知识是人生的灯塔,只有不断学习,才能照亮前行的道路
📢 大家好,我是 WeiyiGeek,一名深耕安全运维开发(SecOpsDev)领域的技术从业者,致力于探索DevOps与安全的融合(DevSecOps),自动化运维工具开发与实践,企业网络安全防护,欢迎各位道友一起学习交流、一起进步 🚀,若此文对你有帮助,一定记得倒点个关注⭐与小红星❤️,收藏学习不迷路 😋 。
0x00 前言简述
描述:前面讲解了 MySQL 数据库中基础 DDL 、DML 语句,想必各位看友都已经有所了解,或者已实践过数据库的创建操作、表的创建操作,数据的增删改操作。在此基础上,我们还需要对数据库中的数据进行查询过滤操作,所以此文将针对 DQL (数据查询语言)基础 SELECT 语句及其常用查询字句关键字进行讲解,附带实践查询操作示例,最后还使用SQL语句演示查询子句各个的执行顺序。
温馨提示:若文章代码块中存在乱码,请通过文末的阅读原文链接,在知识星球中阅读,或者直接访问 https://articles.zsxq.com/id_ejvei8kvqnd2.html
在详细讲解 DQL 语句之前,我们先来看看本小节,究竟要学习实践那些查询关键字,以及基础 SQL 查询语法。
go
SELECT 字段列表 -- 字段列表可以理解为:表中的列名,多个列名使用逗号分隔
FROM 表名列表 -- 表名列表可以理解为:一个或多个表的名字,多个表名使用逗号分隔
WHERE 条件列表 -- 条件列表:指的是对字段设置过滤条件,多个条件使用 AND 或 OR 进行连接
GROUP BY 分组字段列表 -- 分组字段列表:指的是将查询结果按照某一个字段进行分组
HAVING 分组后的条件列表 -- 分组后的条件列表:指的是对分组的结果设置过滤条件
ORDER BY 排序字段列表 -- 排序字段列表:指的是对查询结果进行正序、倒序排序
LIMIT 起始索引, 查询记录数; -- 分页查询,起始索引指的是从哪一条记录开始取数据,查询记录数指的是取出多少条记录温馨提示:本文后续所实践的员工表 employees,可在《DBA | MySQL数据库基础数据操作学习实践笔记》文章中获取,若没有创建的童鞋请自行创建并插入数据。
 weiyigeek.top-演示SQL查询的表数据图
weiyigeek.top-演示SQL查询的表数据图
温馨提示:为了方便各位看友由浅入深的学习,复杂的多表查询语句将在后续的单独文章中进行讲解。
0x01 DQL 数据查询语句
1.查询单、多个或全部字段
描述:SQL 语句中,查询语句的字段列表指的是要查询哪些列的数据。在实际的业务系统中,不建议使用 * 符号来查询所有字段,而是指定需要查询哪些字段。
语法
go
-- # 语法:查询单个字段
SELECT 字段名 FROM 表名;
-- # 语法:查询多个字段
SELECT 字段名1, 字段名2 FROM 表名;
-- # 语法:查询 employees 表中的所有字段,特别注意:在实际业务系统开发中,不建议使用*查询所有字段,而是指定查询哪些字段
SELECT * FROM 表名;示例
go
-- # 查询employees表中的所有字段
mysql> SELECT * FROM employees;
| id | uid | name | gender | age | phone_number | skills | id_card | city | entry_date | salary |
+----+------+--------+--------+-----+--------------+-------------------------------------------+--------------------+--------+------------+----------+
| 1 | 001 | 张三 | 男 | 30 | 13800138000 | {"编程": "高级", "设计": "中级"} | 500102199001010001 | 重庆 | 2020-01-01 | 7500.00 |
| 2 | 002 | 李四 | 女 | 28 | 13900139000 | {"测试": "高级", "项目管理": "中级"} | 500102199201010002 | 北京 | 2020-02-15 | 15800.00 |
| 3 | 003 | 王五 | 男 | 35 | 13700137000 | {"架构": "高级", "数据库": "专家"} | 500102198801010003 | 上海 | 2019-05-10 | 16000.00 |
| 4 | 004 | 赵六 | 女 | 26 | 13600136000 | {"前端": "高级", "UI设计": "中级"} | 500102199601010004 | 杭州 | 2021-03-20 | 12000.00 |
