0. 前言
在数字人文与历史研究领域,浩如烟海的古籍文献是宝贵的文化遗产。然而,如何让计算机自动"读懂"这些布局复杂、版式多变的古籍,精确地识别出其中的标题、段落、注释、插图等元素,一直以来都是一个巨大的挑战。传统的深度学习方法(如 Faster R-CNN、YOLO 等)在面对中文古籍稀疏的文字前景、紧密的排版和长程的语义依赖时,往往表现不佳。近期,合合信息与华南理工大学文档图像分析识别与理解联合实验室发表论文《HisDoc-DETR: Integrating Semantic Learning and Feature Fusion for Historical Document Layout Analysis》,提出了针对中文古籍历史文献版面分析的端到端检测框架 HisDoc-DETR,结合语义关系建模、双流特征融合与 GIoU 感知预测头三大技术创新,显著提升了在稀疏、复杂版面场景下的检测精度和定位鲁棒性,在唯一的公开中文历史文档数据集 SCUT-CAB 上取得了最先进 (State-of-the-Art) 的性能。
1. 研究背景
古籍和历史文献在文化保护、数字人文和学术研究中价值巨大,但历史文档,尤其是中文古籍,与现代文档有着天壤之别,这为自动化分析带来了独特挑战:
- 版面稀疏且不规则:相较于现代报纸、杂志,古籍中文字、题跋、插图等元素分布稀疏且不规则
- 字体、墨迹、噪声多样:老化、褪色、墨渍会破坏局部纹理,使得简单的像素或边缘判断不可靠
- 语义场景复杂:上下文语义、行列关系、装饰元素都可能影响版面分析的判定
尽管许多通用的检测器(例如 Faster R-CNN、Mask R-CNN、YOLO、RetinaNet、FCOS 和 Deformable DETR 等)在规则化、密集场景下表现良好,但面对古籍文档时,依然存在难以克服的结构性缺陷:
- 卷积神经网络的核心是卷积操作,其擅长捕捉局部特征,但感受野有限,难以建立图像中远距离区域间的语义关联,而古籍中常见的"注释对应正文"、"跨页标题"等现象,恰恰需要这种全局的、长程的上下文理解能力
