论文地址:https://arxiv.org/pdf/2512.14080
代码仓库:https://github.com/Dao-AILab/sonic-moe
论文标题:SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
一、宏观印象
论文核心是提出了一种全新的硬件感知优化方案,以解决现代稀疏混合专家模型(MoE) 在训练过程中面临的内存占用大和计算效率低下的问题。
其主要贡献和技术要点可以概括为以下三个核心创新:
1. 最小化激活内存占用的训练算法
-
问题 :为了提升模型质量,现代MoE模型倾向于使用更细粒度 (每个专家网络更小)和更高稀疏度(激活更少的专家)。但这会导致模型在反向传播时需要缓存大量中间结果(激活值),显著增加内存占用,尤其在高粒度下内存占用会线性增长。
-
解决方案:论文重新设计了MoE层的计算图,在不增加计算量(FLOPs)的前提下,通过算法优化避免了为路由器梯度计算缓存激活值。
-
效果 :对于一个细粒度的70亿参数MoE模型,每层的激活内存占用减少了高达45%,且内存占用不再随专家粒度增加而增加。
2. 重叠内存I/O与计算的高效核心
-
问题 :细粒度和高稀疏性使得MoE计算变得更加内存带宽受限(I/O瓶颈),而非计算受限。现有的高性能核心(如ScatterMoE)无法有效应对这种高I/O开销。
-
解决方案 :利用了英伟达Hopper和Blackwell架构GPU的新硬件特性,将数据从高带宽内存(HBM)加载到共享内存(SMEM)的I/O操作,与张量核心的矩阵乘法(GEMM)计算进行重叠,从而隐藏I/O延迟。
-
效果:与高度优化的基准相比,前向传播速度提升了43%;与现有最好的MoE核心相比,反向传播速度提升了83%至115%。