| 5 | 005 | 钱七 | 男 | 32 | 13500135000 | {"运维": "高级", "网络安全": "中级"} | 500102199001010005 | 成都 | 2018-08-05 | 9000.00 |
| 6 | 006 | 孙八 | 女 | 29 | 13400134000 | {"数据分析": "高级", "机器学习": "中级"} | 500102199301010006 | 深圳 | 2020-11-12 | 13500.00 |
| 7 | 007 | 周九 | 男 | 27 | 13300133000 | {"后端": "中级", "移动开发": "高级"} | 500102199501010007 | 广州 | 2021-07-30 | 11500.00 |
| 8 | NULL | 吴十 | 女 | 31 | 13200132000 | {"产品经理": "高级", "市场分析": "专家"} | 500102199101010008 | 成都 | 2019-09-18 | 12800.00 |
-- # 查询employees表中的 id、name 字段
mysql> SELECTid, nameFROM employees;
| id | name |
+----+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
| 4 | 赵六 |
| 5 | 钱七 |
| 6 | 孙八 |
| 7 | 周九 |
| 8 | 吴十 |2.设置别名
描述:AS 关键字用于为字段设置别名,别名可以使用单引号括起来,
go
-- # 语法:为字段设置别名
SELECT 字段名 AS 别名, ... FROM 表名;
SELECT 字段名 别名, ... FROM 表名; -- 设置别名也可以忽略 AS 关键字
SELECT 字段名1AS 别名1, 字段名2AS 别名2FROM 表名;
-- # 示例:
-- 查询employees表中的uid、name字段,并为这两个字段设置别名
mysql> SELECT uid AS'员工ID', name'员工姓名'FROM employees;
| 员工ID | 员工姓名 |
+----------+--------------+
| 001 | 张三 |
| 002 | 李四 |
| 003 | 王五 |
| 004 | 赵六 |
| 005 | 钱七 |
| 006 | 孙八 |
| 007 | 周九 |
| NULL | 吴十 |3.去除重复记录
描述:DISTINCT 关键字用于去除查询结果中的重复记录。
语法示例
go
-- # 语法:去除重复记录
SELECT DISTINCT 字段名 FROM 表名;
-- # 示例:
-- 查询employees表中的 city 字段,去除重复记录,可查看到原始有 8 条记录,除重复后只剩 7 条
mysql> SELECT DISTINCT city FROM employees;
重庆
北京
上海
杭州
成都
深圳
广州4.条件过滤查询
描述:WHERE 子句用于过滤记录,只返回满足条件的记录,常与比较运算符、逻辑运算符、以及其他条件关键字IN、BETWEEN .. AND ...、IS NULL、LIKE等一起使用。
语法
go
-- # 语法:条件过滤查询
SELECT 字段名 FROM 表名 WHERE 条件;条件
| 比较运算符 | 功能 |
|---|---|
> |
大于 |
>= |
大于等于 |
< |
小于 |
<= |
小于等于 |
= |
等于 |
<> 或者 != |
不等于 |
| 逻辑运算符 | 功能 |
|---|---|
AND 或者 && |
并且,两边条件同时满足时结果为真 |
OR 或者 ` |
|
NOT 或者 ! |
非,对条件取反 |
| 其它运算符 | 功能 |
|---|---|
IN(值1,值2,...) |
在指定列表中,相当于多个 OR 条件 |
BETWEEN .. AND .. |
在某个范围内(包括边界值) |
IS NULL |
判断是否为空值 |
LIKE |
模糊匹配,% 表示任意多个字符,_ 表示一个字符 |
示例
go
-- 例1.查询employees表中的员工 uid、name、age 字段,条件为:年龄超过30岁
mysql> SELECT uid, name, age FROM employees WHERE age > 30;
+------+--------+-----+
| uid | name | age |
+------+--------+-----+
| 003 | 王五 | 35 |
| 005 | 钱七 | 32 |
| NULL | 吴十 | 31 |
+------+--------+-----+
-- 例2.查询employees表中的员工 uid、name、gender、salary 字段,条件为: 性别为男 且 薪资大于等于 10000
mysql> SELECT uid, name, gender, salary FROM employees WHERE gender = '男'AND salary >= 10000;
