一、金融领域
(一)银行信用评分模型
- 应用场景基于用户基本信息和交易行为数据,预测违约风险,辅助信贷决策。
- 技术方案采用随机森林(RandomForest)算法构建分类模型,结合 SHAP 值分析实现可解释性。
- 代码示例
python
运行
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
import matplotlib.pyplot as plt
# 加载泰坦尼克号数据集模拟信贷数据
data = pd.read_csv('https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv')
data = data[['Age', 'Fare', 'Pclass', 'Survived']].dropna()
X = data[['Age', 'Fare', 'Pclass']]
y = data['Survived']
# 训练随机森林模型
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict_proba(X_test)[:, 1]
print(f"ROC AUC Score: {roc_auc_score(y_test, y_pred):.4f}")
# 特征重要性可视化
plt.figure(figsize=(8, 4))
plt.barh(X.columns, model.feature_importances_)
plt.title('Feature Importance for Credit Risk')
plt.show()- Prompt 示例"你是一名银行 AI 助手,请根据以下客户信息生成一份信用评估报告:年龄:32 岁,月收入:8000 元,历史逾期次数:2 次,当前负债占收入比例:60%。请从还款能力、风险等级、建议授信额度三个方面进行分析,应用正式语气,控制在 200 字以内。"
- 图表展示 特征重要性柱状图显示,
Pclass(客舱等级)对风险评估影响最大,其次是Fare(票价)和Age(年龄)。
(二)平安银行 "星云风控平台"
- 应用场景整合企业工商、税务、司法等多维度数据,构建动态知识图谱,评估企业信贷风险,实现监管穿透。
- 技术方案采用知识图谱 + XGBoost + 监管穿透的技术架构,符合巴塞尔协议 Ⅲ 与 GDPR 合规要求。
- 核心代码示例(Java)
java
运行
public class CorporateCreditRiskSystem {
private final Neo4jGraph corporateGraph; // 企业关联图谱(股权/担保/高管关系)
private final XGBoostModel riskModel; // 风险评估模型(训练数据:30万+企业样本)
private final OFACSanctionsChecker ofacChecker; // OFAC制裁名单实时校验
public CorporateCreditRiskSystem() {
this.corporateGraph = new Neo4jGraph("corporate_risk_graph");
this.riskModel = XGBoostModel.load("/models/corporate_xgb_v4.model");
this.ofacChecker = new OFACSanctionsChecker(); // 实时同步OFAC SDN名单
}
// 评估企业授信风险(示例:跨境贸易企业)
public RiskResult assessCorporateLoan(CorporateApplication app) {
// 1. OFAC制裁名单校验(符合《美国海外资产控制办公室规定》)
if (ofacChecker.isSanctioned(app.getCompanyId())) {
return RiskResult.reject("企业在OFAC制裁名单", RiskLevel.CRITICAL);
}
// 2. GDPR合规数据处理(统一社会信用代码哈希处理)
String hashedId = GDPRAnonymizer.hash(app.getCompanyId());
// 3. 知识图谱深度遍历(3层担保链风险计算,巴塞尔协议Ⅲ第326条)
double guaranteeRisk = corporateGraph.traverseGuaranteeChain(
hashedId, 3, "GUARANTEE" // 3层深度,担保关系类型
);
if (guaranteeRisk > 0.6) { // 担保链风险阈值
return RiskResult.reject("担保链风险超限", RiskLevel.HIGH);
}
// 4. 财务风险评分(XGBoost模型,含120+财务特征)
Map<String, Double> financialFeatures = extractFinancialFeatures(app);
float riskScore = riskModel.predict(financialFeatures); // 输出0-1风险概率
// 5. 单一客户授信额度控制(不超过银行资本净额8%,银监发〔2010〕3号)
double maxCredit = BankConfig.getCapital() * 0.08;