- 传统目标检测模型将文档视为一个个独立物体的集合,通过局部特征进行分类和回归,但它们缺乏对文档作为一个整体语义结构的理解,例如,模型可能能框出一个"框",但很难理解这个"框"作为"章节名"在整个文档中的逻辑作用
- 历史古籍文档的扫描图像远非现代文档那样规整,污渍、墨迹扩散、纸张发黄、褶皱、破损等极为常见,这些噪声与文本本身高度混杂,对模型的特征提取和判别能力提出了极高要求,传统模型极易被干扰,产生误检和漏检
另一方面,虽然 Transformer 能够建模长程依赖关系,但原生 DETR 在稀疏目标或小样本数据下收敛慢、定位与置信度不完全一致,因此,低层次特征(纹理/边缘)与高层语义(章节/题跋)的信息需要更灵活、更有选择性的融合,HisDoc-DETR 从增强语义关系建模、加强多尺度细节融合、以及定位质量与置信度耦合三方向提出改进。
2. HisDoc-DETR 模型架构
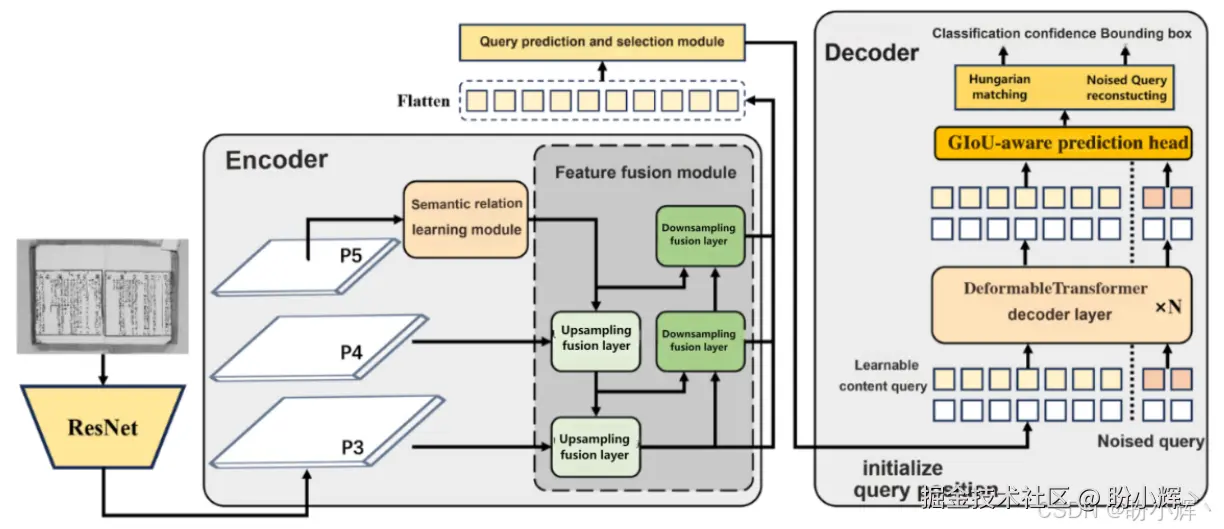
HisDoc-DETR 的整体设计思想是基于 DETR (Detection Transformer) 的端到端目标检测范式,并针对历史古籍文档的特性进行了创新性改进。其核心在于摒弃了传统目标检测模型中复杂的锚框 (anchor) 设计和非极大值抑制 (Non-Maximum Suppression, NMS) 后处理步骤,通过 Transformer 的编码器-解码器结构和集合预测的思想,直接输出最终的布局元素预测结果。下图展示了 HisDoc-DETR 的总体架构,它主要包含四个核心部分:
- 骨干网络:通常采用在
ImageNet上预训练好的ResNet模型,用作特征提取器,从输入图像中提取多尺度的视觉特征图 - 编码器:在多尺度特征上加入语义关系学习模块与双流特征融合模块,用以捕获长程依赖关系并提升特征区分度
- 解码器:使用
Deformable Transformer解码器,配合学习型查询与去噪查询机制,以边界框和类别标签的形式预测版面元素 - 预测头:引入
GIoU感知分类目标,使分类置信度与框定位质量一致,提升后处理稳健性
