还记得 DeepMind 的 Genie 3 世界模型吗?它首次让世界模型真实地模拟了真实世界。
最近,X 博主 anandmaj 在一个月内复刻 Genie 3 的核心思想,开发出了 TinyWorlds,一个仅 300 万参数的世界模型,能够实时生成可玩的像素风格环境,包括 Pong、Sonic、Zelda 和 Doom。

帖子附带演示视频,展示了模型通过用户输入实时生成视频帧的过程。
博主还分享了从架构设计到训练细节的完整经验,并开源了代码仓库。
理解世界模型
世界模型是一类神经网络,它们通过生成视频来模拟物理世界。
DeepMind 在 Genie 3 上展示了这一理念的潜力:当世界模型在大规模视频数据上训练时,会出现类似 LLM 中的「涌现能力」。例如:
-
可控性:按下方向键,镜头会随之平移。
-
一致性:离开房间再返回,墙上的新油漆依旧存在。
-
质量:水坑中的倒影清晰可见。
在 Genie 出现之前,研究者普遍认为要扩展世界模型,必须依赖带动作标注或包含三维结构的数据。
然而 DeepMind 发现,只要足够规模化地训练原始视频,这些高级行为便会自然涌现,就像语言模型会自然习得语法和句法一样。
挑战在于:世界模型的训练通常需要逐帧的动作标签(例如「按下右键 → 镜头右移」)。这意味着我们无法直接利用互联网中庞大的未标注视频。
Genie 1 给出的解决方案是先训练一个动作分词器,自动推断帧间的动作标签。这样一来,就可以把海量未标注视频转化为可用的训练资源。

这也是 Genie 3 能够扩展至数百万小时 YouTube 视频,并解锁上述涌现能力的关键所在。
