在2025年云栖大会上,阿里云DLF产品负责人李鲁兵正式发布了DLF(Data Lake Formation)3.0,升级为面向AI时代的智能全模态湖仓管理平台。此次发布标志着DLF从传统的湖仓管理工具,全面进化为支持结构化、半结构化与非结构化数据统一管理、安全开放、性能卓越的新一代数据基础设施。本文将系统梳理DLF 3.0的架构演进、核心能力、典型应用场景以及其在实际业务中的落地价值。 
一、Data+AI需求驱动Lakehouse再进化
随着AI时代的到来,数据形态正经历前所未有的变革。传统以表结构为主的数据仓库已难以满足日益复杂的业务需求。如今,企业不仅需要处理结构化交易数据,还需高效管理图像、音频、视频、PDF等全模态非结构化数据。同时,业务对数据新鲜度的要求也从"天级"、"小时级"快速演进至"分钟级"甚至"秒级"。
在这样的背景下,Lakehouse架构应运而生,并持续演进。阿里云观察到四大核心趋势正在驱动Lakehouse的下一轮升级:
- 数据处理多维化:从单一表格数据扩展到多模态、多源异构数据的统一管理;
- 数据新鲜度提升:实时性要求从分钟级向秒级演进;
- 开放性必须保留:平台需兼容开源生态,避免厂商锁定(Vendor Lock-in);
- 安全与稳定性要求提高:企业级用户对权限控制、审计合规、系统可靠性提出更高标准;
正是这些需求,推动DLF迈向3.0,构建一个真正"安全、开放、全模态"的新一代全模态湖仓管理平台。 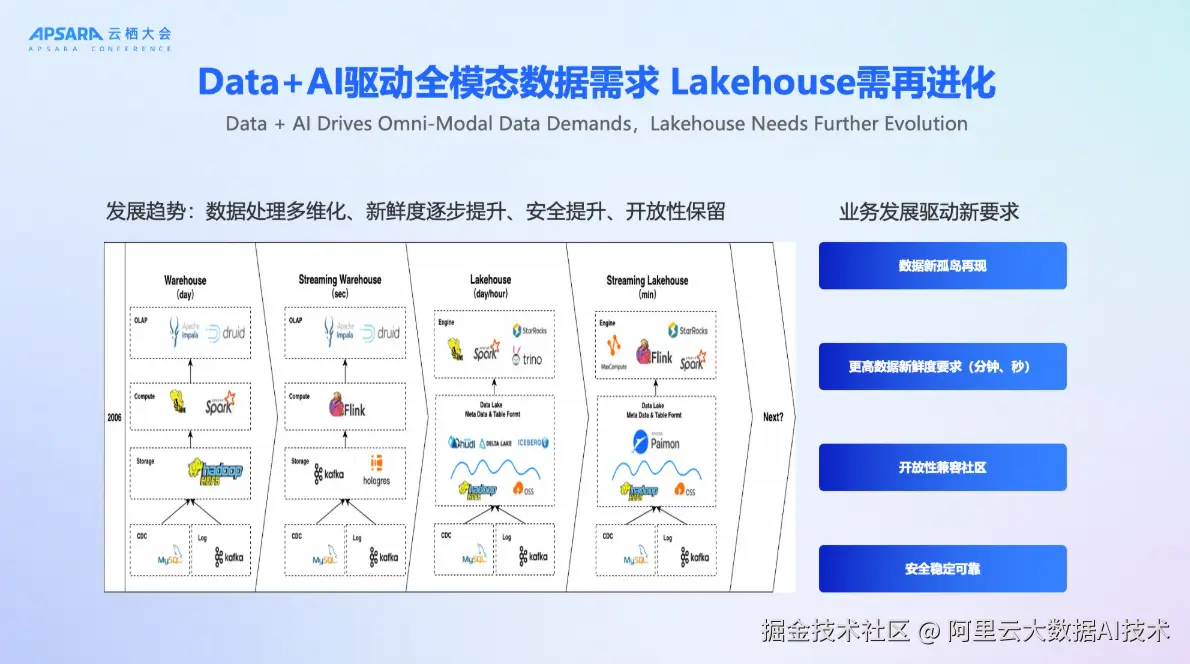
