刚开始训练,目前只能勉强跑起来 medium的微调模型。
先记录几个有用的网址,防止以后乱了找不到。
huggingfaceface:
https://huggingface.co/stabilityai/stable-diffusion-3.5-large
问题1: 77个token如何突破
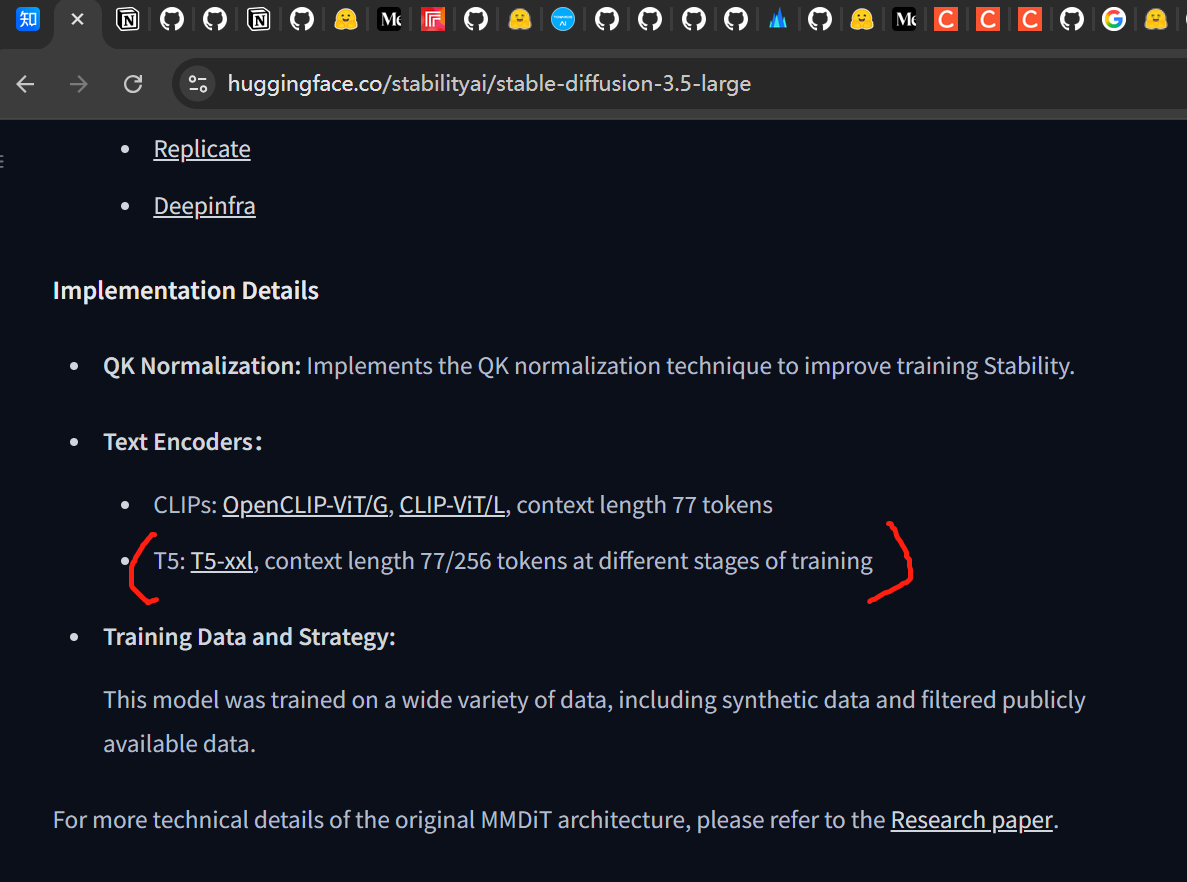
我用开源的stable-diffusion-3.5-large 遇到过clips token 超了77的问题。
现在看起来,text encoder 是可以选择 t5-xxl 进而选择256的长tokens的。
这个问题我还没解决,再次标记一下。
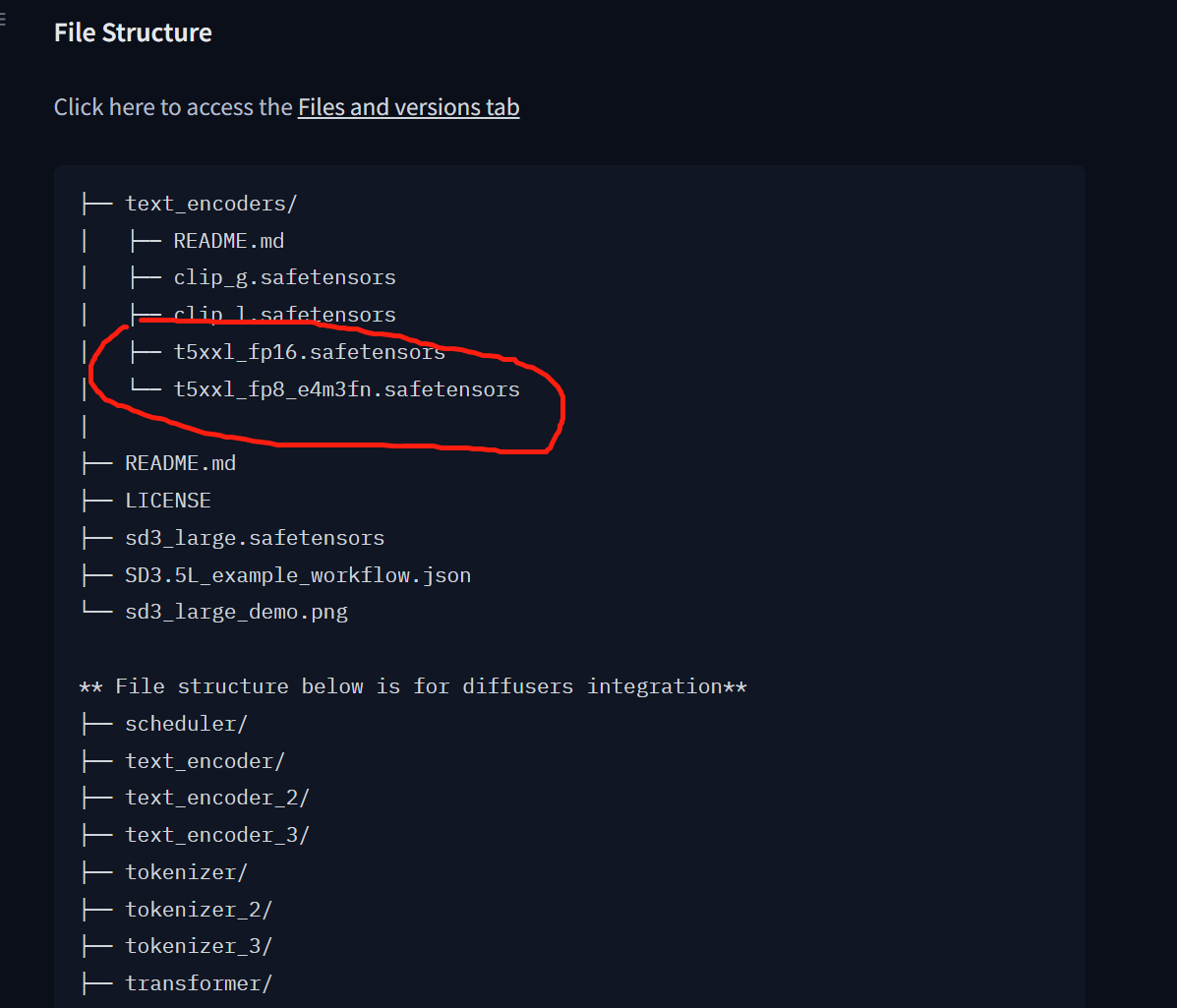
所以一定是可以这样使用的。
fine-tuning 看这里

这是一个老哥写的。
github 上也有 https://github.com/Stability-AI/sd3.5
https://github.com/Stability-AI/sd3.5
安装要看这里,但是安装的时候 要把他的 版本约束去掉
默认安装最新的
训练
https://github.com/huggingface/diffusers
用这里的代码来训练,
使用的是 diffusers
数据集:
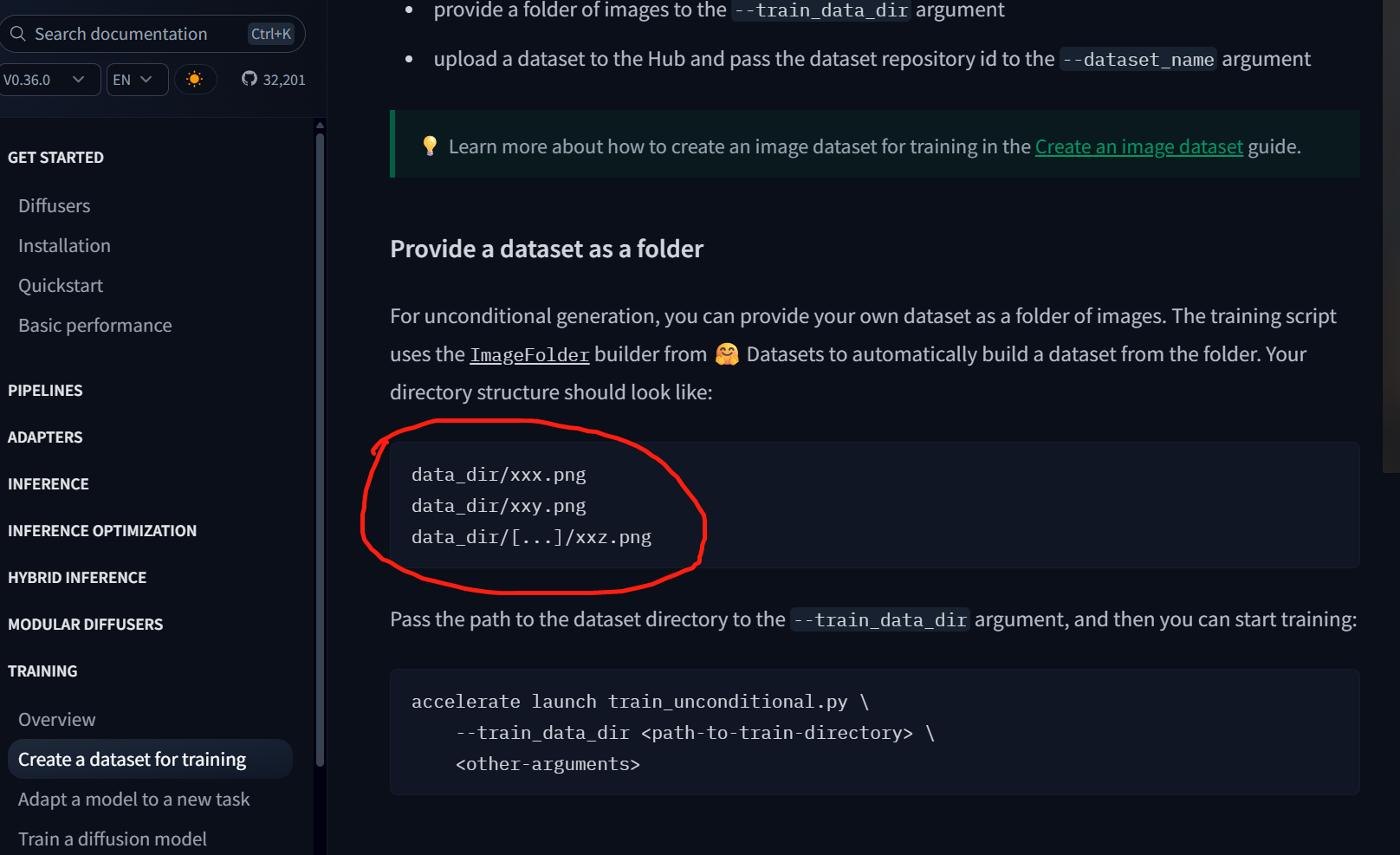

然后就把我指到了这里:
https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sd3.md
我用的命令,
bash
(train-sd) wuyou@wuyou-MS-7E47:~/train_sd/diffusers/examples/dreambooth$ accelerate launch train_dreambooth_sd3.py --pretrained_model_name_or_path=$MODEL_NAME --instance_data_dir=$INSTANCE_DIR --output_dir=$OUTPUT_DIR --mixed_precision="fp16" --instance_prompt="a photo of sks dog" --resolution=256 --train_batch_size=1 --gradient_accumulation_steps=4 --learning_rate=1e-4 --report_to="wandb" --lr_scheduler="constant" --lr_warmup_steps=0 --max_train_steps=500 --validation_prompt="A photo of sks dog in a bucket" --validation_epochs=25 --max_sequence_length 512 --seed="0"报错
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:16<00:00, 8.31s/it]
{'image_encoder', 'feature_extractor'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:16<00:00, 8.29s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 4/9 [00:00<00:00, 10.49it/s]
{'base_shift', 'use_dynamic_shifting', 'shift_terminal', 'use_karras_sigmas', 'base_image_seq_len', 'use_beta_sigmas', 'stochastic_sampling', 'max_shift', 'invert_sigmas', 'use_exponential_sigmas', 'time_shift_type', 'max_image_seq_len'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 20.09it/s]
12/25/2025 10:02:11 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
Steps: 0%|▍ | 2/500 [01:03<08:02, 1.03it/s, loss=0.289, lr=0.0001]Traceback (most recent call last):
File "/home/wuyou/train_sd/diffusers/examples/dreambooth/train_dreambooth_sd3.py", line 1818, in <module>
main(args)
File "/home/wuyou/train_sd/diffusers/examples/dreambooth/train_dreambooth_sd3.py", line 1597, in main