3. 关键创新点
接下来,详细介绍 HisDoc-DETR 的三大核心创新模块。
3.1 语义关系学习模块
语义关系学习 (Semantic Relation Learning) 模块的核心是一个 Transformer 的自注意力层,如下图所示,用于增强编码器在页面级别建模长程语义依赖关系的能力,帮助网络理解"分散但语义相关"的元素(例如章节标题与正文之间的语义联系)。例如,这使得模型能够"理解"一个远处的注释框与当前的正文框之间的关系,从而做出更准确的判断。
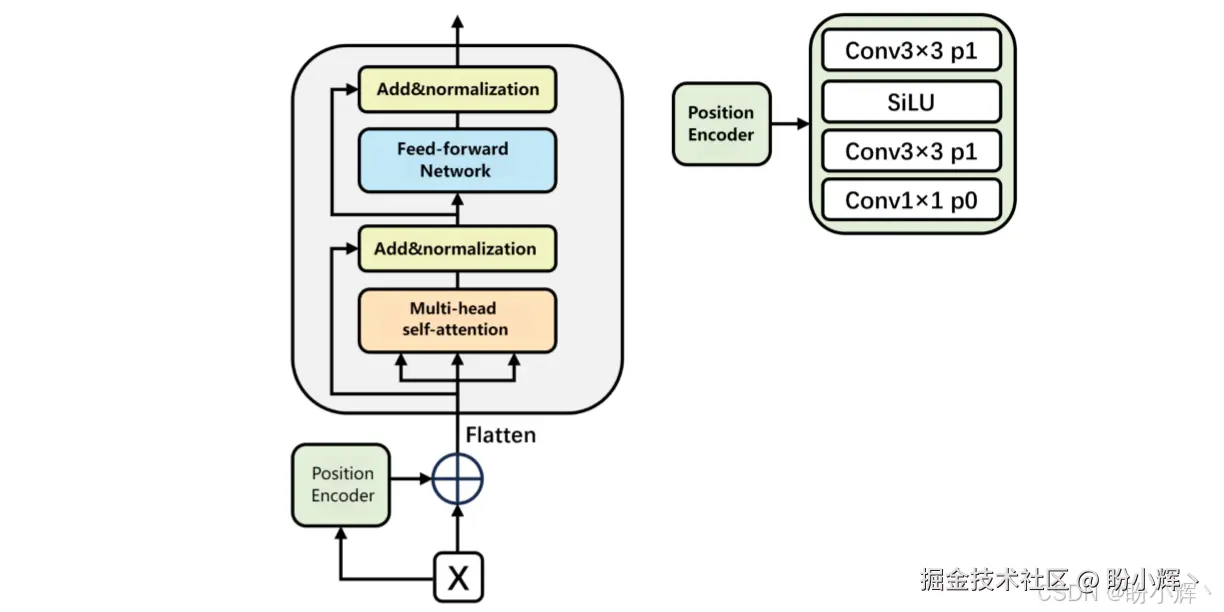
在具体实现上,语义关系学习模块对骨干网络的高层特征应用带 padding 的卷积与 SiLU 激活以获得更平滑的位置编码,需要注意的是,HisDoc-DETR 使用位置编码的卷积变换而不是原始 Transformer 中的正弦/余弦编码,因为古籍页面的局部空间变形与噪声更适合卷积导出的平滑空间先验;然后在该位置编码上执行带残差和层归一化的多头自注意力以捕获长程交互;可叠加若干 Transformer 编码器块,以增强语义传递。
3.2 双流特征融合模块
双流特征融合 (Dual-stream Feature Fusion) 模块通过注意力机制融合语义特征与低级特征,如下所示,用于高效融合来自网络不同深度的多尺度特征图。双流特征融合不像特征金字塔网络 (Feature Pyramid Network, FPN) 那样进行简单的自上而下和自下而上的特征融合,更在融合后引入了通道注意力 (Efficient Channel Attention, ECA) 和空间坐标注意力 (Coordinate Attention, CA) 机制。这意味着模型不仅知道"哪些特征通道更重要"(通道注意力),还能感知"特征图在空间哪个位置更重要"(坐标注意力),从而将高级别的语义信息与低级别的细节信息(如笔划、边缘)进行智能融合,生成质量更高的视觉特征表示。
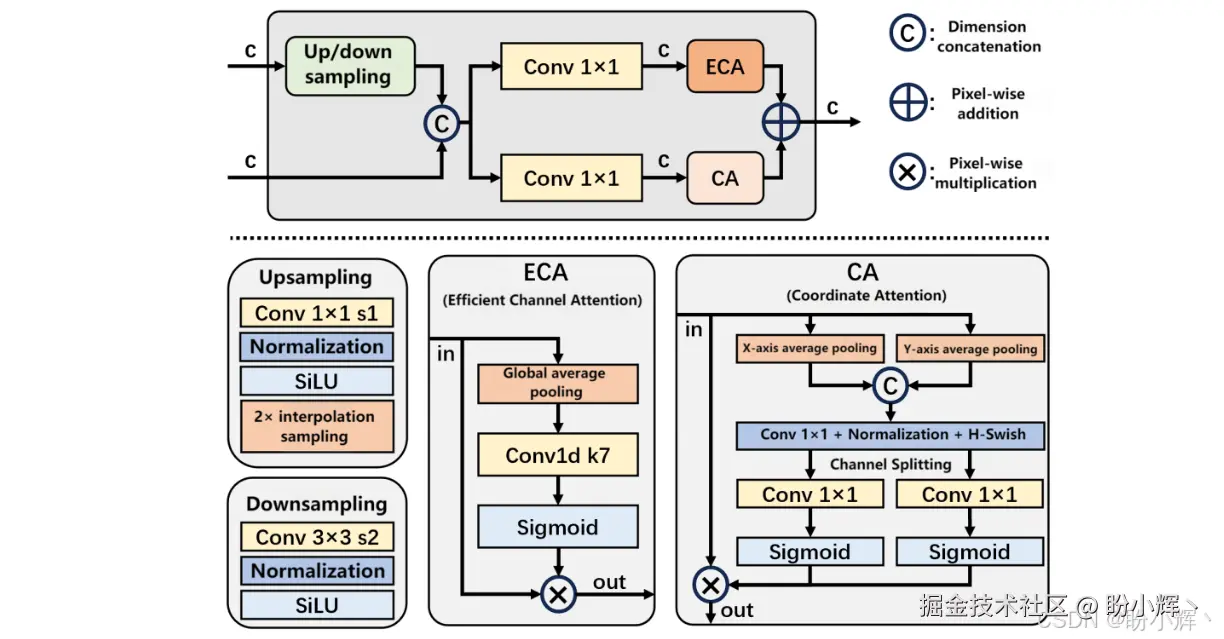
