1 Kafka 的日志文件记录机制
- Kafka 的日志文件记录机制是其能支撑高吞吐、高性能、高可扩展的核心所在,对业界影响巨大;
- 每个 Broker 节点的消息数据(称为 Log 日志)是无状态的,这种无状态设计让 Kafka 集群易于水平扩展,比如可通过工具(如
kafka-reassign-partitions.sh)将无状态数据从旧 Broker 转移到新 Broker 以替换服务(数据转移并非简单复制粘贴,因底层是二进制文件,操作复杂)。
1.1 Topic存储消息的方式
-
搭建 Kafka 服务时,在
server.properties配置文件中通过log.dir属性指定日志存储目录,Kafka 所有消息都存储在该目录下;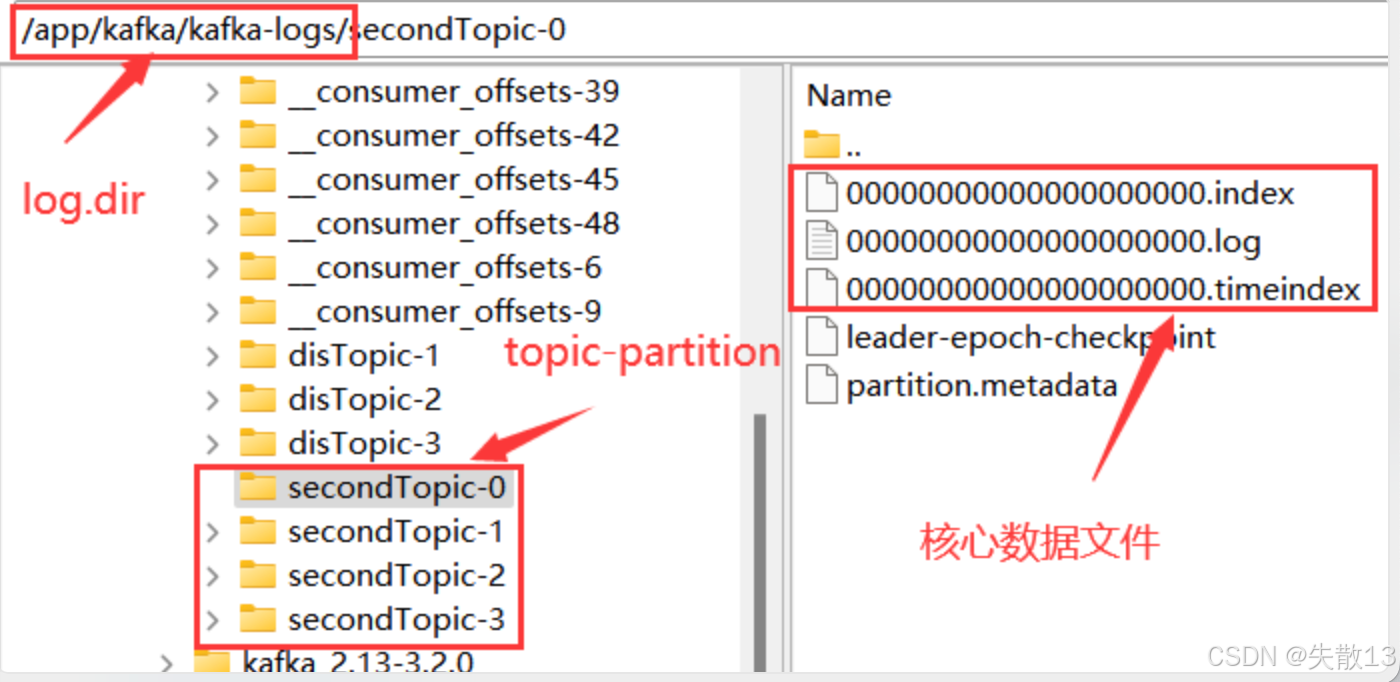
-
日志文件(.log) :是实际存储消息的日志文件,大小固定为 1G(由
log.segment.bytes参数指定),写满后会新增一个文件,每个文件称为一个 segment,文件名表示当前日志文件记录的第一条消息的偏移量;此处的偏移量是绝对偏移量,下节会做解释;
-
索引文件:
-
.index :以偏移量为索引,记录对应
.log日志文件中的消息偏移量;此处的偏移量是相对偏移量,下节会做解释;
-
.timeindex:以时间戳为索引;
-
-
另外还有
partition.metadata文件(简单记录当前 Partition 所属的 cluster 和 Topic)和leader-epoch-checkpoint文件(与之前的 epoch 机制相关)。这些文件都是二进制文件,无法用文本工具直接查看,但 Kafka 提供了工具(如kafka-dump-log.sh)来查看日志文件内容;
-
-
通过
kafka-dump-log.sh工具可查看不同文件内容:cmd# 查看timeIndex文件。能看到时间戳与偏移量的对应关系 [root@192-168-65-112 bin]# ./kafka-dump-log.sh --files /app/kafka/logs/disTopic-0/00000000000000000000.timeindex Dumping /app/kafka/logs/disTopic-0/00000000000000000000.timeindex timestamp: 1723519364827 offset: 50 timestamp: 1723519365630 offset: 99 timestamp: 1723519366162 offset: 148 timestamp: 1723519366562 offset: 197 timestamp: 1723519367013 offset: 246 timestamp: 1723519367364 offset: 295 timestamp: 1723519367766 offset: 344 # 查看index文件。