model_pred = transformer(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/accelerate/utils/operations.py", line 819, in forward
return model_forward(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/accelerate/utils/operations.py", line 807, in __call__
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/amp/autocast_mode.py", line 44, in decorate_autocast
return func(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/transformers/transformer_sd3.py", line 327, in forward
encoder_hidden_states, hidden_states = block(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention.py", line 704, in forward
attn_output, context_attn_output = self.attn(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention_processor.py", line 605, in forward
return self.processor(
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention_processor.py", line 1496, in __call__
hidden_states = attn.to_out[0](hidden_states)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/linear.py", line 134, in forward
return F.linear(input, self.weight, self.bias)
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacity of 47.38 GiB of which 13.62 MiB is free. Including non-PyTorch memory, this process has 47.07 GiB memory in use. Of the allocated memory 46.24 GiB is allocated by PyTorch, and 365.84 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
Traceback (most recent call last):
File "/home/wuyou/train_sd/diffusers/examples/dreambooth/train_dreambooth_sd3.py", line 1818, in <module>
main(args)
File "/home/wuyou/train_sd/diffusers/examples/dreambooth/train_dreambooth_sd3.py", line 1597, in main
model_pred = transformer(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/accelerate/utils/operations.py", line 819, in forward
return model_forward(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/accelerate/utils/operations.py", line 807, in __call__
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/amp/autocast_mode.py", line 44, in decorate_autocast
return func(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/transformers/transformer_sd3.py", line 327, in forward
encoder_hidden_states, hidden_states = block(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention.py", line 704, in forward
attn_output, context_attn_output = self.attn(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention_processor.py", line 605, in forward