在具体实现上,双流特征融合模块对相邻尺度特征做统一尺寸变换(上采样或下采样)后进行通道拼接;然后将拼接特征输入两条注意力支路,其中 ECA 是轻量且高效的通道注意力,可避免过度参数化,强调哪些通道携带主要信息,坐标注意力保留空间坐标信息,辅助局部结构定位,利于版面里行列关系的重构;最终将两条注意力的输出融合(逐像素相加或卷积融合)得到最终多尺度特征。
3.3 GIoU 感知预测头
GIoU 感知预测头 (GIoU-Aware Prediction Head) 通过关联分类置信度与边界框质量提升定位精度,它包含分类和回归(定位)两个分支,使用定制化的损失函数将分类置信度与定位质量 (GIoU) 直接关联。这意味着,模型被鼓励做出"高置信度必然对应高定位精度"的预测,有效解决了目标检测中分类与定位任务不平衡的问题。 在具体实现上,GIoU 感知预测头将每个预测框的 GIoU 归一化到 [0,1],并把它作为分类分支监督目标;改进 focal 损失训练分类分支,使其输出的置信度趋向于框的真实定位质量。
4. 模型训练
4.1 损失函数
总损失函数由三部分组成:
- Lenc:编码器阶段候选目标的损失
- Lpred:每一层解码器的预测损失
- Ldn:去噪辅助任务的损失
Lall=Lenc+0<l<L∑Lpredl+Ldnl
每一项损失都包含分类损失( GIoU 感知)和定位损失( L1 损失 + GIoU 损失)。
4.2 数据集
HisDoc-DETR 在 SCUT-CAB (South China University of Technology - Classical Chinese Books) 数据集上进行了全面评估,SCUT-CAB 是目前唯一公开可用的、专门针对复杂版式中文古籍历史文档的版面分析数据集,为评估模型在真实、复杂场景下的性能提供了至关重要的基准,数据集样本如下图所示。

