背景:内网环境使用大模型前的准备
联网
windows系统我选择安装docker desktop
安装好后,需要跟着docker destop提示 下载子系统linux
docker hub中搜索可用镜像
- ollama
shell
# 1. 下载 Docker 镜像(需联网)
docker pull ollama/ollama
# 2. 导出镜像为离线包
docker save ollama/ollama -o ollama-image.tar- 大模型
拉取到ollama容器中
bash
# 1. 确保模型数据在容器内部(不在卷中)
# 重新运行容器,不使用卷挂载
docker run -d --name ollama-no-volume ollama/ollama
# 2. 在这个容器中拉取模型
docker exec -it ollama-no-volume ollama pull gpt-oss:20b
# 3. 提交这个容器
docker commit ollama-no-volume gpt-oss-complete:latest
# 4. 保存镜像(这次应该包含模型数据)
docker save gpt-oss-complete:latest -o gpt-oss-complete.tar- 命令执行截图
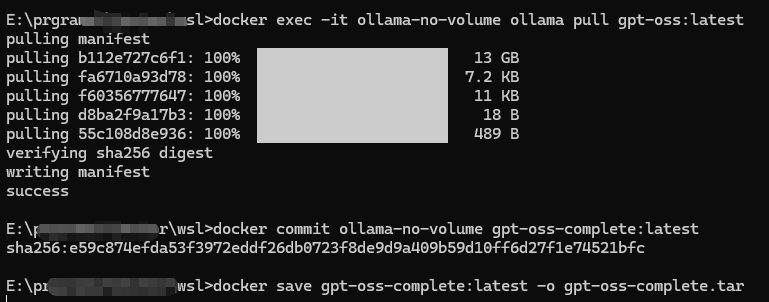
- 离线
bash
# 1. 传输文件到离线服务器
scp ollama-image.tar user@offline-server:/data
scp gpt-oss-20b-model.tar user@offline-server:/data
# 2. 加载 Docker 镜像
docker load -i /data/ollama-image.tar
# 3. 导入模型
mkdir -p /mnt/models
docker run -it -v /mnt/models:/root/.ollama ollama/ollama ollama import /data/gpt-oss-20b-model.tar
# 4. 启动服务(带 GPU 支持)
docker run -d \