受此启发,anandmaj 从零实现了一个最小化版本的世界模型:TinyWorlds。
构建数据集
在开始训练 TinyWorlds 前,作者首先要决定模型能够生成怎样的游戏世界。模型训练时接触的环境,决定了它未来的生成范围。
因此,TinyWorlds 的数据集由处理过的 YouTube 游戏视频构成,包括:
-
Pong:经典的雅达利双人游戏
-
Sonic:二维横版动作平台
-
Zelda:鸟瞰式冒险
-
Pole Position:3D 像素赛车
-
Doom:3D 第一人称射击

构建时空变换器
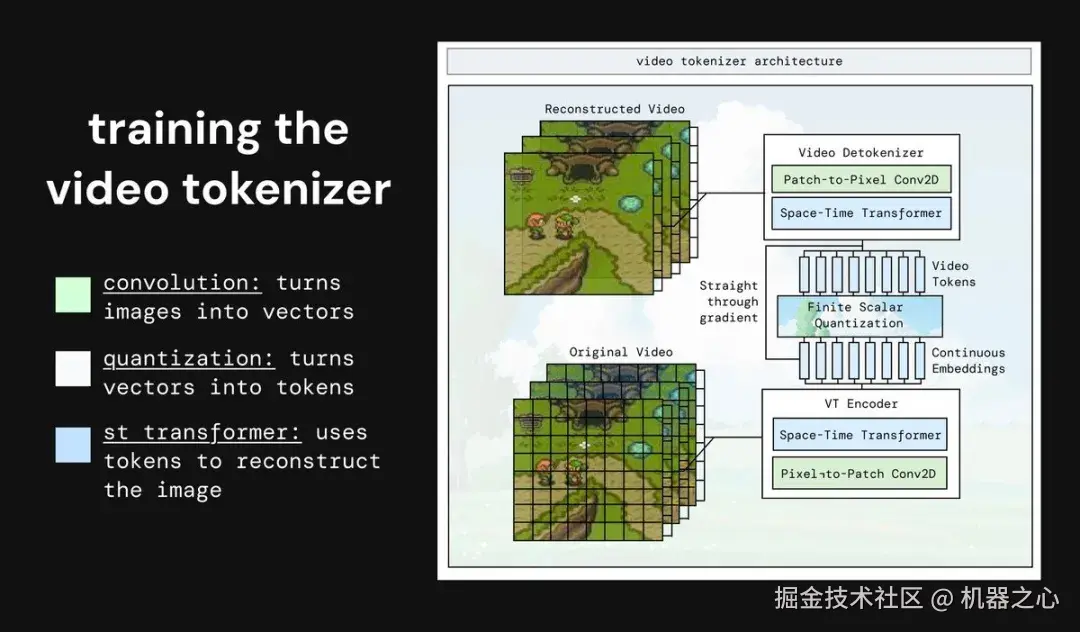
与只需处理一维文本的大语言模型不同,视频理解需要处理三维数据(高度 × 宽度 × 时间)。TinyWorlds 的核心是一个时空变换器(Space-time Transformer),它通过三层机制来捕捉视频信息:
-
空间注意力:同一帧内部的 token 相互关联。
-
时间注意力:token 关注前几个时间步的信息。
-
前馈网络:token 经过非线性处理以提取更高层次特征。
动作如何影响视频生成?作者尝试了两种方式:拼接动作与视频表示,或利用动作对表示进行缩放与移位。实验表明后者效果更好,最终被采纳。
同时,TinyWorlds 也借鉴了大语言模型的优化技巧:SwiGLU 加速学习,RMSNorm 提升稳定性,位置编码则用于指示 token 在图像中的位置。
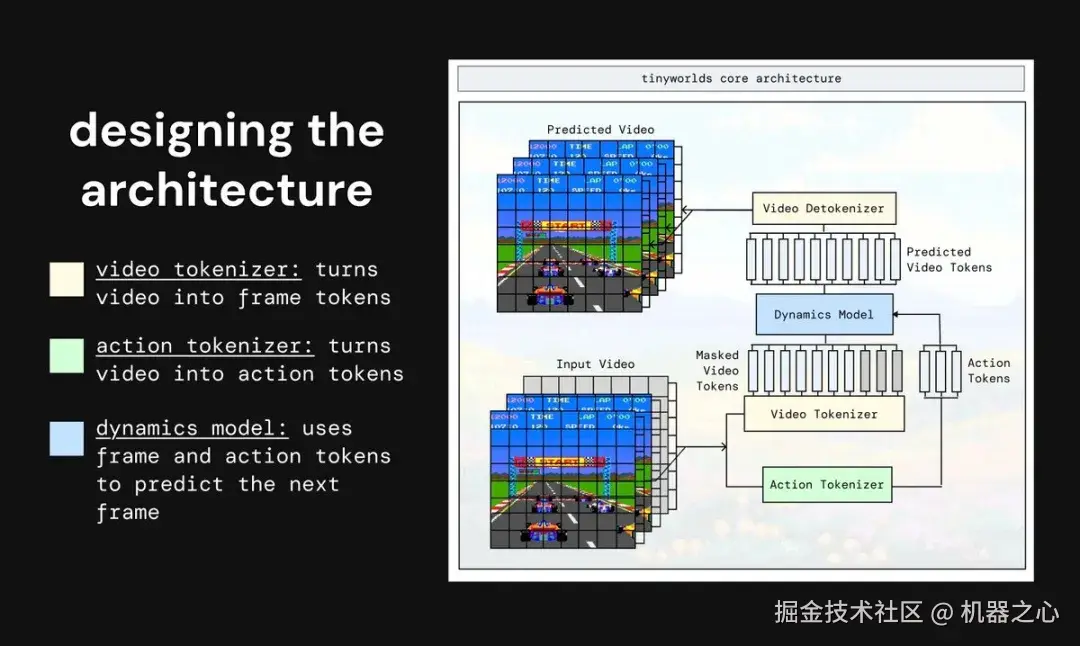
架构设计与分词策略
在生成方式上,作者比较了扩散模型与自回归模型。
TinyWorlds 最终选择自回归,因为它推理更快,适合实时交互,训练也更高效,且实现更简洁。