二、DLF产品演进:从元数据管理到全模态湖仓管理平台
DLF的发展历程紧密跟随大数据架构的演进路径。其1.0版本诞生于Hadoop生态时代,核心目标是替代Hive Metastore(HMS),为用户提供统一的元数据管理服务,帮助企业在复杂的Hadoop组件中实现计算与存储引擎的协同。
随着Lakehouse架构逐步取代传统Hadoop体系,DLF在2.0阶段完成了关键转型:从元数据管理工具升级为面向Lakehouse的开放元数据与数据管理平台。该阶段支持Paimon、Iceberg等主流湖格式,实现流批一体、分钟级数据新鲜度,并帮助用户平滑迁移至Lakehouse架构。
然而,随着用户规模扩大和AI场景爆发,2.0架构暴露出若干挑战:存储管理分散导致误操作风险、安全控制粒度不足、非结构化数据无法纳入统一治理等。为此,DLF 3.0应运而生。
DLF 3.0的核心定位是:一个安全、开放、支持全模态数据的一体化Lakehouse管理平台。它不仅延续了对结构化表数据的支持,更将文件(Files)、向量、多媒体等非结构化数据纳入统一目录与生命周期管理体系,真正实现"一张湖"管理所有数据。 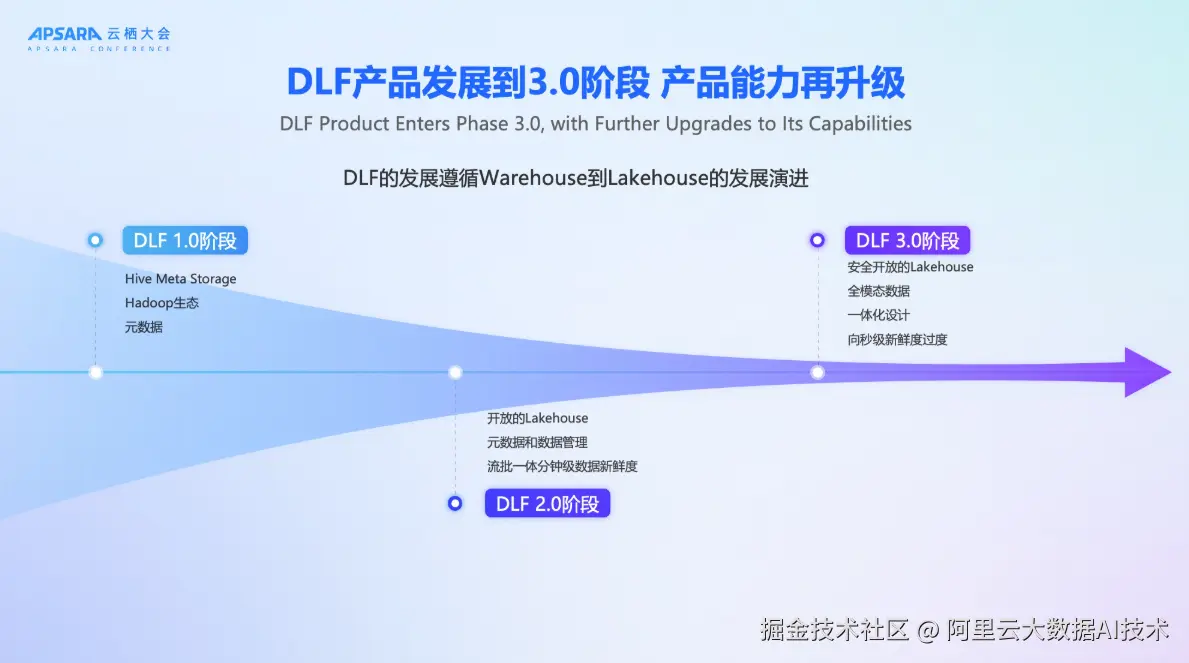
三、DLF 3.0核心能力发布:六大企业级服务全面升级
