一图胜千言
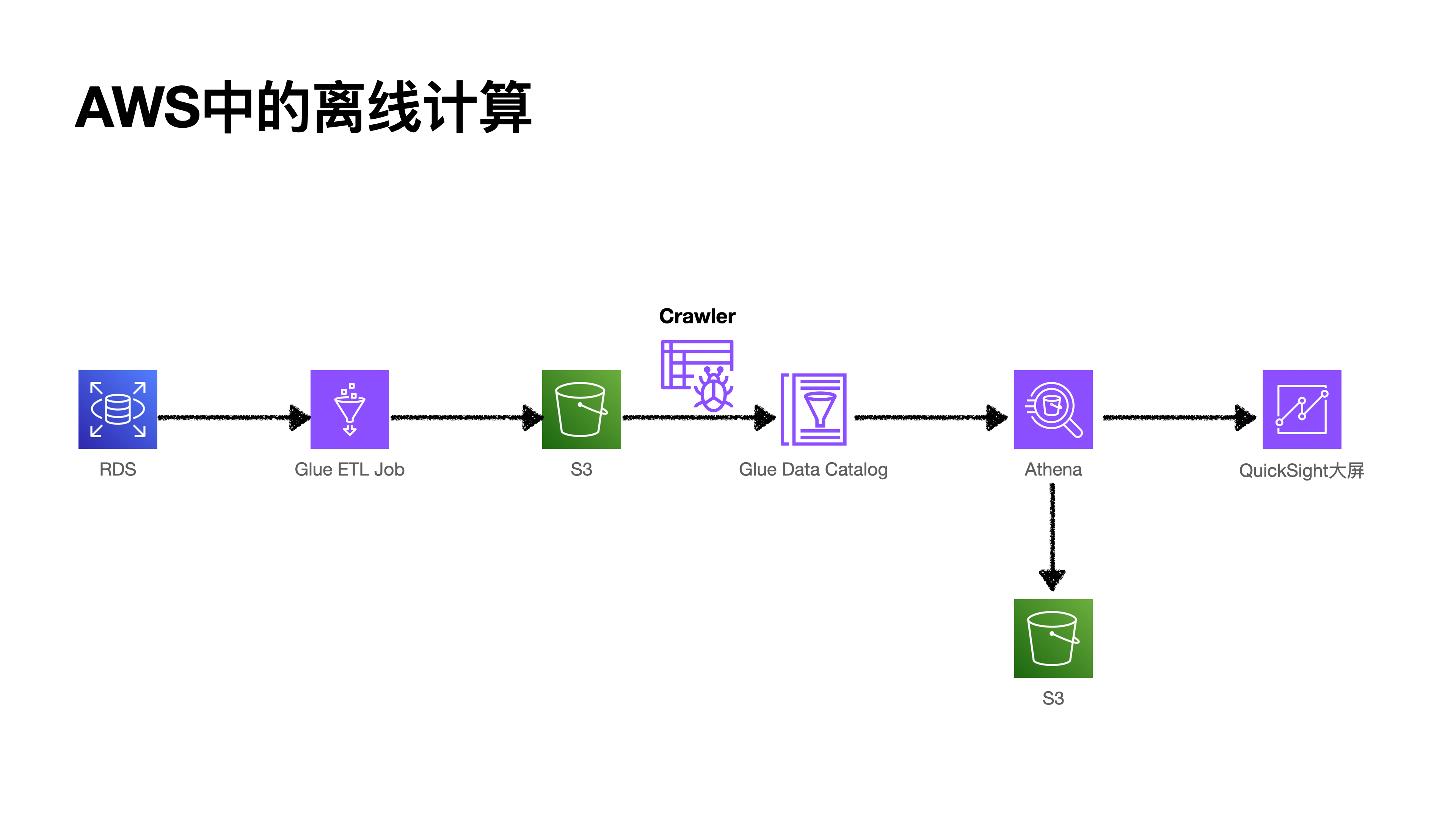
这里主要是通过Glue ETL Job将普通业务库(MySQL)里面的表数据,每日定时任务写入前天的数据到s3(保存为Hadoop的格式为parquet),然后,使用爬虫Crawler定时从S3桶中爬数据,爬到Glue的数据库和表中,即Glue Data Catalog,然后,使用Athena进行查业务聚合查询,结果保存到s3桶中,并使用QuickSight呈现为大屏。这就是AWS最简单的大数据离线计算大屏项目了。
这里主要是通过Glue ETL Job将普通业务库(MySQL)里面的表数据,每日定时任务写入前天的数据到s3(保存为Hadoop的格式为parquet),然后,使用爬虫Crawler定时从S3桶中爬数据,爬到Glue的数据库和表中,即Glue Data Catalog,然后,使用Athena进行查业务聚合查询,结果保存到s3桶中,并使用QuickSight呈现为大屏。这就是AWS最简单的大数据离线计算大屏项目了。