💖💖作者:计算机编程小央姐
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持! 💜💜
💕💕文末获取源码
目录
-
- 基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统功能介绍
- 基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统技术介绍
- 基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统背景意义
- 基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统演示视频
- 基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统演示图片
- 基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统部分代码
- 基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-结语
基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统功能介绍
本系统是一个基于大数据技术栈构建的人口普查收入数据分析与可视化平台,采用Hadoop分布式存储架构结合Spark内存计算引擎,实现对海量人口普查数据的高效处理与深度挖掘。系统运用Hive数据仓库技术建立标准化的数据管理体系,通过Spark SQL进行复杂的数据查询与统计分析,支持多维度的收入数据探索,包括性别、年龄、教育程度、职业类型、工作时长等关键因素对个人收入水平的影响分析。前端采用Vue框架配合ElementUI组件库构建现代化的用户交互界面,集成ECharts图表库实现丰富的数据可视化效果,支持柱状图、饼图、散点图、热力图等多种图表类型,帮助用户直观理解复杂的统计结果。系统后端基于SpringBoot框架搭建RESTful API服务,与大数据处理层无缝对接,确保数据分析结果能够实时响应前端请求。整个系统架构采用分层设计思想,数据存储层、计算处理层、业务逻辑层和展示层职责清晰,既保证了系统的扩展性和维护性,又充分发挥了大数据技术在处理复杂统计分析任务时的优势,为用户提供了一个功能完备、性能优异的人口收入数据分析工具。
基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统技术介绍
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统背景意义