DLF3.0阶段保持开放的同时是一个安全的面向全模态数据管理的平台,同时我们基于一体化设计能够保证更好的安全、更好的开放性。
最上层是多引擎协同,通过用户的场景,选择不同的引擎。就像我们搭乐高积木,刚开始业务的需求是批计算场景,随着业务迭代需要升级到实时计算,采用DLF可以灵活无缝地从批计算升级实时计算。这套平台不仅可以做大规模的实时更新,也可以基于后期changeLog数据订阅做流式的加工,所有这些能力在这个平台上都可以以插件化式来进行集成和完成,平滑地满足用户和业务方要求的升级。同时DLF也对接了对应的OLAP引擎,可以通过OLAP分析引擎来快速查询DLF里面的数据,使用外表的查询也能够接近原来OLAP内表的性能。因此,流、批、OLAP分析可以同时构建在基于DLF这套产品架构上,这也是我们OpenLake解决方案的核心理念。
在DLF产品本身这层,有几个重磅升级
第一个升级就是DLF提供了managed storage service,因为我们洞察到用户在数据管理上遇到了非常大的挑战,所以我们做了全托管的manage方案,不管是数据的生命周期,还是冷热分层,还是存储优化,都能够做更好的支持。
第二个升级对于catalog service的管理,DLF升级到Omni Catalog,我们面向全模态可以提供Iceberg、paimon、lance、object table及file相关的管理,对用户来说有一个非常重要的变化在于原来的Lakehouse架构可能只能管Table,DLF架构下不仅仅可以管理Table数据,还可以管理全模态的数据,意味着tables和files都可以统一管理。