return self.processor(
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention_processor.py", line 1496, in __call__
hidden_states = attn.to_out[0](hidden_states)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/linear.py", line 134, in forward
return F.linear(input, self.weight, self.bias)
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacity of 47.38 GiB of which 13.62 MiB is free. Including non-PyTorch memory, this process has 47.07 GiB memory in use. Of the allocated memory 46.24 GiB is allocated by PyTorch, and 365.84 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
bash
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:16<00:00, 8.31s/it]
{'image_encoder', 'feature_extractor'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:16<00:00, 8.29s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 4/9 [00:00<00:00, 10.49it/s]
{'base_shift', 'use_dynamic_shifting', 'shift_terminal', 'use_karras_sigmas', 'base_image_seq_len', 'use_beta_sigmas', 'stochastic_sampling', 'max_shift', 'invert_sigmas', 'use_exponential_sigmas', 'time_shift_type', 'max_image_seq_len'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 20.09it/s]
12/25/2025 10:02:11 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
Steps: 0%|▍ | 2/500 [01:03<08:02, 1.03it/s, loss=0.289, lr=0.0001]Traceback (most recent call last):
File "/home/wuyou/train_sd/diffusers/examples/dreambooth/train_dreambooth_sd3.py", line 1818, in <module>
main(args)
File "/home/wuyou/train_sd/diffusers/examples/dreambooth/train_dreambooth_sd3.py", line 1597, in main
model_pred = transformer(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/accelerate/utils/operations.py", line 819, in forward
return model_forward(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/accelerate/utils/operations.py", line 807, in __call__
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/amp/autocast_mode.py", line 44, in decorate_autocast
return func(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/transformers/transformer_sd3.py", line 327, in forward
encoder_hidden_states, hidden_states = block(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention.py", line 704, in forward
attn_output, context_attn_output = self.attn(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention_processor.py", line 605, in forward