可看到偏移量与位置(position)的对应关系 [root@192-168-65-112 bin]# ./kafka-dump-log.sh --files /app/kafka/logs/disTopic-0/00000000000000000000.index Dumping /app/kafka/logs/disTopic-0/00000000000000000000.index offset: 50 position: 4098 offset: 99 position: 8214 offset: 148 position: 12330 offset: 197 position: 16446 offset: 246 position: 20562 offset: 295 position: 24678 offset: 344 position: 28794 # 查看log文件。能看到消息的起始偏移量、数量、生产者信息、创建时间等详细内容。这些数据文件的记录方式是理解 Kafka 本地存储的主线 [root@192-168-65-112 bin]# ./kafka-dump-log.sh --files /app/kafka/logs/disTopic-0/00000000000000000000.log Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.log Starting offset: 0 ..... baseOffset: 350 lastOffset: 350 count: 1 baseSequence: 349 lastSequence: 349 producerId: 5002 producerEpoch: 0 partitionLeaderEpoch: 7 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 29298 CreateTime: 1723519367827 size: 84 magic: 2 compresscodec: none crc: 400306231 isvalid: true baseOffset: 351 lastOffset: 351 count: 1 baseSequence: 350 lastSequence: 350 producerId: 5002 producerEpoch: 0 partitionLeaderEpoch: 7 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 29382 CreateTime: 1723519367829 size: 84 magic: 2 compresscodec: none crc: 2036034757 isvalid: true .......
1.1 log 文件记录消息的方式
- 追加写入:在每个文件内部,Kafka 以追加的方式将消息写入 log 日志文件。Kafka 中的消息日志只允许追加操作,不支持删除和修改。因此,只有文件名最大的一个 log 文件是当前用于写入消息的日志文件,其他文件都是不可修改的历史日志;
- 固定大小与文件命名:每个 log 文件保持固定的大小。当当前文件无法再记录新消息时,会重新创建一个 log 文件,并且以这个新 log 文件写入的第一条消息的偏移量来命名。这种设计是为了更方便地进行文件映射,从而加快读取消息的效率。