随着国家统计工作的不断完善和大数据时代的到来,人口普查数据作为反映社会经济发展状况的重要指标,其数据量呈现爆发式增长趋势。传统的数据分析方法在面对包含数百万甚至上千万条记录的人口普查数据时,往往存在处理效率低下、分析维度单一、结果展示不够直观等问题。与此同时,政府部门、研究机构以及企业组织对于人口收入分布规律、影响因素关联性、群体特征差异等深层次信息的需求日益增长,需要更加强大和灵活的数据分析工具来支撑决策制定。大数据技术的快速发展为解决这些挑战提供了新的思路,Hadoop生态系统的成熟应用证明了分布式计算在处理海量数据方面的巨大优势,而Spark作为新一代内存计算引擎,在数据处理速度和分析能力方面都有了显著提升。在这样的技术背景下,开发一个专门针对人口普查收入数据的大数据分析与可视化系统,既是对现有技术能力的实际应用,也是满足实际业务需求的有效尝试。本课题的研究和实现具有多方面的实际价值和学习意义。从技术角度来看,通过构建完整的大数据处理链路,能够深入理解Hadoop、Spark、Hive等核心技术的工作原理和协同机制,掌握从数据存储、计算处理到结果展示的全流程开发经验,这对于提升大数据技术的实际应用能力很有帮助。从应用角度来看,人口普查数据分析是社会科学研究和政策制定的重要工具,通过多维度的收入影响因素分析,可以为相关研究人员提供数据支撑,虽然作为一个毕业设计项目,其分析深度和应用范围相对有限,但仍然能够展示大数据技术在社会统计领域的应用潜力。从学习价值来看,这个项目涵盖了前后端开发、大数据处理、数据可视化等多个技术领域,有助于建立完整的技术知识体系。另外,通过实际的数据处理和分析过程,能够培养数据敏感性和统计思维能力,这些技能在未来的职业发展中都会很实用。当然,作为一个学习性质的项目,我们也要认识到其局限性,它更多的是一次技术实践和能力培养的机会,而不是要解决什么重大的社会问题。
基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统演示视频
【Spark+Hive+hadoop】基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统
基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统演示图片
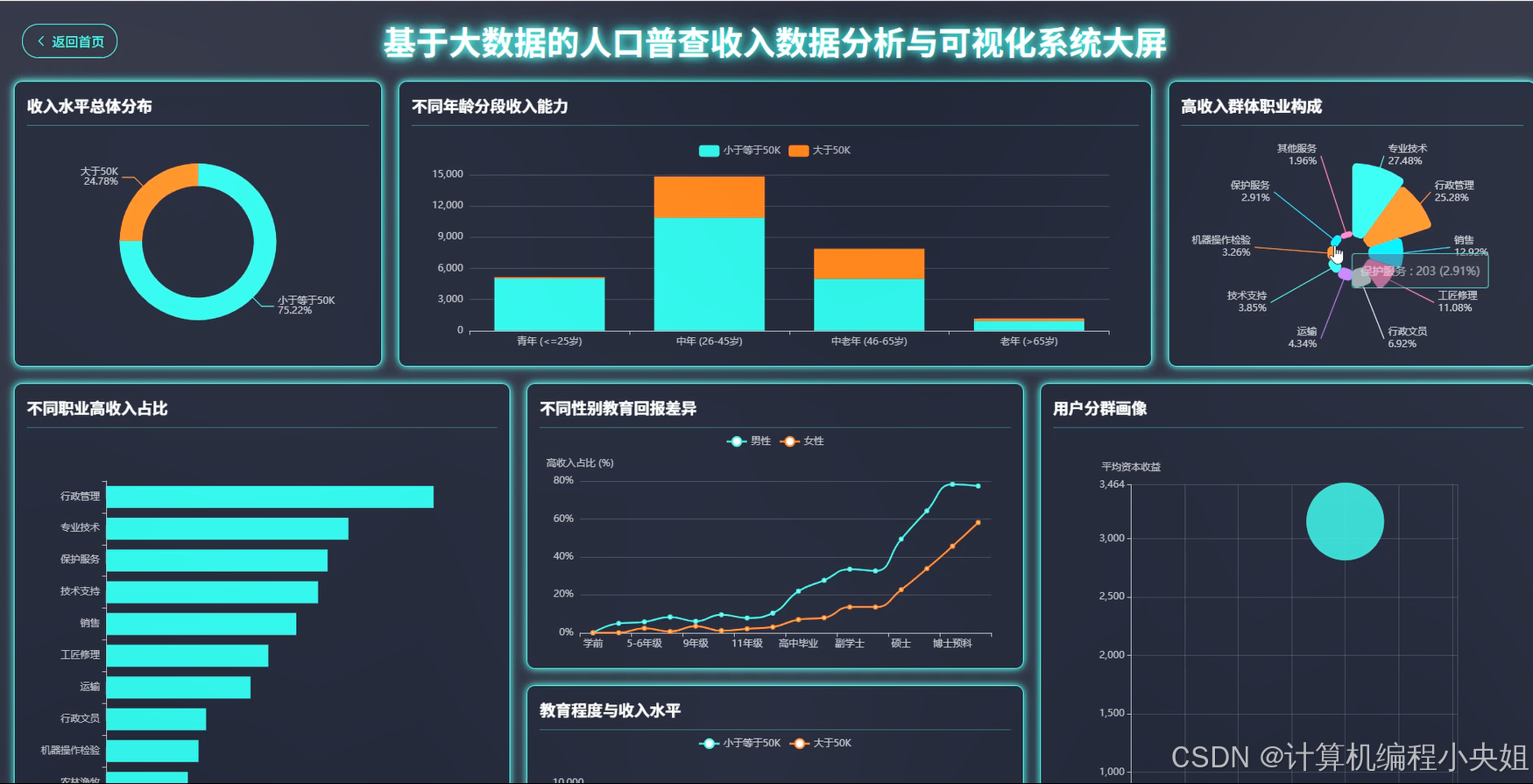
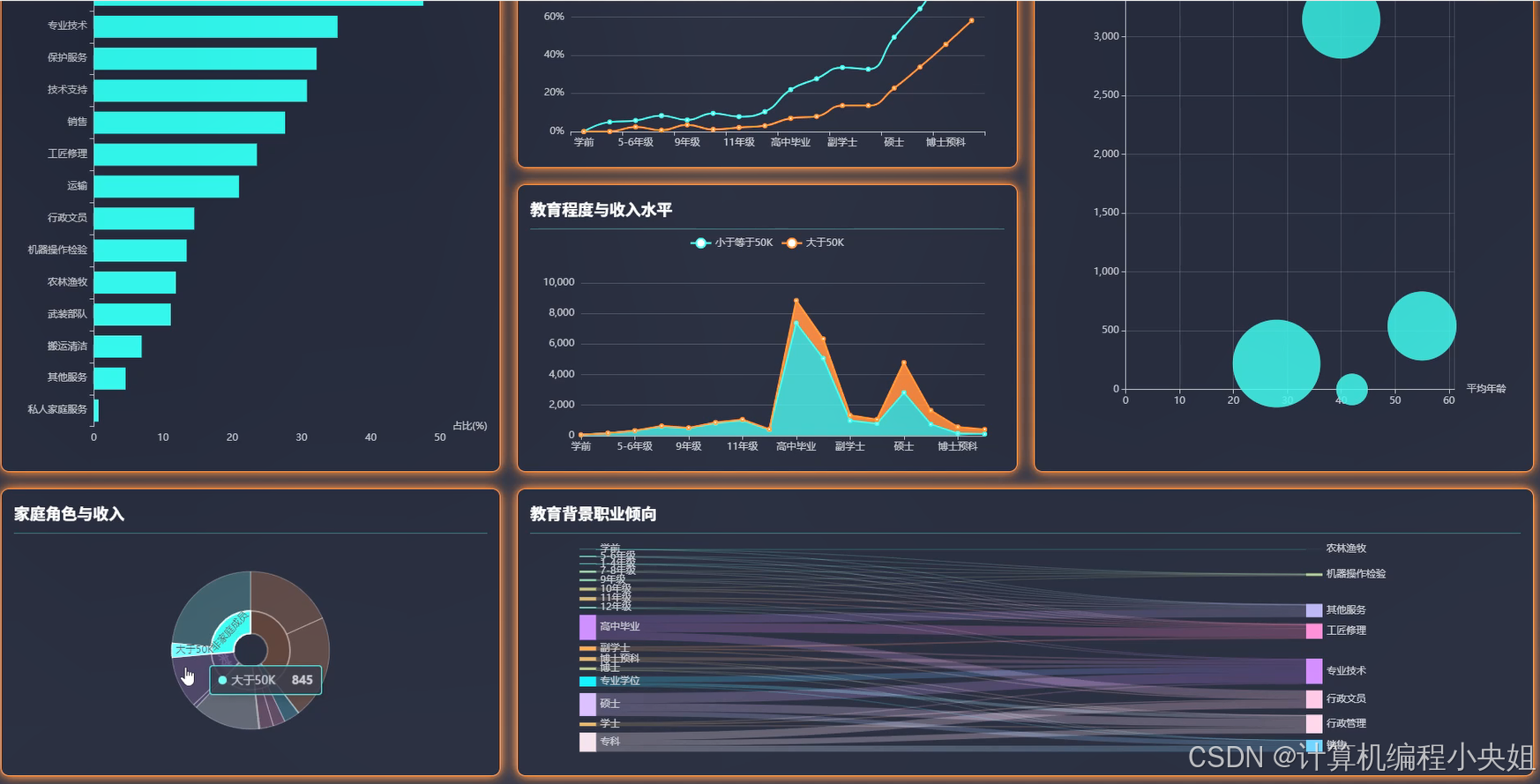
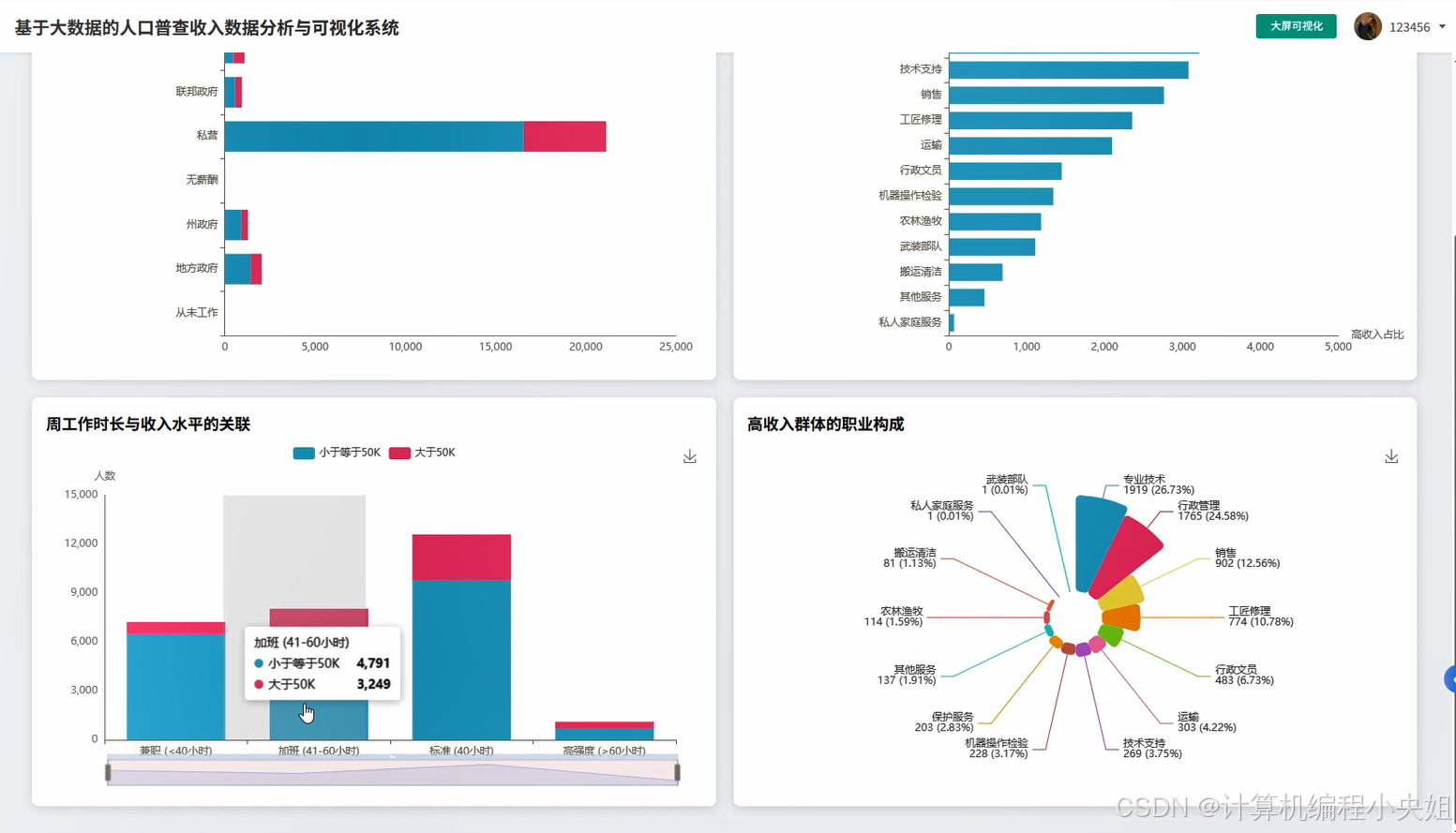
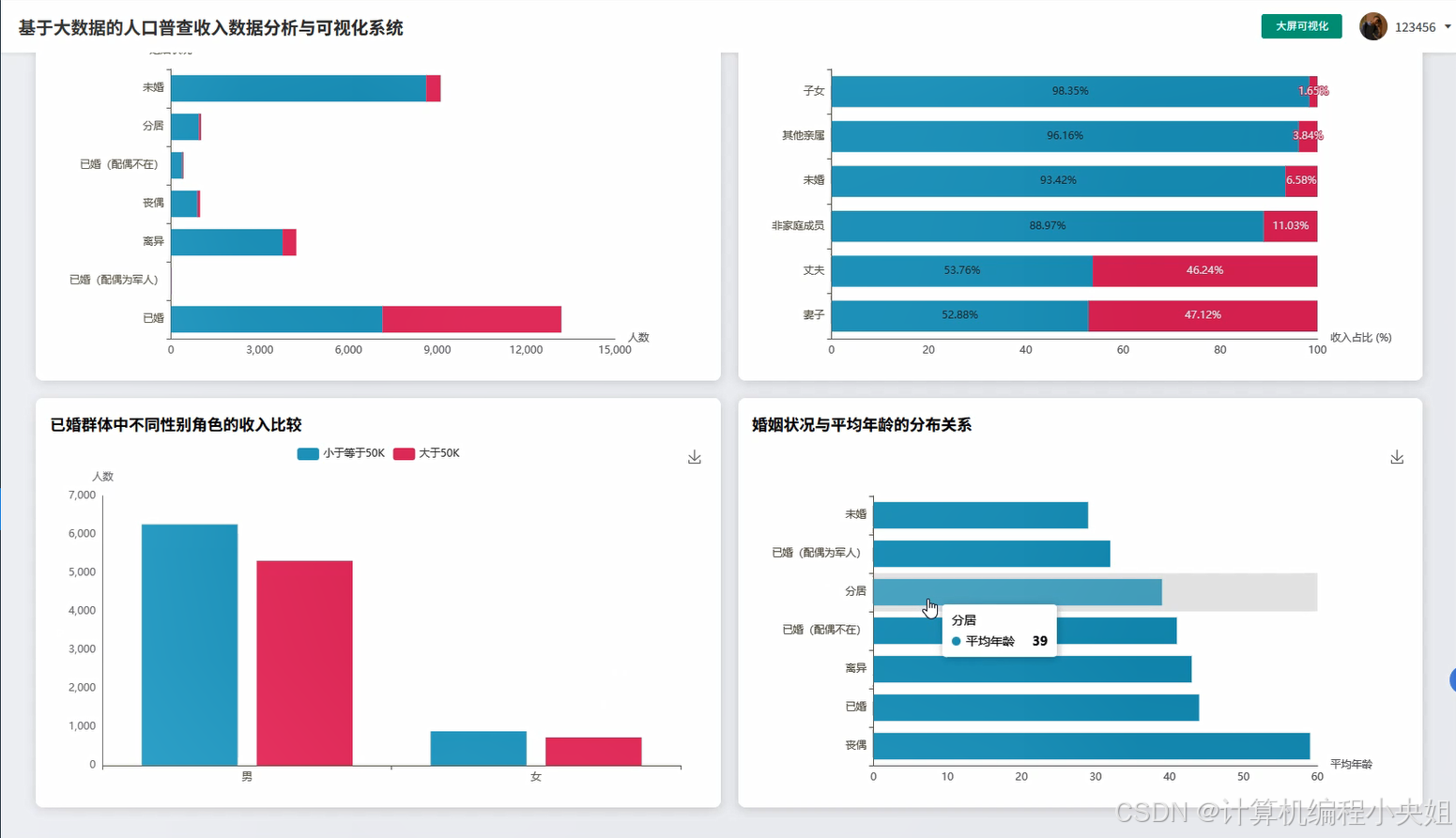
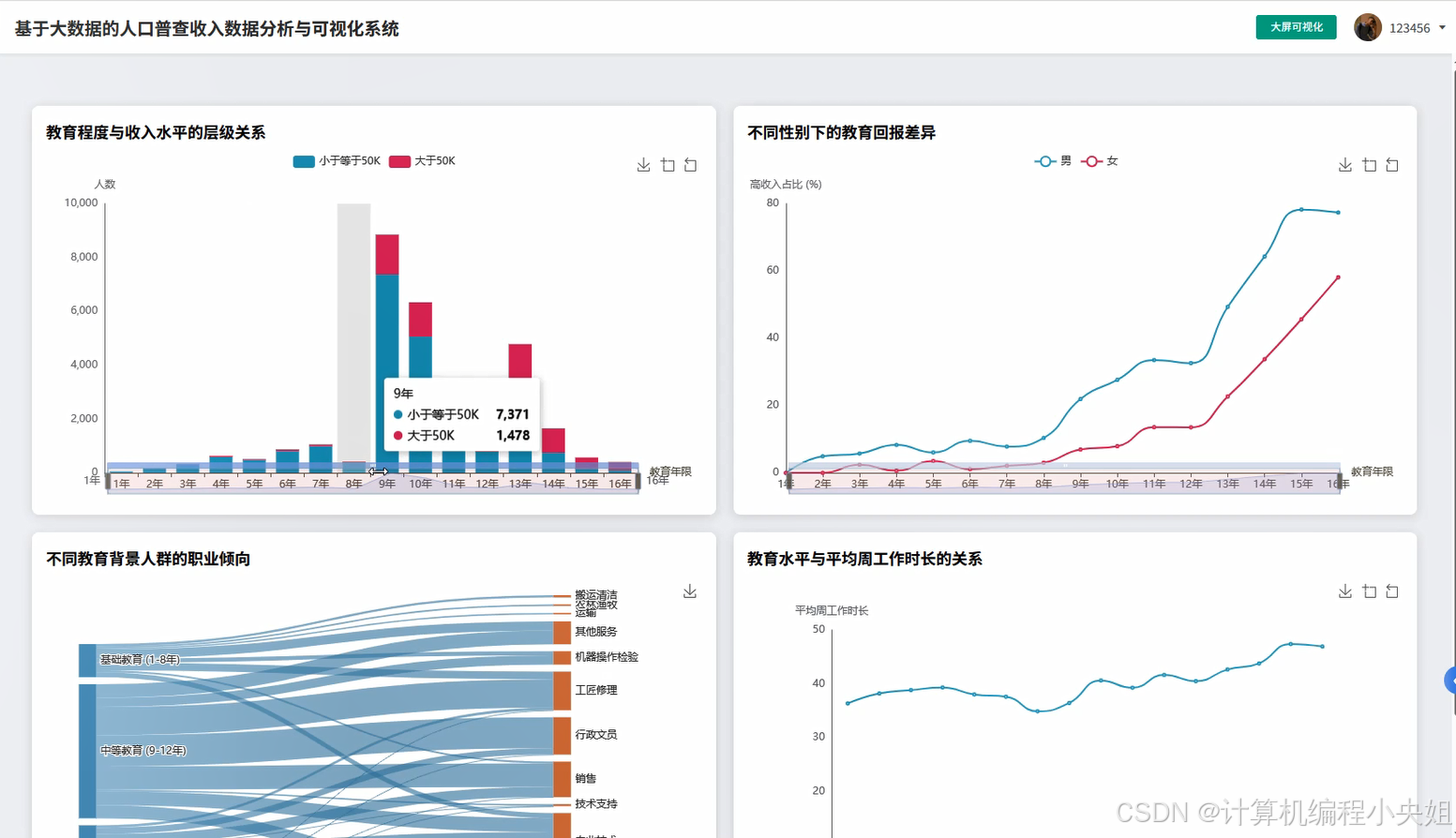
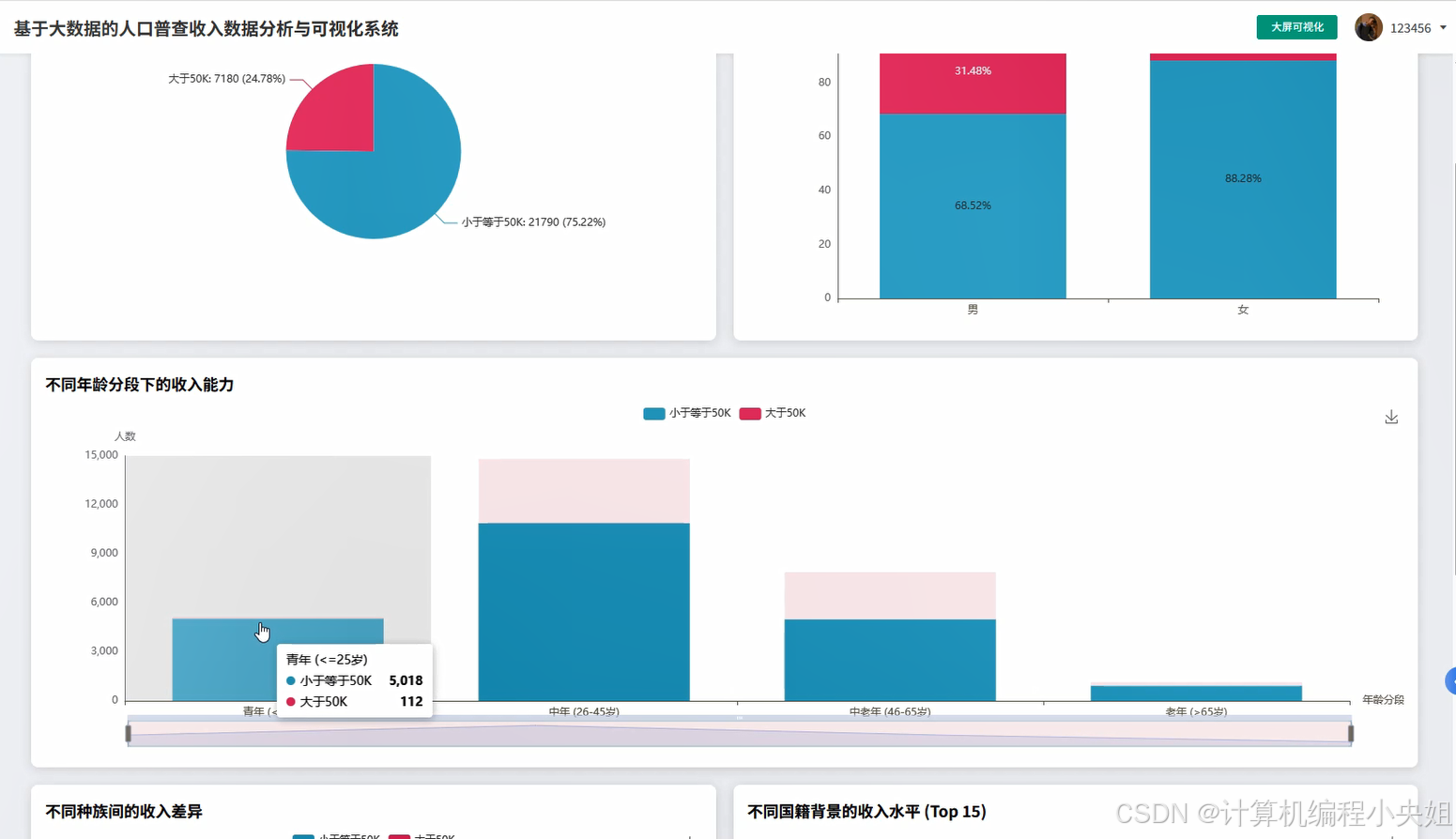
