pandas库学习
数据清洗
现在我们有这样一个场景,有5个面试者A、B、C、D、E来面试,有五个面试官分别对它们的7项能力进行评分,我们通过上面的操作将五个面试官的考核成绩整合到了一起,现在需要对每个人的每项成绩,取五个面试官的平均分。整合后的文件如下:
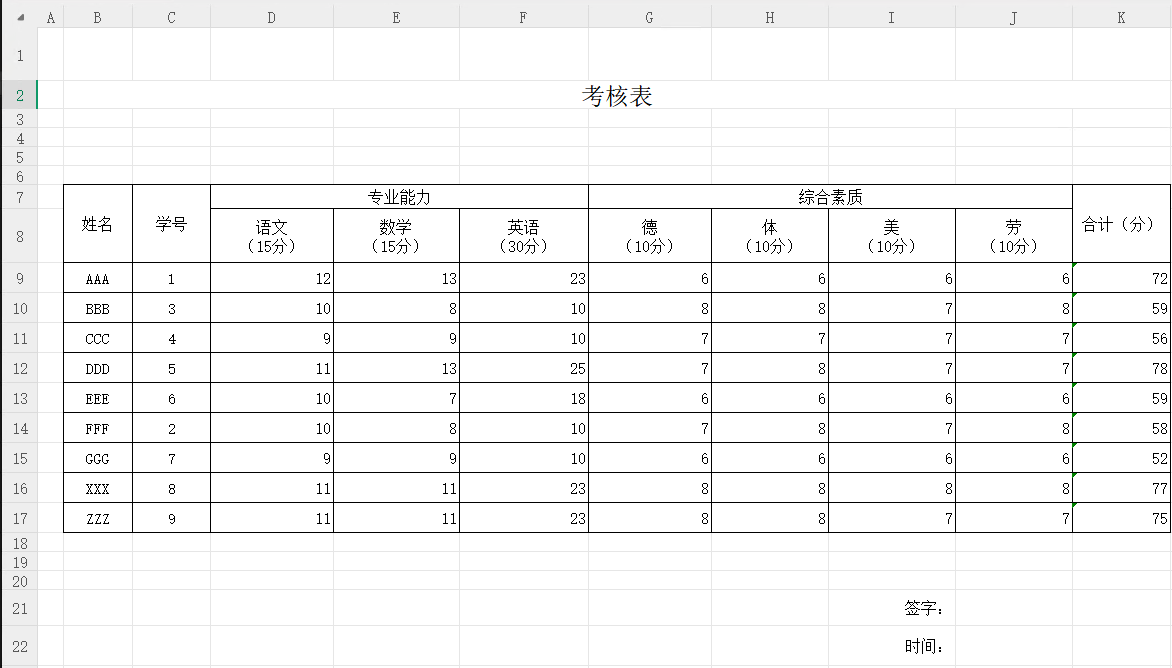
筛选
我们首先看一下代码里如何取得某一列的数据:
python
df = pd.read_excel('D:/测试/汇总.xlsx')
# 只需要指定列名即可
df['面试专家']这里df['面试专家']中括号里,其实相当于进行了一次列名的判断,符合这个列名的为True会展示,不符合的则为False不展示,也就是说,我们可以自己来写一个判断条件,控制哪些内容显示。
基于基本条件筛选:
python
df = pd.read_excel('D:/测试/汇总.xlsx')
# 筛选所有面试专家不是乙的数据
new_df = df[df['面试专家'] != '乙']df['面试专家'] != '乙'会把这一列的每一行都返回一个结果,符合条件为True,反之为False
然后再根据结果,在用df取得为True的数据,new_df就是不含乙的所有行数据
当然,这也可以支持多个条件进行筛选&(与),|(或)
示例:
python
# 面试官为 乙,并且面试人员是 A
new_df = df[df['面试专家'] != '乙' & df['面试人员'] == 'A']也可以使用自带的query方法,有点类似于写sql了,上面的两个例子可以转换为:
python
new_df = df.query('面试专家 != "乙"')
new_df = df.query('面试专家 != "乙" and 面试人员 == "A"')
# 也可以引用变量,使用@符号进行标记
name = "A"
df.query('面试专家 != "乙" and 面试人员 == @name')除了基本的比较语法,在此列举一些其他的条件判断语法:
python
# 使用 isin() 检查是否在列表中
df[df['age'].isin([25, 30, 35])]
# 使用 isnull() 和 notnull() 检查空值
df[df['name'].isnull()]
df[df['name'].notnull()]
df[df['name'].isna()] # 等同于 isnull()
df[df['name'].notna()] # 等同于 notnull()
# 字符串包含
df_str[df_str['email'].str.contains('@')]
# 字符串开头匹配
df_str[df_str['email'].str.startswith('alice')]
# 字符串结尾匹配
df_str[df_str['email'].str.endswith('@gmail.com')]
# 字符串长度
df_str[df_str['name'].str.len() > 10]
# 正则表达式匹配
df_str[df_str['email'].str.contains(r'@(gmail|yahoo)\.com$')]
# 大小写转换后匹配
df_str[df_str['name'].str.lower().str.contains('new')]
# 使用 between() 筛选范围
df[df['age'].between(25, 30)]
df[df['salary'].between(50000, 65000)
# 日期比较
df[df['join_date'] > '2021-01-01']
df[df['join_date'].dt.year == 2020]
df[df['join_date'].dt.month.isin([1, 2, 3])] # 第一季度
# 日期范围筛选
df[df['join_date'].between('2020-01-01', '2021-12-31')])]在某些应用场景下,可以使用iloc[row_indexer, column_indexer]筛选指定的行或列
python
# 选择单行
df.iloc[0]
# 选择多行
df.iloc[0:3] # 不包含第3行(索引为2的行)
# 选择特定元素
df.iloc[0, 1] # 第0行,第1列
# 选择多行多列
df.iloc[0:3, 0:2] # 行0-2,列0-1
