旷视,2204
摘要
图像恢复SOTA方法的系统复杂性在增加,这可能会阻碍方法的便捷分析和比较 。本文提出了一种简单的基线,其性能超过了SOTA,并且在计算上效率高。为了进一步简化基线,我们揭示非线性激活函数不是必要的:它们可以被乘法替代或删除 。因此,我们从基线推导出了一个无非线性激活的网络,即NAFNet。在各类挑战基准测试中,我们实现了SOTA结果,例如在GoPro(用于图像去模糊)上获得33.69 dB的PSNR,超过了之前的SOTA 0.38 dB,仅以8.4%的计算成本;在SIDD(用于图像去噪)上获得40.30 dB的PSNR,超过了之前的SOTA 0.28 dB,计算成本不到其一半。
前言
本文将系统复杂性分为两种:块间和块内
块间:
块内:这篇文章举的例子是Restormer、SwinTransformer和Half Instance Norm Block(HINBlock)。这篇文章倒没有说它们不好,只是说逐一评估这些设计选择很难
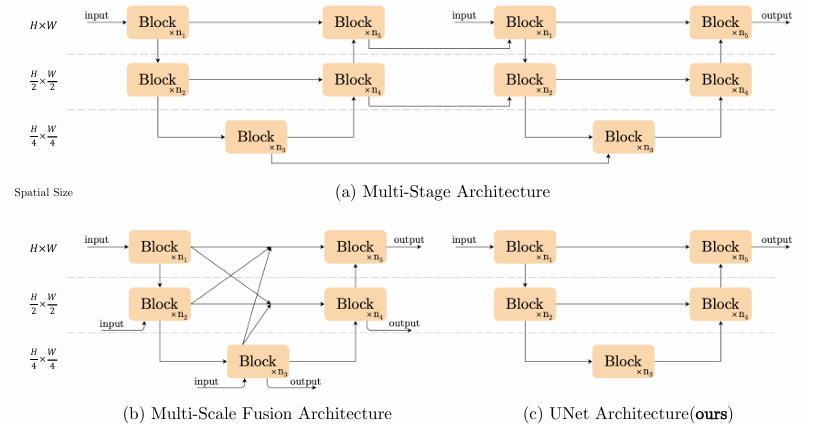
本文想同时降低这两种复杂性,并仍取得SOTA 。为此,本文采用U-Net,并聚焦于降低块内设计。从最简单的组件出发:Conv、ReLU、shortcut,本文逐步加入/替换SOTA方法里的组件,验证它们带来的性能提升量。通过一大堆消融实验,本文提出了一个简单的基线,它超越了SOTA并且计算高效,如下图
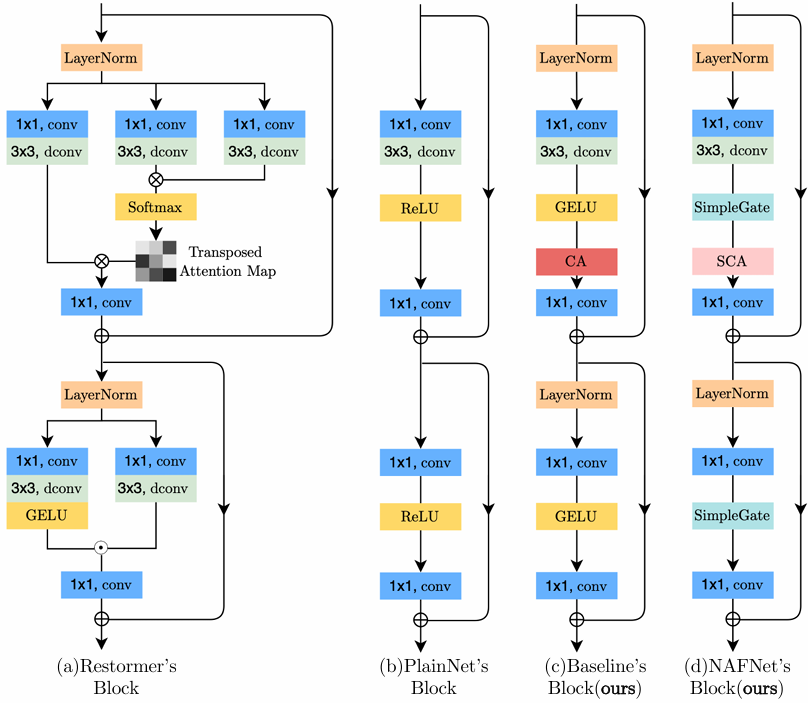
图中的CA就是SE。基线还可以进一步简化:本文表明GELU可以被视作Gated Linear Unit(GLU)的特例,因此可以被替换;CA和GLU也很像,因此CA里的非线性激活函数也可以被移除。总之,这样简化完后,网络就没有非线性激活函数了!(但不是没有非线性了,只是转移到GLU上了)(你可能知道原始的GLU里是有非线性激活的,但本文把它删了!看下面的相关工作)本文将这个网络记作NAFNet(Nonlinera Activation Free)
相关工作(提一下GLU)
GLU【Language modeling with gated convolutional networks,2017】是两个线性层的逐元素乘积,其中一个线性层用非线性激活函数激活。GLU及其变体在NLP中被广泛应用,在CV中也有趋势。本文修改了GLU,把里面的非线性激活删除,这不会造成性能下降。(两个线性层的输出逐元素相乘是会产生非线性性的:Ax × Bx + Ay × By != A(x+y) × B(x+y),Akx × Bkx != k Ax × Bx,更简单点,标量ax × bx = ab x^2,就已经非线性了)
### 前情提要:下面的每一个层的添加/修改,都带来了性能提升,所以就不每次都说了
方法------Baseline
Architecture------UNet
层的排列------Transformer