1.2 index和timeindex文件加速读取log消息日志
-
详细看下这几个文件的内容,就可以总结出 Kafka 记录消息日志的整体方式:
-
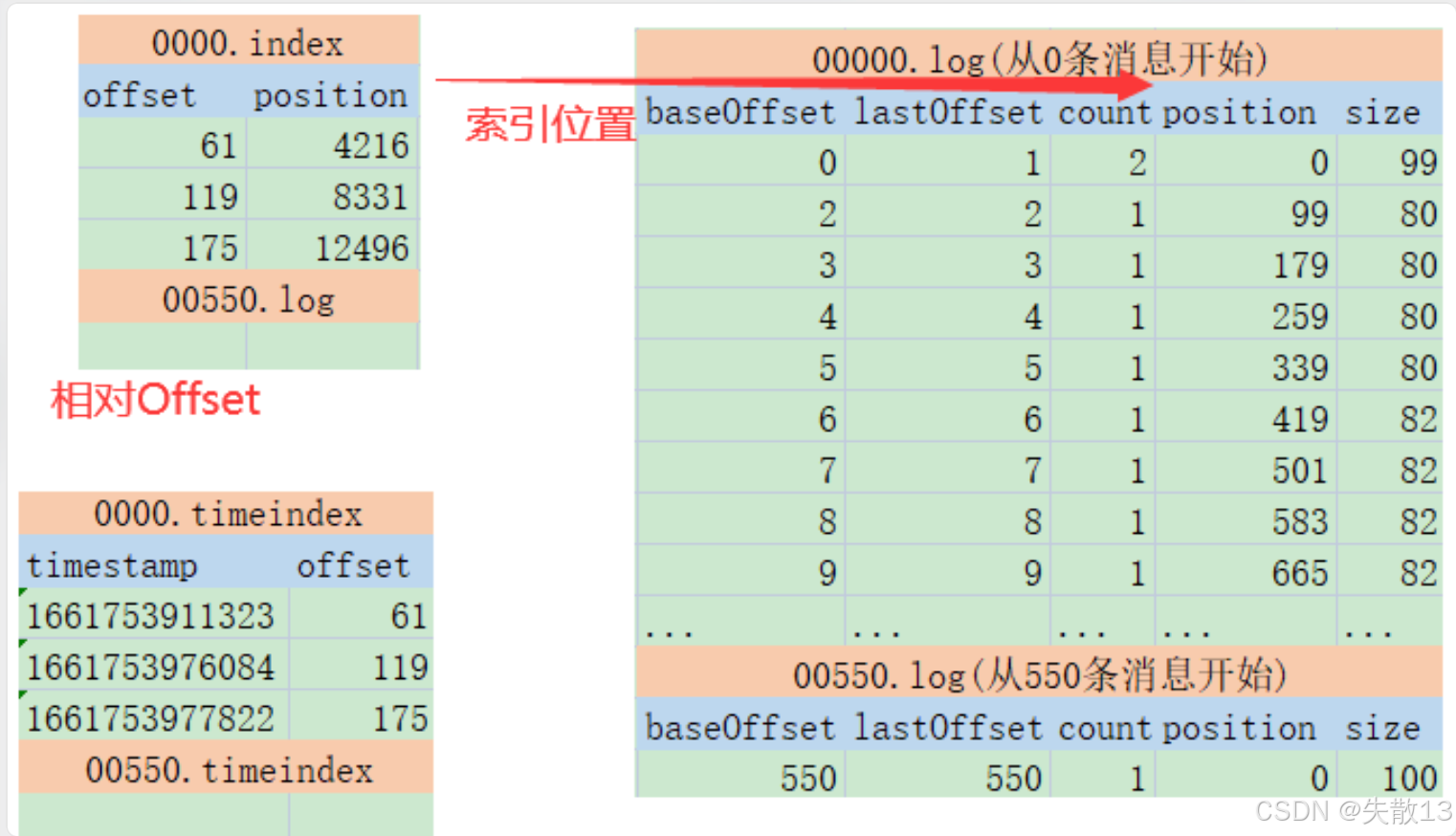
0000.index文件记录了offset(偏移量)和position(位置)的对应关系,通过这些对应关系,能快速定位到log文件中消息的位置; -
0000.timeindex文件记录了timestamp(时间戳)和offset的对应关系,可用于基于时间的消息查找等操作;index文件 :作用类似数据结构中的跳表,用于加速查询log文件的效率;timeindex文件:用于进行一些与时间相关的消息处理,比如文件清理;这两个索引文件也是 Kafka 消费者能够指定从某一个
offset或者某一个时间点读取消息的原因; -
0000.log文件从 0 条消息开始存储,00550.log文件从 550 条消息开始存储,每个log文件有baseOffset(基础偏移量)、lastOffset(最后偏移量)、count(数量)、position(位置)、size(大小)等信息,结合索引文件可高效读取其中的消息;
-
index和timeindex都以相对偏移量的方式为log消息日志建立数据索引。例如0000.index和0550.index中记录的索引数字都从 0 开始,代表相对日志文件起点的消息偏移量,而绝对消息偏移量可通过日志文件名与相对偏移量得到;日志文件命名与绝对偏移量:
- Kafka 的
log文件是以其包含的第一条消息的绝对偏移量 来命名的,index和timeindex文件也是以其对应的log文件中第一条消息的绝对偏移量来命名的; - 比如有一个
log文件名为00000000000000000550.log,这就表示这个log文件中存储的第一条消息的绝对偏移量是550。对应的index文件就会命名为00000000000000000550.index,timeindex文件则命名为00000000000000000550.timeindex;
相对偏移量的含义 :在
index(比如00000000000000000550.index)和timeindex(比如00000000000000000550.timeindex)文件里,记录的索引数字是相对偏移量 ,且从0开始计数。相对偏移量表示的是消息相对于当前log文件起点的偏移量;绝对偏移量的计算 :要得到消息的绝对偏移量,需要把
log文件的命名(即该文件第一条消息的绝对偏移量)和相对偏移量相加;例:假设有一个
log文件00000000000000000550.log,它里面第一条消息的绝对偏移量是550。现在在对应的index文件中,有一条记录的相对偏移量是10。那么这条记录对应的消息的绝对偏移量 就是550 + 10 = 560;通过这种方式,Kafka 就能利用相对偏移量结合
log文件名,快速确定消息的绝对偏移位置,从而加速对log消息的读取; - Kafka 的
-