# 使用列表选择
df.iloc[[0, 2], [0, 1]] # 第0行和第2行,第0列和第1列
# 选择所有行的特定列
df.iloc[:, [0, 2]] # 所有行,第0列和第2列
# 选择特定行的所有列
df.iloc[[0, 2], :] # 第0行和第2行,所有列分组
有了上面的数据,我们首先要进行分组,获得每个面试人员得到的所有面试官得分
使用groupby()进行分组,指定基于哪一列进行分组即可:
python
grouped = df.groupby('面试人员')针对分组后的对象,pandas内置了一些计算,比如可以直接获取平均数:
python
grouped = df.groupby('面试人员')
# 每个面试者,5个面试官对能力1的平均分。
print(grouped['能力1(10分)'].mean())借助columns可以同时对分组后的多列进行计算,不用写很多遍:
python
# 记得列序数是从0开始,不包含尾数。所以这里是excel里的第2列到第9列
grouped[df.columns[1:9]].mean()
# 面试人员 能力1(15分) 能力2(15分) 能力3(30分) 能力4(10分) 能力5(10分) 能力6(10分) 能力7(10分) 合计(分)
# A 7.0 7.0 13.2 7.4 6.6 6.4 6.2 53.8
# B 7.6 7.0 14.2 6.2 6.8 6.0 5.8 53.6
# C 5.8 5.2 10.6 4.8 5.4 5.0 5.4 42.2
# D 9.4 8.8 14.6 6.4 6.2 6.6 5.8 57.8
# E 9.0 8.8 14.2 5.2 5.4 5.8 5.4 53.8这里列举一部分常用的方法:
| 方法名称 | 说明 |
|---|---|
| mean() | 平均数 |
| median() | 中位数 |
| sum() | 求和 |
| count() | 计数 |
| max() | 最大值 |
| min() | 最小值 |
整合
假定我们当前,要取到原数据的"合计(分)"的最大、最小值,并算出平均数,最后以面试人员为准,拼接起来,并且重新对列头进行命名,来区分各列的意义。
根据上面,我们很容易能取得这三个目标数据:
python
# 最大值
max_values = grouped['合计(分)'].max()
# 最小值
min_values = grouped['合计(分)'].min()
# 平均数
avg_values = grouped['合计(分)'].mean()修改表头
这样合并后,我们发现三列的表头都是合计(分),之前我们只介绍了导出的时候,统一修改表头,但是目前的情况下,如果涉及后续的数据清洗操作,同一个表头名字很明显会导致可读性不高,在这里介绍几种修改表头的操作:
rename
python
# reanme
max_values = grouped['合计(分)'].max().rename('最高分')指定列名
python
nd = pd.concat([max_values, min_values, avg_values], axis=1)
# 合并后,按顺序重新命名
nd.columns =['最高分', '最低分', '平均分']ragg
对于基本的统计计算,还可以使用agg一次性操作
python
# 一次性重命名表名与计算
nd= grouped['合计(分)'].agg(
最高分=('max'),
最低分=('min'),
平均分=('mean')
)merge合并
回到正题,正如之前基本操作里所讲的,这里也可以使用concat来拼接
python
# 还记得axis=1是什么意思吗? 横向拼接
nd = pd.concat([max_values,min_values,avg_values],axis=1)这里的例子比较特殊,数据的数量、顺序都是一致的,直接拼接是符合预期的结果的。但是在实际应用中,会有多个excel数量、顺序不一致,最终需要按照以人员为基准进行的拼接,这时使用concat拼接就不是一个好的选择了。以下为一个简单示例:
两个表格分别统计员工的出勤和缺勤天数,但是并不保证顺序一致,此时使用concat拼接的结果,并不能符合我们的预期
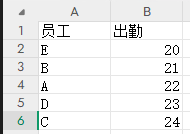
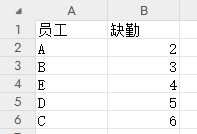