本文模型的Block里的层排列设计参照了Transformer,先是一个"注意力"子块,然后是一个FFN。本文在构造简单基线,因此没有用self-attention
Normalization------LayerNorm
由于小batchsize会造成不稳定,BN被抛弃了。InstanceNorm避免了这个问题,但HIN Block又说IN的加入不一定总能提升性能,需要手动调优。LayerNorm在Transformer兴盛的大背景下被广泛使用,因此本文认为它很关键,实验表明LN使训练更丝滑,即使把学习率调大10倍。此外,大的学习率带来了显著的性能提升
Attention------Restormer与CA(SE)
自注意力属于一种空间注意力,计算上存在随图像尺寸平方增长的复杂度的问题。Restormer用Transposed的方法将这种空间注意力变为了通道注意力。通道注意力天然地聚合了全局信息(但精度上限应该比不上自注意力)。因此,本文加入了SE,将全局信息注入特征图
综上,baseline完成了。这个baseline能打败一众SOTA(图就不放了)
方法------NAFNet
还想继续简化,同时保持性能?看看一些SOTA方法的共性:GLU的使用。(这里列举了一些SOTA方法,基本上都是Transfomer变体,比如Restormer)
GLU的通用形式: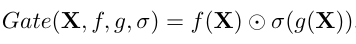 ,其中f和g是线性层,σ是非线性激活函数,⊙是逐元素乘积
,其中f和g是线性层,σ是非线性激活函数,⊙是逐元素乘积
直接用通用GLU实际上还是增加了复杂度,咋办?看一下GELU: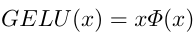 ,Φ(x)是标准正态分布的累积分布函数(CDF)。显然,GELU是GLU的特例。因此,本文认为GLU是一种通用型非线性激活函数,可以替代GELU。但这还不够,GLU里的σ就是非线性激活函数,能删掉吗?可以的!这样的GLU还是非线性的。但这还不够,线性变换要不少计算量,也删了!直接X ⊙ X。诶,这样的GLU还有足够的非线性性吗?(另一方面,这样的GLU还有Gate的作用吗?)本文换了一种设计:沿着通道维度把输入特征图对半分,然后把这两半逐点相乘(这样两半就互相作为对方的Gate)。本文将这种GLU叫做SimpleGate
,Φ(x)是标准正态分布的累积分布函数(CDF)。显然,GELU是GLU的特例。因此,本文认为GLU是一种通用型非线性激活函数,可以替代GELU。但这还不够,GLU里的σ就是非线性激活函数,能删掉吗?可以的!这样的GLU还是非线性的。但这还不够,线性变换要不少计算量,也删了!直接X ⊙ X。诶,这样的GLU还有足够的非线性性吗?(另一方面,这样的GLU还有Gate的作用吗?)本文换了一种设计:沿着通道维度把输入特征图对半分,然后把这两半逐点相乘(这样两半就互相作为对方的Gate)。本文将这种GLU叫做SimpleGate