最终架构由三个模块组成:
-
视频分词器:将视频压缩为 token。
-
动作分词器:预测两帧之间的动作。
-
动力学模型:结合历史视频和动作,预测未来帧。
视频分词器通过有限标量量化(FSQ),将图像划分为立方体,并用这些立方体表示图像块。这样产生的小 token 信息密集,减轻了动力学模型的预测负担。
动作分词器的任务是从原始视频中自动生成帧间动作标签,使模型可以在未标注数据上训练。

在训练初期,它容易忽略动作信号。为解决这一问题,作者引入了掩码帧(迫使模型依赖动作)和方差损失(鼓励编码器覆盖更多可能性)。
在小规模实验中,动作 token 尚未完全映射到具体操作(如「左」「右」),但通过扩大模型或引入少量监督标签,这一问题有望改善。
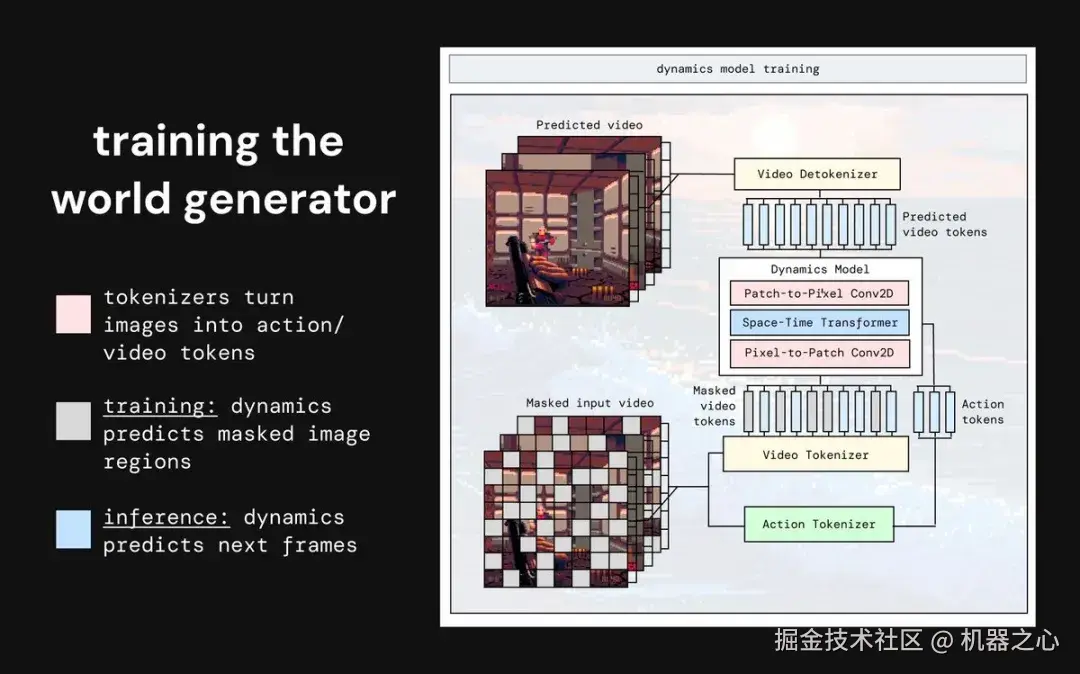
训练世界生成器
动力学模型是整个系统的「大脑」,负责结合视频与动作预测未来帧。训练中它通过预测掩码 token 学习时序关系,推理时则根据用户输入动作生成下一帧。最初由于模型过小,性能停滞且输出模糊;扩大规模后效果显著提升。
尽管 TinyWorlds 只有 300 万参数,它依然能够生成可交互的像素风格世界:
-
驾驶《Pole Position》中的赛车
-
在《Zelda》的地图上探索
-
进入《Doom》的 3D 地牢
虽然生成的画面仍显模糊、不连贯,但已经具备可玩性。
作者认为,若扩展至千亿级参数并引入扩散方法,生成质量会有巨大提升。这正是「苦涩的教训」的再一次印证:规模与数据往往胜过技巧。
参考链接:
x.com/Almondgodd/...