介绍 SWE-bench:语言模型能否解决真实世界的 GitHub 问题?
大家好!今天来聊聊一篇最近在 ICLR 2024 上发表的论文:《SWE-bench: Can Language Models Resolve Real-World GitHub Issues?》。这篇论文来自普林斯顿大学和芝加哥大学的研究团队,他们提出了一种新型基准测试,用于评估语言模型(LM)在真实软件工程任务中的表现。论文的核心问题是:当前的语言模型是否能真正帮助开发者修复 GitHub 上的真实问题?答案是------目前还远远不够,但这个基准为未来发展提供了宝贵平台。
Paper:https://arxiv.org/pdf/2310.06770
为什么需要 SWE-bench?
语言模型如 GPT-4 或 Claude 已经在聊天机器人和代码生成工具中大放异彩,但现有基准测试(如 HumanEval)往往太简单:它们通常是独立的小问题,只需几行代码就能解决。现实中的软件工程远不止于此------修复 bug 可能涉及浏览大型代码库、理解多个文件间的交互,甚至处理复杂的依赖关系。
论文指出,现有的基准测试已经"饱和"(saturated),无法捕捉语言模型的极限能力。作者认为,真实世界的软件工程是一个丰富、可持续且富有挑战性的测试场,能推动下一代语言模型的发展。于是,他们引入了 SWE-bench:一个包含 2,294 个真实 GitHub 问题的评估框架,这些问题来自 12 个热门 Python 仓库(如 Django、Matplotlib 等)。
SWE-bench 是如何构建的?
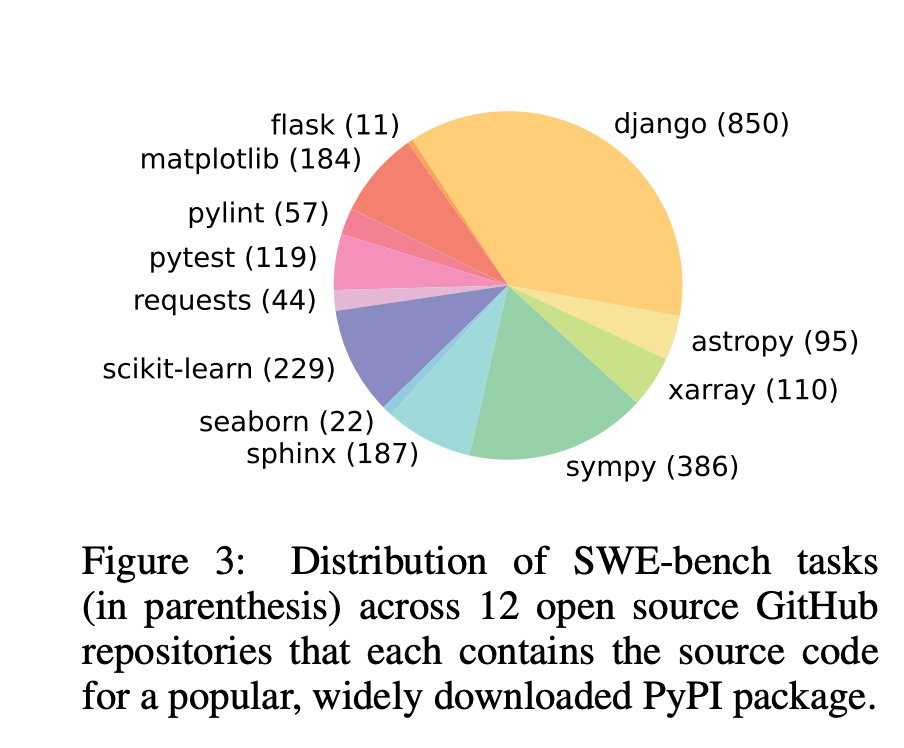
SWE-bench 的构建过程分为三个阶段,确保任务高质量且真实:
- 仓库选择与数据爬取:从 GitHub 上选取 12 个流行 Python 仓库,收集约 90,000 个 Pull Request(PR)。
- 属性过滤:只保留那些解决 GitHub Issue 并修改测试文件的 PR(表示添加了验证测试)。
- 执行过滤:应用 PR 内容,运行测试,确保至少有一个测试从失败转为通过(fail-to-pass test),并排除安装或运行错误的实例。
最终,过滤出 2,294 个任务实例。每个任务包括:
- 一个代码库快照。
- 一个 Issue 描述(通常是 bug 报告或功能请求)。
- 模型需生成一个补丁(patch)来修复问题。
