基于正倒排索引的boost搜索引擎
cpp-httplib库
cpp-httplib 库介绍
cpp-httplib 是一个轻量级的 C++ HTTP 客户端 / 服务器库,由日本开发者 yhirose 开发。它的特点是:
- 单文件设计(仅需包含 httplib.h 即可使用)
- 支持 HTTP 1.1
- 同时提供客户端和服务器功能
- 跨平台(Windows、Linux、macOS 等)
- 无需额外依赖(仅需 C++11 及以上标准)
- 支持 SSL/TLS(需配合 OpenSSL)
常用功能与函数
1. 服务器相关
创建服务器
httplib::Server svr;
注册路由处理函数
// GET 请求处理
svr.Get("/hello", [](const httplib::Request& req, httplib::Response& res) {
res.set_content("Hello World!", "text/plain");
});
// POST 请求处理
svr.Post("/submit", [](const httplib::Request& req, httplib::Response& res) {
// 处理表单数据 req.body
res.set_content("Received!", "text/plain");
});
启动服务器
// 监听 0.0.0.0:8080
if (svr.listen("0.0.0.0", 8080)) {
// 服务器启动成功
}
Request 类主要成员
- method: 请求方法(GET/POST 等)
- path: 请求路径
- body: 请求体内容
- headers: 请求头集合
- params: URL 查询参数
- get_param(key): 获取查询参数
Response 类主要成员
- status: 状态码(200, 404 等)
- body: 响应体内容
- headers: 响应头集合
- set_content(content, content_type): 设置响应内容和类型
- set_header(name, value): 设置响应头
2. 客户端相关
创建客户端
httplib::Client cli("http://example.com");
发送 GET 请求
auto res = cli.Get("/api/data");
if (res && res->status == 200) {
// 处理响应 res->body
}
发送 POST 请求
httplib::Params params;
params.emplace("name", "test");
params.emplace("value", "123");
auto res = cli.Post("/api/submit", params);
发送带请求体的 POST
std::string json_data = R"({"key": "value"})";
auto res = cli.Post("/api/json", json_data, "application/json");
下载与使用
下载路径
GitHub 仓库:https://github.com/yhirose/cpp-httplib
直接下载头文件:https://raw.githubusercontent.com/yhirose/cpp-httplib/master/httplib.h
使用方法
1.下载 httplib.h 文件
2.在项目中包含该文件:#include "httplib.h"
3.编译时需指定 C++11 及以上标准(如 g++ -std=c++11 main.cpp)
4.若使用 SSL 功能,需定义 CPPHTTPLIB_OPENSSL_SUPPORT 并链接 OpenSSL 库
5.编译器版本低可能会报错,升级一下编译器即可
简单示例
下面是一个完整的服务器示例:
#include "httplib.h"
#include <iostream>
int main() {
httplib::Server svr;
// 处理根路径请求
svr.Get("/", [](const httplib::Request& req, httplib::Response& res) {
res.set_content("<h1>Hello World!</h1>", "text/html");
});
// 处理带参数的请求
svr.Get("/greet", [](const httplib::Request& req, httplib::Response& res) {
auto name = req.get_param_value("name");
if (name.empty()) {
res.status = 400;
res.set_content("Name parameter is required", "text/plain");
} else {
res.set_content("Hello, " + name + "!", "text/plain");
}
});
std::cout << "Server running on http://localhost:8080" << std::endl;
svr.listen("localhost", 8080);
return 0;
}
这个库非常适合快速开发小型 HTTP 服务或客户端,由于其轻量性和易用性,在 C++ 社区中非常受欢迎。
网页模块
仿照其它成熟搜索页面
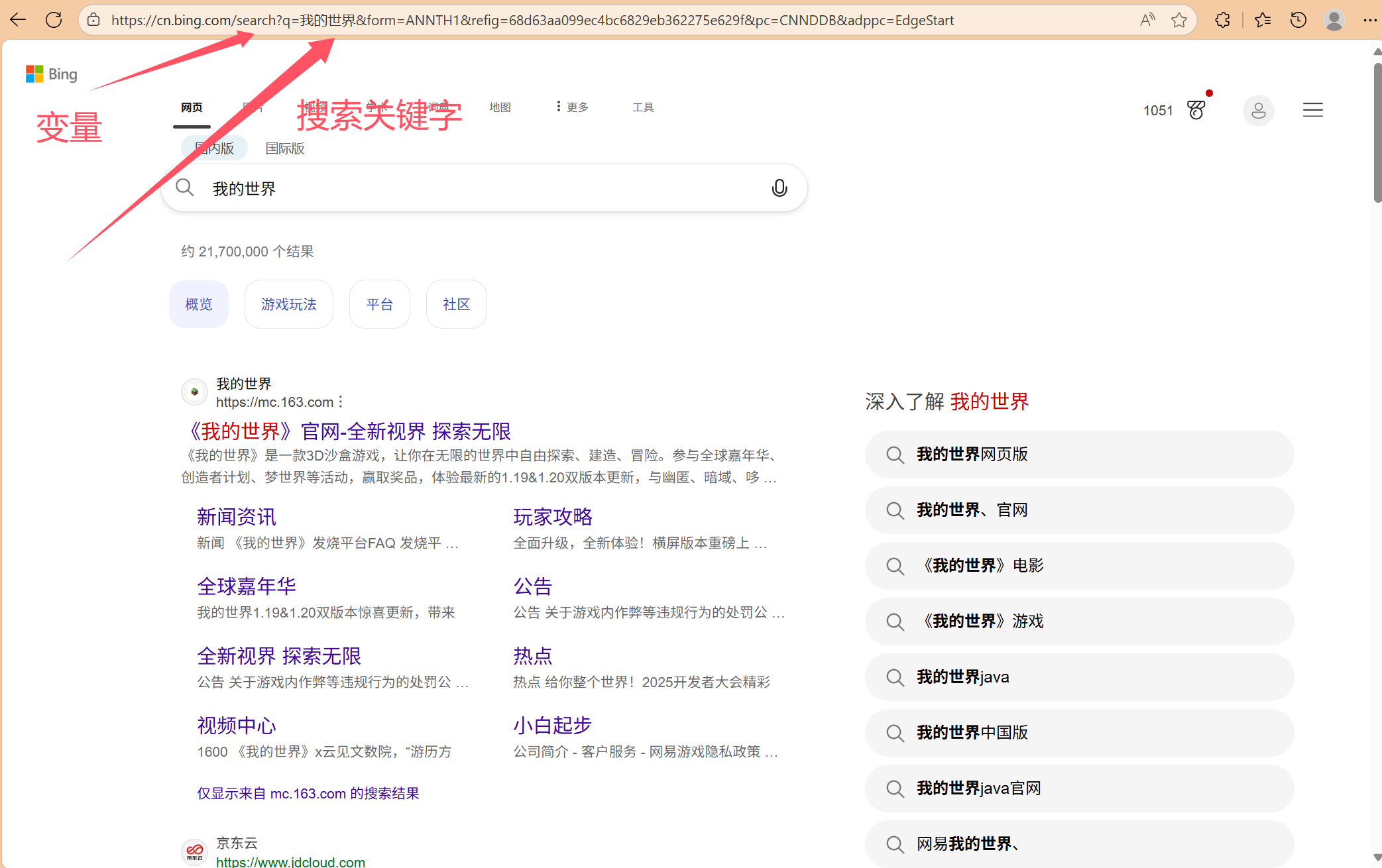
这是一个大公司建立的成熟的搜索页面,我们写的可以仿照着来。

**经过搜索之后,网页地址上会带上搜索的关键词,从而到数据库内部或者其它建立好的搜索模块中查找,在通过网页映射出来。
**
编写主程序入口
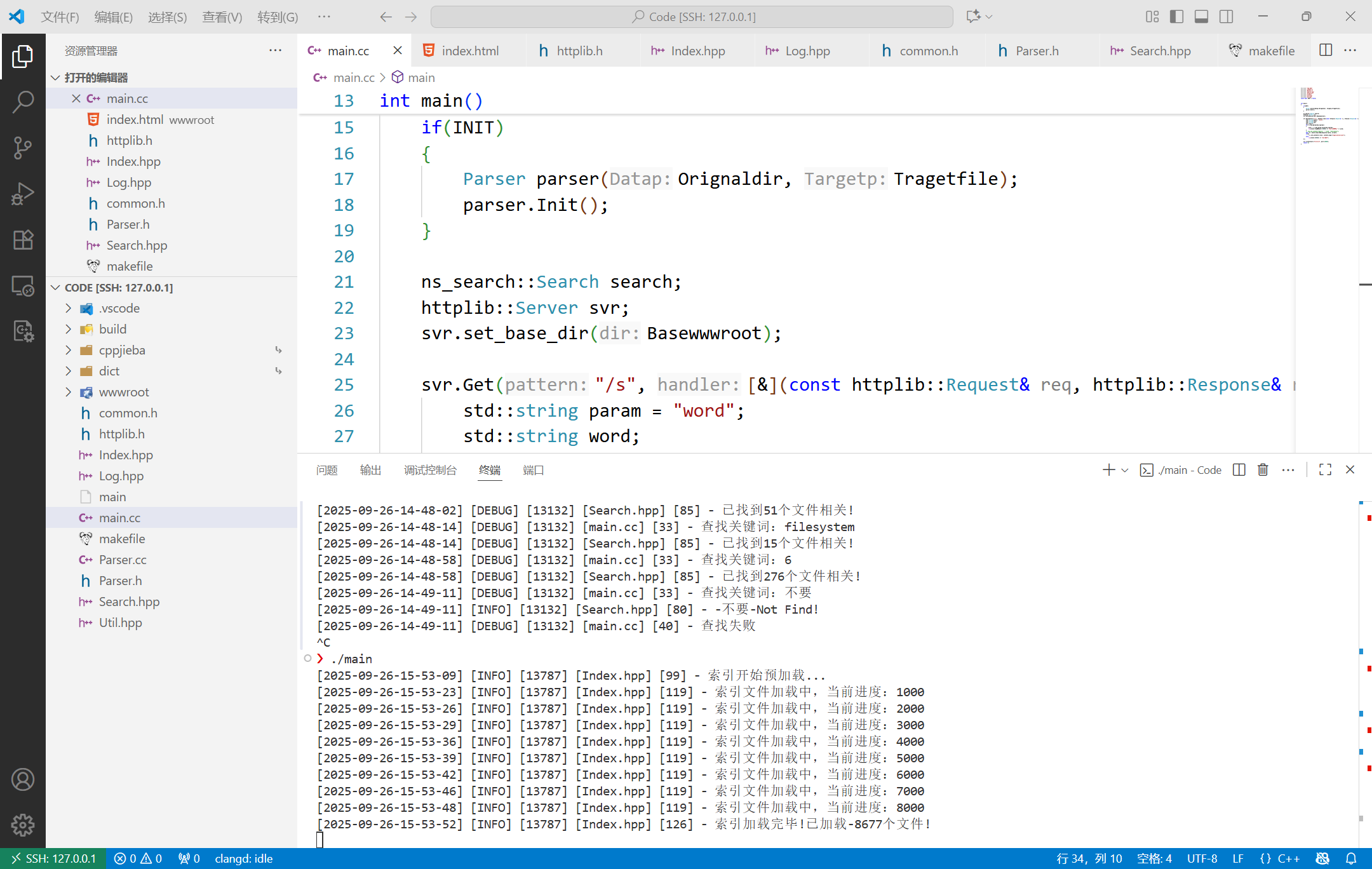
**当外部通过网页访问建立好的端口的时候,搜索模块会初始化一次,文档是已经建立好的,先绑定主网页html的路径,然后注册Get方法,网页访问/s的时候实用?word=来带参数,从而出发搜索模块的查找,然后把结果json串返回给浏览器。启动后绑定host和端口号,则开始运行。
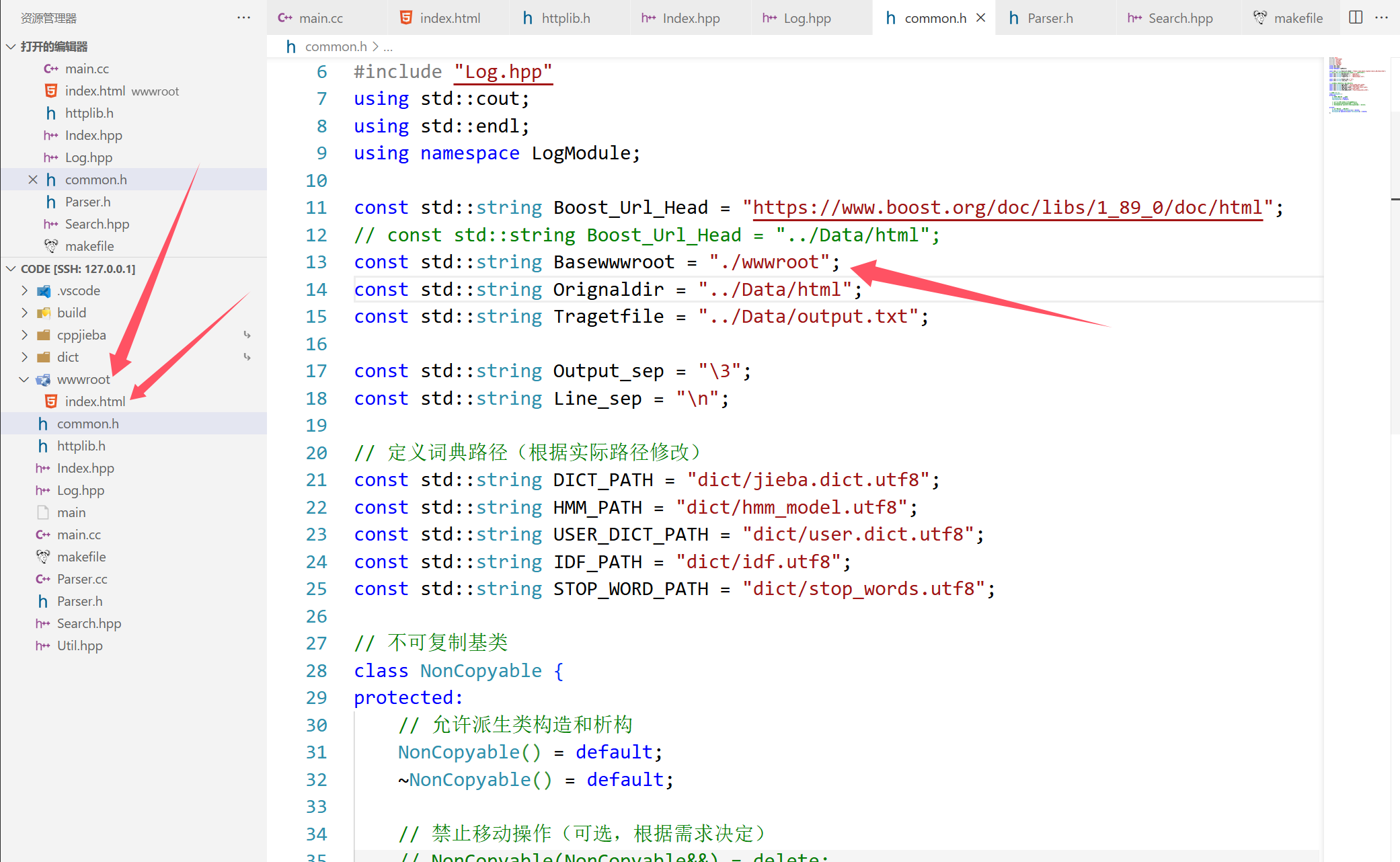
#include "Log.hpp"
#include "common.h"
#include "Parser.h"
#include "Search.hpp"
#include "httplib.h"
#include <cstdio>
#include <cstring>
#include <string>
const bool INIT = false;
int main()
{
if(INIT)
{
Parser parser(Orignaldir, Tragetfile);
parser.Init();
}
ns_search::Search search;
httplib::Server svr;
svr.set_base_dir(Basewwwroot);
svr.Get("/s", [&](const httplib::Request& req, httplib::Response& rep){
std::string param = "word";
std::string word;
std::string out;
out.clear();
if(req.has_param(param))
{
word = req.get_param_value(param);
Log(LogModule::DEBUG) << "查找关键词:" << word;
}
// rep.set_content("Search: " + word, "text/plain");
bool b = search.SearchBy(word, out);
if(b)
rep.set_content(out, "application/json");
else
Log(DEBUG) << "查找失败";
});
svr.listen("0.0.0.0", 8080);
return 0;
}
编写网页
编写网页是从一个大概的框架开始先写主要部分,再用css美化,然后注册相关函数。
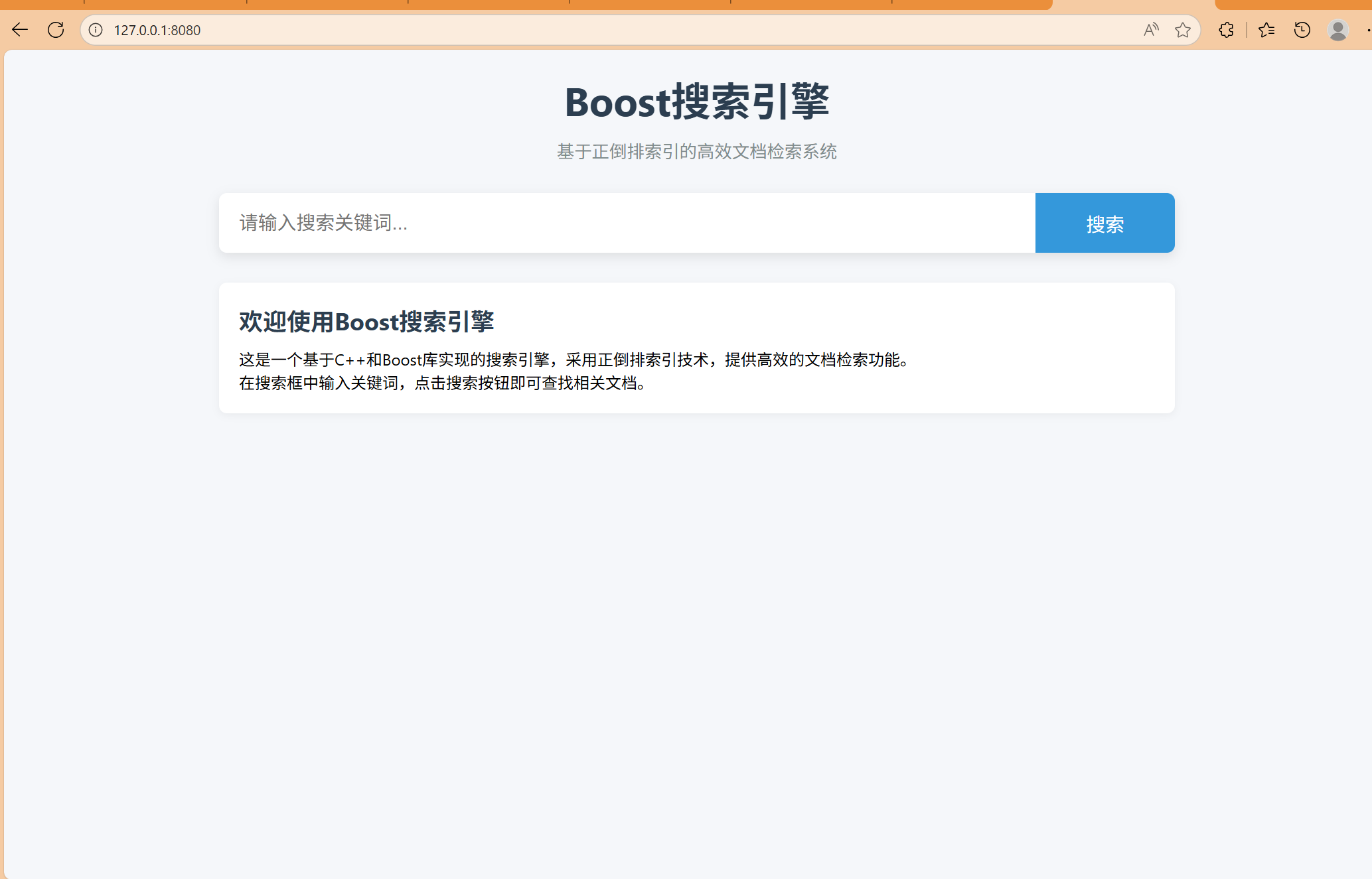
**```text
Boost搜索引擎
欢迎使用Boost搜索引擎
这是一个基于C++和Boost库实现的搜索引擎,采用正倒排索引技术,提供高效的文档检索功能。
在搜索框中输入关键词,点击搜索按钮即可查找相关文档。
```
## 完整代码
### common.h
```cpp
#pragma once
#include
#include
#include
#include
#include "Log.hpp"
using std::cout;
using std::endl;
using namespace LogModule;
const std::string Boost_Url_Head = "https://www.boost.org/doc/libs/1_89_0/doc/html";
// const std::string Boost_Url_Head = "../Data/html";
const std::string Basewwwroot = "./wwwroot";
const std::string Orignaldir = "../Data/html";
const std::string Tragetfile = "../Data/output.txt";
const std::string Output_sep = "\3";
const std::string Line_sep = "\n";
// 定义词典路径(根据实际路径修改)
const std::string DICT_PATH = "dict/jieba.dict.utf8";
const std::string HMM_PATH = "dict/hmm_model.utf8";
const std::string USER_DICT_PATH = "dict/user.dict.utf8";
const std::string IDF_PATH = "dict/idf.utf8";
const std::string STOP_WORD_PATH = "dict/stop_words.utf8";
// 不可复制基类
class NonCopyable {
protected:
// 允许派生类构造和析构
NonCopyable() = default;
~NonCopyable() = default;
// 禁止移动操作(可选,根据需求决定)
// NonCopyable(NonCopyable&&) = delete;
// NonCopyable& operator=(NonCopyable&&) = delete;
private:
// 禁止拷贝构造和拷贝赋值
NonCopyable(const NonCopyable&) = delete;
NonCopyable& operator=(const NonCopyable&) = delete;
};
```
### Index.hpp
```cpp
#pragma once
#include "Log.hpp"
#include "Util.hpp"
#include "common.h"
#include
#include
#include
#include
#include
#include
#include
#include
#include
namespace ns_index
{
//正排索引
typedef struct ForwordElem
{
std::string title_;
std::string content_;
std::string url_;
size_t doc_id_ = 0;
void Set(std::string title, std::string content, std::string url, size_t doc_id)
{
title_ = title;
content_ = content;
url_ = url;
doc_id_ = doc_id;
}
}Forword_t;
typedef struct InvertedElem
{
size_t doc_id_ = 0;
std::string word_;
size_t weight_ = 0;
void Set(size_t doc_id, std::string word, size_t weight)
{
doc_id_ = doc_id;
word_ = word;
weight_ = weight;
}
}Inverted_t;
typedef std::vector InvertedList;
class Index : public NonCopyable
{
private:
Index() = default;
public:
static Index* GetInstance()
{
static Index index;
return &index;
}
public:
Forword_t* QueryById(size_t id)
{
if(id < 0 || id >= Forword_Index_.size())
{
Log(LogModule::DEBUG) << "id invalid!";
return nullptr;
}
return &Forword_Index_[id];
}
InvertedList* QueryByWord(std::string word)
{
auto it = Inverted_Index_.find(word);
if(it == Inverted_Index_.end())
{
//Log(LogModule::DEBUG) << word << " find fail!";
return nullptr;
}
return &it->second;
}
size_t count = 0;
bool BulidIndex()
{
if(isInit_)
return false;
size_t estimated_doc = 10000;
size_t estimeted_words = 100000;
Forword_Index_.reserve(estimated_doc);
Inverted_Index_.reserve(estimeted_words);
std::ifstream in(Tragetfile, std::ios::binary | std::ios::in);
if(!in.is_open())
{
Log(LogModule::ERROR) << "Targetfile open fail!BulidIndex fail!";
return false;
}