+------+--------+--------+----------+
| uid | name | gender | salary |
+------+--------+--------+----------+
| 003 | 王五 | 男 | 16000.00 |
| 007 | 周九 | 男 | 11500.00 |
+------+--------+--------+----------+
-- 例3.查看 employees 表中的城市地点为重庆或程度的员工信息
mysql> SELECT * FROM employees WHERE city IN ('北京', '上海');
| id | uid | name | gender | age | phone_number | skills | id_card | city | entry_date | salary |
+----+------+--------+--------+-----+--------------+------------------------------------------------+--------------------+--------+------------+----------+
| 2 | 002 | 李四 | 女 | 28 | 13900139000 | {"测试": "高级", "项目管理": "中级"} | 500102199201010002 | 北京 | 2020-02-15 | 15800.00 |
| 3 | 003 | 王五 | 男 | 35 | 13700137000 | {"架构": "高级", "数据库": "专家"} | 500102198801010003 | 上海 | 2019-05-10 | 16000.00 |
-- 例4.查询employees表中的员工 uid、name、gender 字段,条件为:员工编号为空的。
mysql> SELECT uid, name, gender FROM employees WHERE uid ISNULL;
| uid | name | gender |
+------+--------+--------+
| NULL | 吴十 | 女 |
-- 例5.查询employees表中的员工 uid、name、salary 字段,条件为:性别为男,年龄小于30岁,薪资大于等于10000 小于15000 。
SELECT uid, name, gender, salary FROM employees WHERE gender = '男'AND age < 30AND (salary >= 10000AND salary < 15000);
-- 或者使用 BETWEEN 关键字进行范围查询
SELECT uid, name, gender, salary FROM employees WHERE gender = '男'AND age < 30AND (salary BETWEEN10000AND15000);
| uid | name | gender | salary |
+------+--------+--------+----------+
| 007 | 周九 | 男 | 11500.00 |
-- 例6.查询employees表中的员工 uid、name、skills 字段,条件为:skills 字段包含"专家"关键字
SELECT uid, name, skills FROM employees WHERE skills LIKE'%专家%';
| uid | name | skills |
+------+--------+------------------------------------------------------+
| 003 | 王五 | {"架构": "高级", "数据库": "专家"} |
| NULL | 吴十 | {"产品经理": "高级", "市场分析": "专家"} |
-- 例7.显示employees表中的员工 uid、name 字段,条件为:uid 不为空
SELECT uid, nameFROM employees WHERE uid ISNOTNULL;
-- 或者使用 NOT 关键字进行取反操作
SELECT uid, nameFROM employees WHERENOT (uid ISNULL);
| uid | name |
+------+--------+
| 001 | 张三 |
| 002 | 李四 |
| 003 | 王五 |
| 004 | 赵六 |
| 005 | 钱七 |
| 006 | 孙八 |
| 007 | 周九 |5.分组聚合查询
描述:在学习分组查询之前,我们先来了解一下聚合函数的概念,以及相关函数的介绍, 然后再学习分组查询过滤的语法及其示例。
聚合函数