--name ollama_gpt \
--gpus all \
-v /mnt/models:/root/.ollama \
-p 11434:11434 \
ollama/ollama- 验证服务
bash
# 1. 检查容器状态
docker logs ollama_gpt | grep "model loaded"
# 2. 发送测试请求(JSON 格式)
curl -s http://localhost:11434/api/generate -d '{
"model": "gpt-oss:20b",
"prompt": "Docker离线部署的优势",
"stream": false
}' | jq .response
# 预期输出:
# "Docker离线部署可在隔离环境中运行模型,无需依赖外部网络..."- 资源优化配置
根据设备显存调整 GPU 层数:
bash
# 高端 GPU(40GB+)
docker exec ollama_gpt ollama run gpt-oss:20b --gpu-layers 35
# 中端 GPU(24GB)
docker exec ollama_gpt ollama run gpt-oss:20b --gpu-layers 20
# 纯 CPU 模式(量化版本)
docker exec ollama_gpt ollama run gpt-oss:20b-q4_0- 常见问题排查
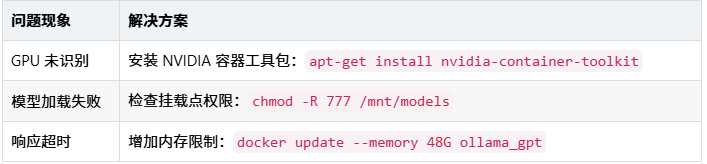
拓展
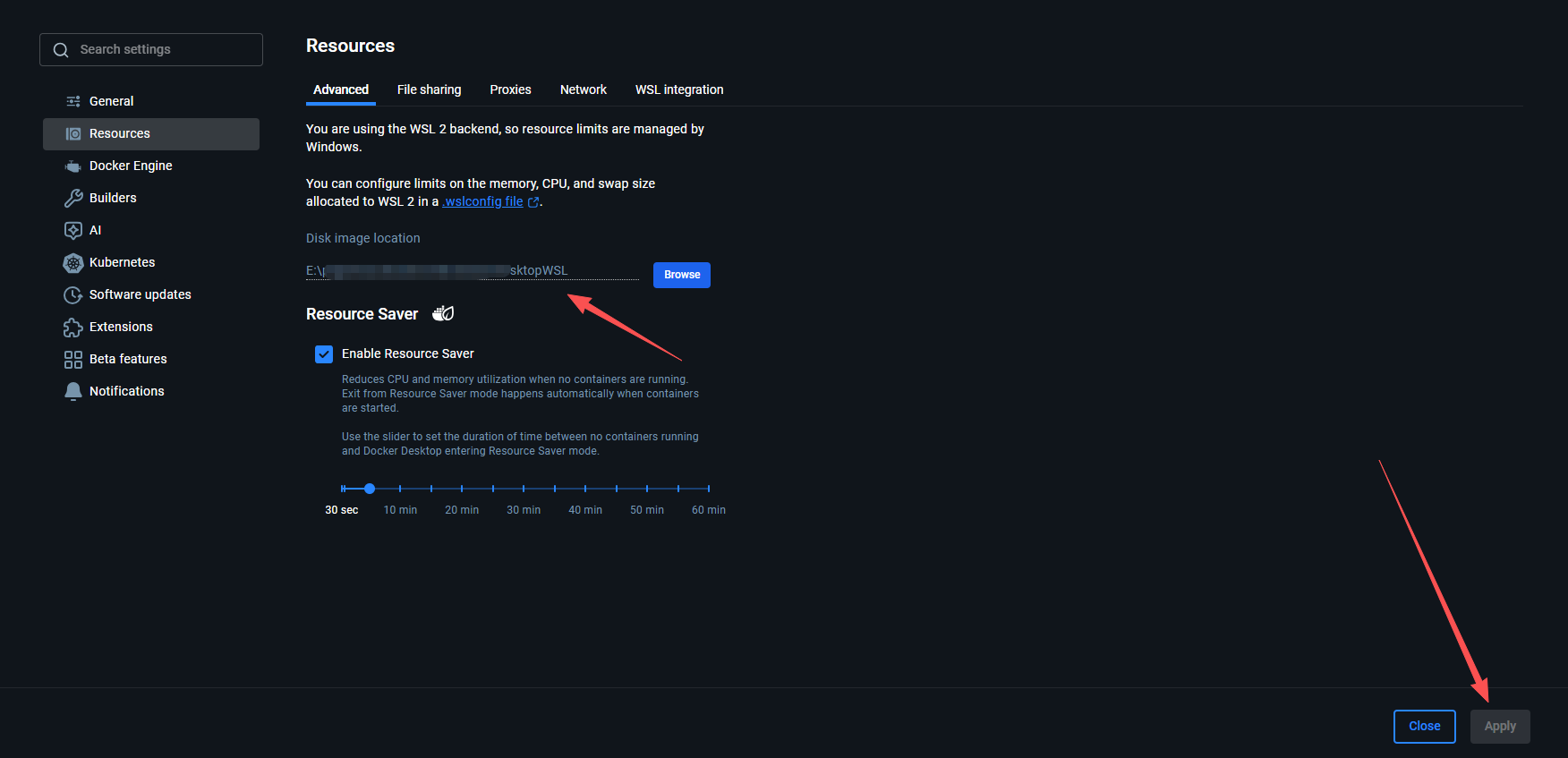
- windows desktop占用c盘空间,迁移到其他盘符
- 配置docker desktop阿里镜像加速器
- 登录你的阿里云账号 ,访问这个链接, 将如下内容加到配置中
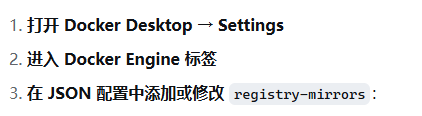
- 登录你的阿里云账号 ,访问这个链接, 将如下内容加到配置中
json
{
"registry-mirrors": ["https://1i***n.mirror.aliyuncs.com"]
}