Log(LogModule::INFO) << "索引开始预加载...";
std::string singlefile;
while (std::getline(in, singlefile))
{
bool b = BuildForwordIndex(singlefile);
if(!b)
{
Log(LogModule::DEBUG) << "Build Forword Index Error!";
continue;
}
b = BuildInvertedIndex(Forword_Index_.size() - 1);
if(!b)
{
Log(LogModule::DEBUG) << "Build Inverted Index Error!";
continue;
}
count++;
if(count % 1000 == 0)
{
Log(LogModule::INFO) << "索引文件加载中,当前进度:" << count;
//debug
//break;
}
}
in.close();
isInit_ = true;
Log(LogModule::INFO) << "索引加载完毕!已加载-" << count << "个文件!";
return true;
}
~Index() = default;
private:
typedef struct DocCount
{
size_t title_cnt_ = 0;
size_t content_cnt_ = 0;
}DocCount_t;
bool BuildForwordIndex(std::string& singlefile)
{
sepfile.clear();
bool b = ns_util::JiebaUtile::CutDoc(singlefile, sepfile);
if(!b)
return false;
// if(count == 764)
// {
// Log(LogModule::DEBUG) << "Index Url: " << sepfile[2];
// }
if(sepfile.size() != 3)
{
Log(LogModule::DEBUG) << "Segmentation fail!";
return false;
}
Forword_t ft;
ft.Set(std::move(sepfile[0]), std::move(sepfile[1])
, std::move(sepfile[2]), Forword_Index_.size());
// if(count == 764)
// {
// Log(LogModule::DEBUG) << "Index Url: " << ft.url_;
// }
Forword_Index_.push_back(std::move(ft));
return true;
}
bool BuildInvertedIndex(size_t findex)
{
Forword_t ft = Forword_Index_[findex];
std::unordered_map map_s;
titlesegmentation.clear();
ns_util::JiebaUtile::CutPhrase(ft.title_, titlesegmentation);
for(auto& s : titlesegmentation)
{
boost::to_lower(s);
map_s[s].title_cnt_++;
}
contentsegmentation.clear();
ns_util::JiebaUtile::CutPhrase(ft.content_, contentsegmentation);
for(auto& s : contentsegmentation)
{
boost::to_lower(s);
map_s[s].content_cnt_++;
//cout << s << "--";
// if(strcmp(s.c_str(), "people") == 0)
// {
// Log(LogModule::DEBUG) << "意外的people!";
// cout << ft.content_ << "------------end!";
// sleep(100);
// }
}
const int X = 10;
const int Y = 1;
for(auto& p : map_s)
{
Inverted_t it;
it.Set(findex, p.first
, p.second.title_cnt_ * X + p.second.content_cnt_ * Y);
InvertedList& list = Inverted_Index_[p.first];
list.push_back(std::move(it));
}
return true;
}
private:
std::vector Forword_Index_;
std::unordered_map Inverted_Index_;
bool isInit_ = false;
//内存复用,优化时间
std::vector sepfile;
std::vector titlesegmentation;
std::vector contentsegmentation;
};
};
```
### Log.hpp
```cpp
#ifndef __LOG_HPP__
#define __LOG_HPP__
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
namespace LogModule
{
const std::string default_path = "./log/";
const std::string default_file = "log.txt";
enum LogLevel
{
DEBUG,
INFO,
WARNING,
ERROR,
FATAL
};
static std::string LogLevelToString(LogLevel level)
{
switch (level)
{
case DEBUG:
return "DEBUG";
case INFO:
return "INFO";
case WARNING:
return "WARNING";
case ERROR:
return "ERROR";
case FATAL:
return "FATAL";
default:
return "UNKNOWN";
}
}
static std::string GetCurrentTime()
{
std::time_t time = std::time(nullptr);
struct tm stm;
localtime_r(&time, &stm);
char buff[128];
snprintf(buff, sizeof(buff), "%4d-%02d-%02d-%02d-%02d-%02d",
stm.tm_year + 1900,
stm.tm_mon + 1,
stm.tm_mday,
stm.tm_hour,
stm.tm_min,
stm.tm_sec);
return buff;
}
class Logstrategy
{
public:
virtual ~Logstrategy() = default;
virtual void syncLog(std::string &message) = 0;
};
class ConsoleLogstrategy : public Logstrategy
{
public:
void syncLog(std::string &message) override
{
std::cerr << message << std::endl;
}
~ConsoleLogstrategy() override
{
}
};
class FileLogstrategy : public Logstrategy
{
public:
FileLogstrategy(std::string filepath = default_path, std::string filename = default_file)
{
_mutex.lock();
_filepath = filepath;
_filename = filename;
if (std::filesystem::exists(filepath)) // 检测目录是否存在,存在则返回
{
_mutex.unlock();
return;
}
try
{
// 不存在则递归创建(复数)目录
std::filesystem::create_directories(filepath);
}
catch (const std::filesystem::filesystem_error &e)
{
// 捕获异常并打印
std::cerr << e.what() << '\n';
}
_mutex.unlock();
}
void syncLog(std::string &message) override
{
_mutex.lock();
std::string path =
_filepath.back() == '/' ? _filepath + _filename : _filepath + "/" + _filename;
std::ofstream out(path, std::ios::app);
if (!out.is_open())
{
_mutex.unlock();
std::cerr << "file open fail!" << '\n';
return;
}
out << message << '\n';
_mutex.unlock();
out.close();
}
~FileLogstrategy()
{
}
private:
std::string _filepath;
std::string _filename;
std::mutex _mutex;
};
class Log
{
public:
Log()
{
_logstrategy = std::make_unique();
}
void useconsolestrategy()
{
_logstrategy = std::make_unique();
printf("转换控制台策略!\n");
}
void usefilestrategy()
{
_logstrategy = std::make_unique();
printf("转换文件策略!\n");
}
class LogMessage
{
public:
LogMessage(LogLevel level, std::string file, int line, Log &log)
: _loglevel(level)
, _time(GetCurrentTime())
, _file(file), _pid(getpid())
, _line(line),
_log(log)
{
std::stringstream ss;
ss << "[" << _time << "] "
<< "[" << LogLevelToString(_loglevel) << "] "
<< "[" << _pid << "] "
<< "[" << _file << "] "
<< "[" << _line << "] "
<< "- ";
_loginfo = ss.str();
}
template
LogMessage &operator<<(const T &t)
{
std::stringstream ss;
ss << _loginfo << t;
_loginfo = ss.str();
//printf("重载<syncLog(_loginfo);
}
}
private:
LogLevel _loglevel;
std::string _time;
pid_t _pid;
std::string _file;
int _line;
std::string _loginfo;
Log &_log;
};
LogMessage operator()(LogLevel level, std::string filename, int line)
{
return LogMessage(level, filename, line, *this);
}
~Log()
{
}
private:
std::unique_ptr _logstrategy;
};
static Log logger;
#define Log(type) logger(type, __FILE__, __LINE__)
#define ENABLE_LOG_CONSOLE_STRATEGY() logger.useconsolestrategy()
#define ENABLE_LOG_FILE_STRATEGY() logger.usefilestrategy()
}
#endif
```
### main.cc
```cpp
#include "Log.hpp"
#include "common.h"
#include "Parser.h"
#include "Search.hpp"
#include "httplib.h"
#include
#include
#include
const bool INIT = false;
int main()
{
if(INIT)
{
Parser parser(Orignaldir, Tragetfile);
parser.Init();
}
ns_search::Search search;
httplib::Server svr;
svr.set_base_dir(Basewwwroot);
svr.Get("/s", [&](const httplib::Request& req, httplib::Response& rep){
std::string param = "word";
std::string word;
std::string out;
out.clear();
if(req.has_param(param))
{
word = req.get_param_value(param);
Log(LogModule::DEBUG) << "查找关键词:" << word;
}
// rep.set_content("Search: " + word, "text/plain");
bool b = search.SearchBy(word, out);
if(b)
rep.set_content(out, "application/json");
else
Log(DEBUG) << "查找失败";
});
svr.listen("0.0.0.0", 8080);
return 0;
}
```
### makefile
```cpp
# 编译器设置
CXX := g++
CXXFLAGS := -std=c++17
LDFLAGS :=
LIBS := -lboost_filesystem -lboost_system -ljsoncpp
# 目录设置
SRC_DIR := .