这两个索引并非对每条消息都建立索引,而是 Broker 每写入 4KB(由参数
log.index.interval.bytes定制,默认 4096 字节,即 4KB)的数据,就建立一条index索引;propertieslog.index.interval.bytes The interval with which we add an entry to the offset index Type: int Default: 4096 (4 kibibytes) Valid Values: [0,...] Importance: medium Update Mode: cluster-wide
2 文件清理机制
-
Kafka 为避免过多日志文件给服务器带来压力,会定期删除过期的 log 文件,涉及以下配置属性:
-
log.retention.check.interval.ms:定时检测文件是否过期的时间间隔,默认是 300000 毫秒(即 5 分钟); -
log.retention.hours、log.retention.minutes、log.retention.ms:这一组参数用于设置文件保留的时间。默认生效的是log.retention.hours,默认值为 168 小时(即 7 天)。如果设置了更高时间精度的参数,以时间精度最高的配置为准; -
检查文件是否超时时,以每个
.timeindex文件中最大的那条记录为准;
-
-
过期日志文件的处理
-
log.cleanup.policy:日志清理策略,有两个选项。delete表示删除日志文件;compact表示压缩日志文件; -
当
log.cleanup.policy选择delete时,还有一个参数log.retention.bytes,用于表示所有日志文件的大小。当总的日志文件大小超过这个阈值后,就会删除最早的日志文件,默认值是 -1,表示无大小限制; -
压缩日志文件不会直接删除日志文件,但会造成消息丢失。压缩过程中会将 Key 相同的日志进行压缩,只保留最后一条。
-
3 客户端消费进度管理
-
Kafka 为实现分组消费的消息转发机制,需要在 Broker 端保持每个消费者组的消费进度,这些消费进度由内置的 Topic ------
__consumer_offsets管理。它是 Kafka 内置的系统 Topic,默认被划分为 50 个分区,在日志文件中能看到相关目录;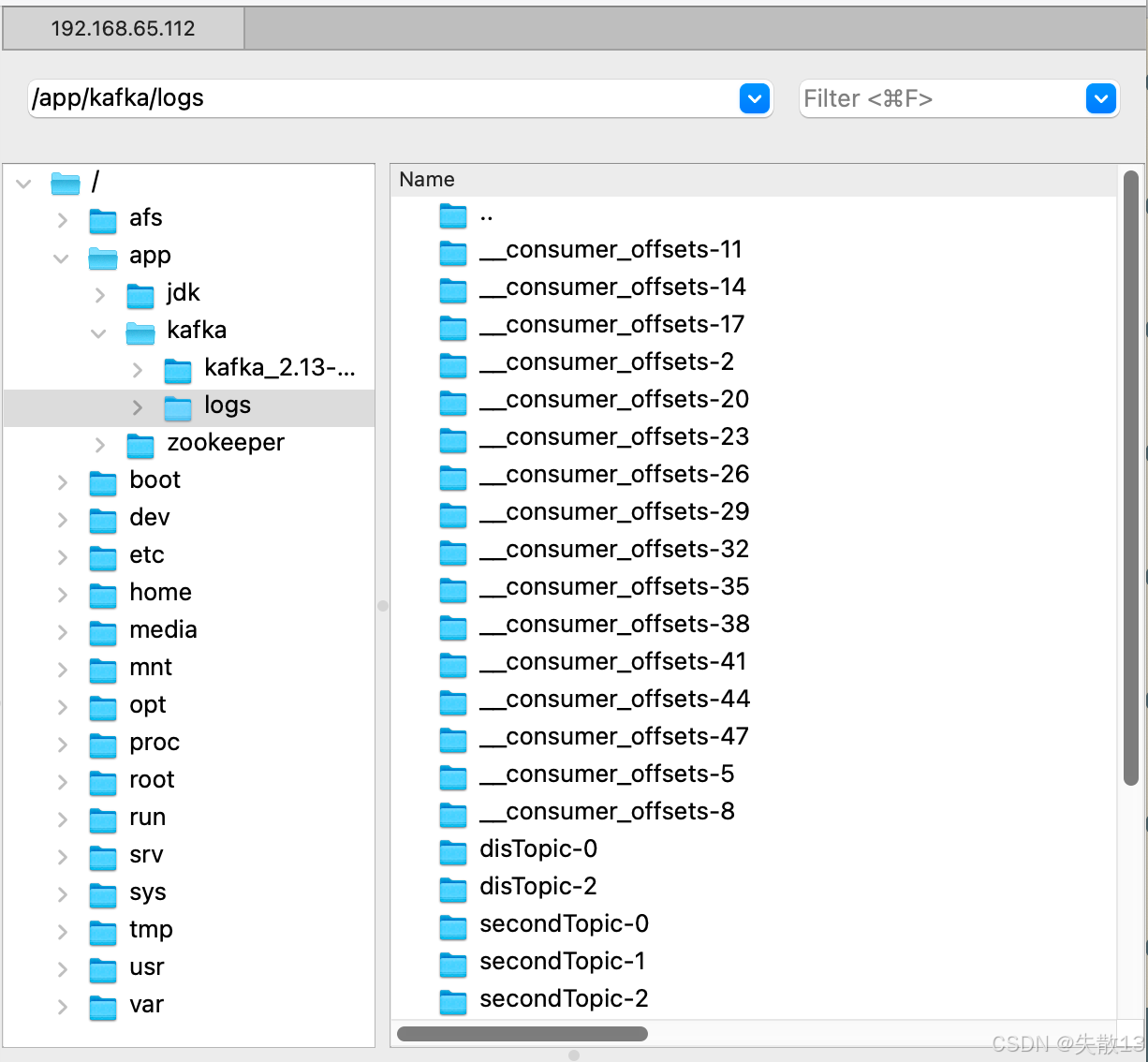
-
同时,Kafka 也会将这些消费进度的状态信息记录到 Zookeeper 中,但在早期版本后,Offset(偏移量)逐渐从 Zookeeper 转移到 Broker 上,这是因为 Kafka 意识到 Zookeeper 这类外部组件在面对高并发等场景时可靠性不足,后续的 Kraft 集群也延续了这种减少对外部组件依赖的思想;
-
__consumer_offsets这个系统 Topic 中记录了所有 ConsumerGroup 的消费进度:-
数据以 Key - Value 方式维护,Key 为
groupid + topic + partition,Value 表示当前的 offset; -