return self.processor(
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention_processor.py", line 1496, in __call__
hidden_states = attn.to_out[0](hidden_states)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/linear.py", line 134, in forward
return F.linear(input, self.weight, self.bias)
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacity of 47.38 GiB of which 13.62 MiB is free. Including non-PyTorch memory, this process has 47.07 GiB memory in use. Of the allocated memory 46.24 GiB is allocated by PyTorch, and 365.84 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
Traceback (most recent call last):
File "/home/wuyou/train_sd/diffusers/examples/dreambooth/train_dreambooth_sd3.py", line 1818, in <module>
main(args)
File "/home/wuyou/train_sd/diffusers/examples/dreambooth/train_dreambooth_sd3.py", line 1597, in main
model_pred = transformer(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/accelerate/utils/operations.py", line 819, in forward
return model_forward(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/accelerate/utils/operations.py", line 807, in __call__
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/amp/autocast_mode.py", line 44, in decorate_autocast
return func(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/transformers/transformer_sd3.py", line 327, in forward
encoder_hidden_states, hidden_states = block(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention.py", line 704, in forward
attn_output, context_attn_output = self.attn(
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention_processor.py", line 605, in forward
return self.processor(
File "/home/wuyou/train_sd/diffusers/src/diffusers/models/attention_processor.py", line 1496, in __call__
hidden_states = attn.to_out[0](hidden_states)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wuyou/miniconda3/envs/train-sd/lib/python3.10/site-packages/torch/nn/modules/linear.py", line 134, in forward
return F.linear(input, self.weight, self.bias)
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacity of 47.38 GiB of which 13.62 MiB is free. Including non-PyTorch memory, this process has 47.07 GiB memory in use. Of the allocated memory 46.24 GiB is allocated by PyTorch, and 365.84 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)是48G的显卡啊,哎。。。这个还还没试一试,等下试一试