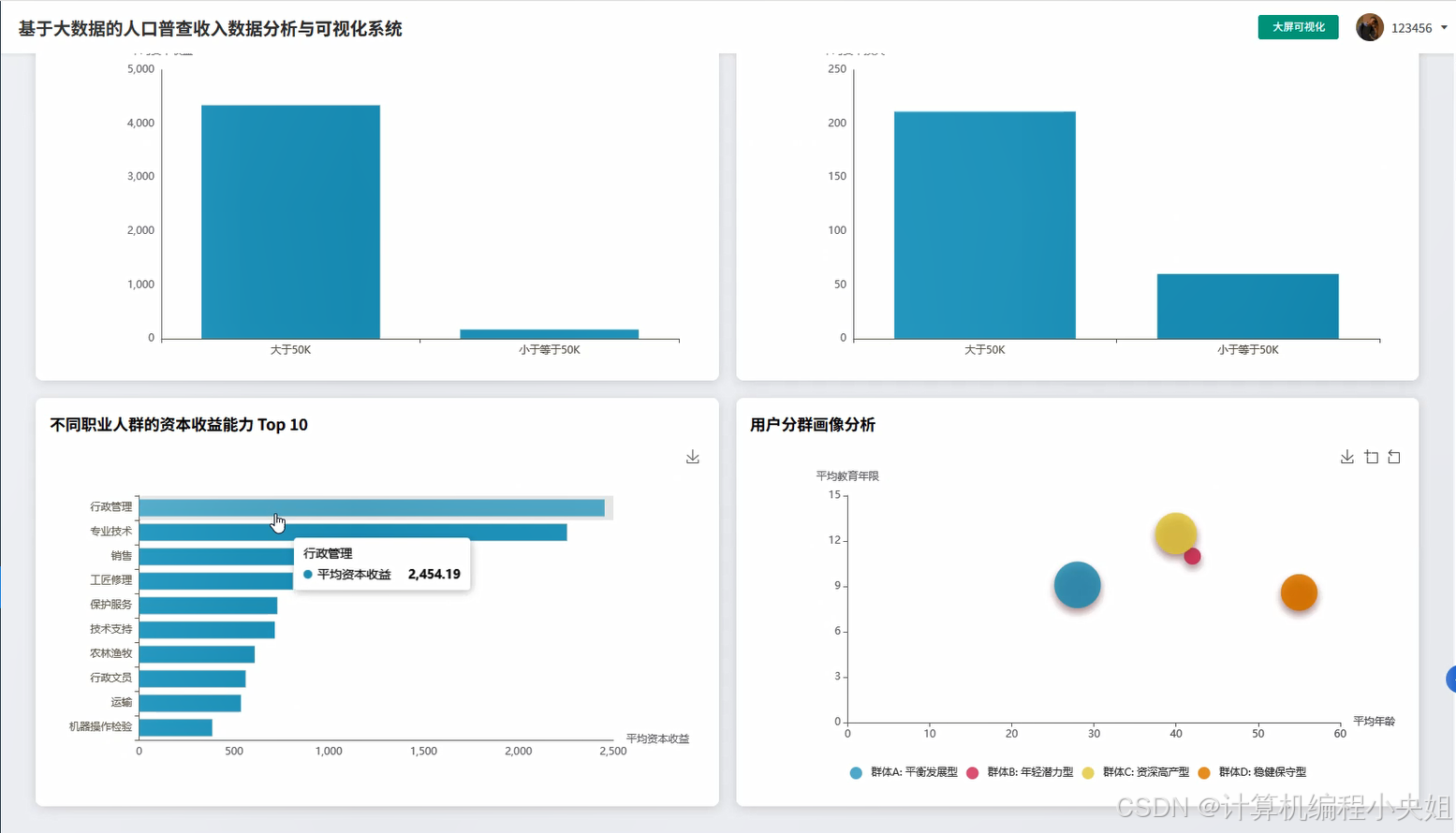
基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-系统部分代码
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, avg, when, desc, asc
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
import pandas as pd
spark = SparkSession.builder.appName("IncomeDataAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def analyze_income_distribution_by_gender():
income_df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/income_data/Income_data.csv")
income_df.createOrReplaceTempView("income_table")
gender_income_analysis = spark.sql("""
SELECT sex, income, COUNT(*) as person_count,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER (PARTITION BY sex), 2) as percentage
FROM income_table
WHERE sex IS NOT NULL AND income IS NOT NULL
GROUP BY sex, income
ORDER BY sex, income
""")
gender_summary = income_df.groupBy("sex", "income").agg(count("*").alias("count")).withColumn("total_by_gender", count("*").over(Window.partitionBy("sex"))).withColumn("percentage", (col("count") / col("total_by_gender") * 100).cast("decimal(5,2)"))
high_income_ratio = income_df.filter(col("income") == ">50K").groupBy("sex").agg(count("*").alias("high_income_count"))