paimon是实时湖仓最领先的一套方案,同时我们也兼顾了用户存量的系统架构需求,也可以支持Iceberg这样的湖仓架构,对于用户来说可以做到更灵活和多样的选择。
在这套架构基础上,DLF可以提供更好地面向Catalog,比如说可以基于Rest做更好的Catalog service,同时有权限、血缘以及监控和日志来帮助用户更好地搭建这样一套Lakehouse架构,帮助大家更好地升级到Lakehouse架构来面对Data+AI时代所带来的数据挑战。 
通过一系列重磅升级,DLF产品以统一开放catalog为基础,整体功能覆盖从数据入湖、湖表管与优化、湖表存储服务、企业级安全等丰富功能,让用户离线数据、实时数据、存量系统迁移平滑入湖,同时实现更高效的湖表存、管、优化,真正实现安全开放可靠的湖仓平台。 
1、Omni Catalog:一套目录统管Tables与Files
DLF 3.0发布Omni Catalog,这是其全模态能力的基石。Omni Catalog不仅支持Paimon、Iceberg、Lance等主流湖表格式,还首次引入对文件(如Parquet、视频、音频、PDF)的原生管理能力。
通过Table API与File API双接口,平台同时满足BI(Business Intelligence)与AI(Artificial Intelligence)两类工作负载,数据分析师可通过SQL查询结构化表,AI工程师可直接通过文件路径读取原始数据进行模型训练。更重要的是,DLF承诺完全兼容开源社区接口。用户可使用Paimon SDK、Iceberg SDK、Lance SDK等社区标准工具无缝接入DLF,彻底避免厂商锁定。同时,平台提供Rest API与Open API,便于管控台集成与自动化运维。 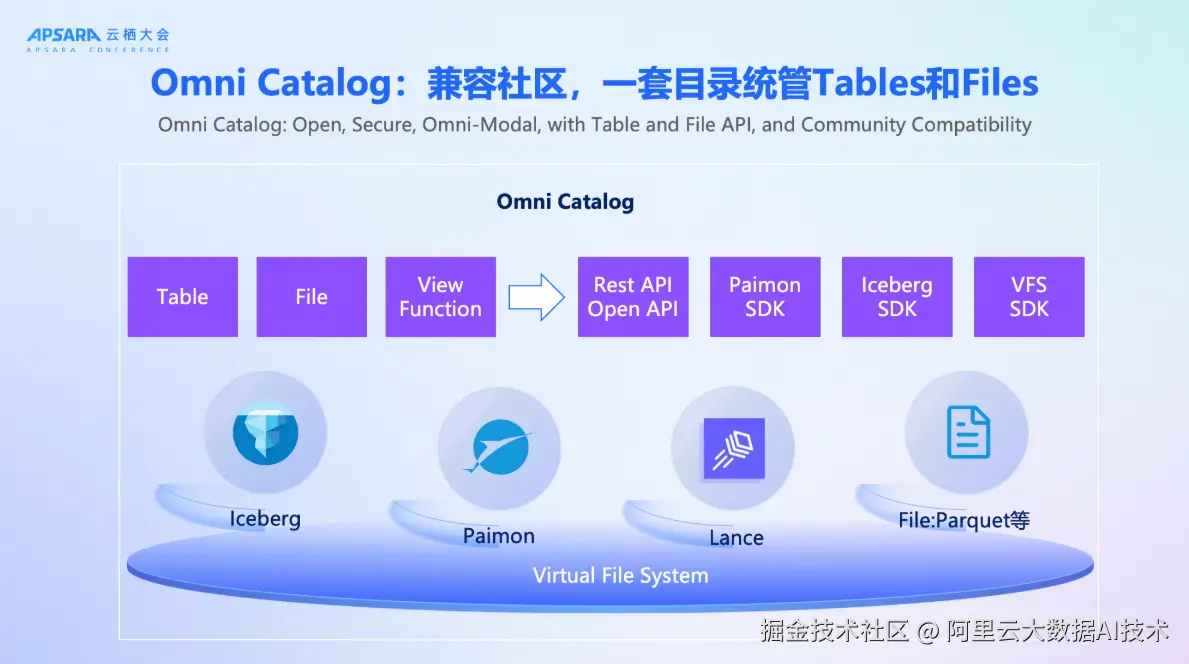
2、数据入湖:零代码流批摄取与存量迁移
为降低数据入湖门槛,DLF 3.0推出零代码数据摄取方案:
实时入湖:通过Flink CDC实现数据库Binlog的全实时捕获,支持Schema Evolution等; 离线入湖:借助Serverless Spark,按调度或事件驱动批量写入; 全模态入湖:支持视频、音频、文档等非结构化数据通过Dataworks数据集成、Spark、Flink等实时离线一体化数据写入或直接上传入湖; 存量迁移:提供产品化迁移工具,支持Hive、Hudi、Iceberg等旧系统迁移,并内置数据校验(Count/Sum/MD5/全文比对)确保一致性。 这套方案可以降低用户在数据摄取过程中的复杂度,帮助用户更低成本地将数据入湖,更低成本地将存量系统升级到Lakehouse架构。 
3、湖表管理与优化:智能Compaction与自适应分桶
DLF 3.0内置智能优化引擎,自动处理湖表维护中的复杂问题,这些能力大幅降低用户运维负担,让Lakehouse真正"开箱即用"。