显存不够怎么办
另一种训训练命令
train_dreambooth_lora_sd3.py
用了这一个就能训练起来了
bash
(train-sd) wuyou@wuyou-MS-7E47:~/train_sd/diffusers/examples/dreambooth$ accelerate launch train_dreambooth_lora_sd3.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--mixed_precision="fp16" \
--instance_prompt="a photo of sks dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--learning_rate=4e-4 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="A photo of sks dog in a bucket" \
--validation_epochs=25 \
--seed="0" \训练过程中的输出日志:
bash
12/25/2025 10:26:26 - INFO - __main__ - Distributed environment: NO
Num processes: 1
Process index: 0
Local process index: 0
Device: cuda
Mixed precision type: fp16
You set `add_prefix_space`. The tokenizer needs to be converted from the slow tokenizers
You are using a model of type clip_text_model to instantiate a model of type . This is not supported for all configurations of models and can yield errors.
You are using a model of type clip_text_model to instantiate a model of type . This is not supported for all configurations of models and can yield errors.
You are using a model of type t5 to instantiate a model of type . This is not supported for all configurations of models and can yield errors.
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.63s/it]
{'mid_block_add_attention'} was not found in config. Values will be initialized to default values.
All model checkpoint weights were used when initializing AutoencoderKL.
All the weights of AutoencoderKL were initialized from the model checkpoint at stabilityai/stable-diffusion-3-medium-diffusers.
If your task is similar to the task the model of the checkpoint was trained on, you can already use AutoencoderKL for predictions without further training.
{'qk_norm', 'dual_attention_layers'} was not found in config. Values will be initialized to default values.
All model checkpoint weights were used when initializing SD3Transformer2DModel.
All the weights of SD3Transformer2DModel were initialized from the model checkpoint at stabilityai/stable-diffusion-3-medium-diffusers.
If your task is similar to the task the model of the checkpoint was trained on, you can already use SD3Transformer2DModel for predictions without further training.