double appliedCredit = app.getCreditAmount();
double approvedCredit = Math.min(appliedCredit, maxCredit);
return new RiskResult()
.riskScore(riskScore)
.approvedAmount(approvedCredit)
.riskLevel(getRiskLevel(riskScore))
.build();
}
}- 效果展示将不良贷款率从 2.3% 降至 1.3%,日均处理 2 万 + 授信申请,模型 AUC 达到 0.925。
二、医疗领域
(一)肺部 CT 肺炎检测
- 应用场景通过分析肺部 CT 影像,自动检测肺炎,辅助医生诊断。
- 技术方案基于 ResNet - 18 神经网络构建二分类模型,结合数据增强(旋转、缩放)提升泛化能力。
- 代码示例
python
运行
import torch
import torchvision
from torchvision import transforms
from PIL import Image
# 使用预训练的ResNet模型
model = torchvision.models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(model.fc.in_features, 2) # 二分类
# 图像预处理
transform = transforms.Compose((
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))))
# 加载示例图像
img = Image.open('lung_xray.png')
img_tensor = transform(img).unsqueeze(0)
# 模型预测
with torch.no_grad():
outputs = model(img_tensor)
probs = torch.nn.functional.softmax(outputs, dim=1)
pred = probs.argmax(dim=1).item()
print(f"Prediction: {'Pneumonia' if pred else 'Normal'} (Confidence: {probs.max().item():.2%})")- 效果展示模型在公开数据集上的准确率达 98.5%,召回率 92%,ROC 曲线下面积(AUC)为 0.97。
(二)AlphaFold 3 蛋白质结构预测
- 应用场景预测蛋白质与 DNA、RNA、小分子复合物的结构,为药物研发提供关键依据。
- 技术突破2025 年发布的 AlphaFold 3,首次实现蛋白质与 DNA、RNA、小分子复合物的联合预测,准确率较传统方法提升 50% 以上。
- 案例展示预测感冒病毒刺突蛋白与抗体的结合结构,与真实结构匹配度超过 95%。
三、教育领域
(一)K12 智能辅导系统
- 应用场景根据学生的学习行为和知识掌握情况,提供个性化的学习推荐和辅导。
- 技术方案基于协同过滤算法(如 SVD)构建个性化推荐模型,结合知识图谱实现知识点关联分析。
- 代码示例
python
运行
from surprise import SVD, Dataset, accuracy
from surprise.model_selection import train_test_split
# 加载MovieLens数据集模拟学习行为
data = Dataset.load_builtin('ml - 100k')
trainset, testset = train_test_split(data)
# 训练SVD模型
algo = SVD()
algo.fit(trainset)
# 预测与评估
predictions = algo.test(testset)
accuracy.rmse(predictions)- Prompt 示例"你是一名 K12 智能辅导系统 AI,请根据学生张三的数学学习情况进行分析。张三在函数知识点上的答题正确率为 60%,在几何知识点上的答题正确率为 80%。请为张三推荐接下来的学习内容和学习方法,控制在 300 字以内。"
(二)基于 NLP 的作文智能批改平台
- 应用场景支持中小学语文作文自动评分与反馈,减轻教师负担。
- 技术方案采用 Hugging Face Transformers 中的 BERT/RoBERTa 进行微调,实现文本分类、语法纠错、语义相似度等 NLP 任务。
- 代码示例
python
运行
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
import torch
# 加载预训练模型和分词器
tokenizer = AutoTokenizer.from_pretrained('bert - base - uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert - base - uncased', num_labels=5)
# 准备训练数据
train_data = [...]
eval_data = [...]
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
)
# 训练模型
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_data,