BUILD_DIR := build
TARGET := main
# 自动查找源文件
SRCS := $(wildcard $(SRC_DIR)/*.cc)
OBJS := $(SRCS:$(SRC_DIR)/%.cc=$(BUILD_DIR)/%.o)
DEPS := $(OBJS:.o=.d)
# 确保头文件依赖被包含
-include $(DEPS)
# 默认目标
all: $(BUILD_DIR) $(TARGET)
# 创建构建目录
$(BUILD_DIR):
@mkdir -p $(BUILD_DIR)
# 链接目标文件生成可执行文件
$(TARGET): $(OBJS)
$(CXX) $(OBJS) -o $@ $(LDFLAGS) $(LIBS)
@echo "✅ 构建完成: $(TARGET)"
# 编译每个.cc文件为.o文件
$(BUILD_DIR)/%.o: $(SRC_DIR)/%.cc
$(CXX) $(CXXFLAGS) -MMD -MP -c $< -o $@
# 清理构建文件
clean:
rm -rf $(BUILD_DIR) $(TARGET)
@echo "🧹 清理完成"
# 重新构建
rebuild: clean all
# 显示项目信息
info:
@echo "📁 源文件: $(SRCS)"
@echo "📦 目标文件: $(OBJS)"
@echo "🎯 最终目标: $(TARGET)"
# 伪目标
.PHONY: all clean rebuild info
# 防止与同名文件冲突
.PRECIOUS: $(OBJS)
```
### Parser.cc
```cpp
#include "Parser.h"
#include "Log.hpp"
#include "Util.hpp"
#include "common.h"
#include
#include
#include
#include
Parser::Parser(fs::path Datap, fs::path Targetp)
{
Orignalpath_ = Datap;
Targetpath_ = Targetp;
}
// 初始化:录入html路径------解析html数据------分割写入Data------记录Url
bool Parser::Init()
{
if(!LoadHtmlPath())
{
Log(LogModule::DEBUG) << "LoadHtmlPath fail!";
return false;
}
if(!ParseHtml())
{
Log(LogModule::DEBUG) << "ParseHtml fail!";
return false;
}
if(!WriteToTarget())
{
Log(LogModule::DEBUG) << "WriteToTarget fail!";
return false;
}
return true;
}
bool Parser::LoadHtmlPath()
{
if(!fs::exists(Orignalpath_) || !fs::is_directory(Orignalpath_))
{
Log(LogModule::DEBUG) << "Orignalpath is not exists or invalid!";
return false;
}
fs::recursive_directory_iterator end_it;
fs::recursive_directory_iterator it(Orignalpath_);
for(; it != end_it; it++)
{
if(!it->is_regular_file())
{
continue;
}
if(it->path().extension() != ".html")
{
continue;
}
htmlpaths_.push_back(it->path());
//Log(DEBUG) << "path: " << it->path();
}
Log(LogModule::DEBUG) << "Found " << htmlpaths_.size() << " HTML files";
return true;
}
bool Parser::ParseHtml()
{
if(htmlpaths_.empty())
{
Log(LogModule::DEBUG) << "paths is empty!";
return false;
}
size_t successCount = 0;
for(fs::path &p : htmlpaths_)
{
// 检查路径是否存在
if (!fs::exists(p)) {
Log(LogModule::ERROR) << "File not exists: " << p.string();
continue;
}
std::string out;
HtmlInfo_t info;
// 读取文件并记录错误
if(!ns_util::FileUtil::ReadFile(p.string(), &out))
{
Log(LogModule::ERROR) << "Failed to read file: " << p.string();
continue;
}
// 解析标题并记录错误
if(!ParseTitle(out, &info.title_))
{
Log(LogModule::ERROR) << "Failed to parse title from: " << p.string();
continue;
}
// 解析内容并记录错误
if(!ParseContent(out, &info.content_))
{
Log(LogModule::ERROR) << "Failed to parse content from: " << p.string();
continue;
}
// 检查URL解析结果
if(!ParseUrl(p, &info.url_))
{
Log(LogModule::ERROR) << "Failed to parse URL from: " << p.string();
continue;
}
htmlinfos_.push_back(std::move(info));
successCount++;
}
// 可以根据需要判断是否全部成功或部分成功
Log(LogModule::INFO) << "Parse HTML completed. Success: " << successCount
<< ", Total: " << htmlpaths_.size();
return successCount > 0;
}
bool Parser::WriteToTarget()
{
if(htmlinfos_.empty())
{
Log(LogModule::DEBUG) << "infos empty!";
return false;
}
for(HtmlInfo_t &info : htmlinfos_)
{
output_ += info.title_;
output_ += Output_sep;
output_ += info.content_;
output_ += Output_sep;
output_ += info.url_;
output_ += Line_sep;
}
WriteToTargetFile();
return true;
}
bool Parser::ParseUrl(fs::path p, std::string *out)
{
fs::path head(Boost_Url_Head);
head = head / p.string().substr(Orignaldir.size());
*out = head.string();
//Log(LogModule::DEBUG) << "filename: " << p.filename();
return true;
}
bool Parser::ParseTitle(std::string& fdata, std::string* title)
{
if(fdata.empty() || title == nullptr)
{
Log(LogModule::DEBUG) << "parameter invalid!";
return false;
}
size_t begin = fdata.find("");
size_t end = fdata.find("");
if(begin == std::string::npos || end == std::string::npos)
{
Log(LogModule::DEBUG) << "title find fail!";
return false;
}
begin += std::string("").size();
*title = fdata.substr(begin, end - begin);
return true;
}
bool Parser::ParseContent(std::string& fdata, std::string* content)
{
if(fdata.empty() || content == nullptr)
{
Log(LogModule::DEBUG) << "parameter invalid!";
return false;
}
typedef enum htmlstatus
{
LABEL,
CONTENT
}e_hs;
e_hs statu = LABEL;
for(char& c: fdata)
{
switch (c)
{
case '<':
statu = LABEL;
break;
case '>':
statu = CONTENT;
break;
default:
{
if(statu == CONTENT)
*content += (c == '\n' ? ' ' : c);
}
break;
}
}
return true;
}
bool Parser::WriteToTargetFile()
{
std::ofstream out;
try
{
// 确保目录存在
auto parent_path = Targetpath_.parent_path();
if (!parent_path.empty())
{
fs::create_directories(parent_path);
}
// 设置缓冲区(使用更大的缓冲区可能更好)
const size_t buffer_size = 128 * 1024; // 128KB
std::unique_ptr<char[]> buffer(new char[buffer_size]);
// 创建文件流并设置缓冲区
out.rdbuf()->pubsetbuf(buffer.get(), buffer_size);
// 打开文件
out.open(Targetpath_.string(), std::ios::binary | std::ios::trunc);
if (!out)
{
Log(LogModule::ERROR) << "Cannot open file: " << Targetpath_.string()
<< " - " << strerror(errno);
return false;
}
// 写入数据
if (!output_.empty())
{
out.write(output_.data(), output_.size());
if (out.fail())
{
Log(LogModule::ERROR) << "Write failed: " << Targetpath_.string()
<< " - " << strerror(errno);
return false;
}
}
// 显式刷新
out.flush();
if (out.fail())
{
Log(LogModule::ERROR) << "Flush failed: " << Targetpath_.string()
<< " - " << strerror(errno);
return false;
}
Log(LogModule::INFO) << "Written " << output_.size()
<< " bytes to " << Targetpath_.string();
}
catch (const fs::filesystem_error& e)
{
Log(LogModule::ERROR) << "Filesystem error: " << e.what();
return false;
}
catch (const std::exception& e)
{
Log(LogModule::ERROR) << "Unexpected error: " << e.what();
return false;
}
// 确保文件关闭(RAII会处理,但显式关闭更好)
if (out.is_open())
{
out.close();
}
return true;
}
```
### Parser.h
```cpp
#pragma once
// 包含公共头文件,可能包含一些全局定义、类型别名或常用工具函数
#include "common.h"
// 包含Boost文件系统库相关头文件,用于文件和目录操作
#include "boost/filesystem.hpp"
#include <boost/filesystem/directory.hpp>
#include <boost/filesystem/path.hpp>
// 包含vector容器头文件,用于存储路径和HTML信息列表
#include <vector>
// 为boost::filesystem定义别名别名fs,简化代码书写
namespace fs = boost::filesystem;
// HTML信息结构体,用于存储解析后的HTML文档关键信息
typedef struct HtmlInfo
{
std::string title_; // 存储HTML文档的标题
std::string content_; // 存储HTML文档的正文内容(去标签后)
std::string url_; // 存储HTML文档的URL或来源路径
}HtmlInfo_t; // 定义结构体别名HtmlInfo_t,方便使用
class Parser
{
private:
// 解析HTML内容,提取标题并存储到title指针指向的字符串
// 参数:fdata-HTML原始数据,title-输出的标题字符串指针
// 返回值:bool-解析成功返回true,失败返回false
bool ParseTitle(std::string& fdata, std::string* title);
// 解析HTML内容,提取正文(去除标签后)并存储到content指针指向的字符串
// 参数:fdata-HTML原始数据,content-输出的正文内容字符串指针
// 返回值:bool-解析成功返回true,失败返回false
bool ParseContent(std::string& fdata, std::string* content);
// 将解析后的HTML信息写入目标文件(内部实现)
// 返回值:bool-写入成功返回true,失败返回false
bool WriteToTargetFile();
public:
// 构造函数,初始化原始数据路径和目标存储路径
// 参数:Datap-原始HTML文件所在路径,Targetp-解析后数据的存储路径
Parser(fs::path Datap, fs::path Targetp);
// 初始化函数:加载HTML路径→解析HTML数据→分割写入数据→记录URL
// 整合了整个解析流程的入口函数
// 返回值:bool-初始化成功返回true,失败返回false
bool Init();
// 加载所有HTML文件的路径到htmlpaths_容器中
// 返回值:bool-加载成功返回true,失败返回false
bool LoadHtmlPath();
// 解析HTML文件:读取文件内容,提取标题、正文和URL
// 将解析结果存储到htmlinfos_容器中
// 返回值:bool-解析成功返回true,失败返回false
bool ParseHtml();
// 对外接口:将解析后的HTML信息写入目标文件(调用内部WriteToTargetFile)
// 返回值:bool-写入成功返回true,失败返回false
bool WriteToTarget();
// 解析文件路径p,生成对应的URL信息并存储到out指针指向的字符串
// 参数:p-文件路径,out-输出的URL字符串指针
// 返回值:bool-解析成功返回true,失败返回false
bool ParseUrl(fs::path p, std::string* out);
// 默认析构函数,无需额外资源释放
~Parser() = default;
private:
std::vector<fs::path> htmlpaths_; // 存储所有待解析的HTML文件路径
std::vector<HtmlInfo_t> htmlinfos_; // 存储解析后的所有HTML信息
std::string output_; // 可能用于临时存储输出数据
fs::path Orignalpath_; // 原始HTML文件所在的根路径
fs::path Targetpath_; // 解析后数据的目标存储路径
};
```
### Search.hpp
```cpp
#pragma once
#include "Log.hpp"
#include "Util.hpp"
#include "common.h"
#include "Index.hpp"
#include <algorithm>
#include <cctype>
#include <cstddef>
#include <cstdio>
#include <ctime>
#include <jsoncpp/json/json.h>
#include <string>
#include <unistd.h>
#include <unordered_map>
#include <vector>
namespace ns_search
{
//查找关键词文档归总
typedef struct DocSumup
{
size_t doc_id_ = 0;
size_t weight_ = 0;
std::vector<std::string> words_;
}DocSumup_t;
class Search : NonCopyable
{
public:
Search() : index(ns_index::Index::GetInstance())
{
index->BulidIndex();
}
bool SearchBy(std::string keywords, std::string& out)
{
//分词
std::vector<std::string> Segmentation;
ns_util::JiebaUtile::CutPhrase(keywords, Segmentation);
//查找
std::vector<DocSumup_t> inverted_elem_all;
std::unordered_map<size_t, DocSumup_t> doc_map;
//debug
// for(auto& e : Segmentation)
// {
// cout << e << " - " ;
// }
//cout << endl;
//debug
for(auto& word : Segmentation)
{
static size_t t = 0;
ns_index::InvertedList* list = index->QueryByWord(word);
if(list == nullptr)
{
//Log(LogModule::DEBUG) << word << "-not find!";
//sleep(1);
continue;
}
//cout << t << "次循环," << word << "-找到" << endl;
for(ns_index::InvertedElem e : *list)
{
doc_map[e.doc_id_].doc_id_ = e.doc_id_;
doc_map[e.doc_id_].weight_ += e.weight_;
doc_map[e.doc_id_].words_.push_back(e.word_);
}
}
//哈稀表的内容插入整体数组
for(auto& e : doc_map)
{
inverted_elem_all.push_back(std::move(e.second));
}
//判断是否找到
if(inverted_elem_all.empty())
{
Log(LogModule::INFO) << "-" << keywords << "-Not Find!";
return false;
}
else
{
Log(LogModule::DEBUG) << "已找到" << inverted_elem_all.size() << "个文件相关!" ;
}
//权重排序
std::sort(inverted_elem_all.begin(), inverted_elem_all.end()
,[](DocSumup_t i1, DocSumup_t i2)-> bool{
return i1.weight_ == i2.weight_ ? i1.doc_id_ < i2.doc_id_ : i1.weight_ > i2.weight_;
});
//写入json串
for(DocSumup_t& e : inverted_elem_all)
{
Json::Value tempvalue;
tempvalue["doc_id"] = e.doc_id_;
tempvalue["weight"] = e.weight_;
ns_index::Forword_t* ft = index->QueryById(e.doc_id_);
if(!ft)
{
Log(DEBUG) << e.doc_id_ << "-id not find!";
//sleep(1);
continue;
}
tempvalue["url"] = ft->url_;
tempvalue["title"] = ft->title_;
tempvalue["desc"] = ExtractDesc(ft->content_, e.words_[0]);
tempvalue["word"] = keywords;
root.append(tempvalue);
}
//写入字符串带出参数
Json::StyledWriter writer;
out = writer.write(root);
// 每次搜索完,都把这个root的内容清空一下
root.clear();
return true;
}
private:
std::string ExtractDesc(std::string& content, std::string word)
{
auto it = std::search(content.begin(),content.end(),
word.begin(),word.end(),
[](char a, char b)->bool{
return std::tolower(a) == std::tolower(b);
});
if(it == content.end())
{
Log(LogModule::DEBUG) << "ExtractDesc fail!";
return "NONE!";
}
const int pre_step = 50;
const int back_step = 100;
int pos = it - content.begin();
int start = pos - pre_step > 0 ? pos - pre_step : 0;
int end = pos + back_step >= content.size() ? content.size() - 1 : pos + back_step;
return content.substr(start, end - start) + std::string("...");
}
public:
~Search() = default;
private:
Json::Value root;
ns_index::Index* index;
};
};
```
### Util.hpp
```cpp
#pragma once
#include "Log.hpp"
#include "common.h"
#include "cppjieba/Jieba.hpp"
#include <boost/algorithm/string/classification.hpp>
#include <boost/algorithm/string/split.hpp>
#include <fstream>
#include <sstream>
#include <string>
#include <unordered_map>
#include <vector>
namespace ns_util
{
class FileUtil : public NonCopyable
{
public:
static bool ReadFile(std::string path, std::string* out)
{
std::fstream in(path, std::ios::binary | std::ios::in);
if(!in.is_open())
{
Log(LogModule::DEBUG) << "file-" << path << "open fail!";
return false;
}
std::stringstream ss;
ss << in.rdbuf();
*out = ss.str();
in.close();
return true;
}
};
class StopClass
{
public:
StopClass()
{
std::ifstream in(STOP_WORD_PATH, std::ios::binary | std::ios::in);
if(!in.is_open())
{
Log(LogModule::DEBUG) << "stop words load fail!";
in.close();
return;
}
std::string line;
while(std::getline(in, line))
{
stop_words[line] = true;
}
in.close();
}
std::pmr::unordered_map<std::string, bool> stop_words;
};
class JiebaUtile : public NonCopyable
{
public:
static cppjieba::Jieba* GetInstace()
{
static cppjieba::Jieba jieba_(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
return &jieba_;
}
static bool CutPhrase(std::string& src, std::vector<std::string>& out)
{
try
{
GetInstace()->CutForSearch(src, out, true);
for(auto s = out.begin(); s != out.end(); s++)
{
if(stop_.stop_words.find(*s) != stop_.stop_words.end())
{
out.erase(s);
}
}
}
catch (const std::exception& e)
{
Log(LogModule::ERROR) << "CutString Error!" << e.what();
return false;
}
catch (...)
{
Log(ERROR) << "Unknow Error!";
return false;
}
return true;
}
static bool CutDoc(std::string& filestr, std::vector<std::string>& out)
{
try
{
boost::split(out, filestr, boost::is_any_of("\3"));
}
catch (const std::exception& e)
{
Log(LogModule::ERROR) << "std Error-" << e.what();
return false;
}
catch(...)