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice: wandb: Enter your choice:
wandb: Enter your choice:
wandb: Enter your choice:
wandb: Enter your choice: 3
wandb: You chose "Don't visualize my results"
wandb: Tracking run with wandb version 0.23.1
wandb: W&B syncing is set to `offline` in this directory. Run `wandb online` or set WANDB_MODE=online to enable cloud syncing.
wandb: Run data is saved locally in /home/wuyou/train_sd/diffusers/examples/dreambooth/wandb/offline-run-20251225_102717-imr3gwed
12/25/2025 10:27:18 - INFO - __main__ - ***** Running training *****
12/25/2025 10:27:18 - INFO - __main__ - Num examples = 5
12/25/2025 10:27:18 - INFO - __main__ - Num batches each epoch = 5
12/25/2025 10:27:18 - INFO - __main__ - Num Epochs = 250
12/25/2025 10:27:18 - INFO - __main__ - Instantaneous batch size per device = 1
12/25/2025 10:27:18 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 4
12/25/2025 10:27:18 - INFO - __main__ - Gradient Accumulation steps = 4
12/25/2025 10:27:18 - INFO - __main__ - Total optimization steps = 500
Steps: 0%|▍ | 2/500 [00:02<07:30, 1.10it/s, loss=0.0329, lr=0.0004]
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
Loading checkpoint shards: 50%|█████████████████████████████████████████████████████████████ | 1/2 [00:08<00:08, 8.22s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:15<00:00, 7.94s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:15<00:00, 7.89s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.█████████████ | 7/9 [00:00<00:00, 17.86it/s]
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 18.88it/s]
12/25/2025 10:27:43 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:10<00:00, 5.49s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:10<00:00, 5.44s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.█████████████ | 7/9 [00:00<00:00, 18.47it/s]
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 19.65it/s]
12/25/2025 10:29:13 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:10<00:00, 5.49s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:10<00:00, 5.44s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 4/9 [00:00<00:00, 39.56it/s]
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 17.67it/s]
12/25/2025 10:30:44 - INFO - __main__ - Running validation... ███████████████████████████████████████████████████████████████████████████████ | 8/9 [00:00<00:00, 14.25it/s]
Generating 4 images with prompt: A photo of sks dog in a bucket.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.51s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:11<00:00, 5.45s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.█████████████ | 7/9 [00:00<00:00, 17.25it/s]
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 18.29it/s]
12/25/2025 10:32:15 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.57s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:11<00:00, 5.51s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.█████████████ | 7/9 [00:00<00:00, 17.92it/s]
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 19.67it/s]
12/25/2025 10:33:44 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.58s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:11<00:00, 5.52s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.█████████████ | 7/9 [00:00<00:00, 16.36it/s]
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 17.35it/s]
12/25/2025 10:35:16 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.57s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:11<00:00, 5.51s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.█████████████ | 7/9 [00:00<00:00, 17.79it/s]
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 18.88it/s]
12/25/2025 10:36:48 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.55s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:11<00:00, 5.49s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.█████████████ | 7/9 [00:00<00:00, 17.51it/s]
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 19.46it/s]
12/25/2025 10:38:18 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.55s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:11<00:00, 5.49s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 4/9 [00:00<00:00, 39.21it/s]
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 13.45it/s]
12/25/2025 10:39:49 - INFO - __main__ - Running validation... ███████████████████████████████████████████████████████████████████████████████ | 8/9 [00:00<00:00, 10.68it/s]
Generating 4 images with prompt: A photo of sks dog in a bucket.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:10<00:00, 5.47s/it]
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.█████████████████████████████████████████████| 2/2 [00:10<00:00, 5.41s/it]
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 4/9 [00:00<00:00, 39.31it/s]
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 19.47it/s]
12/25/2025 10:41:20 - INFO - __main__ - Running validation... ███████████████████████████████████████████████████████████████████████████████ | 8/9 [00:00<00:00, 15.81it/s]
Generating 4 images with prompt: A photo of sks dog in a bucket.
Steps: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 500/500 [15:14<00:00, 1.34it/s, loss=0.026, lr=0.0004]12/25/2025 10:42:33 - INFO - accelerate.accelerator - Saving current state to trained-sd3/checkpoint-500
Model weights saved in trained-sd3/checkpoint-500/pytorch_lora_weights.safetensors
12/25/2025 10:42:33 - INFO - accelerate.checkpointing - Optimizer state saved in trained-sd3/checkpoint-500/optimizer.bin
12/25/2025 10:42:33 - INFO - accelerate.checkpointing - Scheduler state saved in trained-sd3/checkpoint-500/scheduler.bin
12/25/2025 10:42:33 - INFO - accelerate.checkpointing - Sampler state for dataloader 0 saved in trained-sd3/checkpoint-500/sampler.bin
12/25/2025 10:42:33 - INFO - accelerate.checkpointing - Gradient scaler state saved in trained-sd3/checkpoint-500/scaler.pt
12/25/2025 10:42:33 - INFO - accelerate.checkpointing - Random states saved in trained-sd3/checkpoint-500/random_states_0.pkl
12/25/2025 10:42:33 - INFO - __main__ - Saved state to trained-sd3/checkpoint-500
Steps: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 500/500 [15:14<00:00, 1.34it/s, loss=0.0695, lr=0.0004]Model weights saved in trained-sd3/pytorch_lora_weights.safetensors
{'feature_extractor', 'image_encoder'} was not found in config. Values will be initialized to default values.