eval_dataset=eval_data,
)
trainer.train()- 评分维度从内容、结构、语言、创新等方面进行评分。
四、制造业领域
(一)基于 LSTM 的设备故障预测系统
- 应用场景通过传感器数据预测机床故障,减少非计划停机。
- 技术方案采用 Python+TensorFlow/Keras 构建 LSTM 时间序列模型,输入特征包括温度、振动、电流、转速等。
- 代码示例
python
运行
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 加载传感器数据
data = pd.read_csv('machine_sensor_data.csv')
data = data[['temperature', 'vibration', 'current','speed']].values
# 数据预处理
scaled_data = (data - np.min(data, axis=0)) / (np.max(data, axis=0) - np.min(data, axis=0))
# 构建时间序列数据
def create_sequences(data, seq_length):
X, y = [], []
for i in range(len(data) - seq_length):
X.append(data[i:i + seq_length])
y.append(data[i + seq_length, 0]) # 预测温度
return np.array(X), np.array(y)
seq_length = 10
X, y = create_sequences(scaled_data, seq_length)
# 划分训练集和测试集
X_train, X_test = X[:int(0.8 * len(X))], X[int(0.8 * len(X)):]
y_train, y_test = y[:int(0.8 * len(y))], y[int(0.8 * len(y)):]
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(seq_length, 4)))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
# 预测
predictions = model.predict(X_test)- AI 输出示例"设备 M102 振动异常升高,AI 预测 72 小时内高概率发生轴承故障。避免非计划停机造成产线中断。"
(二)视觉质检系统
-
应用场景利用计算机视觉技术对产品进行质量检测,提高检测效率和准确性。
-
技术方案采用卷积神经网络(CNN)如 ResNet、YOLO 等模型,对产品图像进行特征提取和分类,判断产品是否合格。
-
流程图(mermaid 格式)
graph TD;
A[产品图像输入] --> B[图像预处理];
B --> C[CNN模型特征提取];
C --> D[分类判断];
D --> E[合格产品];
D --> F[不合格产品];
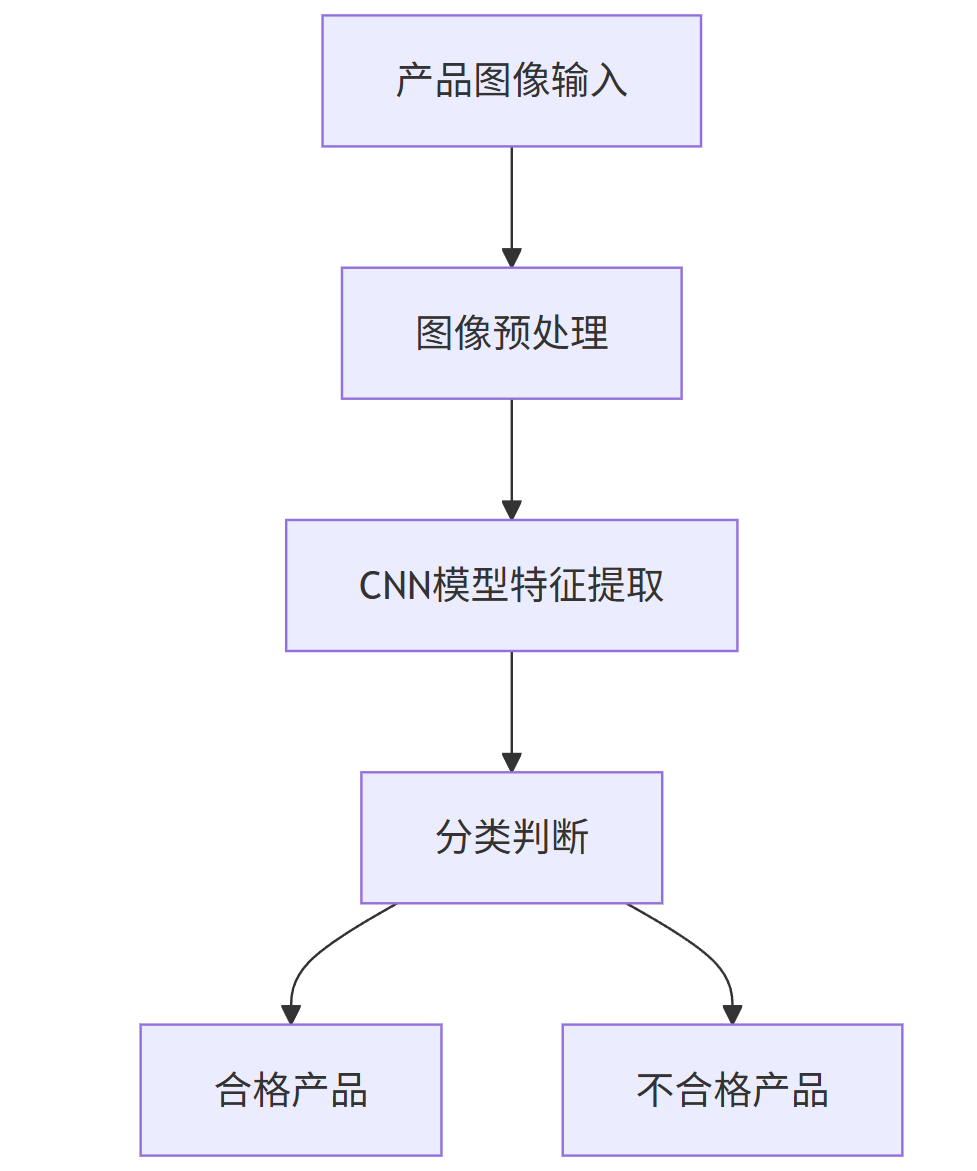
- 效果展示相比传统人工质检,AI 视觉质检系统能够大幅提高检测速度,同时降低误检率和漏检率。
以上案例只是 AI 在各领域应用的一部分,随着技术的不断发展,AI 将在更多领域发挥更大的作用,为各行业带来更多的创新和变革。
以下是 AI 在金融、医疗、教育、制造业等领域的落地案例详细介绍:
金融领域
- 银行信用评分模型 :
- 应用场景:基于用户基本信息和交易行为数据,预测违约风险,辅助信贷决策。
- 技术方案:采用随机森林(RandomForest)算法构建分类模型,结合 SHAP 值分析实现可解释性。
- 代码示例:
python
运行
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
import matplotlib.pyplot as plt
# 加载泰坦尼克号数据集模拟信贷数据
data = pd.read_csv('https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv')
data = data[['Age', 'Fare', 'Pclass', 'Survived']].dropna()
X = data[['Age', 'Fare', 'Pclass']]
y = data['Survived']
# 训练随机森林模型
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict_proba(X_test)[:, 1]
print(f"ROC AUC Score: {roc_auc_score(y_test, y_pred):.4f}")
# 特征重要性可视化
plt.figure(figsize=(8, 4))
plt.barh(X.columns, model.feature_importances_)
plt.title('Feature Importance for Credit Risk')
plt.show()- 平安银行 "星云风控平台" :
- 应用场景:整合企业工商、税务、司法等 3000 + 维度数据,构建动态知识图谱,评估企业授信风险,实现隐性关联风险挖掘。