3. 消除计算浪费的"令牌舍入"路由算法
-
问题 :在高度稀疏的MoE中,每个专家分配到的令牌数量参差不齐。当使用分组GEMM 进行计算时,需要将令牌数量填充(Padding)到硬件要求的分块大小(Tile Size,如128)的整数倍,这造成了大量无效计算浪费。
-
解决方案:提出一种"令牌舍入"路由算法。它在标准的路由决策(如Top-K)之后,微调令牌分配,确保每个专家分配到的令牌数量恰好是分块大小的整数倍,同时最大限度地保持原始分配结果。
-
效果 :在保持模型精度的前提下,彻底消除了分组GEMM中的填充浪费。在高稀疏度设置下,相比传统的Top-K路由,端到端MoE计算吞吐量提升了高达16%。
性能总结
将上述三项技术结合,构成了SonicMoE系统。其实验表明:
-
在64张H100 GPU上训练一个7B的细粒度MoE模型,吞吐量达到每天2130亿个令牌,其效率相当于在96张H100上运行基准方法的效率。
-
图1(论文中)显示,其激活内存占用保持恒定且显著低于其他基线,前向计算吞吐量能达到理论上限的86%-91%。
二、精读论文
摘要
混合专家(Mixture of Experts, MoE)模型已成为扩大语言模型规模而不显著增加计算成本的事实架构。近期的MoE模型展现出向高专家粒度 (更小的专家中间维度)和更高稀疏性 (激活专家数量恒定但总专家数量更多)的明确趋势,从而提升了每单位浮点运算(FLOP)的模型质量。然而,细粒度MoE由于更高的输入/输出(IO)成本,面临着激活内存占用增加 和硬件效率降低的问题;而更稀疏的MoE则因分组通用矩阵乘法(Grouped GEMM)核心中的填充而导致计算资源浪费。