Loaded tokenizer as CLIPTokenizer from `tokenizer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 0/9 [00:00<?, ?it/s]
`torch_dtype` is deprecated! Use `dtype` instead!
Loaded text_encoder_2 as CLIPTextModelWithProjection from `text_encoder_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Instantiating SD3Transformer2DModel model under default dtype torch.float16. | 2/9 [00:00<00:00, 8.10it/s]
{'qk_norm', 'dual_attention_layers'} was not found in config. Values will be initialized to default values.
All model checkpoint weights were used when initializing SD3Transformer2DModel.
All the weights of SD3Transformer2DModel were initialized from the model checkpoint at /home/wuyou/.cache/huggingface/hub/models--stabilityai--stable-diffusion-3-medium-diffusers/snapshots/ea42f8cef0f178587cf766dc8129abd379c90671/transformer.
If your task is similar to the task the model of the checkpoint was trained on, you can already use SD3Transformer2DModel for predictions without further training.
Loaded transformer as SD3Transformer2DModel from `transformer` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
{'time_shift_type', 'base_shift', 'stochastic_sampling', 'use_exponential_sigmas', 'base_image_seq_len', 'max_image_seq_len', 'use_karras_sigmas', 'use_dynamic_shifting', 'shift_terminal', 'max_shift', 'invert_sigmas', 'use_beta_sigmas'} was not found in config. Values will be initialized to default values.
Loaded scheduler as FlowMatchEulerDiscreteScheduler from `scheduler` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:01<00:00, 1.03it/s]
Loaded text_encoder_3 as T5EncoderModel from `text_encoder_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:01<00:00, 1.01s/itLoaded text_encoder as CLIPTextModelWithProjection from `text_encoder` subfolder of stabilityai/stable-diffusion-3-medium-diffusers. | 5/9 [00:02<00:02, 1.42it/s]
Loaded tokenizer_3 as T5TokenizerFast from `tokenizer_3` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loaded tokenizer_2 as CLIPTokenizer from `tokenizer_2` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.█████████████ | 7/9 [00:03<00:00, 2.11it/s]
Instantiating AutoencoderKL model under default dtype torch.float16.
{'mid_block_add_attention'} was not found in config. Values will be initialized to default values.
All model checkpoint weights were used when initializing AutoencoderKL.
All the weights of AutoencoderKL were initialized from the model checkpoint at /home/wuyou/.cache/huggingface/hub/models--stabilityai--stable-diffusion-3-medium-diffusers/snapshots/ea42f8cef0f178587cf766dc8129abd379c90671/vae.
If your task is similar to the task the model of the checkpoint was trained on, you can already use AutoencoderKL for predictions without further training.
Loaded vae as AutoencoderKL from `vae` subfolder of stabilityai/stable-diffusion-3-medium-diffusers.
Loading pipeline components...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:03<00:00, 2.65it/s]
Loading transformer.ponents...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:03<00:00, 3.18it/s]
No LoRA keys associated to CLIPTextModelWithProjection found with the prefix='text_encoder'. This is safe to ignore if LoRA state dict didn't originally have any CLIPTextModelWithProjection related params. You can also try specifying `prefix=None` to resolve the warning. Otherwise, open an issue if you think it's unexpected: https://github.com/huggingface/diffusers/issues/new
No LoRA keys associated to CLIPTextModelWithProjection found with the prefix='text_encoder_2'. This is safe to ignore if LoRA state dict didn't originally have any CLIPTextModelWithProjection related params. You can also try specifying `prefix=None` to resolve the warning. Otherwise, open an issue if you think it's unexpected: https://github.com/huggingface/diffusers/issues/new
12/25/2025 10:42:37 - INFO - __main__ - Running validation...