看着GLU,有没有觉得和SE很像?对的,回顾一下SE: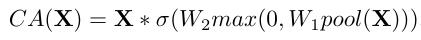 ,把后面那一大块抽象一下,形式上就是GLU的一个特例了。好,让我们简化一下:删去ReLU和sigmoid,以及合并两个线性层,得到:
,把后面那一大块抽象一下,形式上就是GLU的一个特例了。好,让我们简化一下:删去ReLU和sigmoid,以及合并两个线性层,得到: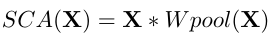 【这里不能直接替换为SimpleGate,因为CA的两个关键特性是:全局信息聚合(通过pool)、通道信息交互(通过W)】
【这里不能直接替换为SimpleGate,因为CA的两个关键特性是:全局信息聚合(通过pool)、通道信息交互(通过W)】
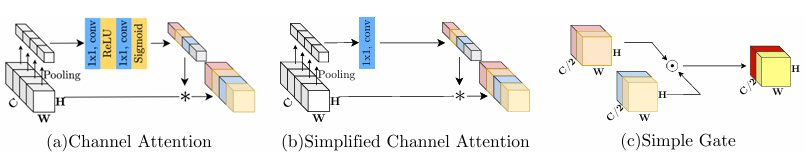
实验
在未特意提及的情况下,遵循HIN-Net的设置,包括gradient clip等。Adam with β=(0.9, 0.9) and weight_decay=0,200K迭代,lr=1e-3 -> 1e-6,cosineAnnealing,256 x 256。测试时采用TLC【Improving image restoration by revisiting global information aggregation,2112,也是旷视的文章】策略,弥补"当图像修复网络中存在全局信息操作时,用patch训练,用全图测试"导致的性能损失。此外,采用skip-init【由Batch normalization biases residual blocks towards the identity function in deep networks提出,但这篇文章说following ConvNeXt】来稳定训练
从PlainNet到Baseline
用lr=1e-3开始练出现了不稳定,遂调低至1e-4。加入LN后,可以用1e-3,并且训练更稳,性能更强【从表里看,LN和大学习率带来的提升比其它的改动要大得多】
从Baseline到NAFNet
没什么可说的,性能和计算效率提升就完事了
块数
主要考虑720 x 1280的图像,因为这是GoPro数据集的全图分辨率。从9 -> 36,性能增长明显,速度下降较少(本文是用latency衡量的,只增加了约14.5%),再往上就不值得了
GLU里的非线性激活函数
没必要,在GoPro上PSNR和SSIM甚至还降了
附录
其它细节
- 特征融合:对于U-Net中的跳跃连接,本文简单地将两个特征进行逐元素求和
- 下采样与上采样:下采样用k=2、s=2的卷积【受arxiv.org/pdf/2010.02178启发】,上采样用1x1卷积将通道数翻倍 + PixelShuffle