- 自适应分桶:用户仅需指定分桶Key,平台根据数据量自动调整分桶数量与并发,实现读写性能最优;
- 智能Compaction:自动合并小文件,减少元数据压力,提升查询效率;
- 快照管理:基于策略自动清理过期快照与孤儿文件,释放存储空间;

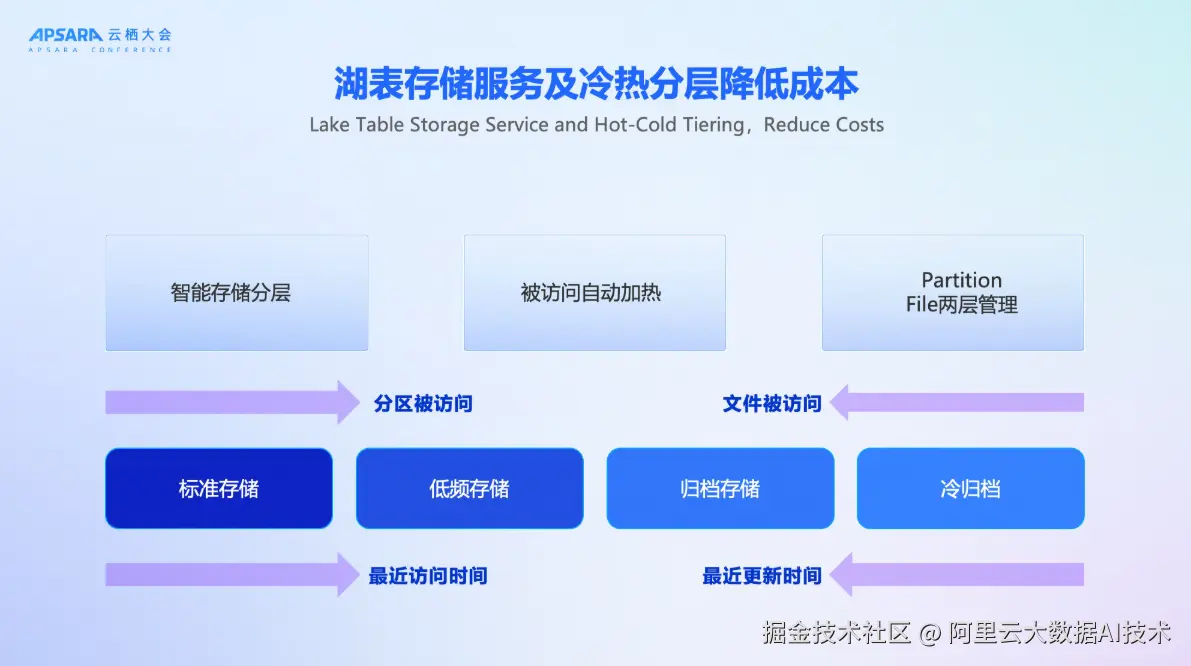
4、湖表存储服务:智能冷热分层降低成本
DLF 3.0推出Managed Storage Service,实现存储成本与性能的平衡。DLF基于智能的冷热分层来解决数据合理规划的问题,可以基于读取时间、更新时间的关键事件来决定分区该用什么样的存储介质来承载,同时也可以基于数据的读写行为来对数据做更合理的加速和预热,帮助用户在合理规划存储介质的过程中能够保持数据读写和管理的效率。
5、企业级安全:细粒度权限与跨引擎授权
原来自己搭建的Lakehouse平台下,数据权限管理是非常松散,甚至用AKSK这样一套方案是非常有挑战的,DLF提供细粒度的权限管理,可以做到粒级别的数据权限管理,基于table、DataBase、Catalog这些层面都可以做到更好的数据权限管理。基于这套数据权限管理也做了数据的共享,因为有跨团队的协同,所以提供了数据共享的能力来帮助大家更好地做数据协同。

6、性能与成本效率:全面跃升
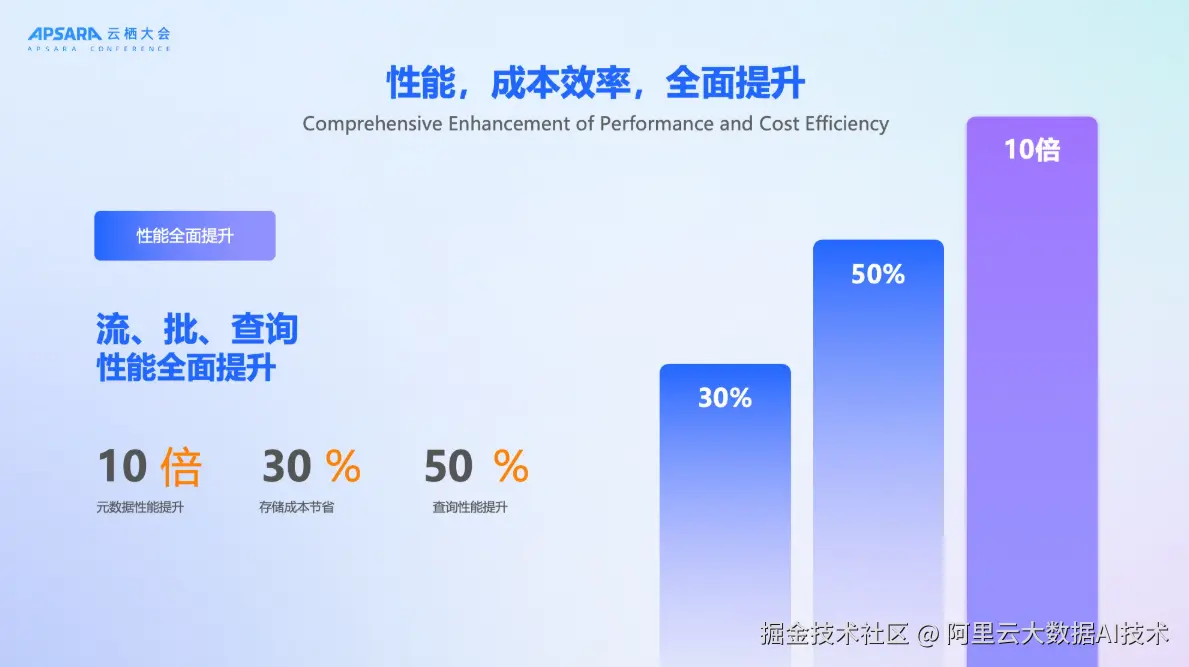