Generating 4 images with prompt: A photo of sks dog in a bucket.
wandb:
wandb: Run history:
wandb: loss ▃▄▄▅▄▄▃▅▅▄▇▁▅▄▆▄▆▂▇▃▇▅▆▃▅▆▃▄▄▄▃▅▆▁▃▅▃▃▃█
wandb: lr ▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
wandb:
wandb: Run summary:
wandb: loss 0.06951
wandb: lr 0.0004
wandb:
wandb: You can sync this run to the cloud by running:
wandb: wandb sync /home/wuyou/train_sd/diffusers/examples/dreambooth/wandb/offline-run-20251225_102717-imr3gwed
wandb: Find logs at: ./wandb/offline-run-20251225_102717-imr3gwed/logs
wandb: WARNING Tried to log to step 2 that is less than the current step 3. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 2 that is less than the current step 3. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 2 that is less than the current step 3. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 52 that is less than the current step 53. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 52 that is less than the current step 53. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 52 that is less than the current step 53. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 102 that is less than the current step 103. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 102 that is less than the current step 103. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 102 that is less than the current step 103. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 152 that is less than the current step 153. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 152 that is less than the current step 153. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 152 that is less than the current step 153. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 202 that is less than the current step 203. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 202 that is less than the current step 203. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 202 that is less than the current step 203. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 252 that is less than the current step 253. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 252 that is less than the current step 253. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 252 that is less than the current step 253. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 302 that is less than the current step 303. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 302 that is less than the current step 303. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 302 that is less than the current step 303. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 352 that is less than the current step 353. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 352 that is less than the current step 353. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 352 that is less than the current step 353. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 402 that is less than the current step 403. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 402 that is less than the current step 403. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 402 that is less than the current step 403. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 452 that is less than the current step 453. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 452 that is less than the current step 453. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
wandb: WARNING Tried to log to step 452 that is less than the current step 453. Steps must be monotonically increasing, so this data will be ignored. See https://wandb.me/define-metric to log data out of order.
Steps: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 500/500 [15:47<00:00, 1.89s/it, loss=0.0695, lr=0.0004]
(train-sd) wuyou@wuyou-MS-7E47:~/train_sd/diffusers/examples/dreambooth$验证
python
import os
# 离线模式:避免无网时 hub 重试拖慢加载
os.environ.setdefault("HF_HUB_OFFLINE", "1")
os.environ.setdefault("TRANSFORMERS_OFFLINE", "1")
# 无网/离线推理建议不要设置 HF_ENDPOINT(仍会触发 hub http 流程)
os.environ.pop("HF_ENDPOINT", None)
from diffusers import StableDiffusion3Pipeline
import torch
# 纯 GPU 速度优先
assert torch.cuda.is_available(), "CUDA 不可用:当前推理会跑在 CPU 上,速度会非常慢。"
print("GPU:", torch.cuda.get_device_name(0))
print("-------------------------------")
# 加载基础模型 + 你的LoRA权重
pipe = StableDiffusion3Pipeline.from_pretrained(
"stabilityai/stable-diffusion-3-medium-diffusers",
torch_dtype=torch.float16,
local_files_only=True
)
# 最快:整条 pipeline 放到 GPU
pipe = pipe.to("cuda")
print('===========================================================')
pipe.load_lora_weights(
"/home/wuyou/train_sd/diffusers/examples/dreambooth/trained-sd3",
weight_name="pytorch_lora_weights.safetensors",
local_files_only=True, )
print("1123=============")
# 生成狗狗图片
prompt = "a photo of sks dog in the park"
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.float16):
image = pipe(
prompt,
num_inference_steps=28,
).images[0]
image.save("my_dog2.png")注意:
前四行必须在最前面:
import os
os.environ'HF_ENDPOINT' ="https://hf-mirror.com"
os.environ"HF_HUB_OFFLINE" = "1"
os.environ"TRANSFORMERS_OFFLINE" = "1"
hf mirror的配置方法:
遗留问题:
1 上面的训练方法是 一个lora 只能对几张图片和 一个prompt 做约束,
那若是多个场景应该怎么办?
-
上面是以midium训练的,那large 是否能跑起来呢?
-
其它ref:https://medium.com/@heyamit10/stable-diffusion-3-5-large-fine-tuning-tutorial-4b25ed1e05dd