注意:该项目只展示部分功能,如需了解,文末咨询即可。
本文目录
- [1 开发环境](#1 开发环境)
- [2 系统设计](#2 系统设计)
- [3 系统展示](#3 系统展示)
- [3.1 功能展示视频](#3.1 功能展示视频)
- [3.2 大屏页面](#3.2 大屏页面)
- [3.3 分析页面](#3.3 分析页面)
- [3.4 登录页面](#3.4 登录页面)
- [4 更多推荐](#4 更多推荐)
- [5 部分功能代码](#5 部分功能代码)
1 开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
随着人工智能技术的快速发展和广泛应用,AI对就业市场产生了深远影响,既创造了新兴职位机会,也带来了传统岗位的自动化替代风险。面对这一复杂的就业环境变化,亟需构建一个基于大数据技术的综合分析平台,通过对AI就业影响数据的深度挖掘和可视化展示,为政策制定者制定劳动力市场调控政策、教育机构调整人才培养方向、企业优化人力资源配置以及个人进行职业规划提供科学的数据支撑和决策依据,从而促进AI时代下就业市场的健康发展和人才的合理配置。
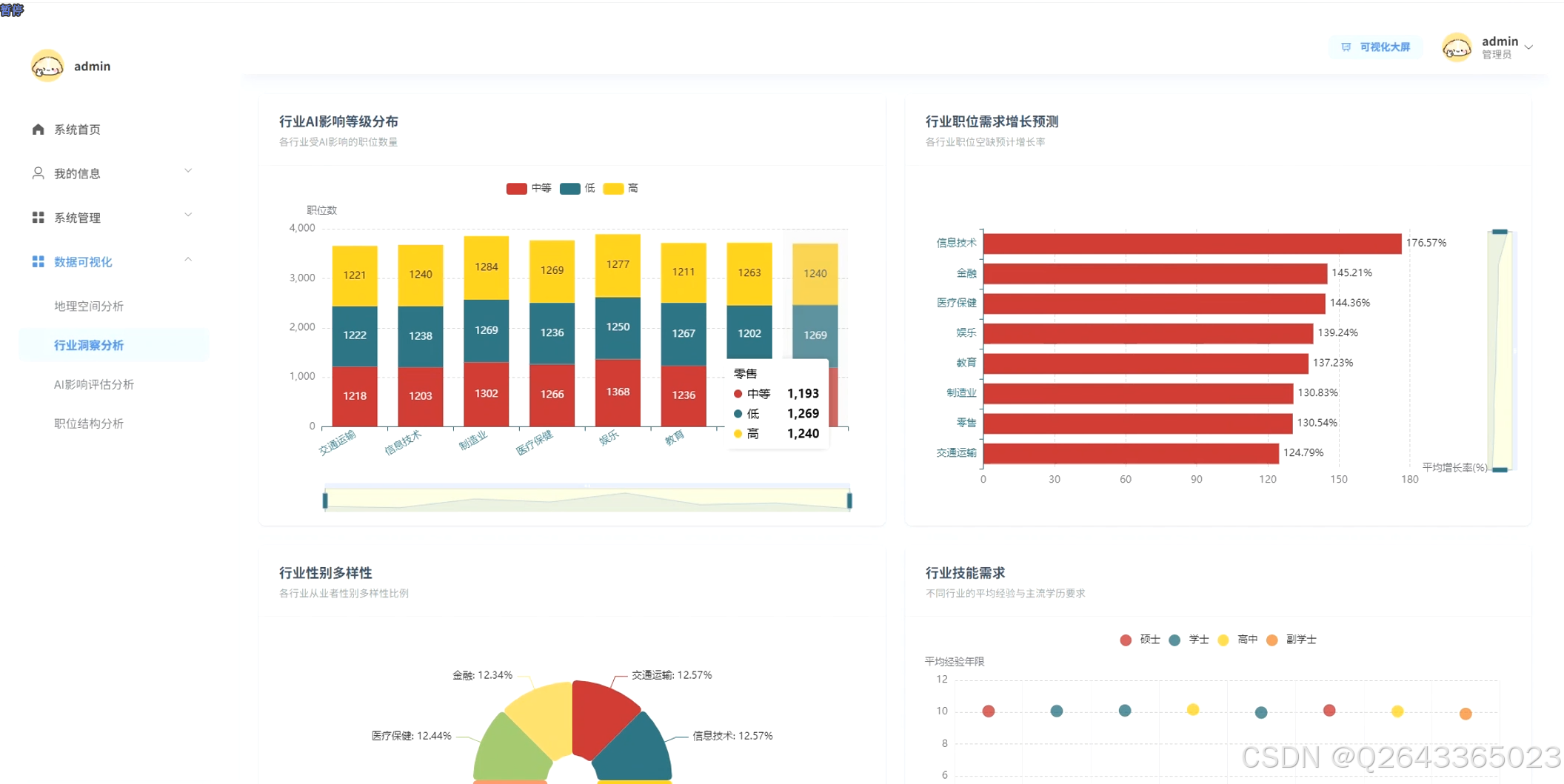