消费者可以直接消费这个 Topic 中的消息,例如:
cmd[root@192-168-65-112 kafka_2.13-3.8.0]# bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server worker1:9092 --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginningcmd[test,disTopic,1]::OffsetAndMetadata(offset=3, leaderEpoch=Optional[1], metadata=, commitTimestamp=1661351768150, expireTimestamp=None) [test,disTopic,2]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1661351768150, expireTimestamp=None) [test,disTopic,0]::OffsetAndMetadata(offset=6, leaderEpoch=Optional[2], metadata=, commitTimestamp=1661351768150, expireTimestamp=None) [test,disTopic,3]::OffsetAndMetadata(offset=6, leaderEpoch=Optional[3], metadata=, commitTimestamp=1661351768151, expireTimestamp=None) [test,disTopic,1]::OffsetAndMetadata(offset=3, leaderEpoch=Optional[1], metadata=, commitTimestamp=1661351768151, expireTimestamp=None) [test,disTopic,2]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1661351768151, expireTimestamp=None) [test,disTopic,0]::OffsetAndMetadata(offset=6, leaderEpoch=Optional[2], metadata=, commitTimestamp=1661351768151, expireTimestamp=None) [test,disTopic,3]::OffsetAndMetadata(offset=6, leaderEpoch=Optional[3], metadata=, commitTimestamp=1661351768153, expireTimestamp=None) [test,disTopic,1]::OffsetAndMetadata(offset=3, leaderEpoch=Optional[1], metadata=, commitTimestamp=1661351768153, expireTimestamp=None) [test,disTopic,2]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1661351768153, expireTimestamp=None) -