SCUT-CAB 数据集共包含 4000 张高质量扫描的中文历史文档图像,其中训练集包含 3200 张图像,测试集包含 800 张图像。图像包含各种真实世界的挑战,如纸张泛黄、墨迹扩散、污渍、褶皱、光照不均等,高度还原了历史文档的数字形态。SCUT-CAB 最显著的特点是其双重标注体系,分别从"物理布局"和"逻辑布局"两个维度对文档进行解析,这与古籍研究的实际需求高度契合。
4.3 模型性能
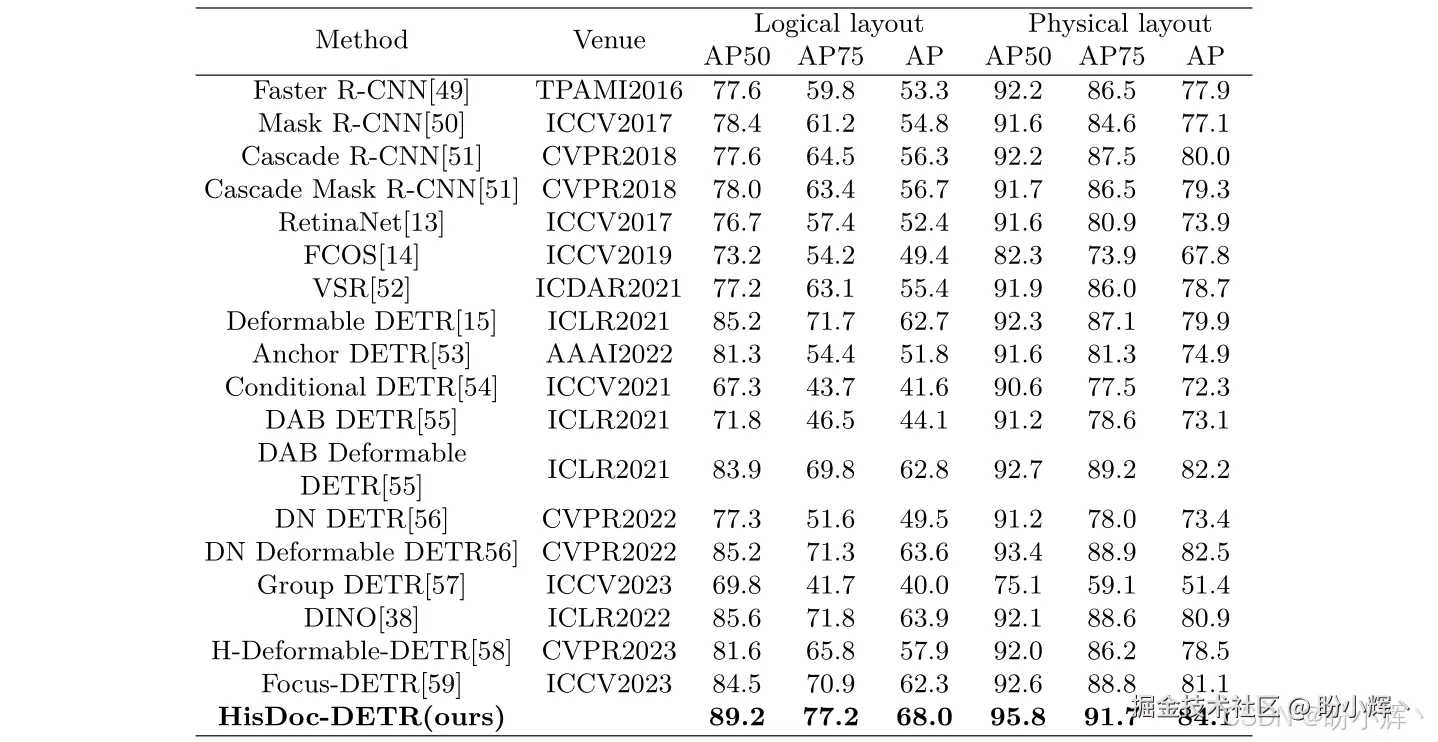
HisDoc-DETR 模型相较于 DINO 等模型,在逻辑布局与物理布局任务上分别取得显著提升:
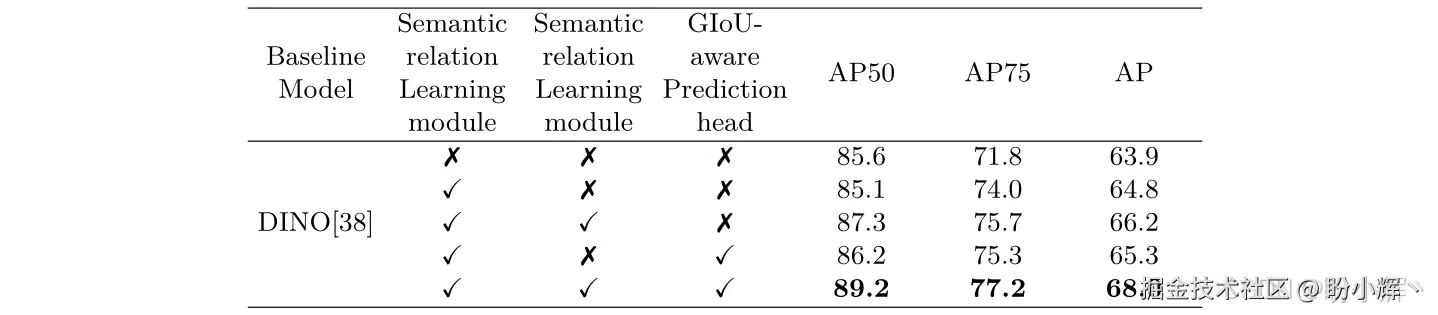
消融实验显示双流特征融合对小目标和细节提升最大,语义关系模块增强全局一致性,GIoU 感知头改善了置信度与定位的一致性,实验结果如下:
版面分析可视化结果如下所示:

5. 应用场景
HisDoc-DETR 的价值远不止于刷高一个数据集的指标,它为历史文化的数字化保存与研究开辟了新的可能性:
- 大规模数字化存档:图书馆、博物馆可以利用该技术自动解析海量扫描古籍的结构,生成高质量的元数据,实现精准检索和知识发现
- 智能阅读与文献复原:自动提取正文、注释、标题,并重建它们之间的逻辑关系,为学者提供可交互、可分析的数字化版本,甚至辅助破损文献的复原
- 文化传承与教育:基于精准的布局分析,可以开发沉浸式的古籍阅读
App,向公众生动展示古籍的原始版面和内容结构,促进文化普及 - 技术迁移:其核心思想(全局语义建模、精细特征融合、定位-分类联合优化)同样适用于其他领域的复杂文档分析,如医疗报告、工程图纸、表格检测等
HisDoc-DETR 完整论文地址:link.springer.com/chapter/10....
小结
HisDoc-DETR 的成功在于它精准地抓住了历史古籍文档版面分析的核心痛点,在多种版面类型和文档条件下均保持高精度。该模型具有更优的长程依赖关系建模能力,并针对稀疏、精细的历史古籍文档具有更强的定位能力,显著提升了复杂稀疏中文历史古籍文档版面检测的准确性与可靠性。该模型能优化古籍文档数字化存档流程,实现更精准、自动化的版面信息提取,对文化遗产保护与历史研究具有重要价值。