系统构建了五大核心功能模块:行业影响分析模块,深入分析不同行业AI影响等级分布、职位状态变化以及薪资风险关系,揭示AI技术在各行业的渗透程度和影响深度;地区就业分析模块,统计全球不同地区的职位数量分布、薪资水平差异和自动化风险等级,展现就业市场的地理分布特征;职位特征分析模块,围绕学历要求、经验需求与薪资的关联性,识别自动化风险最高的职位类型,并分析远程工作比例与性别多样性状况;发展趋势预测模块,通过对比2024年和2030年职位数量变化,预测各行业未来发展潜力,区分新兴职位与传统职位的特征差异;智能聚类分析模块,运用K-Means算法基于薪资、风险、经验等多维特征对职位进行聚类,识别"高薪高风险型"、"稳定成长型"等不同职位画像,为用户提供立体化的职业规划参考。
3 系统展示
3.1 功能展示视频
基于hadoop大数据的AI就业影响数据可视化分析系统源码 !!!请点击这里查看功能演示!!!
3.2 大屏页面
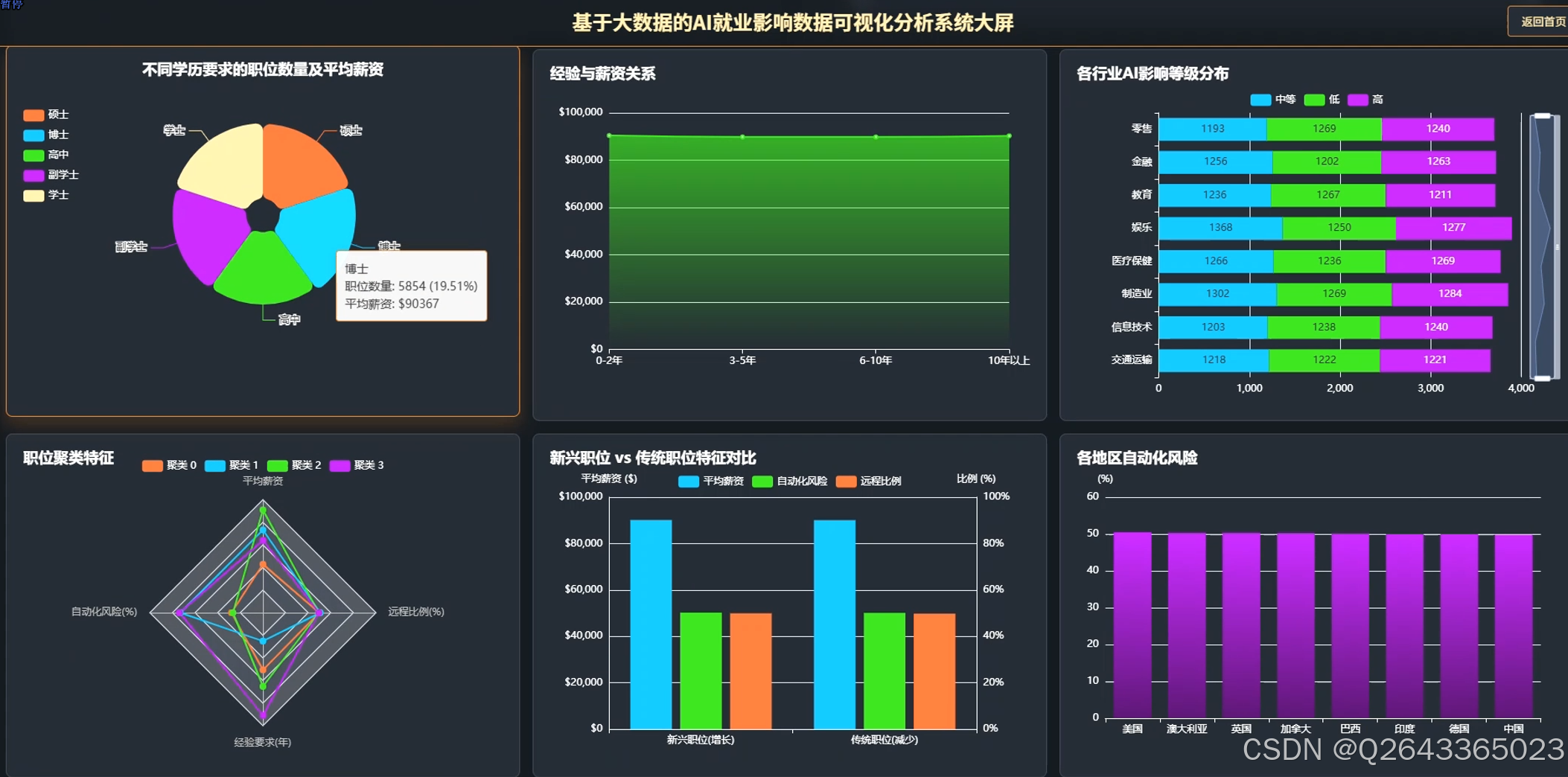
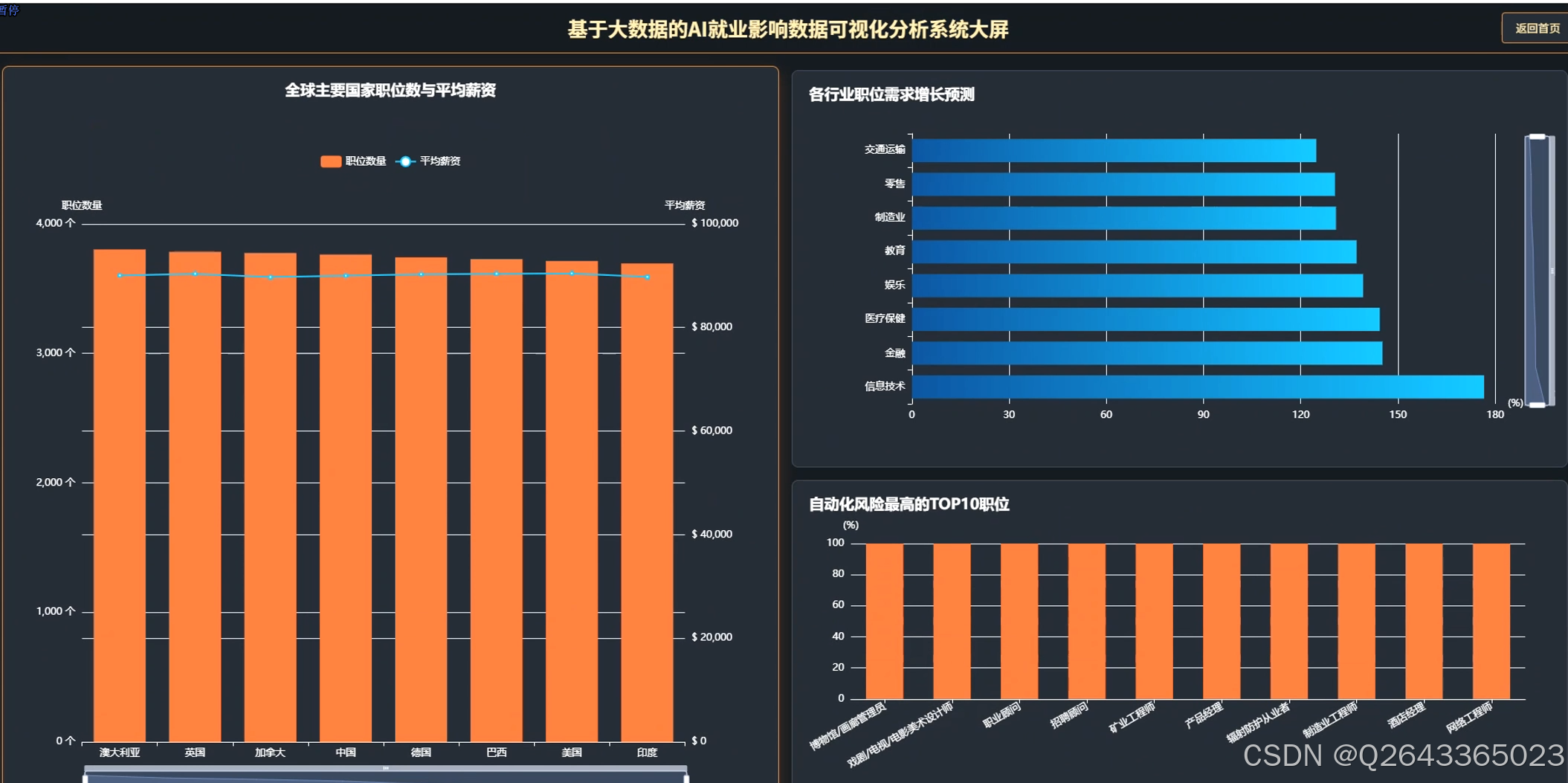
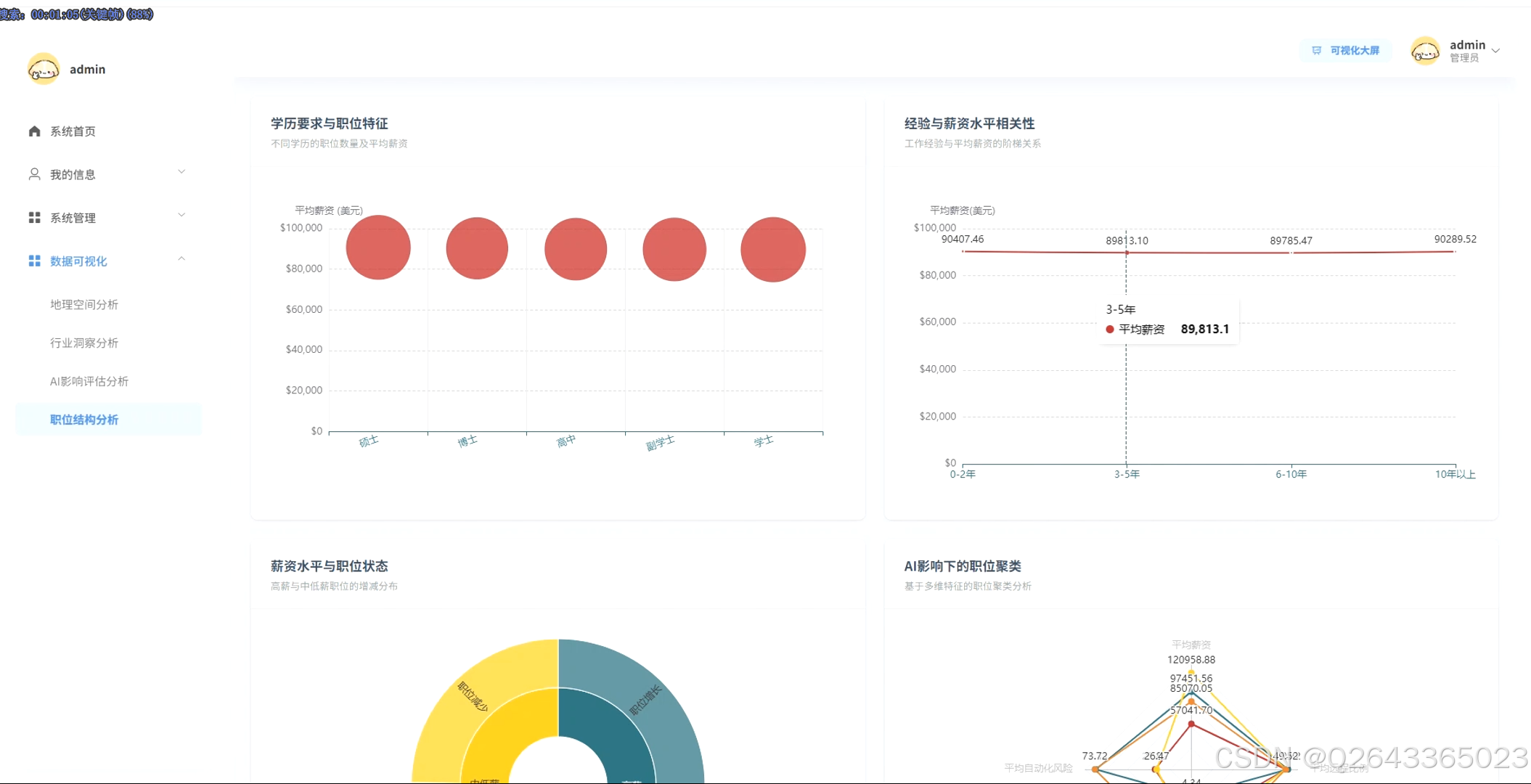