DLF 3.0在性能与成本上实现跨越式提升,元数据访问性能提升10倍以上,存储成本降低30%,查询性能提升50%。我们希望Lakehouse不再是"昂贵玩具",而是高性价比,具备普适性的数据基础设施。
四、典型应用场景
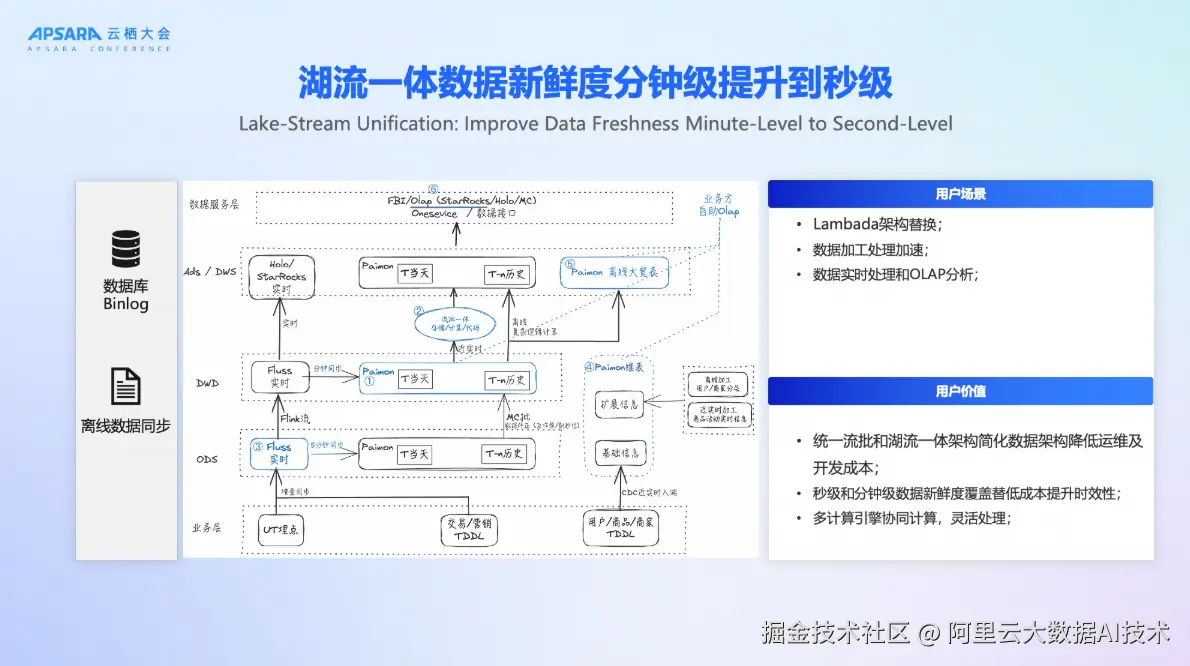
场景一:湖流一体-数据新鲜度从分钟级迈向秒级
基于去年发布的Streaming Lakehouse,DLF 3.0进一步引入Fluss实时存储引擎,构建"湖流一体"架构:
- 实时数据通过Flink写入Fluss,实现秒级延迟;
- 根据策略,数据可定时归档至Paimon表,供准实时、离线分析使用;
- 维表通过Paimon的Partial Update能力实现高效更新;
该方案成功替代Lambda架构,统一了湖流处理链路,降低开发与运维成本,同时满足秒级与分钟级的分析需求。
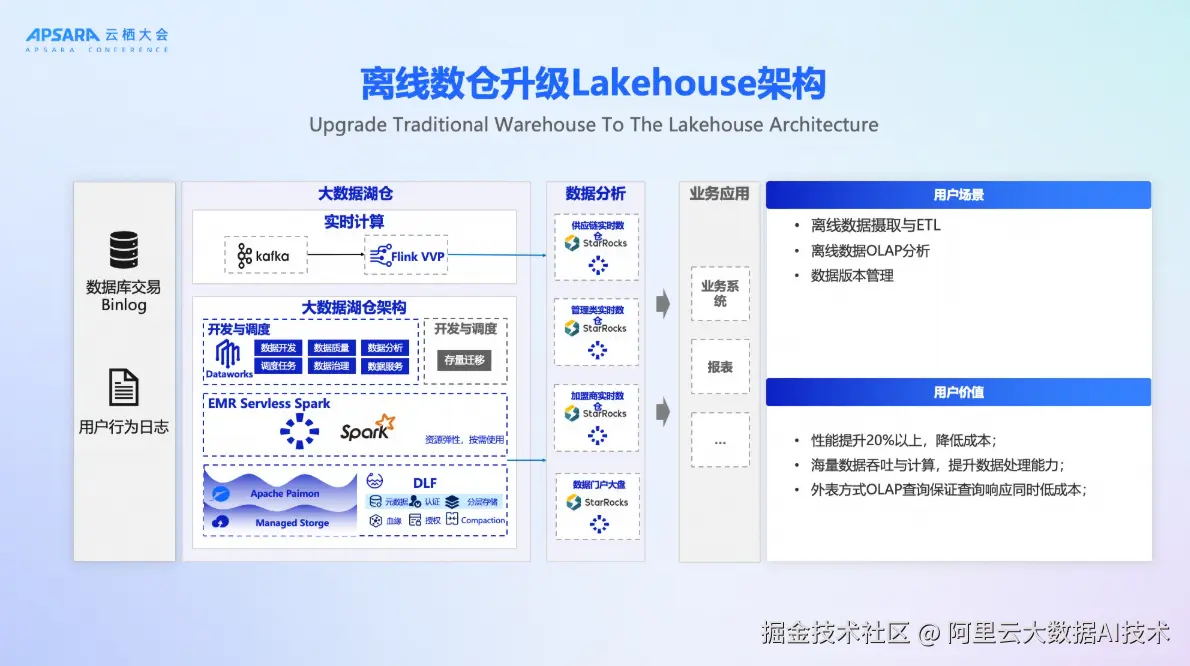
场景二:离线数仓升级Lakehouse架构
针对大量仍在使用Hadoop生态的企业,DLF提供无感迁移路径,整体平台性能提升20%以上。
- 通过迁移工具将Hive表迁移至DLF管理的Paimon湖表;
- 保留原有SQL接口,业务代码几乎无需修改;
- 迁移后可逐步引入实时能力,实现架构渐进式演进;
我们一位DLF的用户在完成迁移后激动地表示:"这是历史性时刻,我们终于告别了古早的Hadoop集群!"