total_by_gender = income_df.groupBy("sex").agg(count("*").alias("total_count"))
gender_high_income_ratio = high_income_ratio.join(total_by_gender, "sex").withColumn("high_income_ratio", (col("high_income_count") / col("total_count") * 100).cast("decimal(5,2)"))
result_data = gender_income_analysis.collect()
analysis_result = []
for row in result_data:
analysis_result.append({
"gender": row["sex"],
"income_level": row["income"],
"person_count": row["person_count"],
"percentage": float(row["percentage"])
})
gender_high_income_data = gender_high_income_ratio.collect()
for row in gender_high_income_data:
analysis_result.append({
"gender": row["sex"],
"high_income_ratio": float(row["high_income_ratio"]),
"analysis_type": "high_income_ratio"
})
return analysis_result
def analyze_education_income_correlation():
income_df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/income_data/Income_data.csv")
income_df.createOrReplaceTempView("education_income_table")
education_income_stats = spark.sql("""
SELECT education, income, COUNT(*) as count,
AVG(CAST(education_num AS DOUBLE)) as avg_education_years,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER (PARTITION BY education), 2) as income_distribution_percent
FROM education_income_table
WHERE education IS NOT NULL AND income IS NOT NULL AND education_num IS NOT NULL
GROUP BY education, income
ORDER BY avg_education_years DESC, income DESC
""")
education_level_mapping = income_df.select("education", "education_num").distinct().orderBy("education_num")
high_income_by_education = income_df.filter(col("income") == ">50K").groupBy("education", "education_num").agg(count("*").alias("high_income_count"))
total_by_education = income_df.groupBy("education", "education_num").agg(count("*").alias("total_count"))
education_success_rate = high_income_by_education.join(total_by_education, ["education", "education_num"], "right").fillna(0).withColumn("success_rate", (col("high_income_count") / col("total_count") * 100).cast("decimal(5,2)")).orderBy("education_num")
education_occupation_correlation = spark.sql("""
SELECT education, occupation, COUNT(*) as count,
RANK() OVER (PARTITION BY education ORDER BY COUNT(*) DESC) as occupation_rank
FROM education_income_table
WHERE education IS NOT NULL AND occupation IS NOT NULL
GROUP BY education, occupation
""").filter(col("occupation_rank") <= 3)
education_stats_result = education_income_stats.collect()