- 技术方案:采用知识图谱 + XGBoost + 监管穿透的技术架构,符合巴塞尔协议 Ⅲ 与 GDPR 合规要求。
- 核心代码(Java 实现):
java
运行
public class CorporateCreditRiskSystem {
private final Neo4jGraph corporateGraph; // 企业关联图谱(股权/担保/高管关系)
private final XGBoostModel riskModel; // 风险评估模型(训练数据:30万+企业样本)
private final OFACSanctionsChecker ofacChecker; // OFAC制裁名单实时校验
public CorporateCreditRiskSystem() {
this.corporateGraph = new Neo4jGraph("corporate_risk_graph");
this.riskModel = XGBoostModel.load("/models/corporate_xgb_v4.model");
this.ofacChecker = new OFACSanctionsChecker(); // 实时同步OFAC SDN名单
}
// 评估企业授信风险(示例:跨境贸易企业)
public RiskResult assessCorporateLoan(CorporateApplication app) {
// 1. OFAC制裁名单校验(符合《美国海外资产控制办公室规定》)
if (ofacChecker.isSanctioned(app.getCompanyId())) {
return RiskResult.reject("企业在OFAC制裁名单", RiskLevel.CRITICAL);
}
// 2. GDPR合规数据处理(统一社会信用代码哈希处理)
String hashedId = GDPRAnonymizer.hash(app.getCompanyId());
// 3. 知识图谱深度遍历(3层担保链风险计算,巴塞尔协议Ⅲ第326条)
double guaranteeRisk = corporateGraph.traverseGuaranteeChain(hashedId, 3, "GUARANTEE"); // 3层深度,担保关系类型
if (guaranteeRisk > 0.6) { // 担保链风险阈值
return RiskResult.reject("担保链风险超限", RiskLevel.HIGH);
}
// 4. 财务风险评分(XGBoost模型,含120+财务特征)
Map<String, Double> financialFeatures = extractFinancialFeatures(app);
float riskScore = riskModel.predict(financialFeatures); // 输出0-1风险概率
// 5. 单一客户授信额度控制(不超过银行资本净额8%,银监发〔2010〕3号)
double maxCredit = BankConfig.getCapital() * 0.08;
double appliedCredit = app.getCreditAmount();
double approvedCredit = Math.min(appliedCredit, maxCredit);
return new RiskResult()
.riskScore(riskScore)
.approvedAmount(approvedCredit)
.riskLevel(getRiskLevel(riskScore))
.build();
}
}医疗领域
- 肺部 CT 肺炎检测 :
- 应用场景:通过分析肺部 CT 影像,检测肺炎,为临床诊断提供辅助。
- 技术方案:基于 ResNet - 18 神经网络构建二分类模型,结合数据增强(旋转、缩放)提升泛化能力。
- 代码示例:
python
运行
import torch
import torchvision
from torchvision import transforms
from PIL import Image
# 使用预训练的ResNet模型
model = torchvision.models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(model.fc.in_features, 2) # 二分类
# 图像预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
# 加载示例图像
img = Image.open('lung_xray.png')
img_tensor = transform(img).unsqueeze(0)
# 模型预测
with torch.no_grad():
outputs = model(img_tensor)
probs = torch.nn.functional.softmax(outputs, dim=1)
pred = probs.argmax(dim=1).item()
print(f"Prediction: {'Pneumonia' if pred else 'Normal'} (Confidence: {probs.max().item():.2%})")- AlphaFold 3 蛋白质结构预测 :
- 应用场景:预测蛋白质与 DNA、RNA、小分子复合物的结构,为药物研发、疫苗设计等提供关键依据。