{
Log(LogModule::ERROR) << "UnKnown Error!";
return false;
}
return true;
}
private:
JiebaUtile() = default;
~JiebaUtile() = default;
private:
static StopClass stop_;
};
inline StopClass JiebaUtile::stop_;
};
```
## 结果展示
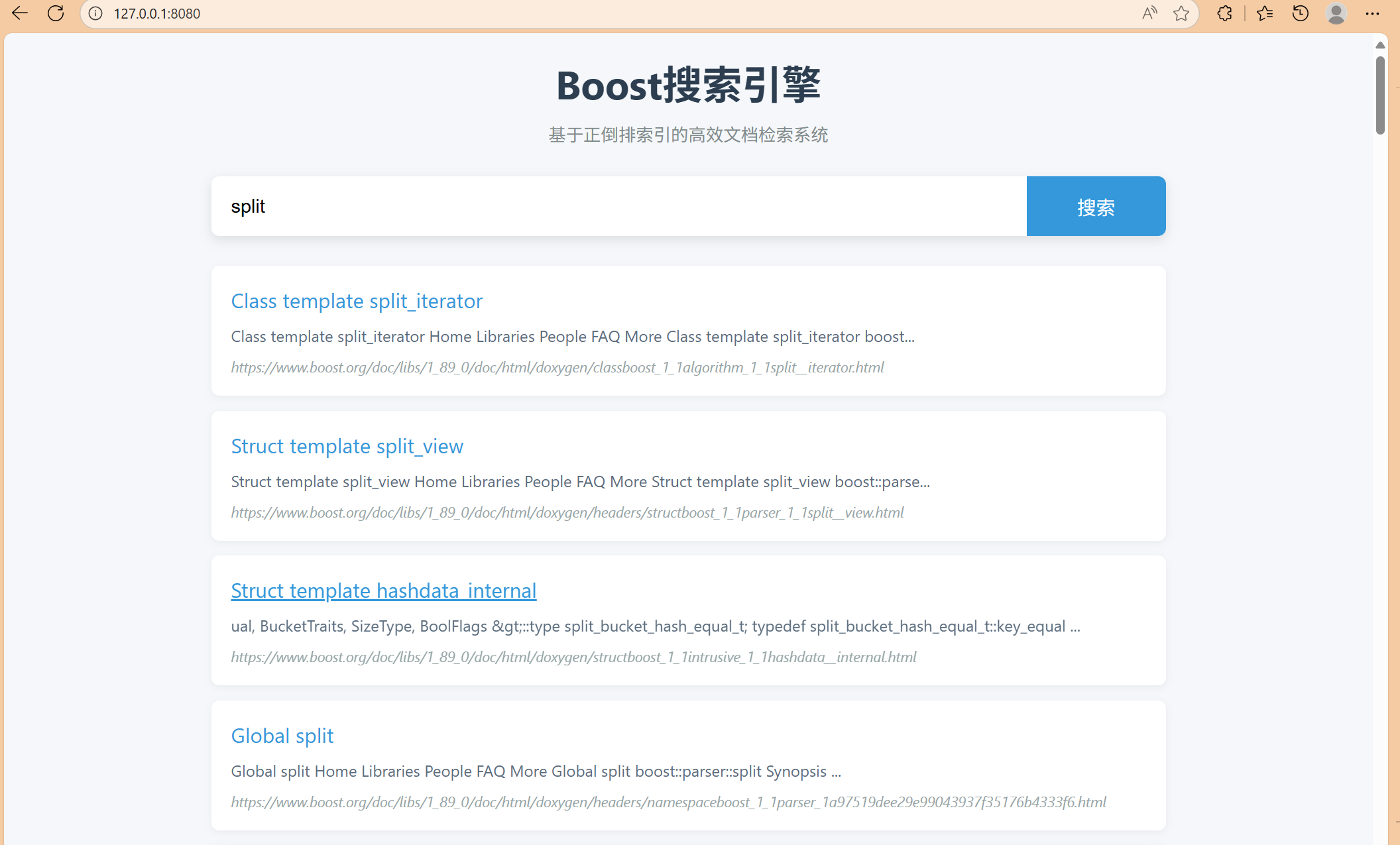********
</div><!----><!--]--></div></div><span data-v-88a210bf></span><div class="article-tag-list" data-v-88a210bf><!--[--><a href="/tag/9" class="" data-v-88a210bf><button ariadisabled="false" type="button" class="el-button el-button--info is-text is-has-bg" style="" data-v-88a210bf><!--v-if--><span class=""><!--[-->linux<!--]--></span></button></a><a href="/tag/27" class="" data-v-88a210bf><button ariadisabled="false" type="button" class="el-button el-button--info is-text is-has-bg" style="" data-v-88a210bf><!--v-if--><span class=""><!--[-->c++<!--]--></span></button></a><a href="/tag/146" class="" data-v-88a210bf><button ariadisabled="false" type="button" class="el-button el-button--info is-text is-has-bg" style="" data-v-88a210bf><!--v-if--><span class=""><!--[-->搜索引擎<!--]--></span></button></a><!--]--></div><div class="article-pre-next" data-v-88a210bf><div data-v-88a210bf><a href="/article/1971875776872640514" class="" data-v-88a210bf><span data-v-88a210bf>上一篇:</span><span class="article-pre-next-item-title" data-v-88a210bf>苦练Python第54天:比较运算魔术方法全解析,让你的对象“懂大小、能排序”!</span></a></div><div data-v-88a210bf><a href="/article/1971876091445440514" class="" data-v-88a210bf><span data-v-88a210bf>下一篇:</span><span class="article-pre-next-item-title" data-v-88a210bf>揭秘Android编译插桩:ASM让你的代码"偷偷"变强</span></a></div></div></div><ins class="adsbygoogle" style="display:block;" data-ad-client="ca-pub-4340231068438843" data-ad-slot="3187524902" data-ad-format="auto" data-full-width-responsive="true" data-v-88a210bf></ins><!----><div class="article-recommend-card" data-v-88a210bf><span class="article-recommend-card-title" data-v-88a210bf>相关推荐</span><div class="el-divider el-divider--horizontal" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><div class="article-recommend-list" data-v-88a210bf><!--[--><a href="/article/2080946962022146049" class="article-recommend-list-item" data-v-88a210bf><div class="article-recommend-list-item-info" data-v-88a210bf><span data-v-88a210bf>念恒12306</span><div class="el-divider el-divider--vertical" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><span data-v-88a210bf>29 分钟前</span></div><span class="article-recommend-list-item-title" data-v-88a210bf>网络基础</span><div class="article-recommend-list-item-tag-list" data-v-88a210bf><!--[--><!--[--><!----><span data-v-88a210bf>linux</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>网络</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>c++</span><!--]--><!--]--></div></a><a href="/article/2080941682823667713" class="article-recommend-list-item" data-v-88a210bf><div class="article-recommend-list-item-info" data-v-88a210bf><span data-v-88a210bf>mct123</span><div class="el-divider el-divider--vertical" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><span data-v-88a210bf>1 小时前</span></div><span class="article-recommend-list-item-title" data-v-88a210bf>c++ iconv 字符utf-8转换gb2312失败</span><div class="article-recommend-list-item-tag-list" data-v-88a210bf><!--[--><!--[--><!----><span data-v-88a210bf>开发语言</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>c++</span><!--]--><!--]--></div></a><a href="/article/2080941352329289730" class="article-recommend-list-item" data-v-88a210bf><div class="article-recommend-list-item-info" data-v-88a210bf><span data-v-88a210bf>ziguo1122</span><div class="el-divider el-divider--vertical" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><span data-v-88a210bf>1 小时前</span></div><span class="article-recommend-list-item-title" data-v-88a210bf>Windows API 文件操作超级指南——从入门到内核</span><div class="article-recommend-list-item-tag-list" data-v-88a210bf><!--[--><!--[--><!----><span data-v-88a210bf>c++</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>windows</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>visualstudio</span><!--]--><!--]--></div></a><a href="/article/2080937064697831426" class="article-recommend-list-item" data-v-88a210bf><div class="article-recommend-list-item-info" data-v-88a210bf><span data-v-88a210bf>皮卡狮</span><div class="el-divider el-divider--vertical" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><span data-v-88a210bf>1 小时前</span></div><span class="article-recommend-list-item-title" data-v-88a210bf>Linux静态库和动态库详解</span><div class="article-recommend-list-item-tag-list" data-v-88a210bf><!--[--><!--[--><!----><span data-v-88a210bf>linux</span><!--]--><!--]--></div></a><a href="/article/2080934005368299521" class="article-recommend-list-item" data-v-88a210bf><div class="article-recommend-list-item-info" data-v-88a210bf><span data-v-88a210bf>撩得Android一次心动</span><div class="el-divider el-divider--vertical" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><span data-v-88a210bf>1 小时前</span></div><span class="article-recommend-list-item-title" data-v-88a210bf>Linux编程笔记4【个人用】</span><div class="article-recommend-list-item-tag-list" data-v-88a210bf><!--[--><!--[--><!----><span data-v-88a210bf>linux</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>笔记</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>学习</span><!--]--><!--]--></div></a><a href="/article/2080927894519029761" class="article-recommend-list-item" data-v-88a210bf><div class="article-recommend-list-item-info" data-v-88a210bf><span data-v-88a210bf>2601_95576007</span><div class="el-divider el-divider--vertical" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><span data-v-88a210bf>2 小时前</span></div><span class="article-recommend-list-item-title" data-v-88a210bf>如何用 Claude Opus 5 API 批量扩展长尾关键词和文章选题</span><div class="article-recommend-list-item-tag-list" data-v-88a210bf><!--[--><!--[--><!----><span data-v-88a210bf>前端</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>python</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>搜索引擎</span><!--]--><!--]--></div></a><a href="/article/2080925295405309954" class="article-recommend-list-item" data-v-88a210bf><div class="article-recommend-list-item-info" data-v-88a210bf><span data-v-88a210bf>Litluecat</span><div class="el-divider el-divider--vertical" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><span data-v-88a210bf>2 小时前</span></div><span class="article-recommend-list-item-title" data-v-88a210bf>2026年7月21日科技热点新闻</span><div class="article-recommend-list-item-tag-list" data-v-88a210bf><!--[--><!--[--><!----><span data-v-88a210bf>人工智能</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>科技</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>搜索引擎</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>新闻</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>每日</span><!--]--><!--]--></div></a><a href="/article/2080922753745166338" class="article-recommend-list-item" data-v-88a210bf><div class="article-recommend-list-item-info" data-v-88a210bf><span data-v-88a210bf>Elastic 中国社区官方博客</span><div class="el-divider el-divider--vertical" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><span data-v-88a210bf>2 小时前</span></div><span class="article-recommend-list-item-title" data-v-88a210bf>不到 5 分钟完成本地部署:Jina embedding 模型现已支持本地部署</span><div class="article-recommend-list-item-tag-list" data-v-88a210bf><!--[--><!--[--><!----><span data-v-88a210bf>大数据</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>人工智能</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>elasticsearch</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>搜索引擎</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>embedding</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>jina</span><!--]--><!--]--></div></a><a href="/article/2080920096645193730" class="article-recommend-list-item" data-v-88a210bf><div class="article-recommend-list-item-info" data-v-88a210bf><span data-v-88a210bf>二进制流水搬运工</span><div class="el-divider el-divider--vertical" style="--el-border-style:solid;" role="separator" data-v-88a210bf><!--v-if--></div><span data-v-88a210bf>2 小时前</span></div><span class="article-recommend-list-item-title" data-v-88a210bf>入职第一天拉了23个仓库,我写了个脚本解放双手</span><div class="article-recommend-list-item-tag-list" data-v-88a210bf><!--[--><!--[--><!----><span data-v-88a210bf>大数据</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>elasticsearch</span><!--]--><!--[--><span class="article-recommend-list-item-tag-list-divider" data-v-88a210bf>·</span><span data-v-88a210bf>搜索引擎</span><!--]--><!--]--></div></a><!--]--></div></div><ins class="adsbygoogle" style="display:block;" data-ad-client="ca-pub-4340231068438843" data-ad-slot="3187524902" data-ad-format="auto" data-full-width-responsive="true" data-v-88a210bf></ins><!----></div><div class="right" data-v-88a210bf><div class="right-body" data-v-88a210bf><div class="hot-article-rank hot-article-rank-wrapper" data-v-88a210bf data-v-08dc960f><span class="title" data-v-08dc960f>热门推荐</span><div class="el-divider el-divider--horizontal" style="--el-border-style:solid;" role="separator" data-v-08dc960f><!--v-if--></div><div class="article-list" data-v-08dc960f><!--[--><a href="/article/1965957555249266689" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>01</span><span class="article-title" data-v-08dc960f>GitHub 镜像站点</span></a><a href="/article/2073594154696953858" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>02</span><span class="article-title" data-v-08dc960f>如何新建文件夹? 电脑新建文件夹的4种方法</span></a><a href="/article/2073572864476958722" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>03</span><span class="article-title" data-v-08dc960f>2026年7月AI圈大地震:GPT-5.6被政府限制、Claude入驻Slack、Anthropic自研芯片</span></a><a href="/article/2072604105083809793" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>04</span><span class="article-title" data-v-08dc960f>AI科技热点日报 | 2026年07月01日</span></a><a href="/article/2061973168230838274" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>05</span><span class="article-title" data-v-08dc960f>国内可直接用、免费额度/永久免费的大模型API清单(含 SiliconFlow、火山、阿里、智谱、百度、Kimi、DeepSeek、DMXAPI 等)</span></a><a href="/article/2073638247544143874" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>06</span><span class="article-title" data-v-08dc960f>AI 编程 IDE 全景解析 2026:Agent 全面接管开发链路</span></a><a href="/article/2059068639778226178" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>07</span><span class="article-title" data-v-08dc960f>幻兽帕鲁 - 服务器管理员权限与 GM 命令完全指南</span></a><a href="/article/2065289201393954817" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>08</span><span class="article-title" data-v-08dc960f>2026 国产 AI 大模型横评:DeepSeek、通义千问、Kimi、文心一言、星火、豆包谁更能打?</span></a><a href="/article/2018132694711451650" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>09</span><span class="article-title" data-v-08dc960f>微信历史版本含下载地址( Windows PC | 安卓 | MAC )及设置微信不更新</span></a><a href="/article/2047884039231700993" class="article" data-v-08dc960f><span class="article-index" data-v-08dc960f>10</span><span class="article-title" data-v-08dc960f>【解构】DeepSeek V4 发布:技术报告深度解读 + 横向对比六大开源模型,我们的判断是……</span></a><!--]--></div></div><!----></div></div></div></div></div><div id="teleports"></div><script>window.__NUXT__={};window.__NUXT__.config={public:{env:"prod",apiRootUrl:"https://jishuzhan.net/api"},app:{baseURL:"/",buildId:"8a8d2c04-c9c0-4945-bc5c-688839d327ad",buildAssetsDir:"/_nuxt/",cdnURL:""}}</script><script type="application/json" data-nuxt-data="nuxt-app" data-ssr="true" id="__NUXT_DATA__">[["ShallowReactive",1],{"data":2,"state":367,"once":370,"_errors":371,"serverRendered":373,"path":374},["ShallowReactive",3],{"wDdEB1REj7eOVA0IINOW8By0h7e6k9_YCMGESItz9sY":4,"glaIx14zzTwMHHGT3VRKOAAT2IWy941uSBVkEtcvnRA":186,"0mAzBCS3CWakgW3AGYauUaIafVRcTpqTzE6xC2Tnrc0":188,"WZ90U2AJ8WAHMpSv5WU9d7GUiJToX5gfe9Fb1fyuzAs":342},[5,19,32,51,62,84,111,142,155,171],{"description":6,"id":7,"imgUrl":8,"ownerHeadUrl":9,"ownerId":10,"ownerName":11,"tagList":12,"time":16,"title":17,"views":18},"国内访问 GitHub 有时会遇到速度慢或不稳定的情况,这时 GitHub 镜像站点就能帮上忙。它们通过代理或缓存机制,让你更顺畅地浏览仓库、下载资源甚至克隆代码。","1965957555249266689","","https:\u002F\u002Fprofile-avatar.csdnimg.cn\u002Fdefault.jpg","1851173111697772545","BillKu",[13],{"id":14,"name":15},424,"github",1757555781000,"GitHub 镜像站点",114755,{"description":20,"id":21,"imgUrl":22,"ownerHeadUrl":9,"ownerId":23,"ownerName":24,"tagList":25,"time":29,"title":30,"views":31},"在Windows操作系统中,创建新文件夹的方法比较简单,一些新手用户,可能还不太清楚怎么新建文件夹。