
1.摘要
background
现有的视频多模态大语言模型(Video MLLM)大多依赖于对视频进行均匀的帧采样,并使用为图像设计的编码器来处理每一帧。这种方法存在两大问题:1) 效率低下 :为了捕捉完整的运动信息,需要密集采样大量视频帧,这导致了巨大的计算冗余和高昂的推理成本。2) 运动感知能力有限:稀疏采样会丢失关键的运动细节,而模型本身并非为直接理解运动而设计。
innovation
1.EMA (Efficient Motion-Aware) 模型 :论文提出了一种高效的、具备运动感知能力的视频MLLM,名为EMA。其核心创新在于直接利用压缩视频流(如H.264格式)作为输入,而不是解码后的原始视频帧。
2**.** 运动感知的GOP编码器:设计了一个关键模块------GOP(Group of Pictures,图像组)编码器。该编码器能在一个GOP单元内,高效地融合两种信息:来自I帧的密集空间信息(是什么物体)和来自P/B帧的稀疏运动矢量(物体如何运动)。这种设计天然形成了一种"慢-快"(slow-fast)输入结构,用更少的token同时表征了丰富的时空信息。
3.MotionBench基准 :针对当前领域缺乏专门评估模型运动理解能力的基准,论文还构建并推出了MotionBench。该基准包含线性、曲线、旋转、接触四种核心运动类型,用于更精确地衡量模型的运动感知能力。
- 方法 Method
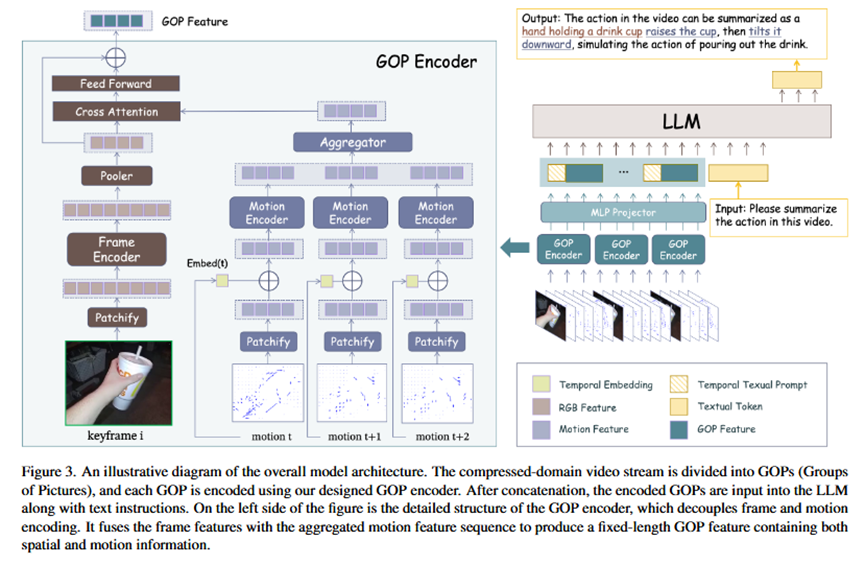
**总体流程 (Pipeline)**模型的整体流程可以概括为四个步骤:
输入处理:将输入的压缩视频流分割成多个GOP(图像组)片段。
GOP编码 :每个GOP片段被送入一个专门设计的GOP编码器,将其中的空间信息(来自I帧)和运动信息(来自运动矢量)编码并融合成一个定长的GOP特征。
特征投影:所有GOP特征序列经过一个MLP(多层感知机)投影层,被转换为大语言模型(LLM)能够理解的视觉token序列。
语言模型生成:最后,将这些视觉token序列与用户的文本指令、时序提示(例如"第k段视频")一起输入到LLM中,由LLM生成最终的文本回答。
核心模块:GOP编码器
这是模型的核心,它采用了解耦编码再融合的策略。
输入:每个GOP的一个I帧(RGB图像)和从P/B帧中均匀采样的一系列运动矢量(Motion Vectors, MV)。
处理流程:
1.空间编码 :使用一个标准的视觉编码器(如SigLIP)处理I帧,提取出包含物体和场景信息的空间特征。
2.运动编码 :将运动矢量序列加上可学习的位置编码(以保留时序信息),然后送入一个轻量的Transformer(即运动编码器)中,提取出运动特征序列。
3.特征融合:
首先,对运动特征序列在时间维度上进行池化 (如平均池化),将其聚合成一个单一的、概括性的聚合运动特征。
然后,通过一个交叉注意力(Cross-Attention)模块,将这个聚合运动特征深度融合到空间特征中。在此过程中,空间特征作为Query,聚合运动特征作为Key和Value,从而让模型学习到空间物体与其运动模式的对应关系。
输出 :一个同时包含了该GOP片段内时空信息的GOP特征。这个特征的token数量与单个图像帧的特征数量相同,但信息含量远比单帧图像丰富。
- 实验 Experimental Results
实验数据集
训练数据:使用了图像-文本对数据集LLaVA-558k、视频-文本对数据集Valley-702k进行基础的图文对齐;使用Cauldron和VideoChat2-IT指令数据集进行微调;并使用Something-to-Something V2(SSV2)数据集对运动编码器进行预热训练。
评估基准:在多个公开的视频问答基准上进行了评估,包括MSVD-QA、MSRVTT-QA、ActivityNet-QA,以及长视频理解基准VideoMME和本文提出的运动理解基准MotionBench。
实验结论与目的
SOTA性能验证(实验目的:证明有效性):在MSVD-QA、ActivityNet-QA等多个基准上,EMA的性能超越了之前依赖帧采样的SOTA模型(如Video-LLaVA),证明了其方法的优越性。
效率分析(实验目的:证明高效性) :与主流模型(如Video-LLaVA)相比,EMA使用了显著更少的视觉token(648 vs 2048),推理速度提升了3倍以上。这有力地证明了通过利用压缩域信息可以大幅提升效率。
运动理解能力评估(实验目的:证明运动感知优势) :在专门的MotionBench上,基于GOP的EMA模型比使用相同token数量但基于帧的模型,平均准确率高出5.7%(50.0% vs 44.3%)。这清晰地表明,GOP编码器能更有效地捕捉和理解运动信息。
消融实验(实验目的:验证设计合理性):一系列消融研究验证了模型各个设计选择的合理性,例如:交叉注意力是比简单相加或拼接更优的融合方式;对运动编码器进行预热训练能显著提升性能;在编码早期融合位置信息效果最好。
- 总结 Conclusion
利用视频原生的压缩结构(I帧+运动矢量)是一种比传统帧采样更高效、更能感知运动的视频理解新范式。通过精心设计的GOP编码器,可以在不增加token负担的情况下,将抽象的运动信息有效融入具象的空间表征中,从而实现视频MLLM的性能与效率双提升。