聚合函数是对一组值执行计算并返回单个值的函数,常见的聚合函数包括 COUNT、SUM、AVG、MAX 和 MIN 等。
-
COUNT():计算行数 -
SUM():计算和 -
AVG():计算平均值 -
MAX():计算最大值 -
MIN():计算最小值
温馨提示:若字段中存在 NULL 值,聚合函数会忽略这些值进行计算。
语法示例
go
-- # 语法
SELECT 聚合函数(字段名) FROM 表名 [WHERE 条件] [GROUPBY 分组依据列名] [HAVING 过滤条件];
-- # 示例
-- 例1.查询employees表中的员工总数
mysql> SELECTCOUNT(*) AS'员工总数'FROM employees;
| 员工总数 |
+--------------+
| 8 |
-- 例2.查询employees表中的员工总数,并按性别分组
mysql> SELECT gender, COUNT(*) AS'员工数'FROM employees GROUPBY gender;
| gender | 员工数 |
+--------+-----------+
| 男 | 4 |
| 女 | 4 |
-- 例3.查询employees表中的男、女员工平均、最高、最低薪资
mysql> SELECT gender, AVG(salary) AS'平均薪资'FROM employees GROUPBY gender;
| gender | 平均薪资 |
+--------+--------------+
| 男 | 11000.000000 |
| 女 | 13525.000000 |
mysql> SELECT gender, MAX(salary) AS'最高薪资'FROM employees GROUPBY gender;
| gender | 最高薪资 |
+--------+--------------+
| 男 | 16000.00 |
| 女 | 15800.00 |
mysql> SELECT gender, MIN(salary) AS'最低薪资'FROM employees GROUPBY gender;
| gender | 最低薪资 |
+--------+--------------+
| 男 | 7500.00 |
| 女 | 12000.00 |
-- 例4.查询employees表中的员工总数,并按性别分组,条件为:薪资大于等于10000
mysql> SELECT gender, COUNT(*) AS'员工数'FROM employees WHERE salary >= 10000GROUPBY gender;
| gender | 员工数 |
+--------+-----------+
| 女 | 4 |
| 男 | 2 |
-- 例5.查询employees表中的各城市员工数,并且只显示员工数小于2的城市,这里特别注意,在HAVING后面使用的是别名,而不是聚合函数。
mysql> SELECT city, COUNT(*) AS'员工数'FROM employees GROUPBY city HAVING 员工数 < 2;
--- 其他示例,因为HAVING后面也直接使用聚合函数
mysql> SELECT city, COUNT(*) AS'员工数'FROM employees GROUPBY city HAVINGCOUNT(*) < 2;
| city | 员工数 |
+--------+-----------+
| 重庆 | 1 |
| 北京 | 1 |
| 上海 | 1 |
| 杭州 | 1 |
| 深圳 | 1 |
| 广州 | 1 |
-- 例6.查询入职时间在 2018~2019 年间,并根据工资地址分组,获取员工数量大于等于2的工作地址
SELECT city, COUNT(*) AS'员工数'FROM employees WHERE entry_date BETWEEN'2018-01-01'AND'2019-12-31'GROUPBY city HAVING`员工数` >= 2;
| city | 员工数 |
+--------+-----------+
| 成都 | 2 |
-- 例7.验证聚合函数对 NULL 值的处理, 由于吴十员工的 uid 为 NULL,因聚合函数会忽略 NULL ,所以 COUNT(uid) 只统计了 7 条数据(特别注意)。
SELECTCOUNT(uid) FROM employees;
| COUNT(uid) |
+------------+
| 7 |温馨提示:HAVING 子句用于对分组后的结果进行过滤,它与 WHERE 不同之处在于,WHERE 在数据分组前进行条件过滤,而 HAVING 则在数据分组后进行,因此 WHERE 不能对聚合函数进行判断,执行顺序:WHERE -> 聚合函数 -> HAVING。
6.排序查询
描述:ORDER BY 子句用于对查询结果进行排序,可以按照一个或多个列的值进行升序(ASC)或降序(DESC)排列。默认情况下,如果没有指定 ASC 或 DESC,则默认为 ASC 升序排列。