下面将为您详细介绍如何在不同环境下创建新文件夹,并提供一些实用的技巧。","2073594154696953858","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fimg_convert\u002Fe745de9d0d265eb10cc68b1bd70ec9d6.png","2073266129056854017","红糖奶茶",[26],{"id":27,"name":28},152700,"新建文件夹",1783218346000,"如何新建文件夹? 电脑新建文件夹的4种方法",2787,{"description":33,"id":34,"imgUrl":8,"ownerHeadUrl":35,"ownerId":36,"ownerName":37,"tagList":38,"time":48,"title":49,"views":50},"一句话总结:2026年7月的AI行业,正从“技术竞赛”全面转向“生态博弈”——监管、硬件、Agent化三条主线同时爆发。","2073572864476958722","https:\u002F\u002Fp26-passport.byteacctimg.com\u002Fimg\u002Fmosaic-legacy\u002F3795\u002F3033762272~300x300.image","2032662933243756546","米小虾",[39,42,45],{"id":40,"name":41},39,"人工智能",{"id":43,"name":44},206,"chatgpt",{"id":46,"name":47},1803,"claude",1783213270000,"2026年7月AI圈大地震:GPT-5.6被政府限制、Claude入驻Slack、Anthropic自研芯片",6579,{"description":52,"id":53,"imgUrl":54,"ownerHeadUrl":55,"ownerId":56,"ownerName":57,"tagList":58,"time":59,"title":60,"views":61},"综合整理自The Verge、TechCrunch、Wired、MIT Technology Review、Reuters Technology、VentureBeat、钛媒体、36氪、虎嗅、新华网科技、网易科技、雷锋网等国内外主流科技媒体当日报道,聚焦人工智能领域核心动态,附资深媒体人综合解读。","2072604105083809793","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002F2a9b5cdb7b6a4def87edb138f47a7929.png","https:\u002F\u002Ffile.jishuzhan.net\u002Fuser\u002F1743724957503852546\u002Fhead.webp","1743724957503852546","刘一说",[],1782982300000,"AI科技热点日报 | 2026年07月01日",6654,{"description":63,"id":64,"imgUrl":8,"ownerHeadUrl":65,"ownerId":66,"ownerName":67,"tagList":68,"time":81,"title":82,"views":83},"2026.6|国内可直接用、免费额度\u002F永久免费的大模型API清单(含 SiliconFlow、火山、阿里、智谱、百度、Kimi、DeepSeek、DMXAPI 等) 按“最值得用→一般”排序 标注:地址 + 免费额度 + 代表模型 + 特点。","2061973168230838274","https:\u002F\u002Ffile.jishuzhan.net\u002Fuser\u002F1682773449346387969\u002Fhead.png","1682773449346387969","子非鱼@Itfuture",[69,72,75,78],{"id":70,"name":71},151,"百度",{"id":73,"name":74},189,"ai",{"id":76,"name":77},435,"aigc",{"id":79,"name":80},1080,"个人开发",1780447687000,"国内可直接用、免费额度\u002F永久免费的大模型API清单(含 SiliconFlow、火山、阿里、智谱、百度、Kimi、DeepSeek、DMXAPI 等)",3794,{"description":85,"id":86,"imgUrl":8,"ownerHeadUrl":87,"ownerId":88,"ownerName":89,"tagList":90,"time":108,"title":109,"views":110},"一句话总结:2026 年,AI 编程工具正式告别\"代码补全\"时代,进入\"Agent 全权接管开发链路\"的新纪元。本文系统拆解 12 款主流工具的最新架构、核心能力与选型策略,数据截至 2026 年 7 月。","2073638247544143874","https:\u002F\u002Ffile.jishuzhan.net\u002Fuser\u002F1684496749571346433\u002Fhead.png","1684496749571346433","DogDaoDao",[91,94,95,98,101,102,105],{"id":92,"name":93},29,"ide",{"id":40,"name":41},{"id":96,"name":97},232,"程序员",{"id":99,"name":100},1235,"ai编程",{"id":46,"name":47},{"id":103,"name":104},8662,"cursor",{"id":106,"name":107},21808,"ai agent",1783228859000,"AI 编程 IDE 全景解析 2026:Agent 全面接管开发链路",3710,{"description":112,"id":113,"imgUrl":8,"ownerHeadUrl":114,"ownerId":115,"ownerName":116,"tagList":117,"time":139,"title":140,"views":141},"由于网络环境限制,国内直连时游戏内聊天框功能可能无法正常显示或使用。因此,在输入管理员命令前,建议先开启游戏加速器,确保聊天框可以正常呼出。","2059068639778226178","https:\u002F\u002Fi-avatar.csdnimg.cn\u002F4c0be02ebceb4485a6f9651be4d37e67_m0_71727150.jpg","2056186309282729985","樱桃花下的小猫",[118,121,124,127,130,133,136],{"id":119,"name":120},11,"服务器",{"id":122,"name":123},33765,"幻兽帕鲁",{"id":125,"name":126},106056,"新手友好",{"id":128,"name":129},145778,"云鸢互联",{"id":131,"name":132},145920,"零门槛一键开服",{"id":134,"name":135},147194,"幻兽帕鲁服务器",{"id":137,"name":138},147338,"幻兽帕鲁游戏服务器管理员教程",1779755194000,"幻兽帕鲁 - 服务器管理员权限与 GM 命令完全指南",3958,{"description":143,"id":144,"imgUrl":8,"ownerHeadUrl":9,"ownerId":145,"ownerName":146,"tagList":147,"time":152,"title":153,"views":154},"2026 年,国产 AI 大模型已从 “追赶” 进入 “局部超越” 的关键期。DeepSeek V4、通义千问 Qwen3、Kimi k1.5、文心一言 ERNIE 5.1、讯飞星火 Spark V4.5、豆包 5.0 Pro六大主流模型,在中文理解、代码生成、长文本处理、多模态交互四大核心能力上各有胜负。","2065289201393954817","2061619578215673858","库拉大叔",[148,149],{"id":40,"name":41},{"id":150,"name":151},887,"文心一言",1781238291000,"2026 国产 AI 大模型横评:DeepSeek、通义千问、Kimi、文心一言、星火、豆包谁更能打?",4685,{"description":156,"id":157,"imgUrl":158,"ownerHeadUrl":9,"ownerId":159,"ownerName":160,"tagList":161,"time":168,"title":169,"views":170},"微信windows PC 各版本下载地址:https:\u002F\u002Fgithub.com\u002Ftom-snow\u002Fwechat-windows-versions\u002Freleases","2018132694711451650","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002Fe8c79d40d8d84b0bbe5bd53de85ec101.png","1893531964925808642","广拓科技",[162,165],{"id":163,"name":164},140,"macos",{"id":166,"name":167},193,"微信",1769995304000,"微信历史版本含下载地址( Windows PC | 安卓 | MAC )及设置微信不更新",3559,{"description":172,"id":173,"imgUrl":174,"ownerHeadUrl":9,"ownerId":175,"ownerName":176,"tagList":177,"time":183,"title":184,"views":185},"2026 年 4 月 24 日,DeepSeek 在 HuggingFace 上传了 58 页的 V4 技术报告,同步开源权重。同一天,OpenAI 发布了 GPT-5.5——这个时间节点显然不是巧合。","2047884039231700993","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002F5cb43984ca464649a85fd0108c3a4846.png","2045151753545515009","qcx23",[178,179,180],{"id":40,"name":41},{"id":43,"name":44},{"id":181,"name":182},398,"prompt",1777088577000,"【解构】DeepSeek V4 发布:技术报告深度解读 + 横向对比六大开源模型,我们的判断是……",4547,{"adMap":187},["Map"],[189,209,223,238,250,268,286,308,331],{"description":190,"id":191,"imgUrl":192,"ownerHeadUrl":193,"ownerId":194,"ownerName":195,"tagList":196,"time":206,"title":207,"views":208},"目录1.网络基础 --- 宏观概念,相关的逻辑线2.初识协议1.初识协议 减少通信的成本,用于快速形成共识","2080946962022146049","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002Fa5eb1bd4f0ac4459a210776cd272e8ec.png","https:\u002F\u002Fi-avatar.csdnimg.cn\u002F8683d490f8f242bcba81fbee39886544_2501_92795260.jpg","2042711271968145410","念恒12306",[197,200,203],{"id":198,"name":199},9,"linux",{"id":201,"name":202},17,"网络",{"id":204,"name":205},27,"c++",1784971392000,"网络基础",2,{"description":210,"id":211,"imgUrl":8,"ownerHeadUrl":212,"ownerId":213,"ownerName":214,"tagList":215,"time":220,"title":221,"views":222},"extern size_t iconv (iconv_t __cd, char **__restrict __inbuf, size_t *__restrict __inbytesleft, char **__restrict __outbuf, size_t *__restrict __outbytesleft);","2080941682823667713","https:\u002F\u002Ffile.jishuzhan.net\u002Fuser\u002F1784942534280089601\u002Fhead.webp","1784942534280089601","mct123",[216,219],{"id":217,"name":218},13,"开发语言",{"id":204,"name":205},1784970133000,"c++ iconv 字符utf-8转换gb2312失败",7,{"description":224,"id":225,"imgUrl":8,"ownerHeadUrl":9,"ownerId":226,"ownerName":227,"tagList":228,"time":236,"title":237,"views":208},"在上一篇文章中,我们系统性地对比了 C\u002FC++ 在 Linux、Windows、macOS 三平台的文件操作。那篇文章的评论区有位读者问了一个很刁钻的问题:“既然 fopen 和 fstream 都能跨平台,我干嘛还要学 Windows API 那一大坨参数?”","2080941352329289730","2080941355332411393","ziguo1122",[229,230,233],{"id":204,"name":205},{"id":231,"name":232},44,"windows",{"id":234,"name":235},184,"visualstudio",1784970055000,"Windows API 文件操作超级指南——从入门到内核",{"description":239,"id":240,"imgUrl":241,"ownerHeadUrl":242,"ownerId":243,"ownerName":244,"tagList":245,"time":247,"title":248,"views":249},"目录前言:一.库的认识二.静态库1.本质2.生成静态库3.链接使用:三.动态库1.本质:2.生成动态库","2080937064697831426","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002F124e8b257b4241c3ac6e301bc5726c47.png","https:\u002F\u002Fi-avatar.csdnimg.cn\u002F8c47480dee4243dc827a33a527910307_nmnmnmnshabhsshj.jpg","2033374654962925569","皮卡狮",[246],{"id":198,"name":199},1784969032000,"Linux静态库和动态库详解",4,{"description":251,"id":252,"imgUrl":253,"ownerHeadUrl":254,"ownerId":255,"ownerName":256,"tagList":257,"time":265,"title":266,"views":267},"目录一、多进程1.进程1.1 什么是程序1.2 什么是进程2.管理进程2.1 进程表2.2 查看进程2.3 列的含义说明","2080934005368299521","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002Fc58968ff96344b99bd03aa47d49a48d2.png","https:\u002F\u002Fprofile-avatar.csdnimg.cn\u002F1f8ee5fadbf647b194229cdf973796bc_indeedes.jpg","1956508167457779713","撩得Android一次心动",[258,259,262],{"id":198,"name":199},{"id":260,"name":261},50,"笔记",{"id":263,"name":264},84,"学习",1784968303000,"Linux编程笔记4【个人用】",3,{"description":269,"id":270,"imgUrl":271,"ownerHeadUrl":9,"ownerId":272,"ownerName":273,"tagList":274,"time":284,"title":285,"views":208},"做 SEO 内容时,最耗时间的往往不是把文章写出来,而是不断找到“值得写”的方向:既要有人搜,又要和业务相关,还不能跟站内已有内容撞车。尤其是技术博客、SaaS 官网、知识付费栏目、工具站这类内容场景,如果全靠人工去翻搜索下拉词、竞品标题、后台数据,再一条条整理,效率确实不高。","2080927894519029761","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002F4aaa93fb3d3040a687df064590c0dfe9.png","2080927898008690690","2601_95576007",[275,278,281],{"id":276,"name":277},14,"前端",{"id":279,"name":280},58,"python",{"id":282,"name":283},146,"搜索引擎",1784966846000,"如何用 Claude Opus 5 API 批量扩展长尾关键词和文章选题",{"description":287,"id":288,"imgUrl":289,"ownerHeadUrl":290,"ownerId":291,"ownerName":292,"tagList":293,"time":305,"title":306,"views":307},"在2026世界人工智能大会上,东方星链时空智能、北京清微智能联合发布了全球首个可重构芯片太空智能体。该技术可根据太空环境实时改变芯片内部线路,以应对辐射干扰和任务切换。清微智能是全球首家实现可重构芯片大规模量产并商用的企业,此次将可重构芯片送入太空在全球尚无公开先例。按计划,该芯片将于今年底搭载卫星入轨,完成全球首次太空实测验证。","2080925295405309954","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002F36d6fa60c64c4068b69c8e1a3ceec1b8.png","https:\u002F\u002Ffile.jishuzhan.net\u002Fuser\u002F1693880251198738434\u002Fhead.png","1693880251198738434","Litluecat",[294,295,298,299,302],{"id":40,"name":41},{"id":296,"name":297},65,"科技",{"id":282,"name":283},{"id":300,"name":301},32765,"新闻",{"id":303,"name":304},147980,"每日",1784966226000,"2026年7月21日科技热点新闻",5,{"description":309,"id":310,"imgUrl":311,"ownerHeadUrl":312,"ownerId":313,"ownerName":314,"tagList":315,"time":329,"title":330,"views":222},"作者:来自 Elastic Scott Martens全部 28 个 Jina AI 模型(包括 reranker),现已提供可直接部署的 Docker 容器,无遥测数据收集,无需许可证服务器。可直接兼容 OpenAI、Cohere、Voyage AI 和 Elastic Inference Service API。","2080922753745166338","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002F784ea857a64c4baa8f9644469a7cce7b.webp","https:\u002F\u002Ffile.jishuzhan.net\u002Fuser\u002F1681521850758205442\u002Fhead.png","1681521850758205442","Elastic 中国社区官方博客",[316,318,319,322,323,326],{"id":249,"name":317},"大数据",{"id":40,"name":41},{"id":320,"name":321},130,"elasticsearch",{"id":282,"name":283},{"id":324,"name":325},992,"embedding",{"id":327,"name":328},23198,"jina",1784965620000,"不到 5 分钟完成本地部署:Jina embedding 模型现已支持本地部署",{"description":332,"id":333,"imgUrl":8,"ownerHeadUrl":9,"ownerId":334,"ownerName":335,"tagList":336,"time":340,"title":341,"views":208},"——你有过这样的经历吗?新入职第一天,leader扔给你一个文档,上面列着23个Git仓库地址,说\"先把代码都拉下来熟悉一下\"。你看着终端里一个个git clone命令,陷入了沉思……","2080920096645193730","2080920103288971265","二进制流水搬运工",[337,338,339],{"id":249,"name":317},{"id":320,"name":321},{"id":282,"name":283},1784964987000,"入职第一天拉了23个仓库,我写了个脚本解放双手",{"articleSourceUrl":343,"content":344,"description":345,"id":346,"imgUrl":347,"nextArticle":348,"ownerHeadUrl":352,"ownerId":353,"ownerName":354,"preArticle":355,"tagList":360,"time":364,"title":365,"views":366},"https:\u002F\u002Fblog.csdn.net\u002Fqq_34434522\u002Farticle\u002Fdetails\u002F152126045","#### 基于正倒排索引的boost搜索引擎\n\n* [cpp-httplib库](#cpp-httplib库)\n*\n * [cpp-httplib 库介绍](#cpp-httplib 库介绍)\n * [常用功能与函数](#常用功能与函数)\n *\n * [1. 服务器相关](#1. 服务器相关)\n * [2. 客户端相关](#2. 客户端相关)\n * [下载与使用](#下载与使用)\n *\n * [下载路径](#下载路径)\n * [使用方法](#使用方法)\n * [简单示例](#简单示例)\n* [网页模块](#网页模块)\n*\n * [仿照其它成熟搜索页面](#仿照其它成熟搜索页面)\n * [编写主程序入口](#编写主程序入口)\n * [编写网页](#编写网页)\n* [完整代码](#完整代码)\n*\n * [common.h](#common.h)\n * [Index.hpp](#Index.hpp)\n * [Log.hpp](#Log.hpp)\n * [main.cc](#main.cc)\n * [makefile](#makefile)\n * [Parser.cc](#Parser.cc)\n * [Parser.h](#Parser.h)\n * [Search.hpp](#Search.hpp)\n * [Util.hpp](#Util.hpp)\n* [结果展示](#结果展示)\n\n## cpp-httplib库\n\n### cpp-httplib 库介绍\n\ncpp-httplib 是一个轻量级的 C++ HTTP 客户端 \u002F 服务器库,由日本开发者 yhirose 开发。它的特点是:\n\n* 单文件设计(**仅需包含 httplib.h 即可使用**)\n* 支持 HTTP 1.1\n* 同时提供客户端和服务器功能\n* 跨平台(Windows、Linux、macOS 等)\n* 无需额外依赖(仅需 C++11 及以上标准)\n* 支持 SSL\u002FTLS(需配合 OpenSSL)\n\n### 常用功能与函数\n\n#### 1. 服务器相关\n\n**创建服务器**\n\n```cpp\nhttplib::Server svr;\n```\n\n**注册路由处理函数**\n\n```cpp\n\u002F\u002F GET 请求处理\nsvr.Get(\"\u002Fhello\", [](const httplib::Request& req, httplib::Response& res) {\n res.set_content(\"Hello World!\", \"text\u002Fplain\");\n});\n\n\u002F\u002F POST 请求处理\nsvr.Post(\"\u002Fsubmit\", [](const httplib::Request& req, httplib::Response& res) {\n \u002F\u002F 处理表单数据 req.body\n res.set_content(\"Received!\", \"text\u002Fplain\");\n});\n```\n\n**启动服务器**\n\n```cpp\n\u002F\u002F 监听 0.0.0.0:8080\nif (svr.listen(\"0.0.0.0\", 8080)) {\n \u002F\u002F 服务器启动成功\n}\n```\n\n**Request 类主要成员**\n\n* method: 请求方法(GET\u002FPOST 等)\n* path: 请求路径\n* body: 请求体内容\n* headers: 请求头集合\n* params: URL 查询参数\n* get_param(key): 获取查询参数\n\n**Response 类主要成员**\n\n* status: 状态码(200, 404 等)\n* body: 响应体内容\n* headers: 响应头集合\n* set_content(content, content_type): 设置响应内容和类型\n* set_header(name, value): 设置响应头\n\n#### 2. 