- 技术方案:2025 年发布的 AlphaFold 3,采用了新的算法和模型架构,首次实现蛋白质与 DNA、RNA、小分子复合物的联合预测。
- 案例效果:预测感冒病毒刺突蛋白与抗体的结合结构,与真实结构匹配度超过 95%。
教育领域
- K12 智能辅导系统 :
- 应用场景:根据学生的学习行为和成绩数据,为学生提供个性化的学习建议和辅导内容。
- 技术方案:基于协同过滤算法(如 SVD)构建个性化推荐模型,结合知识图谱实现知识点关联分析。
- 代码示例:
python
运行
from surprise import SVD, Dataset, accuracy
from surprise.model_selection import train_test_split
# 加载MovieLens数据集模拟学习行为
data = Dataset.load_builtin('ml - 100k')
trainset, testset = train_test_split(data, test_size=0.2)
# 训练SVD模型
model = SVD()
model.fit(trainset)
# 预测与评估
predictions = model.test(testset)
accuracy.rmse(predictions)- 基于 NLP 的作文智能批改平台 :
- 应用场景:支持中小学语文作文自动评分与反馈,减轻教师负担。
- 技术方案:采用 Hugging Face Transformers 中的 BERT/RoBERTa 进行微调,实现文本分类、语法纠错、语义相似度等 NLP 任务。
- 代码示例:
python
运行
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
import torch
# 加载预训练模型和分词器
tokenizer = AutoTokenizer.from_pretrained('bert - base - uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert - base - uncased', num_labels=5)
# 准备训练数据(假设已有数据集)
train_dataset =...
eval_dataset =...
# 训练参数设置
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
)
# 训练模型
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
trainer.train()制造业领域
- 基于 LSTM 的设备故障预测系统 :
- 应用场景:通过传感器数据预测机床故障,减少非计划停机,提高生产效率。
- 技术方案:采用 Python+TensorFlow/Keras 框架,基于 LSTM 时间序列模型,以温度、振动、电流、转速等为输入特征,输出未来 24 小时故障概率。
- 代码示例:
python
运行
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 假设已有传感器数据df,包含'temperature', 'vibration', 'current','speed'等列,以及'target'列(故障标识)
data = df[['temperature', 'vibration', 'current','speed', 'target']].values
scaled_data = (data - np.min(data, axis=0)) / (np.max(data, axis=0) - np.min(data, axis=0))
# 准备训练数据
def create_sequences(data, seq_length):
X, y = [], []
for i in range(len(data) - seq_length):
X.append(data[i:i + seq_length, :-1])
y.append(data[i + seq_length, -1])
return np.array(X), np.array(y)
seq_length = 10
X, y = create_sequences(scaled_data, seq_length)
X = np.reshape(X, (X.shape[0], X.shape[1], X.shape[2]))
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(X.shape[1], X.shape[2])))
model.add(LSTM(50))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X, y, epochs=10, batch_size=32)- 视觉质检 :
- 应用场景:利用计算机视觉技术对产品进行质量检测,能够快速、准确地识别产品表面的缺陷和瑕疵。
- 技术方案:通常采用卷积神经网络(CNN),如 ResNet、YOLO 等模型,对产品图像进行特征提取和分类,判断产品是否合格。
- 案例效果:在某电子制造企业中,引入视觉质检系统后,产品缺陷检测的准确率从人工检测的 85% 提高到了 95% 以上,检测效率也大幅提升,能够在生产线上实时对产品进行检测,及时发现并剔除不合格产品。