评估方式很简单:应用生成的补丁到代码库,运行相关测试。如果补丁应用成功且所有 fail-to-pass 测试通过,则视为解决。基准的指标是解决任务的比例。
SWE-bench 的亮点包括:
- 真实性:直接来自 GitHub,用户提交的问题和解决方案。
- 多样性:Issue 描述平均 195 词,代码库平均 3,010 个文件、438K 行代码。
- 可更新性:可以轻松扩展到更多仓库和语言。
- 挑战性:参考解决方案平均编辑 1.7 个文件、3.0 个函数、32.8 行代码。
此外,他们还创建了一个 Lite 版本(300 个实例),更易评估,以及一个训练集 SWE-bench-train(19,000 个实例)用于 fine-tune 模型。
分析显示:
- 难度因仓库而异,但模型在不同仓库的趋势类似。
- 上下文长度增加时性能下降(模型容易被无关代码分散注意力)。
- 模型生成的补丁通常更短、更简单,但不够全面。
- 细调模型对上下文分布变化敏感。
定性分析显示,模型倾向于编写原始 Python 代码,不利用第三方库或代码库风格;金标准解决方案往往更全面,还考虑未来潜在问题。
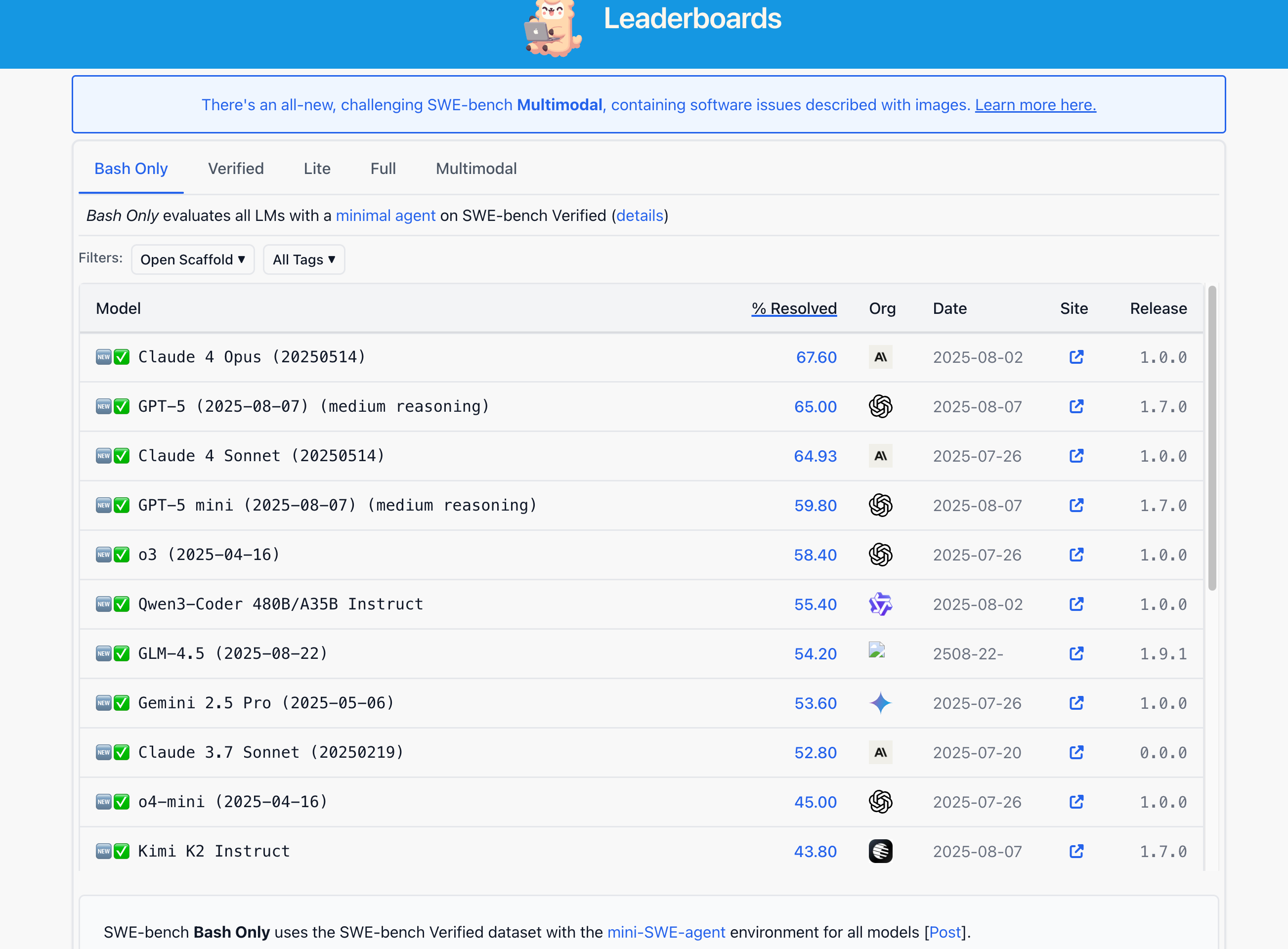
2025年9月24日截图leaderboard。
SWE-Llama:开源模型的尝试
为了评估开源模型,作者在 SWE-bench-train 上 fine-tune 了 CodeLlama-Python,得到 SWE-Llama 7B 和 13B。这些模型在消费者级硬件上运行,能生成仓库级编辑,但仍需改进以处理长上下文和复杂推理。
论文的意义与未来方向
SWE-bench 填补了编程基准的空白,提供了一个真实、可持续的测试平台。它鼓励从检索增强模型到决策代理等多种方法的发展。论文强调,仅靠执行测试不足以保证代码质量------模型生成的代码往往不如人类解决方案全面、高效或可读。
局限性包括:目前只限于 Python;实验仅为基线,鼓励未来探索代理或工具增强 LM。未来可扩展到更多语言和领域。
总之,这篇论文提醒我们:语言模型在简单任务上耀眼,但在真实软件工程中还有很长的路要走。SWE-bench 不仅是基准,更是通往更实用、智能、自治 AI 的桥梁。如果你对 AI 与软件工程感兴趣,不妨去 swebench.com 查看数据、代码和排行榜!
欢迎评论你的看法:你觉得语言模型何时能真正"修复" GitHub Issue?下期见!
后记
本文在grok 3大模型辅助下完成。2025年9月25日于山东。