客户端相关\n\n**创建客户端**\n\n```cpp\nhttplib::Client cli(\"http:\u002F\u002Fexample.com\");\n```\n\n**发送 GET 请求**\n\n```cpp\nauto res = cli.Get(\"\u002Fapi\u002Fdata\");\nif (res && res->status == 200) {\n \u002F\u002F 处理响应 res->body\n}\n```\n\n**发送 POST 请求**\n\n```cpp\nhttplib::Params params;\nparams.emplace(\"name\", \"test\");\nparams.emplace(\"value\", \"123\");\n\nauto res = cli.Post(\"\u002Fapi\u002Fsubmit\", params);\n```\n\n**发送带请求体的 POST**\n\n```cpp\nstd::string json_data = R\"({\"key\": \"value\"})\";\nauto res = cli.Post(\"\u002Fapi\u002Fjson\", json_data, \"application\u002Fjson\");\n```\n\n### 下载与使用\n\n#### 下载路径\n\n> GitHub 仓库:https:\u002F\u002Fgithub.com\u002Fyhirose\u002Fcpp-httplib \n>\n> 直接下载头文件:https:\u002F\u002Fraw.githubusercontent.com\u002Fyhirose\u002Fcpp-httplib\u002Fmaster\u002Fhttplib.h\n\n#### 使用方法\n\n1.下载 httplib.h 文件\n\n2.在项目中包含该文件:#include \"httplib.h\"\n\n3.编译时需指定 C++11 及以上标准(如 g++ -std=c++11 main.cpp)\n\n4.若使用 SSL 功能,需定义 CPPHTTPLIB_OPENSSL_SUPPORT 并链接 OpenSSL 库\n\n`5.编译器版本低可能会报错,升级一下编译器即可`\n\n#### 简单示例\n\n下面是一个完整的服务器示例:\n\n```cpp\n#include \"httplib.h\"\n#include \u003Ciostream>\n\nint main() {\n httplib::Server svr;\n\n \u002F\u002F 处理根路径请求\n svr.Get(\"\u002F\", [](const httplib::Request& req, httplib::Response& res) {\n res.set_content(\"\u003Ch1>Hello World!\u003C\u002Fh1>\", \"text\u002Fhtml\");\n });\n\n \u002F\u002F 处理带参数的请求\n svr.Get(\"\u002Fgreet\", [](const httplib::Request& req, httplib::Response& res) {\n auto name = req.get_param_value(\"name\");\n if (name.empty()) {\n res.status = 400;\n res.set_content(\"Name parameter is required\", \"text\u002Fplain\");\n } else {\n res.set_content(\"Hello, \" + name + \"!\", \"text\u002Fplain\");\n }\n });\n\n std::cout \u003C\u003C \"Server running on http:\u002F\u002Flocalhost:8080\" \u003C\u003C std::endl;\n svr.listen(\"localhost\", 8080);\n \n return 0;\n}\n```\n\n这个库非常适合快速开发小型 HTTP 服务或客户端,由于其轻量性和易用性,在 C++ 社区中非常受欢迎。\n\n## 网页模块\n\n### 仿照其它成熟搜索页面\n\n**这是一个大公司建立的成熟的搜索页面,我们写的可以仿照着来。\n**\n****经过搜索之后,网页地址上会带上搜索的关键词,从而到数据库内部或者其它建立好的搜索模块中查找,在通过网页映射出来。**\n**\n### 编写主程序入口\n*** ** * ** ***\n**当外部通过网页访问建立好的端口的时候,搜索模块会初始化一次,文档是已经建立好的,先绑定主网页html的路径,然后注册Get方法,网页访问\u002Fs的时候实用?word=来带参数,从而出发搜索模块的查找,然后把结果json串返回给浏览器。启动后绑定host和端口号,则开始运行。\n\n```cpp\n#include \"Log.hpp\"\n#include \"common.h\"\n#include \"Parser.h\"\n#include \"Search.hpp\"\n#include \"httplib.h\"\n#include \u003Ccstdio>\n#include \u003Ccstring>\n#include \u003Cstring>\nconst bool INIT = false;\nint main()\n{\nif(INIT)\n{\nParser parser(Orignaldir, Tragetfile);\nparser.Init();\n}\nns_search::Search search;\nhttplib::Server svr;\nsvr.set_base_dir(Basewwwroot);\nsvr.Get(\"\u002Fs\", [&](const httplib::Request& req, httplib::Response& rep){\nstd::string param = \"word\";\nstd::string word;\nstd::string out;\nout.clear();\nif(req.has_param(param))\n{\nword = req.get_param_value(param);\nLog(LogModule::DEBUG) \u003C\u003C \"查找关键词:\" \u003C\u003C word;\n}\n\u002F\u002F rep.set_content(\"Search: \" + word, \"text\u002Fplain\");\nbool b = search.SearchBy(word, out);\nif(b)\nrep.set_content(out, \"application\u002Fjson\");\nelse\nLog(DEBUG) \u003C\u003C \"查找失败\";\n});\nsvr.listen(\"0.0.0.0\", 8080);\nreturn 0;\n}\n```\n### 编写网页\n**编写网页是从一个大概的框架开始先写主要部分,再用css美化,然后注册相关函数。**\n**```text\n\u003C!DOCTYPE html>\n\u003Chtml lang=\"zh-CN\">\n\u003Chead>\n\u003Cmeta charset=\"UTF-8\">\n\u003Cmeta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\n\u003Ctitle>Boost搜索引擎\u003C\u002Ftitle>\n\u003Cscript src=\"https:\u002F\u002Fapps.bdimg.com\u002Flibs\u002Fjquery\u002F2.1.4\u002Fjquery.min.js\">\u003C\u002Fscript>\n\u003Cstyle>\n* {\nmargin: 0;\npadding: 0;\nbox-sizing: border-box;\n}\nhtml, body {\nheight: 100%;\nfont-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;\nbackground-color: #f5f7fa;\n}\n.container {\nmax-width: 1000px;\nmargin: 0 auto;\npadding: 20px;\n}\n.header {\ntext-align: center;\nmargin-bottom: 30px;\n}\n.header h1 {\ncolor: #2c3e50;\nfont-size: 2.5rem;\nmargin-bottom: 10px;\n}\n.header p {\ncolor: #7f8c8d;\nfont-size: 1.1rem;\n}\n.search-box {\ndisplay: flex;\nmargin-bottom: 30px;\nbox-shadow: 0 4px 12px rgba(0, 0, 0, 0.1);\nborder-radius: 8px;\noverflow: hidden;\n}\n.search-box input {\nflex: 1;\nheight: 60px;\npadding: 0 20px;\nborder: none;\nfont-size: 1.2rem;\nbackground-color: white;\n}\n.search-box input:focus {\noutline: none;\nbackground-color: #f8f9fa;\n}\n.search-box button {\nwidth: 140px;\nheight: 60px;\nborder: none;\nbackground-color: #3498db;\ncolor: white;\nfont-size: 1.2rem;\ncursor: pointer;\ntransition: background-color 0.3s;\n}\n.search-box button:hover {\nbackground-color: #2980b9;\n}\n.intro {\nbackground-color: white;\npadding: 20px;\nborder-radius: 8px;\nmargin-bottom: 20px;\nbox-shadow: 0 2px 8px rgba(0, 0, 0, 0.05);\n}\n.intro h2 {\ncolor: #2c3e50;\nmargin-bottom: 10px;\n}\n.results-container {\ndisplay: none; \u002F* 初始隐藏,有结果时显示 *\u002F\n}\n.result-item {\nbackground-color: white;\npadding: 20px;\nborder-radius: 8px;\nmargin-bottom: 15px;\nbox-shadow: 0 2px 8px rgba(0, 0, 0, 0.05);\ntransition: transform 0.2s, box-shadow 0.2s;\n}\n.result-item:hover {\ntransform: translateY(-2px);\nbox-shadow: 0 4px 12px rgba(0, 0, 0, 0.1);\n}\n.result-title {\nfont-size: 1.3rem;\ncolor: #3498db;\nmargin-bottom: 10px;\ntext-decoration: none;\ndisplay: block;\n}\n.result-title:hover {\ntext-decoration: underline;\n}\n.result-desc {\ncolor: #5a6c7d;\nline-height: 1.5;\nmargin-bottom: 10px;\n}\n.result-url {\ncolor: #95a5a6;\nfont-size: 0.9rem;\nfont-style: italic;\n}\n.no-results {\ntext-align: center;\npadding: 40px;\ncolor: #7f8c8d;\nbackground-color: white;\nborder-radius: 8px;\nbox-shadow: 0 2px 8px rgba(0, 0, 0, 0.05);\n}\n.loading {\ntext-align: center;\npadding: 30px;\ncolor: #3498db;\n}\n.footer {\ntext-align: center;\nmargin-top: 40px;\ncolor: #95a5a6;\nfont-size: 0.9rem;\n}\n@media (max-width: 600px) {\n.container {\npadding: 10px;\n}\n.search-box {\nflex-direction: column;\n}\n.search-box input {\nheight: 50px;\nborder-radius: 8px 8px 0 0;\n}\n.search-box button {\nwidth: 100%;\nheight: 50px;\nborder-radius: 0 0 8px 8px;\n}\n}\n\u003C\u002Fstyle>\n\u003C\u002Fhead>\n\u003Cbody>\n\u003Cdiv class=\"container\">\n\u003Cdiv class=\"header\">\n\u003Ch1>Boost搜索引擎\u003C\u002Fh1>\n\u003Cp>基于正倒排索引的高效文档检索系统\u003C\u002Fp>\n\u003C\u002Fdiv>\n\u003Cdiv class=\"search-box\">\n\u003Cinput type=\"text\" id=\"search-input\" placeholder=\"请输入搜索关键词...\">\n\u003Cbutton id=\"search-btn\">搜索\u003C\u002Fbutton>\n\u003C\u002Fdiv>\n\u003Cdiv class=\"intro\" id=\"intro\">\n\u003Ch2>欢迎使用Boost搜索引擎\u003C\u002Fh2>\n\u003Cp>这是一个基于C++和Boost库实现的搜索引擎,采用正倒排索引技术,提供高效的文档检索功能。\u003C\u002Fp>\n\u003Cp>在搜索框中输入关键词,点击搜索按钮即可查找相关文档。\u003C\u002Fp>\n\u003C\u002Fdiv>\n\u003Cdiv class=\"results-container\" id=\"results-container\">\n\u003C!-- 搜索结果将在这里动态生成 -->\n\u003C\u002Fdiv>\n\u003C\u002Fdiv>\n\u003Cscript>\n$(document).ready(function() {\n\u002F\u002F 绑定搜索按钮点击事件\n$('#search-btn').click(performSearch);\n\u002F\u002F 绑定输入框回车键事件\n$('#search-input').keypress(function(e) {\nif (e.which === 13) {\nperformSearch();\n}\n});\n\u002F\u002F 初始显示介绍内容\n$('#intro').show();\n});\nfunction performSearch() {\nconst searchInput = $('#search-input');\nconst keywords = searchInput.val().trim();\nif (!keywords) {\nalert('请输入搜索关键词');\nreturn;\n}\n\u002F\u002F 隐藏介绍内容\n$('#intro').hide();\n\u002F\u002F 显示结果容器和加载提示\nconst resultsContainer = $('#results-container');\nresultsContainer.show().html('\u003Cdiv class=\"loading\">搜索中,请稍候...\u003C\u002Fdiv>');\n\u002F\u002F 发送搜索请求\n$.ajax({\nurl: \"\u002Fs?word=\" + encodeURIComponent(keywords),\ntype: \"GET\",\ndataType: \"json\",\nsuccess: function(data) {\nbuildResults(data);\n},\nerror: function(xhr) {\nconsole.log(\"error\", xhr.status);\nresultsContainer.html('\u003Cdiv class=\"no-results\">搜索失败,请稍后重试\u003C\u002Fdiv>');\n}\n});\n}\nfunction buildResults(data) {\nconst resultsContainer = $('#results-container');\n\u002F\u002F 清空之前的结果\nresultsContainer.empty();\nif (!data || data.length === 0) {\nresultsContainer.html('\u003Cdiv class=\"no-results\">未找到相关结果,请尝试其他关键词\u003C\u002Fdiv>');\nreturn;\n}\n\u002F\u002F 构建结果列表\ndata.forEach(function(item, index) {\nconst resultItem = $('\u003Cdiv>', { class: 'result-item' });\nconst title = $('\u003Ca>', {\nclass: 'result-title',\nhref: item.url || '#',\ntext: item.title || '无标题',\ntarget: '_blank'\n});\nconst desc = $('\u003Cdiv>', {\nclass: 'result-desc',\ntext: item.desc || '无描述信息'\n});\nconst url = $('\u003Cdiv>', {\nclass: 'result-url',\ntext: item.url || '无URL信息'\n});\nresultItem.append(title).append(desc).append(url);\nresultsContainer.append(resultItem);\n});\n}\n\u003C\u002Fscript>\n\u003C\u002Fbody>\n\u003C\u002Fhtml>\n```\n## 完整代码\n### common.h\n```cpp\n#pragma once\n#include \u003Ciostream>\n#include \u003Cstring>\n#include \u003Cvector>\n#include \u003Ccstddef>\n#include \"Log.hpp\"\nusing std::cout;\nusing std::endl;\nusing namespace LogModule;\nconst std::string Boost_Url_Head = \"https:\u002F\u002Fwww.boost.org\u002Fdoc\u002Flibs\u002F1_89_0\u002Fdoc\u002Fhtml\";\n\u002F\u002F const std::string Boost_Url_Head = \"..\u002FData\u002Fhtml\";\nconst std::string Basewwwroot = \".\u002Fwwwroot\";\nconst std::string Orignaldir = \"..\u002FData\u002Fhtml\";\nconst std::string Tragetfile = \"..\u002FData\u002Foutput.txt\";\nconst std::string Output_sep = \"\\3\";\nconst std::string Line_sep = \"\\n\";\n\u002F\u002F 定义词典路径(根据实际路径修改)\nconst std::string DICT_PATH = \"dict\u002Fjieba.dict.utf8\";\nconst std::string HMM_PATH = \"dict\u002Fhmm_model.utf8\";\nconst std::string USER_DICT_PATH = \"dict\u002Fuser.dict.utf8\";\nconst std::string IDF_PATH = \"dict\u002Fidf.utf8\";\nconst std::string STOP_WORD_PATH = \"dict\u002Fstop_words.utf8\";\n\u002F\u002F 不可复制基类\nclass NonCopyable {\nprotected:\n\u002F\u002F 允许派生类构造和析构\nNonCopyable() = default;\n~NonCopyable() = default;\n\u002F\u002F 禁止移动操作(可选,根据需求决定)\n\u002F\u002F NonCopyable(NonCopyable&&) = delete;\n\u002F\u002F NonCopyable& operator=(NonCopyable&&) = delete;\nprivate:\n\u002F\u002F 禁止拷贝构造和拷贝赋值\nNonCopyable(const NonCopyable&) = delete;\nNonCopyable& operator=(const NonCopyable&) = delete;\n};\n```\n### Index.hpp\n```cpp\n#pragma once\n#include \"Log.hpp\"\n#include \"Util.hpp\"\n#include \"common.h\"\n#include \u003Cboost\u002Falgorithm\u002Fstring\u002Fcase_conv.hpp>\n#include \u003Ccstddef>\n#include \u003Ccstring>\n#include \u003Cfstream>\n#include \u003Cstring>\n#include \u003Cunistd.h>\n#include \u003Cunordered_map>\n#include \u003Cutility>\n#include \u003Cvector>\nnamespace ns_index\n{\n\u002F\u002F正排索引\ntypedef struct ForwordElem\n{\nstd::string title_;\nstd::string content_;\nstd::string url_;\nsize_t doc_id_ = 0;\nvoid Set(std::string title, std::string content, std::string url, size_t doc_id)\n{\ntitle_ = title;\ncontent_ = content;\nurl_ = url;\ndoc_id_ = doc_id;\n}\n}Forword_t;\ntypedef struct InvertedElem\n{\nsize_t doc_id_ = 0;\nstd::string word_;\nsize_t weight_ = 0;\nvoid Set(size_t doc_id, std::string word, size_t weight)\n{\ndoc_id_ = doc_id;\nword_ = word;\nweight_ = weight;\n}\n}Inverted_t;\ntypedef std::vector\u003CInverted_t> InvertedList;\nclass Index : public NonCopyable\n{\nprivate:\nIndex() = default;\npublic:\nstatic Index* GetInstance()\n{\nstatic Index index;\nreturn &index;\n}\npublic:\nForword_t* QueryById(size_t id)\n{\nif(id \u003C 0 || id >= Forword_Index_.size())\n{\nLog(LogModule::DEBUG) \u003C\u003C \"id invalid!\";\nreturn nullptr;\n}\nreturn &Forword_Index_[id];\n}\nInvertedList* QueryByWord(std::string word)\n{\nauto it = Inverted_Index_.find(word);\nif(it == Inverted_Index_.end())\n{\n\u002F\u002FLog(LogModule::DEBUG) \u003C\u003C word \u003C\u003C \" find fail!\";\nreturn nullptr;\n}\nreturn &it->second;\n}\nsize_t count = 0;\nbool BulidIndex()\n{\nif(isInit_)\nreturn false;\nsize_t estimated_doc = 10000;\nsize_t estimeted_words = 100000;\nForword_Index_.reserve(estimated_doc);\nInverted_Index_.reserve(estimeted_words);\nstd::ifstream in(Tragetfile, std::ios::binary | std::ios::in);\nif(!in.is_open())\n{\nLog(LogModule::ERROR) \u003C\u003C \"Targetfile open fail!BulidIndex fail!\";\nreturn false;\n}\nLog(LogModule::INFO) \u003C\u003C \"索引开始预加载...\";\nstd::string singlefile;\nwhile (std::getline(in, singlefile))\n{\nbool b = BuildForwordIndex(singlefile);\nif(!b)\n{\nLog(LogModule::DEBUG) \u003C\u003C \"Build Forword Index Error!\";\ncontinue;\n}\nb = BuildInvertedIndex(Forword_Index_.size() - 1);\nif(!b)\n{\nLog(LogModule::DEBUG) \u003C\u003C \"Build Inverted Index Error!