3.3 分析页面
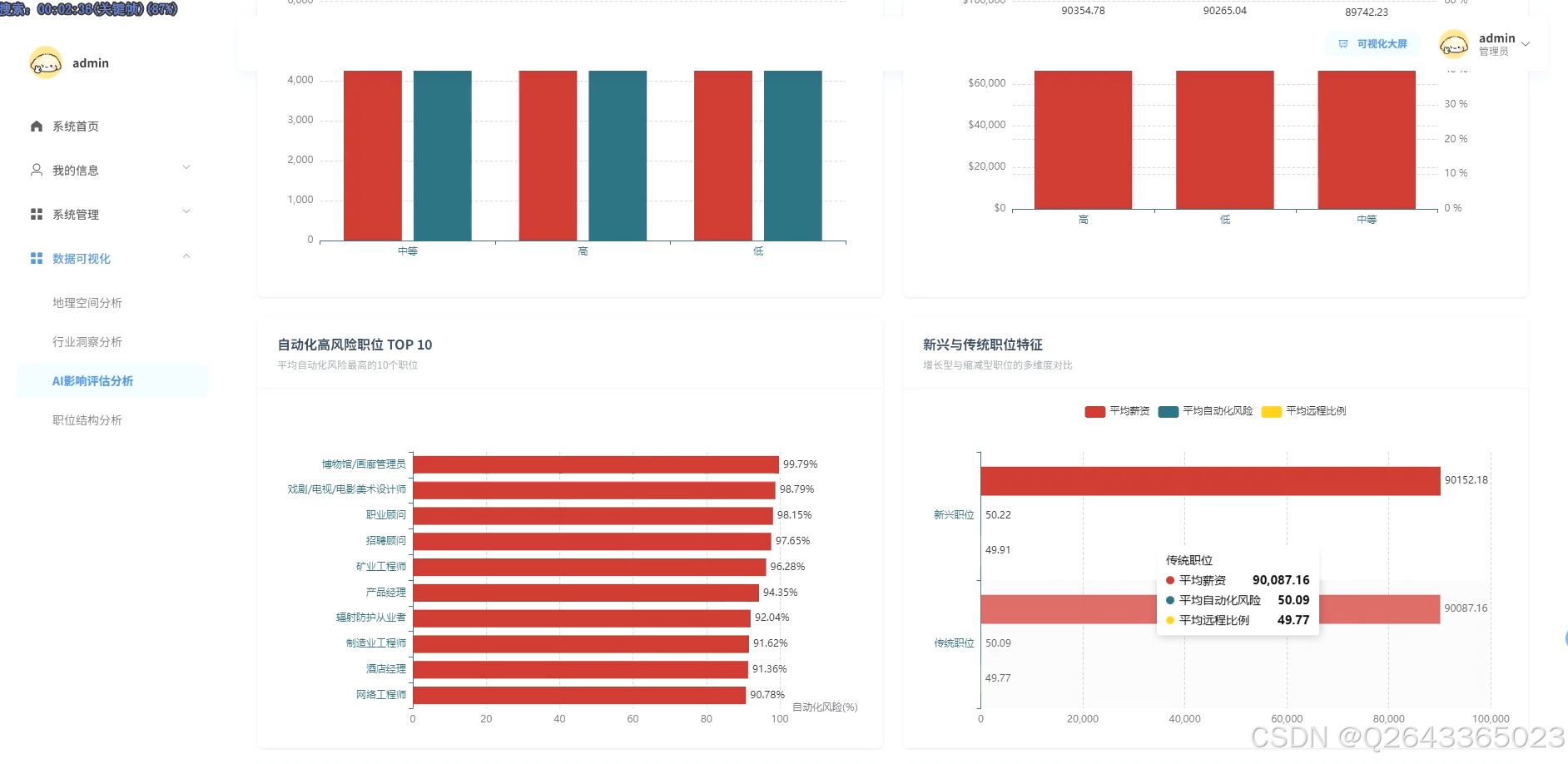
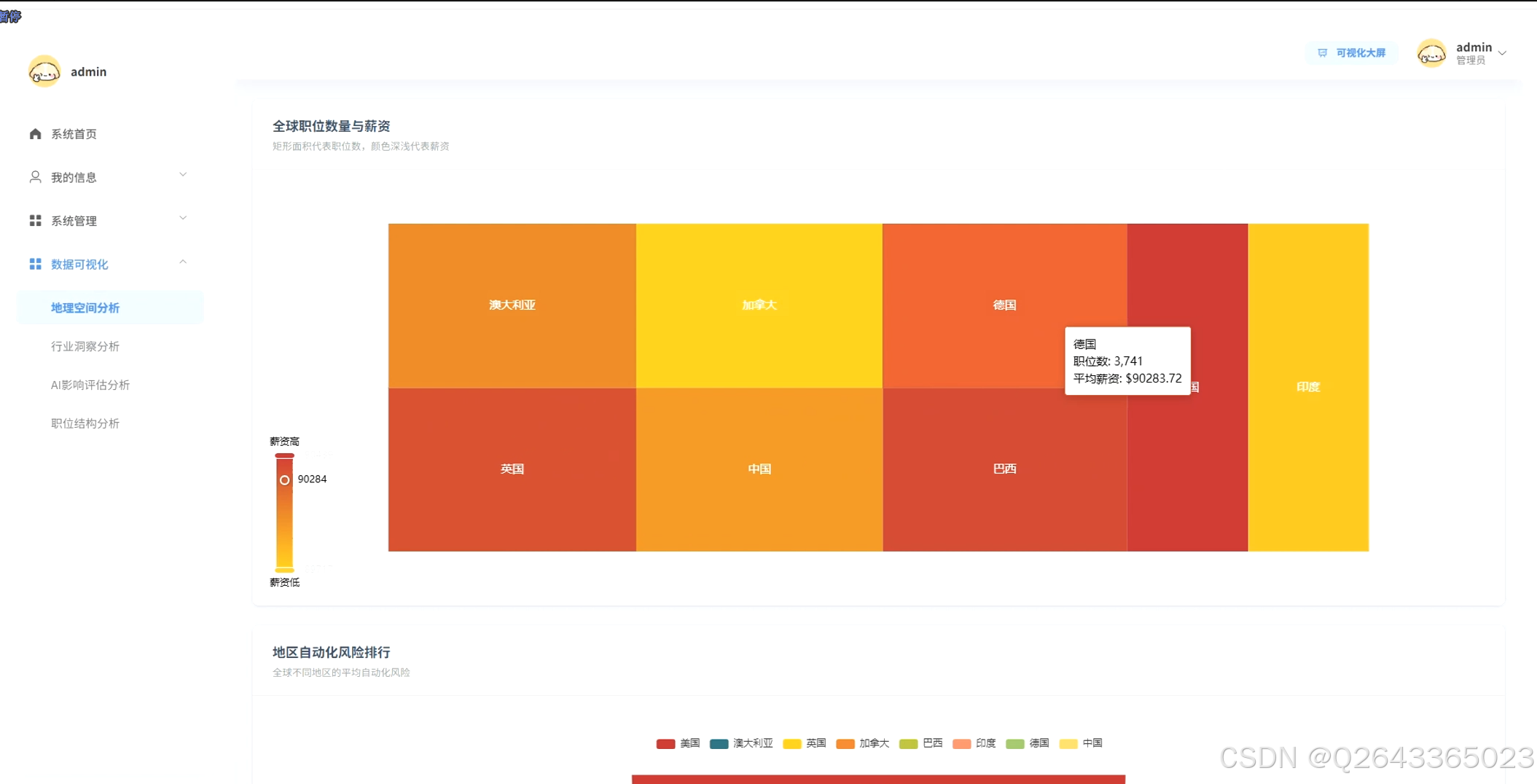
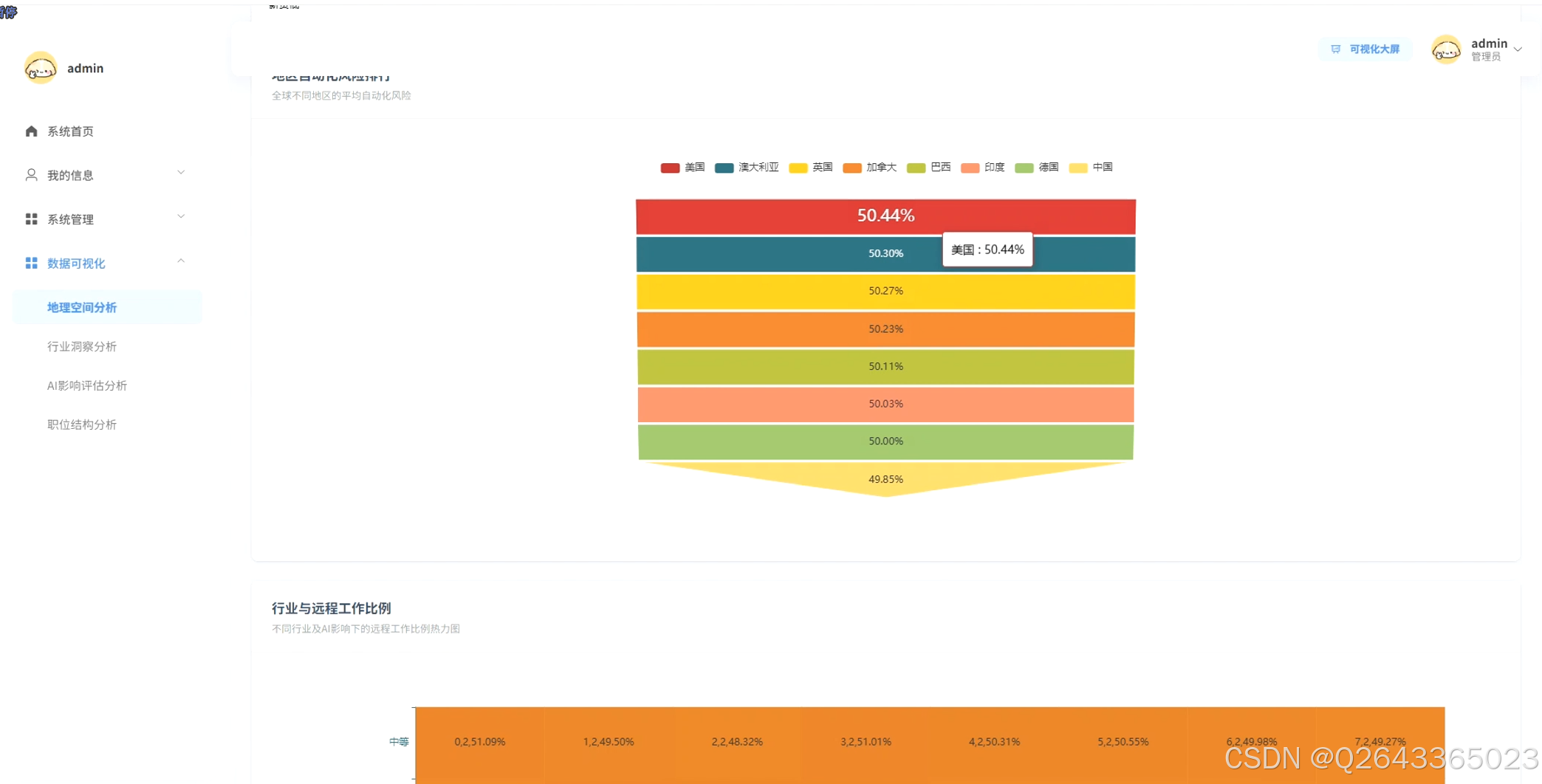
3.4 登录页面


4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
【避坑必看】26届计算机毕业设计选题雷区大全,这些毕设题目千万别选!选题雷区深度解析
基于Hadoop生态的汽车全生命周期数据分析与可视化平台-基于Python+Vue的二手车智能估价与市场分析系统
【有源码】基于Spark+Hadoop的全球企业估值分析与可视化系统-基于Python+Vue+机器学习的全球企业估值分布可视化系统
5 部分功能代码
python
try:
# 如果没有传入数据,则从预处理结果中读取
if df_data is None:
clean_data_path = os.path.join(self.result_path, "ai_job_data_preprocessed.csv")
if os.path.exists(clean_data_path):
df_data = pd.read_csv(clean_data_path, encoding='utf-8-sig')
else:
print("未找到预处理数据,请先执行数据预处理模块")
return None
# 转换为Spark DataFrame进行大数据分析
print("正在转换数据为Spark DataFrame...")
spark_df = self.spark.createDataFrame(df_data)
# 1. 不同行业AI影响等级分布统计
print("正在统计不同行业AI影响等级分布...")