education_success_result = education_success_rate.collect()
education_occupation_result = education_occupation_correlation.collect()
final_analysis = []
for row in education_stats_result:
final_analysis.append({
"education": row["education"],
"income_level": row["income"],
"count": row["count"],
"avg_education_years": float(row["avg_education_years"]),
"distribution_percent": float(row["income_distribution_percent"])
})
for row in education_success_result:
final_analysis.append({
"education": row["education"],
"education_years": row["education_num"],
"success_rate": float(row["success_rate"]) if row["success_rate"] else 0.0,
"analysis_type": "success_rate"
})
return final_analysis
def analyze_occupation_work_hours_income():
income_df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/income_data/Income_data.csv")
income_df.createOrReplaceTempView("occupation_hours_table")
work_hours_categories = income_df.withColumn("hours_category", when(col("hours_per_week") <= 30, "Part-time").when(col("hours_per_week") <= 40, "Standard").when(col("hours_per_week") <= 50, "Overtime").otherwise("Intensive"))
work_hours_categories.createOrReplaceTempView("hours_category_table")
occupation_hours_income_analysis = spark.sql("""
SELECT occupation, hours_category, income, COUNT(*) as worker_count,
AVG(hours_per_week) as avg_hours,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER (PARTITION BY occupation), 2) as percentage_in_occupation
FROM hours_category_table
WHERE occupation IS NOT NULL AND hours_per_week IS NOT NULL AND income IS NOT NULL
GROUP BY occupation, hours_category, income
ORDER BY occupation, avg_hours DESC, income DESC
""")
high_income_occupation_ranking = spark.sql("""
SELECT occupation, COUNT(*) as high_income_count,
RANK() OVER (ORDER BY COUNT(*) DESC) as occupation_rank,
AVG(hours_per_week) as avg_hours_high_earners
FROM hours_category_table
WHERE income = '>50K' AND occupation IS NOT NULL
GROUP BY occupation
ORDER BY high_income_count DESC
LIMIT 10
""")
hours_income_efficiency = spark.sql("""
SELECT hours_category, income, COUNT(*) as count,
AVG(hours_per_week) as avg_hours,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER (PARTITION BY hours_category), 2) as income_ratio_in_category
FROM hours_category_table
WHERE hours_per_week IS NOT NULL AND income IS NOT NULL
GROUP BY hours_category, income
ORDER BY avg_hours, income DESC
""")