\";\ncontinue;\n}\ncount++;\nif(count % 1000 == 0)\n{\nLog(LogModule::INFO) \u003C\u003C \"索引文件加载中,当前进度:\" \u003C\u003C count;\n\u002F\u002Fdebug\n\u002F\u002Fbreak;\n}\n}\nin.close();\nisInit_ = true;\nLog(LogModule::INFO) \u003C\u003C \"索引加载完毕!已加载-\" \u003C\u003C count \u003C\u003C \"个文件!\";\nreturn true;\n}\n~Index() = default;\nprivate:\ntypedef struct DocCount\n{\nsize_t title_cnt_ = 0;\nsize_t content_cnt_ = 0;\n}DocCount_t;\nbool BuildForwordIndex(std::string& singlefile)\n{\nsepfile.clear();\nbool b = ns_util::JiebaUtile::CutDoc(singlefile, sepfile);\nif(!b)\nreturn false;\n\u002F\u002F if(count == 764)\n\u002F\u002F {\n\u002F\u002F Log(LogModule::DEBUG) \u003C\u003C \"Index Url: \" \u003C\u003C sepfile[2];\n\u002F\u002F }\nif(sepfile.size() != 3)\n{\nLog(LogModule::DEBUG) \u003C\u003C \"Segmentation fail!\";\nreturn false;\n}\nForword_t ft;\nft.Set(std::move(sepfile[0]), std::move(sepfile[1])\n, std::move(sepfile[2]), Forword_Index_.size());\n\u002F\u002F if(count == 764)\n\u002F\u002F {\n\u002F\u002F Log(LogModule::DEBUG) \u003C\u003C \"Index Url: \" \u003C\u003C ft.url_;\n\u002F\u002F }\nForword_Index_.push_back(std::move(ft));\nreturn true;\n}\nbool BuildInvertedIndex(size_t findex)\n{\nForword_t ft = Forword_Index_[findex];\nstd::unordered_map\u003Cstd::string, DocCount_t> map_s;\ntitlesegmentation.clear();\nns_util::JiebaUtile::CutPhrase(ft.title_, titlesegmentation);\nfor(auto& s : titlesegmentation)\n{\nboost::to_lower(s);\nmap_s[s].title_cnt_++;\n}\ncontentsegmentation.clear();\nns_util::JiebaUtile::CutPhrase(ft.content_, contentsegmentation);\nfor(auto& s : contentsegmentation)\n{\nboost::to_lower(s);\nmap_s[s].content_cnt_++;\n\u002F\u002Fcout \u003C\u003C s \u003C\u003C \"--\";\n\u002F\u002F if(strcmp(s.c_str(), \"people\") == 0)\n\u002F\u002F {\n\u002F\u002F Log(LogModule::DEBUG) \u003C\u003C \"意外的people!\";\n\u002F\u002F cout \u003C\u003C ft.content_ \u003C\u003C \"------------end!\";\n\u002F\u002F sleep(100);\n\u002F\u002F }\n}\nconst int X = 10;\nconst int Y = 1;\nfor(auto& p : map_s)\n{\nInverted_t it;\nit.Set(findex, p.first\n, p.second.title_cnt_ * X + p.second.content_cnt_ * Y);\nInvertedList& list = Inverted_Index_[p.first];\nlist.push_back(std::move(it));\n}\nreturn true;\n}\nprivate:\nstd::vector\u003CForword_t> Forword_Index_;\nstd::unordered_map\u003Cstd::string, InvertedList> Inverted_Index_;\nbool isInit_ = false;\n\u002F\u002F内存复用,优化时间\nstd::vector\u003Cstd::string> sepfile;\nstd::vector\u003Cstd::string> titlesegmentation;\nstd::vector\u003Cstd::string> contentsegmentation;\n};\n};\n```\n### Log.hpp\n```cpp\n#ifndef __LOG_HPP__\n#define __LOG_HPP__\n#include \u003Ciostream>\n#include \u003Cctime>\n#include \u003Cstring>\n#include \u003Cpthread.h>\n#include \u003Csstream>\n#include \u003Cfstream>\n#include \u003Cfilesystem>\n#include \u003Cunistd.h>\n#include \u003Cmemory>\n#include \u003Cmutex>\nnamespace LogModule\n{\nconst std::string default_path = \".\u002Flog\u002F\";\nconst std::string default_file = \"log.txt\";\nenum LogLevel\n{\nDEBUG,\nINFO,\nWARNING,\nERROR,\nFATAL\n};\nstatic std::string LogLevelToString(LogLevel level)\n{\nswitch (level)\n{\ncase DEBUG:\nreturn \"DEBUG\";\ncase INFO:\nreturn \"INFO\";\ncase WARNING:\nreturn \"WARNING\";\ncase ERROR:\nreturn \"ERROR\";\ncase FATAL:\nreturn \"FATAL\";\ndefault:\nreturn \"UNKNOWN\";\n}\n}\nstatic std::string GetCurrentTime()\n{\nstd::time_t time = std::time(nullptr);\nstruct tm stm;\nlocaltime_r(&time, &stm);\nchar buff[128];\nsnprintf(buff, sizeof(buff), \"%4d-%02d-%02d-%02d-%02d-%02d\",\nstm.tm_year + 1900,\nstm.tm_mon + 1,\nstm.tm_mday,\nstm.tm_hour,\nstm.tm_min,\nstm.tm_sec);\nreturn buff;\n}\nclass Logstrategy\n{\npublic:\nvirtual ~Logstrategy() = default;\nvirtual void syncLog(std::string &message) = 0;\n};\nclass ConsoleLogstrategy : public Logstrategy\n{\npublic:\nvoid syncLog(std::string &message) override\n{\nstd::cerr \u003C\u003C message \u003C\u003C std::endl;\n}\n~ConsoleLogstrategy() override\n{\n}\n};\nclass FileLogstrategy : public Logstrategy\n{\npublic:\nFileLogstrategy(std::string filepath = default_path, std::string filename = default_file)\n{\n_mutex.lock();\n_filepath = filepath;\n_filename = filename;\nif (std::filesystem::exists(filepath)) \u002F\u002F 检测目录是否存在,存在则返回\n{\n_mutex.unlock();\nreturn;\n}\ntry\n{\n\u002F\u002F 不存在则递归创建(复数)目录\nstd::filesystem::create_directories(filepath);\n}\ncatch (const std::filesystem::filesystem_error &e)\n{\n\u002F\u002F 捕获异常并打印\nstd::cerr \u003C\u003C e.what() \u003C\u003C '\\n';\n}\n_mutex.unlock();\n}\nvoid syncLog(std::string &message) override\n{\n_mutex.lock();\nstd::string path =\n_filepath.back() == '\u002F' ? _filepath + _filename : _filepath + \"\u002F\" + _filename;\nstd::ofstream out(path, std::ios::app);\nif (!out.is_open())\n{\n_mutex.unlock();\nstd::cerr \u003C\u003C \"file open fail!\" \u003C\u003C '\\n';\nreturn;\n}\nout \u003C\u003C message \u003C\u003C '\\n';\n_mutex.unlock();\nout.close();\n}\n~FileLogstrategy()\n{\n}\nprivate:\nstd::string _filepath;\nstd::string _filename;\nstd::mutex _mutex;\n};\nclass Log\n{\npublic:\nLog()\n{\n_logstrategy = std::make_unique\u003CConsoleLogstrategy>();\n}\nvoid useconsolestrategy()\n{\n_logstrategy = std::make_unique\u003CConsoleLogstrategy>();\nprintf(\"转换控制台策略!\\n\");\n}\nvoid usefilestrategy()\n{\n_logstrategy = std::make_unique\u003CFileLogstrategy>();\nprintf(\"转换文件策略!\\n\");\n}\nclass LogMessage\n{\npublic:\nLogMessage(LogLevel level, std::string file, int line, Log &log)\n: _loglevel(level)\n, _time(GetCurrentTime())\n, _file(file), _pid(getpid())\n, _line(line),\n_log(log)\n{\nstd::stringstream ss;\nss \u003C\u003C \"[\" \u003C\u003C _time \u003C\u003C \"] \"\n\u003C\u003C \"[\" \u003C\u003C LogLevelToString(_loglevel) \u003C\u003C \"] \"\n\u003C\u003C \"[\" \u003C\u003C _pid \u003C\u003C \"] \"\n\u003C\u003C \"[\" \u003C\u003C _file \u003C\u003C \"] \"\n\u003C\u003C \"[\" \u003C\u003C _line \u003C\u003C \"] \"\n\u003C\u003C \"- \";\n_loginfo = ss.str();\n}\ntemplate \u003Ctypename T>\nLogMessage &operator\u003C\u003C(const T &t)\n{\nstd::stringstream ss;\nss \u003C\u003C _loginfo \u003C\u003C t;\n_loginfo = ss.str();\n\u002F\u002Fprintf(\"重载\u003C\u003CLogmessage!\\n\");\nreturn *this;\n}\n~LogMessage()\n{\n\u002F\u002Fprintf(\"析构函数\\n\");\nif (_log._logstrategy)\n{\n\u002F\u002Fprintf(\"调用打印.\\n\");\n_log._logstrategy->syncLog(_loginfo);\n}\n}\nprivate:\nLogLevel _loglevel;\nstd::string _time;\npid_t _pid;\nstd::string _file;\nint _line;\nstd::string _loginfo;\nLog &_log;\n};\nLogMessage operator()(LogLevel level, std::string filename, int line)\n{\nreturn LogMessage(level, filename, line, *this);\n}\n~Log()\n{\n}\nprivate:\nstd::unique_ptr\u003CLogstrategy> _logstrategy;\n};\nstatic Log logger;\n#define Log(type) logger(type, __FILE__, __LINE__)\n#define ENABLE_LOG_CONSOLE_STRATEGY() logger.useconsolestrategy()\n#define ENABLE_LOG_FILE_STRATEGY() logger.usefilestrategy()\n}\n#endif\n```\n### main.cc\n```cpp\n#include \"Log.hpp\"\n#include \"common.h\"\n#include \"Parser.h\"\n#include \"Search.hpp\"\n#include \"httplib.h\"\n#include \u003Ccstdio>\n#include \u003Ccstring>\n#include \u003Cstring>\nconst bool INIT = false;\nint main()\n{\nif(INIT)\n{\nParser parser(Orignaldir, Tragetfile);\nparser.Init();\n}\nns_search::Search search;\nhttplib::Server svr;\nsvr.set_base_dir(Basewwwroot);\nsvr.Get(\"\u002Fs\", [&](const httplib::Request& req, httplib::Response& rep){\nstd::string param = \"word\";\nstd::string word;\nstd::string out;\nout.clear();\nif(req.has_param(param))\n{\nword = req.get_param_value(param);\nLog(LogModule::DEBUG) \u003C\u003C \"查找关键词:\" \u003C\u003C word;\n}\n\u002F\u002F rep.set_content(\"Search: \" + word, \"text\u002Fplain\");\nbool b = search.SearchBy(word, out);\nif(b)\nrep.set_content(out, \"application\u002Fjson\");\nelse\nLog(DEBUG) \u003C\u003C \"查找失败\";\n});\nsvr.listen(\"0.0.0.0\", 8080);\nreturn 0;\n}\n```\n### makefile\n```cpp\n# 编译器设置\nCXX := g++\nCXXFLAGS := -std=c++17\nLDFLAGS :=\nLIBS := -lboost_filesystem -lboost_system -ljsoncpp\n# 目录设置\nSRC_DIR := .\nBUILD_DIR := build\nTARGET := main\n# 自动查找源文件\nSRCS := $(wildcard $(SRC_DIR)\u002F*.cc)\nOBJS := $(SRCS:$(SRC_DIR)\u002F%.cc=$(BUILD_DIR)\u002F%.o)\nDEPS := $(OBJS:.o=.d)\n# 确保头文件依赖被包含\n-include $(DEPS)\n# 默认目标\nall: $(BUILD_DIR) $(TARGET)\n# 创建构建目录\n$(BUILD_DIR):\n@mkdir -p $(BUILD_DIR)\n# 链接目标文件生成可执行文件\n$(TARGET): $(OBJS)\n$(CXX) $(OBJS) -o $@ $(LDFLAGS) $(LIBS)\n@echo \"✅ 构建完成: $(TARGET)\"\n# 编译每个.cc文件为.o文件\n$(BUILD_DIR)\u002F%.o: $(SRC_DIR)\u002F%.cc\n$(CXX) $(CXXFLAGS) -MMD -MP -c $\u003C -o $@\n# 清理构建文件\nclean:\nrm -rf $(BUILD_DIR) $(TARGET)\n@echo \"🧹 清理完成\"\n# 重新构建\nrebuild: clean all\n# 显示项目信息\ninfo:\n@echo \"📁 源文件: $(SRCS)\"\n@echo \"📦 目标文件: $(OBJS)\"\n@echo \"🎯 最终目标: $(TARGET)\"\n# 伪目标\n.PHONY: all clean rebuild info\n# 防止与同名文件冲突\n.PRECIOUS: $(OBJS)\n```\n### Parser.cc\n```cpp\n#include \"Parser.h\"\n#include \"Log.hpp\"\n#include \"Util.hpp\"\n#include \"common.h\"\n#include \u003Ccstddef>\n#include \u003Cfstream>\n#include \u003Cstring>\n#include \u003Cutility>\nParser::Parser(fs::path Datap, fs::path Targetp)\n{\nOrignalpath_ = Datap;\nTargetpath_ = Targetp;\n}\n\u002F\u002F 初始化:录入html路径------解析html数据------分割写入Data------记录Url\nbool Parser::Init()\n{\nif(!LoadHtmlPath())\n{\nLog(LogModule::DEBUG) \u003C\u003C \"LoadHtmlPath fail!\";\nreturn false;\n}\nif(!ParseHtml())\n{\nLog(LogModule::DEBUG) \u003C\u003C \"ParseHtml fail!\";\nreturn false;\n}\nif(!WriteToTarget())\n{\nLog(LogModule::DEBUG) \u003C\u003C \"WriteToTarget fail!\";\nreturn false;\n}\nreturn true;\n}\nbool Parser::LoadHtmlPath()\n{\nif(!fs::exists(Orignalpath_) || !fs::is_directory(Orignalpath_))\n{\nLog(LogModule::DEBUG) \u003C\u003C \"Orignalpath is not exists or invalid!\";\nreturn false;\n}\nfs::recursive_directory_iterator end_it;\nfs::recursive_directory_iterator it(Orignalpath_);\nfor(; it != end_it; it++)\n{\nif(!it->is_regular_file())\n{\ncontinue;\n}\nif(it->path().extension() != \".html\")\n{\ncontinue;\n}\nhtmlpaths_.push_back(it->path());\n\u002F\u002FLog(DEBUG) \u003C\u003C \"path: \" \u003C\u003C it->path();\n}\nLog(LogModule::DEBUG) \u003C\u003C \"Found \" \u003C\u003C htmlpaths_.size() \u003C\u003C \" HTML files\";\nreturn true;\n}\nbool Parser::ParseHtml()\n{\nif(htmlpaths_.empty())\n{\nLog(LogModule::DEBUG) \u003C\u003C \"paths is empty!\";\nreturn false;\n}\nsize_t successCount = 0;\nfor(fs::path &p : htmlpaths_)\n{\n\u002F\u002F 检查路径是否存在\nif (!fs::exists(p)) {\nLog(LogModule::ERROR) \u003C\u003C \"File not exists: \" \u003C\u003C p.string();\ncontinue;\n}\nstd::string out;\nHtmlInfo_t info;\n\u002F\u002F 读取文件并记录错误\nif(!ns_util::FileUtil::ReadFile(p.string(), &out))\n{\nLog(LogModule::ERROR) \u003C\u003C \"Failed to read file: \" \u003C\u003C p.string();\ncontinue;\n}\n\u002F\u002F 解析标题并记录错误\nif(!ParseTitle(out, &info.title_))\n{\nLog(LogModule::ERROR) \u003C\u003C \"Failed to parse title from: \" \u003C\u003C p.string();\ncontinue;\n}\n\u002F\u002F 解析内容并记录错误\nif(!ParseContent(out, &info.content_))\n{\nLog(LogModule::ERROR) \u003C\u003C \"Failed to parse content from: \" \u003C\u003C p.string();\ncontinue;\n}\n\u002F\u002F 检查URL解析结果\nif(!ParseUrl(p, &info.url_))\n{\nLog(LogModule::ERROR) \u003C\u003C \"Failed to parse URL from: \" \u003C\u003C p.string();\ncontinue;\n}\nhtmlinfos_.push_back(std::move(info));\nsuccessCount++;\n}\n\u002F\u002F 可以根据需要判断是否全部成功或部分成功\nLog(LogModule::INFO) \u003C\u003C \"Parse HTML completed. Success: \" \u003C\u003C successCount\n\u003C\u003C \", Total: \" \u003C\u003C htmlpaths_.size();\nreturn successCount > 0;\n}\nbool Parser::WriteToTarget()\n{\nif(htmlinfos_.empty())\n{\nLog(LogModule::DEBUG) \u003C\u003C \"infos empty!\";\nreturn false;\n}\nfor(HtmlInfo_t &info : htmlinfos_)\n{\noutput_ += info.title_;\noutput_ += Output_sep;\noutput_ += info.content_;\noutput_ += Output_sep;\noutput_ += info.url_;\noutput_ += Line_sep;\n}\nWriteToTargetFile();\nreturn true;\n}\nbool Parser::ParseUrl(fs::path p, std::string *out)\n{\nfs::path head(Boost_Url_Head);\nhead = head \u002F p.string().substr(Orignaldir.size());\n*out = head.string();\n\u002F\u002FLog(LogModule::DEBUG) \u003C\u003C \"filename: \" \u003C\u003C p.filename();\nreturn true;\n}\nbool Parser::ParseTitle(std::string& fdata, std::string* title)\n{\nif(fdata.empty() || title == nullptr)\n{\nLog(LogModule::DEBUG) \u003C\u003C \"parameter invalid!