concat拼接结果:
python
员工 出勤 员工 缺勤
0 E 20 A 2
1 B 21 B 3
2 A 22 E 4
3 D 23 D 5
4 C 24 C 6我们这里介绍一下merge拼接:
merge是基于键的合并,写法非常像SQL,常用的参数如下:
| 参数名称 | 说明 |
|---|---|
| how | 连接方式,可选值包括: inner(默认): 内连接,返回两表的交集 outer: 外连接,返回两表的并集 left: 左连接,返回左表所有行 right: 右连接,返回右表所有行 cross: 笛卡尔积连接 |
| on | 用于连接的列名,必须在两个DataFrame中都存在 |
| left_on | 左侧DataFrame中用作连接键的列名 |
| right_on | 右侧DataFrame中用作连接键的列名 |
以上面的表格为例,展示一下具体使用方式:
python
import pandas as pd
folder_path1 = r'D:/001.xlsx'
folder_path2 = r'D:/002.xlsx'
df1 = pd.read_excel(folder_path1)
df2 = pd.read_excel(folder_path2)
# 写法一
nd = pd.merge(df1, df2, how='inner', on='员工')
# 也可以这么写
nd = df1.merge(df2, how='inner', on='员工')
print(nd)最终可以看到结果符合预期:
python
员工 出勤 缺勤
0 E 20 4
1 B 21 3
2 A 22 2
3 D 23 5
4 C 24 6通过上面的例子可以发现,merge方法每次操作只能合并两个DataFrame,那么如果要合并多个该怎么办?没错,使用for循环或者python的reduce函数。
示例:
python
# 之前已经介绍了如何获取文件夹下的所有excel路径,这里就不写了,最终效果一致。
dataframes = [df1, df2, df3, df4]
# 使用reduce进行合并
result = reduce(lambda left, right: pd.merge(left, right, on='key'), dataframes)填充
现在员工缺勤的表格缺失了一些数据,缺少了C的所有内容,D的一些信息也缺失了,合并的时候期望能够用0来补充,或者用一些关键词来提示信息缺失
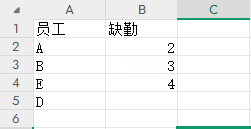
使用fillna进行空值的填充:
python
# 使用左连接
nd = df1.merge(df2, how='left', on='员工')
# inplace = True 表示修改原对象
nd.fillna(0, inplace=True)
print(nd)
# inplace = Flse 表示不修改原对象,创建新对象,要修改成下面的写法
result = nd.fillna(0, inplace=False)
print(result)替换
使用replace进行替换,使用方法与填充类似。接下来我们把上面一步所有的0都替换为文字"数据丢失":
python
nd.replace(0, '数据丢失', inplace=True)
print(nd)去重
对于重复数据,可以使用duplicated进行统计,使用drop_duplicates进行删除,二者都具有下面两个参数:
| 参数名称 | 说明 |
|---|---|
| subset | 指定需要检测重复的列名 |
| keep | 'first'将第一个设定为重复项。'last'将最后一个设定为重复项。False标记所有都为重复项。 |
python
# 检测重复值
df.duplicated() # 标识重复行
df.duplicated().sum() # 统计重复行数量
# 删除重复值
df.drop_duplicates() # 删除完全重复的行
df.drop_duplicates(subset=['员工']) # 基于特定列删除重复对于drop_duplicates还有额外两个可选参数:
| 参数名称 | 说明 |
|---|---|
| inplace | True:修改 DataFrame 。False:创建新的 DataFrame |
| ignore_index | 是否重置索引 |