裁剪工作流程:
输入一张训练图像
随机生成裁剪起始坐标 (x, y)
从该位置裁剪出预定大小的区域
将裁剪后的图像送入模型训练
这种随机性确保了同一张训练图像每次都能以不同的"面貌"呈现给模型,极大地丰富了训练数据的多样性。这就是数据增强(Data Augmentation)的核心价值,也是防止模型过拟合的最有效手段之一。
2. 中心裁剪:让测试更加"稳定可靠"
到了模型测试阶段,我们需要一个公平、稳定的环境来评估模型性能。如果每次输入的测试图像都不相同,就很难公正评判模型的真实能力。
中心裁剪提供了这种"标准化考卷",它的工作流程如下:
中心裁剪工作流程:
输入一张测试图像
计算图像中心点坐标
从中心点开始裁剪出预定大小的区域
将裁剪后的图像送入模型进行预测
这种确定性保证了同一张测试图像每次都会以完全相同的方式输入模型,确保了测试结果的可重复性和可比性。
三、原理解析:训练与测试的目标差异
📊 训练 vs. 测试:截然不同的目标
| 阶段 | 核心目标 | 关键策略 | 图像处理方式 |
|---|---|---|---|
| 训练 (Training) | 让模型学习、泛化 | 数据增强 | 随机裁剪 (Random Crop) |
| 测试/推理 (Testing/Inference) | 公平、稳定地评估模型 | 确定性、可重复性 | 中心裁剪 (Center Crop) |
1. 为什么训练时要使用随机裁剪?
训练阶段的最高目标是提升模型的泛化能力(Generalization),即让模型在未见过的数据上也能表现良好,而不是仅仅记住训练集。
随机裁剪通过以下机制实现这一目标:
-
增加数据多样性:通过随机裁剪,模型能够看到物体的不同部位、不同角度和不同背景
-
防止过拟合:避免模型死记硬背训练样本的具体特征,而是学习更通用的特征表示
-
提升鲁棒性:使模型对目标物体的位置、大小和背景变化更加不敏感
2. 为什么测试时要使用中心裁剪?
测试阶段的最高目标是公平、准确、稳定地评估模型性能。所有引入随机性的操作都必须被排除。
中心裁剪确保:
-
结果可重复:同一张图像每次都会产生相同的裁剪结果
-
公平比较:不同模型可以在相同的输入条件下进行性能比较
-
稳定评估:排除随机性因素,准确反映模型的真实能力
四、实战案例:猫狗识别器的训练与测试
训练阶段:使用随机裁剪增强模型泛化能力
假设我们正在训练一个猫狗分类器,有一张训练图片是"一只柯基在草坪上玩耍"。
使用随机裁剪后,模型在训练过程中可能会看到:
-
第一次:柯基的正面和部分草坪
-
第二次:柯基的尾巴和周围环境
-
第三次:只包含柯基头部的小区域
通过这种方式,模型学会了从各种局部特征识别柯基,而不会形成"柯基必须出现在画面中央"的偏见。这种训练出来的模型在真实场景中会更加鲁棒,即使柯基只出现在画面角落也能准确识别。
测试阶段:使用中心裁剪确保公平评估
当我们需要测试模型性能时,输入一张新的"猫咪在沙发上"的图片。
使用中心裁剪确保:
-
每次测试都从图像中心裁剪出固定大小的区域
-
所有模型都接收到完全相同的输入内容
-
测试结果真实反映模型识别能力,不受随机因素影响
这样可以公平地评估模型的真实能力,确保测试结果的可比性和可靠性。
五、如何选择:简单明了的使用指南
-
训练阶段 → 选择随机裁剪(增加数据多样性,提升模型泛化能力)
-
测试阶段 → 选择中心裁剪(确保结果一致性,公平评估模型性能)
核心原则:训练要"多样性",测试要"一致性"。正确使用这两种裁剪技术,能够显著提升你的计算机视觉模型性能。