occupation_workload_stress = income_df.groupBy("occupation").agg(avg("hours_per_week").alias("avg_hours"), count("*").alias("total_workers"), avg(when(col("income") == ">50K", 1).otherwise(0)).alias("high_income_rate")).filter(col("total_workers") >= 50).orderBy(desc("avg_hours"))
occupation_analysis_result = occupation_hours_income_analysis.collect()
ranking_result = high_income_occupation_ranking.collect()
efficiency_result = hours_income_efficiency.collect()
workload_result = occupation_workload_stress.collect()
comprehensive_analysis = []
for row in occupation_analysis_result:
comprehensive_analysis.append({
"occupation": row["occupation"],
"hours_category": row["hours_category"],
"income_level": row["income"],
"worker_count": row["worker_count"],
"avg_hours": float(row["avg_hours"]),
"percentage_in_occupation": float(row["percentage_in_occupation"])
})
for row in ranking_result:
comprehensive_analysis.append({
"occupation": row["occupation"],
"high_income_count": row["high_income_count"],
"occupation_rank": row["occupation_rank"],
"avg_hours_high_earners": float(row["avg_hours_high_earners"]),
"analysis_type": "occupation_ranking"
})
return comprehensive_analysis基于spark+hadoop基于大数据的人口普查收入数据分析与可视化系统-结语
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。