# 使用Spark进行分布式聚合计算
industry_ai_distribution = spark_df.groupBy('industry_cn', 'ai_impact_level_cn') \
.agg(count('job_title').alias('job_count'),
avg('median_salary_usd').alias('avg_salary'),
avg('automation_risk_pct').alias('avg_automation_risk')) \
.orderBy('industry_cn', 'ai_impact_level_cn')
# 保留两位小数
industry_ai_distribution = industry_ai_distribution.select(
'industry_cn',
'ai_impact_level_cn',
'job_count',
spark_round('avg_salary', 2).alias('avg_salary'),
spark_round('avg_automation_risk', 2).alias('avg_automation_risk')
)
# 转换为Pandas DataFrame以便后续处理和保存
df_distribution = industry_ai_distribution.toPandas()
# 2. 计算各行业AI影响等级占比
print("正在计算各行业AI影响等级占比...")
df_distribution['industry_total'] = df_distribution.groupby('industry_cn')['job_count'].transform('sum')
df_distribution['impact_percentage'] = (df_distribution['job_count'] / df_distribution['industry_total'] * 100).round(2)
# 3. 生成行业AI渗透度综合评分
print("正在生成行业AI渗透度评分...")
# 基于高影响等级职位占比和平均自动化风险计算渗透度评分
high_impact_ratio = df_distribution[df_distribution['ai_impact_level_cn'] == '高'].groupby('industry_cn').agg({
'impact_percentage': 'first',
'avg_automation_risk': 'mean'
}).reset_index()
high_impact_ratio['penetration_score'] = (
high_impact_ratio['impact_percentage'] * 0.6 +
high_impact_ratio['avg_automation_risk'] * 0.4
).round(2)
high_impact_ratio = high_impact_ratio.rename(columns={
'impact_percentage': 'high_impact_ratio',
'avg_automation_risk': 'avg_risk_score'
})
# 4. 识别AI影响最显著的前5个行业
print("正在识别AI影响最显著的行业...")
top_ai_industries = high_impact_ratio.nlargest(5, 'penetration_score')
# 5. 输出分析结果到控制台
print("\n=== 行业AI影响等级分布分析结果 ===")
print("\n1. 各行业AI影响等级分布统计:")
print(df_distribution.to_string(index=False))
print(f"\n2. 行业AI渗透度评分排名:")
print(high_impact_ratio.sort_values('penetration_score', ascending=False).to_string(index=False))
print(f"\n3. AI影响最显著的前5个行业:")
for idx, row in top_ai_industries.iterrows():
print(f" {row['industry_cn']}: 渗透度评分 {row['penetration_score']}")
# 6. 生成详细的行业分析报告
print("正在生成详细分析报告...")
analysis_summary = []
for industry in df_distribution['industry_cn'].unique():
industry_data = df_distribution[df_distribution['industry_cn'] == industry]
total_jobs = industry_data['job_count'].sum()
high_impact_jobs = industry_data[industry_data['ai_impact_level_cn'] == '高']['job_count'].sum()
avg_salary = industry_data['avg_salary'].mean()
avg_risk = industry_data['avg_automation_risk'].mean()
summary_record = {
'industry_name': industry,
'total_job_count': total_jobs,
'high_impact_job_count': high_impact_jobs,
'high_impact_ratio': round((high_impact_jobs / total_jobs * 100), 2) if total_jobs > 0 else 0,
'industry_avg_salary': round(avg_salary, 2),
'industry_avg_risk': round(avg_risk, 2),
'ai_penetration_level': '高' if (high_impact_jobs / total_jobs) > 0.4 else '中' if (high_impact_jobs / total_jobs) > 0.2 else '低'
}
analysis_summary.append(summary_record)
df_summary = pd.DataFrame(analysis_summary)
# 7. 保存分析结果到CSV文件
print("正在保存分析结果...")
# 保存详细分布数据
distribution_file = os.path.join(self.result_path, "industry_ai_impact_distribution.csv")
df_distribution.to_csv(distribution_file, index=False, encoding='utf-8-sig')
# 保存行业综合分析报告
summary_file = os.path.join(self.result_path, "industry_ai_impact_summary.csv")
df_summary.to_csv(summary_file, index=False, encoding='utf-8-sig')
# 保存渗透度评分
penetration_file = os.path.join(self.result_path, "industry_ai_penetration_score.csv")
high_impact_ratio.to_csv(penetration_file, index=False, encoding='utf-8-sig')
# 8. 保存结果到MySQL数据库
self._save_to_mysql(df_distribution, 'industry_ai_distribution')
self._save_to_mysql(df_summary, 'industry_ai_summary')
print("行业AI影响等级分布分析模块执行完成!")
print(f"结果文件已保存到: {self.result_path}")
return {
'distribution_data': df_distribution,
'summary_data': df_summary,
'penetration_scores': high_impact_ratio
}源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流 ↓↓↓↓↓