为此,我们提出一种内存高效的算法 ,以最小化反向传播所需的激活缓存来计算MoE的前向和反向传播。我们还设计了能够将内存IO与计算重叠 的GPU核心,使所有MoE架构受益。最后,我们提出一种新颖的 "token舍入" 方法,以最小化分组GEMM核心中因填充造成的计算浪费。
因此,我们的方法SonicMoE在细粒度70亿参数MoE上,相比ScatterMoE的BF16 MoE核心,减少了45%的激活内存 ,并在Hopper架构GPU上实现了1.86倍的计算吞吐量提升 。具体而言,在64张H100 GPU上,SonicMoE实现了每天2130亿令牌 的训练吞吐量,这相当于使用lm-engine代码库和FSDP-2进行7B MoE模型训练时,ScatterMoE在96张H100上达到的每天2250亿令牌的吞吐量。在高MoE稀疏性设置下,我们基于分块感知的令牌舍入算法,在保持相近下游性能的同时,相比传统的Top-K路由在核心执行时间上带来了额外的1.16倍加速。我们开源了所有核心代码,以促进更快的MoE模型训练。
关键图表
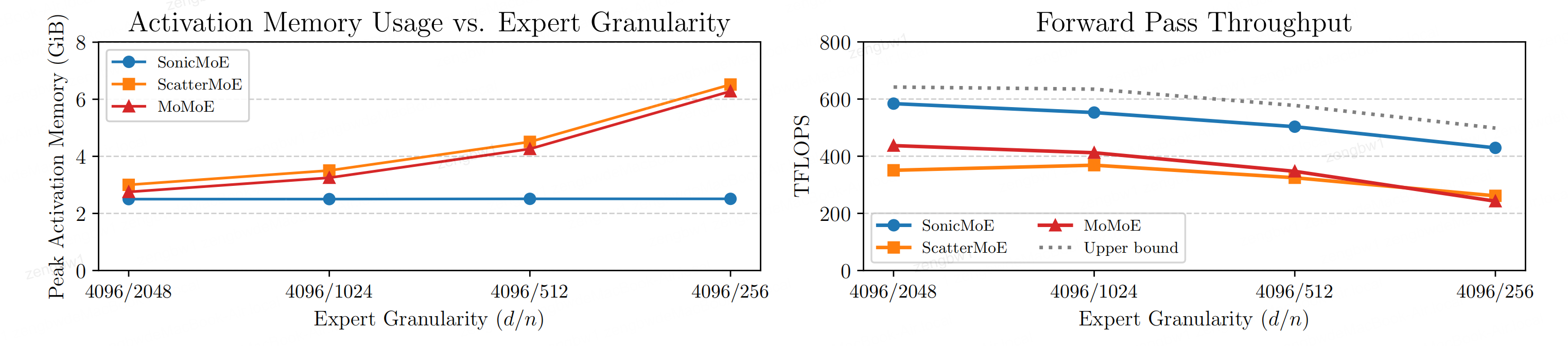
图1:SonicMoE的逐层激活记忆占用量(左图)即使在专家粒度(d/n,其中d为嵌入维度,n为专家中间维度)增加时仍保持稳定,其内存效率比其他基线模型高出0.20-1.59倍。SonicMoE的前向计算吞吐量(右图)平均达到上限值的88%(最大91%,最小86%)(基于cuBLAS BMM + 激活 + cuBLAS BMM + H100聚合)。需注意cuBLAS上限基线未包含路由计算。本研究采用30B MoE配置,微批次大小为32768个标记,并从左至右分别调整激活专家数/专家总数为2/32、4/64、8/128和16/256。