这些 Offset 数据可被消费者修改,若消费者主动调整 Offset,Kafka 会更新对应记录;
-
-
由于
__consumer_offsets里的数据非常重要,Kafka 在消费者端设计了exclude.internal.topics参数来控制是否从订阅关系中剔除这个内部 Topic,默认值为true;javapublic static final String EXCLUDE_INTERNAL_TOPICS_CONFIG = "exclude.internal.topics"; private static final String EXCLUDE_INTERNAL_TOPICS_DOC = "Whether internal topics matching a subscribed pattern should " + "be excluded from the subscription. It is always possible to explicitly subscribe to an internal topic."; public static final boolean DEFAULT_EXCLUDE_INTERNAL_TOPICS = true;
4 Kafka 的文件高效读写机制
4.1 Kafka 的文件结构
- Kafka 的数据文件结构设计有助于加速日志文件的读取;
- 同一 Topic 下的多个 Partition 会单独记录日志文件,并且可以并行读取,这样能加快 Topic 下的数据读取速度;
- 此外,index 的稀疏索引结构,能够加快 log 日志检索的速度。
4.2 顺序写磁盘
- 这一特性和操作系统有关,主要由硬盘结构决定;
- 对于每个 log 文件,Kafka 会提前规划固定的大小,这样在申请文件时,能够提前占据一块连续的磁盘空间;
- Kafka 的 log 文件只能以追加的方式往文件的末端添加(这种写入方式称为顺序写 )。新的数据写入时,可直接往之前申请的磁盘空间中写入,无需再去磁盘其他地方寻找空闲空间(普通的读写文件需要先寻找空闲的磁盘空间,再写入,这种写入方式称为随机写)。因为磁盘的空闲空间可能不连续,存在很多文件碎片,所以随机写的效率会很低;
- Kafka 官网测试数据表明,同样的磁盘,顺序写速度能达到 600M/s,基本与写内存的速度相当;而随机写的速度只有 100K/s,两者差距很大。
4.3 零拷贝
-
零拷贝是 Linux 操作系统提供的一种 I/O 优化机制,Kafka 大量运用该机制来加速文件读写。传统硬件 I/O 过程中,数据在用户态与内核态之间传递时会有多次拷贝(如 CPU 拷贝等),而零拷贝技术重点是配合内核态的复制机制,减少用户态与内核态之间的内容拷贝。具体实现有两种方式:
- mmap 文件映射机制;
- sendfile 文件传输机制;