go
-- # 语法
SELECT 字段名 FROM 表名 [WHERE 条件] [GROUPBY 分组依据列名] [HAVING 过滤条件] ORDERBY 排序依据列名 [ASC|DESC];
-- # 示例
-- 例1.查询employees表中的所有员工信息,并按薪资降序排列
mysql> SELECTname,salary FROM employees ORDERBY salary DESC;
| name | salary |
+--------+----------+
| 王五 | 16000.00 |
| 李四 | 15800.00 |
| 孙八 | 13500.00 |
| 吴十 | 12800.00 |
| 赵六 | 12000.00 |
| 周九 | 11500.00 |
| 钱七 | 9000.00 |
| 张三 | 7500.00 |
-- 例2.查询员工表中薪资大于等于10000的员工信息,并按年龄降序,入职时间升序排列
mysql> SELECTname,age,salary,entry_date FROM employees WHERE salary >= 10000ORDERBY age DESC,entry_date ASC;
| name | age | salary | entry_date |
+--------+-----+----------+------------+
| 王五 | 35 | 16000.00 | 2019-05-10 |
| 吴十 | 31 | 12800.00 | 2019-09-18 |
| 孙八 | 29 | 13500.00 | 2020-11-12 |
| 李四 | 28 | 15800.00 | 2020-02-15 |
| 周九 | 27 | 11500.00 | 2021-07-30 |
| 赵六 | 26 | 12000.00 | 2021-03-20 |7.分页查询
描述:limit 子句用于对查询结果进行分页,可以指定返回的记录数和起始位置。特别注意,起始索引从0开始,起始索引=(查询页码-1)*每页显示记录数,若查询的是第一页,则起始索引为0。
go
-- # 语法
SELECT 字段名 FROM 表名 [WHERE 条件] [GROUPBY 分组依据列名] [HAVING 过滤条件] ORDERBY 排序依据列名 [ASC|DESC] LIMIT 开始索引,每页显示记录数;
-- # 示例
-- 例1.查询employees表中的前5条记录
mysql> SELECT uid,name,gender,age,phone_number,id_card,entry_date FROM employees LIMIT0,5;
| uid | name | gender | age | phone_number | id_card | entry_date |
+------+--------+--------+-----+--------------+--------------------+------------+
| 001 | 张三 | 男 | 30 | 13800138000 | 500102199001010001 | 2020-01-01 |
| 002 | 李四 | 女 | 28 | 13900139000 | 500102199201010002 | 2020-02-15 |
| 003 | 王五 | 男 | 35 | 13700137000 | 500102198801010003 | 2019-05-10 |
| 004 | 赵六 | 女 | 26 | 13600136000 | 500102199601010004 | 2021-03-20 |
| 005 | 钱七 | 男 | 32 | 13500135000 | 500102199001010005 | 2018-08-05 |
-- 例2.查询employees表中的第6条到第10条记录,即第二页
mysql> SELECT uid,name,gender,age,phone_number,id_card,entry_date FROM employees LIMIT5,5;
| uid | name | gender | age | phone_number | id_card | entry_date |
+------+--------+--------+-----+--------------+--------------------+------------+
| 006 | 孙八 | 女 | 29 | 13400134000 | 500102199301010006 | 2020-11-12 |
| 007 | 周九 | 男 | 27 | 13300133000 | 500102199501010007 | 2021-07-30 |