场景三:全模态数据管理与检索
DLF 3.0最引人注目的创新在于全模态数据支持。随着AI时代的到来,大家听到更多的是非结构化数据该怎么管,非常多的视频、图片数据该如何管理,该如何圈选我的DataSet。通过DLF平台可以将非结构化数据,包括视频、音频、PDF进行管理,同时原来这套结构化数据也可以进一步接入。通过实时采集或者离线采集或者数据上传的方式接入到DLF平台,同时通过Lance这样一套底层能力来构建全模态数据的存储、管理以及后续承载embedding数据接入的能力。
基于这样的能力,对于用户来说就可以做到更好的全模态检索,包括图搜图、文搜图,可以更好地检索召回我们的数据。在全模态能力下DLF可以支持多主体的识别,通过多主体的识别,能够帮助后续流程做更好的基于对应主体做embedding,实现更精准的search场景。

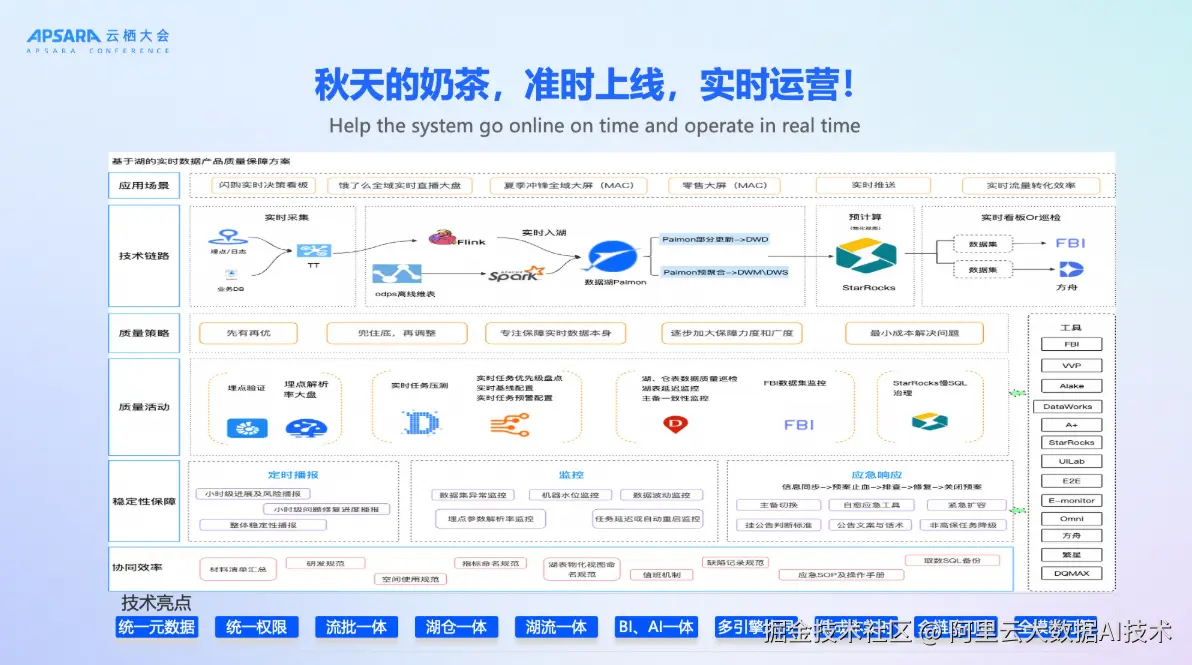
五、实战案例:助力淘宝闪购业务准时上线,实现全链路实时运营
在2025年秋季,阿里云DLF 3.0成功支撑了阿里巴巴集团闪购业务的准时上线。该业务对数据实时性要求极高,需在秒级内完成用户行为分析、库存预警与营销决策。因为在去年阿里巴巴集团就做了Alake项目,基于Lakehouse架构构建了整个平台,所以基于DLF可以让流批做更好地融合。面向用户场景会有BI场景、AI场景,这套架构可以很好地兼容两种场景的使用,灵活选择多种引擎应对业务方的需求。
DLF 3.0的发布,不仅是产品能力的升级,更是阿里云对Data+AI时代数据基础设施的深刻思考。全模态数据将成为未来企业核心资产,而Lakehouse必须进化为能承载这一资产的"智能湖"。基于阿里云OpenLake解决方案的理念,DLF 3.0不再只是一个数据湖管理工具,而是一个融合结构化与非结构化数据、打通BI与AI、兼顾性能与成本、开放且安全的新一代全模态湖仓管理平台。在AI浪潮席卷全球的今天,DLF 3.0为企业提供强有力的基础设施支撑,用数据驱动智能未来。
当前DLF3.0已经在阿里云上开放使用,如果期望了解更多详细内容,可以在阿里云官网搜索DLF。