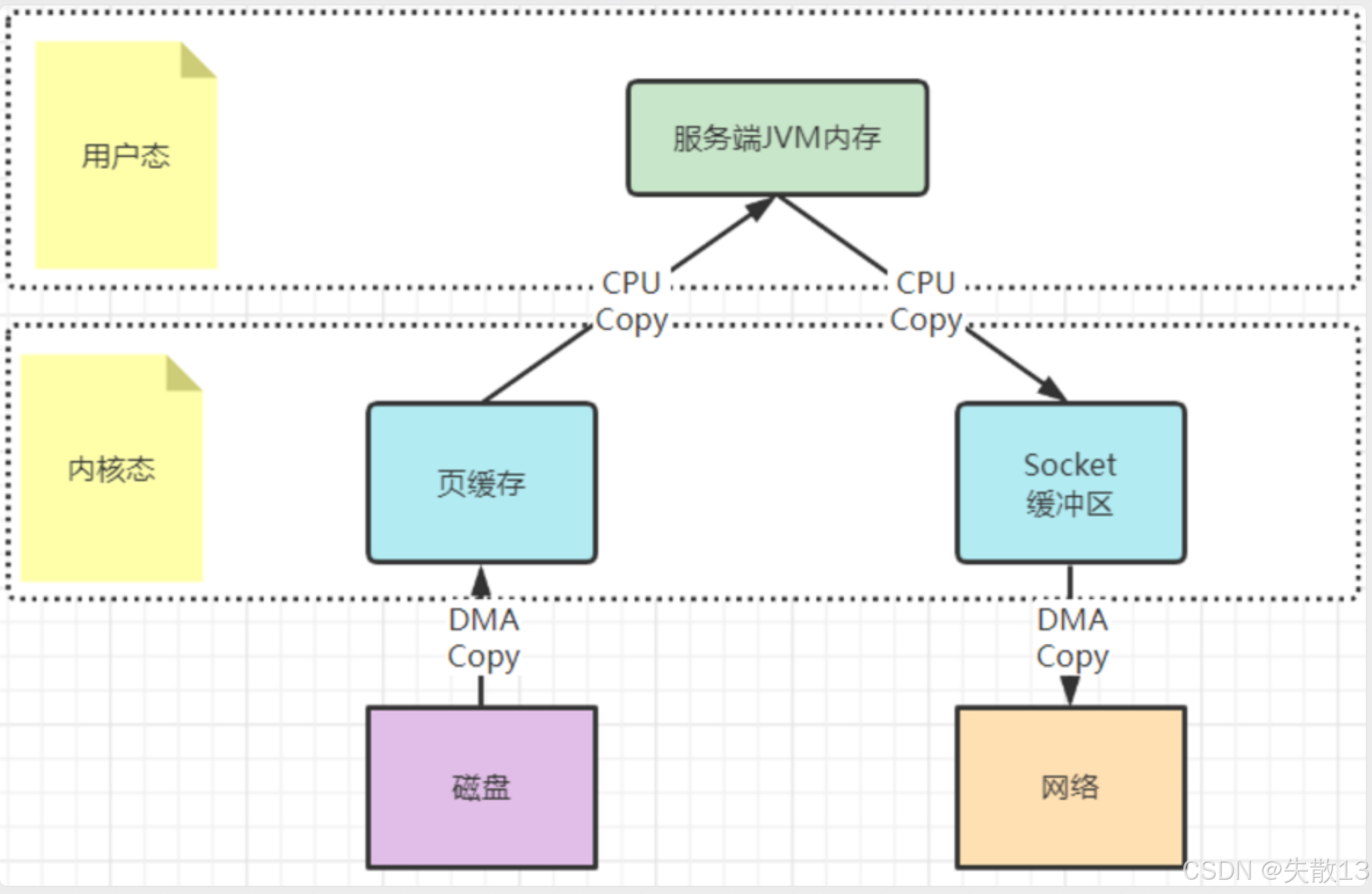
磁盘数据通过 DMA Copy (直接内存访问复制,无需 CPU 参与)被复制到内核态的页缓存中
然后通过 CPU Copy ,将页缓存中的数据复制到用户态的服务端 JVM 内存 里
接着再通过 CPU Copy ,把 JVM 内存中的数据复制到内核态的 Socket 缓冲区
最后通过 DMA Copy,将 Socket 缓冲区的数据复制到网络进行传输
此过程存在多次 CPU 参与的拷贝,以及用户态与内核态之间的切换,效率较低
-
mmap 文件映射机制
-
工作方式 :在用户态不再缓存整个 I/O 的内容,改为只持有文件的一些映射信息,通过这些映射"遥控"内核态的文件读写,从而减少内核态与用户态之间的拷贝数据大小,提升 I/O 效率,可参考 JDK 中
DirectByteBuffer的实现机制; -
适用场景与 Kafka 的设计 :mmap 文件映射机制适合操作不是很大的文件,通常映射的文件不建议超过 2G。所以 Kafka 将 log 日志文件设计成 1G 大小,超过 1G 就另外再新写一个日志文件,以便于对文件进行映射,加快对
.log文件等本地文件的写入效率。这种机制是操作系统提供的文件操作机制,在 Java 程序执行过程中会被大量使用;
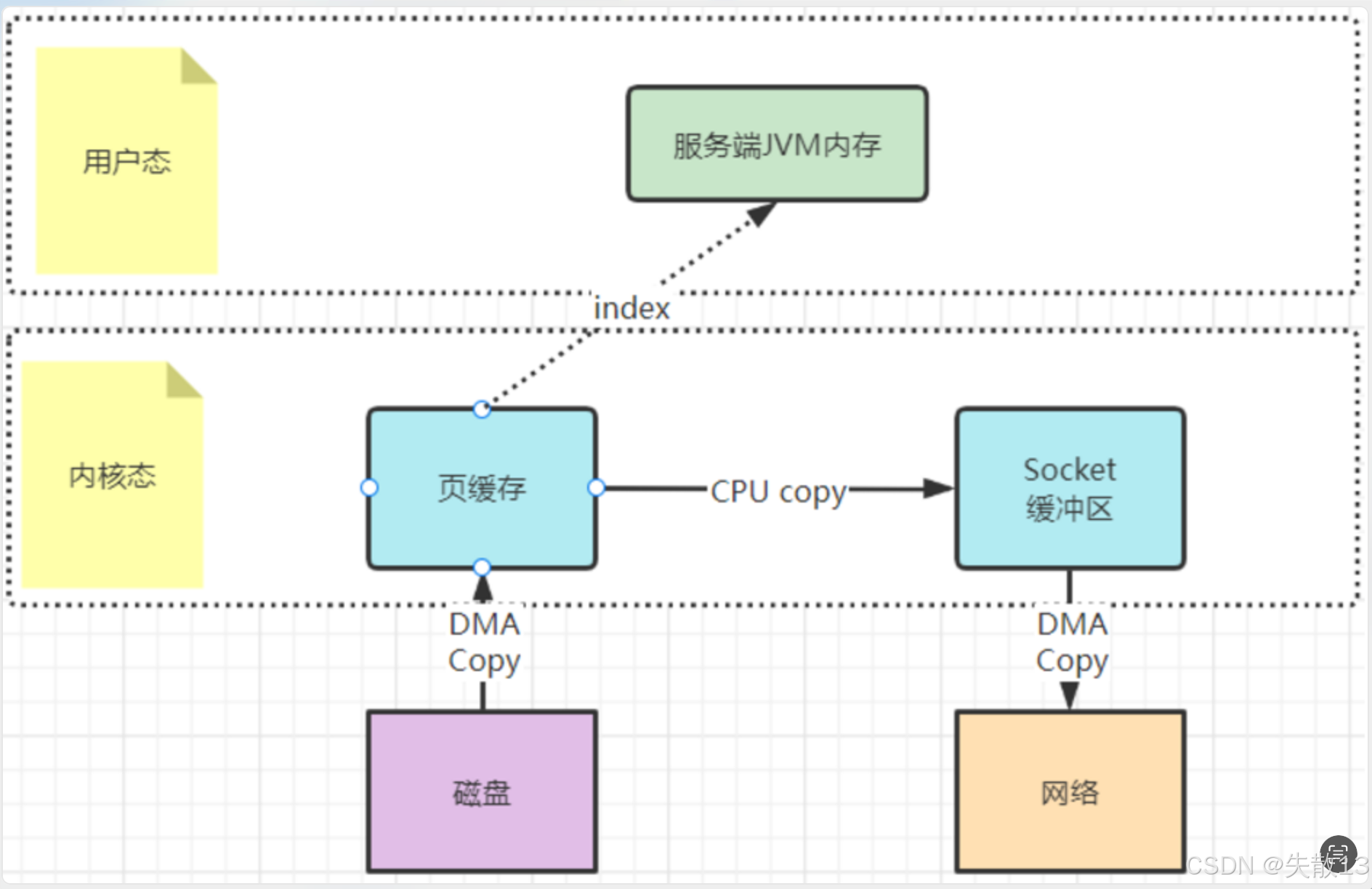
磁盘数据先经 DMA Copy 到内核态的页缓存
利用
mmap(内存映射)机制,用户态的服务端 JVM 内存 可以通过index(索引)直接映射到内核态的页缓存,减少了一次 CPU 从页缓存到 JVM 内存的拷贝之后通过 CPU Copy ,将页缓存中的数据复制到内核态的 Socket 缓冲区
最后通过 DMA Copy 到网络。相比传统流程,减少了一次 CPU 拷贝,提升了效率
-
-
sendfile 文件传输机制
-
工作方式 :用户态(应用程序)不再关注数据内容,只是向内核态发一个
sendfile指令,让内核态去复制文件,这样数据就完全不用复制到用户态,从而实现零拷贝; -
与 mmap 的对比:相比 mmap,sendfile 连索引都不读,直接通知操作系统去拷贝,效率更高,但缺点是在用户态对文件内容完全无感知,无法在用户态对文件内容做解析;
-
Kafka 中的应用 :在 Kafka 中,当 Consumer 要从 Broker 上拉取消息时,Broker 只需将数据从磁盘读取出来,然后通过网络发送出去。此过程中,Broker 只负责传递消息,不对消息进行任何加工,所以只需往内核态发一个
sendfile指令,无需任何数据拷贝过程,Kafka 大量使用sendfile机制来加速对本地数据文件的读取过程; -
具体细节可在 Linux 机器上使用
man 2 sendfile指令查看操作系统的帮助文件。JDK 8 中java.nio.channels.FileChannel类提供的transferTo和transferFrom方法,底层就是使用了操作系统的sendfile机制;
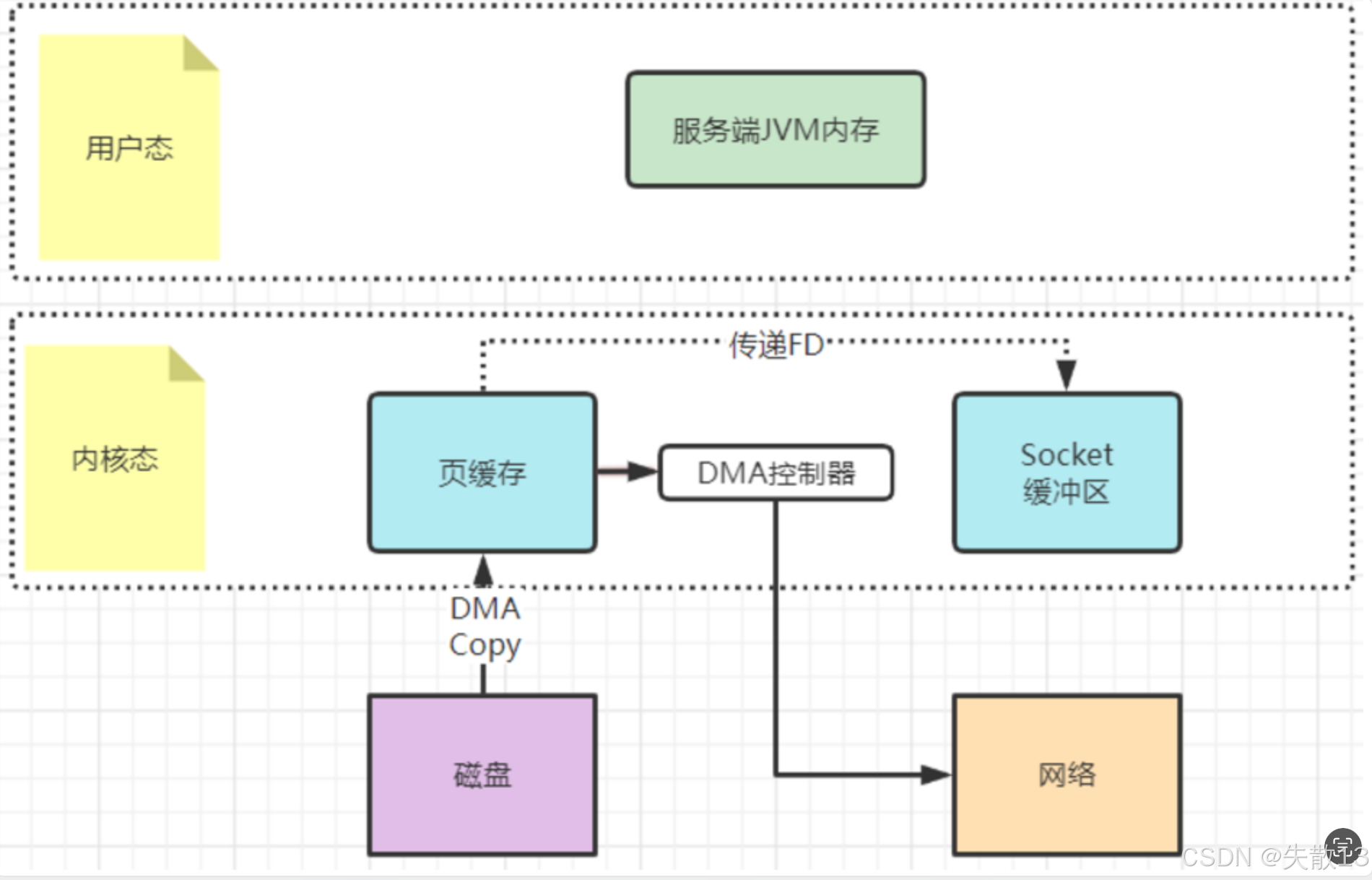