| NULL | 吴十 | 女 | 31 | 13200132000 | 500102199101010008 | 2019-09-18 |温馨提示:分页查询是数据库方言,不同的数据库管理系统(DBMS)在处理分页查询时可能会有所不同,例如 MySQL 使用 LIMIT 关键字进行分页,而 MsSQL 使用 OFFSET 和 FETCH NEXT 关键字,Oracle 使用 ROWNUM 关键字等,这一点需要注意。
总结
描述:上面小节中,主要介绍了 SQL 查询的基础语法,包括选择、过滤、分组、排序和分页等操作。这些基础操作是构建复杂 SQL 查询语句的基石,掌握它们对于进行有效的数据检索和分析至关重要,使用下图简单总结一下:
weiyigeek.top-DQL基础查询语句总结图
SQL 查询语子句执行顺序
描述:在编写基础 SQL 查询语句时,子句关键字执行顺序如下所示:
-
首先是
FROM子句,确定数据来源 -
其次是
WHERE子句,对数据进行条件过滤 -
再次是
GROUPBY 子句,对数据进行分组 -
接着是
HAVING子句,对分组后的数据进行过滤 -
之后是
SELECT子句,确定输出哪些列 -
紧接着是
ORDER BY子句,对结果进行排序 -
最终是
LIMIT子句,对结果进行分页
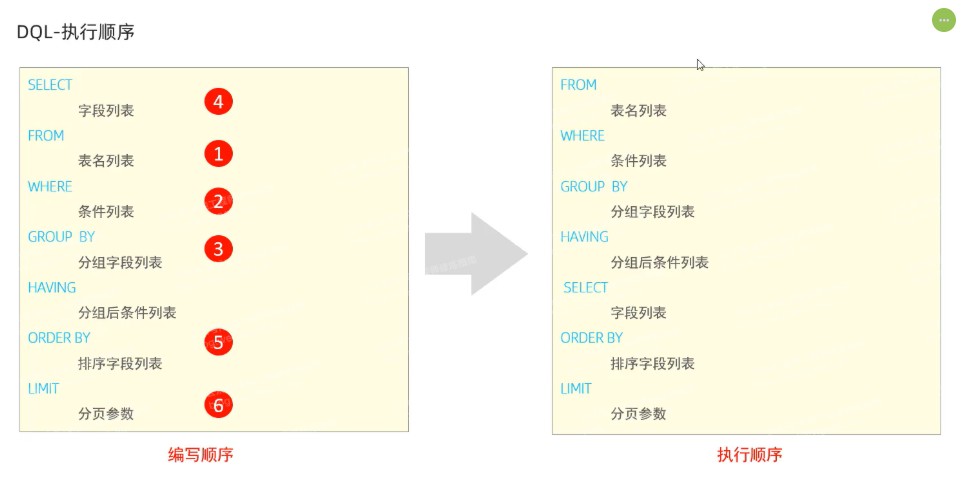 weiyigeek.top-DQL 语句及关键字执行顺序图
weiyigeek.top-DQL 语句及关键字执行顺序图
那如何来验证这个执行顺序呢?下面便跟随作者一起动手使用 SQL 语句来实践吧。
go
-- # 例如,查询employees表中年龄大于25的员工姓名和年龄,并按年龄降序排列
SELECTname,age FROM employees WHERE age > 25ORDERBY age DESC;
| name | age |
+--------+-----+
| 王五 | 35 |
| 钱七 | 32 |
| 吴十 | 31 |
| 张三 | 30 |
| 孙八 | 29 |
| 李四 | 28 |
| 周九 | 27 |
| 赵六 | 26 |
-- # 验证 FROM 与 WHERE 子句的执行顺序,可以使用 age 表别名的方式来验证。
SELECTname,age FROM employees e WHERE e.age > 25ORDERBY age DESC; -- 执行成功的SQL语句,说明FROM子句先执行。
-- # 当然查询语句中没有分组、分组过滤字句时,将直接跳到 SELECT 中,同样验证 SELECT 子句的执行顺序,可以使用表列名来测试。
-- 执行成功的SQL语句,说明 SELECT 子句在 FROM 之后执行。
SELECT e.name, e.age FROM employees e WHERE e.age > 25ORDERBY age DESC;
-- # 验证 ORDER BY 子句的执行顺序,使用 SELECT 指定的字段别名来测试。
-- 执行成功的SQL语句,说明 ORDER BY 子句在 SELECT 之后执行。
SELECT e.name, e.age AS'年龄'FROM employees e WHERE e.age > 25ORDERBY 年龄 DESC;
-- 报错:ERROR 1054 (42S22): Unknown column '年龄' in 'where clause' 由于在 WHERE 子句在 SELECT 之前就执行了,所以无法获取 SELECT 子句定义的别名。
SELECT e.name, e.age AS'年龄'FROM employees e WHERE 年龄 > 25ORDERBY 年龄 DESC;最后,通过实践上述示例,你可以更好地理解如何在不同的场景下应用这些基本查询技巧。

END
加入:作者【全栈工程师修炼指南】知识星球
『 全栈工程师修炼指南』星球,主要涉及全栈工程师(Full Stack Development)实践文章,包括但不限于企业SecDevOps和网络安全等保合规、安全渗透测试、编程开发、云原生(Cloud Native)、物联网工业控制(IOT)、人工智能Ai,从业书籍笔记,人生职场认识等方面资料或文章。
Q: 加入作者【全栈工程师修炼指南】星球后有啥好处?
✅ 将获得作者最新工作学习实践文章以及网盘资源。
✅ 将获得作者珍藏多年的全栈学习笔记(需连续两年及以上老星球友,也可单次购买)
✅ 将获得作者专门答疑学习交流群,解决在工作学习中的问题。
✅ 将获得作者远程支持(在作者能力范围内且合规)。

获取:作者工作学习全栈笔记
作者整理了10年的工作学习笔记(涉及网络、安全、运维、开发),需要学习实践笔记的看友,可添加作者微信或者回复【工作学习实践笔记】,当前价格¥299,除了获得从业笔记的同时还可进行问题答疑以及每月远程技术支持,希望大家多多支持,收获定大于付出!
知识推荐 往期文章
若文章对你有帮助,请将它转发给更多的看友,若有疑问的小伙伴,可在评论区留言你想法哟 💬!