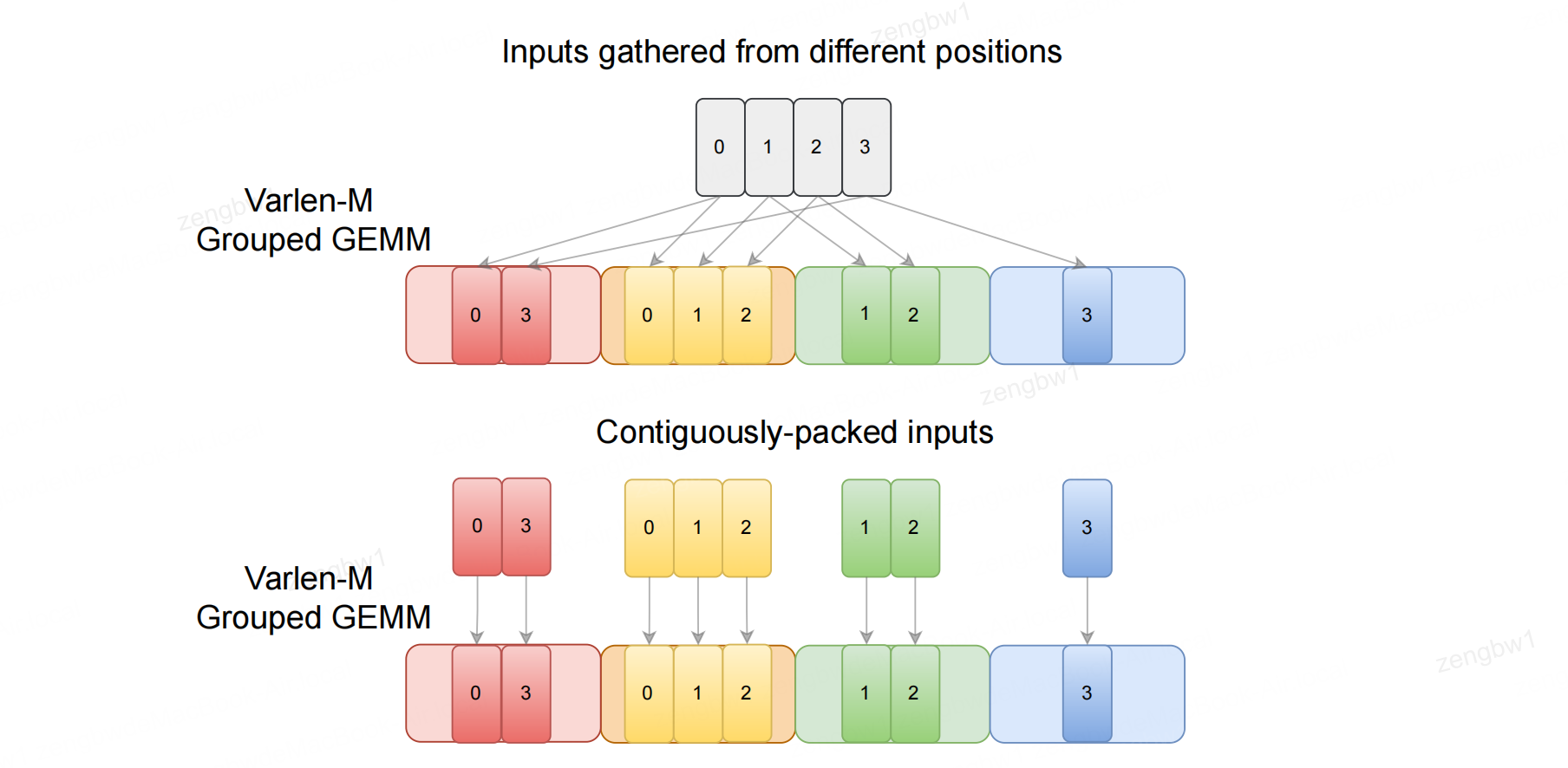
图2:MoE计算通常需要使用分组 GEMM 。每位专家从输入张量的不同位置收集输入(上图),或从分组输入数组中读取连续数据块(下图)。该图改编自 Tan 等人(2024年)的图2。
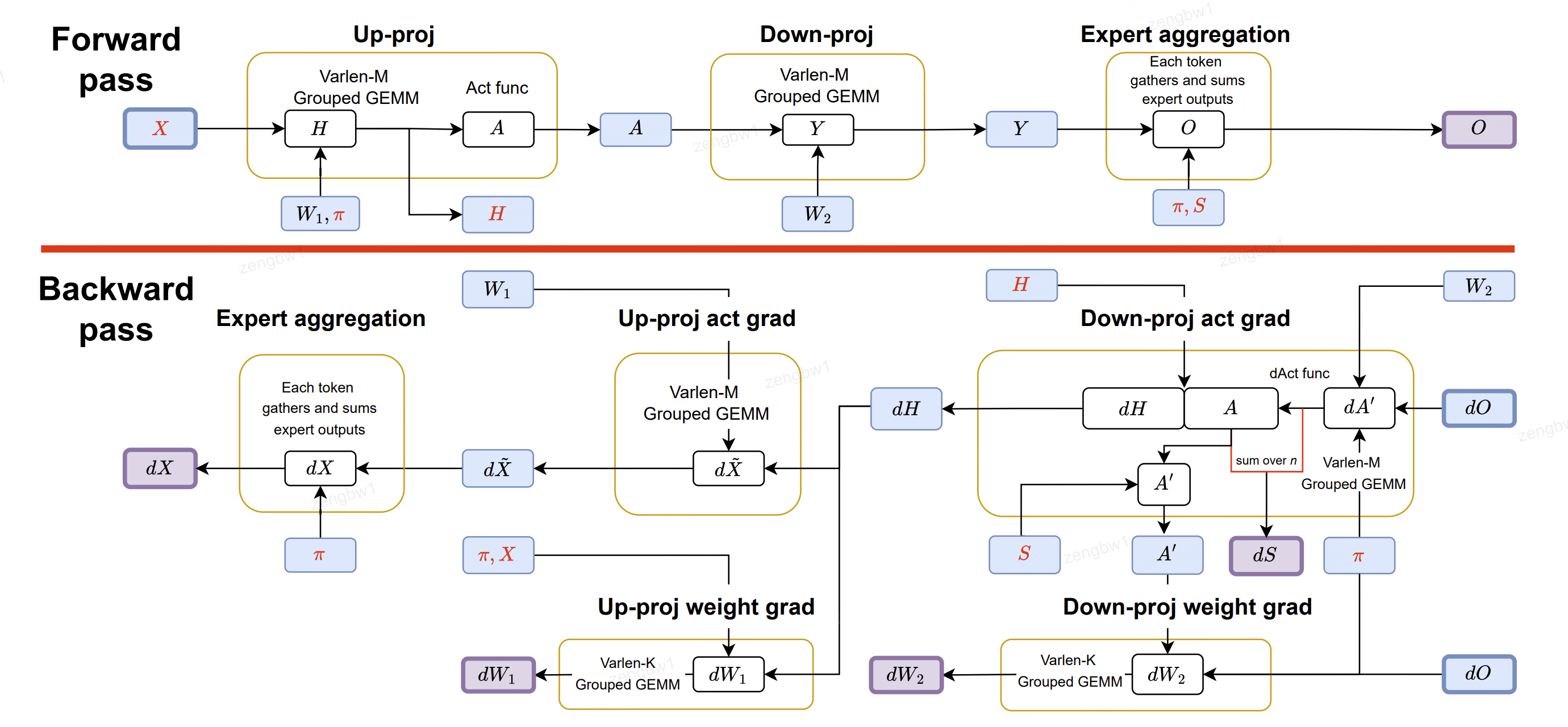
图4:SonicMoE的8个已启动内核计算流程,按黄色方框分组。其中3号和5号内核分别负责前向和后向计算。黄色圆圈的流入箭头表示变量从 HBM 加载到 SRAM ,流出箭头则代表变量存储到 HBM 。 HBM 中所有变量的方框均采用颜色区分:紫色方框表示前向和后向计算的输出结果,蓝色方框表示中间变量或权重(W1、W2)。所有缓存激活值X、H、 π 、S均以红色标注。算法2正式描述了SonicMoE的前向传播过程,算法3和5则描述了后向传播过程。
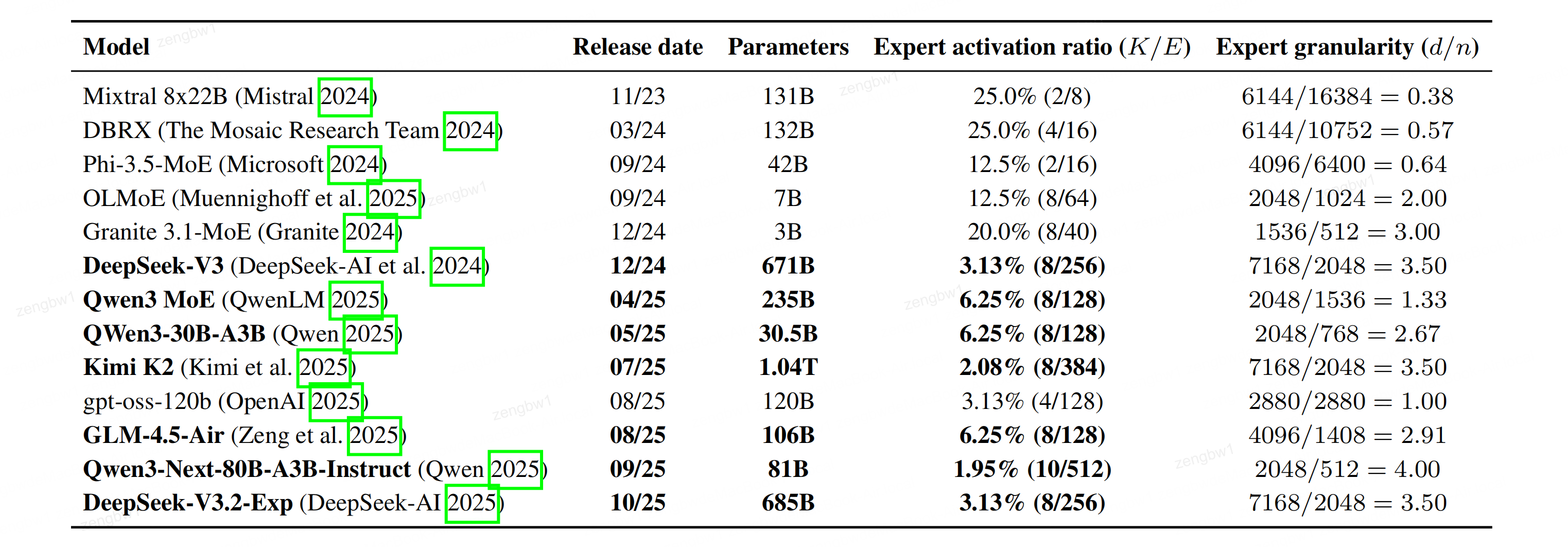 表1:MoE Scaling趋势分析:本表展示专家激活率(即每个标记K对应的专家激活数K/E)与专家粒度(模型嵌入维度d与专家中间层规模n的比值),数据来源于前沿开源模型。计算模型增强稀疏度时未包含共享专家。趋势表明,新型开源模型增强模型往往具有更精细的粒度和更稀疏的结构。
表1:MoE Scaling趋势分析:本表展示专家激活率(即每个标记K对应的专家激活数K/E)与专家粒度(模型嵌入维度d与专家中间层规模n的比值),数据来源于前沿开源模型。计算模型增强稀疏度时未包含共享专家。趋势表明,新型开源模型增强模型往往具有更精细的粒度和更稀疏的结构。