磁盘数据通过 DMA Copy 到内核态的页缓存
内核态的 DMA 控制器直接将页缓存中的数据传输到网络,无需经过 Socket 缓冲区
这是更高效的零拷贝方式,极大减少了数据拷贝次数和 CPU 开销,大幅提升了数据从磁盘到网络的传输效率
-
-
这些底层优化机制对上层应用语言来说是黑盒,上层语言只能调用,不同语言实现方式虽有差异,但本质相同。
4.4 合理配置刷盘频率
-
缓存数据断电会丢失,若缓存中的数据未及时写入硬盘(刷盘),服务突然崩溃时就可能丢失消息。通常认为最安全的方式是写一条数据就刷一次盘(同步刷盘),刷盘操作在 Linux 系统中对应
fsync系统调用;fsync, fdatasync - synchronize a file's in-core state with storage device上面这是 Linux 系统中关于
fsync和fdatasync函数的手册页(Manual Page)相关内容- 这里的
in-core state指的是操作系统内核态的缓存,即 PageCache,这是应用程序接触不到的缓存; - 应用程序打开文件时,内容从 PageCache 中读取;修改文件内容时,也是先写到 PageCache 里,之后操作系统会通过自身缓存管理机制,在未来某个时刻将 PageCache 里的内容统一写入磁盘;
- 对于缓存断掉导致数据丢失的问题,应用程序无法决定数据何时写入硬盘,只能尽量频繁通知操作系统进行刷盘操作,但这会降低应用执行性能,且不能百分百保证数据安全,应用程序在这个问题上只能取舍;
- 这里的
-
Kafka 在 Broker 端设计了一系列参数来控制刷盘频率:
-
flush.ms:指定强制刷盘的时间间隔。例如设置为 1000,就会在 1000 毫秒后执行fsync。一般建议不设置该参数,利用复制(replication)保证数据持久性,让操作系统的后台刷盘能力发挥作用,因为这样更高效; -
log.flush.interval.messages:表示同一个 Partition 的消息数积累到该数量时,就会申请一次刷盘操作,默认是Long.MAX; -
log.flush.interval.ms:当一个消息在内存中保留的时间达到该数量时,就会申请一次刷盘操作,默认值为空,若为空则生效下一个参数; -
log.flush.scheduler.interval.ms:检查是否有日志文件需要进行刷盘的频率,默认是Long.MAX;
-
-
为了最大化性能,Kafka 默认将刷盘操作交由操作系统统一管理;
-
Kafka 没有实现写一个消息就进行一次刷盘的"同步刷盘"机制,无法保证非正常断电情况下的消息安全,这是所有应用程序都面临的问题;
- RabbitMQ 官网明确提出服务端并不完全保证消息不丢失,若要提升消息安全性,需通过
Publisher Confirms机制让客户端参与验证; - RocketMQ 提供了"同步刷盘"的配置选项,但每来一个消息就调用一次刷盘操作,服务器难以承受,后续可关注 RocketMQ 如何实现同步刷盘。
- RabbitMQ 官网明确提出服务端并不完全保证消息不丢失,若要提升消息安全性,需通过