\";\nreturn false;\n}\nsize_t begin = fdata.find(\"\u003Ctitle>\");\nsize_t end = fdata.find(\"\u003C\u002Ftitle>\");\nif(begin == std::string::npos || end == std::string::npos)\n{\nLog(LogModule::DEBUG) \u003C\u003C \"title find fail!\";\nreturn false;\n}\nbegin += std::string(\"\u003Ctitle>\").size();\n*title = fdata.substr(begin, end - begin);\nreturn true;\n}\nbool Parser::ParseContent(std::string& fdata, std::string* content)\n{\nif(fdata.empty() || content == nullptr)\n{\nLog(LogModule::DEBUG) \u003C\u003C \"parameter invalid!\";\nreturn false;\n}\ntypedef enum htmlstatus\n{\nLABEL,\nCONTENT\n}e_hs;\ne_hs statu = LABEL;\nfor(char& c: fdata)\n{\nswitch (c)\n{\ncase '\u003C':\nstatu = LABEL;\nbreak;\ncase '>':\nstatu = CONTENT;\nbreak;\ndefault:\n{\nif(statu == CONTENT)\n*content += (c == '\\n' ? ' ' : c);\n}\nbreak;\n}\n}\nreturn true;\n}\nbool Parser::WriteToTargetFile()\n{\nstd::ofstream out;\ntry\n{\n\u002F\u002F 确保目录存在\nauto parent_path = Targetpath_.parent_path();\nif (!parent_path.empty())\n{\nfs::create_directories(parent_path);\n}\n\u002F\u002F 设置缓冲区(使用更大的缓冲区可能更好)\nconst size_t buffer_size = 128 * 1024; \u002F\u002F 128KB\nstd::unique_ptr\u003Cchar[]> buffer(new char[buffer_size]);\n\u002F\u002F 创建文件流并设置缓冲区\nout.rdbuf()->pubsetbuf(buffer.get(), buffer_size);\n\u002F\u002F 打开文件\nout.open(Targetpath_.string(), std::ios::binary | std::ios::trunc);\nif (!out)\n{\nLog(LogModule::ERROR) \u003C\u003C \"Cannot open file: \" \u003C\u003C Targetpath_.string()\n\u003C\u003C \" - \" \u003C\u003C strerror(errno);\nreturn false;\n}\n\u002F\u002F 写入数据\nif (!output_.empty())\n{\nout.write(output_.data(), output_.size());\nif (out.fail())\n{\nLog(LogModule::ERROR) \u003C\u003C \"Write failed: \" \u003C\u003C Targetpath_.string()\n\u003C\u003C \" - \" \u003C\u003C strerror(errno);\nreturn false;\n}\n}\n\u002F\u002F 显式刷新\nout.flush();\nif (out.fail())\n{\nLog(LogModule::ERROR) \u003C\u003C \"Flush failed: \" \u003C\u003C Targetpath_.string()\n\u003C\u003C \" - \" \u003C\u003C strerror(errno);\nreturn false;\n}\nLog(LogModule::INFO) \u003C\u003C \"Written \" \u003C\u003C output_.size()\n\u003C\u003C \" bytes to \" \u003C\u003C Targetpath_.string();\n}\ncatch (const fs::filesystem_error& e)\n{\nLog(LogModule::ERROR) \u003C\u003C \"Filesystem error: \" \u003C\u003C e.what();\nreturn false;\n}\ncatch (const std::exception& e)\n{\nLog(LogModule::ERROR) \u003C\u003C \"Unexpected error: \" \u003C\u003C e.what();\nreturn false;\n}\n\u002F\u002F 确保文件关闭(RAII会处理,但显式关闭更好)\nif (out.is_open())\n{\nout.close();\n}\nreturn true;\n}\n```\n### Parser.h\n```cpp\n#pragma once\n\u002F\u002F 包含公共头文件,可能包含一些全局定义、类型别名或常用工具函数\n#include \"common.h\"\n\u002F\u002F 包含Boost文件系统库相关头文件,用于文件和目录操作\n#include \"boost\u002Ffilesystem.hpp\"\n#include \u003Cboost\u002Ffilesystem\u002Fdirectory.hpp>\n#include \u003Cboost\u002Ffilesystem\u002Fpath.hpp>\n\u002F\u002F 包含vector容器头文件,用于存储路径和HTML信息列表\n#include \u003Cvector>\n\u002F\u002F 为boost::filesystem定义别名别名fs,简化代码书写\nnamespace fs = boost::filesystem;\n\u002F\u002F HTML信息结构体,用于存储解析后的HTML文档关键信息\ntypedef struct HtmlInfo\n{\nstd::string title_; \u002F\u002F 存储HTML文档的标题\nstd::string content_; \u002F\u002F 存储HTML文档的正文内容(去标签后)\nstd::string url_; \u002F\u002F 存储HTML文档的URL或来源路径\n}HtmlInfo_t; \u002F\u002F 定义结构体别名HtmlInfo_t,方便使用\nclass Parser\n{\nprivate:\n\u002F\u002F 解析HTML内容,提取标题并存储到title指针指向的字符串\n\u002F\u002F 参数:fdata-HTML原始数据,title-输出的标题字符串指针\n\u002F\u002F 返回值:bool-解析成功返回true,失败返回false\nbool ParseTitle(std::string& fdata, std::string* title);\n\u002F\u002F 解析HTML内容,提取正文(去除标签后)并存储到content指针指向的字符串\n\u002F\u002F 参数:fdata-HTML原始数据,content-输出的正文内容字符串指针\n\u002F\u002F 返回值:bool-解析成功返回true,失败返回false\nbool ParseContent(std::string& fdata, std::string* content);\n\u002F\u002F 将解析后的HTML信息写入目标文件(内部实现)\n\u002F\u002F 返回值:bool-写入成功返回true,失败返回false\nbool WriteToTargetFile();\npublic:\n\u002F\u002F 构造函数,初始化原始数据路径和目标存储路径\n\u002F\u002F 参数:Datap-原始HTML文件所在路径,Targetp-解析后数据的存储路径\nParser(fs::path Datap, fs::path Targetp);\n\u002F\u002F 初始化函数:加载HTML路径→解析HTML数据→分割写入数据→记录URL\n\u002F\u002F 整合了整个解析流程的入口函数\n\u002F\u002F 返回值:bool-初始化成功返回true,失败返回false\nbool Init();\n\u002F\u002F 加载所有HTML文件的路径到htmlpaths_容器中\n\u002F\u002F 返回值:bool-加载成功返回true,失败返回false\nbool LoadHtmlPath();\n\u002F\u002F 解析HTML文件:读取文件内容,提取标题、正文和URL\n\u002F\u002F 将解析结果存储到htmlinfos_容器中\n\u002F\u002F 返回值:bool-解析成功返回true,失败返回false\nbool ParseHtml();\n\u002F\u002F 对外接口:将解析后的HTML信息写入目标文件(调用内部WriteToTargetFile)\n\u002F\u002F 返回值:bool-写入成功返回true,失败返回false\nbool WriteToTarget();\n\u002F\u002F 解析文件路径p,生成对应的URL信息并存储到out指针指向的字符串\n\u002F\u002F 参数:p-文件路径,out-输出的URL字符串指针\n\u002F\u002F 返回值:bool-解析成功返回true,失败返回false\nbool ParseUrl(fs::path p, std::string* out);\n\u002F\u002F 默认析构函数,无需额外资源释放\n~Parser() = default;\nprivate:\nstd::vector\u003Cfs::path> htmlpaths_; \u002F\u002F 存储所有待解析的HTML文件路径\nstd::vector\u003CHtmlInfo_t> htmlinfos_; \u002F\u002F 存储解析后的所有HTML信息\nstd::string output_; \u002F\u002F 可能用于临时存储输出数据\nfs::path Orignalpath_; \u002F\u002F 原始HTML文件所在的根路径\nfs::path Targetpath_; \u002F\u002F 解析后数据的目标存储路径\n};\n```\n### Search.hpp\n```cpp\n#pragma once\n#include \"Log.hpp\"\n#include \"Util.hpp\"\n#include \"common.h\"\n#include \"Index.hpp\"\n#include \u003Calgorithm>\n#include \u003Ccctype>\n#include \u003Ccstddef>\n#include \u003Ccstdio>\n#include \u003Cctime>\n#include \u003Cjsoncpp\u002Fjson\u002Fjson.h>\n#include \u003Cstring>\n#include \u003Cunistd.h>\n#include \u003Cunordered_map>\n#include \u003Cvector>\nnamespace ns_search\n{\n\u002F\u002F查找关键词文档归总\ntypedef struct DocSumup\n{\nsize_t doc_id_ = 0;\nsize_t weight_ = 0;\nstd::vector\u003Cstd::string> words_;\n}DocSumup_t;\nclass Search : NonCopyable\n{\npublic:\nSearch() : index(ns_index::Index::GetInstance())\n{\nindex->BulidIndex();\n}\nbool SearchBy(std::string keywords, std::string& out)\n{\n\u002F\u002F分词\nstd::vector\u003Cstd::string> Segmentation;\nns_util::JiebaUtile::CutPhrase(keywords, Segmentation);\n\u002F\u002F查找\nstd::vector\u003CDocSumup_t> inverted_elem_all;\nstd::unordered_map\u003Csize_t, DocSumup_t> doc_map;\n\u002F\u002Fdebug\n\u002F\u002F for(auto& e : Segmentation)\n\u002F\u002F {\n\u002F\u002F cout \u003C\u003C e \u003C\u003C \" - \" ;\n\u002F\u002F }\n\u002F\u002Fcout \u003C\u003C endl;\n\u002F\u002Fdebug\nfor(auto& word : Segmentation)\n{\nstatic size_t t = 0;\nns_index::InvertedList* list = index->QueryByWord(word);\nif(list == nullptr)\n{\n\u002F\u002FLog(LogModule::DEBUG) \u003C\u003C word \u003C\u003C \"-not find!\";\n\u002F\u002Fsleep(1);\ncontinue;\n}\n\u002F\u002Fcout \u003C\u003C t \u003C\u003C \"次循环,\" \u003C\u003C word \u003C\u003C \"-找到\" \u003C\u003C endl;\nfor(ns_index::InvertedElem e : *list)\n{\ndoc_map[e.doc_id_].doc_id_ = e.doc_id_;\ndoc_map[e.doc_id_].weight_ += e.weight_;\ndoc_map[e.doc_id_].words_.push_back(e.word_);\n}\n}\n\u002F\u002F哈稀表的内容插入整体数组\nfor(auto& e : doc_map)\n{\ninverted_elem_all.push_back(std::move(e.second));\n}\n\u002F\u002F判断是否找到\nif(inverted_elem_all.empty())\n{\nLog(LogModule::INFO) \u003C\u003C \"-\" \u003C\u003C keywords \u003C\u003C \"-Not Find!\";\nreturn false;\n}\nelse\n{\nLog(LogModule::DEBUG) \u003C\u003C \"已找到\" \u003C\u003C inverted_elem_all.size() \u003C\u003C \"个文件相关!\" ;\n}\n\u002F\u002F权重排序\nstd::sort(inverted_elem_all.begin(), inverted_elem_all.end()\n,[](DocSumup_t i1, DocSumup_t i2)-> bool{\nreturn i1.weight_ == i2.weight_ ? i1.doc_id_ \u003C i2.doc_id_ : i1.weight_ > i2.weight_;\n});\n\u002F\u002F写入json串\nfor(DocSumup_t& e : inverted_elem_all)\n{\nJson::Value tempvalue;\ntempvalue[\"doc_id\"] = e.doc_id_;\ntempvalue[\"weight\"] = e.weight_;\nns_index::Forword_t* ft = index->QueryById(e.doc_id_);\nif(!ft)\n{\nLog(DEBUG) \u003C\u003C e.doc_id_ \u003C\u003C \"-id not find!\";\n\u002F\u002Fsleep(1);\ncontinue;\n}\ntempvalue[\"url\"] = ft->url_;\ntempvalue[\"title\"] = ft->title_;\ntempvalue[\"desc\"] = ExtractDesc(ft->content_, e.words_[0]);\ntempvalue[\"word\"] = keywords;\nroot.append(tempvalue);\n}\n\u002F\u002F写入字符串带出参数\nJson::StyledWriter writer;\nout = writer.write(root);\n\u002F\u002F 每次搜索完,都把这个root的内容清空一下\nroot.clear();\nreturn true;\n}\nprivate:\nstd::string ExtractDesc(std::string& content, std::string word)\n{\nauto it = std::search(content.begin(),content.end(),\nword.begin(),word.end(),\n[](char a, char b)->bool{\nreturn std::tolower(a) == std::tolower(b);\n});\nif(it == content.end())\n{\nLog(LogModule::DEBUG) \u003C\u003C \"ExtractDesc fail!\";\nreturn \"NONE!\";\n}\nconst int pre_step = 50;\nconst int back_step = 100;\nint pos = it - content.begin();\nint start = pos - pre_step > 0 ? pos - pre_step : 0;\nint end = pos + back_step >= content.size() ? content.size() - 1 : pos + back_step;\nreturn content.substr(start, end - start) + std::string(\"...\");\n}\npublic:\n~Search() = default;\nprivate:\nJson::Value root;\nns_index::Index* index;\n};\n};\n```\n### Util.hpp\n```cpp\n#pragma once\n#include \"Log.hpp\"\n#include \"common.h\"\n#include \"cppjieba\u002FJieba.hpp\"\n#include \u003Cboost\u002Falgorithm\u002Fstring\u002Fclassification.hpp>\n#include \u003Cboost\u002Falgorithm\u002Fstring\u002Fsplit.hpp>\n#include \u003Cfstream>\n#include \u003Csstream>\n#include \u003Cstring>\n#include \u003Cunordered_map>\n#include \u003Cvector>\nnamespace ns_util\n{\nclass FileUtil : public NonCopyable\n{\npublic:\nstatic bool ReadFile(std::string path, std::string* out)\n{\nstd::fstream in(path, std::ios::binary | std::ios::in);\nif(!in.is_open())\n{\nLog(LogModule::DEBUG) \u003C\u003C \"file-\" \u003C\u003C path \u003C\u003C \"open fail!\";\nreturn false;\n}\nstd::stringstream ss;\nss \u003C\u003C in.rdbuf();\n*out = ss.str();\nin.close();\nreturn true;\n}\n};\nclass StopClass\n{\npublic:\nStopClass()\n{\nstd::ifstream in(STOP_WORD_PATH, std::ios::binary | std::ios::in);\nif(!in.is_open())\n{\nLog(LogModule::DEBUG) \u003C\u003C \"stop words load fail!\";\nin.close();\nreturn;\n}\nstd::string line;\nwhile(std::getline(in, line))\n{\nstop_words[line] = true;\n}\nin.close();\n}\nstd::pmr::unordered_map\u003Cstd::string, bool> stop_words;\n};\nclass JiebaUtile : public NonCopyable\n{\npublic:\nstatic cppjieba::Jieba* GetInstace()\n{\nstatic cppjieba::Jieba jieba_(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);\nreturn &jieba_;\n}\nstatic bool CutPhrase(std::string& src, std::vector\u003Cstd::string>& out)\n{\ntry\n{\nGetInstace()->CutForSearch(src, out, true);\nfor(auto s = out.begin(); s != out.end(); s++)\n{\nif(stop_.stop_words.find(*s) != stop_.stop_words.end())\n{\nout.erase(s);\n}\n}\n}\ncatch (const std::exception& e)\n{\nLog(LogModule::ERROR) \u003C\u003C \"CutString Error!\" \u003C\u003C e.what();\nreturn false;\n}\ncatch (...)\n{\nLog(ERROR) \u003C\u003C \"Unknow Error!\";\nreturn false;\n}\nreturn true;\n}\nstatic bool CutDoc(std::string& filestr, std::vector\u003Cstd::string>& out)\n{\ntry\n{\nboost::split(out, filestr, boost::is_any_of(\"\\3\"));\n}\ncatch (const std::exception& e)\n{\nLog(LogModule::ERROR) \u003C\u003C \"std Error-\" \u003C\u003C e.what();\nreturn false;\n}\ncatch(...)\n{\nLog(LogModule::ERROR) \u003C\u003C \"UnKnown Error!\";\nreturn false;\n}\nreturn true;\n}\nprivate:\nJiebaUtile() = default;\n~JiebaUtile() = default;\nprivate:\nstatic StopClass stop_;\n};\ninline StopClass JiebaUtile::stop_;\n};\n```\n## 结果展示\n\n\n********\n","cpp-httplib 是一个轻量级的 C++ HTTP 客户端 \u002F 服务器库,由日本开发者 yhirose 开发。它的特点是:","1971875951879974914","https:\u002F\u002Fi-blog.csdnimg.cn\u002Fdirect\u002F94b53bd07e9a4141bc8c93bc5093d107.png",{"description":349,"id":350,"imgUrl":8,"title":351,"views":231},"想象一下:老板突然说\"所有方法都要加耗时统计\",产品经理补刀\"每个按钮点击都得埋点\",测试同学再加一句\"异常要自动上报\"。如果你手动改,怕是要改到地老天荒。","1971876091445440514","揭秘Android编译插桩:ASM让你的代码\"偷偷\"变强","https:\u002F\u002Ffile.jishuzhan.net\u002Fuser\u002F1794334238066085889\u002Fhead.webp","1794334238066085889","深思慎考",{"description":356,"id":357,"imgUrl":8,"title":358,"views":359},"大家好,我是 倔强青铜三。欢迎关注我,微信公众号:倔强青铜三。欢迎点赞、收藏、关注,一键三连!欢迎来到 苦练Python第54天!","1971875776872640514","苦练Python第54天:比较运算魔术方法全解析,让你的对象“懂大小、能排序”!",28,[361,362,363],{"id":198,"name":199},{"id":204,"name":205},{"id":282,"name":283},1758966837000,"LinuxC++项目开发日志——基于正倒排索引的boost搜索引擎(5——通过cpp-httplib库建立网页模块)",31,["Reactive",368],{"$sisPC2":369},false,["Set"],["ShallowReactive",372],{"0mAzBCS3CWakgW3AGYauUaIafVRcTpqTzE6xC2Tnrc0":-1,"wDdEB1REj7eOVA0IINOW8By0h7e6k9_YCMGESItz9sY":-1,"glaIx14zzTwMHHGT3VRKOAAT2IWy941uSBVkEtcvnRA":-1,"WZ90U2AJ8WAHMpSv5WU9d7GUiJToX5gfe9Fb1fyuzAs":-1,"Dzwe4LPGAfSiILJXw8PrlAmzVm5_6L8U-DtpC3ewI14":-1},true,"\u002Farticle\u002F1971875951879974914"]</script></body></html>